
基于改进YOLOv5的遥感图像目标检测
2024-04-23 10:03崔丽群曹华维
计算机工程 2024年4期
崔丽群,曹华维
(辽宁工程技术大学软件学院,辽宁 葫芦岛 125105)
0 引言
随着空间遥感技术的快速发展,获取的遥感图像的质量也越来越高。遥感图像通过高空拍摄获得,其中包含了丰富的地面信息,在低分辨率转向高分辨率的过程中,所提供的地面信息细节丰富,这使遥感图像在空中侦查、城市规划、自然灾害检测等领域的应用越来越广泛。因此,对遥感图像的研究及应用成为研究热点[1-2]。目前,学者们已提出了很多对自然场景下的图像进行目标检测的算法:一类是以YOLO[3]、YOLOv2[4]、YOLOv3[5]、YOLOv4[6]等算法为代表的单阶段目标检测算法,这类算法通过在特征图上直接预测目标的位置和类别,一次性完成目标检测任务,因此具有较快的检测速度,但在目标定位和边界框精度上相对较弱,检测精度偏低;另一类是两阶段目标检测算法,如快速的基于区域的卷积神经网络(Fast R-CNN)[7]、更快速的基于区域的卷积神经网络(Faster R-CNN)[8]等算法,两阶段算法相对于单阶段算法更加准确,对小目标检测效果更好,但是缺点是速度相对较慢。与自然场景下的图像相比,遥感图像在拍摄角度、物体分布、成像范围等方面具有独特的特点,例如:遥感图像多为高空取景,容易受到天气、光照等背景信息的干扰;在同一场景下,目标间尺度差异较大;目标排列具有任意性。这些都是影响遥感图像目标检测的难点。
学者们针对遥感图像的目标检测进行了相关研究。宋忠浩等[9]提出一种基于加权策略的遥感图像目标检测算法,该算法利用多尺度特征提高了对遥感图像的检测精度,但没有考虑遥感目标角度多样性的特点。LUO等[10]在原有批归一化模块的基础上,增加居中和缩放校准,从而增强YOLOv5算法的特征提取能力,提高对遥感图像中飞机目标检测的精度,但是在复杂的天气情况下难以实现精准的检测效果。WANG等[11]将浅层特征映射引入YOLOX的特征融合部分,提高了模型的检测精度,但也导致模型推理速度下降。王浩桐等[12]在单次多盒检测(SSD)算法的基础上针对飞机图像小尺度且密集的特点,重新设计了锚框尺度大小、比例,并且额外增加了一个包含两种尺度的特征层,但是研究类别相对单一,无法推广到多类别遥感图像的研究中。王道累等[13]针对遥感目标尺度的问题,使用改进的密集连接网络作为特征提取网络,以提升对中小目标的检测精度,但对大尺度目标的检测精度不高。DING等[14]提出了一种称为感兴趣区域(RoI)Transformer的架构,其贡献在于使用旋转位置敏感的RoI Align来提取区域的特征,用于遥感目标的定位和分类,可以有效地检测目标,但存在效率低下的问题。YANG等[15]提出一种用于旋转检测的算法,该算法将检测任务划为两个分支,主要用于生成目标的边界框回归信息,提高了小目标的检测精度,但在边界处会出现损失值暴增的问题。
学者们针对遥感图像数据集中目标尺度差异较大的问题进行了研究。LIN等[16]提出的特征金字塔网络(FPN)通过融合多尺度特征以提高多尺度目标检测性能。然而,FPN不能将低层的位置信息反馈到高层语义特征中,而且特征也只能在邻近层间相互传递,导致了特征融合的不平衡。LIU等[17]提出路径聚合网络(PANet),在FPN的基础上引入一条自底向上的路径增强结构,充分融合低层特征。TAN等[18]提出双向特征金字塔网络(BiFPN),引入上下文信息和基于PANet的权重信息来平衡不同尺度的特征,获取了更丰富的语义信息。然而,遥感图像不同目标间尺度差异过大,现有的特征融合方式难以满足实际检测需求。针对上述问题,本文基于YOLOv5提出一种遥感图像目标检测算法。设计联合注意力的多尺度特征增强网络,融入更多的低层特征并构建特征聚焦模块捕捉关键信息,使特征图包含丰富准确的语义信息和细节信息。利用感受野模块对融合后的特征图进行更新,减少特征信息损失。增加旋转角度,并使用圆形平滑标签优化边界回归,解决了遥感目标方向任意的问题。
1 改进的遥感图像目标检测算法
1.1 相关原理
YOLOv5目标检测算法主要由输入端、骨干网络、特征融合、预测层4个部分组成。首先,在输入端输入一个RGB图像,特征尺寸是640×640×3,其中,图像尺寸为640×640像素,通道数为3。同时,使用马赛克(Mosaic)等数据增强方法丰富图像、简化模型。骨干网络是CSPDarkNet53,旨在从图像中提取特征,主要由卷积块Conv、C3、快速空间金字塔池化(SPPF)等模块组成,其中,C3模块借鉴跨阶段局部网络[19]的思想,由卷积块和瓶颈结构Bottleneck组成,实现不同层次的特征融合。SPPF通过不同池化核的池化层进行特征提取。特征融合部分使用基于PANet的特征金字塔把融合后的特征传入预测层,分别以80×80像素、40×40像素、20×20像素为输出尺度,实现3种不同尺度目标的位置预测。
1.2 联合注意力的多尺度特征增强网络
特征融合旨在聚合骨干网络中不同阶段输出的多尺度特征,以增强输出特征的表达能力,提高模型的性能。
YOLOv5算法特征融合采用PANet结构,如图1所示(彩色效果见《计算机工程》官网HTML版,下同),将上采样后的高层特征与细节信息丰富的低层特征进行融合,使用高分辨的低层特征检测小尺度目标,低分辨率的高层特征检测大尺度目标。然而,YOLOv5算法结构只考虑同一层级的特征,高层信息和低层信息不能有效融合,并且遥感图像背景信息复杂,在YOLOv5算法的特征融合过程中,会受到噪声信息的干扰。
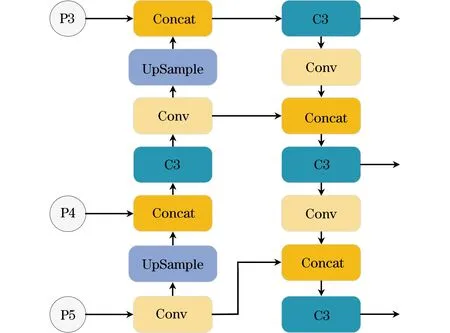
图1 YOLOv5算法特征融合网络Fig.1 Feature fusion network of YOLOv5 algorithm
针对以上问题,本文提出一种联合注意力的多尺度特征增强网络,如图2所示,该结构继承了PANet的自底向上和自顶向下的聚合路径,并增加了更多的低层特征,同时在融合过程中使用特征聚焦模块加强特征聚合,引导模型识别和选择更关键的特征信息。
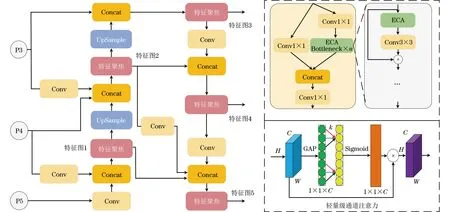
图2 联合注意力的多尺度特征增强网络Fig.2 Joint multiscale feature-enhanced network with attention
联合注意力的多尺度特征增强网络的流程为:1)将从骨干网络输出的P3、P4、P5这3种尺度的特征图输入特征融合部分,由于3种尺度的特征图尺寸是不同的,为了便于特征融合,首先使用1×1卷积调整P5特征图的通道数,并使用3×3卷积提取P4特征图中的目标信息,将两次变换后的特征图进行拼接,通过特征聚焦模块生成特征图1;2)特征图1进行2倍上采样(UpSample)后,和P4特征图、经过3×3卷积处理的P3特征图拼接,通过特征聚焦模块生成特征图2;3)特征图2再进行一次上采样操作与P3特征图拼接,通过特征聚焦模块生成特征图3,用于检测小目标;4)将特征图3和特征图2拼接并通过特征聚焦模块处理,生成特征图4,用于检测中等目标;5)特征图4经过同样的操作与特征图1、2进行拼接,通过特征聚焦模块生成特征图5,用于检测大目标。
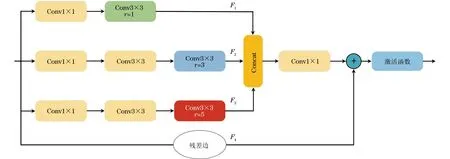
图3 感受野模块结构Fig.3 Structure of receptive field block
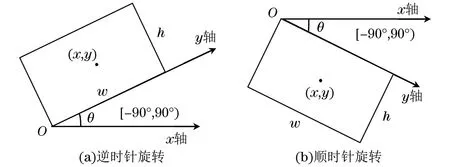
图4 引入旋转角度的检测框Fig.4 Detection box with introduced rotation angle

图5 圆形平滑标签Fig.5 Circular smooth label
在图2中的特征聚焦模块是由1×1卷积、3×3卷积和轻量级通道注意力(ECA)[20]按照残差连接的方式设计的增强模块,旨在获取通道信息以增强网络的特征表达能力,抑制遥感图像中的背景信息。1×1卷积对特征图进行降维操作,ECA机制则采用局部跨通道交互对特征进行组合以增强特征表达,使用全局平均池化(GAP)得到每一个通道的权重值,之后使用包含k个参数的一维卷积捕获局部跨通道的交互信息,并通过激活函数Sigmoid对权重值进行归一化处理,使模型捕捉到关键的通道特征。3×3卷积的目的是从低层特征中二次提取有用的细节特征,经过该模块的处理,模型可以获得包含准确的语义信息和细节位置信息的特征图,提高目标任务的准确性。
1.3 感受野模块(RFB)
随着网络结构的加深,遥感图像中的目标在经过多次卷积操作后可能会丢失大量的关键特征信息,导致目标在高级特征图中难以被检测和识别。使用感受野模块对融合后的特征图进行更新,扩大特征图感受野,减少特征信息的损失[21]。
RFB由多分支卷积层和空洞卷积层组成。多分支卷积层采用不同大小的卷积核,模拟不同尺寸的感受野,从而捕捉不同尺度下的图像特征。空洞卷积层使用不同空洞率(r)的空洞卷积获取多尺度上下文信息,在不增加额外参数的情况下获得不同尺寸的感受野,从而更有效地利用特征信息。
感受野模块结构如图3所示,该结构包括4条支路,F1、F2、F3由1×1卷积、3×3卷积、不同空洞率的3×3空洞卷积组成,F4表示残差连接,旨在保留更多的原始特征信息。计算过程如下:

(1)
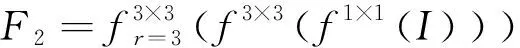
(2)
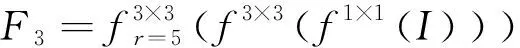
(3)
O=σ(f1×1(Concat(F1,F2,F3))+F4)
(4)
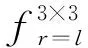
1.4 旋转角度增加和边界回归改进
在遥感图像中,目标密集分布且方向各异,使用水平检测框检测遥感图像会带来很多无用的信息,使定位不准确。对目标增加旋转角度,实现对任意方向下目标的准确定位,检测框格式定义为[x,y,w,h,θ],其中,(x,y)表示检测框的中心点坐标,w和h分别表示检测框的宽和高,θ表示目标的旋转角度。增加旋转角度后的检测框如图4所示。
然而,在遥感图像中,长宽比较大的目标对于旋转角度的变化非常敏感,在周期变化的边界处会出现损失值突增的情况,增加网络学习难度,影响检测精度。因此,通过圆形平滑标签[22]方法,采用分类的形式将角度分为固定的类别,如图5所示,对角度进行离散化处理,将1°分为1类,共180类,这使得-90°和89°这2个度数相邻,避免角度周期性问题。窗口函数能计算预测标签和真实标签之间的角度距离,在有限范围内越靠近真实值,损失越小。
圆形平滑标签的表达式如式(5)和式(6)所示:
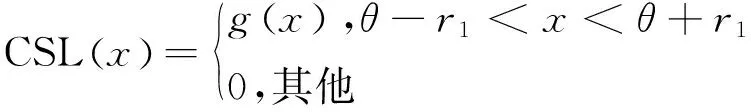
(5)
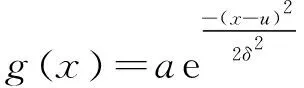
(6)
其中:g(x)为高斯窗口函数;r1是窗口函数半径;a、u、δ均为常数项。
1.5 所提算法网络结构
所提算法网络结构如图6所示。将图像输入骨干网络,经过Conv和C3等模块的处理,得到P3、P4和P5 3种尺度的特征图,将3种特征输入特征融合部分进行高低层信息交换,并利用特征聚焦模块捕捉关键通道特征。使用RFB扩大特征图3、4、5的感受野,减少特征信息的丢失。最终在预测层中输出小、中、大3种尺度的目标。
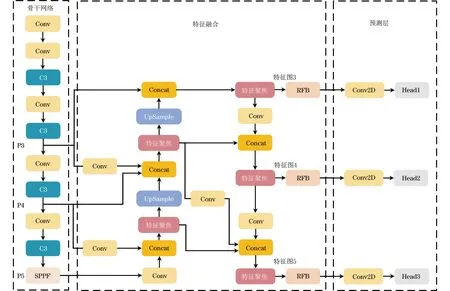
图6 所提算法网络结构Fig.6 Network structure of the proposed algorithm
2 实验结果与分析
2.1 数据集和实验环境
使用公开的用于航拍图像目标检测的大规模数据集(DOTA)[23]。该数据集包含2 806张高分辨率图片和188 282个实例,涵盖15个不同的类别,包括小型车辆(SV)、大型车辆(LV)、飞机(PL)、储油罐(ST)、轮船(SH)、港口(HA)、操场跑道(GTF)、足球场(SBF)、网球场(TC)、游泳池(SP)、棒球场(BD)、环路(RA)、篮球场(BC)、桥梁(BR)和直升机(HC),图片分辨率为800×800像素到4 000×4 000像素。由于数据集尺寸较大,难以直接输入网络进行训练,因此采用图像切割的方式对数据集进行预处理。将原始图像按照间隔为200像素、子图像尺寸为1 024像素的方式进行裁剪,得到多个分辨率为1 024×1 024像素的子图像,共分割得到21 046张图片。随机划分15 749张图片作为训练集,5 297张图片作为测试集。
实验使用的操作系统是Windows 10,GPU是NVIDIA GeForce RTX 3080,深度学习框架为PyTorch 1.9.0,设置300个epoch,初始学习率为0.01,在初始训练前进行3个epoch的Warm-up训练,动量因子和权重衰减分别是0.937和0.000 5。
2.2 评价指标
使用平均精度均值(mAP)作为模型评价指标,通过计算多个类别的平均精度(AP)可以得到mAP。每个类别根据准确率(P)和召回率(R)绘制一条P-R曲线,通过计算曲线下的面积获得该类的AP值,具体计算如式(7)~式(10)所示。mAP@0.5代表检测结果与真实标注框的交并比(IoU)为0.5时的平均精度均值,mAP@0.5∶ 0.95代表检测结果与真实标注框的IoU为0.5~0.95(步长为0.05)时的平均精度均值。
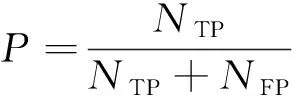
(7)
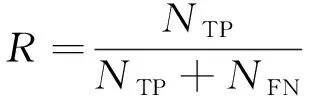
(8)

(9)
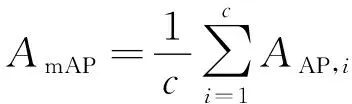
(10)
其中:NTP代表IoU大于等于设定阈值的检测框数目,即被正确检测的目标数量;NFP表示被错误检测的目标数量;NFN表示未被检测出的目标数量;P表示被检出目标中真实样本所占的比例,反映检出结果的准确性;R为召回率,表示所有真实目标中被正确检测的样本比例。
2.3 消融实验
2.3.1 特征融合消融实验
研究不同特征融合结构对模型性能的影响,包括PANet(基准网络)、BiFPN和本文设计的联合注意力的多尺度特征增强网络。由表1可以看出(其中最优指标值用加粗字体标示),PANet的mAP@0.5和mAP@0.5∶ 0.95最低,联合注意力的多尺度特征增强网络结构性能最好。

表1 不同特征融合结构对比Table 1 Comparison of different feature fusion structures %
2.3.2 窗口函数半径消融实验
所提算法使用高斯窗口函数,其中窗口函数半径r的不同会直接影响检测性能。当窗口函数半径设置过小,高斯窗口函数变成脉冲函数,无法学习到角度信息;当窗口函数半径设置过大,角度预测偏差会变大。共设置4组不同半径的消融实验,选取半径为0、2、4、6进行实验。实验结果如表2所示,当窗口函数半径设置为2,模型的检测精度达到最高。

表2 窗口函数半径的消融实验Table 2 Ablation experiment of window function radius
2.3.3 模块消融实验
为了检验所提算法的有效性,在DOTA数据集上进行模块消融实验,验证联合注意力的多尺度特征增强网络、圆形平滑标签和感受野模块对算法性能的影响。设置5组消融实验,实验结果如表3所示,其中,“√”表示模型使用该模块,“×”表示模型未使用该模块。

表3 所提算法在DOTA数据集上的消融实验Table 3 Ablation experiment of proposed algorithm on the DOTA dataset %
由表3可以得知:第1组实验为YOLOv5算法,将其作为基准模型与后续实验进行对比,mAP@0.5为70.7%,mAP@0.5∶ 0.95为46.1%;第2组实验仅使用联合注意力的多尺度特征增强网络,mAP@0.5提升了2.3个百分点,mAP@0.5∶ 0.95提升了1.0个百分点,可见该结构通过融入更多低层特征,并且利用特征聚焦模块模型捕捉关键信息,有效提升了检测精度;第3组实验是对目标增加旋转角度后使用圆形平滑标签优化边界回归,使模型对目标定位更准确,mAP@0.5提升了4.4个百分点,mAP@0.5∶ 0.95提升了0.3个百分点;第4组实验同时引入圆形平滑标签和联合注意力的多尺度特征增强网络,mAP@0.5提升了6.1个百分点,mAP@0.5∶ 0.95提升了1.1个百分点;第5组实验在第4组实验的基础上再引入感受野模块,将算法的mAP@0.5提升至78.0%,mAP@0.5∶ 0.95提升至49.4%。由数据分析可知,所提算法可以有效提高对遥感图像的检测精度,并且每个模块都在遥感图像目标检测算法中起着重要的作用。
2.4 对比实验
为了对所提算法进行评估,将原YOLOv5算法和所提算法在DOTA数据集上进行训练,训练结果分别如表4所示。由表4可以看出:所提算法的mAP@0.5值从70.7%提高到78.0%,整体精度提升了7.3个百分点;对于密集排列目标,所提算法与YOLOv5算法相比精度有较大提升,小型车辆AP值从51.8%提高到82.8%,提升了31.0个百分点,大型车辆AP值从84.5%提高到89.5%,提升了5.0个百分点,轮船AP值从89.8%提高到96.0%,提升了6.2个百分点;对于操场跑道、足球场、棒球场等大尺度目标,所提算法精度与YOLOv5算法相比也有一定程度的提高。这说明所提算法对不同尺度下的遥感目标均有较强的适用性,验证了所提算法的有效性。

表4 YOLOv5和所提算法训练结果Table 4 Training results of YOLOv5 and the proposed algorithm %
此外,将所提算法分别与YOLOv3[5]、RoI Transfomer[14]、面向细小、杂乱和旋转的物体稳健检测(SCRDet)[15]、用于检测任意方位场景文本的旋转区域CNN(R2CNN)[24]、YOLOv7-tiny[25]和掩码定向包围盒(Mask OBB)[26]等主流算法进行对比,实验结果如表5所示。由表5可以看出,基于Faster R-CNN提出的R2CNN算法的mAP@0.5值为60.6%,算法需要使用区域选取网络(RPN)生成大量水平框,水平框间大量重叠的问题导致该算法对多类别的遥感图像整体检测精度不高;YOLOv3的mAP@0.5值达到64.6%,对大目标类别检测精度较高,但受到锚框重叠问题的影响,整体检测精度不高;RoI Transfomer的mAP@0.5值为68.1%,相比前两种算法的mAP@0.5值有较大提高,但该算法存在效率低下和空间信息丢失的问题;YOLOv7-tiny的mAP@0.5值为71.5%,作为先进的单阶段检测算法速度较快,但整体检测精度明显低于所提算法;SCRDet针对杂乱小目标效果较好,mAP@0.5值为72.6%,检测精度较高,但是存在边界突变问题;Mask OBB的mAP@0.5值是75.3%,但对密集目标检测精度不够。从实验结果来看,所提算法在所有算法中检测精度为最高,并且对飞机、桥梁、小型车辆、大型车辆、轮船等密集目标的检测精度提升显著,进一步说明了所提算法对遥感图像的检测有效性。
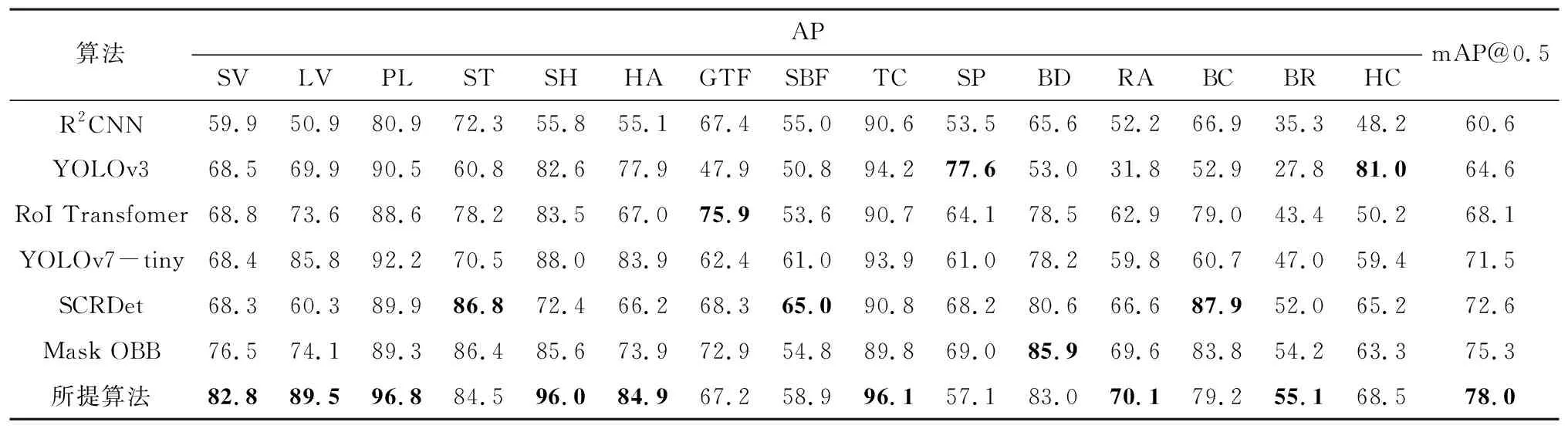
表5 不同算法在DOTA数据集上的对比实验Table 5 Comparison experiments of different algorithms on the DOTA dataset %
在DOTA数据集上对所提算法进行测试,并把测试结果进行可视化展示,如图7所示。根据检测效果对比可以看出:YOLOv5算法忽略了遥感目标存在方向性的问题,在采用水平检测框检测目标时出现检测框重叠的情况;所提算法对目标引入旋转角度,使用圆形平滑标签优化边界回归,检测框与待检测目标更加贴合。同时,在背景复杂且尺度差异大的场景下,YOLOv5算法存在一定的漏检、误检情况,如在图7(a)的第2张图片中没有检测出左上角的游泳池和左下角的小型车辆、又将图7(a)的第3张图片中地面目标错误的识别成港口。在同样的检测条件下,所提算法通过使用联合注意力的多尺度特征增强网络及引入感受野模块,帮助模型提取关键信息,有效识别出上述目标,并显著地提高了对遥感目标的检测精度。上述分析均表明了所提算法在遥感检测中的有效性。

图7 YOLOv5与所提算法检测效果可视化对比Fig.7 Visual comparison of detection effect between YOLOv5 and the proposed algorithm
3 结束语
本文对目前遥感图像存在的问题进行分析,针对背景复杂、目标间尺度差异大、目标方向任意等特点导致检测精度低下的问题,提出一种基于改进YOLOv5的遥感图像目标检测算法。在特征融合部分提出一种联合注意力的多尺度特征增强网络,融入更多的低层特征以丰富特征图细节信息。在融合过程中构建特征聚焦模块,帮助模型获得关键通道特征。利用感受野模块更新融合后的特征图,减少特征信息的损失。最后,引入旋转角度,并利用圆形平滑标签对角度离散化,把回归问题转化成分类问题,实现对任意目标的精准定位。在DOTA数据集上的实验结果表明,所提算法较YOLOv5算法检测精度有明显提升,对遥感图像具有良好的检测效果。虽然所提算法在检测精度上有较大的提升,但也增加了大量模型参数,推理速度有所下降,在未来工作中将对算法模型进行轻量化处理,兼顾推理速度和检测精度,以达到更好的实际应用效果。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年11期)2019-07-04
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
太空探索(2016年5期)2016-07-12
测绘科学与工程(2016年5期)2016-04-17
电子设计工程(2015年3期)2015-02-27
时代英语·高三(2014年5期)2014-08-26
电视技术(2014年19期)2014-03-11
