
基于语义与几何约束的动态SLAM系统
2024-04-23 04:35丁国强赵朋朋娄泰山
计算机工程与设计 2024年4期
丁国强,赵朋朋,李 涛,娄泰山
(郑州轻工业大学 电气信息工程学院,河南 郑州 450002)
0 引 言
当前的SLAM研究大多基于静态场景的假设[1,2],但是在实际应用中,动态对象是不可避免的。这些动态对象将改变图像信息,从而导致错误的数据关联并会降低定位的精度。此外,一旦将动态信息加载到地图中,将会导致“重影”[3],从而影响地图的可视化和应用。基于静态场景的假设极大地限制了SLAM的发展和在现实生活中的应用。传统SLAM[4]将动态对象视为错误数据关联,并通过RANSAC[5,6](random sample consensus)对其进行过滤,但当动态目标太多时,RANSAC将失效。
在面向动态环境的视觉SLAM系统中[7-10],特征可以分为两类,静态特征和动态特征。各种动态SLAM算法的目标基本上都是剔除动态特征,仅保留静态特征,以提高系统的精度。杨世强等[11]首先利用几何约束双向投票模型进行动态特征粗过滤,然后通过RANSAC计算系统基础矩阵,最终采用极线几何来精确判断动态特征并进行剔除;Wang等[12]应用基本矩阵检测特征点的不一致性,然后对深度图像进行聚类,当聚类区域中的异常值超过阈值时,该区域将被识别为移动对象。
为了应对动态环境的挑战,使视觉SLAM更好得到应用,本文提出了一种基于语义和几何约束的动态SLAM系统。将语义先验信息与几何约束相结合来处理动态特征,并且通过加入图像补全线程来降低剔除动态特征后对位姿估计的影响,从而提高视觉SLAM系统在动态环境中的定位精度。最后,在公开数据集上进行测试,实验验证了本文算法的有效性。
1 系统设计
1.1 SLAM系统框架
目前大部分有关SLAM的研究基本上都是基于ORB-SLAM2开展的,ORB-SLAM2是目前较为完善的SLAM方案之一,因此本文也在此基础上进行改进,如图1所示。原始的ORB-SLAM2系统主要包括3个线程:跟踪、局部建图、回环检测;本文针对动态环境的挑战,加入了语义分割网络,用来检测特征点的状态,针对剔除动态目标上的特征点后产生的掩膜空洞,加入了图像补全线程,有利于提高位姿估计和地图构建的精度。在输入图像后,并行运行语义分割网络和跟踪线程,进行运动一致性检测,利用先验的语义信息,判断图中的静态区域,待判断区域,背景区域,然后用静态区域的特征点迭代出基础矩阵,来确定待判断区域的状态。将动态区域的特征点剔除后,该区域的点将不参与后续的位姿估计与地图构建,以致于会导致图像特征的缺失,从而影响系统精度,因此采用图像补全线程,通过相关算法,搜索动态区域的背景图像块来形成一个合成帧,就相当于SLAM运行在一个不包含动态物体的静态区域,利用合成帧来估计相机位姿,可以有效提高相机位姿估计精度。
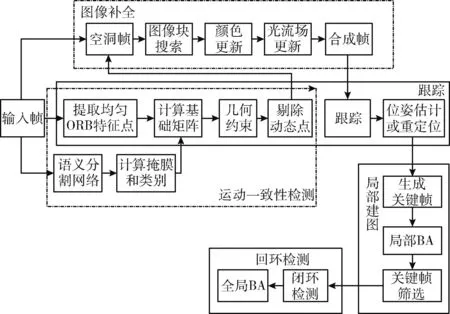
图1 系统框架
1.2 语义分割网络
为了检测动态对象,本文采用了SegNet语义分割网络,并在此基础上加入了注意力机制。引入注意机制是为了提高语义分割模型的性能。注意力机制的想法是允许解码器以灵活的方式利用输入序列中最相关的部分,通过所有编码输入向量的加权组合,使相关性最高的向量被赋予最高权重。本文改进后的语义网络结构如图2所示。

图2 改进的SegNet网络框架
Badrinarayanan等提出了SegNet网络结构,主要为了处理智能机器人领域中的图像语义分割问题。SegNet是一种具有深度卷积的对称网络结构,并且提出了编码器和解码器的概念。该网络的编码器部分主要由VGG16网络的前13个卷积层组成,并且没有使用全连接层,与其它分割网络相比,其网络参数数量显著下降。在Max pooling过程中,通过添加池化索引来记录池化过滤器中最大特征值的位置,以便保留池化操作的位置信息。然后,将最大值恢复到池化索引所记录的位置,并对其它位置用零填充,以确保上采样过程中信息的准确性,上采样池化恢复过程如图3所示。解码器部分则使用来自编码过程所记录的最大池化索引进行上采样,确保了解码器的上采样特征信息的恢复,并很好地保证了检测目标的边缘信息。上采样仅在解码器部分使用,与编码过程的池化层对应,并且上采样步骤不用进行学习,只需要通过池化索引就可完成。最终解码器输出高维的特征到分类器中,独立的对每个像素进行分类,预测的分割对应于每个像素具有最大概率处的类别。

图3 上采样恢复过程
本文在SegNet网络的基础上加入了通道注意力模块,其中Max pooling是将目标区域输出最大值,这种方式得到的特征图可以保留更多的纹理特征;Average pooling则是对池化区域内的图像取平均值,这种方式可以得到更多的背景信息。经过池化操作,得到两组1×1×512维的向量,然后用1×1的卷积使它们降到1×1×256维,接着经过ReLU激活层增加模型的非线性能力,最后使两组特征向量恢复到512维,将得到的权重乘以编码器的输出,可以有效提高网络的分割能力。其中,语义分割效果与部分先验信息如图4所示。

图4 语义分割效果与语义先验信息
1.3 运动一致性检测
对于两帧图片进行特征匹配,可以粗略得到特征点之间的匹配关系,但是因为场景中可能包含动态物体,因此会对位姿求解产生影响。一般来说,静态物体的匹配精度的置信度比较高。因此,本文选择使用先验静态匹配点对来估计模型。
根据之前的目标检测网络,我们已经得到了图像中的先验语义信息,根据一般经验,可以事先定义训练数据库所包含物体的类别的静态率,例如人、车、动物具有较低的静态率,此类目标是本文主要关注的对象,需要进行优化;而电视,桌子具有较高的静态率,如果将这个指标量化,可以表示为θ∈[0,1], 本文定义静态率大于0.9的区域为静止区域,其余部分为待判断区域。本文主要利用静止区域的特征点和背景点去计算帧间图像的基础矩阵。
通过语义分割网络,可以得到图片中所有的掩膜区域,和掩膜的分类信息,读取事先定义的物体的静态率。因此可以将掩膜区域分为静态掩膜,其中的特征点定义为staticP={P1,P2,P3,…Pn}, 和待判断掩膜,其中的特征点集合为unknownQ={Q1,Q2,Q3…Qn}, 而除去所有掩膜区域的部分,定义为背景区域,静态率为1,其中的特征点集合为backgroundM={M1,M2,M3…Mn}, 定义staticS为当前帧所有静态特征点的集合,则
staticS=staticP+backgroundM
(1)
对两帧图片staticSK与staticSK-1中的特征点进行匹配,计算其汉明距离,可以得到两帧图片静态特征点的对应关系。在此处使用RANSAC算法进行迭代,主要步骤为:
(1)在样本空间staticS中随机选择8对匹配点;
(2)利用式(6)使用8点法计算基础矩阵F;
(3)利用式(8)验证其余点的几何约束,统计符合约束的点的对数n;
(4)重复迭代步骤(1)~(3),将n达到最大时的F作为两帧图像的基础矩阵。
利用先验静态区域的特征点计算的基础矩阵精度较高,本文采用运动一致性检验来验证unknownQ中特征点的状态。定义约束条件如图5所示。

图5 几何约束
图5中O1与O2代表相机光心,PA与PB分别为3D点P在图像A与图像B上的投影点,归一化坐标分别表示为
pa=[u1v11]T,pb=[u2v21]T
(2)
对于pa与pb满足关系
s1pa=KP,s2pb=K(RP+t)
(3)
其中,K为相机内参矩阵,R、t为相机间的变换关系,s1、s2表示尺度因子。
在理想情况下,图片中一对匹配点满足约束
(4)
其中可以将基础矩阵F改写为
f=[f11f12f13f21f22f23f31f32f33]T
(5)
然后对式(4)进行改写,可以得到
[u1u2u1v2u1v1u2v1v2v1u2v21]f=0
(6)
其中,F中的元素全都包含在f中,pa与pb是一对匹配点,共有n对匹配点。而f中共有9个参数,且一般令f33=1来归一化矩阵,共有8个未知数,因此需要8个方程来求解,对应于取图片中8对匹配点,所以该方法称为8点法。
l1与l2分别代表两图中的对极线,在同一平面内可用Ax+By+C=0来表示,则像点PA映射到极线l2上用方程可表示为
(7)
其中,F为前一步RANSAC迭代出来的基础矩阵。
根据像点与极线的映射关系,可以得出特征点是否符合约束,从而判断特征点的状态。如果pb不在极线l2上,则需要计算像点到极线的距离
(8)
理想状态下,d应该等于0,而在现实场景中,由于相机采集的照片不可避免的存在一定程度的畸变和噪声,使得相邻帧间的点无法完美匹配在极线上。因此设定一个阈值T,当d>T,则判定该点为动态点。由于像点与极线的距离与特征点的视差值相关,因此阈值T定义为
T=αf+ε
(9)
其中,α代表视差系数,f代表特征点的视差值,也就是相邻两帧像素坐标的变化。通过对特征点与极线关系判断,确定动态特征点并进行筛除,如图6所示。

图6 动态特征点剔除效果
1.4 图像补全
经过运动一致性检测环节,环境中运动的物体并不参与位姿估计,而直接将运动目标滤除,必然会导致特征缺失,并在图像中产生掩码空洞,如图7所示,影响后续的位姿估计和建图,因此需要补充空洞区域。

图7 掩码空洞
视频补全方法旨在使用每帧中其余部分相似的内容来填充目标空洞。目前很多视频补全算法[13]仅针对固定摄像机,无法很好应用到SLAM中。因此本文采用一种非参数的基于图像块的补全算法[14]。该算法可以处理使用移动摄像机捕捉的动态场景,目前大部分方法还未涉及此类问题,因为视点变化会提升问题的复杂度。主要通过联合估计缺失区域中的光流和颜色来解决这个问题。
在该算法中,首先使用两帧光流算法计算所有相邻帧的已知区域中的正向和反向光流。经过初始化后,在每个尺度下,主要迭代3个步骤:
(1)最近邻场估计:在局部外观最相似的源图像块中寻找与目标图像块近似的图像块来最小化颜色空间误差;
(2)颜色更新:颜色更新通过图像块投票进行重建,其中未知像素处的像素颜色通过对所有重叠图像块中相应最近邻区域的颜色进行平均来估计,并且沿着光流向量搜索已知像素来合并已知区域中最近的相邻时刻的颜色,使用前向、后向流动一致性来识别不可靠流动的区域;
(3)光流更新:在估计目标区域的颜色后,细化正向和反向光流场。固定源区域中的光流,仅更新目标区域中的光流,从而得到具有时空孔边界约束的光流估计算法。
该算法补全效果如图8所示,最终任务归结为求解目标函数

图8 补全结果
(10)
其中,Ecolor-spatial表示目标区域中基于空间图像块的颜色重建误差;Ecolor-temporal表示合成颜色的时间不一致性;Eflow-spatial表示正向和反向流场的空间正则化。
对于颜色空间误差,可以使目标区域的局部邻域Pi近似为源区域的局部邻域Qi。由于考虑了重叠区域,因此可以保证空间一致。目标图像块Pi是一个以ti为中心的5×5轴对称区域,而Qi可通过Pi以si为中心,以θi为比例变换得到。颜色空间误差表示为所有重叠图像块的平方损失之和
(11)
而颜色时间误差可以保证正向和反向流向量的相邻帧之间颜色时间的一致性
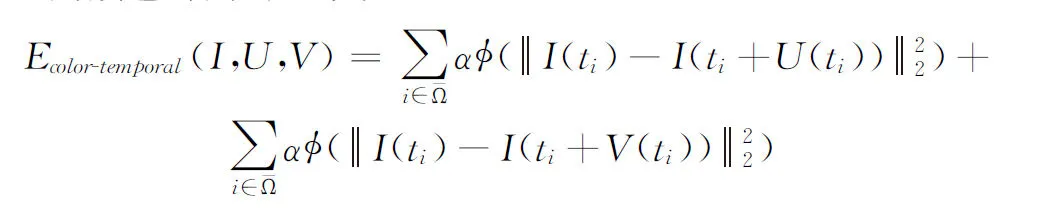
(12)
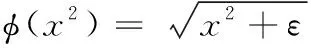
对于光流空间误差,为了促进分段平滑光流场,引入了空间正则化
(13)

1.5 位姿估计
经过之前的运动一致性检测剔除动态点,并对空洞区域进行补全后,利用合成帧提取特征点,求解相机位姿,更新位姿优化初值。假设有n个3D空间点Pi=[Xi,Yi,Zi], 以及这些点在二维图像中的像点pi=[ui,vi], 建立起Pi与pi的关系如式(14)所示,变换为参数形式如式(15)所示。其中si为尺度因子,K为相机的内参,ξ∧为位姿变换的李代数矩阵,exp(ξ∧) 表示为向量到矩阵的指数映射,e代表误差项
(14)
sipi=K·exp(ξ∧)Pi+e
(15)
对相邻帧构建最小二乘问题,就可以得到优化后的相机位姿
(16)
2 实 验
本文运行测试平台为笔记本电脑,其硬件配置为Intel Core i5-9400H,主频为2.3 GHz,内存为8 G,显卡为GTX 1050,搭载系统为Ubuntu 16.04。
2.1 数据集
实验所需的TUM RGB-D数据集是慕尼黑工业大学提供的一个大型开源数据集,其中包含RGB图、深度图和真实轨迹,可以用来评估视觉SLAM系统。
在测试中,本文主要使用数据集中的7个序列,且将它们定义为:freiburg2_desk序列是静态环境;freiburg3_sitting_xyz、freiburg3_sitting_static序列是低动态环境;freiburg3_walking_static、freiburg3_walking_xyz、reiburg3_walking_halfsphere、freiburg3_walking_rpy序列是高动态环境,关于数据集的介绍可参见文献[15,16]。为了后续表述简便,本文将数据集序列中的freiburg简写为fr,将sitting简写为s,将walking简写为w,将halfsphere简写为hs。
目前,视觉SLAM系统主要使用两种评估指标,包括绝对轨迹误差(absolute trajectory error,ATE)和相对位姿误差(relative pose error,RPE),具体定义请参见文献[17]。此外,我们还使用均方根误差(root mean square error,RMSE)和标准差(standard deviation,SD)来判断本文算法的准确性。
2.2 相机位姿误差分析
定量比较结果见表1~表3,比较了本文算法和ORB-SLAM2在7个数据集序列中的实验结果。评价指标为RMSE、平均误差(Mean)和SD。这些评价指标显示了估计轨迹与系统真实值之间的差异,可以此来分析系统的性能。

表1 绝对轨迹误差对比结果
表中本文算法相较于ORB-SLAM2性能的提升率可以表示定义为
(17)
其中,δ表示提升率,α表示ORB-SLAM2算法的轨迹误差,β表示本文算法的轨迹误差。
在表1中展示了算法之间的ATE对比结果,表2与表3分别是在不同序列中,算法之间的相对轨迹平移误差和相对轨迹旋转误差的对比结果。分析表1~表3中的数据,在高动态场景中,相较于ORB-SLAM2,本文算法ATE和RPE的各项数值明显降低了,其中ATE部分的RSME最高降低了98.4%,RPE平移和旋转误差部分最高分别降低了98.35%和97.52%,因为ORB-SLAM2无法处理相机的复杂运动叠加场景高速运动,容易定位丢失,而本文如入了运动一致性检测模块和语义分割模块来检测动态物体,使SLAM可以在高动态场景中工作。而对于静态和低动态场景,本文算法提升幅度不大,因为对于ORB-SLAM2算法本身具有一定的鲁棒性,可以处理一些低动态场景。
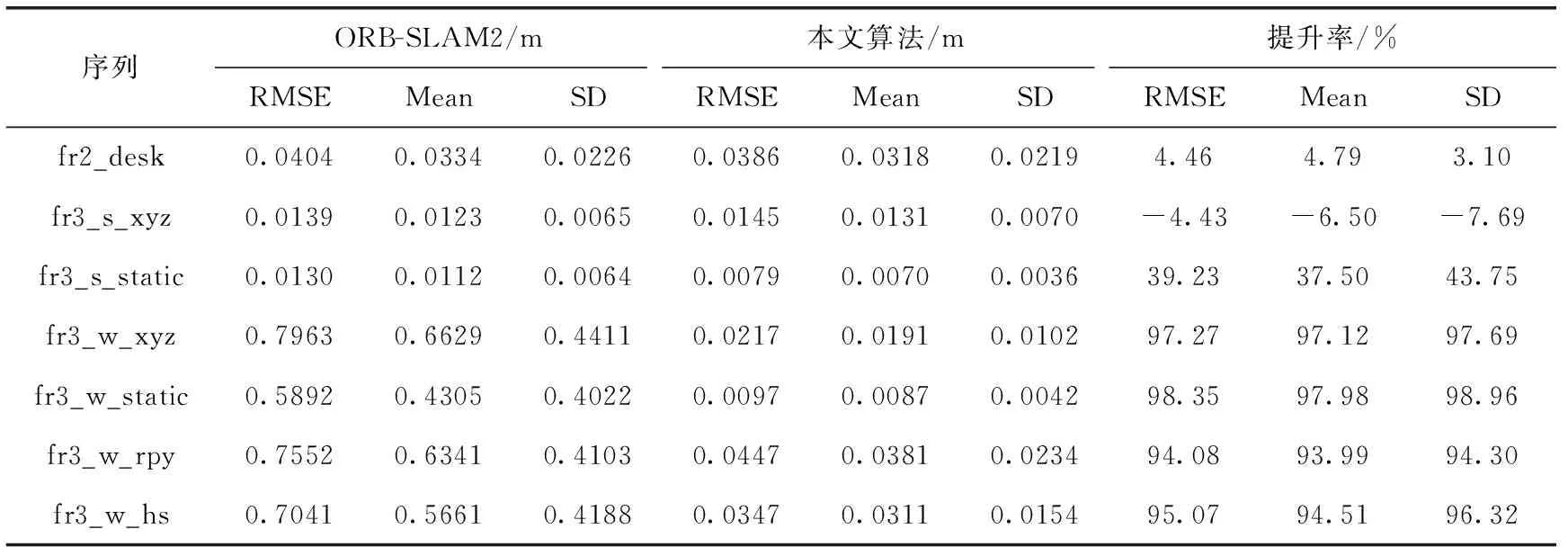
表2 相对轨迹误差平移部分对比结果
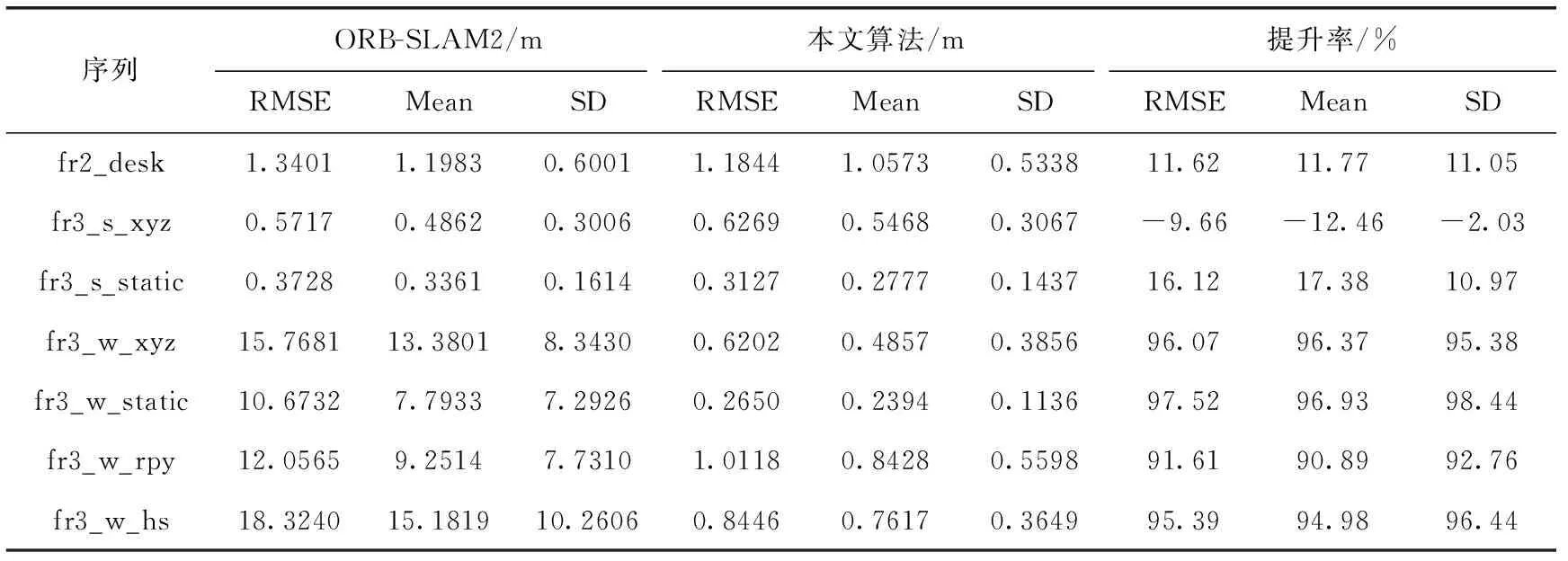
表3 相对轨迹误差旋转部分对比结果
对于图9、图10中,主要展示了本文算法与ORB-SLAM2在数据集的高动态序列上估计轨迹与真实轨迹的误差和两算法的相对位姿误差,从图中可以看出,ORB-SLAM2算法不能很好处理高动态场景,具有很大的轨迹误差。而观察本文算法的误差图,可以发现可以有效减小动态对象对系统的影响,因为本文利用语义网络提取先验信息,然后与几何约束相结合剔除了场景中的动态特征点,并且图像补全线程补充了动态特征剔除后的图像信息,相当于把原来的动态场景转化为静态场景,可以有效降低系统轨迹误差,提高位姿估计的精度。

图9 fr3_w_xyz序列上的ATE和RPE

图10 fr3_w_hs序列上的ATE和RPE
然后为了进一步验证本文算法的有效性,计算出其它面向动态环境的视觉SLAM系统的各项误差指标,并与本文算法进行对比,由表4可以得知,与目前一些先进的应用于动态环境的SLAM相比,本文算法也具有一定的竞争性。结果表明,该方法可以有效消除动态对象的干扰,从而降低优化过程中的位姿误差。

表4 同类算法ATE对比
2.3 算法实时性测试
这部分实验用于评估每个系统的跟踪时间。平均跟踪时间见表5。本文SLAM算法主要侧重于位姿估计和轨迹误差,因此对SLAM系统实时性能提升不大,主要是由于本文加入了语义分割网络来提取语义信息,分割图像,加入了运动一致性检测,用来剔除动态点,之后还对剔除动态点后的图像进行了补全,来优化位姿估计,这些线程都会产生时间成本。因此下一步需要进一步优化网络结构,进一步提高SLAM系统的实时性。
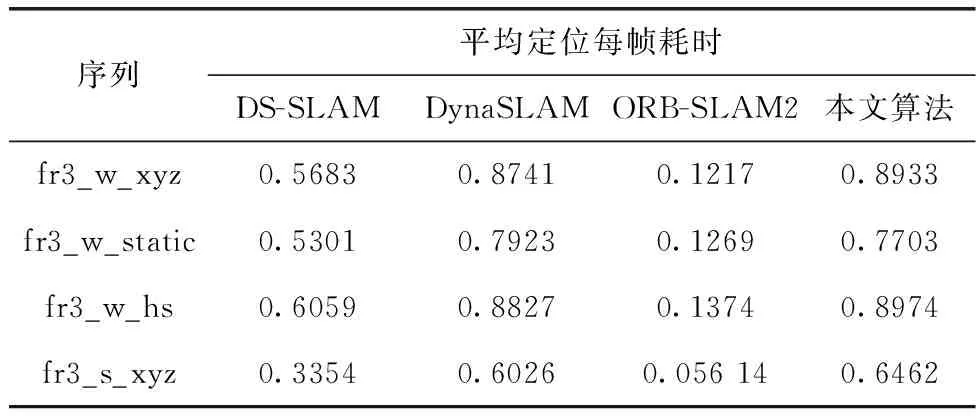
表5 不同系统的平均定位跟踪时间
3 结束语
本文利用改进的语义分割网络提取语义先验信息,结合几何约束剔除动态特征,并且对产生掩码空洞的图片进行补全。最后,在公开的TUM数据集上进行了评估。结果表明,在动态环境下,该算法可以显著提高定位精度。然而,在室外大规模、多动态目标场景中,仍会出现定位丢失的情况。目前,该算法可以应用在各种静态场景,以及一些室内动态场景中。在未来研究中需要进一步优化网络结构,以应对复杂环境中的各种挑战,更好的实现机器人的导航与定位。
猜你喜欢
云南画报(2021年8期)2021-11-13
开放教育研究(2020年2期)2020-03-31
阅读(低年级)(2019年4期)2019-05-20
光学精密工程(2016年5期)2016-11-07
光学精密工程(2016年4期)2016-11-07
现代语文(2016年21期)2016-05-25
湖北工业大学学报(2016年5期)2016-02-27
电子设计工程(2015年15期)2015-02-27
大连民族大学学报(2015年2期)2015-02-27
组合机床与自动化加工技术(2014年12期)2014-03-01
