
基于深度学习和颜色特征的行人跟踪算法∗
2024-04-17 07:29:24曹建荣韩发通朱亚琴
计算机与数字工程 2024年1期
曹建荣 李 凯 尚 硕 韩发通 庄 园 朱亚琴
(山东建筑大学信息与电气工程学院 济南 250101)
1 引言
近年来,得益于深度学习和计算机视觉的发展,视频中运动目标识别与跟踪进入新的发展阶段[1~2],目标跟踪作为计算机视觉最重要的子任务之一,被广泛应用到各个领域,例如视频监控、运动目标分析、动作识别和流量统计等[3]。为了完成行人跟踪任务,首先要在一帧中定位人体初始位置并提取相关信息,为每个行人赋予唯一的ID 号,在后续帧中保持该对象的ID号不发生跳变[4]。
早期目标跟踪算法主要集中在对单目标跟踪研究。1950年提出的光流法[5],它是对视频中像素的变化进行建模,在相邻帧之间寻找像素位置的变化来实现目标跟踪。但是,光流法的局限性比较大,对光照变化比较敏感。Camshift[6]算法是利用颜色直方图的概率分布进行追踪,其运行速度较快,但是在背景颜色相近时,会出现跟踪误报。卡尔曼滤波算法能够对行人位置进行观测估计,可以利用人体目标的动态信息,预测出下一时刻目标的位置。基于Kalman[7]滤波的目标跟踪认为物体的运动模型服从高斯分布,用物体的动态信息估计运动状态,将得到的状态与观察模型对比,利用误差来更新目标运动状态,该算法的运行效率不高。早期跟踪算法主要针对单目标轨迹跟踪,无法适应场景中多个目标。
随着深度学习和计算机视觉的发展,目前主流的多目标跟踪框架主要分为两种[8]:第一种是基于检测器的跟踪(Tracking-by-Detection),先用检测器进行目标检测,然后将检测结果进行关联匹配。第二种是将检测和跟踪联合(Detection-Free Tracking),在第一帧中手动初始化一定数量的对象,然后在后续帧中定位这些对象。基于检测器的跟踪首先利用目标检测器如Faster R-CNN[9]和YOLO[10]等算法检测定位视频帧中的行人,并提取行人的运动特征或颜色纹理等特征来区分不同的行人及背景,然后建立跟踪模型并进行行人轨迹预测,最后根据行人的运动模型或外观模型等特征完成匹配。Bewley 等提出的Sort[11]跟踪算法,是一种简单的在线实时行人跟踪算法,首先检测出视频中的行人,再利用卡尔曼滤波器预测行人轨迹,最后利用匈牙利算法进行线性分配。其优点是跟踪速度快,缺点是该算法几乎不对遮挡环境下行人进行处理,因此该算法的ID Switch 较多。针对Sort 跟踪算法中目标ID 切换频繁的问题,该团队又提出的Deep-Sort[12]跟踪算法,在Sort 跟踪算法基础上加入了深度外观特征和级联匹配,利用一个轻量级的卷积神经网络去提取行人的外观特征并保存下来,最后结合级联匹配,在遮挡的环境下大量降低行人的ID Switch 现象,但是该算法要用卷积神经网络去提取行人的深度外观特征,因此该算法的运行速度会变慢。Chen等[13]提出的MOTDT算法从检测和跟踪结果输出中收集候选者来处理不可靠的检测,并且用大规模行人重识别数据集训练深度外观网络,但是整体准确率不高。Wang等[14]针对检测后再提取特征,提出一种检测和ReID 融为一体的网络,减少了重新提取行人外观特征的时间,算法运行效率变高。
基于检测器的跟踪算法在提取行人外观特征时,因行人遮挡可能会造成行人特征混淆,本文针对行人存在遮挡的情况下,用坐标判断行人是否发生遮挡,如果存在遮挡则划分遮挡区域,用非遮挡区域提取行人外观特征。针对卷积神经网络提取特征速度慢的问题,本文提出使用行人HSV 颜色特征,将颜色特征量化并提取颜色直方图,最后转化为一维向量,可以有效提升精度和速度。
2 基于深度学习和颜色特征的行人跟踪算法
2.1 算法总框架
本文跟踪算法首先使用预训练好的yolov5m_c模型检测视频中的行人,输出带有行人框的视频流,根据行人框的坐标来判断行人之间是否存在遮挡,若行人之间存在遮挡,则将行人遮挡区域像素设为0,提取非遮挡区域HSV 颜色特征作为行人特征,若不存在遮挡,则直接提取矩形框中行人的HSV 颜色特征。提取HSV 颜色特征后,量化HSV分量并提取颜色直方图,最终用一维向量表示。在跟踪阶段利用每个行人框质心的变化来预测下一帧该行人的质心和行人框大小,匹配阶段利用IOU匹配结合行人的外观特征完成匹配,最后由匈牙利算法完成分配。本文的算法总框架如图1所示。

图1 本文跟踪算法框架
2.2 yolov5行人检测算法
yolov5 是一种单阶段目标检测算法,其按照模型大小分为yolov5s、yolov5m、yolov5l、yolov5x 四种,随着模型深度和宽度的增加,检测效果和精度也会增加。yolov5 将目标检测视为一种回归任务[15],能够端到端进行训练和检测,yolov5 在yolov4 的基础上添加了一些新的改进,使其在检测精度和检测速度方面有了很大的提升。yolov5 网络结构分为主干特征提取网络、特征融合部分和检测输出三部分。主干特征提取网络采用CSPDarknet53,经过一系列卷积层和残差块完成图像特征提取,最终得到三个不同尺寸大小的特征层输出。特征融合部分不仅采用特征金字塔网络还采用路径聚合结构,目的是充分融合各个特征层的特征,有利于目标的预测。在检测输出端有三个尺度的预测输出,分别对应小型、中型和大型目标的输出。基于检测器的跟踪算法中,检测器检测的质量对跟踪的准确率影响较大,在本文行人跟踪中,首先使用预训练好的yolov5m_c 目标检测算法检测视频中的行人,输出带有行人框的视频流,然后再进行跟踪。
2.3 行人特征提取区域
在行人跟踪中,准确提取行人的特征是完成跟踪的前提,传统算法提取的Harr 特征[16]和SIFT 特征[17]仅用于未遮挡环境下行人的匹配,在遮挡的情况下会出现错误匹配的情况。在实际的跟踪任务中,会存在行人之间的遮挡问题[18],为了避免行人之间的特征发生混淆,在本文中用行人非遮挡区域的HSV颜色特征完成匹配。
首先根据行人框的坐标信息来判断行人之间是否存在遮挡,假设视频帧中的行人由左到右分为G与G,行人G左上角的坐标为G,右下角的坐标为G,行人G左上角的坐标为G,右下角的坐标为G,如果G且G则行人G与行人G之间存在遮挡,此时将对遮挡的行人框进行分割,如图2 所示,将行人框划分为遮挡区域和特征区域,遮挡区域的像素设置为0,将行人非遮挡区域作为该行人的特征区域。如果不存在遮挡,则直接提取行人的HSV颜色特征。

图2 行人遮挡区域划分
2.4 行人HSV颜色特征提取
HSV 颜色模型对颜色的描述简洁完备,H 为色调,S 为饱和度,V 一般称为明度[19]。相比RGB 颜色空间,HSV颜色空间能够非常直观地表达颜色的明暗、色调以及鲜艳程度,且与人类视觉系统对颜色感知的自然描述一致。这些特点使得HSV 颜色特征更适合图像处理。在特征提取阶段针对行人之间有遮挡的情况下,分割出行人非遮挡区域提取HSV 颜色特征,行人无遮挡的情况下则直接提取HSV 颜色特征。对行人特征区域进行HSV 颜色特征提取的流程图如图3所示。
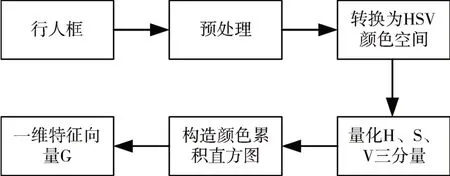
图3 行人HSV颜色特征提取流程
首先获取行人框图像,由于不同的检测框大小不同,而一幅图像中颜色直方图只与图像中颜色的组成分布有关,为了后续的特征匹配,需要对提取出来的行人框进行统一预处理,将图片裁剪到64*128 统一像素大小,然后将图像从RGB 颜色空间转换到HSV 颜色空间。为了方便后续计算,采用量化的方法,量化H、S、V 三分量为8、3、3,量化方法如式(1)所示,构造颜色特征直方图,并表示为一维向量,G是长度为72bin的一维特征向量[20]。
量化公式:
2.5 行人轨迹预测
在本文中,行人轨迹预测框的位置和大小是由前两帧行人跟踪框质心变化来确定的,由于第一帧只有检测框,没有跟踪框,首先要初始化跟踪对象[21]。从第三帧开始行人轨迹预测,假设当前为第t帧,其前一帧为t-1,前两帧为t-2。假设第t-2帧行人IDi跟踪框左上角坐标表示为(xi1,t-2,yi1,t-2) ,右下角的坐标为(xi2,t-2,yi2,t-2) ,那么第t-2 帧行人IDi质心坐标Ci,t-2如式(2)所示:
其中,第t-2 帧行人IDi质心Ci,t-2的横纵坐标可表示为
同理,假设第t-1 帧行人IDi跟踪框的左上角坐标表示为(xi1,t-1,yi1,t-1),右下角的坐标为(xi2,t-1,yi2,t-1),则第t-1帧行人IDi质心Ci,t-1坐标表示为

最后,根据第t-2 帧到第t-1 帧质心坐标的变化∆xi和∆yi,以及第t-1 帧行人IDi跟踪框的w、h和Ci,t-1,可预测第t帧行人IDi的质心Ci,t坐标和行人IDi的位置。第t帧行人IDi质心坐标Ci,t可表示为

2.6 行人跟踪与匹配
在本文中使用IOU 匹配和行人HSV 颜色特征进行跟踪匹配,只有当前帧的行人轨迹预测框和当前帧的行人检测框匹配成功才能完成跟踪。IOU匹配阶段,首先计算行人检测框和行人预测框两两之间的IOU,经过1-IOU 得到代价矩阵,将代价矩阵输入到匈牙利算法中完成线性匹配,IOU 匹配的特点是速度快,但是在行人受到遮挡,或者长时间检测不到行人时,IOU匹配会重新给该行人赋予ID号,为了减少ID 切换次数,本文在遮挡情况下引入行人的外观颜色特征,结合行人的HSV 颜色特征进行特征匹配,以减少行人ID 切换次数。在行人HSV颜色特征匹配阶段,利用之前提取的行人HSV颜色特征得到的一维特征向量计算检测框和预测框之间的余弦相似度,通过1 减余弦相似度[22]得到余弦距离,使用余弦距离来衡量检测框和预测框之间的行人相似度,余弦距离公式如式(13)所示:
其中G与Gi,pre计算的是检测框与预测框的余弦相似度,余弦距离则是1 减余弦相似度。通过余弦距离来度量当前帧行人检测框和行人预测框相似程度,在遮挡情况下准确匹配行人ID,如果最小余弦距离小于所设定的阈值t,则代表当前帧行人i预测框与行人i检测框匹配成功,完成跟踪任务。
3 实验与结果分析
3.1 实验环境
本文实验操作系统为Windows,硬件环境CPU为Intel(R)Core(TM)i7-7700 显 卡 为GeForce GTX 1050TI,软件平台为python3.9+pytorch1.10 深度学习框架。
3.2 评价指标
实验中采用MOT 评价指标[23],所用的评价指标和含义如下所示,MOTA(%):多目标跟踪准确度,该度量结合了三个错误源,误报、错过目标和身份转换;IDF1(%):正确识别的检测与平均真实数和计算检测数之比。MOTP(%):多目标跟踪精度,标注框和预测框的不匹配程度;ID Sw:跟踪对象ID切换的次数;IDP(%):识别准确率;IDR(%):识别召回率;平均FPS:平均每秒运行的帧数。
3.3 不同目标检测权重实验
在基于检测器的跟踪算法中,检测质量的好坏非常影响跟踪质量,为了研究不同的检测效果对跟踪质量的影响,本文选择使用在coco数据集预训练的yolov5s.pt、yolov5m.pt和在Crowdhuman 行人数据集训练好的yolov5m_c.pt 权重进行实验,实验结果如表1所示。
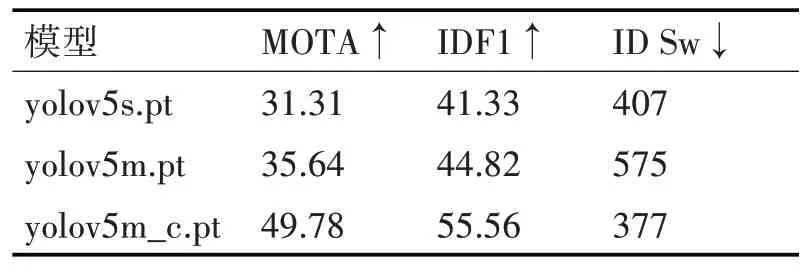
表1 不同检测模型之间对比
由表1 可以看出,针对较大模型的检测权重,检测质量好跟踪准确率高,在大模型中有针对性训练后,跟踪准确率提高较大,并且ID切换次数变少。
3.4 多行人跟踪实验
在日常环境中,行人跟踪的场景是复杂多变的,为了验证算法在真实场景下跟踪的适用性与准确性,本文选取了一段真实的监控视频,该视频中监控摄像头固定,共有274 帧,视频中有多个行人,并且部分行人在行走过程中存在遮挡情况,本文选取Sort 和DeepSort 算法进行可视化对比,部分实验结果对比如图4~6所示。

图4 Sort跟踪算法

图5 DeepSort跟踪算法

图6 Ours跟踪算法
本文算法在第8帧时检测到视频中共有5个行人,完成行人轨迹初始化并建立跟踪对象,每个行人由不同颜色的跟踪框和ID号组成。在第26帧时因为行人之间的遮挡原因,未检测到行人ID3(棕色框)和行人ID5(绿色框),到第90 帧后重新检测到行人ID3(棕色框)和ID5(绿色框),并且他们的ID 号保持不变。从第164 帧到第231 帧,行人ID5(绿色框)一直在ID4(蓝色框)的遮挡下,但在跟踪中却能始终保持其ID 号唯一。本文算法在整个跟踪过程中没有发生任何ID Switch 现象,跟踪精度较高。而Sort 跟踪算法和DeepSort 跟踪算法在第164 帧到第231 帧跟踪过程中,在遮挡环境下改变了被遮挡人的ID号,发生了一系列的ID跳变现象,当遮挡结束后,前方行人的跟踪框ID 号跳变到后方被遮挡行人的身上。
3.5 公开数据集测试
为了测试本文算法的跟踪性能,本文选择在公开数据集MOT-16[24]数据集进行跟踪测试,MOT-16 是2016 年提出的多目标跟踪MOT Challenge 系列的一个衡量多目标检测跟踪方法标准的数据集,该数据集训练集包含7 个视频片段,测试集包含7 个视频片段。不仅含有固定机位拍摄,而且还有动态机位拍摄。MOT-16 数据集视频背景较为复杂,画面比较丰富,人员比较密集,行人间遮挡严重。部分实验结果如图7~9所示。

图7 Sort跟踪算法结果图

图8 DeepSort跟踪算法结果图
本文跟踪算法在行人的外观和运动方向相似时会发生ID Switch现象,如图9 第182 帧到308 帧,两个行人的运动方向和外观比较相似所以发生了ID Switch 现象,图中被遮挡住的行人ID32(红色框)跳转到了外观相似的黑衣行人身上。当运动方向相反且颜色外观差别较大时,不容易发生ID Switch。如图第308 帧到第342 帧,右侧ID23(白衣服)和ID42(黑衣服),虽然在中间ID23 会被ID42遮挡,但当遮挡结束后,ID23(白衣服)并没有发生跳变。但是Sort 和DeepSort 跟踪算法在遮挡过程中发生了ID切换、跟踪不准确现象。

图9 Ours跟踪算法结果图
3.6 不同算法之间对比
为了对比该算法的优越性,本文选择在多目标跟踪数据集MOT-16 训练集上与常见的基于检测器跟踪算法Sort、MOTDT 和DeepSort 算法进行对比。目标检测使用的检测权重是yolov5m_c 模型,该模型是在Crowdhuman数据集预训练得到。所有的实验使用相同权重、相同数据集和同一硬件平台。实验结果如表2所示。

表2 不同算法之间对比
由上表所示,本文算法在公开数据集MOT-16数据集上MOTA 为49.78%,相比于Sort、MOTDT 和DeepSort 算法分别提高1.51%、0.85%和0.33%;在IDF1分数上分别高于Sort、MOTDT和DeepSort算法7.07%、1.03%和3.46%;在ID Switch 上比Sort 算法降低了33%,比MOTDT算法降低59%,但是比DeepSort 算法略高,是因为HSV 颜色特征比深度学习提取的特征对光线变化等更加敏感。本文算法的识别精确率是最高的。由于本文实验硬件设备较低端并且目标检测模型较大,本文的平均FPS仅有7.24frame/s。Sort 算法在跟踪过程中对遮挡的人几乎不做任何处理,故其运行速度最快,但也是ID Switch 最高的。而DeepSort 算法和MOTDT 算法在提取行人深度外观信息时都会用到卷积神经网络,算法大多耗时在了提取外观特征,导致其运行速度变慢,本文的算法兼顾了精度和速度,在这几个算法中表现较佳。
4 结语
本文在兼顾跟踪精度与跟踪速度的前提下,提出了一种基于深度学习和颜色特征的行人跟踪算法,算法首先使用yolov5 目标检测算法检测出视频帧中的行人,并根据行人框之间的坐标关系选择合适的特征提取方式,有效解决行人特征匹配时的特征混淆问题。为了验证算法的有效性,在公开数据集MOT-16 上进行实验,实验结果表明,本文提出的跟踪算法与经典的Sort 和DeepSort 算法对比,不仅在跟踪精度上有所提升,并且在运行速度上比DeepSort 快。尽管该算法在相同的实验条件下具有优越性,但是仍然存在较多的ID Switch 现象,下一步的工作是进一步研究该算法ID Switch 较多的原因,降低ID Switch现象,进而提高跟踪准确率。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:59:12
阅读(快乐英语高年级)(2022年6期)2022-06-17 04:48:48
家庭影院技术(2021年10期)2021-11-20 06:08:52
电子制作(2018年19期)2018-11-14 02:37:08
紫禁城(2017年6期)2017-08-07 09:22:52
自动化学报(2017年11期)2017-04-04 02:52:58
中学数学杂志(高中版)(2016年6期)2017-03-01 18:53:58
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27 06:31:40
职业技术(2015年8期)2016-01-05 12:16:46
噪声与振动控制(2015年4期)2015-01-01 07:08:21
