
基于改进YOLOv4的多目标车辆检测算法
2024-04-23 04:35殷时蓉罗天洪郑讯佳张洪杰
计算机工程与设计 2024年4期
江 屾,殷时蓉,罗天洪,郑讯佳,张洪杰
(1.重庆交通大学 机电与车辆工程学院,重庆 400074;2.重庆文理学院 智能制造工程学院,重庆 402160;3.中国汽车工程研究院股份有限公司,重庆 401122)
0 引 言
车辆检测已经成为了高级辅助驾驶系统(advanced driver assistance systems,ADAS)以及智能交通系统(intelligent transportation system,ITS)研究中的一个重点[1-3]。目前,车辆检测方法主要分为基于传统图像处理的车辆检测和基于深度学习的车辆检测两种[4-6]。基于传统图像处理的车辆检测方法的特征泛化性差、鲁棒性低,容易出现目标误检、漏检现象,同时特征提取难度较大,运算量大,无法满足人们对目标检测精确度及实时性的要求[7,8]。基于深度学习的车辆检测算法可以分为基于区域的和基于回归的车辆检测两种[9,10]。基于区域的车辆检测方法是通过生成候选区域[11],再使用神经网络进行分类处理,主要方法有R-CNN、Fast R-CNN、Faster R-CNN等[12],而基于回归的目标检测方法是通过把目标检测问题当作回归问题,直接得到物体的类别及坐标位置,主要方法有SSD[14]、YOLO系列[15,16]。但基于回归的车辆检测算法网络结构较大,模型的参数量与计算量较大,同时对于小目标车辆的漏检率较高,在实车嵌入式设备中的运行速度较慢。
基于此,本文提出一种基于改进YOLOv4模型的多目标车辆检测算法。主要采用3种改进方法:①引入深度可分离卷积代替标准卷积;②增加一层网格为104×104的输出层以及在Head部分引入Inceptionv3结构;③构建车辆数据集以及K-means++聚类算法重新确定锚框。改进的网络在保证检测速度的同时降低模型大小并提高算法对小目标车辆的检测性能。
1 YOLOv4检测算法
YOLOv4检测算法主要由主干特征提取网络CSPDarknet53、颈部特征融合网络Neck以及检测头Head这3部分组成。其中颈部网络Neck又由路径聚合网络(path aggregation network,PANet)和空间金字塔池化(spatial pyramid pooling,SPP)模块组成,其网络结构如图1所示。
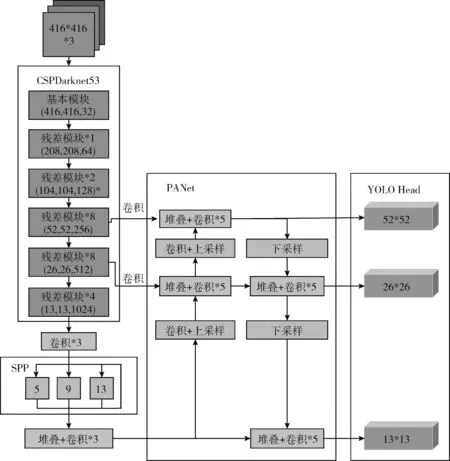
图1 YOLOv4网络框架
当输入像素为416×416×3的车辆图片经过特征提取网络CSPDarknet53后,YOLOv4将输出网格为13×13、26×26、52×52这3个尺度的特征图。在颈部特征融合网络Neck中,13×13尺寸的特征图卷积后进入SPP结构中进行池化、堆叠,得到新特征图,之后再经过卷积输入到路径聚合网络PANet中。PANet对输入的13×13的特征图进行两次卷积以及上采样,结果分别与26×26、52×52的特征图进行堆叠以及卷积,再自上而下传递定位信息,对不同网络层的信息进行融合,进一步提升检测性能[17],并输入至Head部分。在Head检测部分,对输入的特征进行大小为3×3和1×1的卷积后完成检测。
2 改进YOLOv4检测算法
YOLOv4算法虽然具有较高的精确度,但是由于模型中使用了很多标准的3×3卷积而导致参数量较多、计算量较大,不适用在算力及内存资源有限的移动端设备进行车辆检测。而对于目标车辆来说,在进行检测时需要更多的特征层信息才能够被Head部分检测出来,而在YOLOv4网络中,负责检测的Head部分仅利用3个尺度的特征且检测时只进行卷积核大小为3×3以及1×1的卷积,导致所划分出来的网格数量有限,对于网络结构中的浅层信息利用不充分。基于上述原因,本文对YOLOv4算法进行改进。
2.1 网络结构的改进
2.1.1 引入深度可分离卷积
YOLOv4模型中使用了很多标准的3×3卷积而导致参数量较大,不适用在算力及内存资源有限的设备上进行车辆检测,因此通过引入深度可分离卷积代替标准卷积,降低模型的参数量,减轻模型大小,来提高模型检测速度。
标准卷积的过程如图2所示。如当其输入的特征图为Dx×Dy×S时,该特征图分别与N个3×3的卷积核进行卷积,最后得到通道数为N的新特征图。
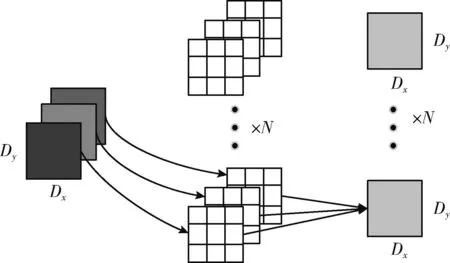
图2 标准卷积流程
深度可分离卷积的过程如图3所示。当其输入同样为Dx×Dy×S的特征图时,深度可分离卷积首先将输入的特征图分别与3个3×3的卷积核进行逐层卷积,得到通道数与输入通道数相同的特征图,再将此特征图与N个1×1的卷积核进行逐点卷积,最后同样得到通道数为N的新特征图。卷积所用参数量计算如式(1)所示
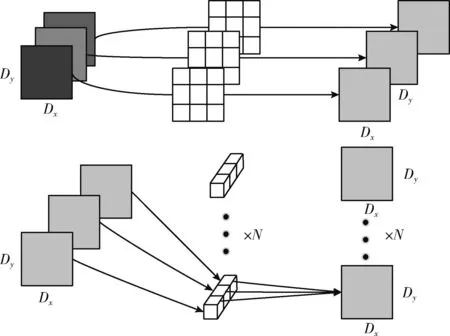
图3 深度可分离卷积流程
Pc=W×H×S×N
(1)
其中,Pc是卷积所用参数量,W×H是卷积大小,S是输入通道数,N是输出通道数。当输入为Dx×Dy×3的特征图,与N个3×3的卷积核进行卷积时,标准卷积所用参数量P1如式(2)所示
P1=3×3×S×N=9×S×N
(2)
深度可分离卷积所用参数量P2如式(3)所示
P2=P3+P4=9S+S×N
(3)
其中,P3为逐层卷积时所用参数量,P4为逐点卷积时所用参数量。
将式(2)、式(3)进行比较得到式(4)
(4)
其中,k为深度可分离卷积所用参数量与标准卷积所用参数量的比值,由于在YOLOv4中输入通道数S与输出通道数N都较大,因此,k远小于1。
由上述公式可知,使用深度可分离卷积后,在得到与标准卷积差不多效果的同时可以大大减少卷积所用的参数量,因此引入深度可分离卷积代替标准卷积。
2.1.2 增加104×104输出层
YOLOv4网络中负责检测的Head部分仅利用3个尺度的特征,导致所划分出来的网格数量有限,对于网络结构中的浅层信息利用不充分,因此在原有的3个输出层的基础上,增加一层网格为104×104的输出层。将路径聚合网络PANet网络中网格为52×52的特征层继续进行上采样得到网格为104×104的特征层,并与浅层网格为104×104的特征层进行堆叠以及卷积得到新的特征层,新的特征层一方面输入检测头Head部分进行检测,另一方面继续进行下采样并与深层特征层进行堆叠卷积操作,为检测网络提供更多的特征信息,提升模型对小目标车辆的检测性能。
2.1.3 引入Inceptionv3结构
YOLOv4网络在Head部分进行识别的过程中,输入的车辆特征越精细,目标车辆被检测到的可能性就越大,为提高模型的检测精度,一般通过增加网络的深度来实现,但增加网络深度的同时也会增加网络的参数量,降低检测速度。YOLOv4网络在Head部分只进行卷积核大小为3×3以及1×1的卷积,对输入的车辆特征利用不充分,而Inceptionv3网络具有稀疏结构,同时具有密集矩阵高性能的特点,其利用卷积核大小为1×1、3×3、5×5分别对输入进行卷积,然后将含有不同尺度特征的输出进行堆叠融合,最后利用一个卷积核大小为1×1进行整合,能够在不大量增加参数量的同时大幅度提高模型的检测性能。
为了进一步加强YOLOv4网络对小目标车辆的检测性能,将Inceptionv3结构引入到Head部分,构建Inceptionv3 Head结构,如图4所示。
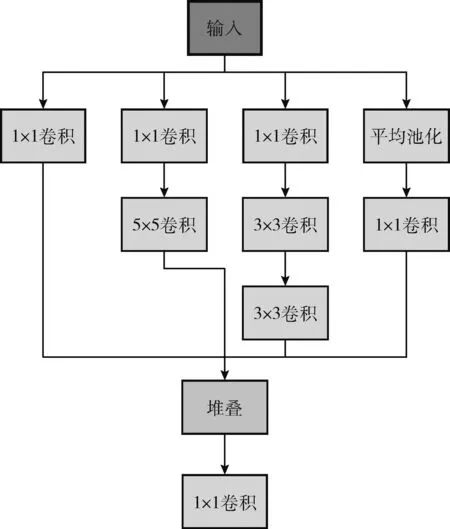
图4 Inceptionv3 Head结构
综上所述,最后改进YOLOv4算法的网络框架如图5所示。其中引入深度可分离卷积代替标准卷积部分记为改进1,在图5中将所有深度可分离卷积用卷积_DW表示,而增加网格为104×104的输出层记为改进2,Inceptionv3 Head结构记为改进3。
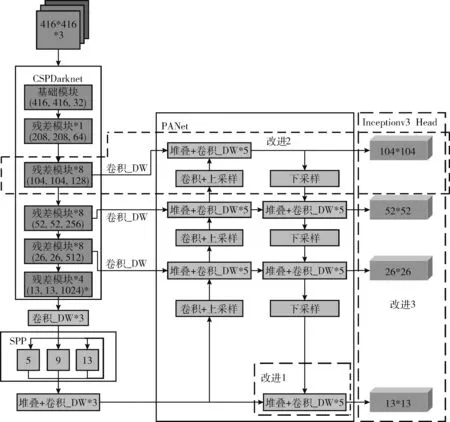
图5 改进YOLOv4网络框架
2.2 优化先验锚框
在YOLOv4算法中,利用了K-means聚类算法对锚框进行聚类,但是K-means聚类算法存在聚类效果不稳定以及聚类中心不一致的问题,因此,对锚框的聚类进行优化,采用K-means++聚类算法对数据集进行聚类分析,K-means++聚类算法能够避免由于随机初始化聚类中心而导致聚类效果的不确定性的问题,其具体步骤为:
(1)从输入的车辆数据集中随机选取一个数据样本作为聚类中心;
(2)计算数据集中每个样本数据xi(i=1,2,3,…,n) 到聚类中心的距离D(xi), 如式(5)所示
D(xi)=1-I(xi)
(5)
其中,I(xi) 为第i个样本数据到聚类中心的平均交并比。
(3)计算样本数据xi是下个聚类中心的概率P(xi), 如式(6)所示
(6)
(4)重复步骤(2)、(3),从样本数据中选出K个聚类中心;
(5)计算其它样本数据距离这K个聚类中心的平均交并比,其中平均交并比的值越大,则距离该聚类中心的距离就越小,将其中距离越小的样本数据划分为一类,共划分为K类;
(6)对这K类数据的聚类中心进行更新;
(7)重复执行步骤(5)、步骤(6),直到聚类中心不再变化,将聚类中心进行输出。
通过K-means++聚类算法进行聚类分析,其聚类分析效果如图6所示,其中三角形的点代表聚类中心,横纵坐标代表锚框的宽和高。
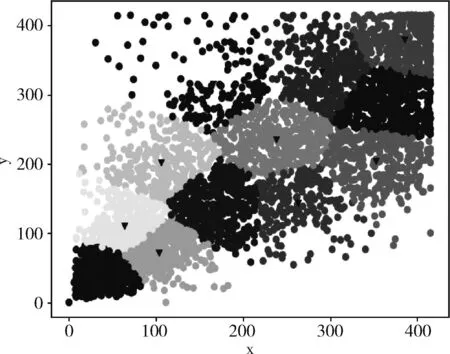
图6 聚类效果
由图6可知,K-means++聚类算法的聚类效果较好,12个聚类锚框能够较好的对数据集进行聚类,最终得到的12个锚框其对应聚类中心的宽度和高度分别为(37,35)、(59,106)、(105,74)、(105,191)、(167,316)、(185,127)、(207,212)、(282,266)、(303,355)、(316,168)、(372,258)、(389,368)。
3 实验设置
3.1 数据集构建
本文通过拍照、网络下载等手段共采集市区、乡镇、高速公路等地方的车辆图片2500张,其中包括汽车、公共汽车、卡车、摩托车等道路上常见车辆,还涵盖了包括晴天、阴天、夜晚等场景以及车辆相互遮挡等情况。本文将数据集中的车辆共标注为4个类别,其中小型乘用车标注为car;公共汽车标注为bus;摩托车标注为motorbike;卡车标注为truck。为增强改进YOLOv4算法对于光照变化、图像模糊等因素的鲁棒性,通过图像亮度调整、图像加噪、图像模糊以及Mosaic算法对数据集进行数据增强,增强后数据集图片扩充到了10 000张。最后利用LabelImg工具对数据集进行标注,共标注车辆18 876辆。
3.2 实验环境及参数介绍
改进YOLOv4算法进行训练和测试的实验环境配置见表1。

表1 实验环境配置

3.3 性能评估指标介绍
为了衡量改进YOLOv4算法的性能,采用平均精确度均值(mean average precision,mAP)以及每秒检测帧数(frames per second,FPS)作为模型的性能评价指标,mAP是一个综合评价指标,表示所有类别平均精度(ave-rage precision,AP)的均值,检测目标的AP值越高,则该类目标的检测效果越好。其中AP值由精确率(precision,P)、召回率(recall,R)确定,精确率、召回率的计算如式(7)、式(8)所示
(7)
(8)
其中,TP表示图像中正确检测出的目标车辆数量,FP表示图像中错误检测出的目标车辆数量,FN表示未被检测到的目标车辆数量。
4 实验结果及分析
4.1 实验结果
为了更直观地展示改进YOLOv4算法的训练过程,其训练时的损失曲线如图7所示。由图7可知,模型的训练损失值在前150次迭代时呈现下降趋势,而在150次迭代之后训练的损失稳定在0附近,表示模型趋于稳定,具有较好的训练效果。
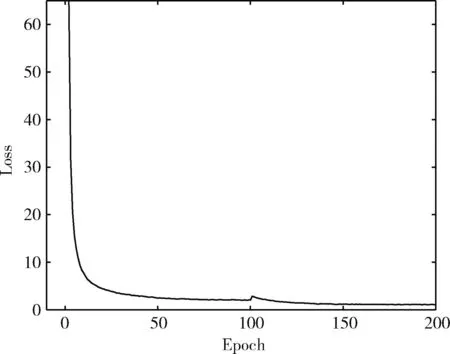
图7 训练损失曲线
改进YOLOv4算法训练后得到bus、motorcycle、car、truck的平均精度条形图如图8所示。由图8可知,改进YOLOv4算法对motorbike、truck、bus以及car这4种车辆的检测平均精度均在98%以上,分别达到了98.94%、98.55%、98.40%以及98.16%,同时通过计算可得模型的平均精度均值mAP达到了98.51%,说明该算法对于车辆的检测性能较好。
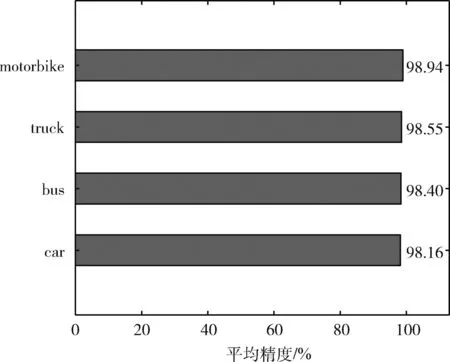
图8 平均精度条形图
4.2 对比分析
为了验证改进YOLOv4算法的车辆检测性能,将只引入深度可分离卷积的模型记为对比模型1,将只增加一层104×104输出层的模型记为对比模型2,将只引入Inceptionv3结构的模型记为对比模型3,并将这3个对比模型与改进YOLOv4模型、YOLOv4模型进行对比实验,其对比结果见表2。
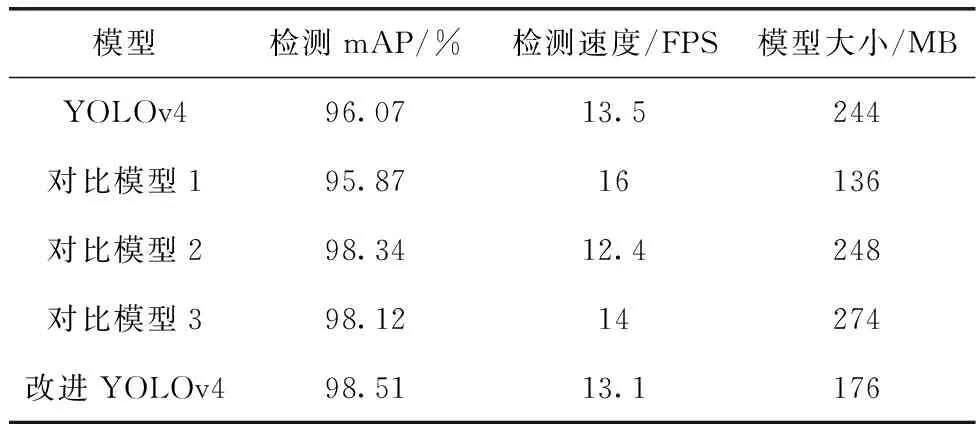
表2 改进YOLOv4与YOLOv4性能对比
由表2可知,对比模型1相比于YOLOv4模型,其检测精度基本不变,但其检测速度提高了2.5 FPS,模型大小降低了108 MB,说明引入深度可分离卷积代替标准卷积大幅度减少了模型的参数量以及计算量,提高了模型的检测速度;对比模型2相比于YOLOv4模型,其检测mAP增加了2.27%,同时模型大小也只增加了4 MB,但是其检测速度降低了1.1 FPS,说明增加YOLOv4网络检测层的数量,能够提高模型对车辆的检测能力,但是同样会降低检测速度;对比模型3相比于YOLOv4模型,其检测速度增加了0.5 FPS,同时其检测mAP增加了2.05%,但模型大小增加了30 MB,说明引入Inceptionv3结构,在保证检测精度基本不变的情况下,能够提高模型对车辆的检测能力,但也会小幅度增加模型的参数量以及计算量;而使用改进YOLOv4模型进行检测,在检测速度基本不变的情况下,其mAP增加了2.44%,模型大小也降低了68 MB,验证改进YOLOv4算法的检测性能优于YOLOv4。
为了更加直观地对改进YOLOv4与YOLOv4的检测效果进行对比,选取白天、夜间、大雾3种场景对改进YOLOv4与YOLOv4进行测试,其检测结果如图9所示。

图9 不同场景检测结果
由图9(b)可知,YOLOv4算法在白天、夜间、大雾3种场景进行车辆检测时,对于一些小目标车辆以及遮挡车辆出现了误检现象,将图片中的car检测为truck,且在夜间以及大雾场景下的车辆检测性能弱于白天的检测性能,而改进YOLOv4模型通过增加一个尺度的输出层,以及引入Inceptionv3结构,提高了算法对车辆特征的提取能力,因此在图9(c)中,对于小目标车辆以及遮挡车辆,改进YOLOv4算法都能够准确地检测出来,而且在夜间以及大雾场景下都具有较好的检测效果,进一步验证了改进YOLOv4算法的有效性以及鲁棒性。
由表3可知,改进YOLOv4模型与Faster R-CNN模型相比,虽然模型大小增加了68 MB,但是其检测速度提高了7.1 FPS,同时检测mAP提高了16.04%;改进YOLOv4模型与SSD模型相比,虽然模型大小增加了84 MB,检测速度降低了4.9 FPS,但是其检测提高了6.76%;而改进YOLOv4模型与YOLOv3模型相比,虽然检测速度降低了2.9 FPS,但是其检测mAP提高了2.95%,且模型大小降低了59 MB,综上所述,改进YOLOv4算法的车辆检测性能高于其它目标检测算法。
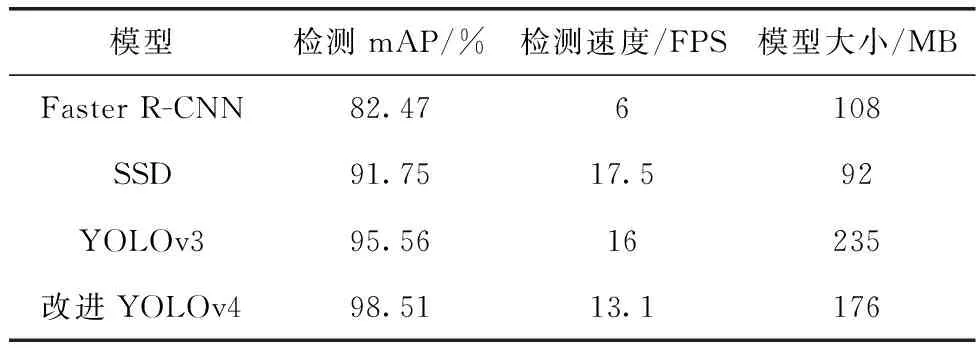
表3 不同检测算法性能对比
5 结束语
针对现有检测方法存在小目标车辆漏检率高以及夜间车辆误检率高的问题,本文提出一种基于改进YOLOv4的多目标车辆检测算法。通过引入深度可分离卷积代替标准卷积,减轻网络模型大小;增加一层输出层以及引入InceptionV3结构,提高对小目标车辆的检测性能;构建适用于多场检测的车辆数据集,并采用K-means++聚类算法重新确定锚框。通过构建的车辆数据集对改进YOLOv4算法进行测试,并与其它常见的目标检测算法进行对比分析,结果表明,改进YOLOv4算法优于其它模型,相比于改进前,在检测速度基本不变的情况下,其检测mAP增加了2.44%,且模型大小减小1/3,同时在不同场景下改进YOLOv4算法具有良好的鲁棒性。后续将在此实验的基础上继续进行更深入研究,在不降低其检测性能的同时,大幅度减轻模型大小,并且将检测的车辆类型增加。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
电子制作(2019年11期)2019-07-04
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
北京航空航天大学学报(2018年1期)2018-04-20
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
电子设计工程(2015年6期)2015-02-27
