
Towards efficient generative AI and beyond-AI computing:New trends on ISSCC 2024 machine learning accelerators
2024-04-23 13:30BohanYangJiaChenandFengbinTu
Journal of Semiconductors 2024年4期
Bohan Yang, Jia Chen, and Fengbin Tu,†
1Department of Electronic and Computer Engineering, The Hong Kong University of Science and Technology, Hong Kong, China
2AI Chip Center for Emerging Smart Systems, The Hong Kong University of Science and Technology, Hong Kong, China
3School of the Gifted Young, University of Science and Technology of China, Hefei 230026, China
Compared to the last decade when the convolution neural network (CNN) dominated the research field, machine learning (ML) algorithms have reached a pivotal moment called the generative artificial intelligence (AI) era.With the emergence of large-scale foundation models[1], such as large multimodal model (LMM) GPT-4[2]and text-to-image generative model DALL·E[3], advanced ML accelerators should address challenging scaling problems from both compute and memory.Meanwhile, with the growing demand for general intelligence on diverse application scenarios (robotics, automobiles, digital economy, manufacturing, etc.), designing integrated smart systems with intelligent perception, processing,planning, and action capabilities is a trend for future AI platforms.Besides the AI processing engine, an integrated smart system also requires domain-specific architectures (DSA) for beyond-AI computing.
Last year, Prof.Chixiao Chen’s group from Fudan University summarized trends for ML chips beyond CNN computing in the "Chip Olympiad" ISSCC 2023[4].In this survey, we take a deep look into ISSCC 2024 and observe four research trends toward efficient generative AI (ML chips for generative AI,computing-in-memory (CIM) innovation from circuits to systems) and beyond-AI computing (DSA for embedded vision processors, DSA for solver accelerators), as illustrated in Fig.1.We believe these remarkable trends will lead to more AI software and hardware innovations from academia and industry in the near future.
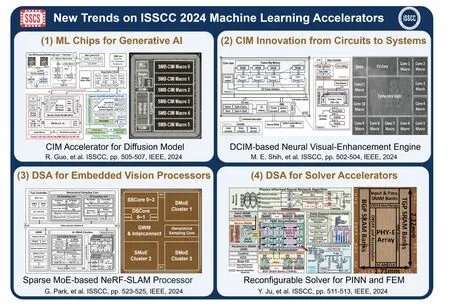
Fig.1.(Color online) New trends on ISSCC 2024 machine learning accelerators.
Trend 1: ML chips for generative AI
Since 2022, generative AI models have demonstrated remarkable capabilities in creating new data samples based on the probabilistic model learned from huge datasets.By generating high-quality and coherent text, images, or even control signals, generative AI has the potential to revolutionize any field with its creative sample generation skills.In order to power this new era of AI platforms with high computing and memory efficiency, there is a trend of ML chips for generative AI observed in different events of ISSCC 2024, including the plenary speech, main conference, and forum.
In ISSCC 2024, Dr.Jonah Alben, senior vice president of NVIDIA, delivers a plenary speech about Computing in the Era of Generative AI[5].He shows the possibility of alleviating the gap between AI algorithms and underlying computing systems by letting AI help us design chips because they can find more optimized architecture and circuits.In the main conference, AMD proposes MI300 series processors for generative AI and high-performance computing (HPC) workloads with modular chiplet package and cutting-edge HBM3 memory which has up to 192 GB capacity and 5.3 TB/s peak theoretical bandwidth[6].Guoet al.from Tsinghua University propose the first heterogenous CIM-based accelerator for image-generative diffusion models[7], which leverages pixel similarity between denoising iterations to apply mixed quantization.They propose novel methods in bit-parallel CIM by booth-8 multiplier, balanced integer/floating-point (INT/FP) processing latency by exponent processing acceleration, and support FP sparsity by in-memory redundancy search.Kimet al.from KAIST target hybrid SNN-transformer inference on edge[8].Spiking neural network (SNN) has supremacy in low power and high efficiency with low-bitwidth accumulationonly discrete operations and can be integrated with transformers.They realize an ultra-low-power on-device inference system by hybrid multiplication/accumulation units, speculative decoding, and implicit weight generation, reducing external memory access (EMA) by 74%-81%.In addition, a special forum namedEnergy-Efficient AI-Computing Systems for Large-Language Modelsshares more practical thoughts about large language model (LLM) computing systems[9].Georgia Institute of Technology, NVIDIA, Intel, Google, KAIST, Samsung,Axelera AI, and MediaTek introduce their latest research over LLM training and inference in both cloud and edge.
Trend 2: CIM innovation from circuits to systems
Computing-in-memory (CIM) technology, as a promising way to break the memory wall of traditional Von Neumann architecture, has gained significant popularity in the integrated circuit and computer architecture communities.As complex ML algorithms advance, new challenges for CIM design are widely investigated.In ISSCC 2024, we have noticed many CIM innovations from energy-efficient circuits, floating-point(FP) support, to system integration.
The lookup table (LUT)-based digital CIM (DCIM) scheme presents a promising enhancement in the compute density of traditional single-bit-input DCIM design.TSMC reports an advanced 3 nm-node DCIM macro with a parallel multiplyaccumulation (MAC) architecture based on LUTs[10].Heet al.from Tsinghua University also propose an eDRAM-LUT-based DCIM macro for compute and memory-intensive applications[11].
Hybrid CIM is another appealing direction in ISSCC 2024 to integrate the advantages of analog and digital schemes.Guoet al.from Southeast University design a lightning-like analog/digital hybrid CIM structure to capitalize on both the high energy efficiency of analog CIM (ACIM) and the robust accuracy of DCIM[12].Wanget al.from the Institute of Microelectronics, Chinese Academy of Sciences report a hybrid flash-SRAM CIM design to support on-chip plastic learning in a 14 nm FinFET process[13].
Since Tuet al.from Tsinghua University proposed the first FP CIM on ISSCC in 2022[14], the CIM community has been actively studying this new direction to meet the growing high-precision demand of both AI inference and training,especially in this generative AI era.Wanget al.from Tsinghua University propose an FP SRAM-CIM macro based on an emerging dynamic POSIT8 data format, which utilizes the low bitwidth to achieve comparable accuracy to the BF16 format[15].Wenet al.from National Tsing Hua University present an FP ReRAM-CIM macro, with a kernel-wise weight pre-alignment scheme and a rescheduled multi-bit input compression scheme to suppress the amount of truncated data by 1.96-2.47× and reduce MAC operation cycles by 4.73×[16].
Moreover, researchers are collaborating and considering challenges from a systematic perspective to help CIM integrate into real computing systems.A DCIM-based neural visual-enhancement engine (NVE) is fabricated in the 3 nm process through the collaboration of MediaTek and TSMC[17].Wanget al.from the University of Texas at Austin present Vecim, a RISC-V vector co-processor integrated with a CIMbased vector register file, using foundry SRAM cells in 65 nm CMOS for efficient high-performance computing[18].On the other hand, the fusion with RISC-V also enhances the programmability of CIM-based systems.
Trend 3: DSA for embedded vision processors
When we move towards more autonomous and collaborative AI computing, visual perception of physical environments becomes a fundamental capability for future integrated smart systems.In 2023, Apple Vision Pro[19]reinvigorated the landscape of augmented reality (AR) and virtual reality (VR), blending digital elements with our physical surroundings (a.k.a.spatial computing).Moreover, emerging embodied AI hinges on agile visual perception and LLM-embedded processing systems, enabling a deeper understanding of our world (e.g., Figure 01 robot[20]).However, these vision workloads need to directly communicate with humans and give fast feedback during runtime.A slow response may significantly hurt user experience, especially in autonomous driving tasks.Also, edge devices usually have strict constraints on device weight, leading to a layout with limited batteries.To drive these devices continuously, ultra-low power consumption is required for the underlying hardware.As more realtime and resource-constrained edge systems are supporting intelligent vision tasks, we observed a trend to design dedicated embedded vision processors.
ISSCC 2024 sheds light on many research prototypes and commercial products on this trend.Parket al.from KAIST integrate neural radiance fields (NeRF), simultaneous localization and mapping (SLAM), and sparse mixture-of-expert (SMoE) in their space-mate[21], a fast and low-power NeRF-SLAM edge accelerator, which solves irregular SMoE expert loading patterns by out-of-order MoE router, large mapping energy expense by familiar region pruning, and dual-mode sparsity by heterogeneous coarse-grained sparse core.Ryuet al., also from KAIST, design an accelerator for vanilla-NeRF-based instant 3D modeling and real-time rendering, called NeuGPU[22].They use segmented hashing tables with data tiling to reduce on-chip storage pressure and attention-based hybrid interpolation units to alleviate bank conflict costs.Also, by their exploration of similar activation characteristics in NeRF, they compressed similar values in feature vectors of adjacent samples.Noseet al.from Renesas Electronics propose a heterogenous processor for multi-task and real-time robot applications[23], combining vision recognition with planning and control based on the cooperation among a dynamically reconfigurable processor, AI accelerator, and embedded CPU.
Trend 4: DSA for solver accelerators
The optimization problem solver is another important component of integrated smart systems, which can take the role of intelligent decision-making and planning.Optimization problems across various domains, including modeling,controlling, and scheduling, are addressed by corresponding solver algorithms.However, given that the large and complex solution space should be efficiently explored in real-time systems, hardware implementations of solver algorithms face strict requirements in terms of low latency, high accuracy,and high robustness.
In ISSCC 2024, we observe an emerging trend of DSA for solver accelerators.One of the popular solvers is the Ising machine solver for combinatorial optimization problems(COP).The Ising machine’s significance lies in its ability to solve COPs with the nondeterministic polynomial-time (NP)complexity costing only polynomial overhead.Together with the hardware-friendly dataflow, Ising machine accelerators achieve significant speedup and efficiency improvement for solving COPs.Chuet al.from National Taiwan University propose an annealing-based Ising machine processor for largescale autonomous navigation with integrated mapping workflow[24].Songet al.from Peking University design an eDRAMbased continuous-time Ising machine with embedded annealing and leaked negative feedback[25].Baeet al.from the UCSB propose two chips for scalable SRAM-based Ising macro with enhanced chimera topology[26]and continuous-time latchbased Ising computer using massively parallel random-number generations and replica equalizations[27].
Apart from the Ising machine, there are also accelerators for other solver algorithms in ISSCC 2024.Shimet al.from UCSB propose VIP-SAT to solve the Boolean satisfiability (SAT)problem with a scalable digital in-memory computing dataflow and hardware-software co-design method[28].Juet al.from Northwestern University accelerate real-time partial differential equation (PDE) solver on edge devices by reconfiguring its architecture between advanced physics-informed neural network (PINN) mode for low latency and traditional finite element method (FEM) mode for high accuracy[29].
In conclusion, we discuss four exciting ML accelerator research trends in ISSCC 2024:ML chips for generative AI,CIM innovation from circuits to systems, DSA for embedded vision processors, and DSA for solver accelerators.With the goal of efficient generative AI and beyond-AI computing, we believe future ML accelerators will realize general intelligence in diverse application scenarios.
Acknowledgments
This research was supported in part by ACCESS - AI Chip Center for Emerging Smart Systems, sponsored by InnoHK funding, Hong Kong SAR, and HKUST-HKUST(GZ) 20 for 20 Cross-campus Collaborative Research Scheme C031.
 Journal of Semiconductors2024年4期
Journal of Semiconductors2024年4期
- Journal of Semiconductors的其它文章
- Chemical vapor deposition for perovskite solar cells and modules
- Highlights in recent wireless power IC research
- Recent advancements in continuously scalable conversion-ratio switched-capacitor converter
- Millimeter-wave PA design techniques in ISSCC 2024
- Light-emitting devices based on atomically thin MoSe2
- Anomalous bond lengthening in compressed magnetic doped semiconductor Ba(Zn0.95Mn0.05)2As2