
异质中心角距离约束的多粒度跨模态行人重识别
2024-04-23 04:35邹业欣
计算机工程与设计 2024年4期
邹业欣,蒋 敏
(江南大学 人工智能与计算机学院,江苏 无锡 214122)
0 引 言
传统单模态行人重识别[1]是一项从不相交的摄像头中,对可见光行人图像进行匹配的任务,而跨模态行人重识别是在查询集中选定一特定行人的可见光图像或红外光图像,从相应的另一种模态下的图库集中匹配同一行人身份图像的任务[2]。红外光图像丢失了丰富的颜色信息,并且两种图像的波长范围不同。二者的巨大差异导致跨模态行人图像匹配异常困难[3]。
为提高跨模态行人重识别的精度,文献[4]提出使用生成对抗网络生成与真实可见光图像对应的虚拟红外光图像,并将其与真实红外光图像进行匹配。文献[5]利用一个自监督学习的网络生成X模态的图像作为辅助输入,使得网络能够提取公共空间中的跨模态共享信息。但是基于造图的方法需要耗费昂贵的计算资源,并且会破坏生成图像中的空间结构和颜色信息[6]。文献[7-9]采用了基于欧氏距离的三元组损失来限制相同行人特征在公共空间的距离小于不同行人之间的距离。但是基于欧式距离的三元组损失函数不能有效地约束特征向量之间的角度。
针对上述问题,本文提出了一种对于跨模态行人重识别的多粒度特征学习网络,通过有效结合全局特征和不同粒度的局部特征,提高网络提取可鉴别性行人特征的能力。本文采用了能够有效约束特征向量在公共空间上角度的角距离度量学习方法,并结合异质中心的思想,提出了基于角距离的异质中心三元组损失函数。最后在SYSU-MM01和RegDB数据集上进行实验,以验证本文方法的有效性。
1 相关工作
1.1 多粒度特征学习
跨模态行人重识别存在遮挡问题[10],局部特征在处理遮挡问题时往往起着关键作用。为了提取具有可鉴别性的局部特征,文献[11]提出了卷积基准模块结合精确部分池化的网络模型,可以学习到部分层级局部特征,这使得属于同一类的不同模态样本在学习到的特征子空间上更紧密地聚集,但这种特征切块策略容易导致特征不连续以及特征不对齐[12]。文献[13]提出了多粒度网络,有3个分支,每个分支对特征进行不同处理,并使用多损失来进行学习,在单模态行人重识别上性能取得了显著的提升。但这种模型对硬件要求较高,且实验时间较长。为此,本文提出了多分支不同粒度特征切块策略,粗粒度、细粒度的局部特征与全局特征三者互为补充,使网络学习到更具判别性的行人特征。
1.2 多粒度特征学习
为了缩小跨模态之间固有的差异,文献[14]提出了学习跨模态可共享特征的匹配模型,其中三元组损失是不可或缺的。然而在传统三元组的采样方法中,每个batch中所涉及和更新的信息非常有限,容易重复训练,使得网络难以收敛。为此文献[15]提出了pk采样来缓解上述问题,其随机选取p个行人身份,每个行人身份采样k张图像,依此形成三元组样本对。但当出现异常样本时,即在一类行人图像中,异常样本偏离其它同类样本的距离过远,这会破坏其它学习的好的成对距离。为解决此类问题,文献[16]提出了异质中心三元组损失,通过计算批样本类中心与其它批样本类中心的距离来校正跨模态和相同模态样本类之间的中心距离。考虑到跨模态行人重识别的输入为红外光图像和可见光图像,本文采用2pk采样方法,并结合异质中心三元组损失来减小计算量,同时增强模型的鲁棒性。
1.3 度量学习
现今跨模态行人重识别主要是聚焦于学习具有语义表示的高级特征(如属性和深度特征)和低级特征(如形状、颜色和纹理),后者更具鉴别性[17]。基于度量学习的方法可以更好地学习数据之间的潜在相关性和更具鉴别性的特征。文献[18]基于度量学习提出了三元组损失,拉近相同行人身份特征之间的距离,推远与不同行人身份特征之间的距离。但是由于三元组损失函数自身有限的局部优化使得网络难以收敛[19]。文献[20]提出使用角距离作为度量学习的策略,与身份验证损失相结合,可以更容易实现局部以及全局优化。为此,本文采用了基于角距离的三元组损失,有效地测量特征向量之间的角度,从而模型能够正确分离公共空间中的特征向量。
2 方 法
2.1 网络结构
本文设计的CM-MGN网络结构如图1所示,主要由ResNet50骨干网络、池化层、1×1卷积降维层,全连接层(FC)和多种损失函数构成。

图1 CM-MGN网络结构
ResNet50骨干网络的前两个残差块(stage)提取不同模态的特定特征,参数不共享;后3个残差块则提取不同模态的共享特征,参数共享。经过stage5得到特征图(Feature map)后,依次进入3个分支(Branch)。分支一对特征图直接进行广义平均池化(GeM)[21]以及卷积降维(1×1 Conv)操作;分支二在水平方向上对特征图均等分为3块,得到粗粒度的局部特征,再进行GeM以及卷积降维操作;分支三在水平方向上对特征图均等分为6块,得到细粒度的局部特征,再进行池化和降维操作。最后,将3个分支提取到的特征使用HCAT损失和平滑身份损失进行联合训练,从而缩小跨模态内相同行人特征的差异。
由于本文需要对粒度进行分块切割的特点,对提取到的特征维度有一定要求。为此,本文删除了残差块stage5后面的平均池化层和全连接层,直接得到Feature map后分别进入各分支进行处理。为了清晰地展示各分支维度变化,在图1中特征图下方均标明了对应的维度。
2.2 异质中心角距离三元组损失(HCAT)
传统三元组损失函数的设计思想是拉近锚点图像与所有正样本之间的距离,推远与所有负样本之间的距离,通常使用的是欧式距离。此外,设置了超参数δ使得具有相同行人身份的特征向量之间的距离小于不同行人身份之间的距离,如式(1)所示
(1)
其中,a,p,n表示一个基准三元组样本对,分别代表着锚点样本图像、正样本图像和负样本图像,表示batch的大小,Fe(·) 表示特征提取器,D(·) 表示欧式距离,[·]+表示裁剪函数,δ表示校正距离的超参数。
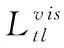
(2)

(3)
其中,I代表图像,上标v,ir分别表示可见光模态和红外光模态,下标a,p,n分别表示锚点样本、正样本和负样本,式(2)中的基准三元组样本对为可见光锚点图像,正样本红外光图像和负样本红外光图像。式(3)中的基准三元组样本对为红外光锚点图像,正样本可见光图像和负样本可见光图像。总的跨模态三元组损失如式(4)所示
(4)
传统三元组损失函数需要计算锚点样本与其它所有样本之间的距离,计算复杂度是巨大的。另外,若选取样本中存在离其类中心过远的异常样本案例时,会破坏其它学习好的成对距离。为此,本文选择计算锚点类样本中心与其它类样本中心的距离。在一个batch中,本文计算锚点类样本中心的计算方式如式(5)和式(6)所示
(5)
(6)
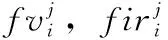
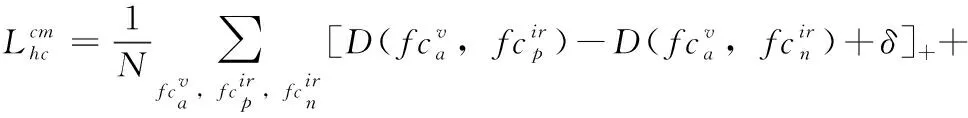
(7)
然而,基于欧式距离的三元组损失函数并不能有效地测量特征向量的角度,未能分离其在公共空间上的方向。同时,在跨模态行人重识别中三元组损失会经常结合身份验证损失一起使用,身份验证损失利用相对距离使得分类器进行更好的分类,然而基于欧式距离的三元组损失使用的是绝对距离。二者的关注点是不同的,角距离关注的是相对距离,并且可以有效测量特征向量在公共空间中的角度。因此,结合异质中心的思想,提出了基于角距离的异质中心三元组损失,如式(8)所示

(8)
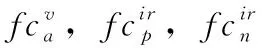
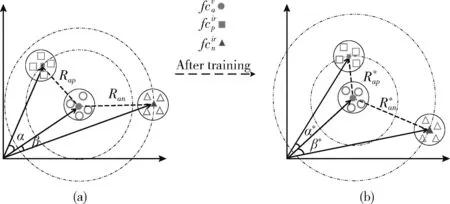
图2 HCAT损失
2.3 总损失函数
为了提高模型正确匹配图像的能力,本文采用了通过将每个行人视为一个类来整合特定身份信息的身份验证损失,增大了不同类的间距。同时为了解决模型训练过拟合的问题,本文加入了标签平滑的操作[22],平滑身份验证损失如式(9)所示
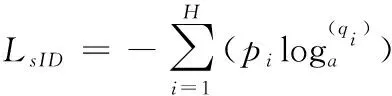
(9)
其中,H表示行人身份类别数目,pi表示标签平滑参数,表示防止训练模型过于相信训练集的超参数,υ在本文的实验中设置为0.1,y表示真实值的标签,qi表示模型预测类别为i的概率值,如式(10)所示
(10)
其中,wj表示全连接层中第j类的权重向量,T表示矩阵的转置,b表示偏置参数,xi表示属于yi类别的第i个样本提取到的特征向量。
网络包含全局特征分支一,粗粒度局部特征分支二和细粒度局部特征分支三。每个分支都有各自相应的损失,其中,分支二和分支三中的每一个分块都有相应的损失,如式(11)所示

(11)
总的损失如式(12)所示
Lall=LBranch-1+LBranch-2+LBranch-3
(12)
3 实 验
3.1 实验数据集
SYSU-MM01是跨模态行人重识别中应用最广泛的一个数据集,图像由4个可见光摄像机和两个红外光摄像机拍摄而成,总共有491个行人。训练集中有395个行人身份,其中296个行人身份用作训练集,剩下的99个用作验证集,总共有22 258幅可见光图像和11 909幅红外光图像。测试集中有96个行人身份,随机选择301幅可见光图像作为图库集,剩下的3803幅红外光图像作为查询集。共有全局搜索模式,全局搜索模式是指将可见光摄像机(1,2,4,5)拍摄的图像作为图库集,而红外光摄像机(3,6)拍摄的图像作为查询集,特点是随机选取行人图像作为图库集,查询集中的图像都是红外光图像。室内搜索模式是指图库集和查询集只采用室内摄像机(1,2,3,6)拍摄的图像。由于室外图像存在更多的噪声,全局搜索模式比室内搜素模式更具有挑战性。
RegDB[23]数据集总共有412个行人身份,每个行人身份都有相对应的10幅可见光图像和10幅红外光图像,总共有8240幅图像。数据集被随机均等分为两部分,一部分作为训练集,另一部分则作为测试集。在测试阶段,随机选取其中一种模态的图像作为图库集,则另一种模态的图像作为查询集。图3是两个数据集中部分行人图像展示,第一行是可见光行人图像,第二行是红外光行人图像,每一列展示的行人身份是相同的。

图3 跨模态行人重识别数据集
3.2 实验设置
本文采用的深度学习框架是PyTorch 1.6,使用在Ima-geNet上预训练过的ResNet50模型作为本文的骨干网络,并在单张NVIDIA 2080Ti GPU上进行训练。在训练阶段,两种输入图像的维度均为3×288×144,填充设置为10,并采用了随机翻转和裁剪的数据增强策略。采用SGD优化器对网络进行优化,并将动量设置为0.9,学习率设置如式(13)所示
(13)
其中,lr表示学习率,t表示训练周期。本文使用的是经典的2pk采样方法,由于两个数据集大小并不同,对于SYSU-MM01数据集,p设置为6,k设置为8,训练总批次为120;对于RegDB数据集,p设置为8,k设置为4,训练总批次为80。
3.3 实验评估标准
本文采用Rank-1、Rank-10和Rank-20的标准累积匹配特征CMC(cumulative matching characteristics)和平均精度均值mAP(mean average precision)作为评估标准。对查询图像特征与图库集图像特征的差异进行排序,差异最小的图库集图像排在首位。Rank-1表示图库集中排序第一的图像身份与查询图像身份相同的概率,Rank-10表示在图库集中排序前十的图像身份是否有一张图像的行人身份与查询图像身份相同的概率。平均精度(AP)是指每一类行人图像所有正确匹配率之和除以正确匹配图像的数量,mAP是指所有查询集行人图像类的平均AP。
3.4 实验结果分析
为了验证本文方法的有效性,数据集RegDB上是可见光图像匹配红外光图像,数据集SYSU-MM01上采用了全局搜索模式,与现今跨模态行人重识别主流方法进行对比,采用统一的评估指标mAP和Rank-n。其中AliGAN[4]、HiCMD[24]和XIV[5]算法都是采用对抗生成网络造图的方法,对实验的硬件条件要求较高,且消耗的计算资源较大,本文算法不仅减小了计算复杂度,同时也增强了模型的鲁棒性。对比效果最佳的XIV算法,在RegDB和SYSU-MM01数据集上的mAP和Rank-1分别提升了23.94%和30.12%/8.16%和12.20%,从结果可以看出,本文算法大幅优于基于造图方法的跨模态行人重识别。其中AGW[1]、CIDL[25]和HCTri[26]算法均采用了关注相对距离的三元组损失和关注绝对距离的身份验证损,忽略了二者关注点不协调的问题,而本文算法提出的HCAT损失有效解决了上述问题。对比效果最佳的HCTri算法,在RegDB和SYSU-MM01数据集上的mAP和Rank-1分别提升了1.84%和2.28%/2.09%和2.44%。具体结果见表1。
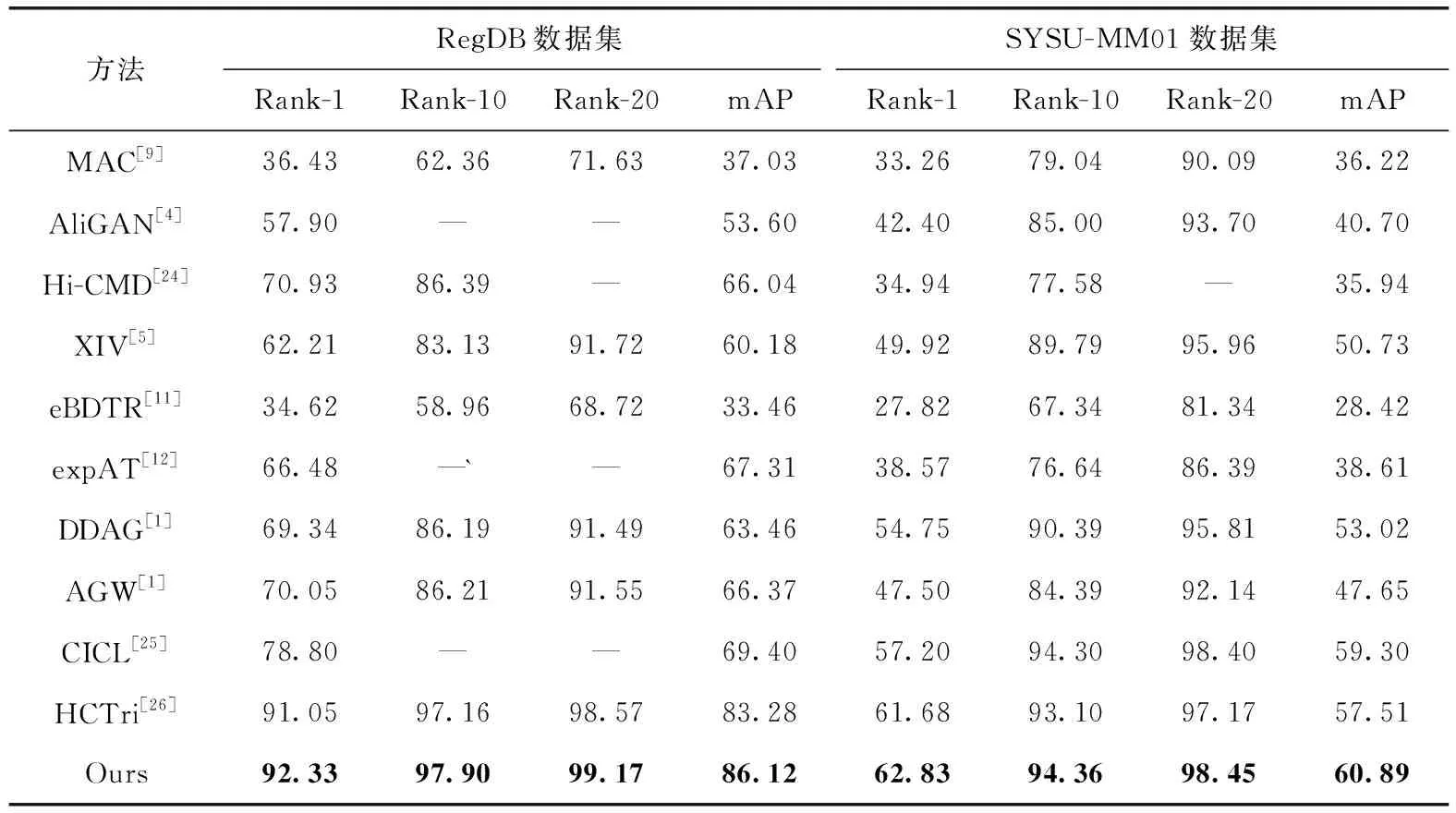
表1 RegDB和SYSU-MM01数据集上不同方法的性能比较结果
从表1的实验结果可知,本文方法在两个数据集上均取得了较优的效果。在SYSU-MM01数据集上Rank-1和mAP分别达到了62.83%和60.89%,在RegDB数据集上Rank-1和mAP分别达到了92.33%和86.12%。本文通过有效结合全局特征和不同粒度的局部特征提升了模型的判别能力,提高了跨模态行人重识别的精确度。
3.5 消融实验
为了验证本文CM-MGN以及HCAT损失的有效性,本文分别在SYSU-MM01以及RegDB上设计了一系列消融实验来评估它们对整体实验结果的影响。基线网络(BS)未提取多粒度局部特征,仅用到全局特征,并且使用的是传统的三元组损失。实验结果见表2。
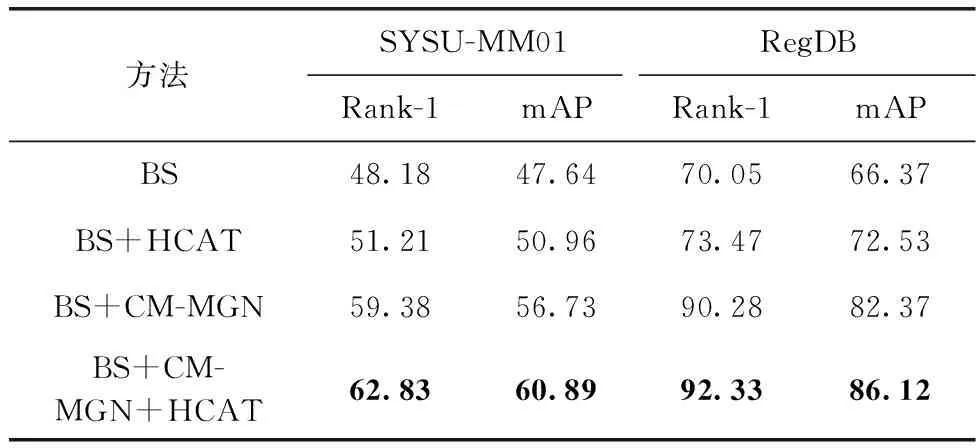
表2 不同模块组合在数据集上的实验结果
从表2实验结果可以得知,在基线网络单独引入HCAT损失后,SYSU-MM01/RegDB数据集实验评价指标Rank-1和mAP的提升分别是3.03%/3.42%和3.32%/6.16%首位命中率的提升可以发现HCAT损失有效地提升了网络的鲁棒性。在基线网络上单独引入CM-MGN后,SYSU-MM01/RegDB数据集实验评价指标Rank-1和mAP的提升分别是11.20%/20.23%和9.09%/16.00%。这表明多粒度局部特征可以对全局特征进行有效的补充。通过将二者结合,可以取得更进一步的精度提升。
HCAT损失计算的成对距离是锚点所在批样本中心与其它批样本中心的距离,与传统三元组损失(TL)相比,极大地减小了计算量。如表3所示,在一个有2pk张图像的batch中,传统三元组需要计算2pk×(2k-1) 的成对距离来进行最困难的正样本挖掘,需要计算2pk×2(p-1)k的成对距离来进行最困难的负样本挖掘。而HCAT损失只需计算2p的成对距离来进行最困难的正样本挖掘,只需计算2p×2(p-1) 的成对距离来进行最困难的负样本挖掘。

表3 不同损失需要计算的成对距离量
同时,为了更为清晰地展示特征向量在公共空间上的方向得到了有效地分离。如图4所示,图4(a)为在公共特征空间中使用基线网络提取后的特征分布;图4(b)为在公共特征空间中使用本文的方法提取后的特征分布。

图4 特征在公共空间中的分布
图中圆圈表示可见光行人特征,方块表示红外光行人特征。图4(a)中行人A可见光图像和红外光图像特征分布显示了相同行人不同模态特征分布相近,但分布较为分散,且不同行人的特征未能得到有效分离。而图4(b)中,行人A不同模态特征得到了更有效地聚合,并且在公共特征空间上,不同行人身份的特征得到了有效地分离。
另外,本文实验了多种不同的池化方法,采用了现今最流行的平均池化(GAP)、最大池化(GMP)和GeM方法,表4展示的是分别采用上述池化方法的结果,实验表明,使用GeM可以取得最佳的效果。
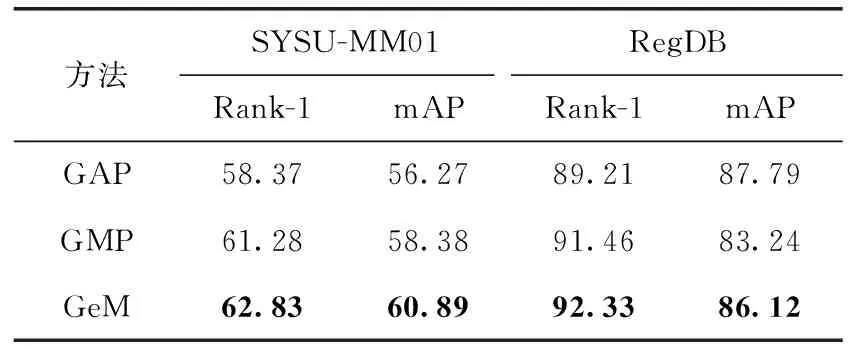
表4 不同池化方法在数据集上的实验结果
其次,由于身份验证损失采用的是相对距离对分类器进行分类,而基于欧式距离的传统三元组损失使用的是绝对距离,二者对距离的选取并不匹配。为此,本文实验了基于欧式距离和角距离的三元组损失对实验的影响,结果见表5。基于角距离的三元组损失取得了更佳的效果,这表明当身份验证损失和三元组损失关注的都是相对距离的时候,可进一步提高模型的准确率。

表5 不同度量方法在数据集上的实验结果
最后,本文设计了去除某一局部特征分支后对模型精度影响的实验,以验证粗粒度局部特征分支和细粒度局部特征分支起到互相补充的作用。结果见表6。

表6 不同分支组合在数据集上的实验结果
为了更为直观地展示所提方法的跨模态行人重识别效果,如图5所示,在SYSU-MM01数据集上进行了部分结果的可视化。从查询集中随机选取3张所需查询图像,取相对应Rank-10的结果进行可视化。图像框具有外边框表示匹配结果正确,无外边框表示匹配结果错误。可视化示例选取的是姿势变换、有遮挡样本,所提方法通过有效结合行人粗细粒度局部特征和全局特征,从而正确匹配出不同模态下同一行人身份。通过可视化结果可以发现,前列正确匹配结果的准确率较好。

图5 SYSU-MM01数据集可视化结果
4 结束语
本文提出了一种有效结合全局特征和不同粒度局部特征的跨模态行人重识别网络结构,粗细粒度下的局部特征与全局特征互为补充,避免了信息的缺失,以此来缩小跨模态行人特征的差异。同时,提出了基于角距离的异质中心三元组损失,不仅可以减小计算复杂度,还可以增强模型的鲁棒性。在RegDB和SYSU数据集上的实验结果表明,本文的方法可以显著提高跨模态行人重识别任务的性能。后续将从提高网络提取可鉴别性行人特征能力的方面来进一步提升识别的精度。
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31
红外技术(2022年11期)2022-11-25
中国典型病例大全(2022年7期)2022-04-22
山西大学学报(自然科学版)(2021年1期)2021-04-21
意林(2021年5期)2021-04-18
纺织科学研究(2021年1期)2021-03-19
五邑大学学报(自然科学版)(2019年3期)2019-09-06
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
现代工业经济和信息化(2016年8期)2016-05-17
