
多模态南海疆维权证据本体模型构建*
2024-04-25 01:45司徒凌云沈固朝
情报杂志 2024年4期
司徒凌云 孙 鹤 石 进 沈固朝
(1.南京大学信息管理学院 南京 210023;2.中国南海研究协同创新中心 南京 210023 )
南海疆维权关乎国家安全、区域和平与亚太经济发展。中国一直坚持“搁置争议,共同开发”的原则开展南海活动,然而随着域外势力的持续介入和东南亚各声索国的单边行动,南海局势持续紧张,中国南海疆域的维权和维稳面临挑战。因此,加快收集南海疆维权证据资料、构建本体模型、提取证据要素、挖掘证据关系、建立维权证据链成为维护我国南海权益,服务中国海洋强国战略的重大需求和紧迫任务。
以中国南海研究协同创新中心和中国南海研究院为代表,耗费十余年,构建了中国南海疆全文数字资料库,其中包括文献库、地图库、影像库、视频库以及档案库等多个数据库,为南海疆维权证据链的构建提供了强大的数据基础。然而,面对海量、异构、内容丰富的资料库群,如何有效地定义多模态南海疆维权证据的本体模型成为关键。本体模型的构建旨在从不同类型的南海疆资料中提取有效证据、识别证据关系,进而构建维权证据链条。
南海疆维权证据本体模型的构建面临挑战。首先,南海疆资料具有多源异构的特点,这些资料来源于不同的渠道,使用不同的数据标准。因此,本体模型的构建需要综合考虑资源差异性,以实现对南海疆资料的标准化处理。其次,南海疆资料具有多时态、多样态、多语言、多载体、多学科等多模态特征。过去的本体模型或知识表示工作主要针对"单一模态"的文本型数据,对于图像型数据的处理尚不充分。
因此,本研究面向南海疆维权服务,构建了统一的多模态南海疆维权证据本体模型,涵盖文本型和图片型资料,实现对海量异构南海疆资料的标准化处理。以《开罗宣言》为例,利用本体模型对其中南海维权语义进行结构化表达,验证了本体模型的有效性。多模态南海疆维权证据本体模型的构建对于南海疆维权证据实体的抽取以及证据关系的挖掘具有基础性支撑作用。
1 文献综述
1.1 本体模型构建研究
传统的知识表示方法,如谓词逻辑表示法、产生式表示法、框架表示法、语义网络表示法和面向对象表示法等[1],在知识表示研究的发展过程中发挥了重要作用,同时也存在一定的限制[2]。为了克服这些限制,本体模型应运而生。本体模型能够对领域实体进行本质抽象,通过多种知识元素反映实体之间的关联[3]。作为一种主流的知识表示方法[4],本体模型已经受到学界与业务的广泛研究与应用。
在文本型知识的本体构建研究方面,发展较快,取得了丰富的成果。例如,毛军[5]在RDF叙词表研究方面做出了贡献,薛建武[6]则致力于枪械领域本体的构建。然而,传统的通过手动构建本体模型的方法效率不高[7]。为此,学界提出了通过制定叙词表转换规则并设计算法来实现本体半自动或自动化的构建。但某些构建完成的本体存在与应用脱节、难以复用或集成、概念体系不够规范等问题。因此,专家学者开始关注基于顶层本体模型进行下层本体构建的研究。其中,SPAR[8]是面向语义出版应用最具代表性的本体集合。该本体集合包含了8个核心本体,分别描述了文献题录、参考文献的不同属性。上述研究为解决本体构建过程中的问题提供了新的思路。
基于图像型知识的本体构建研究通常采用基于顶层本体的方法。例如,朱学芳等[9]的研究复用了CIDOC-CRM[10]和FOAF[11]和两个本体标准,以“非遗—图像”的二元概念为核心,展现了非遗项目与图像资源之间的一对多关系。赵雪芹等人的研究[12]选择参考CIDOC-CRM概念参考模型、FOAF本体、TIME本体、EVENT本体以及都柏林核心集(DC)元数据标准等,致力于解决传统图像资源组织方式中细粒度不够、语义程度不高、关联性不强的问题。利用图像知识元素构建了数字人文图像本体模型,从而描述了图像中复杂的语义概念和属性关系。Srinivasa等人的研究[13]提出了一种从英文在线报纸的文本和图像数据中提取和集成犯罪实体与关系知识库的方法,并开发了Crime Base系统。该系统采用基于规则的方法从文本和图像标题中提取实体,并使用上下文语义相似性度量来关联从文本数据中提取的实体,使用图像特征来关联图像实体。
面向南海疆维权与维稳场景的应用,目前专家学者们更多地集中于基础资料整理和关键技术研究上,如司徒凌云等[14]首次提出了基于多模态知识图谱构建南海疆维权证据链系统;齐小英等[15]以南海历史事件、新闻数据及文献资料为语料库,构建了南海领域主题词表。该词表梳理了南海领域核心实体概念间的内在逻辑与知识脉络,为南海文献资源的语义分析提供组织工具与关联基础。程为等[16]探索了面向南海叙事的事件要素自动抽取方法,可以实从海量南海历史文本中快速、有效地抽取出各类型事件要素。沈固朝等[17]提出了一种基于描述规则的知识元抽取方法,实现从以篇幅为单位的主题词抽取到以句为单位的知识元抽取,实验表明该方法能够较好地完成民国南海文献的知识元抽取。彭玉芳等[18]基于BERT预训练模型和分面分类法,构建南海文献分类法,实现了对南海证据性资料的细粒度分类。王燕红等[19]构建了南海疆维权证据证明力综合指标体系,探索了基于证明力的维权证据关联,为南海司法维权场景下证据效力的量化研究提供了启发。丁晟春等[20]构建了南海问题本体及知识库,为南海问题智库的研究提供了有益参考。
目前本体模型相关研究很多,整体来看,本体模型的构建方法正逐步从基于叙词表的手动构建过渡至基于顶层本体复用的自动化构建。单独基于文本和图像模态资料进行本体模型构建的研究很多,但面向多模态资料的本体模型构建研究较少。面向海疆领域本体模型构建的研究日益丰富,但大多集中于该领域本体构建的基础资料整理、关键技术研究上,鲜有学者提出一个完整的适用于海疆维权的本体模型。
1.2 本体属性标记研究
本体属性标记技术,在本体模型构建过程中扮演着至关重要的角色,主要用于将语料库中的实体概念与本体中的属性进行识别关联。因此,学术界对本体属性标记进行了深入的研究,包括属性抽取、属性归一化以及属性关联等。
针对文本型资料的标记,研究者们进行了多方面的探索。李斌等[21]以自动分析技术为基础,结合人工标记和校对,采用实体标记方法来解决同名异指和异名同指等问题。尽管取得了良好的结果,但人工标记仍然限制了效率的提高。宋宁远等[22]基于叙事性文本语义标记流程,选择GATE8.5.1作为标记工具,并利用插件来实现中文文本的标记,一定程度上实现了叙事性文本的半自动标记,但对于事件、情节等富语义文本内容的准确表征仍存在不足。Xu等[23]提出了一种用于物联网生态系统中移动和边缘服务自动标注的语义标注框架,通过爬取大型真实数据进行实验,对注释标注的分布进行深入分析,从而验证了方法的有效性。Shi等[24]通过微调BERT预训练模型,应用于ADME(吸收、分布、代谢和排泄)的自动语义标记,相较于传统的机器学习技术,实现了高达12.5%的绝对F1改进。Fernández-González[25]基于深度学习提出了一种基于指针网络的过渡语义角色标记方法,并在CoNLL-2009共享任务的大多数语言上取得了较好的性能。上述研究展示了在文本型资源标记领域的不断探索和创新,取得了一定的成果。然而,对于构建大规模、高质量语料库,标记技术仍需要进一步提高准确性和效率。
针对图片型资源的标记,L. Stork等人[26]提出了一种半自动化的标记模型和工具,用于对1820-1850年间荷兰印度群岛自然史委员会收集的8000页图书的图像进行扫描和注释。然而,图像语义的半自动化标记在标注精度、准确率和效率上仍然存在着局限性。Hofmann[27]提出了一种基于统计方法的图像自动化标记模型 PLSA,但为了避免过拟合问题,通常需要结合EM算法进行最大似然估计。随着机器学习和深度学习的迅速发展,专家学者们开始将机器学习和深度学习方法应用于图像的自动化标记。例如,Wang等[28]提出了一种基于数据驱动的方法,通过挖掘搜索结果来标记图像。该方法具有对离群数据鲁棒性的优势,但可能导致检索到大量相似但冗余或含有噪声的数据。Jin等[29]提出了一种半监督对抗网络来解决图像语义标记时标记数据不足的问题。通过在PASCAL VOC 2012和cityscape数据集上进行大量实验,他们证明了该方法只需少量标记图像即可达到优秀性能,验证了模型的有效性。这些研究展示了在图片型资源标记领域的持续创新。然而,仍需要在提高标记精度、准确率和效率的同时,解决冗余数据和标记语义的挑战。
2 多模态南海疆维权证据本体模型构建
2.1 多模态南海疆证据要素界定
本文借鉴了通用的本体模型CIDOC-CRM和FOAF来构建南海疆维权所需的证据本体模型。值得说明的是,本文将所有可能证明待证事实的证明材料统称为证据,并通过证据本身的客观属性、场景属性以及类型属性来确定维权证据的要素。周洪波[30]指出,证据应具备客观性、相关性和合法性。客观性指的是证据所反映的内容是客观存在的事实,这是证据的根本属性。相关性指的是证据与案件的待证事实之间存在客观联系[31]。合法性指的是证据必须按照法律要求和法定程序获得的事实材料。
基于南海资料的多模态特征,本文将南海维权证据分为文本型和图片型两类,其中图片型证据又细分为图像和地图证据。这样的划分是因为其他类型的南海疆资料,如视频和音频,可以转化为文本型和图片型两类。图1所示的是南海维权证据的本体层次结构,第一层和第二层是上层的多模态证据分类,第三层及以下是具体南海维权证据类的层次关系。第一层根据证据的模态将其分为文本型证据类和图片型证据类。第二层根据文本的发布来源将文本型证据类划分为官方文本类和私人文本类。官方文本类指的是由国家、政府部门、国际组织、国际机构等具有一定公信力的对象发布的文本型证据。私人文本类则是由个人发布的文本,例如国际条约和个人传记之间的区别。图片型证据类可以分为一般图片证据类和地图证据类。一般图片证据类包括会议照片、报纸图片、碑刻图片、画册等。而地图证据类则是专指对南海维权起到支撑作用的地图证据材料,例如中华民国地图等。第三层及更细分层次主要依据证据类之间的组成关系来确定层次关系。例如,“中华民国地图”类根据时期的不同,包括“1936年中国全图”“1946年新民中国地图”“1948年民国地图”等地图证据类。而“1948年民国地图”则包括“南沙群岛分布”“西沙群岛分布”等细分区域,“南沙群岛分布”又包括“中业岛”“西月岛”等岛礁类。通过这样的本体结构,我们能够清晰地描述南海维权证据的不同类型及其层次关系,有助于对证据进行有效的分类和组织。

图1 南海维权证据的本体层次结构
2.1.1文本型证据分类
国际法院对于领土主权归属问题受理的证据主要包括书面证据、口头证词和专家证据三种类型,其中以书面证据为主。在南海维权工作中,文本型证据是书面证据的重要组成部分。文本资料在证据层面的知识粒度较粗,长篇的文献资料中可能只有部分内容可作为具有专指性的有效证据。但面向南海维权的司法场景,需要对文献资料中的证据要素进行实现细粒度抽取。因此,本研究调研了国内学者对于海疆维权证据链构建的思考[32],复用了通用本体模型CIDOC-CRM、W3C[33]对于实体的界定,针对南海维权文本型证据的特点,构建了文本证据、时间、空间、标识、引源、证明效力、证据来源类型、证据主体、主权行为类型和证据倾向这10个核心实体概念。如图2所示,核心实体概念融合了证明价值(如证明效力、证据倾向等实体)和证据属性(如时间、空间等实体)两方面的特征,是本体模型构建的基准点。下文将详细介绍证据本体模型中各个核心实体概念。
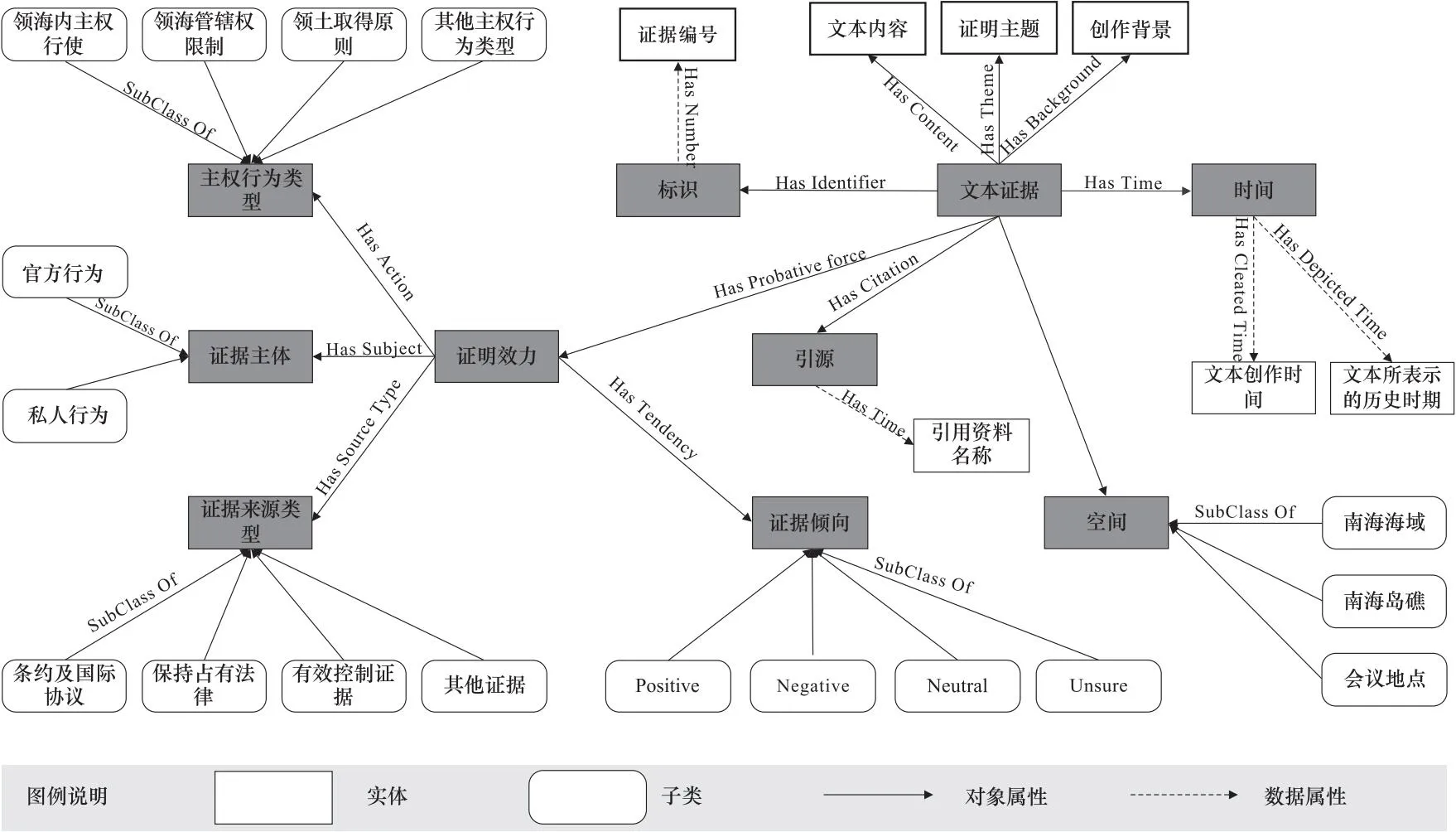
图2 文本型证据本体模型图
文本型证据(Textual evidence)是本文所构建的本体模型的基础之一。我们构建了标识、时间、空间、引源、文本内容、创作背景等属性,以此构建了整个知识网络。
标识(Identifier)是表示证据事件在计算机存储中的唯一编号,在进行实体标注时,需要依靠证据的标识进行标引。本文对从南海资料中抽取的证据进行编号,例如某条证据是抽取的第888条证据,则其编号为888。
时间(Time)用于描述证据事件的发生时间。文本型证据所描述的事件通常处于发生、发展和消亡的过程中。随着时间的变化,事件也会动态发展。时间信息对于判断事件发生的先后顺序、梳理事件的演变过程,具有重要价值。
空间(Space)用于描述证据事件的发生地点。空间下分为两个子类,分别是南海岛礁和南海海域。空间信息是定位具体问题的核心依据,根据空间信息,可以梳理出争议频发、有争议的主要区域。
引源(Citation)是文本型证据内容中引用的参考文献。引源能够提供该条证据的依据或出处。通过引源,可以找到更多相关的证据文本,增强某一证据主题的证明力。
证明效力(Probative Force)是文本证据的重要属性。根据前期工作文[34]对书面证据证明力大小认定规则的研究,本文将证据来源类型、证据主体、主权行为类型和证据倾向作为考量证明效力的标准。
证据来源类型(Source Type)用于描述获取南海文本证据实体的来源资料的所属类型。证据来源的所属类型也可以为判断证据的证明力提供帮助。例如,对于“南沙群岛属于中国”这一证据文本,如果来源是《开罗宣言》《波茨坦条约》等国际公约,可以根据证明力层级来判断该证据文本的证明力大小。
证据主体(Subject)指证据文本中出现的主语和宾语。证据主体能够直观地表示文本型证据所描述的行为对象,通常是国家、政府部门、行政司法执法机构、国际组织、国际机构或个人。
主权行为类型(Action)用于对证据中涉及的主体主权行为类型进行分类,或者针对不同主体的证据主题分类。本文将主权行为类型总体上分为领海内主权行使、第三方对领海管辖权的限制以及领土(岛屿)取得原则三大类及其他类。不同类别的主权行为证据具有不同的证明力级别,可以根据这些级别判断证据文本的证明力大小。
证据倾向(Tendency)主要包括四类情感,即Positive、Negative、Neutral和Unsure,用于表示该条证据在南海维权情境下的情感倾向。例如,Positive表示该事实描述/证据对“南海属于中国”这一主张有正向解释作用,而Unsure表示很难确定该证据的情感倾向。通过设立证据倾向核心类,可以更系统地判断和分类证据文本的证明力方向。
2.1.2图像型证据分类
在南海维权工作中,图像型证据同样具有重要价值。图像型证据主要包括会议照片、报纸图片、碑刻图片、画册和地图等。其中,地图作为一类重要的间接证据,在南海维权中具有特殊的地位。专家学者们已经对地图进行了广泛的研究,包括地图在解决领土争端中的证明价值以及构建南沙群岛主权地图子证据链等[34]。考虑到地图在支撑南海维权工作中的重要作用,本文将地图证据独立于图像型证据,并在后文对其详细说明。尽管图像型证据与文本型证据在模态上存在差异,但在维权逻辑上存在相通性。因此,本文基于已有的文本型证据实体分类框架,对图像型证据的要素进行界定。
如图3所示,本文构建了图像证据实体的要素,包括标识、时间、空间、图像内容、创作背景和技术参数等属性。在证明效力方面,与文本型证据有所不同,考虑了引源和图像的技术参数对证明效力的影响。如果图像型证据官方文件、维权文件或领域权威文献中被引用,那么该证据材料的证明力就会得到提升。因此,本文引入了引源类,并进一步分为被引文献、官方文件和维权文件三个子类,以具体反映引源因素对图像型证据证明效力的影响。图像证据的技术参数包括分辨率、清晰度等。一般来说,技术参数符合国际法庭对图像型证据的可采用标准,就会在司法维权场景中具有优势。因此,本文在图像型证据要素的界定中,借鉴了都柏林核心[35]关于图像的元数据标准,结合图像模态的特点,将图像的各个重要参数视为影响证据证明效力的重要因素。
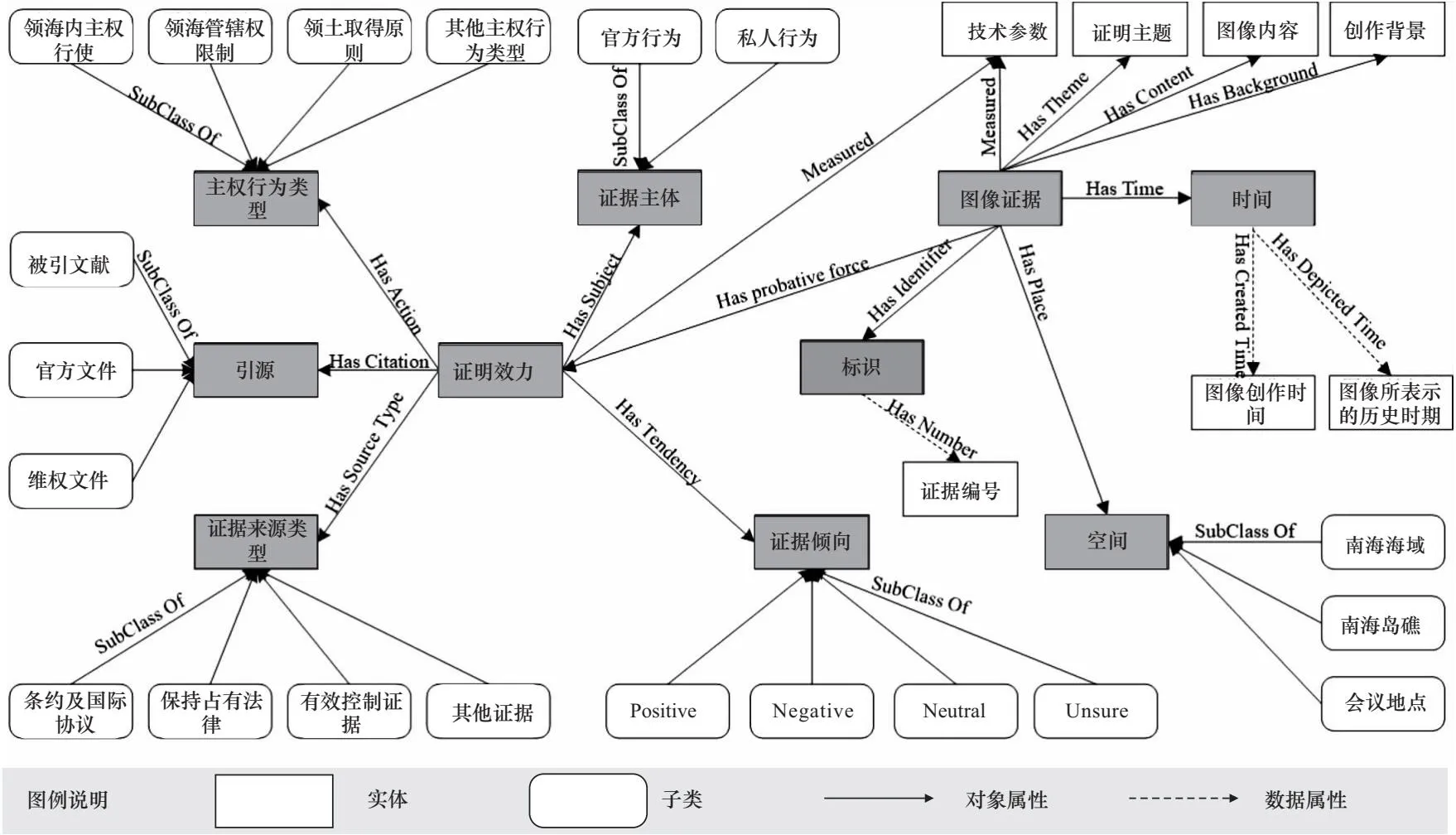
图3 图像型证据本体模型图
2.1.3地图型证据分类
地图证据在国际法院解决领土争端中具有关键作用,通常能够为领土主权的归属提供有力说明。例如,中国国民政府出版的《中国南海各岛屿图》《南海诸岛位置略图》《南海诸岛位置图》等地图具有较高的专业性和权威性,既体现了中国官方的立场,也成为中国拥有南海主权与治权的关键历史证据,同时也为当前中国维护南海诸岛主权提供了重要的法理依据。一般来说,国际法院将地图作为可采信证据的标准主要依赖于地图的来源、清晰度、比例、地图的官方地位、公开出版以及当事方随后的使用情况等因素[36]。
地图的证明效力通常会受到地图是否能够清晰反映国家意图的影响。具体来说,地图是否由国家官方绘制并发行,以及地图是否被官方文件引用或作为附件放入官方文件中,都会对地图证据的证明效力产生较大程度的影响。为了反映这一影响因素对地图证明效力的作用,本文设立了"来源主体"类和"引源"类。
地图的来源类型也会对其证明力大小产生一定程度的影响。一般认为,来自正式法律文件(如条约)中的地图比非政府组织报告中出现的地图更具证明力。因此,本文设立了“来源类型”类来刻画这一因素。
地图是否得到国际社会特别是周边有利害关系国家的承认或默认,也是判断地图证明效力的重要因素。如果一国在较长时期内对其他国家公开出版发行的、与自身主张不符的地图没有提出外交抗议或反对,并未在合理期限内将该事项提交适当的国际组织或国际法庭,可能会被国际司法机关认定为对该政治地理边界存在默认。因此,本文设立了“地图被承认度”类来反映这一因素。
地图的证明力在一定程度上也取决于其制作者是否中立和权威。一般来说,如果地图是由客观中立的专家绘制的,其证明力会增加;相反,如果地图是在争议的一方授意下制作的,其呈现的内容可能不够客观。因此,本文设立了“地图立场与倾向”类来考量中立性因素对地图证据证明力的影响。
地图的证明力与其技术上的精确度也有一定的相关性。因此,本文在“地图证据”类下设立了“技术参数”这一子类,以反映清晰度、比例尺等因素对地图证明力的影响。除以上与证明效力直接相关的实体概念以外,本文对地图证据还构建了4个核心实体概念,分别是地图证据实体、标识实体、时间实体、空间实体,从而形成一个较为完善的以地图证据证明效力为核心的南海维权地图证据本体模型,如图4所示。

图4 地图型图片证据本体模型图
2.2 多层次南海疆证据关系识别
证据关系识别是南海疆维权证据链构建的核心。南海疆维权证据间的语义关系层次多样、错综复杂。本文根据已界定的证据要素,集合场景要求与本体关系结构来定义证据要素之间的关联关系,主要包括属性层关系、逻辑层关系,以及证明层关系。
2.2.1属性层关系
实体类之间的属性层关系,主要分为对象属性关系和数据属性关系。对象属性关系通常表示证据要素之间或内部的语义关系;数据属性关系一般用来表示实体类固有的数据特征关系。对象属性关系包括类与子类之间的从属关系(subClassOf)、证据内容描述的时间(hasTime)等。数据属性关系包括证据技术参数包含的分辨率大小(hasResolution)、标识和证据编号之间的指向关系(hasNumber)等。本文复用了CIDOC CRM和FOAF本体模型标准,结合已经界定的证据要素,构建了17个对象属性关系和7个数据属性关系,如表1所示。

表1 多模态南海证据本体的属性层关系
2.2.2逻辑层关系
本研究参考了修辞结构理论,PDTB2.0[37]和ISO 24617-8[38]核心语义关系标准,基于多模态南海证据链构建需求,设计了12种逻辑层语义关系,具体列举如表2所示。其中,时间关系用于描述事件发生的先后顺序,以展现重要证据事件的动态发展过程;因果关系表示事件之间存在着因果关联,即有因必有果;印证关系是证据本体特有的一种语义逻辑关系,用于表示证据之间的相互印证关系;互斥关系则表明两个证据在某一证据主题的证明方向上是相反的;包含关系则表示某一证明主题下的证据之间存在层次关系。
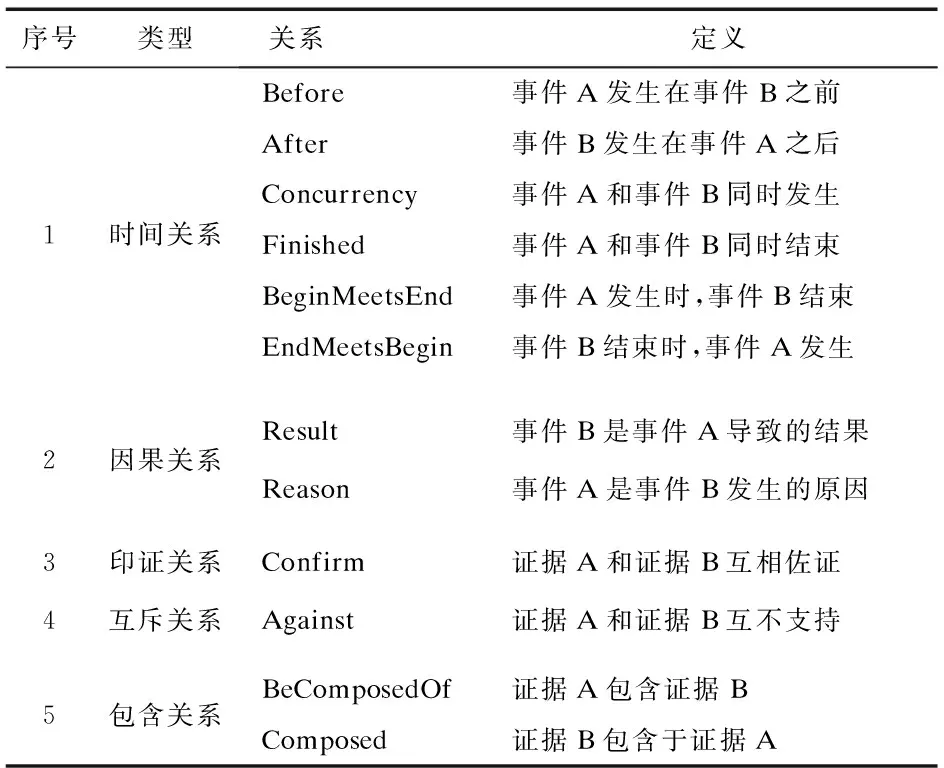
表2 多模态南海证据本体的逻辑层关系
为了支持多模态南海疆证据本体的语义推理和扩展,本文对逻辑层关系定义了语义属性,包括互逆属性和对称属性。互逆属性用于描述相互补充的关系,例如Before和After表示事件发生的先后顺序,BeginMeetsEnd和EndMeetsBegin表示事件的开始和结束相遇,BeComposed Of和Composed表示组成关系。对称属性则表示两个关系之间的对等性,例如Concurrency和Finished表示事件的同时发生,Result和Reason表示事件之间的因果关系。例如,如果已知事件B是事件A的结果,那么事件A是事件B的原因。
2.2.3证明层关系
针对文本型证据和图像型证据,基于已定义的证明力核心实体概念,结合文献[34]中关于南海维权证据证明力的分析,设计了多模态南海证据本体的证明层级关系,具体如表3所示。
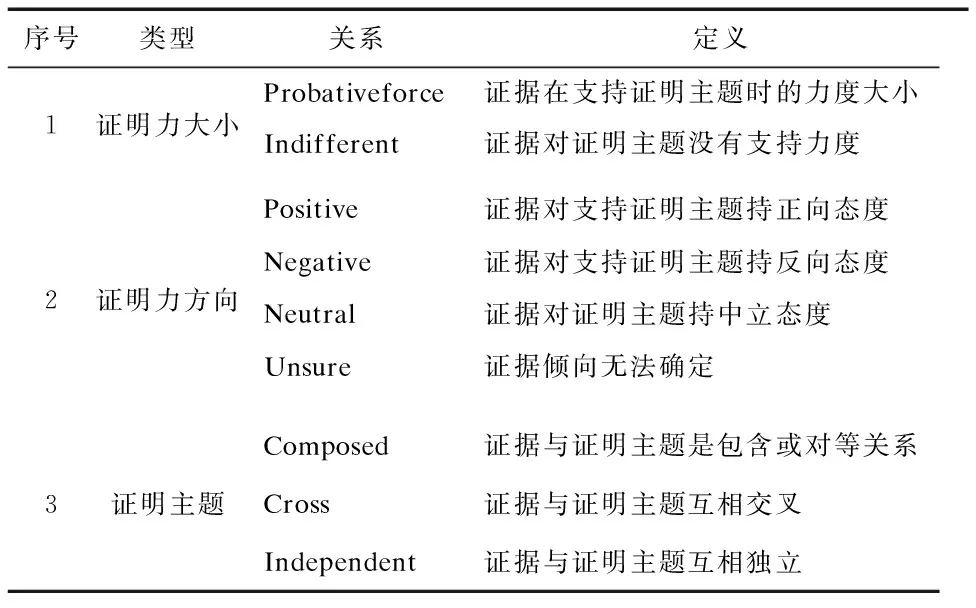
表3 多模态南海证据本体的证明层关系
本文主要从证据主体、证据来源类型和主权行为类型三个方面进行分析。对于图像型证据,还考虑了图像引源和重要的图像参数。在证据主体方面,通常认为官方行为的证明效力大于私人行为;在证据来源类型方面,按照国际法院解决领土争端的标准,通常认为证明力从高到低的顺序是:条约及国际协议>保持占有法律>有效控制证据>其他证据。对于地图证据,综合考虑地图来源类型、来源主体、引源、地图被承认度和地图技术参数等方面来分析证明力大小。证明力方向表示的是证据在特定证明主题下所支持的方向,在证据本体中体现为证据倾向。证明主题能够反映证据之间的相关程度,多个证据指向同一证明主题的关联程度越高,证据之间的联系也越紧密,对该主题的支持效力也越大。
2.3 多模态证据本体属性标记
2.3.1标记流程
本文旨在构建多模态南海维权证据本体模型,以实现对南海维权证据的细粒度语义的结构化表示。首先,需要对文本和图片模态的资料进行本体属性标记,即提炼多模态证据的特征词。然后,建立特征词之间的映射关系。最后,将多模态证据关联起来,形成证据链条[39]。
多模态证据本体属性的标记流程如图5所示。首先,根据多模态证据的事件触发词,对地图证据和其他证据进行标记。然后,对文本型证据和图像型证据进行证据内容分析,识别出证据本体所需的证据要素。对于地图证据,需要进行元数据录入,从南海地图库等知识库中导入地图证据的各个参数。接下来,基于已有的本体和受控词表,对文本和图像证据进行事件要素抽取,将抽取出来的证据要素赋值,并建立多层次关系。对于地图证据,需要进行实体识别,保留证据本体所需的特定实体,并通过关系识别建立实体之间的关联关系。最后,对结果进行规范化处理,输出标记结果。通过这一流程,多模态南海维权证据本体模型能够实现对南海维权证据的语义结构化表示,从而提供了更细粒度的证据分析和推理基础。这一过程当中设计多项关键技术,包括实体识别、事件抽取与关系识别等。
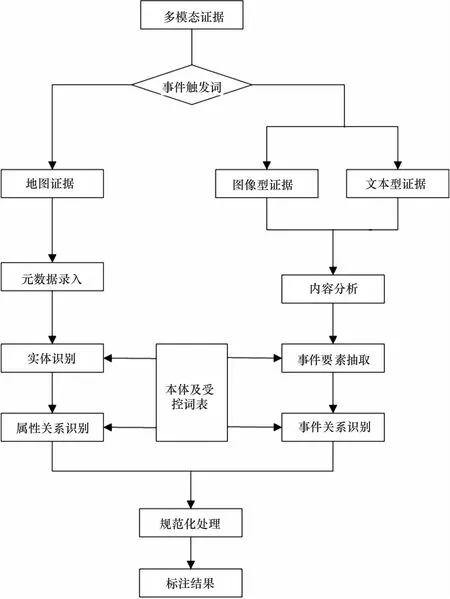
图5 多模态证据本体属性标记流程
2.3.2关键技术
a.实体识别。实体识别是从证据中识别出特定类型的实体,并将其正确分类[40]。尽管在多模态实体识别方面,专家学者已经取得了一些成果,但跨模态抽取与融合仍然是亟待解决的问题之一。目前的研究主要采用交叉Transformer来进行特征融合,但其融合方式相对单一,注意力机制在融合过程中的潜力尚未充分发挥。此外,将BERT应用于多模态学习的网络结构主要分为两类:一类是直接对视觉流和文本流进行跨模态预训练;另一类是先对两种模态进行编码,然后使用编码后的表示进行跨模态融合。其中,先编码再融合的网络结构效果更好。在当前的研究中,需要进一步探索更有效的跨模态抽取与融合方法,以提高实体识别的性能。同时,对注意力机制在融合过程中的应用进行优化,以充分利用不同模态之间的关联信息,提高跨模态信息抽取的准确性和效率。
b.事件抽取。事件抽取技术是对南海问题相关事件中具有标志性意义的事件进行整理和提取的过程,是构建南海维权证据本体并支持维权工作的基础工作。目前,主流的事件抽取技术可以分为两大类。第一类是基于自然语言处理工具的抽取方法,它通过利用自然语言处理工具来提取事件文本中的"主语+谓语+宾语"等结构。这种方法在通用文本中效果较好,对于中文文本常用的处理工具有LTP,对于英文文本常用的处理工具有StanfordNLP[41]。第二类是构建自动抽取模型来实现事件抽取,主要包括基于规则、基于机器学习和基于深度学习的方法。基于规则的方法通常是将人工设计的规则转化为程序规则,从而实现自动化处理。常用的机器学习基准模型包括HMM、SVM、CRF等;而常用的深度学习模型包括CNN、BiLSTM、Bi-GRU等。随着深度学习技术的发展,基于深度学习的方法在事件抽取任务中取得了显著的进展,但对于特定领域或任务,仍需要结合具体情况选择适合的方法并进行优化。
c.关系识别。关系识别目的在于挖掘给定事件之间的关系,从而快速地构建领域知识库。基于传统机器学习的事件抽取方法主要包括基于特征向量的方法[42]、基于核函数的方法[43],应用于事件关系识别的深度学习模型主要有CNN、RNN、GCN等。属性关系识别是领域本体及知识图谱构建的重要基础,目前国内外的研究主要集中在实例及属性的提取,或属性和属性值对的提取[44]。为了提高属性关系抽取的性能,目前较为主流的关系识别技术是通过机器学习和深度学习模型进行算法设计,来提高精度和适应各种复杂环境。
2.3.3实例分析
《开罗宣言》是世界反法西斯战争时期,中美英三国首脑在埃及开罗举行会议后签署的重要文件,宣言中提到多项涉及我国在战争中被侵略领土的解决办法,对于支持南海维权工作具有重要意义。因此,本文选取《开罗宣言》相关的多模态南海维权证据和中华民国地图证据作为实验样本,基于本文提出的本体模型进行语义标注,最后以知识图谱的形式进行表示,从而验证多模态南海疆维权证据本体模型的实用性。
如图6所示,《开罗宣言》的证明主题是基于《开罗宣言》的南海维权,分别具有文本证据《开罗宣言》中英文抄本和图像证据《开罗宣言》签署照片,两者对于支持该证明主题均有一定证明效力。《开罗宣言》中英文抄本的证据编号为NO.003,于1943年12月1日在重庆、华盛顿、伦敦三地同时发表,其创作背景是“二战胜利,中美英三国首脑召开开罗会议”,文本创作时间是“1943年11月22日至26日”,文本内容包括“...使日本所窃取于中国之领土...归还中华民国...”,该文本被文献《论<开罗宣言>在当代国际法律秩序中的地位》引用。“《开罗宣言》签署照片”的证据编号为“NO.001”,图像内容为“中美英三国首脑召开开罗会议时的合照”,照片拍摄时间为“1943年11月25日”。针对《开罗宣言》中英文抄本,本文所考虑的南海维权证据证明力影响因素包括:证据倾向为“Positive”、证据来源类型为“条约”、证据主体为“中美英三方首脑”、主权行为类型为“收复失地”。针对《开罗宣言》签署照片,除文本证据具有的四个影响因素以外,该图像证据收录于《美国条约和其他国际协定汇编(1776-1949)》,其照片格式为“jpg”、分辨率为“300ppi”、图像大小为“6.1MB”同样作为证明力影响因素来考虑。

图6 基于《开罗宣言》进行南海维权的语义结构化表示
1948年中华民国地图同样能够为证明主题“基于《开罗宣言》的南海维权”提供支持,其证据编号为“NO.888”,其绘制时间和地图所指时间为“1948年”,地图绘制的主要区域为“二战后中华民国全境”。地图所包含的内容包括“南海九段线符号和国界线”,以及地图的创作背景为“二战胜利,中华民国收回战争失去的领土”,基于此,可知“1948年中华民国地图”呈现的是战后的中华民国全境,对于支持南海维权工作的有用性。针对“1948年中华民国地图”,本文所考虑的“南海地图证据证明力影响因素”包括:地图制作者的立场为“正向”;证据本身对于证明主题的倾向为“Positive”;地图来源类型为“单图”,来源主体为“亚光舆地学社”;地图的被承认度为“国际社会持中立态度”;地图被文献“《从地图看中国南海海域疆界线的形成与演进》”和文件“《中华民国年鉴》”引用;地图的技术参数(比例尺为“1:100,000,000”、图例“有”、分辨率为“96ppi”)。
通过分析基于《开罗宣言》的内容可知,一方面需要对证据模态进行识别,另一方面需要对证据的证明力进行判断,主要流程流程为四个步骤:首先,查询证据编号,找到该证据在知识库中所对应的标识;其次,分析证据所要证明的主题;然后,通过证据倾向和制作者立场等因素判断证据在证明力上的方向来确定支撑价值;接着,根据影响因素分析证据的证明力大小;最后,综合不同模态证据的证明效力,对“基于《开罗宣言》的南海维权”所涉及的多模态证据的证明效力进行综合判断。
根据以上分析可知,本文提出的多模态南海疆维权证据本体模型可以有效的规范的描述基于《开罗宣言》的南海维权内容,清晰地呈现证据要素和维权过程,说明了本体模型的表示能力与实际作用。
3 多模态南海疆维权证据本体模型的应用价值
多模态南海疆维权证据本体模型的构建具有重要的意义,既是南海疆知识图谱构建的基础,也是南海疆维权实践的重要支撑,更是南海疆人文叙事的重要依托。
第一,南海疆知识图谱构建的基础。多模态南海疆维权证据本体模型是多模态知识图谱构建后续研究的基础。基于对多模态证据进行了证据要素界定,可以实现南海疆维权证据的结构化语义表示。通过属性层、逻辑层、证明层的语义关系可以实现多层次证据关系的智能识别链接;通过多模态证据的标记方法,可以实现知识图谱的自动化构建。为后续针对维权证据链知识图谱的可视化、证据知识发现与推荐研究奠定基础。
第二,南海疆维权实践的重要支撑。面向南海疆维权的实际工作,本文所提出的多模态南海疆维权证据本体模型是重要的支撑。基于多模态南海疆证据本体模型,可以实现细粒度的证据实体抽取、多层次语义关系识别,对南海疆证据资料进行语义结构化表示,呈现清晰的证据知识组织体系,为南海疆维权证据链的智能化构建提供了重要的工具支撑,能够在国际外交舆论和司法维权场景下,通过提供多脉络、多形式的证据链有理有据地维护我国南海疆权益。
第三,南海疆人文叙事的重要依托。面向南海疆的人文叙事工作,多模态南海疆维权证据本体模型是其重要依托。南海疆人文叙事的宣教工作对历史资料的真实性和完整性,故事脉络的逻辑条理性有着严格的要求。多模态南海疆维权证据本体的应用,一方面有助于利用多模态南海资料,更生动形象,直观易懂地讲好中国南海故事;另一方面,有助于证据关系的挖掘和组织,实现从碎片史料到关联史料以及全景史料的探究,实现从单一脉络到多重脉络的史实还原与印证。
4 结 语
本文融合了文本型、图像型和地图型三种类型的证据,构建了多模态南海维权证据本体模型,为多模态证据实体的智能抽取表示和多层次证据关系的智能识别链接提供了模型基础。以开罗宣言为实例说明了多模态南海维权证据本体模型表示能力的有效性与实用性。融合本体模型、本体属性标记与关系关联,可以更好地挖掘和推理多模态南海证据之间的关系,增强证据的证明效力,讲好南海维权故事,服务南海维权实际工作。未来的研究中,我们将基于多模态南海维权证据本体,推进多模态南海维权证据链的构建,实现面向不同维权场景下的证据链条组织。
猜你喜欢
哲学分析(2023年4期)2023-12-21
小哥白尼(军事科学)(2021年6期)2021-11-02
少先队活动(2021年4期)2021-07-23
中国音乐学(2020年4期)2020-12-25
小哥白尼(军事科学)(2020年7期)2020-05-22
小哥白尼(军事科学)(2020年5期)2020-05-22
绿色中国(2019年19期)2019-11-26
杂文月刊(2017年19期)2017-11-11
知识经济·中国直销(2017年5期)2017-06-15
公民与法治(2016年24期)2016-05-17
