
基于高效通道注意力的多阶段图像去雨网络
2024-04-19 04:36李国金张书铭陶志勇
电光与控制 2024年4期
李国金, 张书铭, 林 森, 陶志勇
(1.辽宁工程技术大学电子与信息工程学院,辽宁 葫芦岛 125000;2.沈阳理工大学自动化与电气工程学院,沈阳 110000)
0 引言
在雨天,雨滴和雨纹对背景信息的覆盖会导致图像变得模糊,这将严重降低计算机视觉任务的性能,例如图像分割[1]、语义分割[2]和目标检测[3]等。因此,近年来图像去雨算法备受国内外关注,如何有效地去除雨图中的雨纹,同时保留图像背景信息,是一个具有挑战性的任务。
现有的图像去雨算法可分为两类:一是基于模型驱动的算法;二是基于深度学习的算法。早期雨纹去除主要是采用基于模型驱动的算法,通过构建去雨模型和对图像雨纹施加先验约束来解决图像去雨问题。文献[4]通过对背景层和雨层都施加基于高斯混合模型的先验约束,可以适应各种背景以及雨纹的外观;文献[5]使用自动图像分解框架将图像分解为高频和低频两部分,然后使用字典学习从高频部分去除雨纹;文献[6]考虑到雨纹的线状特性和角度分布,在基于先验约束的去雨网络模型中引入任意方向的梯度算子,提高了网络的去雨泛化能力。然而,基于物理模型的去雨算法只能提取雨纹层和背景层的浅层信息,不能满足计算机视觉任务的要求。
近年来,随着深度学习的快速发展及其在计算机视觉任务中取得的成功,研究人员提出许多基于深度学习的图像去雨算法。文献[7]考虑到普通卷积无法捕获大范围的情境信息,将空洞卷积引入图像去雨网络,扩大感受野,并使用雨图的上下文信息去除雨纹;文献[8]提出一种多尺度去雨网络,利用多尺度和多分辨之间的互补信息表示雨纹,进而完成去雨;文献[9]通过一个端到端的门控上下文聚合网络融合来自不同层次的特征,使用平滑扩张卷积消除扩张卷积引起的网格伪影;文献[10]联合图像去雨中的雨纹检测和去除,设计了一种多任务联合雨水检测和去除的图像去雨网络,使用二值映射标出雨水的位置,先检测雨水位置再估计雨纹,最后提取背景层,去除雨纹;文献[11]提出一种半监督学习框架,在该框架中同时从已标记和未标记的数据中进行学习,以达到图像去雨的目的。尽管与传统的模型驱动算法相比,基于深度学习的图像去雨算法已经取得了更好的效果,但是仍然不能在去除雨纹的同时更好地保留图像背景细节,导致输出的图像无法达到较好的视觉效果。
为了解决上述问题,本文提出一种基于高效通道注意力的多阶段图像去雨网络。
1 本文算法
1.1 网络模型
本文提出了一个端到端多阶段去雨网络,主要由3个部分构成,如图1所示。首先,网络使用3×3卷积(通道数C为40)提取雨图的浅层特征并传递给高效通道注意力模块,为不同的特征通道分配不同的权重,使网络专注于具有重要信息的通道;然后,传递给3个并行阶段,对于第1阶段和第2阶段,先通过U-Net结构的编码-解码器进行多尺度操作,由于不同尺度下雨纹的精细程度不同,在多尺度操作下可以更加精确地去除不同粗细的雨纹;随后,使用Transformer 模块筛选出有用的特征信息传递到下一阶段;最后,在第3阶段使用初始分辨率网络(Initial Resolution Net,IRN)代替编码-解码器,在没有任何下采样操作的情况下,只对输入图像的原始分辨率进行处理,以确保在最终输出的图像中保留所需的精细纹理。此外,在不同阶段之间还加入了特征融合网络(Feature Fusion Net,FFN),该模块利用前一阶段的多尺度特征帮助补充下一阶段的多尺度特征。
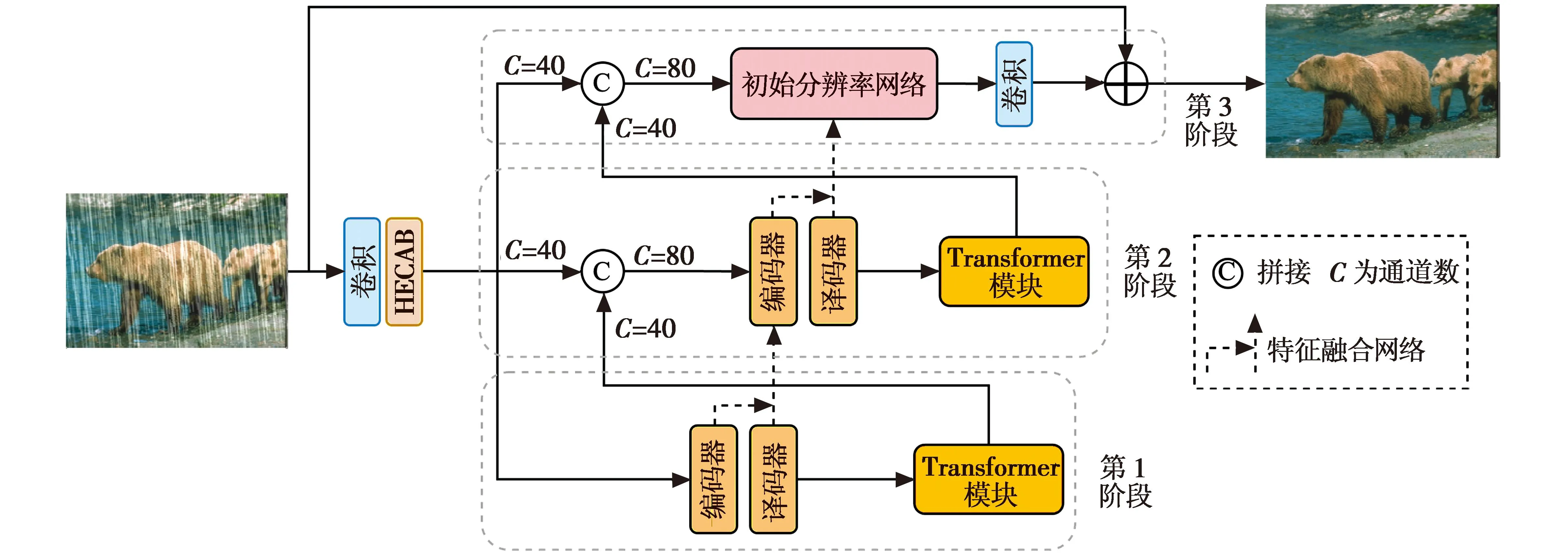
图1 本文网络模型
1.2 高效通道注意力模块(HECAB)
在图像去雨任务中,为不同的特征通道分配不同的权重,对于捕捉和去除雨纹非常重要。文献[12]提到的SE(Squeeze and Excitation)通道注意力模块通过全连接层学习特征通道权重,将减少特征图的通道维度,对通道注意力的预测产生负面效果。因此,本文提出一个高效通道注意力模块,如图2所示。

图2 高效通道注意力模块
高效通道注意力模块使用一维卷积代替全连接层,有效避免了因通道维度缩减造成的信息丢失,能够捕捉到更多的雨纹信息,保护了图像的背景细节,并且一维卷积的局部跨通道交互比全连接运算的全通道交互具有更少的参数量,提高了运算速度。
实现过程为:首先,输入特征x1经过由卷积和批量归一化(Batch Normalization,BN)组成的并行分支,用来提高模型表征能力。然后,使用全局平均池化(Global Average Pooling,GAP)对特征图F1进行空间特征压缩,特征图从[HWC]的矩阵变成[1 1C]的特征向量,其中,H为特征图的高,W为特征图的宽,通道数C为80。最后,特征向量通过一维卷积处理,避免了因全连接运算导致的通道维度降低,有效保护了通道信息的传递。
并行分支的输出为
F1=β(Conv3×3(x1))+β(Conv1×1(x1))
(1)
式中:x1为并行分支的输入;β为批量归一化操作;Conv3×3和Conv1×1分别为卷积核为3×3和1×1的卷积运算。
高效通道注意力模块的最终输出为
FH=δ(σ(Conv1D(α(F1)))⊙F1)
(2)
式中:δ为ReLU激活函数;σ为Sigmoid激活函数;Conv1D为一维卷积运算;α为全局平均池化;⊙为元素乘法。
在HECAB中,卷积核大小k决定了局部交互的范围,与通道数C呈非线性关系,由于人工微调容易浪费计算资源,因此使用自适应函数[13]来自动调整卷积核k的大小,算式为
(3)
式中:|t|odd表示距离t最近的奇数;系数γ和b在本文中设置为2和1,用于改变通道数C和卷积核大小k之间的比例。
1.3 编码-解码器
在单一尺度下提取粗细不同的雨纹信息较为困难,为了捕捉更加全面的雨纹特征,在网络中加入了U-Net结构的编码-解码器(Encoder-Decoder),如图3(a)所示。编码-解码器分为下采样和上采样两个部分。首先,编码器通过下采样逐渐将高分辨输入映射到低分辨率,每次下采样后特征图尺寸变为采样前的一半;然后,解码器使用双线性插值法进行上采样处理,有助于减少输出图像因使用转置卷积上采样而出现的网格伪影。此外,在跳跃连接处加入了HECAB,为不同分辨率下特征图的通道分配权重,提取不同分辨率下的雨纹特征。
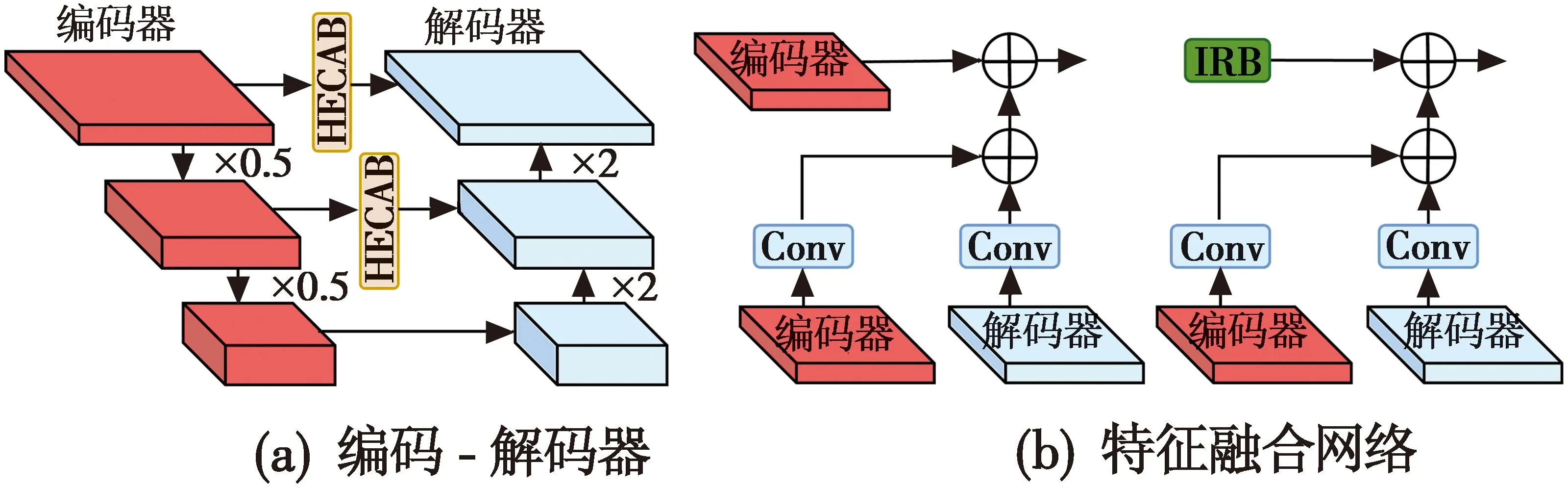
图3 编码-解码器和特征融合网络
由于编码器重复地使用下采样操作,难免会丢失部分特征信息。为了避免该问题,在每两个阶段之间加入了特征融合网络,如图3(b)所示。来自上一阶段编码-解码器的特征被输送到FFN中,输入的特征首先经过两个1×1的卷积对特征进行细化,然后把来自两个卷积细化后的特征相加,最后传递到下一阶段进行特征融合。
1.4 Transformer模块
现有的多阶段图像去雨网络大多直接把上一阶段得到的去雨图像信息传递到下一阶段,导致向下一阶段传递了很多无用的特征信息。受文献[14]的启发,本文在网络中加入了Transformer模块,如图4所示。Transformer模块由两部分构成,即多深度卷积头部转置注意力(Multi-Depthwise conv head Transposed Attention,MDTA)和门控深度卷积前馈网络(Gated-Depthwise conv Feed-forward Network,GDFN)。

图4 Transformer模块
在MDTA中,输入特征首先经过层归一化(Layer Normalization,LN),再使用1×1卷积提取通道上下文信息,3×3深度卷积提取局部空间上下文信息。卷积后的特征经过Reshape操作后得到特征矩阵Q,K和V,用于丰富局部上下文信息。然后计算Q与K的跨通道交叉协方差,即在通道维度上使用自注意力(Self Attention,SA)机制,以生成提取全局上下文信息的转置注意力图。最后,通过聚合局部和全局像素交互来有效处理高分辨像。MDTA的输出FM为
FM=Conv1×1(R(V⊗σ(Q⊗K/θ)))+x2
(4)
在GDFN中,输入特征FM先经过层归一化处理,然后进入由1×1卷积和3×3深度卷积组成的并行分支,1×1卷积用以扩展特征通道,3×3深度卷积用以学习局部信息。并行分支的关键点在于下支路会通过一个非线性的GELU函数,可以将有用的特征保留,然后与上支路得到的原特征图相乘,从而达到增强有用特征的目的。最后使用1×1卷积降低通道维度。GDFN抑制无用信息,仅允许有用的信息传播,从而使下一阶段聚焦于更重要的信息。输出特征FG的计算过程可以表示为
FG=Conv1×1(F2⊙F3)+FM
(5)
F2=DConv3×3(Conv1×1(LN(FM)))
(6)
F3=GELU(F2)
(7)
其中:F2为上支路输出;F3为下支路输出;LN(·)表示层归一化;DConv3×3表示3×3深度卷积运算;Conv1×1表示1×1的卷积运算;GELU(·)为激活函数。
1.5 初始分辨率网络
为了保留从输入图像到输出图像的精细特征,生成信息丰富的高分辨率雨纹特征,在最后阶段引入了一个初始分辨率网络(Initial Resolution Net,IRN),如图5所示。

图5 初始分辨率网络
IRN由3个初始分辨率模块(Initial Resolution Block,IRB)组成,每个初始分辨率模块由8个高效通道注意力模块和1个卷积层组成,表达式为
FI=IRB(IRB(IRB(x3)))+FD
(8)
式中:IRB为初始分辨率模块;FI和x3分别为初始分辨率网络的输出和输入;FD为特征融合网络的输出。
1.6 损失函数
为了获取更多的背景细节和边缘结构,本文使用一种双损失函数L来训练网络,该损失函数可以使去雨图像生成丰富的边缘细节,避免梯度消失。双损失函数L由Charbonnier损失函数[15]和边缘Edge损失函数[8]组成,算式为
L=LChar(X,Y)+λLEdge(X,Y)
(9)
(10)
(11)
其中:X和Y分别为有雨图像和无雨图像;LChar为Charbonnier损失函数;LEdge为Edge损失函数;Δ(·)为拉普拉斯运算;λ控制着Charbonnier损失函数和Edge损失函数在双损失函数L中所占权重比例,本文设置为0.05,根据经验将常数ε设置为0.003[15]。
2 实验与分析
2.1 实验环境和数据集
本文所提出的多阶段网络模型基于PyTorch实现,在具有24 GiB内存的NVIDIA GeForce RTX3090上进行训练,使用SGD优化器对模型梯度进行优化,模型初始学习率为2×10-4,训练过程中逐渐下降到1×10-6,Batch size为8,epoch为250。使用4个公开合成数据集Rain800[16],Rain12[4],Rain100L[10]和Rain100H[10]来训练和测试网络。Rain800包含700对训练图像和100对测试图像;Rain12中包含12对有雨和无雨图像,仅作为测试图像;Rain100L为仅存在一种雨纹的小雨数据集,包含200对小雨训练图像和100对测试图像;Rain100H为存在5种雨纹的大雨数据集,包含1800对大雨训练图像和100对测试图像。
3)合理修剪。梨园要适度密植,通过合理修剪改善通风透光条件,对减轻病害发生非常重要。修剪时要剪除密挤、冗长的内膛枝,疏除外围过密、过旺、直立生长枝条,对发病较重的树要适当重剪。同时调整好负载,以提高树体抗性。
2.2 实验结果与分析
2.2.1 合成雨图
为进一步验证本文算法在去雨上的优势,将本文算法与SEMI算法[11]、DiG-Com算法[6]、GCANet算法[9]、RESCAN算法[7]、JORDER算法[10]和MSPFN算法[8]的去雨性能进行比较,并使用峰值信噪比(PSNR)[17]和结构相似性(SSIM)[18]指标进行评估。对于早期的算法以及未提供训练代码的算法,本文直接采用提供的预训练模型进行测试,不同算法在合成数据集上的定量对比结果如表1所示。
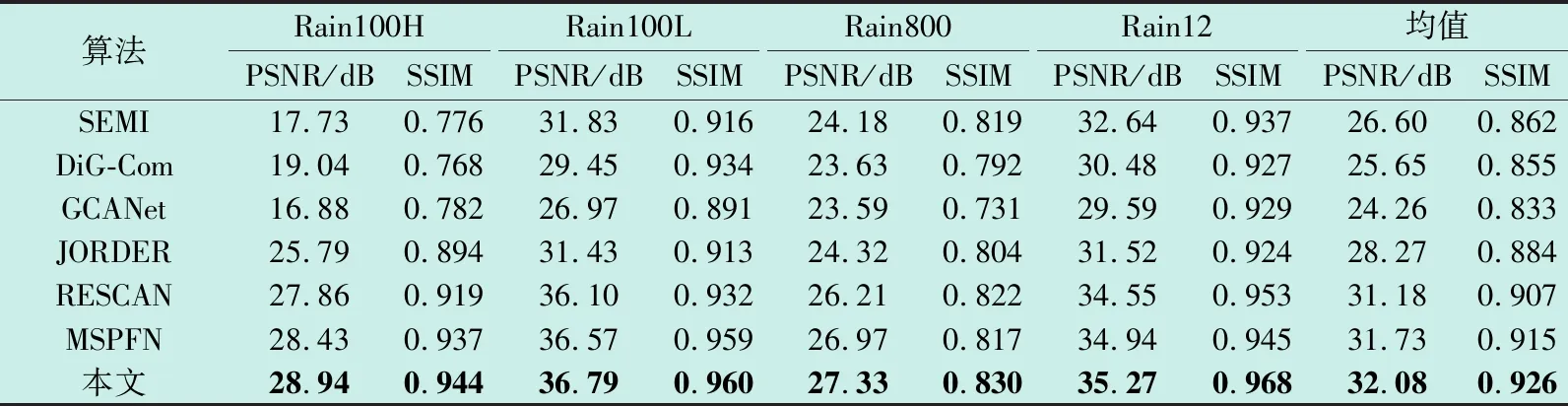
表1 合成数据集上的评估指标
实验结果表明,本文算法在测试数据集Rain100H、Rain100L、Rain800和Rain12上与其他6种对比算法相比,PSNR较次优算法分别提高了0.51 dB、0.22 dB、0.36 dB、0.33 dB、SSIM分别提高了0.007、0.001、0.008、0.015。从而说明本文所提算法在去雨性能上较其他算法有更好的效果。
为了直观地展示本文算法的性能,给出具有代表性数据集Rain100H上的实验结果,本文算法的合成雨图去雨效果与其他算法的视觉对比结果如图6所示。

图6 Rain100H数据集的测试结果
从5组图像中可以发现,对比算法在去雨时雨纹残留明显,背景呈现出不同程度的虚化。进一步发现:SEMI,DiG-Com和GCANet算法无法有效去除雨纹;JORDER算法虽然去除了大部分雨纹,但背景模糊不清且有较为明显的伪影;RESCAN和MSPFN算法虽然可以去除雨纹,但丢失了部分背景细节,并且边缘不够锐利;本文算法在将雨纹去除的同时,能够较好地恢复图像的背景细节,更加接近无雨图像。因此,本文算法在去除雨纹和恢复背景图像细节方面具有更好的效果。
2.2.2 真实雨图
为进一步验证本文算法在真实雨图去雨中的泛化性能,将MSPFN、RESCAN、JORDER、GCANet、SEMI和本文算法的去雨表现进行对比,测试所用的模型为Rain100H上训练的模型。由于真实雨图没有无雨图像做对比,无法使用PSNR和SSIM做评估指标,本文采用自然图像质量评估指标(NIQE)[19]作为评价指标,其值越小表明输出图像的质量越高,不同算法在真实雨图上的定量结果如表2所示。

表2 真实雨图的评估指标
表2中数据为68张真实雨图的NIQE平均值。实验结果表明,相比SEMI、GCANet、JORDER、RESCAN和MSPFN算法,本文算法在真实雨图上的NIQE达到最小值,为3.677。不同算法的真实去雨视觉效果如图7所示。

图7 真实数据集的测试结果
由图7可以看出,在前两组图像中,SEMI和GCANet算法处理后依然有大量雨纹残留,JORDER和RESCAN算法虽然可以去除大部分雨纹,但同时也使图像细节变得模糊,MSPFN算法仍然存在少量雨纹,部分背景细节模糊;第3组图像中,其他对比算法均存在不同程度的雨痕和伪影,背景细节较差。通过3组真实去雨图像对比,本文算法在去除雨纹和恢复背景细节方面效果更优。
2.3 消融实验
2.3.1 网络组成消融实验
为验证本文所提网络结构的有效性,消融实验针对不同网络组成在Rain100H上的去雨结果进行分析,如表3所示。

表3 网络组成消融实验
本次消融实验设计了4种不同的网络组合方式,分别是用编码-解码器代替原网络的IRNet(Net1)、用SE通道注意力模块代替HECAB(Net2)、在原网络中不引入Transformer模块(Net3)和本文原网络。
由表3分析可知:Net1中用编码-解码器代替网络第3阶段的初始分辨率网络时,PSNR和SSIM分别下降了0.83 dB和0.121;Net2的PSNR和SSIM较原网络分别下降1.12 dB和0.061,说明在图像去雨网络中,HECAB相比于SE通道注意力模块具有更好的表现;Net3中不引入Transformer模块,PSNR和SSIM分别下降了1.43 dB和0.077,这表明在多阶段网络中加入Transformer模块抑制无用信息传递,网络的去雨能力会有明显提升。实验结果表明,本文所使用原网络组成在去雨上有较好的性能。
2.3.2 损失函数消融实验
为验证本文所使用双损失函数L的有效性,对MSE损失函数、Edge损失函数、Charbonnier损失函数、MSE与Edge损失函数的组合、Edge与Charbonnier损失函数的组合进行实验。损失函数的消融实验对比结果如表4所示。

表4 损失函数消融实验
实验结果表明,由Edge和Charbonnier组成的双损失函数训练网络的性能与单独使用MSE、Edge和Charbonnier损失函数相比,在PSNR指标上分别提升1.27 dB、0.89 dB和1.11 dB,在SSIM上分别提升0.065、0.052和0.063。同时,比MSE和Edge组成的双损失函数在PSNR和SSIM指标上分别提升了0.53 dB和0.027。因此,本文所使用的双损失函数相比其他单个损失函数和双损失函数在去雨效果上有更好的表现。
3 结论
本文提出一种基于高效通道注意力的多阶段图像去雨网络。在网络中使用高效通道注意力模块为不同的特征通道分配不同的权重,使网络更专注于具有重要信息的通道。为保留从输入图像到输出图像的精细特征,生成信息丰富的高分辨率雨纹特征,使用初始分辨率模块代替了U-Net结构的编码-解码器。此外,在不同阶段中还加入了特征融合模块和Transformer模块,阻止了无用信息进一步传递。与对比算法相比较,本文算法在逐渐去除图像中雨纹的同时,也很好地恢复了背景图像,去雨效果更优越。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
电子制作(2019年11期)2019-07-04
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
