
基于深度特征聚类的商标检索方法
2024-04-22 15:42:40李东升杜春梅
科学与信息化 2024年7期
李东升 杜春梅
河北建筑工程学院 河北 张家口 075000
引言
近年来,我国商标申请量、注册量连续实现较快速度增长。新商标必须具有足够的独特性以避免与已注册的商标混淆或冲突[1]。商标申请人在进行商标注册前会通过专业的商标代理机构进行商标检索,国家商标局同意商标注册之前会排查该商标是否与已注册商标存在过高的相似度,若相似则无法注册[2]。在图像检索中,李振东[3]采用K-means聚类算法对提取的深度特征进行聚类,使得对应的人脸图像集划分为不同的簇,然后在相应的簇中进行人脸图像特征相似度匹配执行检索任务,有效地提高了人脸图像检索速度,但是这种方法应用在巨量的数据集上,就会突显出其检索速度的不稳定性。
1 相关理论
1.1 深度特征提取网络
在图像检索领域主要有AlexNet、VGG、GoogleNet、ResNet4种模型作为特征提取的网络。Alexnet模型由5个卷积层,3个池化层和3个全连接层所构成。Alexnet模型在卷积后加入了Relu激活函数,解决了Sigmoid的梯度消失问题,使用dropout选择性地忽略训练中的单个神经元,避免模型的过拟合。VGGNet通过反复堆叠3×3的小型卷积核得出结论,卷积神经网络的深度增加和小卷积核的使用对网络的最终分类识别效果有很大的作用。VGGNet采用多尺度的方式进行训练,对训练图像进行裁剪和缩放,从而提高了检索任务的特征不变性。
GoogleNet是一个更深、更宽,具有22层但参数量却更少的网络,这使其具有更高的学习效率。GoogleNet能够重复使用多个Inception模块,每个Inception模块由4个分支组成,使用5×5、3×3、1×1三种卷积核。每个分支的输出在空间上连接起来,组成一个Inception模块的最终输出。ResNet使某些层跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系,使其随着网络的不断加深,效果变得更好。
1.2 聚类
k-means聚类算法是一种迭代求解的聚类分析算法,它的核心是对需要聚类分析的数据集随机选出k个数据点作为初始值[4],这些初始值作为分簇的中心点,其他样本对象根据离中心点的最近距离进行划分,和最近的中心点划分为一个簇即实现分组,在此聚类算法的基础上进行改进,使中心点中的数据平均化,以优化商标检索速度的目的。若待分类数据集为D并结合检索速度v的要求,确定k为聚类中心点个数,根据数据集D中的数据量与k值确定双阈值,本文采用的k-means均匀聚类,算法流程如下:
(4)重复步骤二,步骤三,若计算得到的中心点与原中心点一致,则本次二分类结束。
(7)在数据集D中计算每个待分类数据点 , … 与所有中心点的距离,得出所有待分类数据点所属中心点,并返回其中心点索引保存在对应分类数据点的相应位置。
(9)得到中心点。
2 实验与分析
2.1 商标数据集
数据集采用Logo-2K+,该数据集是从谷歌(www.Google.com)和百度(www.Baidu.com)搜索引擎抓取的。“Logo-2K+”由2341个类别和167140个图像组成。它们属于10个根类别和2341个子类。
2.2 商标图像深度特征提取
本文使用的是Googlenet深度卷积神经网络作为特征提取网络,因为Googlenet在控制了计算量和参数量的同时,还具有特别好的分类性能,在Imagenet数据集上能够达到94%以上的准确率,这得益于Googlenet网络中的inception结构以及两个辅助分类器。inception结构如图1所示,Inception结构能够保留输入信号中的更多特征信息,GoogleNet重复使用多个Inception模块,每个Inception模块由4个分支组成,使用5×5、3×3、1×1 3种卷积核。每个分支的输出在空间上连接起来,组成一个Inception模块的最终输出,使用1、3和5大小的卷积核,有利于限制参数的规模和模型的复杂性[5]。Googlenet中的辅助器主要是防止网络深度学习中出现的梯度消失结果。Googlenet的参数量以及计算量得以减少,则是得益于大量使用卷积核大小为1的滤波器进行卷积,通过1×1的滤波器进行卷积来减低特征矩阵的通道数,从而减少了网络参数量和计算量,避免了因为大量参数量而产生过拟合的可能,已经证明,更深层次的架构有利于学习更高层次的抽象特性,以减少语义差距。
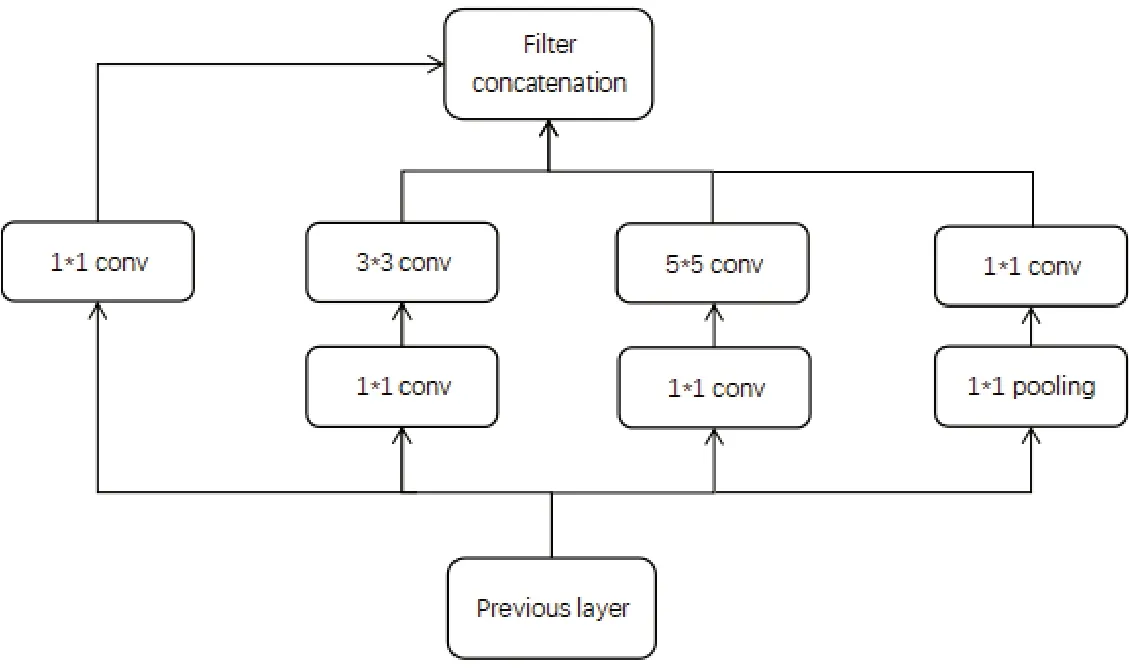
图1 inception结构
2.3 商标图像深度特征聚类
聚类使得到中心点平均化以达到最佳检索性能的目的。按照1.2小节当中提到的方法,用数据集中16.7w商标数据提取出特征向量,根据数据量进行均匀聚1000类的任务,设定=130,=200,按照1.2中k-means均匀聚类算法流程。设每次聚类的k值为固定值2,若在某次聚类后得到的某个类数据M<,视为无效中心点,删除该中心点,若M>,则聚类得到的数据,再次进行聚类。若<=M<=,则视为有效数据,保存中心点。在NVIDIA RTX 3090上跑了一天,最终得到811个中心点,接下来用16.7w商标数据提取出的特征向量计算所属中心点,并对中心点的所属数据量进行从大到小的排序,最终结果中心点对应的数据量在200以上的有5个,最大数据量为245,这5个中心点所属数据分别执行1.2小节k-means均匀聚类算法中的步骤2到步骤7,最后得到了821个均匀分布的中心点。
2.4 相似度计算
利用余弦距离来计算特征向量之间的相似度,通过计算两个相同维度的向量之间的夹角余弦值来衡量它们之间的相似度。待检索商标特征先与中心点进行相似度对比,以缩小检索相似商标的范围,然后待检索商标特征在相似的中心点内进行检索,利用argmax()进行排序,得到相似度排序,向量之间夹角越小则余弦值越大代表两个向量越相似,X和Y表示两个n维的特征向量,计算特征向量 X 与 Y 的余弦距离公式如下:
2.5 实验结果
得到均匀分布的聚类中心点后,用多进程计算每个商标特征向量对应的中心点(特征向量与那个中心点的余弦距离最大),返回中心点所对应的索引并保存,这样就可以得到16.7w数据对应的中心点索引,待检索商标经过特征提取之后,先和中心点用余弦距离进行相似度对比,通过argmax()函数对结果进行排序,取相似度最高的中心点,然后待检索商标与该中心点对应的所有数据进行相似度对比,argmax()排序得到最终结果,在数据集中取商标进行检索,检索结果如图2所示,上边为检索商标,下边为商标库中与检索商标最相似的10张商标。

图2 检索结果
3 结束语
本文先通过深度卷积神经网络提取商标的特征,然后对特征库使用改进后的聚类算法进行聚类,从而得到了均匀分布的中心点,使商标数据集中的数据划分到不同的中心点当中且每个中心点的数据量较为平均,待检索商标先通过深度卷积神经网络提取特征,特征向量先与中心点进行相似度对比,然后与相似中心点中的数据进行相似度对比并排序,得到检索结果,大幅缩小了检索范围,从而提高检索性能,本文在传统的商标检索中对聚类进行了改进,改善了传统聚类算法应用在商标检索中的不稳定性,使人们在面对庞大的数据量时,能够达到较好的检索性能。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
北京大学学报(自然科学版)(2021年3期)2021-07-16 07:13:40
东北师大学报(自然科学版)(2021年1期)2021-03-27 01:22:14
电脑爱好者(2020年19期)2020-10-20 06:02:06
电脑报(2020年12期)2020-06-30 19:56:42
电子制作(2019年13期)2020-01-14 03:15:18
电脑报(2019年4期)2019-09-10 07:22:44
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
