
基于改进CeiT的GTAW焊接熔透状态识别方法
2024-04-17 01:52王颖高胜
焊接学报 2024年4期
王颖,高胜
(东北石油大学,大庆,163318)
0 序言
焊缝熔透状态是表征焊接质量、影响焊接产品使用性能最重要的指标之一,然而由于焊接过程的瞬时性和复杂性,使得利用正面熔池信息实时准确获得焊缝熔透状态成为焊接过程监测和质量控制的关键瓶颈[1-2].已有的关于焊缝熔透状态识别的研究主要采用机器学习的方法,通过人为设计特征,建立其与熔透状态之间的非线性映射关系;然而人为设计的特征具有较强的主观性,严重影响识别精度和速度.随着深度学习的不断发展,其通过自动提取所需的特征进行预测,提高了识别的自动化程度和准确率,有效解决了传统方法所面临的问题[3-4].因此,近些年有许多学者将深度学习应用到熔池变化的在线监测中,其中基于视觉信号的研究和应用最为广泛[5-8].文献[9]利用短时傅里叶变换获得电弧声的时频频谱图像,建立卷积神经网络识别焊缝的熔透状态;文献[10]以感兴趣区域的温度场图像为输入,基于深度残差网络建立了焊缝熔透预测模型;文献[11]以采集的二维熔池图像作为输入,建立了CNN 熔透状态预测模型;文献[12]以匙孔图像作为输入,建立LeNet-5 网络模型对熔透状态进行识别;文献[13]以正面熔池图像作为输入,搭建CNN 模型预测烧穿,并建立回归模型对穿透深度进行估计;文献[14]利用HDR焊接摄像机获得熔池/匙孔图像,使用图像增强方法提高训练数据集的多样性,并建立Resnet 网络对焊接状态进行识别;文献[15]以熔池/匙孔图像序列作为底层输入,利用CNN 提取图像序列中每一帧图像的空域特征,同时建立BiLSTM 网络挖掘时域内的上下文信息,最后利用获得的时空特征映射到具体的熔透状态上.基于深度学习的方法大大提升了识别的准确率,为了进一步提升预测的实时性,文献[16]以SSD 作为主干网络,利用视觉传感信号作为输入,将特征提取网络VGG 替换为轻量网络Mobilenet,熔池的定位与识别速度得到了提升;文献[17]基于MobileNetV2 构建了迁移学习模型,将ImageNet数据集进行预训练获得的参数迁移到自建的GTAW 熔池图像数据预测中,训练速度得到了大幅提升;文献[18]利用从振荡焊接熔池表面反射的点结构激光图像进行焊缝熔深预测,在不对图像做任何预处理的情况下,利用提出的小批量梯度下降法进行训练,获得了较快的训练速度和较高的准确率.
Google 提出的Vision Transformer[19-20](ViT)在图像识别领域也取得了突破性进展,其将图像分割成固定大小的像素块输入到编码器,编码器由多头自我注意力机制(multi-head self-attention mechanism,MSA)和多层感知模块(multi-layer perceptron,MLP)组成,利用最后一个编码器层的分类标记作为全局特征表示,获得最终的分类结果.ViT 在图像识别领域取得了与卷积网络相当的性能,但需要更大量的训练数据或额外的监督.为了克服这个限制,提出了CeiT 网络[21],它集合了CNN 在提取低级特征、增强局部性方面,以及ViT 在建立远程依赖关系方面的优势,在数据量、准确率及收敛速度方面进行了均衡.但为了进一步满足焊接过程的实时性和准确性要求,对CeiT 网络进行了改进.首先通过聚焦(Focus)模块、通道分组、通道混洗、多尺度特征融合构建了一种FMCbneck 模块,使得模型能够获得更多的熔池空间位置信息;其次将FMCbneck 模块嵌入MobileNetV3(Large)网络中,并调整其结构代替Image-to-Tokens 模块进行熔池图像浅层特征提取,在保证较高检测精度的条件下,极大的降低了模型参数量,提高了模型的检测速度;设计了DGCA 模块并将其应用到LeFF中,有效增强了特征间的远程依赖关系、丰富了类标记中所包含的分类信息,并通过将LeFF 模块中的底层特征和高层语义特征进行融合,提高了模型对熔池特征的表示能力、进一步提升了检测效果;最后与不同的网络模型进行对比,证明了所提模型在保持较低参数量的同时拥有着更高的精确度.
1 基于改进CeiT的熔透状态识别模型
1.1 CeiT 网络结构
CeiT 网络结构如图1 所示,其在ViT的基础上设计了Image-to-Tokens(I2T)模块、LeFF 模块和LCA 模块.

图1 CeiT 网络结构Fig.1 CeiT network structure
I2T 模块由一个卷积层和一个最大池化层组成,用于提取熔池图像的底层特征,即
式中:X为I2T 模块的输入特征.
将提取的熔池底层特征X′分割(Split)成特征小块,并通过flatten 操作将特征小块转换成一维向量,同时添加一个可学习的类别块,这个类别块用于与所有的特征小块进行交互,最终从类别块中学习到用于分类的特征.特征序列加入位置编码送入Encoder block中,重复堆叠L次.在Encoder block中除了包含MSA 模块、Layer Normalization 模块(Layer Norm)、Add(残差块)外,还设计了局部增强前馈模块(LeFF),目的是通过使用深度卷积增加相邻特征小块在空间维度上的相关性.抽取Encoder block 所得交互特征中的L个类别块送入LCA 模块(layer-wise class token attention),目的是为了关注不同层的类标记信息,将注意力放在不同层的特征快上,最后获得输出信息.
1.2 Image-to-Tokens 模块轻量化改进
为充分利用熔池图像中的浅层特征、减少冗余操作、提高焊接检测的实时性与部署便捷性,使用MobileNetV3(Large)作为Image-to-Tokens 模块的特征提取网络.MobileNetV3[22]网络的逆残差结构、深度可分离卷积、SE(squeeze and excitation)通道注意力机制和h-swish 激活函数,使得模型能够很好地获得熔池图像中的重要特征信息,并且避免训练时出现梯度消失及计算量过大的问题.然而轻量化的网络结构也会带来检测精度上的损失,为此对MobileNetV3的bneck 结构进行改进,改进的bneck 模块结构(FMCbneck)如图2 所示.
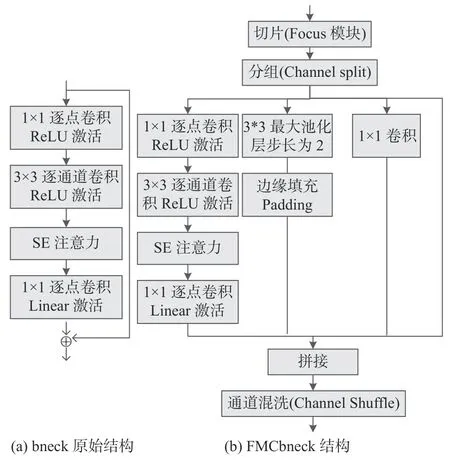
图2 改进前后的bneck 结构Fig.2 Improved bneck structure before and after.(a)bneck original structure; (b) FMCbneck structure
(1)由于熔池图像像素低、携带的信息少,并且在下采样过程中特征信息会部分丢失,使得在处理过程中容易导致图像失真.为解决这一问题,在bneck 输入端引入了聚焦模块(Focus 模块),Focus模块通过间隔采样对图片进行切片操作,目的在于将高分辨率特征图拆分成多个低分辨率的特征图,且没有信息丢失,Focus 切片采样原理如图3 所示.

图3 Focus 切片采样原理Fig.3 Focus slice sampling principle
(2)为了融合不同尺度的缺陷特征,提升模型的泛化能力、抑制过拟合、扩大特征感受野,并且不会大幅度增加模型的复杂度,在原bneck 基础上增加2 个分支,分别为Maxpooling 和1 × 1的普通卷积.
(3)为了进一步降低计算量,增加特征信息间的交流和特征的表达能力,对Focus 切片后的特征通道进行了分组操作(channel split),并在多尺度特征融合后进行了通道混洗操作(channel shuffle).
除了对MobileNetV3的bneck 结构进行了改进,还对其中的SE 模块以及5 × 5 卷积核的位置进行了调整.通过消融试验发现SE 模块在越靠后的位置对模型精度的提升越大,5 × 5 卷积核在网络的中后部对模型性能的提升作用更明显,并且在步长为1 时采用FMCbneck 结构,步长为2 时采用原bneck 结构,模型效果更好.所采用的MobileNetV3网络参数如表1 所示.表1 中exp 表示FMCbneck和bneck 中第一层1 × 1 卷积升高的维度;#out 表示FMCbneck 和bneck 输出的通道数;SE 表示是否使用SE 模块.

表1 MobileNetV3 网络参数Table 1 MobileNetV3 network parameters
1.3 LeFF 模块改进
CeiT 网络的LeFF 模块结构如图4 所示,输出的类标记将作为LCA 模块的输入参与分类.为了丰富类标记中所包含的分类信息、提高模型对熔池特征的表示能力、增强特征间的远程依赖关系,改进后的LeFF 结构如图5 所示.

图4 原始LeFF 结构图Fig.4 Original LeFF structure diagram

图5 改进的LeFF 结构图Fig.5 Improved LeFF structure diagram
将Depth-wise Convolotion(DWConv)操作替换成DGCA 模块,对特征图进行增强且保持较少的计算量.DGCA 模块结构如图6 所示,其在DWConv操作前后引入Ghost Module、建立残差机制、添加Coordinate Attention(CA)注意力模块.

图6 DGCA 模块Fig.6 DGCA Module
CA 注意力模块分别沿两个方向聚合特征,一个方向捕捉长期依赖,另一个方向保留精确的位置信息,起到了聚焦显著目标区域,抑制飞溅、弧光等背景噪声的作用,其结构如图7 所示.

图7 CA 注意力模块结构图Fig.7 CA attention module structure diagram
对输入尺寸为W×H×C的特征图(W,H,C分别表示特征图的宽、高和通道数)使用(1,W)和(H,1)进行平均池化编码,分别得到了水平方向感知特征图C×H×1和垂直方向感知特征图C×1×W,计算原理为
将垂直方向和水平方向感知特征图在空间维度进行拼接,得到特征图C×1×(W+H).利用1 ×1 卷积变换对其进行降维至C/r,r用于控制缩减率,再进行归一化和非线性变换操作.然后沿着空间维数将其分解为两个单独的张量C/r×H×1和C/r×1×W,再利用1 × 1 卷积变换分别对其升维至C,并经过sigmoid 激活函数将其作用于原特征图上,最终输出yc(i,j)为
2 数据准备和试验设置
2.1 样本获取
采用的焊接方法为GTAW 脉冲焊,保护气体为氩气,焊接材料为厚度3.175 mm的304 不锈钢,摄像头采集频率为1 000 Hz,曝光时间为20 μs,硬件设备如图8 所示.将工业相机和数据采集卡采集到的熔池正面图片和相应的电流、电压信号传输到计算机,计算机对接收到的数据处理之后可通过调节电流电压控制器和伺服电机控制器控制焊接过程中的电流电压以及焊接速度,从而得到不同状态下的熔池数据.

图8 图像采集平台Fig.8 Image acquisition platform
焊接电流控制在140~ 200 A,变化步长为20 A;焊接速度控制在20~ 40 cm/min,变化步长为10 cm/min;通过调节焊接电流与焊接速度,获得未熔透(图9(a))、熔透(图9(b))、烧穿(图9(c))三种状态下的熔池图片,去掉起弧和收弧时不稳定状态下采集的图像,最终采集得到1 475 张未熔透照片、7 567 张正常熔透照片和725 张烧穿照片,其中未熔透样本标记为0,正常熔透样本标记为1,烧穿样本标记为2.

图9 三种焊接熔池Fig.9 Three types of welding pools.(a) not melted through; (b) melt through; (c) burn through
2.2 图像预处理
熔池图像的预处理是通过提取ROI、3 次样条插值和归一化进行的.视觉系统采集到的原始图像尺寸为1 280 × 700,直接对原始图像进行训练不仅干扰信息多而且计算量大,会严重影响训练速度,因此选择从原始图像中裁剪感兴趣的区域,去掉无关信息.由于在采集的图像中熔池的位置几乎保持在固定的区域,因此选择ROI 自动提取算法.未熔透和熔透两类图像设定的左上角坐标为(200,50),烧穿图像设定的左上角坐标为(390,150),窗口大小为700 × 350,提取ROI的结果如图10 所示.

图10 ROI 提取结果Fig.10 ROI extraction results.(a) original image; (b)image after ROI extraction
采用3 次样条插值方法将ROI 图像调整为224 × 224,再将图像中的每个像素值除以255 归一化为[0-1].复制灰度图像矩阵,使其变为224 ×224 × 3.
2.3 数据增强
在深度学习中,样本数据集大小和数据质量会直接影响模型的泛化能力和鲁棒性.在实际焊接过程中,虽然数据量在不断增大,但大多数数据为正常数据,未熔透和烧穿的样本很少.因此,在保证图像自然特征表达情况下,将对未熔透和烧穿的样本进行数据增强,以弥补样本数量不均衡问题.增强方法为改变图像的对比度和亮度、水平翻转、椒盐噪声、高斯噪声等,其中烧穿的样本还采用了多种方式叠加的方法进行数据增强,处理效果如图11所示.最终未熔透样本扩充至7 375 张、烧穿样本扩充至6 579张,按照8∶1∶1的比例随机划分为训练集、验证集和测试集,各数据集所含图片数量如表2 所示.
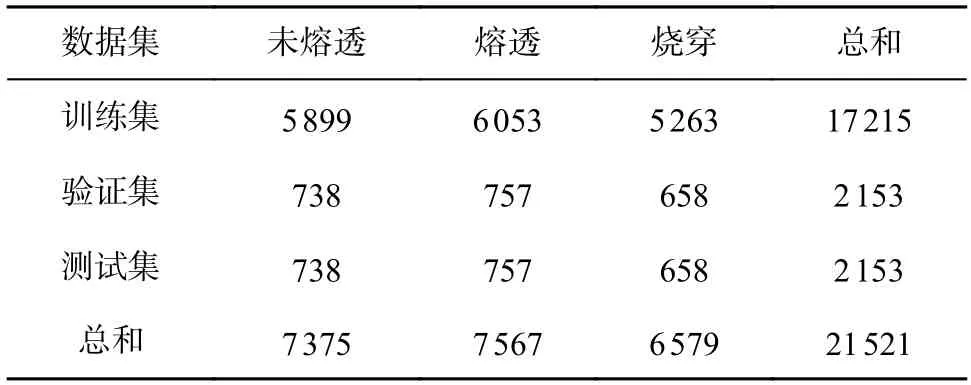
表2 扩充后各数据集数量(张)Table 2 Number of each data set after expansion

图11 样本数据增强效果Fig.11 Sample data enhancement effect.(a) fusion state; (b) burn-through condition
2.4 试验设置
CPU 型号为Intel Core i9 13900K,GPU 为16G显存的NVIDIA RTX 4080,操作系统为Ubuntu 16.04 LST 64位,深度学习框架为Pytorch 1.8,TorchVision 0.8,CUDA 版本为 10.1.批次大小设置为128,训练轮次为100,优化器使用Adam(Adaptive momentum),学习率衰减策略为
式中:lt为学习率;b为预热初始值;R2为全局预热周期;R为训练总轮数;r为当前轮数.
2.5 损失函数
损失函数由两部分组成:分类损失函数和中心损失函数.
(1)分类损失函数L1.采用交叉熵损失函数来计算预测值和真实值的误差,计算式为
式中:N为样本数;M为类别数目(M=3);yic的取值为0 或1(如果样本i的类别为c取1,否则取0);pic为样本i属于类别c的预测概率.
(2)中心损失函数L2.为了增大不同熔透类别间距离、减小同一类别内距离,采用中心损失函数增强同类样本相似性,计算式为
式中:wyi为第yi类训练样本特征的中心位置;xi为样本i进入全连接层之前的特征.
(3)总体损失函数L总体损失函数为
式中:λ和(1-λ)分别表示各自的权重,λ的初始值为0.5,在训练过程中不断对两个超参数进行更新.
2.6 评价指标
精确率(Precision)、召回率(Recall)和F1 分数(F1-Score)、准确率(Accuracy)作为模型的评价指标,模型训练时间和模型内存占用量作为模型计算复杂度的评价指标,识别单个样本平均时间作为模型检测速度的评价指标.
Pprecision表示预测为正的样本实际为正样本的比例,精确率越高则模型对负样本区分能力越强,计算式为
Rrecall表示所有正样本中被预测为正样本的比例,召回率越高则模型对正样本的区分能力越强,计算式为
FF1-score是Pprecision和Rrecall的调和平均值,计算式为
Aaccuracy表示预测正确的样本占总样本的比例,计算式为
式中:TP表示实际正类预测为正类的数量;TN表示实际负类预测为负类的数量;FP表示实际负类预测为正类的数量;FN表示实际正类预测为负类的数量.
3 试验结果与分析
3.1 数据增强对检测效果的影响
利用改进后的CeiT 模型对数据增强效果进行对比试验,表3 为未使用数据增强的试验结果,表4 为使用数据增强的试验结果.数据增强前未熔透照片1 475 张、正常熔透照片7 567 张、烧穿照片725 张.数据增强后未熔透样本7 375 张、正常熔透样本7 567 张、烧穿样本6 579 张.

表3 未数据增强试验结果Table 3 No data enhancement test results

表4 数据增强试验结果Table 4 Data enhancement test results
通过试验结果可以看出使用数据增强三种类别的识别效果均得到了提升,尤其是未熔透和烧穿.数据样本不均衡时,未熔透样本会有大部分误判为正常熔透,烧穿样本误判为未熔透.由此可见数据增强缓解了由于数据量不足造成的模型过拟合和泛化能力不足等问题.
3.2 学习率对检测效果的影响
学习率是深度学习中非常重要的超参数之一,为了选择合适的学习率,在控制其他条件相同的情况下,分别设置学习率为0.01,0.001 和0.000 1 进行分析,图12 为试验验证集结果.比较图12(a)中曲线,学习率为0.001的损失值较低.对比图12(b)中曲线,训练初期学习率为0.01 与0.001 准确率波动较大,训练40 轮时,学习率0.000 1的准确率随着训练轮数的增加变化稳定,而其他两种的准确率还有一定波动.综合对比验证集上损失值和准确率的变化情况,可以看出当学习率为0.000 1时,泛化能力最佳,可以获得较好的结果.

图12 学习率对比结果Fig.12 Learning rate comparison results.(a) validation set loss value curve; (b) validation set accuracy curve
3.3 消融试验结果
为了证明对CeiT 模型一系列改进在提升模型整体性能方面的有效性,在训练集上进行了消融试验.方案如表5 所示,其中“I2T 模块改进”对应1.2 节Image-to-Tokens 模块轻量化改进,“LeFF 模块改进”对应1.3 节;“M3”表示利用MobileNetV3进行底层熔池特征提取;“BNSA”表示MobileNetV3的bneck 模块改进和结构调整;“DG”表示使用DGCA 模块替换DWConv 操作;“FI”表示将LeFF模块中空间复原前与复原后的特征图进行融合;“C0”表示未熔透样本对应的识别结果;“C1”表示正常熔透样本对应的识别结果;“C2”表示烧穿样本对应的识别结果;“—”表示在改进CeiT 时不使用该策略;“Π”表示在改进CeiT 时使用该策略.

表5 消融试验结果Table 5 Ablation test results
由表5 试验结果可知,方案2 利用轻量化网络MobileNetV3 进行熔池底层特征提取训练时间降低了20.79%,准确率降低了3.44%,说明轻量型网络能够有效降低模型的计算量,但会损失一定的检测精度;方案3 在方案2的基础上对MobileNetV3的bneck 模块进行了改进,并对其结构进行了调整,与方案2 相比训练时间略有增加,但准确率提高了10.24%,与方案1 相比训练时间提升12.04%,准确率提升了6.62%,说明对Image-to-Tokens 模块的轻量化改进有效的提高了模型的综合能力;与方案1 相比方案4 中Ghost Module、残差机制、CA注意力模块的引入有效的提升了模型的识别精度,但训练时间增加了21.38%;方案5 在方案4的基础上融合了底层特征与高层语义特征,识别准确率得到了进一步提升.对比方案1、方案3 和方案5,对Image-to-Tokens 模块和LeFF 模块的改进均提升了模型的准确率,但方案3 有效降低了训练时间,方案5 增加了训练时间.方案6 为提出的改进后模型,即同时使用方案3 和方案5 进行改进,与方案1 相比模型的识别准确率提升了9.74%,训练时间也缩小了0.31 h.
组合改进策略的模型迭代曲线,如图13 所示.可以看出,所提模型的损失值更小、收敛速度更快、在验证集上的识别准确率更高、泛化能力更强,进一步验证了对CeiT 模型一系列改进的有效性.

图13 组合改进策略的模型迭代曲线Fig.13 Model iteration curves for combined improvement strategies.(a) Iteration curves of loss values on the training set for different improvement schemes; (b) Iteration curves of the accuracy of different improvement schemes on the validation set
3.4 不同检测模型对比试验
为了综合评估所提网络的有效性,将其与改进前的CeiT 网络、DeiT 网络、MobileNetV3、ResNet 50 和ShuffleNetV2 模型进行对比试验.利用测试集上获得的精确率、召回率、F1 分数和准确率评估识别效果,使用训练时间和模型内存占用量评估模型的复杂度,使用识别单个样本平均时间评估模型的检测速度.迭代过程中各模型在验证集上的准确率变化如图14 所示.从图14 中可以看出,所提模型与其他模型相比在验证集上有最高的识别准确率,而DeiT的表现最差.训练好的各个模型在测试集上的识别效果如表6 所示.由表6 数据可知,改进的CeiT 模型和ResNet50均获得了较高的检测精度,但非轻量化的ResNet50 在训练时间、模型内存占用量和识别单个样本平均使用时间要高出很多,无法满足焊接实时性要求.轻量化网络ShuffleNetV2和MobileNetV3 训练时间相当,但MobileNetV3的检测精度比ShuffleNetV2低,说明在熔池数据集上ShuffleNetV2 表现更好.DeiT 网络的检测精度最差,原因是其需要海量数据作为支撑,试验数据量远达不到要求,但其训练时间、模型内存占用量和识别单个样本平均时间比CeiT 要少.改进的CeiT 网络与原CeiT 模型相比准确率提高了8.66%,计算复杂度和检测速度都有了大幅提升.试验结果表明,所提模型对焊接熔透状态的识别取得了最好的效果.

表6 不同模型试验结果Table 6 Test results of different models

图14 各对比模型在验证集上准确率的迭代曲线Fig.14 Iteration curves of the accuracy of each comparison model on the validation set
4 结论
(1)使用MobileNetV3 作为Image-to-Tokens 模块的特征提取网络,能够缩减网络模型的参数量和计算量,有效提升实时检测性能.
(2)通过Ghost Module、残差机制、注意力模块对LeFF 模块的改进增强了特征间的远程依赖关系、提升了多尺度特征表达能力、丰富了局部和细节特征信息.
(3)所提出的模型在试验数据集上与改进前的CeiT 网络、DeiT 网络、MobileNetV3、ResNet 50 和ShuffleNetV2 模型进行对比,结果表明所提模型获得了最高的准确率,且检测速度可以满足焊接实时性的要求,展现了较好的有效性和鲁棒性,为焊接熔透状态实时预测提供了新的方法.
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中学生数理化·高一版(2021年2期)2021-03-19
知识经济·中国直销(2018年8期)2018-08-23
中国交通信息化(2018年5期)2018-08-21
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
焊接(2016年10期)2016-02-27
焊接(2015年11期)2015-07-18
