
基于嵌入式终端的YOLOv3 算法优化实现∗
2024-04-17 07:28:44杨争争薛少辉翟二宁
计算机与数字工程 2024年1期
侯 勇 杨争争 薛少辉 翟二宁
(西北机电工程研究所 咸阳 712000)
1 引言
目标检测技术是从特定复杂场景中提取并自动识别出感兴趣目标的类别和位置坐标信息,目前已经被广泛应用于视频监控、目标跟踪和军事侦察等领域。鉴于传统的目标检测算法均存在识别准确率低、跨平台移植性和鲁棒性较差等问题,在分类任务上大放异彩的深度学习技术已成为该研究任务的主要手段。目前基于深度学习技术的目标检测算法主要划为两类:一类是先提取候选区域再进行目标检测的双步式(Two-stage)检测,另一类是设计端到端网络直接进行回归预测的单步式(One-stage)检测[1]。
其中,双步式目标检测方法分两步进行,第一步采用选择性搜索算法大致检测出目标区域的所在位置,第二步对目标区域位置采取精细化后再进行全局整合。这类最具代表性的算法是RCNN[2]、Fast-RCNN[3]和Faster-RCNN[4],也被称为RCNN 系列检测算法。
由于该类算法采取了较为精细化的目标区域特征提取方式,相较于传统使用滑窗遍历提取特征进行目标识别的算法,其在检测准确度和速度上都有了较大的进步。但由于其检测过程需要两个步骤,而导致计算量较大,耗时较长,无法满足实时性需求。随后,相关研究者提出了基于回归的单步式检测方法。
单步式检测方法采用端到端式网络结构仅需要一步就可以完成整个目标检测流程。单阶段代表性检测方法包括:SSD[5]、YOLO 系列[6~9]。该类算法不再预先进行目标候选区域的预测,而是直接通过网络回归的方式输出待测目标的类别与位置坐标信息。相比较双步式目标检测方法,该类算法采用的端到端式检测流程大幅度地提高了检测效率。同时,在该类以检测速度著称的算法中,YOLO算法取得了非常好的目标检测效果,并且在很多场景中已经实现了工程化落地应用[10~13]。并且提出团队对该算法进行了系列优化,本工作中使用已经工程化应用的YOLOv3 算法来进行轻量化目标检测任务的训练学习,并将训练好的模型部署在百度EdgeBoard 计算盒上,实现轻量化检测模型的嵌入式终端落地应用。
2 嵌入式终端介绍
本文基于百度EdgeBoard-FZ9B 边缘AI 计算盒进行深度目标检测模型的部署,该计算盒基于Xilinx Zynq UltraScale 和MPSoCs开发平台打造,采用Xilinx FPGA 核心处理器将多核ARM Cortex-A53 和FPGA 可编程逻辑集成在一颗芯片上,并在此基础上搭载了丰富的外部接口和设备[14]。
2.1 硬件环境
百度EdgeBoard 边缘AI 计算盒中内含嵌入式FPGA高性能计算卡和深度模型嵌入开发工具包以及AI 模型加速工具包等,具有强悍的终端加速性能。Xilinx FPGA 高性能的加速引擎提供3.6Tops的强大AI 算力,经典分类模型Resnet50 部署在计算盒上实测可达到60FPS处理速度,且用户可以根据需要输入百度大脑预置或自定制算法模型。EdgeBoard 边缘AI 计算盒具有丰富的开发资源:定制化图像识别开发平台(EasyDL)、视频监控开发平台(EasyMonitor)和开源深度学习平台(Paddle-Paddle)。如图1 展示了EdgeBoard AI 计算盒实物图。

图1 EdgeBoard AI计算盒实物图
EdgeBoard 灵活的芯片架构,可适配行业内最前沿、效果最好的算法模型。基于EdgeBoard 打造的软硬一体化产品,可应用于安防、工业、教育、交通等各个场景。EdgeBoard 计算盒参数指标如表1所示。

表1 EdgeBoard-FZ9B计算盒性能参数
2.2 软件环境
EdgeBoard计算盒基于Linux系统,整个开发过程就是一个Linux应用程序的开发。应用程序获取视频输入,调用预测库加载模型,调度模型,驱动加速模块进行计算,加速模型运行,获得运行结果。EdgeBoard计算盒的软件架构如图2所示。
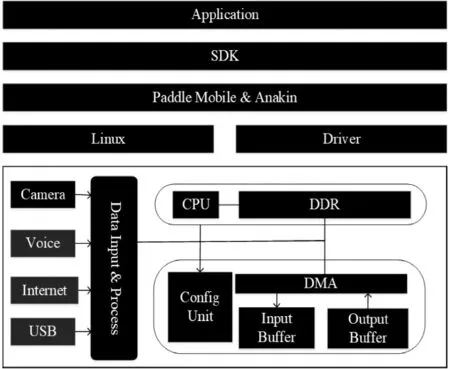
图2 EdgeBoard边缘AI计算盒软件架构
典型图像识别模型在EdgeBoard-FZ9B 计算盒上的性能数据如表2所示。

表2 典型识别模型在计算盒上的性能数据
3 YOLOv3模型优化
3.1 YOLOv1
YOLOv1 网络首先提取输入待测图像的特征图并将其划分成S*S 个网格,然后用每个格子来预测所含目标物体的矩形边界框、目标所属类别的概率和置信度。其中,目标边界框信息包含了五个预测信息,具体包括目标物体的中心位置坐标(x,y),目标的宽w 和高h 以及预测物体边界框相对于真实目标标注框(Ground Truth)的重合百分比即IOU,也称为目标预测框的置信度。检测时,将每个网格所预测目标的类别概率和每一个目标预测边界框的置信度相乘,就得到了该目标边界框所属类别的准确度,如式(1)所示:
上式中,Pr(Class|Object)表示边界框预测目标类别的信息,Pr(Object)表示预测边界框内是否含有目标,IOUp表示目标预测边界框坐标的准确度。YOLO 算法在实际训练模型时,会选择网格上与目标物体真实标注框重合百分比即IOU 最大的边界框来预测目标物体位置信息。
随着网络模型的训练迭代次数增加,检测精度也在不断提升。但实际应用中YOLOv1 也显示出了弊端:
1)因为每个划分的网格只能预测一个目标类别和两个矩形边界框,当存在多个目标中心落入到一个格子的情况时,模型最终检测的准确度将无法保证。
2)v1 框架中没有考虑到不同比例尺度大小的预测边界框设计,需要借助大量数据来支撑模型训练,严重限制了算法模型的泛化能力。
3.2 YOLOv2
YOLOv2是v1模型的升级版本,v2在v1检测网络架构基础上,优化使用了骨干网络框架Darknet-19,并去掉了Dropout 机制从而使得整个网络模型更容易得到充分训练和收敛。为了进一步减小冗余的模型参数提高计算效率,舍弃了分类任务常使用的全连接层而改用效率更高的全卷积来进行运算。同时,相对于v1 网络架构,v2 中添加了高效率的anchors 多比例尺度预测框机制,更精细化地预测模型输出边界框相较于目标真实标注框的偏移量。在模型训练时,通过输入不同尺度大小的图像来进一步提升模型泛化能力。同时使用了K-means 聚类算法在训练数据集的真实标注框中产生目标物体对应的先验框。
3.3 YOLOv3
相较于v1、v2,YOLOv3 模型整体增加了整个网络的深度,提出了Darknet53 的骨干网络框架。其借鉴了ResNet[15]网络的思想,多次使用了残差的跳层连接方式,同时为了提取更丰富的高级语义特征信息,V3 网络中去掉了池化层与全连接层,而是使用步长为2 的卷积操作来替代传统的池化层对较大特征图进行下采样操作。同时结合多尺度预测机制,YOLOv3网络结构如图3所示,分别在三种尺度上进行目标检测,每种尺度的特征图各产生三个预测框,每个目标框返回四个坐标参数。YOLOv3 使用逻辑回归判定每个边界框的目标评分,如果预测框与真值框重叠超过某一阈值,则设置其目标评分为1,最后根据目标评分结果选择对应的预测框。

图3 原始YOLOv3网络结构
3.4 YOLOv3网络优化
为了进一步优化模型参数,提升检测模型的推理速度,本文将原始骨干网络Darknet-53 替换为高效的轻量化网络MobileNetv1[16]。Mobile-Netv1 网络主要利用点卷积和分组卷积操作来替代原来的标准卷积操作,可以极大地消除网络中卷积运算部分,从而使得网络整体计算量和复杂度大大减小。我们将该网络模型命名为YOLOv3-MobileNetv1,详细的网络结构如图4 所示。
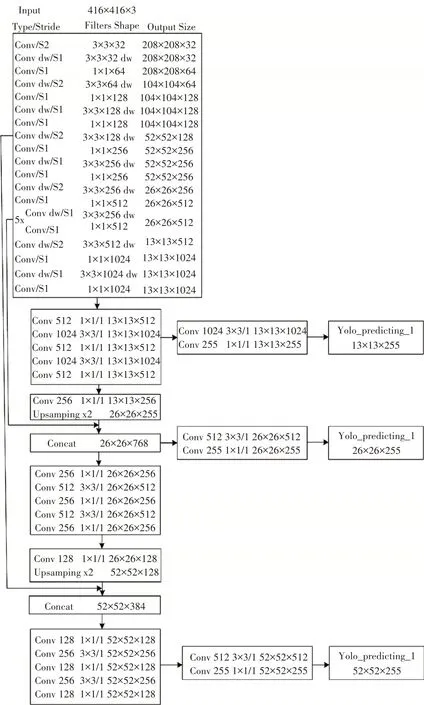
图4 YOLOv3-MobileNetv1网络结构
4 YOLOv3模型优化与部署
4.1 实验环境
本节对优化后的YOLOv3-MobileNetv1 模型进行训练和部署,实验中用到的软硬件环境如表3 所示。

表3 实验软硬件环境
4.2 实验数据集
在目标检测领域,PASCAL VOC 数据集是经典且具有影响力的基准数据集。PASCAL VOC 从2005 年开始举办挑战赛,数据集包含的样本数量和类别也在不断完善更新。PASCAL VOC 数据集的层级结构如图5所示。

图5 PASCAL VOC数据集层级结构
在本工作中,我们采用VOC2007 数据集来训练和测试优化后的YOLOv3 网络。该数据集的样本统计信息如表4所示。

表4 PASCAL VOC2007数据集统计信息
4.3 目标损失函数
YOLOv3-MobileNetv1 网络的目标损失函数如式(2)所示。共分为三部分:坐标预测误差,置信度预测误差和类别预测误差。网络在预测目标位置时将特征图划分为S*S 个网络,每个网络又分别产生B 个目标候选框,每个候选框经过迭代优化会得到相应的Bounding Box。

4.4 网络训练配置文件
表5 分别定义了YOLOv3-MobileNetv1 网络训练过程中的学习率Lr、优化器Optimizer、迭代次数Iter和Batch Size等参数。

表5 网络训练配置文件
4.5 检测模型识别性能评估
通常,PASCAL VOC 数据集检测性能的评价标准为MAP,即数据集中所有类别目标的检测准确率平均值,本工作中沿用该评价标准。
4.6 实验结果分析
在PASCAL VOC2007 训练集上优化好网络模型后在相应的测试集上进行测试,得到的测试精度MAP为76.2%。
同时,在图6(a)~6(b)中展示了训练收敛的模型在PASCAL VOC2007 测试数据集上得到的部分检测结果。其中,上边是原始测试图像,下边是训练收敛的YOLOv3-MobileNetv1 模型推理得到的目标检测结果,检测结果图包含了预测目标的类别、置信度和位置坐标等信息。

图6 测试结果展示
从图6(a)~6(b)展示的部分测试结果来看,优化后的YOLOv3-MobileNetv1 模型对于行人、风筝等小目标均具有良好的检测识别效果。
接下来将训练收敛好的检测网络模型部署到EdgeBoard-FZ9B 计算盒上,同时在互联网上采集了一些飞机、坦克等典型军事目标图像,并基于计算盒使用该模型进行检测,测试结果如图7(a)~7(b)所示。其中,上边是原始测试图像,下边是计算盒上部署模型推理的检测结果。

图7 计算盒部署模型测试结果展示
从图7(a)~7(b)展示的测试结果来看,计算盒上部署的YOLOv3-MobileNetv1 模型对于飞机、坦克等典型军事目标图像均具有良好的检测识别效果。
5 结语
近年来,目标检测技术广泛应用于视频监控、目标动态跟踪和军事侦察等多个领域。本文首先对先进的YOLOv3 目标检测模型进行了轻量型优化,将骨干网络Darknet-53 替换为更为高效的MobileNetv1网络,极大地缩减了网络模型的参数和计算量。之后基于经典的PASCAL VOC2007 图像目标检测数据集对YOLOv3-MobileNetv1 模型进行了充分训练,并在相应的测试集上取得了76.2%的高识别准确度。之后将训练收敛的模型部署在百度EdgeBoard-FZ9B AI 计算盒上,并采集了部分互联网上的图像进行测试。实验结果表明优化后的YOLOv3-MobileNetv1 检测模型具有优良的目标识别性能,并可以高效地部署到嵌入式终端以实现目标识别技术的落地应用。但同时由于PASCAL VOC数据集的训练样本有限,在一定程度上限制了模型的最终识别性能。在下一步研究工作中,可以进一步采取一些手段来扩充训练的数据样本量,并通过充分训练来获取准确率更高的深度检测模型,以更高效地部署到嵌入式终端。
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
儿童时代·幸福宝宝(2021年11期)2021-12-21 06:18:46
幽默大师(2020年11期)2020-11-26 06:12:12
摄影之友(影像视觉)(2019年3期)2019-03-30 01:37:20
摄影之友(影像视觉)(2019年2期)2019-03-05 08:27:26
摄影之友(影像视觉)(2018年12期)2019-01-28 09:01:20
证券法律评论(2018年0期)2018-08-31 02:33:08
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
