
车联网中基于位置语义的差分隐私保护方法
2024-04-22 02:41:46解杉杉刘海龙赵国生
小型微型计算机系统 2024年4期
解杉杉,刘海龙,赵国生
(哈尔滨师范大学 计算机科学与信息工程学院,哈尔滨 150025)
0 引 言
伴随科技的迭代更新,万物互联已经成为时代发展趋势,由车辆、行人以及周围环境构建的车联网,极大的推动了未来智慧城市的建设.在车联网中,用户获取基于位置服务(Location Based Service,LBS)时,需要提供真实的位置信息.用户的请求内容中包含大量敏感信息,隐私数据在多方不可信设备之间的来回传输,为不法分子的恶意攻击提供了条件,对用户安全问题构成极大的威胁.因此解决车联网中车辆轨迹隐私问题,对车联网的发展和推广具有积极意义[1].
针对车联网中存在的轨迹隐私问题,众多学者提出了不同的解决思路.Jia等人[2]从用户社交的角度出发,基于用户属性、用户行为和用户关系将车联网中主流的轨迹隐私保护方法划分为4类:泛化思想是将敏感信息模糊化,其中代表方法是K-匿名,Zhang等人[3]提出了一种双K机制,通过将K个位置的查询信息发送到K不同的匿名区保护用户在进行连续位置查询时的轨迹隐私;混合区思想是将十字路口、停车场和商场等热门区域建组,用户在组内交换假名,切断轨迹之间的时空相关性,避免持续暴露自己的位置信息[4].Palanisamy等人[5]针对时空条件和位置属性对混合区构建进行优化,提出基于路网的混合区构建方法;抑制的思想是采用间断性的服务请求策略,通过在敏感地区选择不发送信息,来避免隐私泄露.Li等人[6]提出了一种两阶段隐私保护抑制算法,通过控制车辆在行驶过程中抑制部分数据的传输,来减少连续位置之间的时空相关性;位置扰动的思想是发布扰乱或加噪的虚假位置代替真实位置,该类型方法的研究核心在于虚假位置的生成方式.Dai等人[7]参照路网环境将轨迹分段,针对不同时间段生成虚假轨迹,并按照时间顺序进行连接,以降低整条轨迹面临的隐私暴露风险.
差分隐私[8,9]的提出,为轨迹隐私保护提供了新思路,符合差分隐私的位置扰动算法逐渐成为轨迹隐私保护的研究热点[10].差分隐私的主要思想是在原始查询结果中添加随机噪声,使输出内容不会因数据的某些修改而发生变化,防止攻击者通过多次查询推理或者利用背景知识进行暴力破解.按照添加噪声时间不同,可以将差分隐私分为中心化和本地化两类[11]:中心化差分隐私是先将用户数据收集到受信任的服务器中,然后再进行加噪处理;本地化差分隐私是在数据上添加噪声后再将其收集到数据中心.由于中心化差分隐私对可信单位要求高不具普适性,因此利用不可信的边缘节点探索本地化差分隐私成为当下研究热点[12].
基于本地化的差分隐私在轨迹隐私保护上可以分为2个方向:历史数据发布和实时位置发布,在车联网中道路状况多变,实时位置发布极具研究价值[13].Andrés等人[14]提出了地理不可区分性,不仅保护了用户所在位置的隐私安全,还保障了服务质量,Bordenabe等人[15]在此基础上从线性角度进行优化,提出了δ-spanner模型.Xiao等人[16]通过马尔科夫链表示位置的分布信息并结合相邻数据集概念,提出隐私保护方法(Planar Isotropic Mechanism,PIM).Cui等人[17]提出一种基于实时位置数据的隐私保护方案,通过获取周围车辆的行驶状态为用户动态生成虚假位置.
轨迹数据具有时空相关性,不仅包含时序信息,也包含位置信息.Huo等人[18]认为相较轨迹中经过的地点,用户的访问位置更需要保护.通过保护轨迹上的停留点可以降低整条轨迹的暴露概率,减少保护过程中的信息损失.为了满足位置语义安全,Wang等人[19]利用语义位置和攻击历史,提出了一种基于强化学习的差分隐私机制.Chen等人[20]针对车联网中连续时间戳泄露隐私问题,提出了一种模糊处理机制,保护车辆不会暴露精确位置.上述方法中并未考虑数据的可用性,车联网中的差分隐私保护方法仍存在以下问题:
1)隐私预算分配问题.在隐私保护上,服务质量和保护强度之间一直存在矛盾.车联网中车辆处于动态运动中,不合理的隐私预算分配,会导致服务质量和保护需求失衡,从而降低可用性,最终难以实现隐私保护.现有轨迹隐私保护方法没有考虑不同位置对隐私保护需求不同,需要针对不同敏感位置分配不同的隐私预算.
2)数据可用性低.受位置语义和地理拓扑影响,在车联网中即使单个位置满足隐私安全,基于连续位置生成的虚假轨迹也会遭受背景信息攻击.假设攻击者获取到用户请求内容是住宅到医院的行驶路线,在发布的虚假轨迹中,终点经加噪后变为医院附近的超市,与用户的实际需求冲突.攻击者根据请求内容排除不满足用户行为模式的虚假轨迹,提高暴力破解概率,使保护方法的数据可用性急剧下降.
针对以上两种问题,本文提出了基于位置语义的差分隐私(Differential Privacy Based on Semantic Location,DPSL)轨迹保护方法,根据语义位置和用户喜好设置相应的隐私保护等级,满足不同用户的定制化需求;在保障隐私保护程度的前提下,以用户的行为模式和轨迹曲线相似度为标准,对待发布的位置进行筛选,提高虚假轨迹的可用性.
1 预备知识
本文中常用符号如表1所示.

表1 常用符号Table 1 Common symbols
1.1 攻击模型
车联网又称车辆自组织网络(Vehicular Ad-hoc Network,VANET)通过车辆与路侧单元(Road Side Unit,RSU)、车辆、行人不同单位之间的通讯功能,为用户提供导航、事故预警、安全驾驶、寻找行车路线等基于位置服务[1].在车联网中,车辆为了获取实时位置服务需将其真实数据发送给RSU再由其将数据转发给LBS,数据包括用户的请求内容以及当前所在地等.在本文研究背景中,认定以上所有服务器都是不可信单位,结合图1信息,对攻击者模型做出假设:攻击者使用设备算力强,可利用背景知识暴力破解;服务器不可信,攻击者可以获取用户模糊的发布位置信息和请求内容.

图1 攻击者模型Fig.1 Attacker model
1.2 位置语义信息
在地图上包含着不同的功能区域,按照应用场景可以划分成不同的语义区,车辆轨迹通常就是由一个语义区前往另一个语义区.语义区的隐私敏感度往往受两种因素影响,分别是位置语义和兴趣点(Point of Interest,POI).其中位置语义是指位置本身包含的隐私信息,如超市附近可能泄漏的是购物习惯,在医院则是关于健康问题,明显后者更为敏感;POI则是根据用户的访问频率确定,攻击者可以通过收集用户历史轨迹,推断出用户的出行习惯获取隐私信息.因此,不同语义区对隐私保护的需求程度也会不同,本文采用Voronoi图对地图上的语义区进行划分.
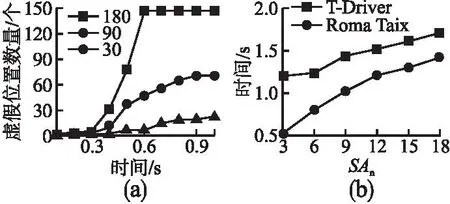
定义1.位置语义地图.Voronoi图是由一组连续多边形组成,假设X表示任意一个多边形,x是从X中的随机选取的一点,U={u1,u2,…,uη}是平面上η个点的集合,则在Voronoi图区域中任意一点,都满足∀ua,ub∈U,x∈X存在d(x,ua) 图2 位置语义地图Fig.2 Map with location semantics 定义2.语义流行度.通过计算历史轨迹中位置的重复次数,来统计车辆行驶过程中对不同位置语义的访问概率. (1) 公式(1)中qi表示位置i的语义流行度,φ×γ是历史轨迹中的位置总数,ni是位置i的访问次数.由于在轨迹数据中交叉路口出现频繁,为了降低影响,此类型位置的语义流行度不计入统计范畴. 定义3.用户行为模式.在车联网中,根据用户的服务请求可以分析出车辆的前进方向,再结合位置语义和地理拓扑便可对用户前进方向进一步精确,这种带有目的性的模糊路线,本文将其描述为用户的行为模式.如图2中的轨迹E所表示的用户行为模式可以描述为:从住宅到公司途中经过商场.符合用户行为模式的虚假轨迹,可以防止攻击者利用背景信息攻击,保障敏感位置的语义安全性. 信息熵通常用来表示系统的稳定程度,当系统越趋于稳定时熵值变小,相反系统混乱时熵值随之变大.熵的值可由公式(2)计算得出,其中p(xi)是事件发生的概率.在p(xi)取0.5时熵值最大,p(xi)的值越接近0或1时熵值越小. (2) 当数据集D和D′中有且只有一个数据不同时,可将其称为相邻数据集[8,9].当随机算法A在相邻数据集D和D′上满足公式(3)时,表示算法A符合ε差分隐私保护. Pr[A(D)=β]≤Pr[A(D′)=β]eε (3) 当eε=1时,算法A在式中的输出概率一致,表示该算法对相邻数据集没有隐私威胁.其中ε是差分隐私预算,表示隐私保护程度.ε越小,隐私保护效果越好,隐私数据越安全,相反ε值越大,表示隐私保护效果越差. 定义4.轨迹差分隐私.差分隐私的相邻数据集都是相对于传统数据库而言,然而轨迹上每个位置都会涉及到隐私安全.因此原有的差分隐私模型并无法直接应用到轨迹隐私保护中[16].当t时刻真实位置为zt,发布的虚假位置为ot时,zt的先验概率可表示为Pr(zt),由ot反推测出zt的后验概率可表示为Pr(zt|ot).将贝叶斯模型与差分隐私模型结合后,如果后验概率与先验概率的比值满足公式(4),则表示其满足轨迹差分隐私定义,其中εt表示zt的隐私预算[21]. (4) 在虚假轨迹发布过程中可能存在误差,若虚假轨迹中出现语义不合理位置,则会影响生成轨迹的可用性[22].本文通过对比轨迹之间的曲线相似度,对虚假轨迹进行筛选. 定义5.轨迹曲线相似度.假设发布的虚假位置集合和真实位置集合分别是O和Z,本文采用Hausdorff距离来衡量位置集合O和Z之间的相似度.根据公式(5)可求出两组集合之间的距离,HD(O,Z)的值越大表示曲线相似度越低. HD(O,Z)=max(hd(O,Z),hd(Z,O)) (5) 其中: hd(O,Z)=maxot∈ominzt∈z‖ot-zt‖ hd(Z,O)=maxzt∈zminot∈o‖zt-ot‖ 定义6.轨迹误差.虚假轨迹与真实轨迹之间的误差距离是评判虚假轨迹可用性的依据.长度为w的真实轨迹和虚假轨迹之间的误差平均值MTD可由公式(6)计算得出: (6) 其中dis(zt,ot)=‖zt,ot‖2是t时刻虚假位置ot和真实位置zt之间的距离.Hausdorff距离值越大时虚假轨迹与真实轨迹相似性越低,相反值越小时相似性越高.当轨迹相似性越高、轨迹误差越小时虚假轨迹的可用性越强. DPSL算法主要应用场景是解决车辆存在的轨迹隐私安全问题,防止攻击者发动针对性的背景信息攻击,对用户的隐私安全构成威胁.算法的主要思路是在满足隐私安全的基础上,选择符合用户的行为模式且与真实轨迹曲线相似度高的位置集合进行发布,从而增强虚假轨迹的可用性. 车联网中由于地理位置属性不同,其对应的敏感程度也会不一样,合理的隐私预算分配方案需要同时兼顾保护效果和服务质量.根据以上需求,提出一种基于位置语义的隐私等级实时计算方法,使用信息熵值来评判隐私等级. 根据熵值的分布规律可知,当事件概率越接近0.5时熵值越大,过高或过低的概率都会使得熵值变低.因此,根据历史轨迹得出的语义流行度qi不具普适性,如果低频访问位置恰好是敏感位置,为其分配过低的隐私等级并不合理.针对不同用户隐私需求,在qi基础上加入语义相关度si来调控敏感位置的熵值,则位置i处的隐私等级可描述为公式(7): (7) 在计算位置的隐私等级时,语义相关度的默认值设为1,用户可根据自己需求设置不同位置的语义相关度. 算法1.隐私等级计算 输入:历史轨迹集合W,位置语义相关度集合S 输出:隐私位置集合SP,隐私等级集合PL 1.initializeSP,PL; 2.whilei∈W: 3.q[i]= get_Location Frequency(i);//公式(1)得出 4. ifS[i]= 1: 5.p[i]=q[i]; 6. else: 7.p[i]=q[i]*S[i] 8. end if; 9.PL[i]=H(p[i]);//由公式(7)得出 10. ifPL[i]>0: 11.SP[i]=W[i]; 12.i++; 13.returnSP,PL. 计算得出的隐私等级并无法直接使用,只能用作分配隐私预算的参考依据.完整的虚假轨迹发布流程为:生成虚假位置、建立隐私模型、轨迹可用性优化以及发布虚假轨迹. 2.2.1 生成虚假位置 在车联网中,用户能使用专用短程通信技术(Dedicated Short Range Communications,DSRC)获取周边车辆运行信息,内容包括目标车辆的方向、速度以及经度和纬度.为了抵抗隐私攻击,收集的位置可以作为虚假位置来获取基于位置服务.用户同时向LBS发送多条请求服务,在收到所有的响应消息后,丢弃无用信息选择真实位置对应响应内容. 用户发布请求信息可表示为REQ={req1(ID,Mes,Loc1),req2(ID,Mes,Loc2),…,reqnum(ID,Mes,Locnum)},这些请求信息中除位置外其他内容均保持一致,num为发送请求信息的数量,ID表示请求编号,Mes表示信息内容,Loc表示位置.LBS收到服务请求后会在Tr时间段内进行响应,通常是1~3s[17],REQ中的位置信息可以用来构建虚假位置集合,即RL={rl1,rl2,…,rlm},其中rl和m分别对应的是REQ集合中的Loc和num.为了防止背景信息攻击,在目标车辆的选择上要符合用户的行为模式,保障用户和目标所在语义区相同.考虑到GPS和DSRC系统存在的定位误差,因此用户与目标车辆之间的距离需满足一定偏差量.本文通过公式(8)选择虚假位置,其中Vi表示目标车辆运行速度,locu表示用户当前所在地,dis(locu,loci)表示用户与目标车辆i之间的距离.本文将距离偏差量Dgap值设定为10~15米. Dgap=dis(locu,loci)-ViTr,i∈[1,num] (8) 2.2.2 差分隐私模型 通过算法1成功获取各个位置的隐私等级后,为满足不同用户的隐私需求,本文结合本地化差分隐私建立δ-隐私模型[21].由于车辆的位置实时更新,在计算车辆隐私预算时,对时间要求严格,因此模型设计不能过于复杂. 定义7.δ-隐私模型.当一个发布位置对应的差分隐私预算ε与隐私等级pl满足公式(9)时,表示其满足δ-隐私模型.给定δ值时,隐私等级pl越高,为其分配的隐私预算ε越低,对应的隐私保护程度越高,相反则保护程度越低. (9) 2.2.3 选择虚假位置 由定义4可知,通过先验概率和后验概率便能够计算出隐私预算,其中先验概率和后验概率可以使用马尔可夫链[21]获取.求出各个扰动位置的隐私预算并与δ-隐私模型中隐私预算进行对比,便能筛选出符合隐私需求的发布位置.本文通过马尔可夫链模拟车辆位置之间的关系,首先通过历史轨迹求出一个二维状态转移矩阵M,然后使用mij表示在车辆行驶过程中从i区域到j区域的转移概率. (10) 2.2.4 提高虚假轨迹可用性 通过2.2.2节得到发布位置对应的先验概率与后验概率后,可以使用公式(4)求出隐私预算.将其与预先设定的隐私预算(由δ-隐私模型和隐私等级计算得出)进行对比,便可在RL中筛选出符合差分隐私机制的待发布位置集合DPRL.为了提高虚假轨迹的可用性,还需要对发布位置进行再次优化.主要思路是将相同语义区的位置进行聚类操作,使生成的虚假轨迹符合用户的行为模式,并对比轨迹曲线相似度,以高相似度为标准选择出最佳的发布位置. 本文使用无监督聚类算法K-means,选择出满足语义安全的虚假位置[23].K-means算法是将样本按一定规律分为K组,在样本划分过程中,首先根据预设定的簇心数量分布簇心,通过比较未分配样本与不同簇心的欧氏距离,将样本分入距离较近的簇中,然后更新簇心继续对下一个样本数据进行分类.整个样本划分过程,不断重复操作,直到样本数据划分完毕.在K-means聚类算法中,K的取值是需要提前给定,本文中K的值取决于真实轨迹中所包含的语义区数量,初始的聚类簇心以位置语义Voronoi图中GLI为准. 经过上述推导,虚假轨迹的发布流程大致可描述为:第1步构建位置语义Voronoi图;第2步生成虚假位置;第3步筛选满足差分隐私的虚假位置;第4步进一步选择满足位置语义的虚假位置;第5步将满足语义和隐私的位置进行聚类操作;第6步计算虚假位置与真实位置的Hausdorff距离;第7步对距离进行排序,选择距离最小的点作为发布位置. 算法2.虚假轨迹发布算法 输入:状态转移矩阵M,地理信息GLI,隐私等级PL,隐私模型δ,t时刻用户真实位置Zt,t-1时刻用户真实位置Zt-1,t-1时刻的扰动位置dlt-1,距离偏差量Dgap. 输出:t时刻的发布位置,与真实位置的误差距离Dis. 1.initializeWr,RL,R,HD,Dis; 2.Voronoi=Delaunay(GLI); 3.RL=get_location(REQ,Dgap,Zt);//由公式(8)生成 4.ε=δ/PL;//由公式(9)生成 5.DP_RL=select_location(M,RL,Zt,ε,R); 6.a=get_location_semantic(Zt); 7.CC=select_clustering_center(GLI); 8.whilei∈DP_RL: 9.b=get_location_semantic(i); 10. ifa=b: 11. returnLS_DP_RL;//满足语义和隐私 12. whilei∈LS_DP_RL: 13.Wr=get_clustering(CC); 14.i++; 15.forj∈Wr,j++: 16.HD[j]=get_hd(dlt-1,Wr[j],Zt-1,Zt); 17.end for; 18.Sort min(HD,Wr);//将Wr按HD最小排序 19.Dis=get_distance(Wr,Zt); 20.Res=get_result(Wr,Dis); 21.returnRes. 本文采用真实的公开数据集T-Drive[24]和Roma Taxi[25]对DPSL进行仿真实验分析.T-Driver数据集包含2008年2月2日~2月8日期间,北京内10357辆出租车的GPS轨迹,数据集中总点数约为1500万,采样间隔在30s~300s之间,平均采样间隔为177s.Roma Taxi数据集包含2014年2月1日~3月2日期间,意大利罗马内大约320辆出租车的GPS轨迹,数据集中总点数约为2100万,平均采样间隔为7s.由于原数据集中使用的时间戳不一致,导致无法直接进行实验,因此需要对原数据集进行预处理,抽取车辆编号、时间、经度和纬度构建成新的数据集. 实验环境配置为3.6GHz CPU,16GB RAM,Microsoft Windows 10操作系统,实验平台为Pycharm 2020.实验内容围绕三方面展开:通过对比不同算法的隐私保护程度评测算法的隐私保护性能;分析不同的隐私预算及语义区(聚类簇头)数量SAn对轨迹误差距离的影响,评测算法的轨迹可用性;对比轨迹数量Tran对生成虚假位置的影响以及分析SAn对算法运算时间的影响,评估算法性能.实验对比算法为PIM[16],该算法采用基于差分隐私的实时轨迹保护方法. 在衡量隐私预算δ对隐私保护程度影响时,相同条件下ε′值越小表示隐私保护程度越高.本次实验参数设定为:SAn=3,Tran=90,δ=[0.2,1],步长为0.2. 从图3中可以看出,ε′随着δ增加而增加,但ε′的值总是小于δ;对比不同算法,PIM与DPSL对应的值基本一致,最大误差是在T-Driver数据集中,当δ=1时DPLM的ε′值为0.9284,PIM的ε′值为0.8975,DPLM的隐私保护性能仅比PIM低3.3%.最小误是在T-Driver数据集中,当δ=0.4时,DPLM的ε′值为0.36589而PIM的ε′值为0.3659,仅相差0.03%.这是因为DPLM侧重点在于优先考虑的轨迹的可用性,虽然相比PIM保护程度略低但是相差不多,能够满足用户的隐私安全需求;对比不同数据集,当δ相同时Roma Taxi数据集中的ε′均大于T-Driver数据集.这是因为DPSL和PIM都是基于马尔可夫的模型,受轨迹相关性影响大.Roma Taxi数据集采样间隔稳定,相较之下轨迹中的位置之间时空相关性比T-Driver数据集更强. 图3 隐私保护程度Fig.3 Degree of privacy protection 隐私性能实验结果表明,DPSL的隐私保护程度与PIM基本一致,当轨迹相关性较强时,隐私保护程度会有所下降.但是在所有应用场景中,DPSL均能满足用户的隐私需求. 在衡量隐私预算δ对生成的虚假轨迹可用性影响时,MTD数值越低,表明轨迹可用性越好.本次实验参数设定为:SAn=3,Tran=90,δ取值范围为[0.2,1],步长为0.2. 图4从整体上看,MTD随着隐私预算δ的增加而减少,且减少幅度也在变小,当δ接近1时,MTD逐渐趋于稳定.这是因为高隐私预算降低了位置扰动幅度,减少了虚假位置与真实位置之间的误差距离,使MTD变小;对比不同算法,在给定δ时,PIM算法对应的MTD均大于DPSL,这是因为DPSL算法在位置发布之前,从用户行为模式和轨迹曲线相似度两方面入手,提高虚假轨迹与真实轨迹的相似度,降低了轨迹之间的误差距离,PIM算法更注重于位置隐私的保护质量并未对轨迹做出优化,最终导致相同条件下DPSL的MTD较小,轨迹可用性高;对比不同数据集,相同隐私预算下的PIM和DPSL算法,在Roma Taxi数据集MTD值均小于T-Driver数据集,这是因为T-Driver采样间隔不稳定,且采用频率低于Roma Taxi.同时受到数据采集地的地理因素影响,最终导致在Roma Taxi数据集上MTD值整体偏小. 图4 δ对轨迹的可用性的影响Fig.4 Effect of δ on the availability of the trajectory 图5是评测SAn对轨迹可用性影响的实验结果,本次实验参数设定为:δ=0.6,Tran=90,SAn=[3,18],步长为3.从整体上看,伴随着SAn的增长,MTD也在逐渐增加,但是观察纵坐标轴可发现MTD的增加幅度并不大,增加趋势缓慢而且有个别区域并未出现增长.如在T-Driver数据集中SAn为9和12时,对应的MTD值相同.以上结果是因为随着轨迹中语义区域的数量增加使得轨迹复杂度变高,为了保障轨迹的相似度导致部分语义区无法选择最佳发布位置,从而增大位置之间的距离.此外,由于划分的语义区面积大小不一致,所以会出现SAn增加但是MTD不变的现象. 图5 语义区数量对轨迹的可用性的影响Fig.5 Effect of SAn on the availability of the trajectory 轨迹可用性评测实验表明,发布轨迹前对虚假轨迹进行曲线相似度优化,能有效减少真实轨迹与虚假轨迹之间的误差,提高轨迹的可用性;轨迹的可用性会受到轨迹数据的时空相关性影响;随着轨迹中语义区数量增加导致轨迹的复杂程度变高后,生成的虚假轨迹可用性也会有所下降. 本文从两方面对算法运算性能进行评测,分别是分析虚假位置的生成效率和对比不同聚簇数目下算法的运算时间.图6(a)是虚假位置生成效率的实验结果,在本文2.2.1节中描述的虚假位置生成方式需要参照周围车辆,为了验证该算法的运算性能,将实验内容设定为:首先选取一条轨迹作为用户当前位置,然后使用其他轨迹作为参照物来源,通过对比不同轨迹数量下生成虚假位置的速率,对虚假位置生成算法的性能进行评测.本次实验参数设定为:SAn=1,Tran分别为30、90和180,记录时间为0.1s~1s,步长0.1s,服务响应时间Tr=3s,Dgap为10~15米,数据集为T-Driver. 图6 算法性能评测Fig.6 Evaluation of algorithm performance 图6(a)中,0.1s~0.3s区间内不同轨迹数量生成的虚假位置基本一致,在0.3s~0.6s区间内,Tran=180时,虚假位置数量增加迅速;Tran=90时缓慢增加;Tran=30时,虚假位置数量增加不明显.在0.6s~1s区间内,Tran=180时,虚假位置已经不再增加;Tran=90时,虚假位置数量增加速度减缓并于0.9s处停滞不再增加;Tran=30时,虚假位置数量开始有明显的提升.3组轨迹数据中,生成的虚假位置均低于轨迹数量.实验结果表明,参照轨迹中存在噪声并非所有位置都符合虚假位置要求;提高参照轨迹数量能有效增加虚假位置生成的效率.应用到车联网使用场景中,用户当前位置的车流量会影响虚假位置的生成效率,高车流量的路段能有效提高虚假位置的生成速率. 图6(b)是评测SAn对DPSL算法运行时间影响的实验结果,实验参数设定为:δ=0.6,Tran=90,SAn=[3,18],步长为3.观察结果可知,伴随着语义区域数量的增加,运算时间也在不断增加,但是增加速率逐渐趋于平缓.对比不同数据集,T-Driver数据集与Roma Taxi数据集之间的差距基本保持一致,且发展趋势相同.运算性能实验结果表明DPSL有良好的运算性能,在轨迹复杂度变化时能有效保障算法运算时间的稳定性,适用于车联网中复杂多变的道路状况. 为了满足车联网中轨迹隐私的保护需求,本文在差分隐私基础上引入位置语义概念,提出基于位置语义的隐私等级计算方法并结合隐私预算搭建了δ-隐私模型;为了提高轨迹可用性,使用K-means对满足隐私需求的位置基于位置语义进行聚类,并使用Hausdorff距离衡量轨迹相似度,筛选出最佳发布位置.仿真实验结果表明,本文方法在保障轨迹隐私需求的前提下,有效提高了生成虚假轨迹的可用性.在实际场景中,车辆的停留点、方向以及周边车辆和环境都可能影响隐私安全.因此,今后的研究重点将围绕车辆的运行状态展开,进一步完善车联网的轨迹隐私保护模型.
1.3 信息熵
1.4 差分隐私
1.5 虚假轨迹可用性
2 DPSL轨迹隐私保护算法
2.1 隐私等级计算
2.2 虚假轨迹发布
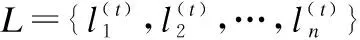
3 仿真分析
3.1 隐私性能评测

3.2 轨迹可用性评测

3.3 运算性能评测
4 结 论
猜你喜欢
包装工程(2023年24期)2023-12-27 09:18:26
新世纪智能(数学备考)(2021年5期)2021-07-28 06:19:46
海洋信息技术与应用(2021年1期)2021-06-11 01:20:34
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
现代装饰(2018年5期)2018-05-26 09:09:39
中国三峡(2017年2期)2017-06-09 08:15:29
河南科技(2015年7期)2015-03-11 16:23:13
信息安全研究(2015年3期)2015-02-28 20:17:57
太空探索(2014年1期)2014-07-10 13:41:50
