
基于集成学习的信用卡欺诈检测模型
2024-04-14 11:44徐天培罗永胜
信息系统工程 2024年1期
徐天培?罗永胜

摘要:旨在探讨和验证一种基于集成学习的信用卡欺诈检测模型,以提高识别欺诈交易的准确性。分析了信用卡欺诈的背景,回顾了现有的关键技术和方法,在此基础上,采用硬投票策略,将决策树、逻辑回归和朴素贝叶斯分类器三种不同的机器学习模型集成在一起,形成一个强大的集成模型。通过实验验证,该集成模型实现了高达99%的准确性,相较于单一模型至少提高了3.22%的准确性。这种显著的准确性提升归因于模型间的互补性和集成学习的稳健性。不仅为信用卡欺诈检测提供了一种高效的方法,也为其他金融欺诈检测问题提供了有价值的参考。
关键词:信用卡欺诈检测;机器学习;集成学习;硬投票
一、前言
在全球数字化的现代社会中,电子商务和在线交易已经成为日常生活和商业活动的核心组成部分。据Statista的預测,2023年全球电子商务的市场规模将达到13,190亿美元。这种交易方式的普及和便利为全球消费者和企业带来了诸多益处,但同时也伴随着日益严重的安全问题,尤其是信用卡欺诈问题。信用卡欺诈的形式多种多样,包括卡不在场的欺诈、身份盗窃、虚假交易等。根据Nilson Report的数据,2022年全球信用卡欺诈损失超过320亿美元,并且这一数字预计在未来几年中将持续上升。这些欺诈行为不仅给消费者带来巨大的经济损失,也给商家和金融机构带来沉重的经济负担和声誉损害。
因此,信用卡欺诈检测成为一个亟待解决的关键议题。虽然传统的欺诈检测方法,例如基于规则的系统和阈值检测,在一些场景下仍然有效,但它们在面对复杂和多变的欺诈模式时往往显得无能为力。因此,研究者们开始转向使用机器学习和数据挖掘技术来提高欺诈检测的准确性和效率。
机器学习方法能够通过分析大量的交易数据,识别出潜在的欺诈模式,并在新的交易中实时检测潜在的欺诈行为。尽管机器学习在信用卡欺诈检测中展现出了巨大的潜力,但设计和实施一个高效且可靠的信用卡欺诈检测模型仍然面临着许多挑战,例如数据不平衡、特征选择和模型解释性等。本文旨在提出一个基于集成学习模型的信用卡欺诈检测模型,以提高模型的检测性能,保持良好的实用性。同时,探讨集成学习模型在提高模型准确性方面的优势,并通过实验验证模型的有效性。
二、相关工作
信用卡欺诈的严重性引发了一系列的防范技术的发展。金融机构不仅要提供财务服务便利,也应保护信用卡持有人,因此,投资并研究了包括机器学习技术在内的多种检查方法。
决策树(DT)是一种被广泛使用的检测技术,尽管实施简单,但需逐一检查每笔交易。Khatri等人在一个不平衡的欧洲信用卡欺诈检测(ECCFD)数据集上分析了各种模型,结果显示DT在召回率和精确度上表现较好,而KNN在召回率和精确度上表现更佳,但时间消耗较大[1]。LightGBM技术也得到了应用。Taha和Malebary在两个数据集上进行实验,发现优化Light梯度提升机(OLightGBM)在两个数据集上均取得了最高分[2]。Vengatesan等人在不平衡的ECCFD数据集上检查了LR和KNN的性能,发现KNN在精确度、召回率和F1分数上表现最佳[3]。Puh 和Brki?c?在欧洲持卡人数据集上研究了不同算法的性能,并使用合成少数类过采样技术(SMOTE)解决了数据集中的不平衡类问题,他们使用LR创建了两个模型,结果显示静态学习和增量学习的AUC分数分别为91.14%和91.07%[4]。 Kumar等人使用RF对ECCFD数据集进行了基础研究,发现RF的准确度为90%[5]。人工神经网络(ANN)也被考虑用于信用卡欺诈检测。Asha和KR9在ECCFD数据集上使用了SVM、KNN和ANN模型,结果显示ANN在准确度、精确度和召回率上表现最佳[6]。
综观前人的研究,每种方法都能提高模型性能,但从整体考虑,应兼顾机器学习模型的准确性和泛化性。因此,有必要使用集成学习方法构建一个新的集成学习模型用于信用卡欺诈检测。
三、数据集与理论
(一)数据集
本文使用Kaggle数据竞赛网站的开源数据集,该数据集包含了284,807条信用卡交易的详细信息,每条记录包含31个特征。这些特征可能包括交易时间、金额以及可能与交易模式、客户行为和卡的安全性相关的其他变量。所有的交易细节都已经通过PCA转换,进行了匿名处理,以保护个人信息和敏感特征。唯一未经PCA转换的特征是“Class”。“Class”特征是本文的目标变量,用于标识每个交易是否为欺诈交易。在这个特征中,0表示非欺诈交易,1表示欺诈交易。
(二)理论
1.硬投票分类器
硬投票分类器(Hard Voting Classifier)是一种集成学习方法[7],它通过整合多个模型的预测结果来做出最终的预测。在硬投票中,每个模型对样本的预测被视为一个“投票”,最终的预测结果是基于多数投票的原则得出的。细节上,对于每个样本,模型预测的类别中获得最多“投票”的类别被选为最终的预测类别。
2.朴素贝叶斯分类器
朴素贝叶斯分类器是基于贝叶斯定理[8],假设特征之间相互独立。尽管这个“朴素”假设在现实应用中往往不成立,但朴素贝叶斯分类器在许多情况下仍然表现出色,特别是在文本分类和垃圾邮件过滤等领域,其简单、快速且易于实现的特点,使其成为工业领域中一个有价值的成员。
3.逻辑回归
逻辑回归是一种广泛应用于二分类问题的模型[9],它通过sigmoid函数将线性组合的结果映射到(0,1)区间,用于预测目标变量属于某一类的概率。逻辑回归在处理线性可分的问题上具有较强的表现,并且能输出概率估计,便于分析。
4.决策树
决策树[10]通过递归地分割特征空间,将特征空间划分为一系列简单的决策区域。它是一种非参数化模型,能够处理非线性关系,且模型的解释性强。决策树能够自然地处理多种数据类型,并且对异常值和缺失值具有较强的鲁棒性。
5.基于集成学习的硬投票模型
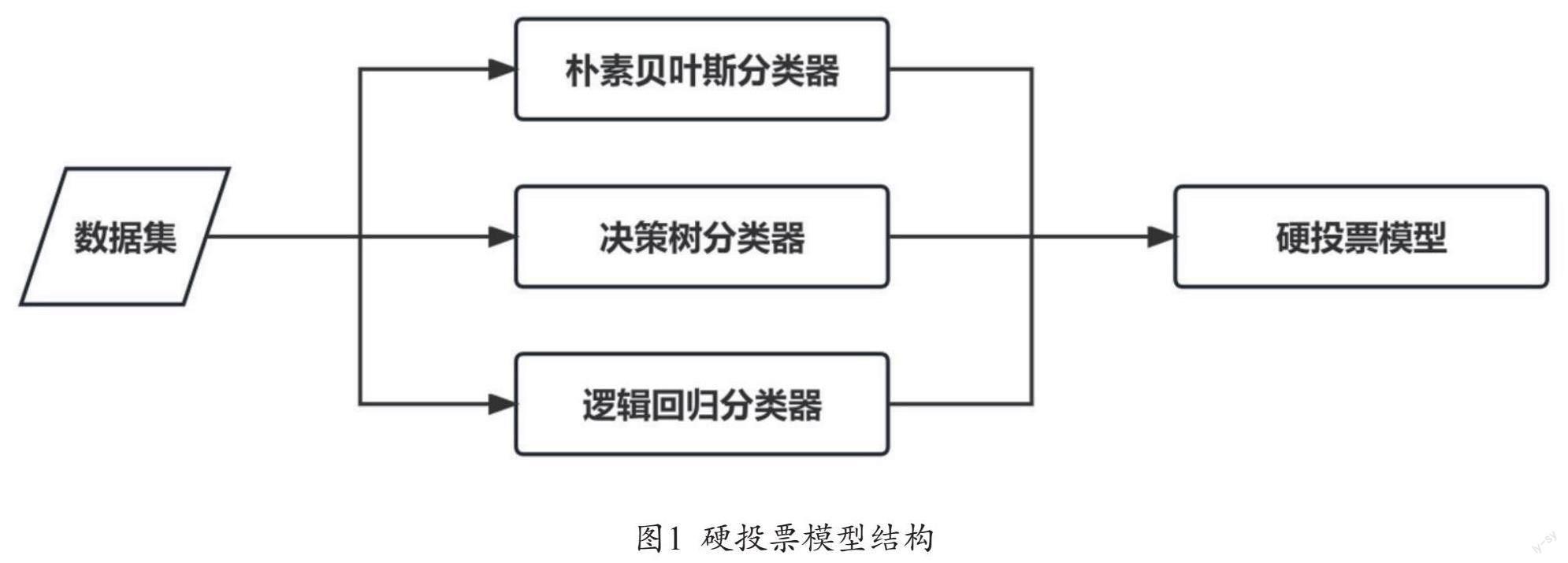
在本文中,选择了朴素贝叶斯分类器、逻辑回归和决策树这三种基础模型来构建硬投票模型,主要基于它们在不同方面的优势和计算特性的差异性,以期望在集成中实现互补和提升。对于每一个预测实例,硬投票模型会选择三个基模型中预测结果出现次数最多的类别作为最终的输出。例如,如果决策树和逻辑回归预测一个样本为正类,而朴素贝叶斯分类器预测为负类,硬投票分类器将选择正类作为该样本的预测结果,因为正类获得了更多的“投票”。
通过整合三个模型的预测能力,硬投票模型旨在减少模型的方差,提高泛化能力。由于每个基模型的计算特性和假设不同,它们在不同的数据分布和特征空间上可能有不同的表现。因此,本文期望硬投票模型能够在不同场景下提供更加稳健和准确的预测。硬投票模型结构如图1所示。
6.机器学习模型评估标准
机器学习模型的评估中,准确性(Accuracy)通常用于衡量模型预测的正确性,即正确预测的样本占总样本的比例。然而,在不平衡数据集的情境下,准确性可能不是一个可靠的指标。此时,AUC(Area Under the Receiver Operating Characteristic Curve)成为一种流行的度量,它衡量的是模型对正例的排名能力,即模型将正例排在负例前面的概率。F1分数(F1 Score)则是精确度(Precision)和召回率(Recall)的调和平均数,它在评估正负样本极度不平衡的数据集时特别有用,因为它同时考虑了模型的精确性和召回性。这些指标为本文提供了多个维度来全面评估模型的性能和可靠性[11]。
四、结果
(一)三种机器学习的模型性能
本文先对三种机器学习的模型性能进行了评估,结果如表1所示。其中,决策树分类器在所有指标上表现均衡,F1 分数为 93.91%,表明模型在准确度和召回率之间达到了一个较好的平衡。逻辑回归分类器在所有模型中表现最好,尤其在 F1 分数上达到了 98.73%,表明模型在精确度和召回率之间有着极好的平衡,且准确度也是最高的。朴素贝叶斯分类器在平衡准确度和AUC上的表现下降,这可能暗示模型在正负样本的分类上存在一些问题,尽管其准确度和 F1 分数表现尚可。
(二)硬投票结果
本文将决策树(准确度为94.91%)、逻辑回归(准确度为95.78%)和朴素贝叶斯分类器(准确度为94.83%)组合起来构建硬投票模型,可在一定程度上抵消各自的缺点,从而获得更高的准确性。通过交叉验证,实现了99%的准确度。这表明,尽管单个模型的准确度介于94%—96%之间,但通过将它们的预测相结合,达到了相对理想的预测效果。
具体而言,与原先准确度最高的逻辑回归模型相比,硬投票方法至少提升了3.22%的准确度。这种显著的准确度提升可以归因于模型间的互补性。也就是说,在某些实例上,一个模型的预测不准确时,其他模型可能能够进行正确预测。这种互补性降低了模型预测的误差和方差,从而增强了整体的准确度,这也凸显了集成学习的一个核心优点:通过整合多个模型,能够获得比任何单一模型更为强大和稳定的预测性能。
五、结语
随着数字化支付的普及和在线交易的增加,信用卡欺诈已成为一个全球性的问题,对个人和金融机构造成了巨大的经济损失。在这方面,构建一个能够精确检测欺诈行为的模型变得至关重要。
本文在相关研究基础上,审视了现有的一些方法和技术,分析了它们的表现和局限性,创造性地采用了一种硬投票策略,将决策树、逻辑回归和朴素贝叶斯分类器等不同的基模型集成在一起,实现了更高的预测准确性。实验结果表明,这种集成方法的准确性高达99%,相较于单一模型的表现至少提高了3.22%的准确性。该方法利用模型间的互补性显著提升准确性,实现了超越单一模型的稳定、强大的预测性能,为金融领域提供了一个有效的工具,帮助金融领域更高效地识别和防止信用卡欺诈行为,从而保护消费者和金融机构免受经济损失。
在未来的工作中,计划进一步探索其他的集成学习策略和不同的基模型,以进一步提高模型的预测性能和泛化能力。同时,也将探讨如何将更多的特征工程和领域知识融入模型中,以便更精确地捕捉欺诈行为的各种模式和策略。
参考文献
[1]Khatri, S.; Arora, A.; Agrawal, A.P. Supervised machine learning algorithms for credit card fraud detection: A comparison. InProceedings of the 2020 10th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida,India, 29–31 January 2020:680–683.
[2]Taha, A.A.; Malebary, S.J. An intelligent approach to credit card fraud detection using an optimized light gradient boosting machine. IEEE Access 2020, 8:25579–25587.
[3]Vengatesan, K.; Kumar, A.; Yuvraj, S.; Kumar, V.; Sabnis, S. Credit card fraud detection using data analytic techniques. Adv. Math.Sci. J. 2020, 9:1185–1196.
[4]Puh, M.; Brki?c, L. Detecting credit card fraud using selected machine learning algorithms. In Proceedings of the 2019 42ndInternational Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Zagreb,Croatia, 20–24 May 2019: 1250–1255.
[5]Kumar, M.S.; Soundarya, V.; Kavitha, S.; Keerthika, E.; Aswini, E. Credit card fraud detection using random forest algorithm. InProceedings of the 2019 3rd International Conference on Computing and Communications Technologies (ICCCT), Chennai, India,21–22 February 2019: 149–153.
[6]Asha, R.; KR, S.K. Credit card fraud detection using artificial neural network. Glob. Trans. Proc. 2021, 2:35–41.
[7]黃富幸,韩文花.基于Voting机制的IMA-BP不平衡数据分类算法[J].科学技术与工程,2023(27): 11698-11705.
[8]周妹,常建华,陈思成,等.一种基于朴素贝叶斯分类器的气溶胶类型识别模型[J].光学学报,2022,42(18):49-57.
[9]孟云伟,张熙衍,青光焱,等.基于Logistic回归的高速公路交通事故后果的影响因素分析[J]. 武汉理工大学学报 (交通科学与工程版). 2022,46(01): 12-16.
[10]吕志鹏,郑丁丁,郭琼,等.决策树算法对整家定制家居购买决策的预测研究[J].林产工业,2023,60(05):88-92.
[11]卢冰洁,李炜卓,那崇宁,等.机器学习模型在车险欺诈检测的研究进展[J].计算机工程与应用,2022,58(05):34-49.
基金项目:博士基金研究项目“基于大数据技术的电信用户行为序列化分析在欺诈识别中的应用研究”(项目编号:2023BSJJ16)
作者单位:徐天培,呼伦贝尔学院;罗永胜,呼伦贝尔市公安局伊敏分局
责任编辑:尚丹
猜你喜欢
科教导刊·电子版(2017年22期)2017-09-20
时代金融(2016年36期)2017-03-31
科技创新与应用(2017年6期)2017-03-23
现代电子技术(2017年1期)2017-02-16
电子技术与软件工程(2016年22期)2016-12-26
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
科教导刊·电子版(2016年10期)2016-06-02
科技视界(2015年27期)2015-10-08
