
融合实体信息和时序特征的问答式事件检测方法
2024-04-23 04:35马宇航宋宝燕丁琳琳鲁闻一纪婉婷
计算机工程与设计 2024年4期
马宇航,宋宝燕,丁琳琳,鲁闻一,纪婉婷
(辽宁大学 信息学院,辽宁 沈阳 110036)
0 引 言
随着预训练语言模型在自然语言处理中的普及,现有一些研究[1-4]将基于BERT的机器阅读理解框架应用在事件检测任务中,其主要优势如下:①基于“预训练+微调”范式缓解了训练数据匮乏的问题;②基于“问答”范式在模型中引入了丰富的先验信息。然而,此类方法虽然能够通过BERT[5]达到一词多义的表征效果,但仍难以处理触发词分类子任务中的歧义性[6]问题(即触发词在不同的语境中可能会表达不同的含义,从而触发不同类型的事件),这主要归因于此类方法简单以BERT作为核心特征编码器,对句子的上下文语境以及句子前后的语义关系、句法结构的特征编码能力仍有很大的提升空间。
针对上述不足,本文提出了一种融合实体信息和时序特征的问答式事件检测方法,从以下3个层面对现有方法进行了改进:①在框架层面,构建一种以RoBERTa[7]为基础的问答式事件检测框架,增强模型的语义表示能力;②在输入层面,以特定的标注规则在输入序列中显式添加实体、实体类型等先验信息,增强模型对于句子上下文语境的感知;③在网络层面,采用最小门控循环单元(minimal gated unit,MGU)[8]和Transformer编码器[9]对句子的时序依赖关系进行建模,增强模型对于句子序列各单元之间的语义关系和句法结构的感知。通过在ACE2005英文语料上进行实验,验证了所提方法的性能以及在缓解触发词歧义性问题上的有效性。
1 相关工作
现有的主流事件检测方法主要分为以下两类:基于预训练语言模型的方法、基于机器阅读理解的方法。
1.1 基于预训练语言模型的方法
预训练语言模型通过在大规模的外部语料上进行预训练并在特定任务语料上进行微调,能够有效弥补训练语料对神经网络学习能力的影响。目前,BERT由于其出色的语义表示能力,被广泛应用于事件检测任务中。Wadden等[10]使用BERT来获取具有跨句子信息的语义表示,并使用动态图来捕获实体、触发词和论元之间的依赖关系。Nguyen等[11]提出了一种基于全局特征的联合信息抽取模型,在编码阶段使用BERT来获取字符的上下文语义表示,并在解码阶段引入全局特征捕获实例间和子任务间的依赖关系。Lin等[12]提出了一种端到端的联合框架,首先使用BERT对句子进行编码,然后通过条件随机场来检测触发词。程等[13]提出一种基于BERT和图卷积网络的触发词检测模型,在利用BERT进行语义表示后引入了句法结构来捕获长距离依赖。
此外,Liu等[7]在BERT网络架构的基础上另提出一种预训练语言模型RoBERTa,通过调整BERT的训练策略进一步提升了模型的语义表示能力,其主要改进如下:①引入动态掩盖机制,同一序列在不同epoch中采用不同的掩码模式;②移除NSP(next sentence predict)目标任务;③增加了训练数据的规模以及训练批次;④采用BPE(byte-pair encoding)编码;⑤调整了优化器的相关参数。在其基础上,张等[14]基于RoBERTa训练了两种维吾尔语预训练语言模型,胡等[15]则利用RoBERTa和全局图神经网络解决了文档级事件抽取中存在的长距离依赖问题。
1.2 基于机器阅读理解的方法
近期一些方法在BERT的基础上,将机器阅读理解框架应用在事件检测中,为模型引入了丰富的先验信息。Du等[1]和Li等[2]首先提出了两种基于机器阅读理解的事件检测方法,通过在模型输入序列中引入预定义的触发词问题,以问答的范式实现了触发词识别及分类。在此基础上,Zhao等[3]基于无触发词的设计,额外将事件类型直接添加到输入序列中进行二分类,而An等[4]则通过引入双流注意力机制缓解了论元角色重叠的问题。
然而,上述方法虽然通过引入先验信息有效提升了事件检测的性能,但仍难以正确分类具有歧义性的触发词,这主要是因为这些方法对句子的语境、语义、句法结构的特征编码能力仍有不足。为此,本文提出了一种融合实体信息和时序特征的问答式事件检测方法,从模型的框架、输入以及网络3个层面对现有方法进行了改进。
2 融合实体信息和时序特征的问答式事件检测方法
本章节首先介绍模型的整体架构,然后将从问题模板设计、实体信息融合、时序特征融合以及触发词识别及分类几个模块依次对模型进行展开讲解。
2.1 模型整体架构
针对触发词的歧义性问题,本文提出了一种融合实体信息和时序特征的问答式事件检测方法EDQA-EITF,模型架构如图1所示。给定一个待检测的句子,所提模型的处理流程可概述为:首先,利用RoBERTa分隔符将预定义的触发词问题Q={q1,…,qm}、 句子S={s1,…,sn} 以及实体信息E={e1,…,ep} 以固定形式拼接,生成模型的输入序列,m、n和p分别表示问题、句子和实体信息的子序列长度;其次,采用RoBERTa对输入序列中的所有分词(词向量表示的单位)进行交互以及编码,得到融入实体、问题等先验信息的句子语义表示;然后,引入时序特征融合网络(temporal feature fusion network,TFFN)对句子的时序依赖关系进行建模,进一步增强句子的语义表示;最后,引入线性层对TFFN输出的向量编码进行线性变换,并采用Softmax多分类器来预测触发词的位置和事件类型。此外,英文语料中的触发词往往只由一个单词充当,因此本文并未采用多个分类器来依次预测触发词的起始和结束位置。
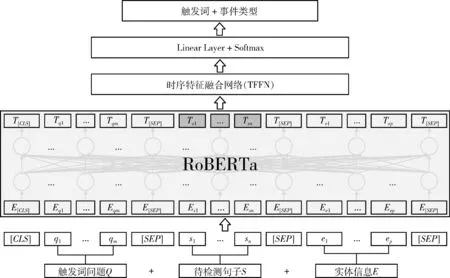
图1 EDQA-EITF模型架构
2.2 问题模板设计
问题模板设计是机器阅读理解任务中极其重要的一个环节,好的问题应该具备有效的先验语义信息,经过语义交互后使得模型基于问题来返回相应的答案,从而达到提示的效果。对于事件检测而言,问题模板主要由与触发词语义高度相关的单词或句子充当,其蕴含的先验信息能够帮助模型在训练的过程中更多地拟合到与触发词相关的关键特征。然而,现有方法[1-4]所提供的问题模板缺乏严谨的设计规则,导致模板之间的关联性较弱,因而无法通过对比实验充分地体现不同模板中的先验信息对模型性能的影响。为此,本文从语义贴近度和语义丰富度两个方面入手,逐步设计了多个触发词问题模板,增强了模板之间的关联性,详细信息见表1。

表1 触发词问题模板
2.3 实体信息融合
实体信息的具体引入方式借鉴了文献[16]在实体关系抽取任务中提出的实体标记方法,其通过设定特殊字段对句子中的实体开始位置和结束位置进行了标记。不同的是,为了避免标记字段对后续预测产生干扰,本文并未直接在句子中对实体信息进行标记,而是在原序列的基础上,额外增加了新的实体子序列用于存储实体信息,并引入了实体类型来标记实体的前后位置,使得模型对句子的语境进行更深层次的解读,详细信息如图2所示。值得注意的是,图中的“”并非固定字段,而是表示对应实体的类型,分别置于实体起始单词前和末尾单词后来标记实体的起始和结束位置。
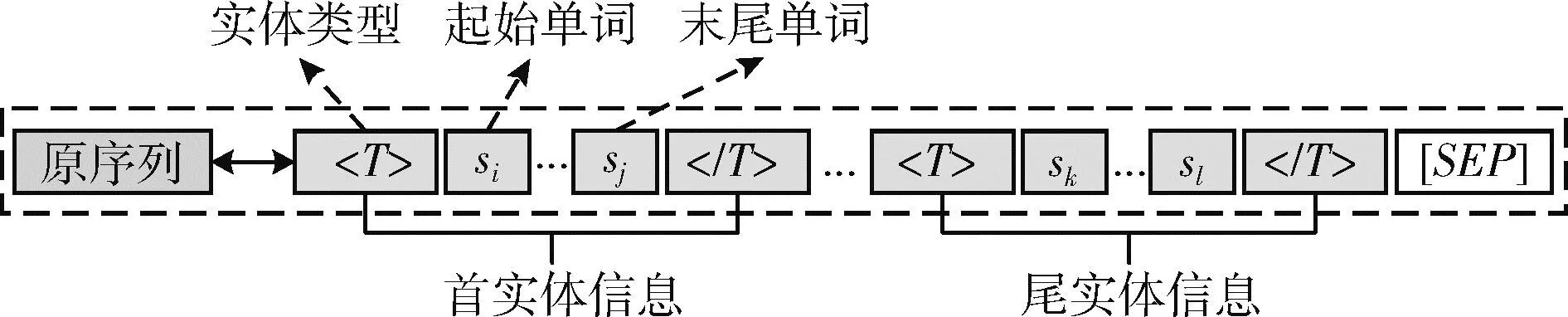
图2 实体信息融合
基于此种方式,在融入句子中的实体信息E={e1,…,ep} 后,模型的输入序列将变为
Input=[CLS]Q[SEP]S[SEP]E[SEP]
(1)
以句子“They released tear gas to protesters.(译:他们向抗议者释放了催泪瓦斯。)”为例,当选择表1中的模板“verb”作为触发词问题时,融入实体信息后的模型输入序列将被初始化为:[CLS]verb[SEP]Theyreleasedteargastoprotesters.[SEP]
{T[CLS],…,Ts,…,T[SEP]}=RoBERTa(Input)
(2)
2.4 时序特征融合
在得到融入实体信息、触发词问题等先验语义知识的句子语义表示后,为了增强模型对于句子各单元之间的语义关系和句法结构的感知,本文提出一种时序特征融合网络来增强句子的语义表示,整体架构如图3所示。
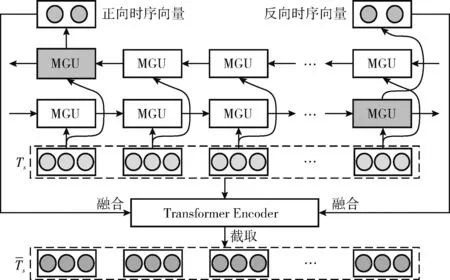
图3 时序特征融合网络架构
图3中所示的MGU是门控循环单元(GRU)的一种新型变体,其通过将遗忘门(更新门)和输入门(重置门)进一步融合为遗忘门,最简化了门控单元的数量,可以实现在保持GRU网络性能的同时,减少网络参数量,从而加快模型的收敛速度,并仍能够规避传统循环神经模型存在的梯度消失和梯度爆炸的问题。MGU的核心网络结构如图4所示,其在t时刻的计算过程如下:
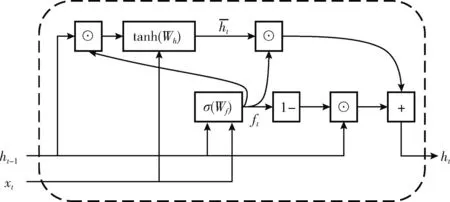
图4 MGU网络结构
(1)计算遗忘门。将t-1时刻的隐藏层状态ht-1和t时刻的新信息xt联合输入,经过线性变换后交由sigmoid激活函数计算ht-1的遗忘比例
ft=σ(Wf[ht-1,xt]+bf)
(3)
(2)计算候选隐藏层状态。首先将ft和ht-1乘积得到ht-1被遗忘的部分,然后将其和xt联合输入,经过线性变换后交由tanh激活函数得到候选隐藏层状态
(4)
(3)计算最终隐藏层状态。首先将1-ft和ht-1乘积得到ht-1被保留的部分,然后将ft和候选隐藏层状态乘积得到新的状态,最后通过相加得到最终的隐藏层状态
(5)
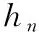
(6)
(7)
(8)
(9)
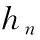
(10)
(11)
2.5 触发词识别及分类
触发词识别和触发词分类是事件检测的两个核心子任务,本文则将其整体视为一种分词级别的多分类任务,基于分类结果可同步得到触发词在句子中的偏移量及其事件类型。具体来讲,在得到融合了时序特征的增强语义表示后,首先引入一个线性层对词向量的特征维度进行转换,然后采用Softmax分类器来完成触发词的预测
(12)
其中,Pt表示句子每个分词在所有分类标签下的概率分布,Nt表示预定义事件类型的数量。在测试阶段,本文采用Argmax函数得到每个单词的具体分类结果
Result=Argmax(Pt)
(13)
而在训练阶段,本文采用交叉熵损失函数来计算模型整体的损失
(14)
其中,yij表示第i个分词在第个j分类标签下的真实分类结果(0或1),pij表示第i个分词在第j个分类标签下的实际预测概率。
3 实验分析
3.1 数据集
为评估所提方法的性能,本文在ACE2005英文语料上进行了详细的实验与分析。该语料为广播新闻、广播对话等多个领域的文档提供了注释,共标注了8种事件类型、33种子事件类型以及5272个事件触发词。基于子事件类型的数量,本文在触发词分类子任务中预定义了34种分类标签(包含None)。此外,本文沿用文献[1]中的数据分割方法对语料进行了划分,从而依次得到训练集(529个文本,14 180个句子)、验证集(30个文本,863个句子)以及测试集(40个文本,672个句子)。
3.2 评估标准及评价指标
本文沿用了文献[1]在触发词识别和触发词分类子任务上的评估标准:①如果触发词的预测偏移量与真实偏移量相同,则将其统计为触发词识别子任务中的正确项;②如果触发词满足条件1,并且其预测事件类型与真实事件类型相同,则将其统计为触发词分类子任务中的正确项。
本文采用精确率P(Precision)、召回率R(Recall)和F1值(F1-score)作为实验结果的评价指标。此外,在迭代训练的过程中,本文将在验证集评估中触发词分类F1值最高的迭代模型视为最佳模型,而模型的性能由最佳模型在测试集上进行评估。
3.3 实验环境及参数设置
本文采用的实验环境如下:操作系统版本为Windows 10,显卡版本为RTX 3090,显存大小为24 GB,Python版本为3.7,Pytorch版本为1.2.0。在超参数设置方面,详细信息见表2。
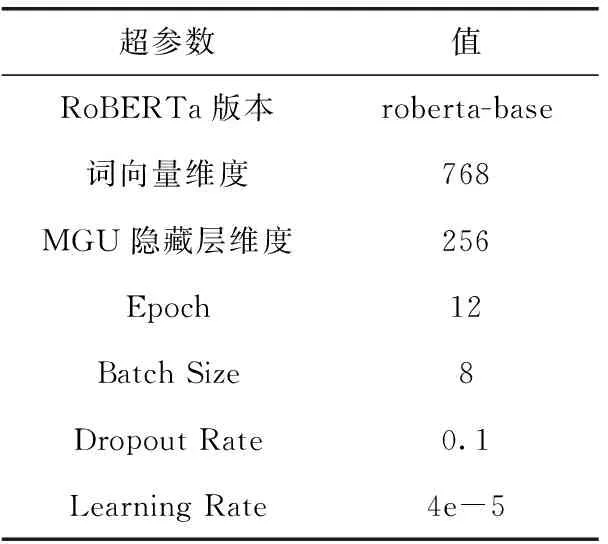
表2 超参数设置
3.4 总体实验结果及分析
本文选取以下模型作为对比实验的基线模型:①GYDIE++[10]:一种基于上下文跨度表示的多任务框架,能够以图传播的方式充分感知全局信息;②Joint3EE[11]:一种基于共享隐藏层表示的深度联合模型,能够同时提取实体、触发词以及论元;③EEQA[1]:一种基于机器阅读理解框架的事件检测模型,能够以单轮问答的形式同步提取触发词和事件类型,并提供了多种有效的触发词问题模板;④BGCN[13,1]:一种基于BERT和图卷积网络的事件检测模型,通过引入句法结构能够捕获句子中的长距离依赖特征;⑤Text2event[17,1]:一种序列到结构式事件检测模型,能够在不使用触发词偏移量的前提下,直接从并行的文本记录注释中学习;⑥DEGREE[18,13,1]:一种基于数据生成的高效事件检测模型,基于手工设计的提示规则能够为模型提供语义指导。
表3展示了本文所提模型EDQA-EITF和基线模型在测试集上的总体实验结果。整体来看,EDQA-EITF在触发词识别和触发词分类子任务上的F1值上显著优于基线模型,验证了EDQA-EITF整体设计的有效性,这主要归因于相比于大多数基线模型,EDQA-EITF基于问答范式在模型输入序列中显示地添加触发词问题、实体等信息,引入了丰富的先验语义知识,从而提升了模型对于关键特征的感知能力。
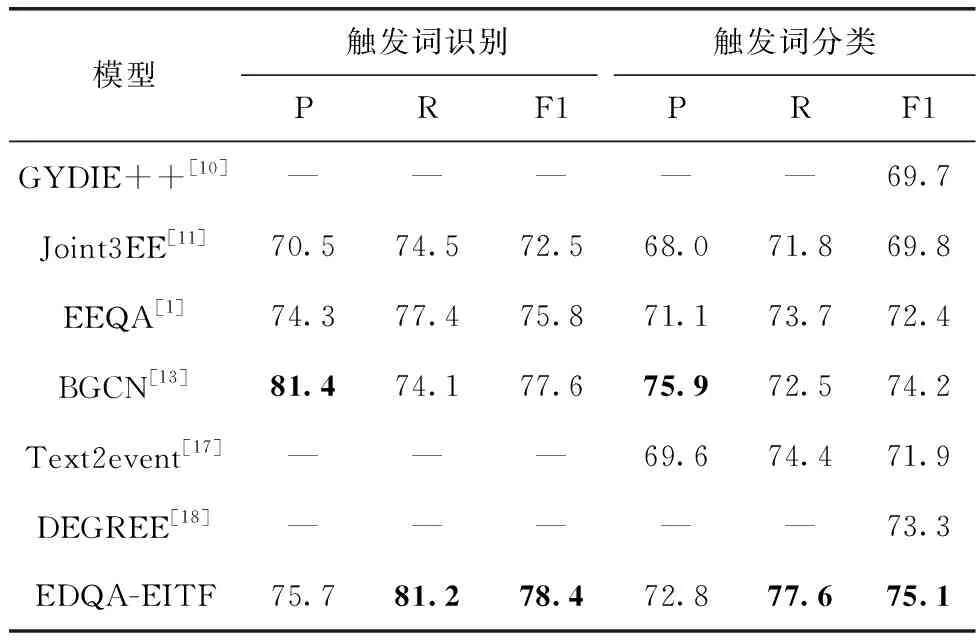
表3 总体实验结果
此外,与同类方法EEQA相比,EDQA-EITF同样在利用“verb”作为触发词问题时取得了更好的性能,这主要归因于以下几个方面:①相比于EEQA,EDQA-EITF在模型中额外融入了实体、实体类型等先验信息,提升了模型对句子上下文语境的感知能力,从而在触发词分类子任务中取得了更好的效果;②EDQA-EITF利用实体类型额外标记了实体在句子中的前后位置,而语料中的触发词和实体在句子中的位置通常并不交互,模型通过学习后将更倾向于在实体跨度以外的单词中识别触发词,从而在触发词识别子任务中也取得了更好的效果;③EDQA-EITF引入RoBERTa进一步增强了句子的语义表示,并通过在模型中融入句子的时序依赖特征,提升了模型对句子语义关系、句法结构的解读能力。
3.5 问题模板对比实验结果及分析
表4详细展示了模型在不同问题模板下的实验结果。根据模板1至模板8的实验结果来看,在以“verb”作为触发词问题模板时,模型在触发词识别及分类子任务上的F1值均达到了最佳。
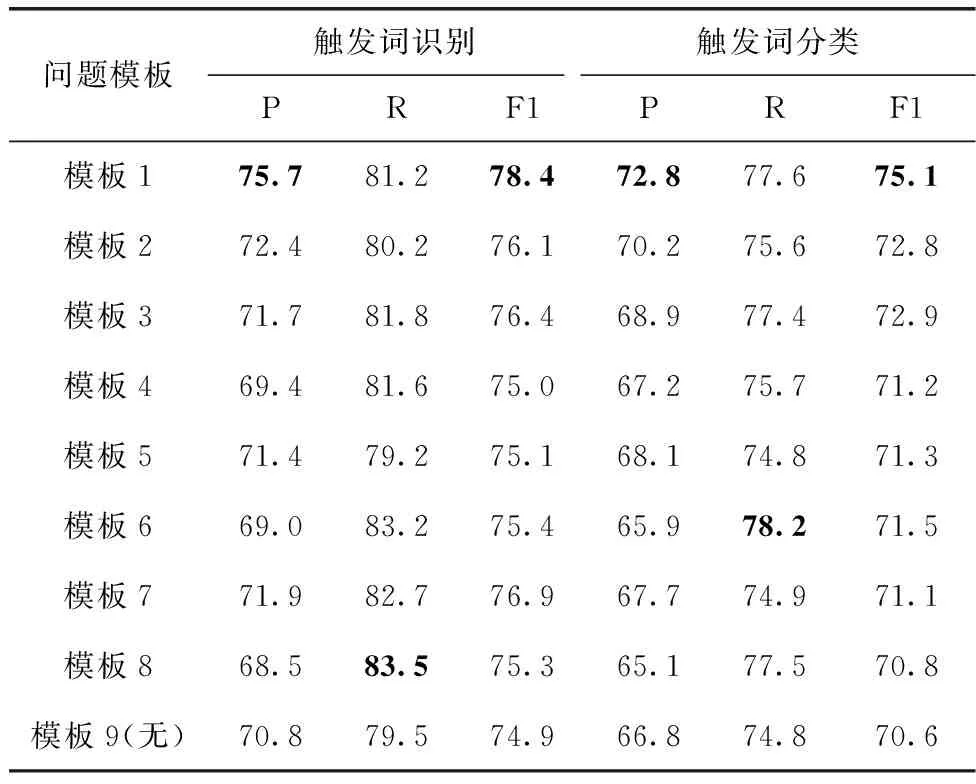
表4 问题模板对比实验结果
根据模板1至模板4的实验结果来看,“verb”和“symbol”在触发词识别及分类子任务上的F1值均高于“trigger”和“happen”,这表明在基于语义贴进度设计的触发词问题模板中,“verb”和“symbol”可以为模型提供更有效的先验信息。根据模板1、模板5、模板7的实验结果来看,在以“verb”为核心词汇进行扩充语义后,模型在触发词识别和触发词分类子任务上的F1值均有所下降。同样的,根据模板3、模板6、模板8的实验结果来看,在以“symbol”为核心词汇进行扩充语义后,模型在触发词识别和触发词分类子任务上的F1值也均有所下降。这主要归因于在基于语义丰富度进行设计后续问题模板时,虽然通过扩充语义的方式使得触发词问题模板表达的语义更为清晰和完整,但逐渐增长的序列长度却会引入过多的噪声,从而导致模型捕获到过多与触发词无关的语义特征。
此外,为了分析触发词问题在整个模型框架中的重要性,本文将问题置为空后额外进行了实验,如模板9的实验结果所示。整体来看,在移除触发词问题后,模型在触发词识别和触发词分类子任务上的F1值有了明显的下降。这表明通过添加具有提示作用的触发词问题,并利用注意力机制对问题中的先验信息和待检测句子进行充分的交互,能够有效提升模型对于句子关键特征的感知能力。
3.6 消融实验
为验证模型(EDQA-EITF)核心模块设计的有效性,本文进行了如下的消融实验:整体移除RoBERTa、时序特征、实体信息3个模块(EDQA)、仅保留RoBERTa模块(EDQA-RB)、仅保留实体信息模块(EDQA-EI)、仅保留时序特征模块(EDQA-TF),实验结果如图5所示。
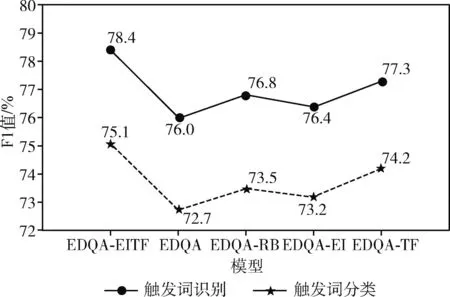
图5 消融实验结果
整体来看,在移除RoBERTa、实体信息、时序特征等模块后,模型的性能均出现了明显的下降,这验证了EDQA-EITF各个核心模块设计的有效性,也表明了句子语义表示的增强以及实体信息、句子时序特征的引入对于事件检测具有很好的促进作用。
3.7 案例分析
为进一步展示所提方法的优越性,本小节展示了EDQA-EITF和EEQA[1]在同样以“verb”作为触发词问题时的两个事件检测案例,如图6所示。从图中提供的句子原文可知,句1和句2中的触发词均为“fired”,但却触发了不同类型的事件。从图中提供的检测结果可知,EEQA虽然能够精准地从句1中识别出“fired”并对其正确分类,但在句2中却依旧将其错误地划分为“攻击”类型的事件。而EDQA-EITF却没有出现这样的错误,这主要归因于其对触发词所在的上下文语境、句子序列结构等语义信息有更深层次的感知,也验证了EDQA-EITF在缓解触发词歧义性问题上的有效性。
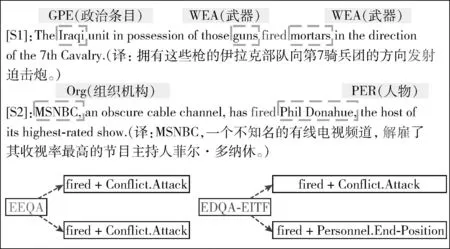
图6 案例分析
4 结束语
本文提出了一种融合实体信息和时序特征的问答式事件检测方法,通过增强模型对输入序列的语义表示,以及在模型中融入实体先验信息和句子的时序依赖关系,缓解了触发词的歧义性问题。此外,本文针对问题先验信息对模型性能的影响进行了更细致的分析。在ACE2005英文语料上的实验结果表明了所提方法的有效性。在未来的研究工作中,将尝试在模型中融入跨句子的文档级特征,并将此框架扩展到论元抽取子任务中。
猜你喜欢
中国农业信息(2023年3期)2023-03-18
中国农业信息(2021年3期)2021-11-22
开放教育研究(2020年2期)2020-03-31
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
电子制作(2016年15期)2017-01-15
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
