
基于学习风格的个性化自适应资源推荐算法研究∗
2024-04-17 07:28王浩畅潘俊辉MariusPetrescu
计算机与数字工程 2024年1期
王浩畅 王 辉 潘俊辉 Marius.Petrescu 张 强
(1.东北石油大学计算机与信息技术学院 大庆 163318)(2.普罗莱斯蒂石油天然气大学 什蒂 100680)
1 引言
随着数据时代的迅猛发展,海量数据蕴含着巨大的价值,大数据的分析、挖掘及运用已经渗透到社会生活的各个领域[1]。与国内电子商务领域知名平台相比,如“淘宝”、“百度新闻”等平台的个性化推荐服务已成功融入人们生活,然而大数据推荐服务在教育领域中的发展与应用滞后很多,显得相对缓慢[2]。疫情期间,随着移动互联网应用技术和教育信息化的深度结合,各类在线教学平台比比皆是,但在教育领域,一直以来都未能真正解决“因材施教”的问题,传统教学平台仅作为提供知识仓库的载体,几乎没有关注到学习者个体的不同需求,不能保证及时调整教学策略[3]。
由于推荐算法设计单一且不到位,推荐内容往往不够“精准”[4]。利用现代信息技术和大数据技术,注重个体特征的个性化自适应学习,实现智慧教育,已成为顺应信息时代创新、培养具备应用能力合格人才的迫切需要[5]。本文结合已有的在线教学平台实际资源,探索基于学习风格的混合式个性化自适应学习资源推荐算法的研究与实践。
2 个性化自适应学习
个性化学习的概念,最早来源于孔子提出的“有教无类”教育思想。自适应学习是指通过动态调整学习资源,为学习者提供个性化服务的一种学习方式,能够根据学习者表现的个性特征,进行动态预测及策略调整,保证推送学习资源及学习途径的差异化、精准化,以期实现最优的学习效果。
国外较早开展了个性化自适应学习的研究。1959 年,美国开启了自适应学习的先河,成功开发了第一个计算机辅助教学系统[6]。自21 世纪初以来,国外对于自适应学习的研究呈整体上升趋势,研究范围逐步扩宽,美国的Peter Brusilovsky、荷兰DeBra 以及澳大利亚Wolf 等也陆续研发了诸多个性化教育系统,得到了研究界普遍认可,陆续涌现了诸如Knewton、Knowre等著名自适应学习平台[7]。
自21 世纪以来,随着科技的迅猛发展,个性化自适应学习也逐渐引起国内学者专家的重视,各种计算机技术层出不穷,语义网本体技术、文本挖掘、模糊逻辑、进化算法、贝叶斯网络、推荐算法[8]等先进技术也陆续被应用于自适应学习系统[9]。例如,姜强等提出的个性化自适应在线学习分析模型,在国内一直处于领先水平[6]。
3 基于学习风格的个性化自适应资源推荐算法
个性化自适应学习模式,以学习者学习风格为中心,从学习者实际情况出发,运用大数据相关技术给出个性化动态调整,最终为学习者提供有效的资源推荐。
3.1 学习风格
学习风格是指学习者在学习时所表现出来的学习方式,简言之,学习者在研究和解决某个学习任务时,所表现出来的具有个人特色的或偏爱的某种学习方式[10]。自1954 年,赛伦提出学习风格概念之后,陆续出现了很多有关学习风格模型的研究。其中,以Felder-Silverman 学习风格模型应用最为普遍,它将学习风格划分成了四个维度八个属性,如表1所示,分别为信息输入(视觉型/言语型)、信息加工(感悟型/直觉型)、内容理解(活跃型/沉思型)、感知(综合型/序列型)[11~12]。

表1 学习风格维度及属性
3.2 构建学习资源的学习风格模型
首先,需明确学习资源在每个维度分别属于哪种类型。学习者完成挑选资源的学习后,须对学习资源进行“非常满意、满意、一般、不满意、非常不满意”的评价,系统根据所有学习者的评价结果,利用式(1)计算出某项资源在某维度某类型的概率P。
其中,Pi表示评价为“非常满意”的某维度某类型的概率,m 表示“非常满意”的人数;Pj表示评价为“满意”的某维度某类型的概率,n 表示“满意”的人数。可得到每项资源在所有维度及类型上的概率Pij矩阵,如式(2)与式(3)所示。
其中,i 表示维度,j 表示维度i 对应的类型,Pi3表示对Pi1和Pi2进行归一化处理后的结果。依此,得到学习资源在各维度的风格数据,形成学习资源模型库。
3.3 构建学习者的学习风格模型
每个维度都有对应的11 道测试题,形成了获取学习风格数据的所罗门调查问卷(ILS)[13],系统会将回答结果以一个空间矩阵形式表示,如式(4)与式(5)所示。
其中,ILSi分别表示四个维度,ILSi1与ILSi2表示回答该维度的统计数据,ILSi3表示学习风格倾向。依此,得到学习者在各维度风格数据。
3.4 个性化资源推荐算法
3.4.1 基于学习风格过滤的个性化资源推荐算法
基于学习风格过滤的推荐算法,其核心思想是利用余弦相似性原理,根据式(6)计算选取学习资源与学习者学习风格相似度大的资源进行推荐[14]。
3.4.2 基于协同过滤的个性化资源推荐算法
基于协同过滤的推荐算法,其核心思想是根据式(7)计算学习者学习风格相似性来进行推荐操作,即向具有相似学习风格的学习者推荐其拥有的个性化学习资源[15]。
3.4.3 基于关联规则的个性化资源推荐算法
基于关联规则的推荐算法,其核心思想是根据学习资源中知识点内在关联的特点,向学习者推荐一些关联度较大的学习资源,进一步有效优化个性化资源推荐效果[16],如图1所示。

图1 基于关联规则的推荐算法示意图
学习资料中各知识点相互之间存在一定的关联,知识点1 与2、3、4、5 之间存在相关性,知识点2与5、8 存在相关性,知识点7 与4、8 存在相关性。当学习者获得了知识点2 的学习资源时,可通过计算知识点2 与其他知识点之间的相关性相似度,向其推荐关联度较大的学习资源。
4 个性化自适应资源推荐系统
依据因材施教的原则,以“数据挖掘”课程为例,融合个性化自适应资源推荐算法,搭建了个性化自适应学习平台。
4.1 推荐系统平台架构
个性化自适应学习资源推荐系统平台架构由三层线性架构组成,即表示层、业务逻辑层、数据访问层,如图2所示。

图2 推荐系统平台架构
整个平台不断采集学习者学习风格相关数据,利用大数据技术分析学习者学习行为数据,通过推荐算法分析,为学习者提供自适应学习路径,推荐最佳学习资源。
4.2 个性化自适应学习资源推荐流程
个性化自适应学习资源推荐系统以微信小程序作为网络教学平台,应用基于学习风格的资源过滤、协同过滤、关联规则的个性化资源推荐算法,构建了如图3所示的学习资源推荐模型。
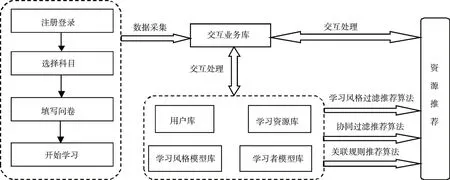
图3 个性化自适应学习资源推荐模型
学习者经过“注册-登录”、选择所学科目、填写所罗门调查问卷等一系列操作,将所产生的相关教育数据,即学习者学习风格、学习者基本信息等,逐一提交给用户库、学习风格模型库及学习者模型库等数据库。
推荐系统根据学习者产生的学习风格,采用大数据分析技术,依据基于学习风格过滤、基于协同过滤、基于关联规则的个性化资源推荐算法并行处理,确定学习需求,生成个性化学习路径,给出推荐资源,达到自建学习资源的目的。
同时,结合学习者学习行为不断产生的操作日志数据及学习者特征数据,系统可适时更新推荐算法得到的资源推荐。系统平台的操纵者,也可为学生推荐学习资源,避免“信息孤岛化”。
4.3 个性化自适应学习资源推荐效果
资源推荐服务水平的高低,取决于推荐系统关联的数据。如表2 所示,针对不同学习者,当学习同一资源时,不同算法给出了不同推荐结果。

表2 资源推荐结果对比
表2 中,学习者A 为非计算机相关专业学生,学习者B为计算机相关专业学生。当学习者A与B学习同一资源时,推荐系统根据学习者学习风格得到学习风格相似度较大的资源过滤结果,再根据相似学习风格学习者曾经的学习资源得到协同过滤推荐资源,又根据学习资源关联规则得到推荐资源,最终将三类算法推荐结果综合,得出混合推荐资源。研究结果表明,通过学习风格的分析,根据得到的资源推荐结果可以看出,系统对学习者的前期知识掌握程度进行了明显的区分,将一些前期应该掌握的专业知识推荐给了非专业学习者,而对专业学习者推荐更多的是深层次的学习资源。随着推荐系统在各类在线教学中的广泛应用,系统数据库的不断完善,推荐系统逐步实现多种方式并行的混合推荐,推荐资源精准度必定明显提升,成为必备的教学助手。
5 结语
本文针对个性化自适应资源推荐算法进行了深入的研究与分析,将基于学习风格过滤、协同过滤及关联规则过滤算法综合应用于个性化自适应资源推荐系统。研究表明,推荐系统能够为学习者提供精准的个性化资源,形成了完整的学习资源推荐生态圈。在未来的工作中,将进一步研究学习者更多个性特征,如心理特征等,并尝试更多领域的研究对比。
猜你喜欢
学生天地(2020年15期)2020-08-25
文苑(2020年4期)2020-05-30
意林·少年版(2020年2期)2020-02-18
中华诗词(2019年7期)2019-11-25
新闻传播(2018年12期)2018-09-19
海外华文教育(2016年4期)2017-01-20
汽车与新动力(2016年6期)2017-01-04
灯与照明(2016年4期)2016-06-05
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01
中国卫生(2015年1期)2015-01-22
