
一种基于LDA模型的新兴主题识别与探测方法
2024-04-21 12:08:50吴东雪沈桂兰
河南师范大学学报(自然科学版) 2024年2期
吴东雪 沈桂兰


摘 要:新兴主题识别是科技研究领域识别新兴技术的重要方式,高效精准地识别新兴主题是早期辨识新兴技术研究方向的前提.提出一种基于LDA模型的新兴主题识别与趋势预测方法,通过LDA模型提取科技文献中的研究主题,构建主题强度、主题新颖度和复合主题关注度的指标体系识别新兴主题,采用Prophet模型预测新兴主题的主题强度,探测未来发展趋势.以智慧农业领域最近14年的科研文献为数据集,对提出的识别和探测方法进行验证,识别出了5个新兴主题,并预测了未来3年的发展趋势,同时验证所提方法的有效性.
关键词:主题识别;最优主题数;新兴主题识别指标;Prophet模型
中图分类号:TP399文献标志码:A文章编号:1000-2367(2024)02-0072-09
随着新一轮科技革命到来,产业急剧变革,全球技术竞争日趋激烈.新形势下,如何选择国家的科技发展战略,确定重点发展领域是各国政府面临的重要问题.掌握科学前沿理论和技术发展动态,可以在有限的资源支持下高效地推动科学技术进步.新兴主题是新出现的一组由多个关键词或词组表示的主题领域簇,代表着科学研究中极具发展潜力的研究方向或趋势[1].识别新兴主题是对科学前沿、技术前沿以经济和社会发展导向进行战略性探索的有效手段,新兴主题识别和预测方法的研究已经成为研究者关注的热点.
早期主要是通过科技文献的引文网络分析或关键词分析进行新兴主题识别[2-5],但引文网络分析时间滞后、缺少动态更新,关键词分析主题相对片面、缺少语义解读,识别出来的新兴主题往往准确性不高、可解释性不强,且无法预测新兴主题未来发展趋势.近年来,以潜在狄利克雷分布模型(latent dirichlet allocation,LDA)为代表的主题建模及其改进方法[6-8],以概率形式从科技文献中抽取大量主题信息,能高效快捷地挖掘科学领域中的主题方向而广受关注.周云泽等[9]对自动驾驶领域的专利和论文文献进行LDA主题建模识别该领域的新兴技术,吴胜男等[10]提出了Co-LDA主题模型和链路预测相结合的方法预测核心主题关联机会,张振青等[11]采用PhraseLDA模型对领域学科交叉主题进行识别,ALATTAR等[12]将LDA模型看作一个过滤器,用按时间戳识别删除旧主题,保留新主题的方法识别新兴主题.但是上述研究忽略了LDA模型中最优主题数的设定,识别出主题往往存在较高的同质性,而且这些研究也未对识别出的新兴主题的未来发展趋势进行预测.另外,进行新兴主题识别时,还应该关注新兴主题的关键特征.新兴主题具有概念新、影响力大、增长快、成长潜力大的特点,PORTER 等[13]根据这些特点构建了新兴主题指标识别体系,但是缺乏针对LDA主题概率的指标量化表示.
为提升新兴主题的识别与趋势分析的准确性与有效性,本文提出一种基于LDA主题模型的新兴主题识别与探测的方法,主要贡献包括:(1)改进模型评估方法,优化LDA模型主题抽取结果;(2)构建新兴主题识别指标体系,设计适用于主题概率模型的指标量化计算方法;(3)在指标量化基础上,使用先知神经网络Prophet模型对新兴主题未来三年的趋势发展预测;以智慧农业领域科技文献为数据集进行仿真实验,验证了方法识别和预测的有效性和准确性.
1 基于LDA模型的主题抽取
LDA是词-主题-文档三层结构的经典概率生成模型[14],以“主题”为语义中介,将词与文档连接起来,认为每一个文档集都是一组潜在主题的集合,其原理如图1所示.LDA通过引入α、β两个参数作为Dirichlet分布的超参数,分别生成主题的多项分布Θ和词的多项分布φ,对于文档集M中的一篇有N个词的文档m,主题分布Θ中的主题Z以某个概率选定了这个文档,同时从主题Z对应的词分布φ中选中某个概率词W,过程重复N次,就产生了文档m.在这个过程中,通过文档-主题概率分布和主题-词概率分布实现词-主题-文档的语义结构关联.
LDA模型的概率主题分布可以抽取科技文献中潜在主题信息,其中最优主题数目的确定对主题抽取至关重要.困惑度是经典的最优主题数目判定指标,该指标关注模型泛化能力,实际应用中存在提取主题数量较大,主题间相似度高的问题.为平衡模型的泛化能力以及主题抽取效果,提出了Perplexity-Var(P-V)指标,在进行困惑度计算的基础上辅以主题方差、复合困惑度和主题相似度来确定最优主题数[15],計算公式如下:
其中,D是文本数据集,P(D)是数据集的困惑度,T是数据集中LDA抽取的主题,Var(T)是数据集的主题方差.P越小,LDA的泛化能力越好.主题方差越大,LDA主题抽取的效果越好,同时P-V指标就越小.综上,当P-V指标最小时,其主题数对应的LDA主题模型识别主题的效果最优.
困惑度P(D)的基本思想是给测试集赋予较高概率值的语言模型泛化效果更好,困惑度越小,模型对新文本具有越好的预测作用,计算公式如下:
其中,语料库中的数据集D中共M篇文档,wd表示文档d中的词,p(wd)即文档中词wd产生的概率,Nd表示每篇文档d中的单词数量.
主题方差Var(T)是各个主题分别与其均值之间的距离平方和的平均数,衡量了主题之间的稳定性和差异性,当Var(T)越大时,主题间的差异性越大,主题区分度越好,计算公式如下:
其中,T表示LDA抽取的主题,为主题-词概率分布均值,DJS表示JS散度(Jensen-Shannon divergence),度量各个主题和其均值之间的偏离程度,K表示主题数目.
2 新兴主题识别指标体系
新兴主题通常是研究内容上具有较高的新颖性,具有一定的话题规模,并能够吸引新的学者进行研究的主题.构建了包含主题强度、主题新颖度、复合主题关注度的新兴主题识别指标体系.
2.1 识别指标
2.1.1 主题强度
主题强度是一种抽象的属性,可以用不同的量化计算方法,如按照包含主题的论文数量计算以及根据发文量和被引量计算等[16],因LDA模型提取的主题是文档主题概率形式,直接采用主题文档数量方式量化计算存在偏差,这里定义主题强度(Ts)为该主题在某时间节点内所有的文档主题概率的总和.
其中,pi表示主题s内的第i个文档的文档主题概率.
2.1.2 主题新颖度
主题新颖度一般根据主题的年份信息确定,某个主题的年份越新,其新颖性越高.选取各个主题下概率大于等于10%的文档作为主题的支持文档[17],用主题内所包含文档的平均年份作为主题新颖度Ns的度量,即:
其中,n表示主题s内文献数量;yi表示第i篇论文的发表年份.
2.1.3 复合主题关注度
主题关注度是测度主题对研究者的吸引力大小,可以用相关文献指数[18]表示,即主题相关的文献数量与对应年份下平均主题相关文献数量的比值来表示,计算公式如下:
其中,ds代表主题s的相关文献数量;Mt=ctn代表时间窗口t下平均主题相关文本量,ct为t年的相关文本总数,n为t年的主题数.
主题关注度也可以表现为作者关注指数,用主题相关的作者数量与对应年份下平均主题相关作者数量的比值来表示,计算公式如下:
其中,nts表示时间窗口t下某个主题s所有作者数量和,Nt表示时间窗口t内平均主题相关作者数量,Nt=Atn,At为t年的相关作者总数量,n为t年的主题数.
复合主题关注度T′s综合考虑指标的变异性和冲突性,将相关文献指数和作者关注数进行复合加權,计算公式如下:
其中,权重α和权重β由CRITIC客观赋权法[19]确定.
2.2 识别主题类型判定
根据主题强度和主题新颖度的值,将识别出主题进行类型划分,包括新兴主题、潜在新兴主题、非成长型主题和热门主题4类,以主题强度和主题新颖度值的均值为原点,绘制出主题类型的判定坐标系,如图2所示.
在判定坐标系中,第一象限是新兴主题,具有一定的话题规模,研究内容具有较高的新颖性;第二象限的是潜在新兴主题,主题强度不高,但具备一定的主题新颖度,有吸引研究者进入研究,具有成为新兴主题的潜力;第三象限是非成长型主题,具有一定的成长停滞性,其话题规模和新颖度都较小,吸引研究者关注的潜力也相对较小;第四象限的是热门主题,具有较大的话题规模,但主题新颖度相对较低,对研究者的吸引度相对低.
3 新兴主题的识别与预测
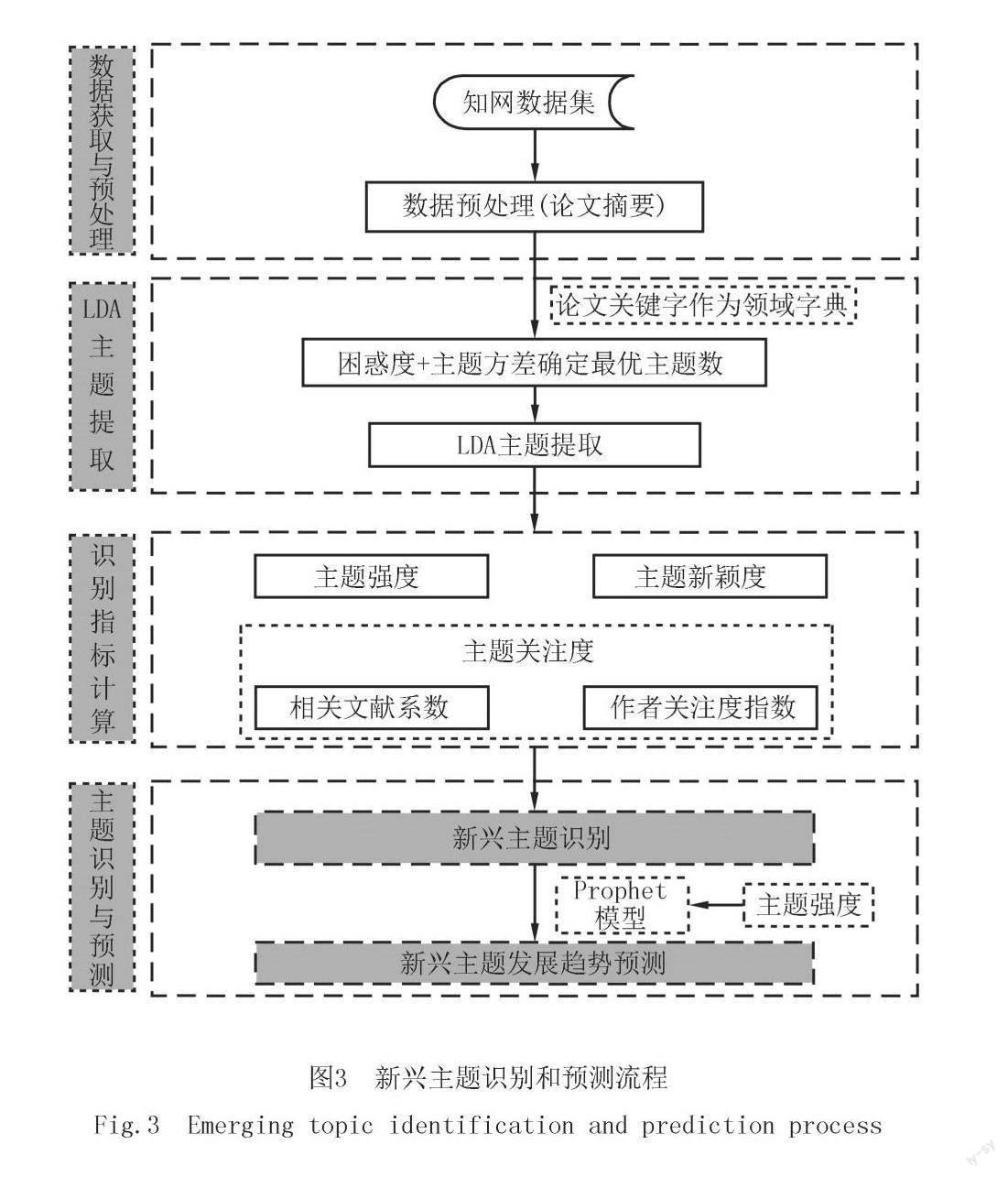
新兴主题识别与预测的方法流程如图3所示,主要包括数据获取和预处理、基于LDA主题模型的主题提取、识别指标计算、新兴主题识别与预测.
3.1 新兴主题的识别
新兴主题识别的具体的步骤如下:
步骤1 准备领域科技文献数据集.
步骤2构建领域词典,提取论文摘要进行分词、去停用词操作,并构建文档数据集的词频—逆文档频率(term frequency-inverse document frequency,TF-IDF)模型,计算每篇文档的TF-IDF向量值.
步骤3 训练不同主题数的LDA主题模型,并计算模型对应的Perplexity-Var指标,选取令Perplexity-Var值最低的主题数为最优主题数.
步骤4 根据最优主题数进行LDA主题建模,提取领域内研究主题.利用主题词概率分布确定主题高概率主题词进行主题内容解读.
步骤5 利用文档主题概率分布确定主题所属文档,计算各个主题的主题强度和主题新颖度及所有主题强度和主题新颖度的均值.
步骤6 以主题的强度和新颖度的均值为坐标轴的原点,绘制主题类型判定坐标系.
步骤7 根据主题强度值和主题新颖度值将每个主题划分到对应的象限.位于第一象限的新兴主题和第二象限的潜在新兴主题是要关注的主题.
步骤8 计算复合关注度的权重α和β,确定复合关注度的计算方法.
步骤9 计算所有主题关注度均值,对步骤7中筛选出的主题进行二次筛选,筛选出大于主题关注度均值的主题,作为最终新兴主题的识别结果.
3.2 新兴主题的预测
Prophet先知神经网络[20]是目前时间序列分析[21]的热门工具,与ARIMA[22]模型、LSTM[23]神经网络模型等主流的时间序列模型相比,Prophet 模型具有自动性好、可解释性强、可扩展性强、训练速度快等优点.作为一个加法模型,其假设观测变量的规律满足如下公式:
y(t)=g(t)+s(t)+h(t)+εt, (9)
其中,g(t)为非周期性的增长的趋势项,s(t)是周期因素项,h(t)为节假日因素项,εt是满足正态分布的误差项.
模型训练中趋势项g(t)选择分段线性进行趋势预测,不考虑周期因素和节假日因素的影响,分段线性函数满足以下公式:
g(t)=(k+a(t)Tδ)t+(m+a(t)Tγ), (10)
其中k+a(t)Tδ表示增长速率,m+a(t)Tγ表示线性的偏移.考虑到时间序列中可能的突变点,引入了指示函数a(t),δ和γ表示突变点对趋势函数的斜率和偏移量影响的大小,参数T控制趋势灵活度.
具体的预测步骤如下:
步骤1 以年为时间片计算新兴主题的年度主题强度,组成主题强度序列;
步骤2 将主题强度序列划分已知序列和待预测序列;
步骤3 设置Prophet模型参数,构建预测模型,利用R-squared和平均绝对误差指标分别验证模型拟合度和预测准确率;
步骤4 设定模型准确率阈值,如果模型准确率大于阈值,则使用该模型对未来3年的主题强度进行迭代预测;
步骤5 如果模型准确率小于阈值,则重新训练模型.
4 新兴主题识别与探测的应用研究
将提出的方法应用到智慧农业技术领域,识别该领域的新兴主题并预测未来的发展趋势.
4.1 数据集及预处理操作
在中国知网中以“智慧农业”“农业物联网”为主题检索词进行智慧农业技术领域的期刊文献检索,时间跨度为2009-2022年,获得1 710篇科技文献.
预处理操作主要针对文献摘要进行的文本预处理,首先使用正则表达式剔除掉论文摘要中的非中文字符,包括特殊符号、数字、标点、英文字符等,然后在以论文的关键词作为领域字典的基础上,进行分词、去停用词处理,最后采用TF-IDF模型对语料进行向量化处理.
4.2 智慧农业领域研究主题提取
对预处理后的文献语料首先进行LDA主题建模,为使抽取的主题和主题词更具代表性,设置主题分布的先验参数α=0.01,词分布的先验参数η=0.01,然后利用Perplexity-Var的计算选取最优主题数.计算了主题数量为1到20之间的Perplexity-Var指标值,结果如图4所示,可以看出,当主题数量为9时,Perplexity-Var值最小,模型泛化能力与主题区分度相对较好.
每个主题提取了前20个关键词,对应的主题词表如表1所示.
4.3 新興主题的识别与发展趋势预测
4.3.1 主题强度和新颖度的计算
对利用LDA提取的9个主题分别计算出其主题强度的值和主题新颖度的值,主题强度的均值为0.11,大于均值的有主题3、主题4、主题5、主题6、主题8;说明智慧农业领域的技术较新,各个主题新颖度普遍较高,但略有差异,大于均值的有主题1、主题4、主题5、主题7和主题8.
以主题强度和新颖度的均值为原点,绘制主题分布坐标系,对每个主题进行分类划分,结果如图5所示.主题4、主题5、主题8的位于第一象限,为新兴主题;主题1和主题7位于第二象限,为潜在新兴主题;位于第三象限的主题2和主题9是非成长型主题;位于第四象限的主题3和主题6为热门主题.
4.3.2 复合主题关注度计算
在确定新兴主题和潜在新兴主题后,计算复合主题关注度对新兴主题进行二次筛选,主题相关文献指数和主题作者关注指数随年份变化的结果如图6和图7所示.利用CRITIC客观赋权法计算得到的相关文献指数和作者关注指数的权重,如表2所示.复合的主题关注度计算结果如表3所示,平均主题关注度约为9.16,高于均值的有主题3~6以及主题8(黑色字体).
4.3.3 新兴主题的识别
通过包括主题强度、主题新颖度和复合主题关注度在内的新兴主题识别指标体系的筛选,最终确定主题4(物联网技术在智慧农业的探索应用)、主题5(智慧农业下的数据来源以及利用)、主题8(示范基地的带动以及由单点到面的推广)为新兴主题;主题1(吸引企业助力发展智慧农业)和主题7(智能装备以及服务体系优化)为潜在新兴主题.
从主题识别内容上看,涵盖了在智慧农业的试点示范阶段,研究者对于智慧农业在综合运用移动互联网、物联网、智能控制、无线传感等现代信息技术上的探索以及如何有效推广和助力智慧农业发展上的探索.
4.3.4 新兴主题发展趋势预测
利用Prophet模型进行2022年至2024年的3年发展趋势预测.
为了验证模型性能,先进行样本内预测,利用训练集中2020年之前的主题强度序列进行2021年的预测.模型训练中的趋势增长模型选择分段线性函数进行预测,即设置参数growth='linear',不考虑周期因素和节假日因素的影响,设置weekly_seasonality = False,daily_seasonality = False,其他参数使用模型默认.
模型的拟合度优劣采用R方(R-squared)进行衡量,R方越接近于1,模型拟合度越好.选择平均绝对误差(mean absolute error,MAE)进行预测偏差评估,MAE值越小,预测效果越好.出于对主题强度发展偏差的考量,设定MAE值小于10时,模型预测有效.
2021年的主题预测结果如表4所示,其中R方为0.995,说明模型拟合效果优良;MAE值为6.97,在设定的阈值范围内;主题4、主题1和主题7的实际值均在预测区间内,主题5和主题8在预测区间外,但根据其主题内容判断数据融合应用以及在政策推动下,主题5和主题8近期获得的关注度较大,有超出模型预测区间的可能.总体来看,Prophet模型可以进行2022-2024年的趋势预测.
将预测区间设为2022-2024,预测结果如表5所示,可以看出5个主题在未来3年的主题强度区间值均呈逐渐上升趋势,表明这些主题会持续获得领域内研究者的关注和探究.
5 结 语
围绕新兴主题识别和探测,首先对新兴主题识别的研究以及主要方法进行了梳理,然后基于LDA主题模型,利用Perplexity-Var指标确定的最优主题数进行主题抽取,最后通过新兴主题识别指标体系的筛选识别出新兴主题,并利用Prophet模型对新兴主题未来发展趋势进行预测.以智慧农业领域的文献数据为实验数据集,经过实验验证,最终确定了3个新兴主题和2个潜在新兴主题,反映了当前智慧农业领域的研究发展前沿及未来3年的发展趋势.
构建的包含主题抽取最优数目确定、识别指标体系优化以及利用Prophet模型进行趋势分析的新兴主题的识别与趋势预测方法是对新兴主题识别和预测进行的有益探索,实验结果较好地反映了智慧农业领域内的新兴主题及发展趋势,表明识别和预测方法的有效性,能够达到优化和探索新兴主题识别和趋势分析的目的.
当前研究尚存在一定的不足.首先,限于篇幅和研究精力,数据源只选择了科技论文文献,未考虑专利文献数据、基金项目数据、网评文本数据等;新兴指标测量上只考虑了文献本身的发表年份、作者、关键词、摘要等文本内容特征,忽略了文献之间的引文特征.在以后的研究中,数据源可采用论文、专利等多源数据从不同角度反映领域主题的发展情况;指标识别体系上可从文本内容特征、结构特征、引用特征等多角度进行指标构建以更好、更全面、更客观地进行新兴主题识别;此外,在新兴主题的趋势发展分析上也可尝试用不同的参数设置进行趋势优化探索.
参 考 文 献
[1]WANG Q.A bibliometric model for identifying emerging research topics[J].Journal of the Association for Information Science and Technology,2018,69(2):290-304.
[2]LI H Y,CUI L,CUI M,et al.Active research fields of acupuncture research:a document co-citation clustering analysis of acupuncture literature[J].Alternative Therapies in Health and Medicine,2010,16(6):38-45.
[3]SMALL H,BOYACK K W,KLAVANS R.Identifying emerging topics in science and technology[J].Research Policy,2014,43(8):1450-1467.
[4]陈新亚,李艳.近20年来我国教育技术研究的热点与前沿:基于7种CSSCI期刊的文献计量分析[J].现代教育技术,2020,30(12):12-19.
CHEN X Y,LI Y.The hotspots and frontiers of Chinese educational technology research in the lastest 20 years:based on the bibliometric analysis of 7 CSSCI journals[J].Modern Educational Technology,2020,30(12):12-19.
[5]曹琨,吴新年,靳军宝等.基于共词和Node2Vec表示学习的新兴技术识别方法[J/OL].[2023-10-10].http://kns.cnki.net/kcms/detail/10.1478.G2.20221125.1824.012.html.
[6]VAYANSKY I,KUMAR S A P.A review of topic modeling methods[J].Information Systems,2020,94:101582.
[7]嚴宇宇,陶煜波,林海.基于层次狄利克雷过程的交互式主题建模[J].软件学报,2016,27(5):1114-1126.
YAN Y Y,TAO Y B,LIN H.Interactive topic modeling based on hierarchical dirichlet process[J].Journal of Software,2016,27(5):1114-1126.
[8]WANG J Y,ZHANG X L.Deep NMF topic modeling[J].Neurocomputing,2023,515:157-173.
[9]周云泽,闵超.基于LDA模型与共享语义空间的新兴技术识别:以自动驾驶汽车为例[J].数据分析与知识发现,2022,6(S1):55-66.
ZHOU Y Z,MIN C.Identifying emerging technology with LDA model and shared semantic space—case study of autonomous vehicles[J].Data Analysis and Knowledge Discovery,2022,6(S1):55-66.
[10]吴胜男,田若楠,蒲虹君,等.基于社交媒体的医药领域关联主题预测方法研究[J].数据分析与知识发现,2021,5(12):98-109.
WU S N,TIAN R N,PU H J,et al.Predicting related medical topics from social media[J].Data Analysis and Knowledge Discovery,2021,5(12):98-109.
[11]张振青,孙巍.基于特征测度和PhraseLDA模型的领域学科交叉主题识别研究:以纳米技术的农业环境应用领域为例[J].数据分析与知识发现,2023,7(7):32-45.
ZHANG Z Q,SUN W.Interdisciplinary subject recognition based on feature measurement and PhraseLDA model—case study of nanotechnology in agricultural environment[J].Data Analysis and Knowledge Discovery,2023,7(7):32-45.
[12]ALATTAR F,SHAALAN K.Emerging research topic detection using filtered-LDA[J].AI,2021,2(4):578-599.
[13]PORTER A L,GARNER J,CARLEY S F,et al.Emergence scoring to identify frontier R&D topics and key players[J].Technological Forecasting and Social Change,2019,146:628-643.
[14]BLEI D M,NG A Y,JORDAN M I.Latent dirichlet allocation[J].Journal of Machine Learning Research,2003,3:993-1022.
[15]關鹏,王曰芬.科技情报分析中LDA主题模型最优主题数确定方法研究[J].现代图书情报技术,2016(9):42-50.
GUAN P,WANG Y F.Identifying optimal topic numbers from sci-tech information with LDA model[J].New Technology of Library and Information Service,2016(9):42-50.
[16]白敬毅,颜端武,陈琼.基于主题模型和曲线拟合的新兴主题趋势预测研究[J].情报理论与实践,2020,43(7):130-136.
BAI J Y,YAN D W,CHEN Q.Trend prediction of emerging topics based on topic model and curve fitting[J].Information Studies:Theory & Application,2020,43(7):130-136.
[17]MANN G S,MIMNO D,MCCALLUM A.Bibliometric impact measures leveraging topic analysis[C]//Proceedings of the 6th ACM/IEEE-CS joint conference on Digital libraries.New York:ACM,2006:65-74.
[18]李松繁,黄永,杨金庆.基于BERT的农业领域前沿研究主题识别方法研究[J].情报工程,2021,7(5):100-114.
LI S F,HUANG Y,YANG J Q.Research on frontier research topic recognition method in agriculture field based on BERT[J].Technology Intelligence Engineering,2021,7(5):100-114.
[19]颜惠琴,牛万红,韩惠丽.基于主成分分析构建指标权重的客观赋权法[J].济南大学学报(自然科学版),2017,31(6):519-523.
YAN H Q,NIU W H,HAN H L.Objective weight method based on principal component analysis to establish index weight[J].Journal of University of Jinan(Science and Technology),2017,31(6):519-523.
[20]TAYLOR S J,LETHAM B.Forecasting at scale[J].The American Statistician,2018,72(1):37-45.
[21]HOSSAIN M M,ANWAR A H M F,GARG N,et al.Monthly rainfall prediction at catchment level with the facebook prophet model using observed and CMIP5 decadal data[J].Hydrology,2022,9(6):111.
[22]HAN F S,ZHANG C X,ZHU D L,et al.Talent cultivation of new ventures by seasonal autoregressive integrated moving average back propagation under deep learning[J].Frontiers in Psychology,2022,13:785301.
[23]FENG S F,FENG Y.A dual-staged attention based conversion-gated long short term memory for multivariable time series prediction[J].IEEE Access,2021,10:368-379.
An emerging topic identification and detection method based on LDA model
Wu Dongxuea, Shen Guilanb
(a. College of Applied Arts and Sciences; b. Bussiness College, Beijing Union University, Beijing 100191, China)
Abstract: Emerging topic identification is an important way to identify emerging technologies in the field of science and technology research, and efficient and accurate identification of emerging topics is the premise of early identificating emerging technology research direction. An emerging topic identification and trend prediction method based on LDA model is proposed. It extracts research topics from scientific literature by LDA model, constructs an index system of topic strength, topic novelty and composite topic attention to identify emerging topics, and uses Prophet model training to predict topic strength of emerging topics. Based on the data set of scientific research literature in the field of smart agriculture in the last 14 years, the proposed recognition and detection methods are verified. Five emerging topics are identified, and the development trend in the following three years is predicted. The validity of the proposed methods is verified.
Keywords: topic identification; optimal topiccount; emerging topic identification indicators; Prophet model
[責任编校 陈留院 赵晓华]
