
基于YOLO-Pose的城市街景小目标行人姿态估计算法
2024-04-23 10:03马明旭马宏宋华伟
计算机工程 2024年4期
马明旭,马宏,宋华伟
(1.郑州大学网络空间安全学院,河南 郑州 450000;2.战略支援部队信息工程大学信息技术研究所,河南 郑州 450000)
0 引言
随着计算机视觉各个分支领域的不断发展,深度学习、卷积神经网络等技术的不断成熟,业界提出了人体姿态估计这一研究方向。姿态估计相比于传统的目标检测,能够在检测的过程中提供更多维度、更深层次的人体特征信息,可以实时掌握人体二维空间的姿态和位置变换,为计算机视觉的应用和人体行为解读等诸多方向提供了巨大的可拓展性。在城市街道场景中,如十字路口工厂园区、养老院、医院、体育场等公共区域,经常会发生一些异常行为(如摔倒、打架斗殴、溺水、区域入侵等),带来的影响可能非常严重,因此在发生异常行为初期,通过监控采集和算法分析,由相关单位提供及时的响应和援助是至关重要的。通过对人体姿态估计的研究,以及充分地理解单个人或人群在视频中的交互信息,开发设计一个能够满足工业应用部署的行人姿态估计算法,对于公共安全、医疗监护、安防、虚拟现实等领域都有着巨大的应用价值。
人体姿态估计作为计算机视觉中备受关注的重要任务之一,也是人类利用计算机理解人体动作、行为信息的重要一环,近年来逐渐成为了国内外学术界和工业应用的热门研究方向。传统的多人姿态估计根据方法的不同,分为自底向上和自顶向下两大类[1-2]。自顶向下[3-5]的方式首先通过检测算法获得人形轮廓,然后检测出轮廓内的关键点,进而连接所有关键点获取人体姿态,这种方式较为直观,易于理解,骨骼信息提取的精度较高。文献[6]提出的DeepPose最早将卷积神经网络(CNN)应用于人体关节点检测,将人体姿态估计转换为关节点回归问题,并提出了将CNN应用于人体关节点回归的方法,将整幅图像输入到7层CNN来做关节点回归,更进一步,使用级联的CNN检测器来增加关节点定位的精确度。AlphaPose[7]是由上海交通大学研究团队提出的一种新的区域多人姿态估计(RMPE)框架,能够实现在人体候选框不准确的情况下进行姿态估计。自底向上[8-10]的方法需要先检测出一幅图像内的所有人体部位,然后通过聚类等方法将所有关键点进行连接并分组,拼接成每个人的骨架,这种方法的最大特点是只需对图片进行一次检测,并且检测速度不受图像内人数的影响。文献[11]提出的OpenPose通过部分亲和场(PAFs)的非参数表示,首次提出了关联分数,用学习的方法将身体部位与图像中的个体关联起来。文献[9]提出的Higher HRNet通过提高输出分辨率大幅提升了预测精度。文献[12]提出了一种基于流行的YOLOv5[13]目标检测框架的二维多人姿态估计算法YOLO-Pose,该算法使用了一种新型的无热力图联合检测方法,能够实现端到端的训练并且优化目标关键点相似度(OKS)指标,该方法不需要对自底向上的方法进行后处理,而是通过将检测到的关键点分组到一个框架中,每个包围框都包含一个相关联的姿态,从而实现关键点的固有分组。除了传统的二维姿态估计[2]外,三维姿态估计[14]和视频流场景下连续的姿态估计也是近期的热门研究方向。文献[15]提出了一种双向交换二维和三维信息的框架,利用单目相机采集到的视频信息,该框架能够估计出高精度的三维人体姿态。文献[16]采用三阶段多特征网络生成初始姿态关节点数据,通过自底向上的树形结构学习身体部位之间的空间特征,并将相邻3帧图像进行融合来保证视频估计前后的一致性。
虽然上述算法在某些场景下取得了不错的表现,但是在实际的城市街景中,在待检测行人目标有效面积较小的条件下,检测精度会受到严重影响,同时会出现较高的漏检率,且部分算法效率低,无法满足工业应用的实时性要求。导致小目标行人检测困难的主要原因有2个:1)小目标标注区域的面积占比少;2)训练数据集中小目标的实例少。针对问题1),可通过进一步提升神经网络模型对小目标区域的感兴趣程度、加强各层级网络所提取到的有用特征信息的有效融合、优化锚框(anchor)的聚类手段等方法解决;针对问题2),则需要丰富数据集中标注目标尺度的多样性,在数据层面就聚焦解决小目标行人检测难的问题。
近年来,基于深度学习的计算机视觉技术不断进步,针对小目标行人检测问题的优化方法层出不穷[17-18]。文献[17]提出的TPH-YOLOv5将即插即用的注意力模块(CBAM)集成到YOLOv5模型中,帮助网络在大区域覆盖的图像中找到感兴趣的区域,同时增加一个更小尺度的检测头来预测更小的物体,该文证实了CBAM模块能够注意到更有价值的目标区域,提升了对小目标物体的预测精度。文献[19]提出了一种高效的加权双向特征金字塔网络(BiFPN),通过在同一水平的节点之间增加一条额外的通道,在不增加太多计算成本的情况下融合更多尺度的特征信息,该方法改进了路径聚合PANet[20]网络结构,丰富了特征融合的来源。文献[21]提出的SIoU Loss[21]考虑到预测框与真实框之间的向量角度信息,重新定义了惩罚指标,证明了SIoU损失函数能够提高神经网络的训练速度和准确性。文献[22]通过使用k-means++[23]算法重新聚类锚框,避免聚类中心过近所导致的局部最优解问题,提升了目标检测算法的预测精度,加快了模型的收敛。
针对YOLO-Pose算法在城市街景中对小目标行人的预测效果不佳的问题,本文提出一种基于YOLO-Pose算法改进的小目标行人姿态估计算法YOLO-Pose-CBAM。
1 基于YOLO-Pose的小目标行人姿态估计
1.1 YOLO-Pose姿态估计算法原理
YOLO-Pose[12]基于当前流行的YOLOv5[13]目标检测算法,使用CSP-darknet53网络[24]作为特征提取骨干网络(Backbone),使用PANet[20]网络融合多尺度特征作为颈部结构(Neck),最后使用4个不同尺度的解耦头用于预测候选框和关键点。YOLO-Pose的网络模型结构如图1所示(彩色效果见《计算机工程》官网HTML版,下同)。
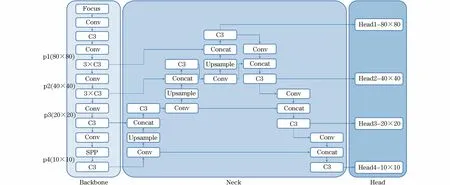
图1 YOLO-Pose网络结构Fig.1 YOLO-Pose network structure
输入的图像通过CSP-darknet53骨干网络产生4种不同尺度的特征图:p1(80×80),p2(40×40),p3(20×20),p4(10×10),相比于原始的YOLOv5目标检测算法多添加了一个尺寸的特征图,通过在更多尺度上采集特征信息,能够实现更好的检测效果。使用PANet网络来融合不同尺度的特征图,将PANet的输出作为4个尺度检测头的输入,传到每个检测头中的box候选框检测器和关键点检测器中。最终使用CIoU[25]损失作为边界框的监督,将IoU的损失概念从边界框扩展到关键点,使用OKS作为关键点的IoU,针对特定部位的关键点倾斜重要性,比如耳朵、鼻子、眼睛会比肩膀、膝盖、臀部等在像素级别上受到更多的错误惩罚。总损失函数公式如下:
λkptsLkpts+λkpts_confLkpts_conf)
(1)
为了平衡不同规模之间的损失,超参数的值设置为:λcls=0.5,λbox=0.05,λkpts=0.1,λkpts_conf=0.5。
对于每个边界框,存储对应的一套姿态信息,针对每一个单独的关键点计算OKS指标,并累加到最终的OKS损失,公式如下:
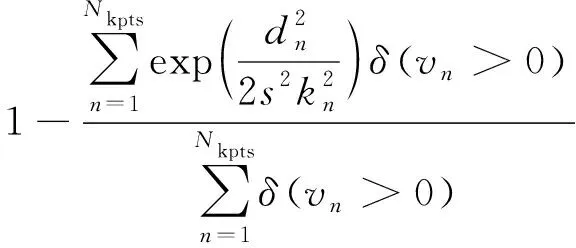
(2)
其中:OOKS表示OKS指标;dn代表第n个关键点预测和真实坐标的欧氏距离;kn代表关键点的特定权重;s代表目标的比例;δ(vn>0)代表每个关键点的可见性标识。
针对每个关键点学习一个置信度参数,它表示该关键点对于目标人体是否存在,关键点置信度的损失公式为:
Lkpts_conf(s,i,j,k)=
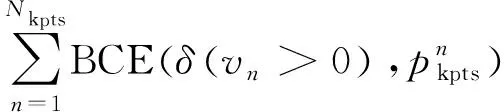
(3)
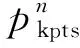
YOLOv5目标检测算法主要着眼于COCO数据集[26]在目标检测上的挑战,其每个候选框预测85种元素,包含80个类别的目标分数、边界框的4个位置坐标和置信度分数。对于YOLO-Pose算法而言,检测到的一个人的anchor会存储整个二维姿态信息和边界框信息,而它需要检测的只有人体这一种类别。COCO keypoints人体关键点数据集中每个人体信息使用17个关节点表示,并且每个关节点使用坐标和置信度{x,y, conf}确定,也就是对于每个检测到人的anchor,关键点头预测3×17=51个元素,候选框头预测6个元素{Cx,Cy,W,H,Bconf,Sconf},其中,Bconf、Sconf表示为候选框和类别的置信度。因此,对于YOLO-Pose预测到的每个anchor,所有需要的元素可以表达为一个向量,即:

(4)
与自上而下的方法相比,YOLO-Pose对于关键点没有限制约束其必须在检测的边界框内,因此,如果关键点被遮挡或位于边界框外,也仍然能被正确识别[13]。但笔者在实际测试中发现,YOLO-Pose算法对城市街景中较小的行人目标不够敏感,经常出现漏检情况。针对该问题,本文对YOLO-Pose算法模型进行了改进。
1.2 改进的YOLO-Pose-CBAM算法
如图2所示,本文算法主要有以下技术创新点:1)在YOLO-Pose算法的特征提取网络中加入CBAM注意力机制[27],构建了一个全新的特征提取网络,从通道和空间2个维度提取更有效的特征信息,增加对小目标特征信息的关注度;2)构建跨层级联特征融合通道[28],加强浅层特征与深层特征之间的信息交流,进一步丰富人体姿态估计特征融合的尺度和来源,缓解漏检和误检问题;3)引入SIoU[21]代替CIoU[25],使用真实框与预测框之间的向量角度重新定义损失函数,加速收敛并提升预测的准确度;4)使用k-means++[23]算法代替k-means算法,规避初始聚类中心过近的问题。
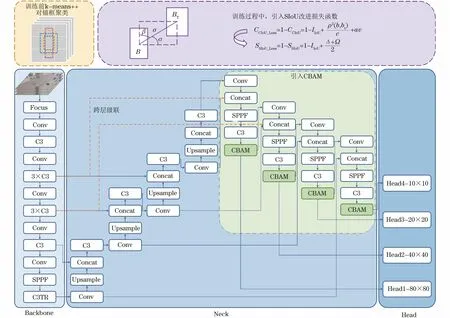
图2 改进的YOLO-Pose-CBAM网络结构Fig.2 Improved YOLO-Pose-CBAM network structure
1.2.1 CBAM轻量化注意力模块的引入
为了解决YOLO-Pose在城市街景中对小目标行人不敏感的问题,本文提出改进的YOLO-Pose-CBAM算法,提升了算法模型对小目标行人的敏感度,同时增强了姿态估计的稳定性和可靠性。
文献[27]提出了一种轻量化的CBAM注意力模块,它可以同时在通道和空间2种维度上进行Attention操作,能赋予网络更大的感受野,使网络更关注识别的物体。同时其轻量化的设计,能够忽略开销无缝集成到YOLO-Pose的架构中。本文将CBAM注意力模块放到每个检测头的前一层,使其从空间和通道2个维度进行注意力特征融合。
CBAM注意力机制包含了通道注意力模块(CAM)和空间注意力模块(SAM),如图3~图5所示,给定的中间特征图的信息沿着通道和空间2个单独的维度依次生成注意力映射。
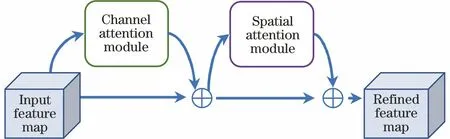
图3 CBAM注意力机制Fig.3 CBAM attention mechanism
如图4所示,通道注意力模块将维数为C×H×W的中间层特征图作为输入,使用AvgPool和MaxPool对特征图进行空间维度压缩后生产2个通道注意力向量,分别用Favg,c、Fmax,c来表示。随后将Favg,c、Fmax,c输入一个由3层全连接网络组成的共享多层感知器W0,并生成2个维数为C×1×1的注意力向量,最终将2个注意力向量相加,通过Sigmoid函数融合为一个维度C×1×1的通道注意力向量Mc,如式(5)所示:
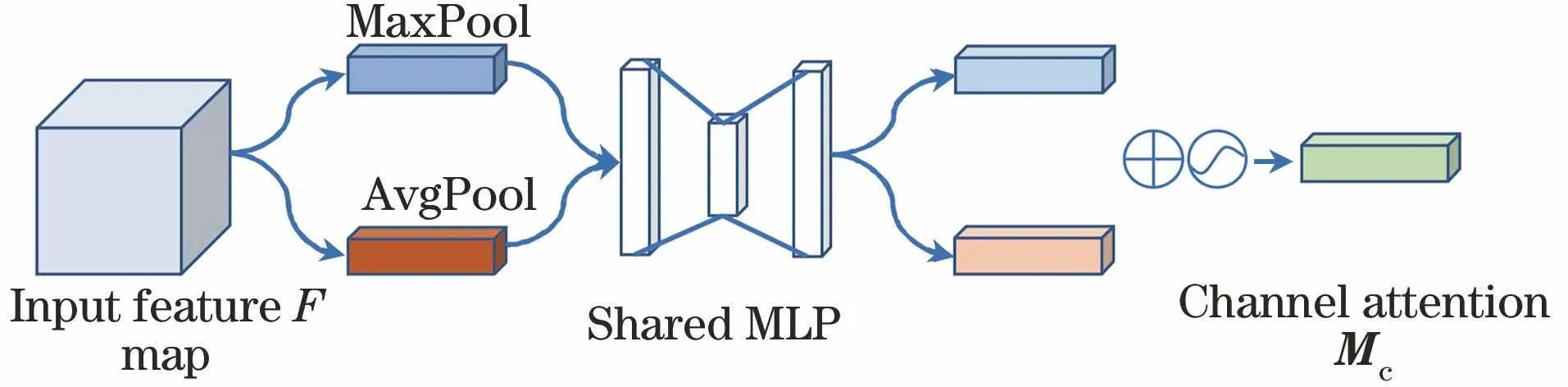
图4 通道注意力模块Fig.4 Channel attention module
Mc(F)=
σ(MLP(AvgPool(F))+MLP(MaxPool(F)))=
σ(W1(W0(Favg,c))+W1(W0(Fmax,c)))
(5)
如图5所示,空间注意力模块将CAM输出的结果进行MaxPool和AvgPool操作,随后将得到的2个1×H×W特征图进行Concat拼接操作,通过7×7卷积将其变为1×H×W的特征图,经过Sigmoid激活函数得到SAM的输出结果。最终将空间注意力模块的输出结果乘上原特征图变回C×H×W大小,即为CBAM整体的输出结果,如式(6)所示:

图5 空间注意力模块Fig.5 Spatial attention module
Ms(F)=
σ(f7×7([AvgPool(F);MaxPool(F)]))=
σ(f7×7([Favg,s;Fmax,s]))
(6)
本文的实验在引入CBAM注意力机制的同时,将YOLO-Pose网络中的空间金字塔池化(SPP)结构替换为快速SPP(SPPF)结构,网络模型整体训练速度相较于SPP提升7.67%。将CBAM模块集成到YOLO-Pose的每一个检测头前,使模型的性能得到了较大的提升,对小目标行人姿态估计的增强尤为明显。
1.2.2 跨层级联的特征融合
在单阶段的目标检测器[1]中,骨干网络主要负责提取数据中更复杂的纹理特征,而颈部网络放在骨干网络之后,可以更好地利用提取到的特征信息,提升特征的多样性和鲁棒性。YOLO-Pose采用的PANet[20]结构引入了自底向上的路径,虽然在颈部提取到了较为复杂的特征信息,但忽略了行人目标浅层特征较为明显这一特性。因此,为进一步加强算法对小目标行人的特征提取能力,防止有效信息在传递过程中丢失,增强网络对小目标行人的回归能力,本文对YOLO-Pose的网络结构进行改进。
如图6所示,本文在骨干网络和颈部之间增加2条跨层的级联通道[4]。第1条级联通道将骨干网络中8倍下采样的特征图A1∈C×H×W(C、H、W分别代表通道数、高度和宽度)、颈部上采样特征图B1∈(C/2)×H×W、颈部下采样特征图C1∈(C/2)×H×W通过Concat拼接操作融合为特征图M1∈(2×C)×H×W,第2条级联通道同理。

图6 跨层级联的特征融合结构Fig.6 Cross layer cascading feature fusion structure
不同通道数的特征图融合公式如下:
Mi=Concat(Bi,Ci,Ai)
(7)
通过将浅层网络中提取到的原始行人轮廓特征与深层网络中提炼的轮廓特征进行跨层级联融合,加强了浅层特征与深层特征之间的信息交流,使网络可以有选择性地提取特征信息,改善了原网络中融合特征来源单一导致的漏检、误检等问题,提升了预测精度。
1.2.3 SIoU改进损失函数的引入
在YOLO-Pose中,损失函数中使用CIoU[25]作为边界框的监督指标。CIoU Loss公式如下:

(8)
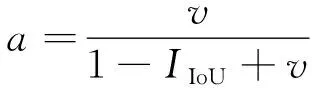
(9)

(10)
其中:CCIoU表示CIoU;IIoU表示IoU;(b,bt)分别表示预测框和真实框的中心点;ρ2(b,bt)表示预测框与真实框中心点的欧氏距离;c表示预测框与真实框的最小外接矩形对角线长度;a是权重函数;v用于衡量预测框与真实框的长宽一致性。
在本文算法中,引入了最新的SIoU Loss[21]重新定义了边界框回归的定位损失函数。SIoU相较于CIoU,进一步考虑了真实框和预测框之间的向量角度,具体包含4个部分:角度损失,距离损失,形状损失,IoU损失。SIoU Loss回归损失函数公式如下:
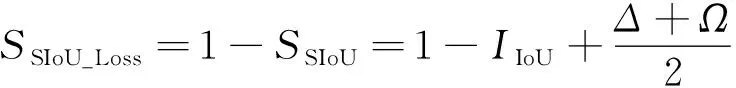
(11)
其中:SSIoU表示SIoU。
1)角度损失公式如下:
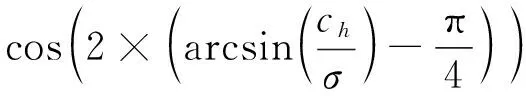
(12)

(13)
ch=max(bcy,t,bcy)-min(bcy,t,bcy)
(14)
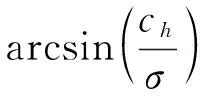
2)距离损失公式如下:
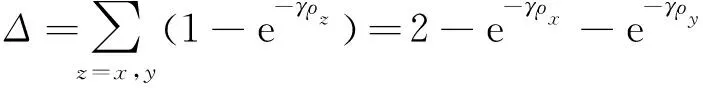
(15)
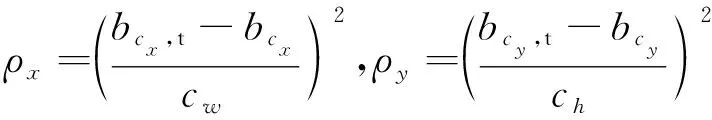
(16)
γ=2-Λ
(17)
其中:(cw,ch)为预测框与真实框最小外接矩阵的宽和高。
3)形状损失公式如下:

(18)
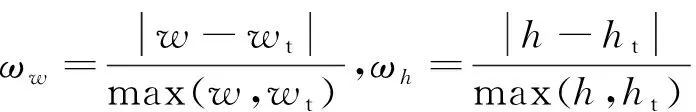
(19)
其中:(w,h)和(wt,ht)分别为预测框和真实框的宽和高;θ负责控制对形状损失的关注程度,避免过于关注形状损失而减少了对预测框的移动。
4)IoU损失公式如下:
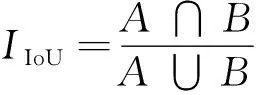
(20)
综上,引入SIoU后的边界框定位损失函数定义为:
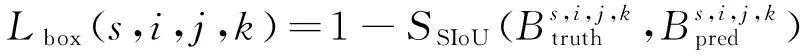
(21)

1.2.4 k-means++改进锚框聚类
k-means算法是一种广泛使用的聚类算法,在YOLO系列算法中默认使用k-means算法聚类COCO数据集标注的锚框,并且采用遗传算法在训练的过程中调整锚框[29]。但k-means算法在正式聚类之前要先初始化k个聚类中心点,k-means存在的巨大缺陷就是收敛情况严重依赖于聚类中心的初始化情况,如果初始点选择不当会导致精度和效果不佳。
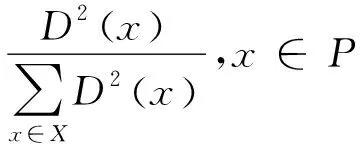
2 实验
在开展本文算法模型实验时,首先进行数据集的构建,其次对YOLO-Pose算法进行网络结构的优化和参数的调优,最后对比其他姿态估计算法,验证本文算法在城市街道等场景监控视频下的有效性和先进性。
2.1 实验数据集
COCO keypoints数据集[26]是一个可以用于同时检测目标并定位其关键点的大规模数据集。COCO keypoints将人体关键点的定义为17个关节点,分别为nose、left_eye、right_eye、left_ear、right_ear、left_shoulder、right_shoulder、left_elbow、right_elbow、left_wrist、right_wirst、left_hip、right_hip、left_knee、right_knee、left_ankle、right_ankle。在城市街景环境中,监控摄像头中的行人目标的待检测区域往往比较小,且可能出现拥挤的情况,这些场景在MS COCO数据集上有67.01%的图片没有重叠的人群[30],因此,有必要引入符合应用场景的数据集作为评判标准。WiderPerson数据集[31]是户外行人检测基准数据集,图像选自广泛的场景,不再局限于单一场景,其多样化、密集型、室外的特点非常符合小目标行人姿态估计的应用场景。
本文着眼于改进YOLO-Pose算法在城市街道等场景中检测小目标行人姿态的性能,为了验证算法在小目标行人姿态估计方面的先进性,本文通过数据采集以及使用标注软件对WiderPerson目标检测数据进行人体关键点标注,得到高质量的小目标人群数据集WiderKeypoints。本文实验训练和验证数据集均为WiderKeypoints,数据集概况如表1所示,其中,训练集、验证集、测试集的比例为8∶1∶1。

表1 实验数据集概况Table 1 Overview of experimental datasets 单位:个
2.2 评价指标
在目标检测任务中,常见的评价指标有精度、召回率和平均精度均值(mAP)。精度表示预测中正确的目标占全部预测目标的比例,召回率表示所有已标注目标中模型预测正确的比例,也称为查全率。这2个指标的计算方式如下:
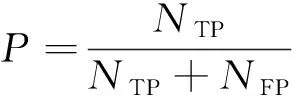
(22)
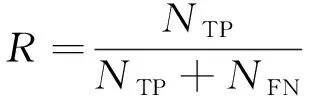
(23)
其中:P表示精度;R表示召回率;NTP表示被正确划分为正例的个数,即实际为正例且被分类器划分为正例的实例数;NFP表示被错误划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;NFN表示被错误划分为负例的个数,即实际为正例但被分类器划分为负例的实例数。
平均精度均值是P和R这对变量的融合指标,表示网络模型预测的识别精度,是所有类别平均精度(AP)的均值,如下所示:

(24)
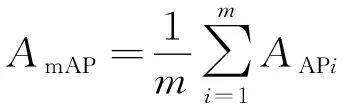
(25)
其中:AAP表示AP;AmAP表示mAP;m代表类别的个数,在本文中为1(person),此时mAP等价于AP。
参考COCO数据集中姿态估计任务的判定标准,本文使用OKS来测量预测关键点与真实关键点之间相似度,实验的评价指标包括:1)OKS=0.5条件下的预测平均精度AP50;2)OKS=0.5,0.55,…,0.95这10个阈值点的模型预测平均精度均值;3)算法速度(FPS)。
2.3 实验与结果分析
2.3.1 环境设置与训练结果
本文实验平台服务器配置如表2所示。

表2 实验平台配置Table 2 Experimental platform configuration
本文算法网络模型共460层,总参数量为14 372 140,每秒10亿次的浮点运算数(GFLOPs)为19.6,经过37.943 h完成300个epoch训练,模型权重大小为30 MB。在模型训练的超参数设置中,初始学习率lr0=0.01,最终学习率lrf=0.2,随机梯度下降的动量momentum=0.937,权重衰减weight_decay=0.000 5,采用3个轮次的warmup,共训练300轮,输入图像大小为640×640像素。
图7为本文网络模型的训练损失曲线,损失曲线在训练刚开始阶段下降幅度较大,在迭代250轮左右时下降趋势开始变缓,在迭代300轮后,总体损失函数值收敛于0.196,相较于YOLO-Pose原损失函数,引入SIoU后改进的损失函数能使网络更快收敛,因此,本文网络损失函数改进合理。

图7 损失函数变化曲线对比Fig.7 Comparison of change curve of loss function
2.3.2 消融实验
为了进一步验证本文算法在小目标行人场景下具有更先进的检测效果,使用YOLO-Pose作为基准模型对网络逐步改进,对于每个步骤改进后的新模型,在融合数据集上进行实验和测试,得出模型消融实验结果,如表3所示。
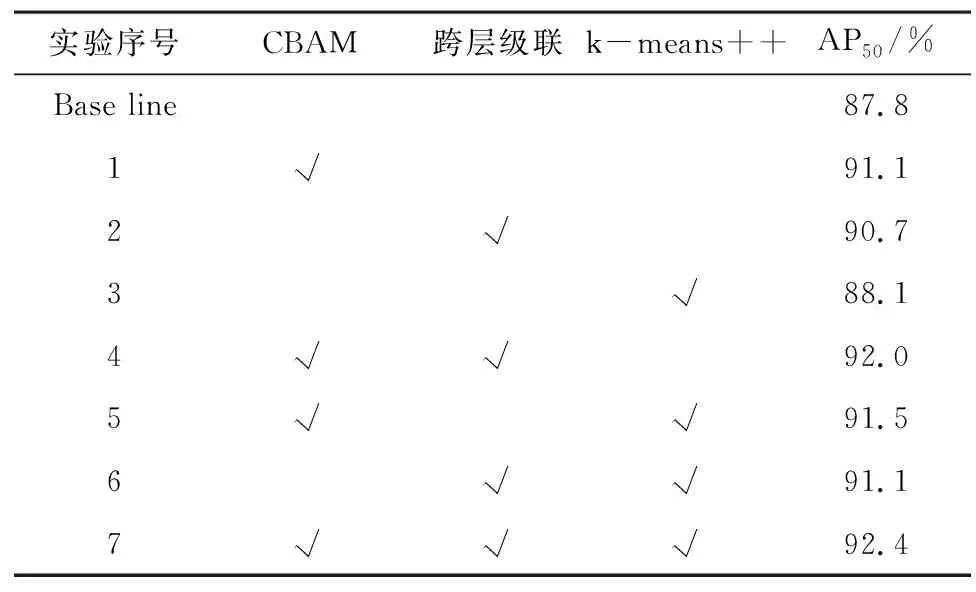
表3 消融实验结果Table 3 Ablation experiment results
2.3.3 不同算法检测结果对比
为了进一步验证本文算法的有效性和优越性,将本文算法和其他算法在相同的数据集和实验环境下进行测试,输入图像大小为640×640像素,得到各个算法的检测结果,如表4所示。
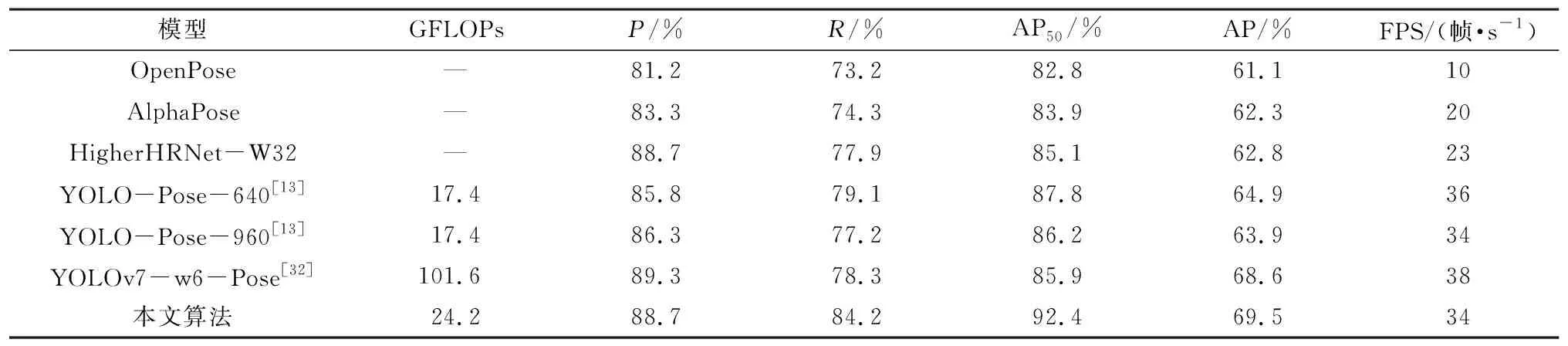
表4 不同算法检测结果Table 4 Detection results of different algorithms
2.3.4 姿态估计检测效果对比
图8给出了针对测试集的检测效果对比,可见YOLO-Pose-CBAM展现出了更高的精度和预测稳定性。如图8(a)所示,在非特殊场景下,原算法出现骨骼信息丢失,而本文算法对图中的手部和腿部有更细节的表现,预测出的骨骼架构更加清晰、准确;如图8(b)所示,当人体之间存在较多重叠区域时,原算法出现近半数目标漏检问题,而本文算法对重叠遮挡有较强的抗干扰能力;如图8(c)所示,当室外人群较密集、视角较低时,原算法对画面中央远端行人的检测出现丢失情况,相比之下本文算法依旧表现稳定。总之,本文算法针对测试集中的小目标行人、密集人群等场景都有更优异的姿态估计效果。

图8 测试集检测效果对比Fig.8 Comparison of test set detection effects
针对实际城市街景的小目标行人姿态估计对比如图9所示,可以看出,在图像边缘区域,当行人即将走进画面或走出画面时,目标区域逐渐变小,原算法会出现一段检测不到的真空带,在真空带出现异常信息漏检可能会造成严重的影响。而本文算法能够在目标较远、较小的情况下对行人姿态进行精确估计,有助于监控安防系统关注区域内的重点行人信息,在发生异常行为的初期,提供及时有效的援助,避免异常事件发酵成严重的社会事件。因此,针对城市街景小目标行人的场景,改进后的网络模型预测精度明显优于原网络。

图9 街景行人检测效果对比Fig.9 Comparison of pedestrian detection effects in street views
3 结束语
本文提出了一种改进YOLO-Pose的人体姿态估计算法YOLO-Pose-CBAM。本文的贡献主要包括:在特征提取网络中引入CBAM注意力机制,建立跨层级联的特征融合通道,使用SIoU改进损失函数,同时引入k-means++解决检测框初始聚类中心的选择局限性问题,构建WiderKeypoints小目标行人关键点数据集,验证算法有效性。实验结果表明,本文提出的算法在检测速度相近的前提下,提升了对小目标行人姿态的提取和估计能力,能够精准地检测到户外摄像头环境下的多人人体姿态信息,实现稳定的姿态估计效果。未来将通过对姿态估计得到的信息进行数据分析,结合目标追踪技术实现姿态追踪,同时,将引入Tensorrt技术进行网络推理加速,以及更深层次地分析人体姿态的意义。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
意林(2021年5期)2021-04-18
学生天地(2020年3期)2020-08-25
扬子江(2019年1期)2019-03-08
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
小天使·一年级语数英综合(2017年6期)2017-06-07
中国卫生(2014年2期)2014-11-12
语文知识(2014年7期)2014-02-28
