
政策文献量化研究中的PMC指数模型应用述评
2024-04-14 13:33方思越刘清
现代情报 2024年4期
方思越 刘清

关键词:政策文献量化:PMC指数模型:计量分析:综述
当前,政府治理现代化不断推进,政府信息公开制度已逐步完善。同时,伴随着统计学、计量学、数据可视化等学科和方法的不断发展,以政策文献为研究对象的公共政策研究有了更为广阔的发展空间,政策文献量化研究这一分析视角也获得了更多的关注。政策文献量化研究将语言表述的非结构化的政策文本转化为使用数量表示的资料,并使用统计数字描述分析的结果,在研究的过程中克服质化政策研究中的主观性和不确定性,从而得到相对直观和精确的政策认知。
近年来,政策文献量化研究蓬勃发展,使用的方法也更加多元,典型的研究方法有政策计量分析、政策内容量化和政策文本挖掘3个类别,而政策内容量化的主要类型又包括基于政策文本描述性量化分析结果,再使用PMC指数对政策进行绩效评价。PMC指数模型(Policy Modelling Consistency)由MarioArturo Ruiz Estrada(下文简称Estrada)于2011年提出。该模型被引入国内后在政策文献量化研究中得到了较为充分的应用,但具体应用情况仍未明晰,同时也未见对该模型本土化应用上的系统梳理。鉴于此,本文对目前国内使用PMC指数模型的研究进行梳理,计量分析当前研究现状,整理出PMC指数模型的一般流程,讨论使用过程中存在的问题并给出相应的建议,以期为PMC指数模型后续的实践提供一定的借鉴。
1研究设计
1.1研究问题
梳理政策文献量化研究中的PMC指数模型应用研究,首先需要厘清研究问题。Estrada提出的PMC指数模型用于评判政策建模的一致性。政策建模是通过使用不同的理论、模型和技术对任意政策进行分析评估的学术或实践工作,其本身即可被理解为一种对政策的评价工作。PMC指数模型的提出基于“Omnia Mobilis”假说,即“一切都在运动中”,在政策建模中不应忽略任何相关变量。然而,当PMC指数模型被引入国内后,却多被用于政策文献的评价之中。从政策建模的评价到政策文献的评价,这种本土化应用是本研究的主要关注点。由此衍生出本研究主要讨论的3个问题:①国内PMC指数模型应用现状如何?②国内学者是如何使用PMC指数模型的?③如何更合理地应用PMC指数模型?
1.2数据来源与处理
本研究的目标文献是应用了PMC指数模型的期刊文献,选取的数据库为中国知网数据库和维普中文期刊服务平台。本研究制定的文献选择阶段和标准为:①文献检索。根据研究主题,PMC指数模型在应用上与“政策”这一关键词息息相关,且“PMC”暂无代称,因此使用“政策”与“PMC”的组合作为检索词进行学术期刊文献检索,设定检索字段为篇关摘,出版年度结束年为2022年;②文献去重。剔除重复文献;③文献筛选。此阶段主要判断文献是否完整地使用了PMC指数模型。对标题和摘要进行浏览,剔除与政策文献量化研究无关的内容,如省直管县(Province Manage Country,PMC)和项目管理承包模式(Project ManagementContracting.PMC)等的研究;对正文进行浏览,剔除没有描述PMC指数模型应用全过程的文献。最终,本研究确定的目标文献为169篇。
1.3研究方法
研究主要采用计量分析的方法。针对问题①,对目标文献的发布时间、刊载期刊、作者信息和关键词进行统计分析,得到国内PMC指数模型应用的发文趋势、期刊分布、主要作者、机构和主要研究主题;针对问题②,对目标文献进行深入阅读,结合原PMC指数模型,提炼出本土化应用的一般流程,再对流程每一阶段进行描述分析;在问题①和问题②的基础上,对问题③展开讨论,给出更合理使用PMC指数模型的建议。
2研究结果分析
2.1目标文献统计分析
2.1.1发文趨势
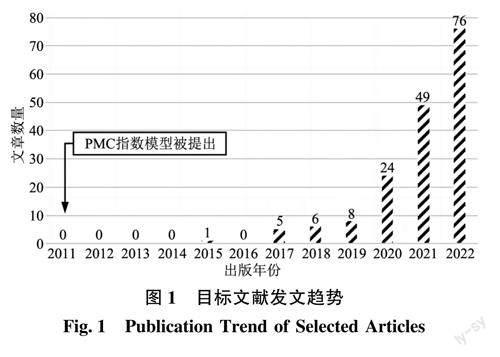
对目标文献进行发文趋势统计,如图1所示。201 1年,Estrada设计PMC指数模型,2015年国内首次将该方法引入。发文量呈逐年增长趋势,2015-2022年,发文量从1篇增长到169篇。可见,PMC指数模型在国内正越来越多地被应用。
2.1.2期刊分布
对目标文献来源进行统计,如图2所示。目标文献分布于113本不同的期刊上,收录量为5篇及以上的期刊分别为《中国科技论坛》《科技进步与对策》《情报杂志》《软科学》《统计与决策》和《科技管理研究》,总占比21.89%。其余期刊的收录量均在5篇以下,有88本期刊只发了1篇相关文献,说明应用了PMC指数模型的期刊文献分布较为分散。
参考数据库中的专辑名称、专题名称和期刊描述对期刊进行分类统计,如图3所示。有100篇文献分布在55本管理科学类的期刊上,占总文献量的57.17%,有31篇文献分布在26本大学学报上,20篇文献分布在13本医药卫生科技类的期刊上,另外,在教育学、体育学、信息科学等领域的期刊上也都有应用了PMC指数模型的文献。在不同类别期刊上的分布说明应用了PMC指数模型的文献多分布于管理科学类的期刊上,且在其他学科领域也获得了一定的认可。
2.1.3作者信息
对作者的发文次数进行统计,共有411位不同的作者。发文量排名前3的作者分别为张永安教授(北京工业大学经济与管理学院,8篇),杜宝贵教授(东北大学文法学院,4篇)和褚淑贞教授(中国药科大学国家药物政策与医药产业经济研究中心,4篇)。其中,张永安教授是首位将PMC指数模型引入国内的学者。
对第一作者的相关信息进行统计,共有145名不同的第一作者,发文量排名前5的作者分别为张永安教授(北京工业大学经济与管理学院,8篇),杜宝贵教授(东北大学文法学院,4篇),周海炜教授(河海大学商学院,3篇),沈俊鑫教授(昆明理工大学管理与经济学院,3篇)和刘纪达博士(哈尔滨工业大学经济与管理学院,3篇)。对这些作者所属的机构进行统计,共涉及101个不同的机构。其中,有8名不同的作者来自北京工业大学的经济与管理学院,涉及16篇目标文献;6名不同的作者来自河海大学(5名来自商学院,1名来自公共管理学院),涉及9篇目标文献;6名不同的作者来自中国药科大学,涉及6篇目标文献。通过对作者信息的统计可以发现,以张永安教授为代表的北京工业大学经济与管理学院在PMC指数模型的应用上有较多经验,作者的分布相对分散。
2.1.4研究主题
对目标文献的关键词进行统计,排名前3的研究主题如表1所示。研究主题中,“政策量化评价”的出现频次位列第一,与“PMC指数模型”不相上下,但与“文本内容分析”这一主题拉开了较大差距。研究主题的排序印证了PMC指数模型多应用于政策文献量化研究,尤其是政策量化评价中,且部分研究还应用了其他文本内容分析的方法。
通过对关键词的统计还可以发现,这些文献选取的政策来自不同的领域,按照《国民经济行业分类》(GB/T4754-2017)将目标文献涉及的政策内容进行划分,并映射到经济、政治、文化、社会、生态文明五大建设中。排名前3的政策领域如表2所示,分别为公共管理、社会保障和社会组织,科学研究和技术服务业以及租赁和制造业。五大建设中的分布如图4所示,相关研究分析的政策在这五大建设中均有涉猎,其中最多的是有关经济建设的政策。
2.2目标文献PMC指数模型应用分析
Estrada提出的PMC指数模型分为6个步骤:①构建多投入一产出表;②确认变量和具体参数;③PMC指数计算:④构建政策建模的一致性评价标准:⑤绘制PMC曲面图:⑥根据评价标准分析政策建模的优劣势。而通过对目标文献的梳理,可得国内学者应用该模型时主要分为政策文本搜集与预处理、指标体系构建、PMC指数计算、PMC曲面图绘制和政策综合分析5个步骤,如图5所示。
2.2.1政策文本搜集与预处理
在政策文本搜集与预处理部分,学者们依据需要分析的主题设计关键词,在专业政策数据库(北大法宝、北大法意、白鹿智库等)和相关政府网站上搜集政策文本。根据文本的相关性和有效性筛选出研究需要的政策文献,并挖掘文本内容。部分学者使用ROST数据分析软件和(或)Python编程语言辅助识别政策文本高频关键词和主题,部分学者根据编码提取政策文本的要点,这些关键词、主题和要点是构建PMC指标体系的重要依据。
2.2.2指标体系构建
使用PMC指数模型的第一步是设计多投入一产出表。多投入产出表在Estrada的设计中是一种量化单个政策建模文本的数据分析框架,由10个一级变量和50个二级变量构成,如表3所示。国内学者在沿用的过程中保留了含两级变量的指标体系,并根据待分析的政策文本调整各级变量的数目和内容。
对目标文献构建的指标体系进行分析。169篇目标文献中有98篇构建了10个一级变量.65篇构建了9个一级变量,各有两篇文献构建了13个和16个一级变量,各有1篇文献构建了7个和8个一级变量。构建的二级变量数量最少为25个,最多为77个,为40个二级变量的文献数量最多。出现频次前10的一级变量和相应的二级变量示例如表4所示。
这10个一级变量分别为政策性质、政策时效、政策评价、政策领域、政策公开、政策功能、政策视角、政策内容、政策工具和发布机构。在相应的二级变量设计上:①政策性质。二级变量除了示例中的预测、监管、建议、描述、引导之外还有诊断、导向、判定、倡议、支持、稳定、规范、试行等;②政策时效。二级变量中的长期、中期、短期主要有两种时长划分方式:一是将长期划分为10年以上,中期5~10年,短期1~5年;二是将长期划分为5年以上,中期3~5年,短期1~3年;③政策评价。二级变量的设计是研究者对政策文本的主观判读,除了示例中的依据充分、目标明确、方案科学、符合国情之外还有鼓励创新、规划翔实等;④政策领域。二级变量主要为政治、经济、社会、环境、科技;⑤政策公开。一般没有设置二级变量,主要用于判断政策文本是否公开;⑥政策功能。二级变量描述政策期望实现的功能,依据预处理时得到的关键词、主题和要点确定;⑦政策视角。二级变量主要有宏观、中观和微观,也有学者直接用宏观和微观;⑧政策内容。二级变量描述政策包含的内容,依据预处理时得到的关键词、主题和要点确定;⑨政策工具。二级指标列举政策使用的工具,描述粒度上因研究而异,示例中直接将政策工具划分为供给型、环境型和需求型,粒度较粗,部分研究直接使用下位层次的具体工具作为二级变量,如财政投入、基础设施建设、人才培育等;⑩发布机构。二级变量列举指发布政策的机构性质,不同研究在该变量的设计和表达上也有所不同。
2.2.3PMC指数计算
在构建了指标体系后,需要对变量进行计算。一般地,指标体系中一级变量的取值范围为[0,1],二级变量的取值为0或1,也有部分研究规定了具体变量的取值。根据式(1)将每一项政策的一级变量的分值进行加总,即得到相应政策的PMC指数。假设一项研究中有10个一级变量,且变量取值范围为[0,1],则其最高分为10,最低分为0。
另有学者改进了PMC指數计算的方法,提出PMC-AE指数,即利用神经网络中的自编码技术对多参数进行融合,对政策进行打分。PMC-AE指数的计算减少了人工赋值的主观性,但计算过程相对复杂。
目标文献中,有的研究会计算所有搜集到的政策文本的PMC指数,而有的研究则根据一定的标准选取部分政策文本进行计算。
2.2.4PMC曲面绘制
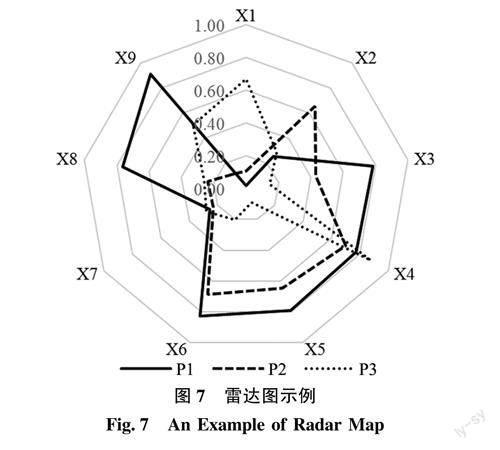
绘制PMC曲面图,是为了直观地展示各项被研究的政策在各个变量上的分值o PMC曲面绘制有两种形式:一是绘制单一政策的三维曲面图:二是将多个政策进行横向对比绘制雷达图。在绘制单一政策的曲面图时,将政策样本中的各个一级变量得分转化为矩阵形式,再进行绘制,如图6所示,假设某一政策有9个一级变量,取值分别为1.0、0.2、0.6、0.2、0.5、0、0.1、0.9、0.8,被转化为三维矩阵形式。
在绘制雷达图时,依据为政策个数和其相应的一级变量的分值,示例如图7所示(图示分值为随机生成),假设研究涉及3项不同的政策P1、P2、P3,共有9个一级指标体系。雷达图直观展示了P1、P2、P3在X1~9指标上的分值和凹陷程度。
2.2.5政策综合分析
通过政策综合分析,得出政策优化建议。目标文献中,有156篇文献沿用了Estrada划分PMC指数值等级的做法,按照PMC指数值等级对相对应的政策进行评价。Estrada将PMC指数值划分为4个不同的等级:分值在9~10为完美一致性,7~8.99为优秀一致性,5~6.99为可接受一致性,0~4.99为低一致性。国内学者沿用时,部分直接采取这一等级划分,也将政策分为完美(优秀)、优秀(良好)、可接受、不良(不及格)4个等级;部分研究则自定义等级划分,如参考百分制标准将分值划分为完美、优秀、良好、不良4个等级,亦有学者划分为不良、可接受(合格)、良好、优秀、完美5个等级。由于Estrada设计了10个一级变量,对于一级变量数量并非10的研究,等级评判的分值应当作出相应的改变,如对于设计了9个一级变量的研究,完美、优秀、可接受、不良4个层级的取值可能分别为[7,9]、[5,7)、[3,5)、[0,3) ]或[8,9]、[6,7)、[4,6)、[ 0,4)]等。没有划分政策等级的研究则直接根据PMC指数值进行分析。
在具体的分析过程中,如果研究只计算了某单一政策的PMC指数,则在给出优化建议的过程中依据其一级变量的分值给出对应的方案。举例而言,计算后发现政策P1在X4(政策领域)和X6(政策功能)上的评分较低,则可以聚焦到政策领域和政策功能的二级变量上寻找评分较低的原因,提出改进方案。如果研究计算了多项政策的PMC指数,一般会对这些政策进行分值排序,再进行单一政策的重点分析。
此外,部分目标文献并未将PMC指数模型作为主要研究内容,而是服务于整体的分析框架。最为典型的是“政策主体一政策工具一政策效力”三维分析框架。其中政策主体是依照法定权限和程序颁布相关政策文件的机构或组织:政策工具是为落实某项政策采取的相关措施或手段:政策效力是政策文本的内容效力和影响力。政策主体的识别可以通过政策文献的结构要素直接获取:政策工具主要依托Rothewell的政策工具理论,将政策文本单位化后进行编码,划分为环境面、供给面和需求面3类政策工具:政策效力使用PMC指数进行衡量。使用三维分析框架在进行政策综合分析时关注政策主体维度上各政策主体之间的协同程度,政策工具维度上3类政策工具的占比和各自的优化点,以及政策效力维度上政策的PMC指数值分析结果。
3研究讨论及结论建议
PMC指数模型在国内的应用自2015年兴起,稳步发展至今,已经成为政策文献量化研究中的重要研究方法之一。通过研究结果分析可以得知:
1)PMC指数模型在国内越来越多地被应用,且应用的学科领域较为广泛,作者分布也较为分散。以张永安教授为代表的北京工业大学经济与管理学院在PMC指数模型的应用上有较多的经验,其研究内容可作为初学者的重要参考。
2)通过统计分析,可知PMC指数模型的主要研究主题为“政策量化评价”。通过应用分析,可知在政策综合分析这一步骤中,目标文献中有156篇文章(占比92%)对计算得到的PMC指数值进行了等级划分,进一步印证了PMC指数模型在国内主要被应用于政策评价。
3)国内在PMC指数模型应用的过程中,政策文本搜集与预处理是基础,指标体系构建是核心,PMC指数计算实现量化,PMC曲面图绘制实现可视化,政策综合分析是PMC指数模型应用的最终目的。与原模型相比,指标体系更加多样化、指数计算存在改进算法、曲面图绘制新增雷达图。
通过对研究结果的进一步审视,有以下3个问题值得讨论:
1)使用PMC指数模型进行政策评价是否合理。首先,PMC指数模型的原设计是对政策建模的评价,政策建模不应该忽略任何变量。政策建模是通过使用不同的理论、模型和技术对任意政策进行分析评估的学术或实践工作。在Estrada的设计中,作者通过计算发现政策建模文章在应用研究类型、研究方向、数据源、应用的计量经济学方法、研究领域、研究理论框架、按部门划分的政策建模、经济学框架在政策建模中的应用、地理分析和论文引用这10个一级变量上的一致性。首先,如果一份政策建模的研究的PMC指数值高,则说明该政策建模研究在变量考虑上较为全面,一致性高,因此较优。但政策建模并不等于政策,故国内将PMC指数模型方法移植到政策评价上的合理性值得探讨。其次,相关研究表明,政策评价有广义和狭义之分。对政策系统及政策过程进行综合的、全方位的考察与分析,并给予评价、判断和总结的功能活动是广义层面上的评价。作为系统观念的政策评估,包括作为评估者的评估主体、作为评估客体的公共政策、作为外部條件的评估环境,以及政策评估过程与方法体系等诸多组成要素,对政策系统及政策过程某个或若干个要素及环节的评估是狭义层面的评价。鉴于此,从狭义层面去理解PMC指数模型在政策评价中的作用是可以被接受的,因为政策文本被视为是对客观事实的全面描述与建构,具有确定性和完尽性。而如果使用PMC指数模型直接判断政策的优劣,容易造成广义层面上的误解。最后,政策文本的注意力也并不能完全通过PMC指数模型体现,目标文献中,指标体系中的变量一般为不含情感的短语,如“科技供给”,而非“提高科技供给”或“降低科技供给”。因此,一项政策在某一级变量上的分值高只说明该政策在这一变量上有所描述,在某一变量上的分值低只说明该政策在这一变量上描述不足,而该政策是否需要在低分值变量部分施以更多的关注度,则需要回归政策文本,由原文决定。综上,笔者认为使用PMC指数模型进行政策评价是一种仅落在政策文本上的狭义评价,这种评价方式主要用于评价政策的完尽性。
2)怎样构建更加科学的指标体系。指标体系构建是PMC指数模型应用的核心,通过对目标文献的梳理发现,指标体系的科学性有待提高。在目标文献中,部分指标的设计可操作性不强,如“政策评价”,二级指标的设计和评价都显得主观:部分指标的设计独立性不够,如一级变量为“政策领域”,其下的二级变量既含“社会服务”又含“医疗”,“医疗”亦可以算作“社会服务”的一种:部分指标的设计在分析过程中显得冗余,如“政策公开”,不公开的政策不会出现在待分析文献集中。一般地,综合评价问题在指标体系的设计过程中需要遵循目的性、完备性、可操作性、独立性、显著性与动态性6个原则。目的性代表指标体系应具有一定的导向性,能为评价对象的改进提供方向:完备性代表指标体系指标能较全面地反映待评价对象系统的整体性能和特征:可操作性代表每项指标都可被观测和衡量:独立性代表每项指标要尽可能相互独立,互不交叉重叠,互不矛盾因果;显著性代表指标体系涵盖关键指标即可,指标数量不应过多冗余:动态性代表指标体系可根据评价的反映效果进行动态修正。笔者认为,在指标体系的构建中需要检验是否符合这6个原则。
3)怎样保证PMC指数模型使用的前后一致性。部分学者在研究过程中的搜集和预处理部分对目标领域的所有相关政策文本进行处理,但后续指数计算部分则只选取了“具有代表性的”“随机的”政策文本进行分析。这一做法的出发点可能在于对所有政策文本进行预处理,以增强指标体系的全面性,但选择代表性政策意味着丢失了研究的完备性,且存在一定的主观性,对政策的随机选择又存在不确定性。因此笔者认为,为了保证模型使用的前后一致性,在政策文本搜集与预处理阶段就确定待分析的政策文献集,这一做法也可以保证构建的指标体系中的各级变量能包含待分析文献中的全部要点。
通过对以上3个问题的讨论,精简出3条在政策文献量化分析中使用PMC指数模型的建议:①由于PMC指数模型应用于政策评价是一种狭义的政策评价,在使用PMC分值进行划分时,“完美”“优秀”“可接受”“不良”之类的描述较为粗糙,使用“合理完备”“符合预期”“有所侧重”“覆盖面窄”“适用性弱”的类似表达更为合理:②指标体系构建尽量满足目的性、完备性、可操作性、独立性、显著性与动态性的原则,尤其需要注意完备性、可操作性和独立性;③研究设计之初就确定待分析的政策文献,避免后续应用PMC指数模型时对政策文献的二次选择。
4小结
本研究系统梳理了当前国内政策文献量化研究中应用的PMC指数模型期刊文献,通过目标文献的统计分析揭示国内应用PMC指数模型的现状,通过目标文献的PMC指数模型应用分析揭示国内学者如何使用PMC指数模型,并进一步讨论了如何更合理地应用PMC指数模型。同时,本研究也存在一定的局限性。首先,为了使目标文献更具有解释性和对比性,本研究并未对学位论文进行分析:其次,本研究仅对国内应用PMC指数模型的现状进行梳理,并未考虑外文文献中的应用;最后,本研究侧重于对方法本身的描述,更适合对PMC指数模型不了解或未实践过PMC指数模型的读者。此外,还存在一些待思考的更加深入的问题,如怎样对PMC指数模型进行改进使其能更好地体现政策的关注度,怎样构建指标体系才能满足目的性、完备性、可操作性、独立性、显著性与动态性的原则,怎样选取合适的待分析政策文献等。
猜你喜欢
石油沥青(2018年6期)2018-12-29
NBA特刊(2018年21期)2018-11-24
电子制作(2018年14期)2018-08-21
中国经贸(2016年19期)2016-12-12
合作经济与科技(2016年24期)2016-12-07
商(2016年30期)2016-11-09
商(2016年21期)2016-07-06
科技视界(2016年14期)2016-06-08
功能高分子学报(2016年1期)2016-04-26
今传媒(2016年1期)2016-01-20
