
基于数据挖掘的财务预警研究
2024-04-12 09:33□文/杨卓
合作经济与科技 2024年12期
□文/杨 卓
(西安石油大学经济管理学院 陕西·西安)
[提要]上市公司的财务预警工作直接关系着对财务风险的控制效果和公司自身的整体发展。近年来,在经济下行压力加大的整体形势下,部分上市公司难以准确分析和把控复杂多变的内外部环境,从而导致自身决策失当,财务风险增加,不利于保障公司的稳定经营。因此,采用恰当科学的方法对公司可能出现的财务风险做出及时预警,进而做好应对措施,已成为当前上市公司在经营发展过程中需要解决的关键问题。基于此,本文基于数据挖掘对上市公司进行财务预警研究,并对三种模型的预测效果进行对比,分别是神经网络、决策树和Logistic回归。以便提高上市公司财务预警效率效果,使其对财务风险做出及时响应,进而提高公司对财务风险的应对能力,并提供有价值的参考意见。
一、相关概念
(一)财务风险。财务风险主要是企业客观存在的财务风险,企业由于各种各样没法控制的因素造成了损失,虽然财务风险不可能完全消除,但是可以用一些方法控制财务风险,尽量降低财务风险对企业的负面影响。
(二)财务预警。财务预警是指对企业当前的各类财务与非财务数据进行挖掘和分析,在这些数据中选出可以反映企业整体经营状况的指标,通过对这些指标进行综合评价,使得企业财务风险可以被有效识别和预测。通过开展科学有效的财务预警工作,企业能够及时识别当前经营发展过程中存在的财务风险,了解自身财务状况,并采取相关措施降低财务风险发生概率。
(三)数据挖掘。数据挖掘,即利用计算机和统计学相关技术,从海量的数据中检索对研究内容或相关决策具有一定支持的数据信息的过程。数据挖掘的对象涵盖了所有类型的数据源,包括结构化、半结构化和异构的数据,目标数据库也包括了关系数据库和数据仓库等多种类型。基于数据挖掘的信息或知识,然后通过归纳得出相关数据,最终的数据信息常常在决策支持、信息管理以及查询优化和数据库维护等方面有很大作用。
数据挖掘需要模型,有五种常用方法,分别是神经网络法、决策树算法、模糊集法、遗传算法、粗集算法。
基于数据挖掘的建模主要分为六步:一是定义问题,即定义所需查找的数据和解决的业务问题;二是构建数据挖掘库,通过数据的找寻、整合,然后进行数据质量的评估,数据挖掘库的构建就完成了;三是数据分析与描述,数据分析是找出对将进行预测影响力最大的数据,然后完成数据准备工作;四是模型构建,需要对不同模型的应用效果予以综合考量,通过开展反复的模型训练与测试,确定出最优模型;五是模型评价,对基于模型的数据挖掘结果以及模型本身的价值进行评价;六是实施,模型构建与评价结束后,应将其应用于对目标数据的挖掘当中。本文对数据挖掘在企业财务预警中应用的研究突出体现的是基于模型的财务风险预测。
二、财务预警指标选取与样本来源
(一)指标选取原则。对上市公司财务预警的指标选取应遵循以下几点原则:(1)易得性原则。指标应该可以从数据库或者是企业的财务报表中得到,降低指标选取难度和财务预警工作的复杂性。(2)真实性原则。指标都必须是真实存在的,数据必须是可以真实反映出企业财务状况。(3)可比性原则。对任意时期的任意公司都可以进行比较。(4)系统性原则。关于上市公司财务预警的各类指标不应该是分散和独立的,而应兼顾各类指标的内在关联,这样指标就可以综合反映出公司的经营状况。(5)科学性原则。选取的各种指标都应该代表性比较强,可以使研究人员以及公司各利益相关主体通过少量指标尽可能多地了解公司的财务状况。
(二)财务指标选取。财务预警指标体系最重要的构成是财务指标,因为企业的财务状况都在财务指标中反映。财务指标主要选取了四个方面,如表1 所示。(表1)

表1 财务指标选取一览表
(三)非财务指标选取。非财务指标是财务预警指标体系的核心的重要补充,主要是从公司治理的角度来确定各类指标,主要有三部分,分别是治理结构、股权结构和审计意见。
1、治理结构。主要是指公司所有者对公司经营者的一种监督,反映了公司内部管理的特点。本文主要选取了三个二级指标:独立董事人数、高管人数和监事人数。
2、股权结构。股权结构是指各股权人所持有的股份/公司总股份,本文选取了两个二级指标,股权集中度:企业持股比例在前五的股东;股权制衡度:企业持股比例在第二到第五的总和/控股股东持股比例(Z 值)。
3、审计意见。审计意见是指审计人员对企业财务报告审计结果评价。本文选取了两个审计意见衡量指标,分别是标准无保留意见(取值为1)与其他(取值为2)。
根据上述对上市公司各个财务预警指标的分析,得到如表2 所示的上市公司财务预警指标体系,相关指标的计算方式已在上文对指标进行介绍时予以说明。(表2)
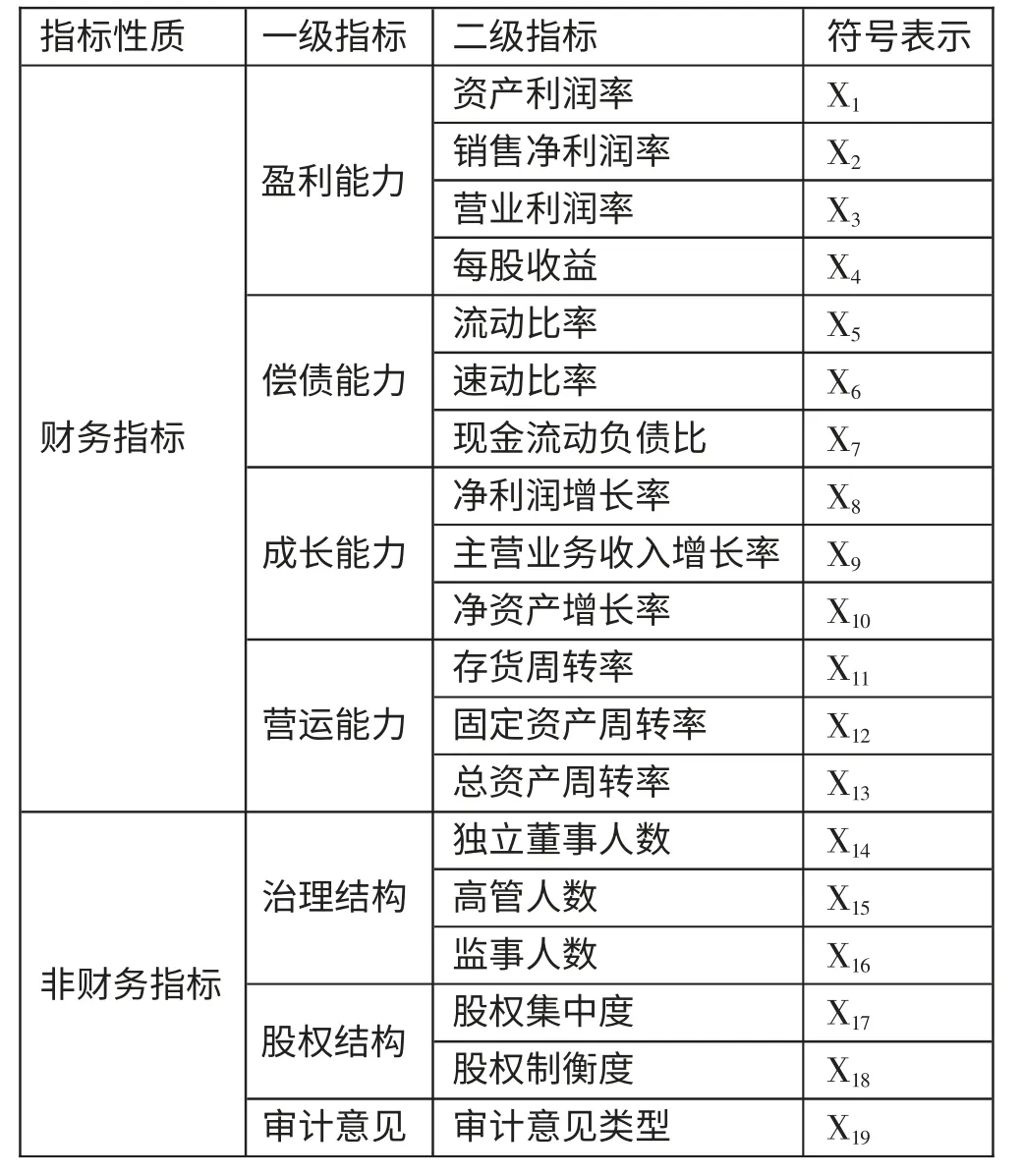
表2 上市公司财务预警指标体系一览表
(四)研究样本。本文选取的研究样本主要为在A 股上市的160 家ST 与非ST 公司。其中,80 家是2017~2019 年第一次被ST 的上市公司,再去掉5 家由于数据残缺或者金融类的上市公司,最终ST 样本有75 家公司,2017 年是15 家、2018 年是25 家、2019 年是35 家。非ST 公司与ST 公司在各个方面的选取原则都一致,公司数量同样为75 家,2017 年、2018 年和2019 年的非ST 样本公司数量同样为15 家、25 家和35 家。在样本数据的确定与选择方面,本文假设ST 公司被特别处理的年份为T,那么(T-1)年则表示被处理的前一年,(T-2)年则表示被处理的前两年,相关数据来自Wind 数据库与Csmar 数据库。
(五)显著性检验。进行显著性检验,对上述财务预警指标体系先确定出各个变量对财务预警是否有影响。对19 个变量进行正态分布检验,有两个结果:如果满足正态分布,则对变量进行独立样本T 检验;如果不满足正态分布,则用M-W(U)非参数检验,对各类财务指标是否对财务预警有影响的确定方法是判断P 值(是否<0.05)。
首先,对(T-2)年的财务预警指标进行正态分布检验后,检验结果是有两个指标满足正态分布,则对流动比率和股权集中度进行独立样本T 检验,结果如表3 所示。(表3)

表3(T-2)年独立样本T检验结果一览表
根据表3,股权集中度检验结果并不显著,只有流动比率通过了T 检验,故将其作为财务预警变量予以保留。对于其他非正态分布变量,进行M-W(U)非参数检验,本文直接给出通过显著性检验的指标,如表4 二级指标所示,通过显著性检验的指标共11 个,各变量平均值如表4 所示。(表4)
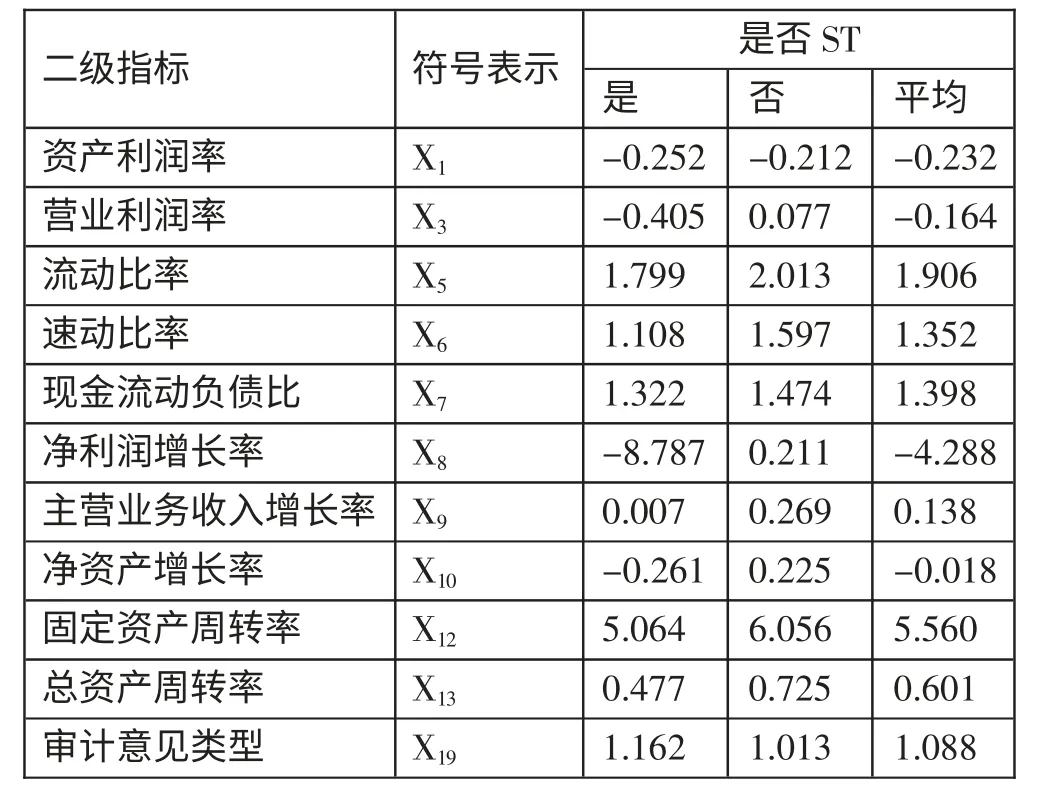
表4(T-2)年通过显著性检验的变量平均指标一览表
根据表4,(T-2)年非ST 公司财务状况比ST 公司的财务状况好。此外,ST 公司的审计意见更倾向于非标准无保留意见,进一步表明ST 公司的财务状况不容乐观。
其次,对样本(T-1)年的财务预警指标进行正态分布检验后,仅有一个指标满足正态分布,则对股权集中制进行独立样本T 检验,结果如表5 所示。(表5)

表5(T-1)年独立样本T检验结果一览表
根据表5,股权集中度检验结果并不显著。对于其他非正态分布变量,进行M-W(U)非参数检验,本文直接给出通过显著性检验的指标,如表6 二级指标所示,通过显著性检验的指标共12 个,各变量平均值如表6 所示。(表6)
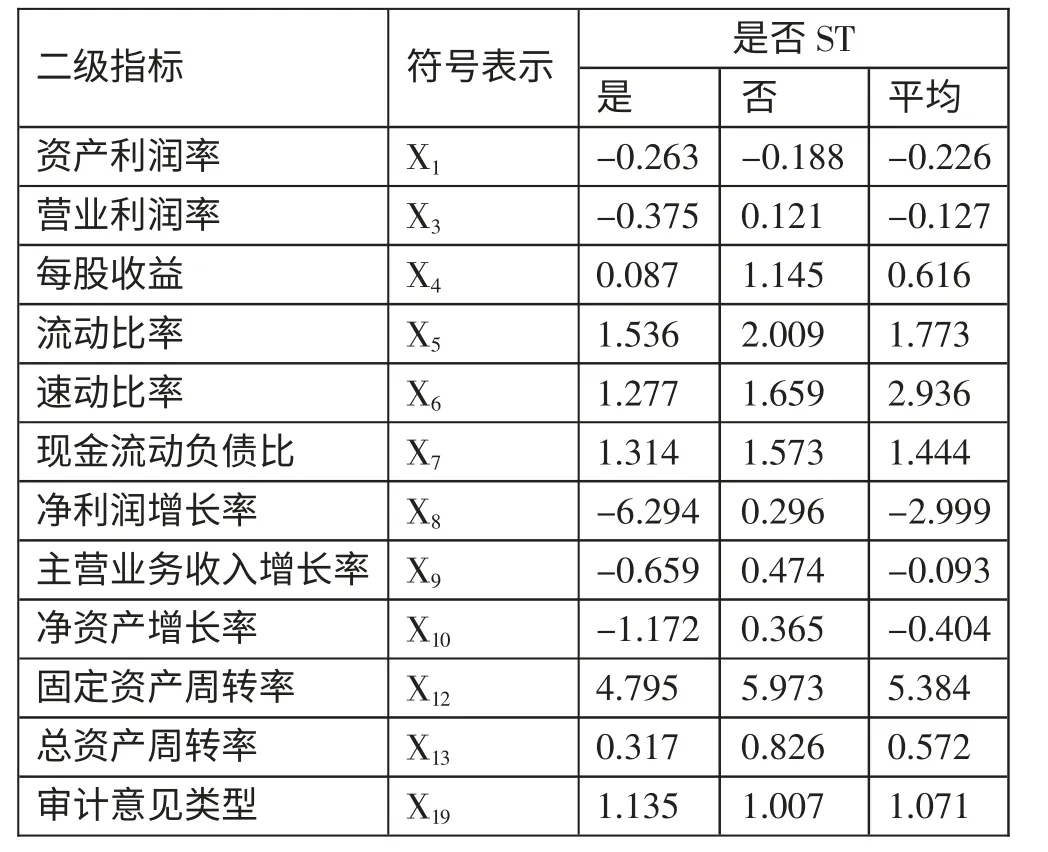
表6(T-1)年通过显著性检验的变量平均指标一览表
根据表6,(T-1)年非ST 公司财务状况要明显优于ST 公司。此外,ST 公司的审计意见更倾向于非标准无保留意见,进一步表明ST 公司的财务状况不容乐观。
三、基于数据挖掘的财务预警模型指标筛选有效性
(一)神经网络财务预警模型预测。利用因财务问题被特别处理的ST 公司的(T-2)和(T-1)年数据,构建基于多层感知器(MLP)的神经网络模型,并将样本数据按7∶3 比例进一步分为训练样本与测试样本,以使模型结果更加直观地反映各项财务和非财务指标。
1、(T-2)年神经网络财务预警模型预测。基于MLP 的神经网络的输入层因子应为表4 中通过显著性检验的11 个指标,输出层是对两年后目标公司是否被ST 所进行的判断,故输出层单元数应为2;相应地,隐藏层单元数则是以输入与输出层结构为依据,自动认定为4。(T-2)年神经网络财务预警模型的信息如表7 所示。(表7)
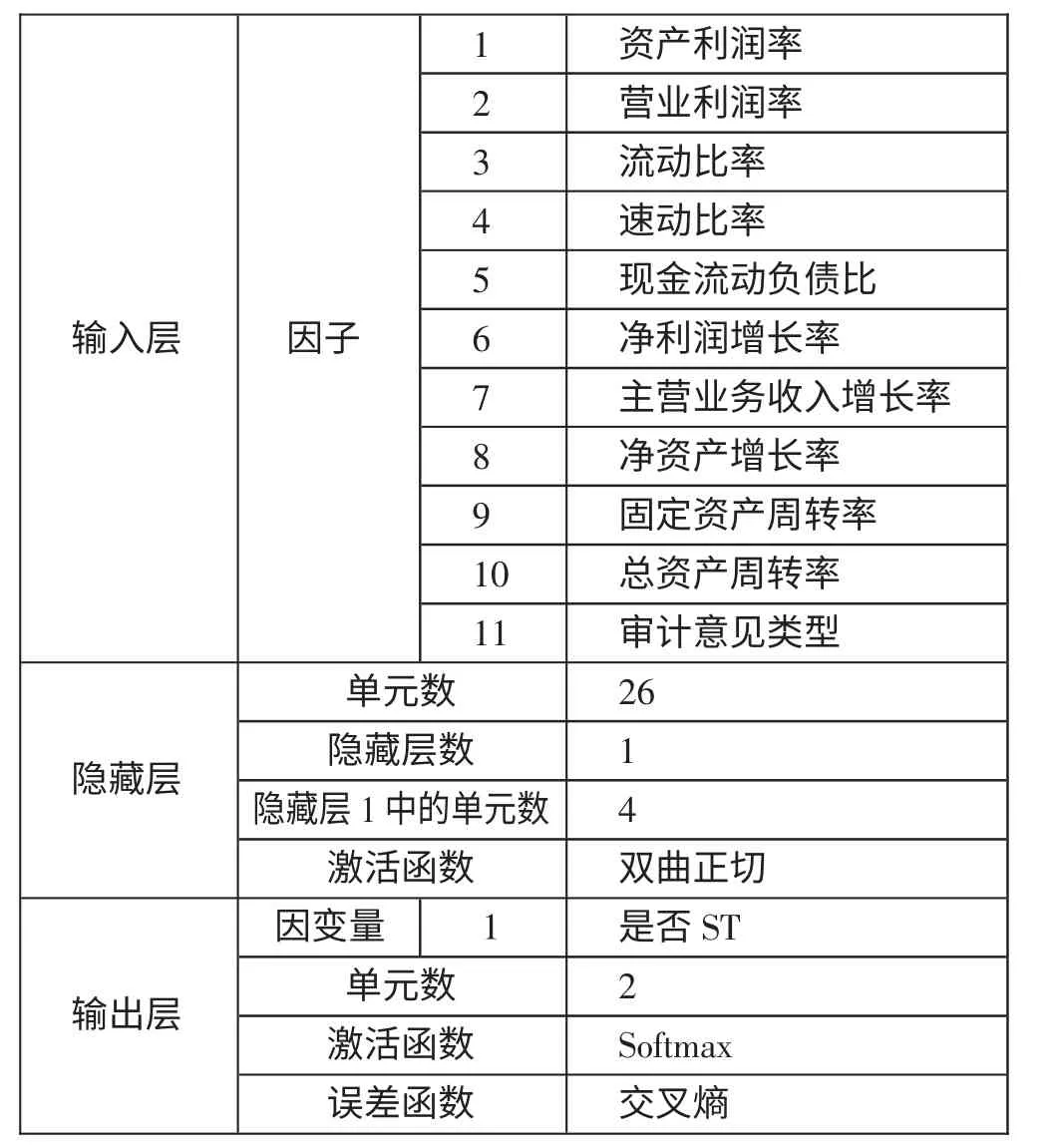
表7(T-2)年神经网络信息一览表
图1 给出了ROC 曲线(接受者操作特征曲线),可知神经网络财务预警模型的拟合效果较好。(图1)
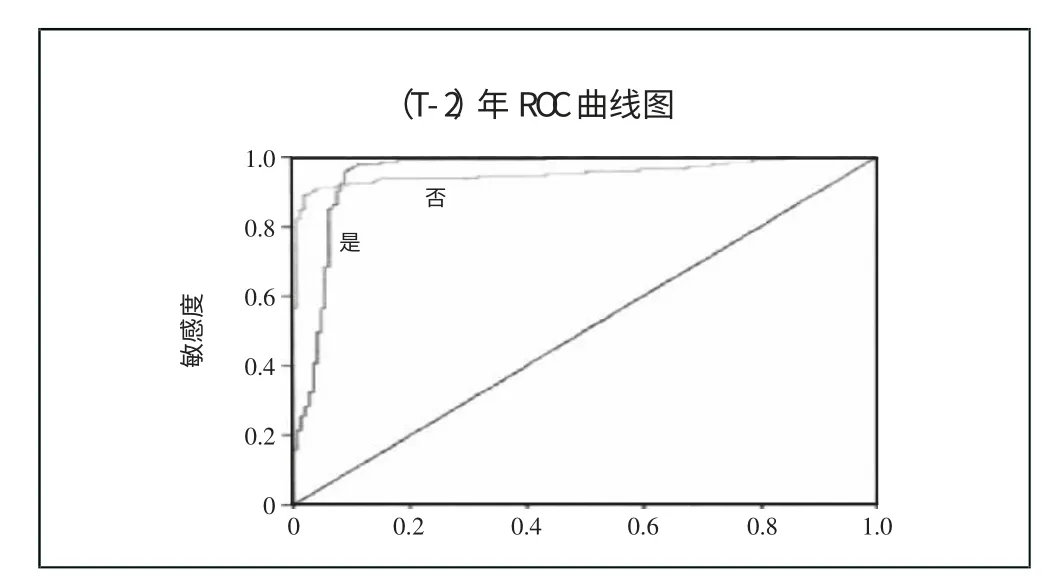
图1(T-2)年ROC曲线图
表8 给出了(T-2)年神经网络财务预警模型的分类表。由表8 可知,(T-2)年神经网络模型把2 家ST 公司错误的预测为了非ST 公司,得出ST 公司的预测准确率为91.3%。因为把4家非ST 公司错误的预测为了ST 公司,得出非ST 公司的预测准确率为82.6%。用两个准确率可以看出,预警模型对ST 公司的识别更为准确。根据神经网络模型,上述11 个变量对模型分类的影响程度的排序情况如图2 所示,其中去掉了重要性低于20%的总资产周转率和流动比率。(表8、图2)
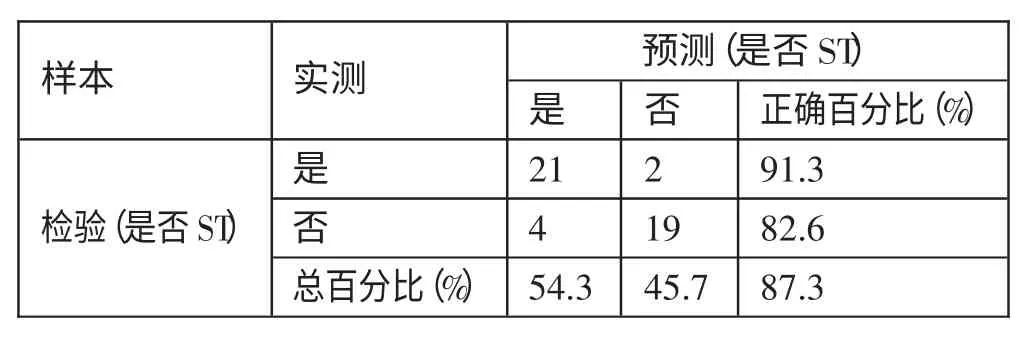
表8(T-2)年神经网络财务预警模型的神经网络分类一览表
2、(T-1)年神经网络财务预警模型预测。基于MLP 的神经网络的输入层因子应为表6 中通过显著性检验的12 个指标,输出层是判断一年后目标公司是否会被ST,2 是输出层的单元数,然后隐藏层单元数就自动认定为2。表9 所示的是(T-1)年神经网络财务预警模型的信息表。(表9)
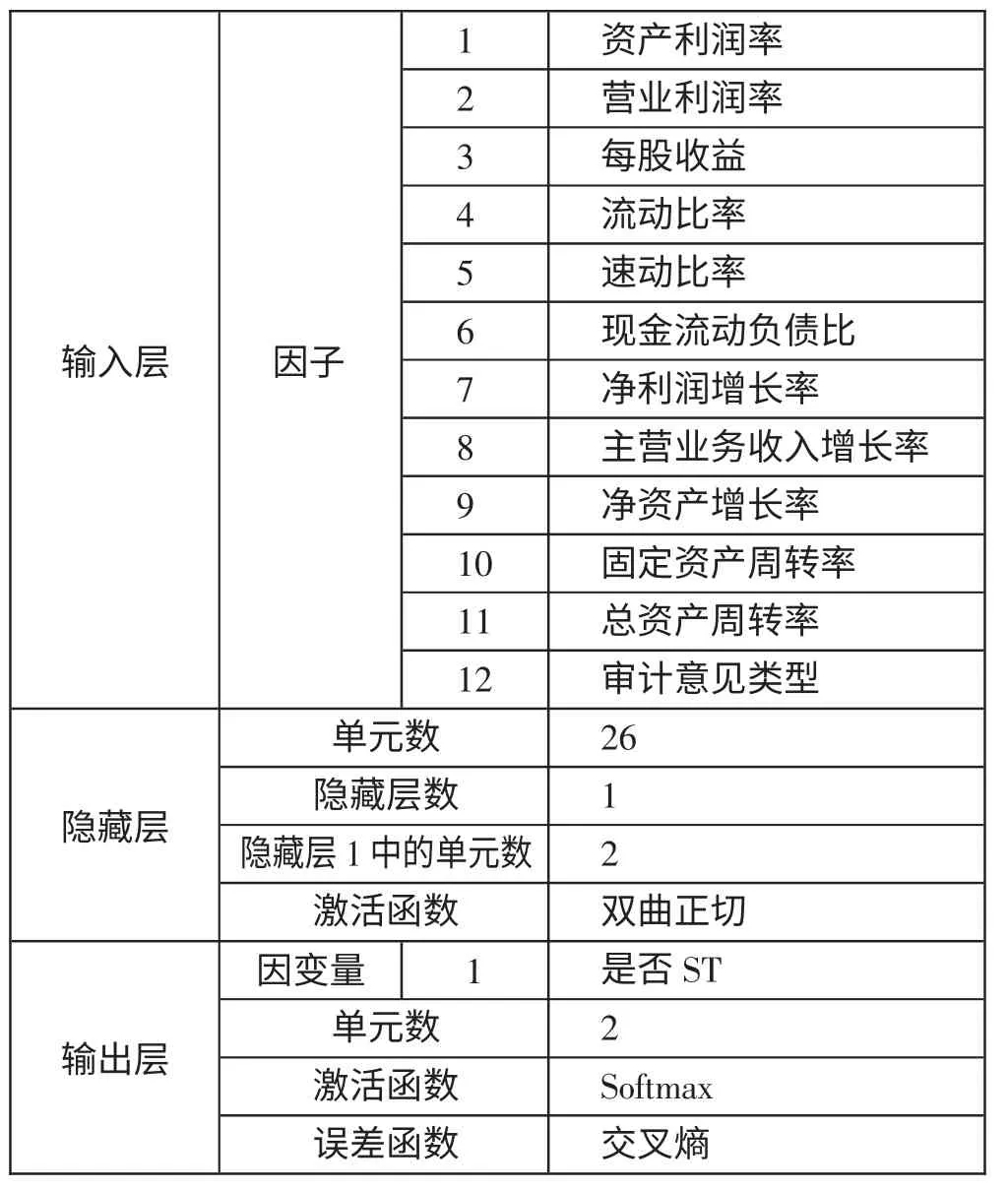
表9(T-1)年神经网络信息一览表
图3 给出了ROC 曲线(接受者操作特征曲线),可知神经网络财务预警模型的拟合效果较好。(图3)
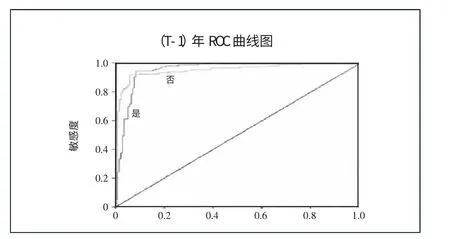
图3(T-1)年ROC曲线图
表10 给出了(T-1)年神经网络财务预警模型的分类表。由表10 可知,(T-1)年神经网络模型把1 家ST 公司错误地预测为非ST 公司,得出ST 公司的预测准确率为95.7%。因为把3家非ST 公司被错误地预测为ST 公司,得出非ST 公司的预测准确率为86.9%。可见,模型对ST 公司的识别效果更佳。根据神经网络模型,上述12 个变量对模型分类的影响程度的排序情况如图4 所示,其中去掉了重要性低于20%的总资产周转率。(表10、图4)
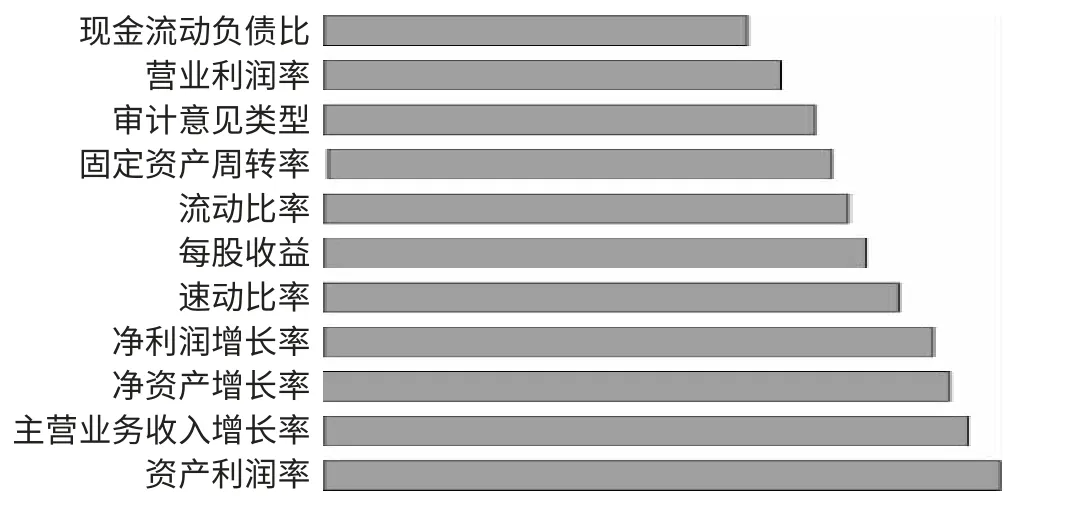
图4(T-1)年神经网络变量重要性排序图
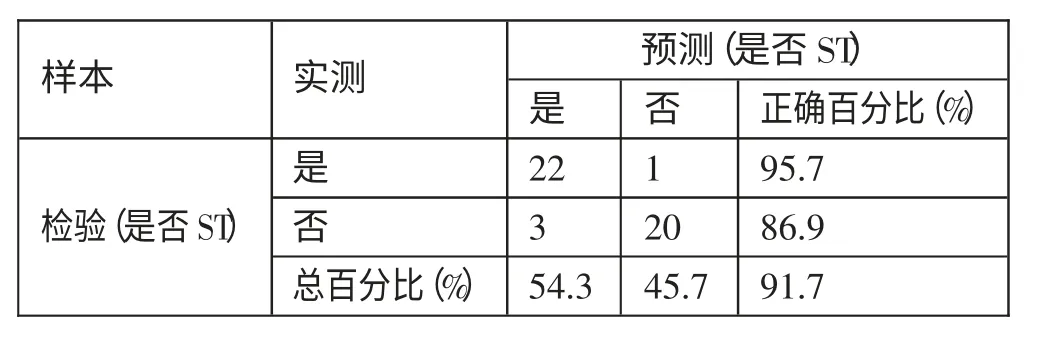
表10(T-1)年神经网络财务预警模型的神经网络分类一览表
通过构建(T-2)年和(T-1)年神经网络财务预警模型,去除掉重要程度低于20%的变量,得出2017~2019 年对样本公司财务预警相对重要的变量指标,主要有五项,分别是净利润增长率、固定资产周转率、净资产增长率、审计意见类型和资产利润率。
(二)决策树财务预警模型预测。借助选取的ST 公司的各项指标数据,对(T-2)年和(T-1)年的CHAID 决策树模型进行构建,上文所选出的5 项重要的指标变量就是决策树模型的自变量。并将样本分为训练样本和测试样本(7∶3)。除此之外,修正树的父节点的最小个案数为3,子节点的最小个案数确定为1,还要控制最大树深度。
1、(T-2)年决策树财务预警模型预测。根据(T-2)年决策树模型的结果,对决策树的关键指标进行排次(按重要程度:(1)资产净利率;(2)净资产增长率;(3)净利润增长率;(4)固定资产周转率。决策树的节点数为11,终端节点数为6,树深为3,输出结构具体如表11 所示。(表11)
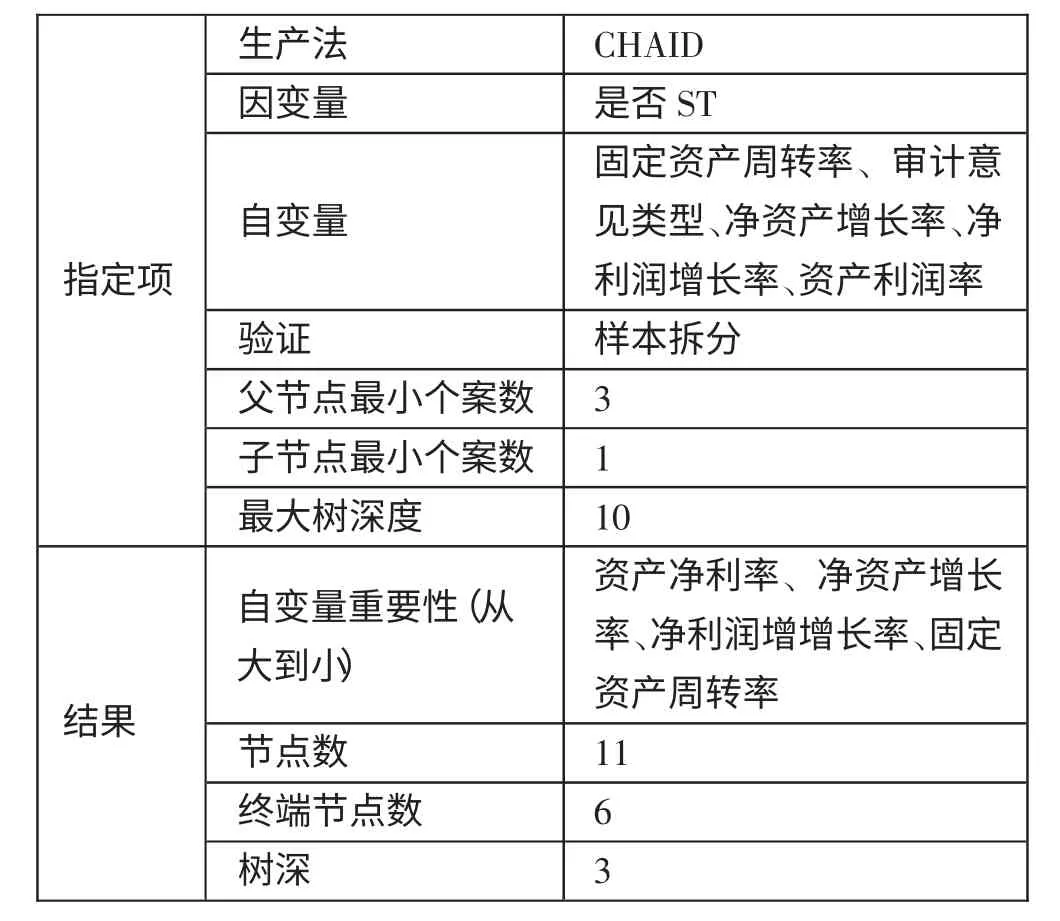
表11 决策树财务预警模型(T-2)年输出结构一览表
决策树财务预警模型(T-2)年的判别分类结果如表12 所示。根据表12,决策树模型对样本公司(T-2)年的财预警结果如下:对ST 公司的预测结果准确率为91.3%;对非ST 公司的预测准确率为86.9%,模型总体的准确率为89.2%,预测的准确性较高。(表12)
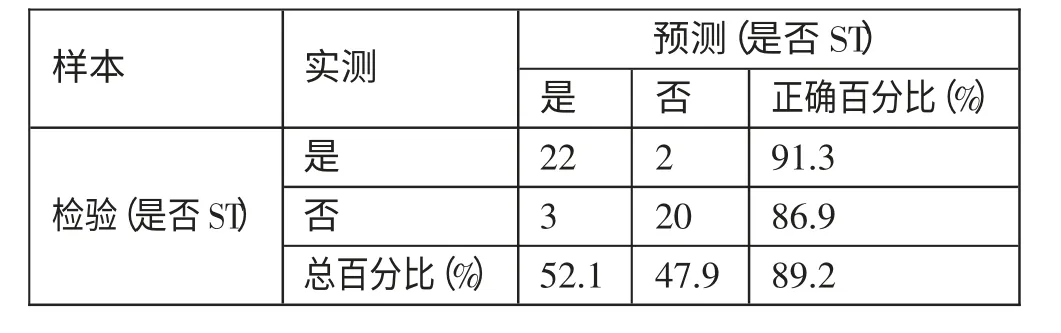
表12 决策树财务预警模型(T-2)年判别分类结果一览表
2、(T-1)年决策树财务预警模型预测。根据(T-1)年决策树模型结果,对决策树的关键指标进行排次(按重要程度):(1)资产净利率;(2)审计意见类型;(3)净利润增长率。决策树的节点数为7,终端节点数为4,树深为3,模型输出的结构如表13 所示。(表13)
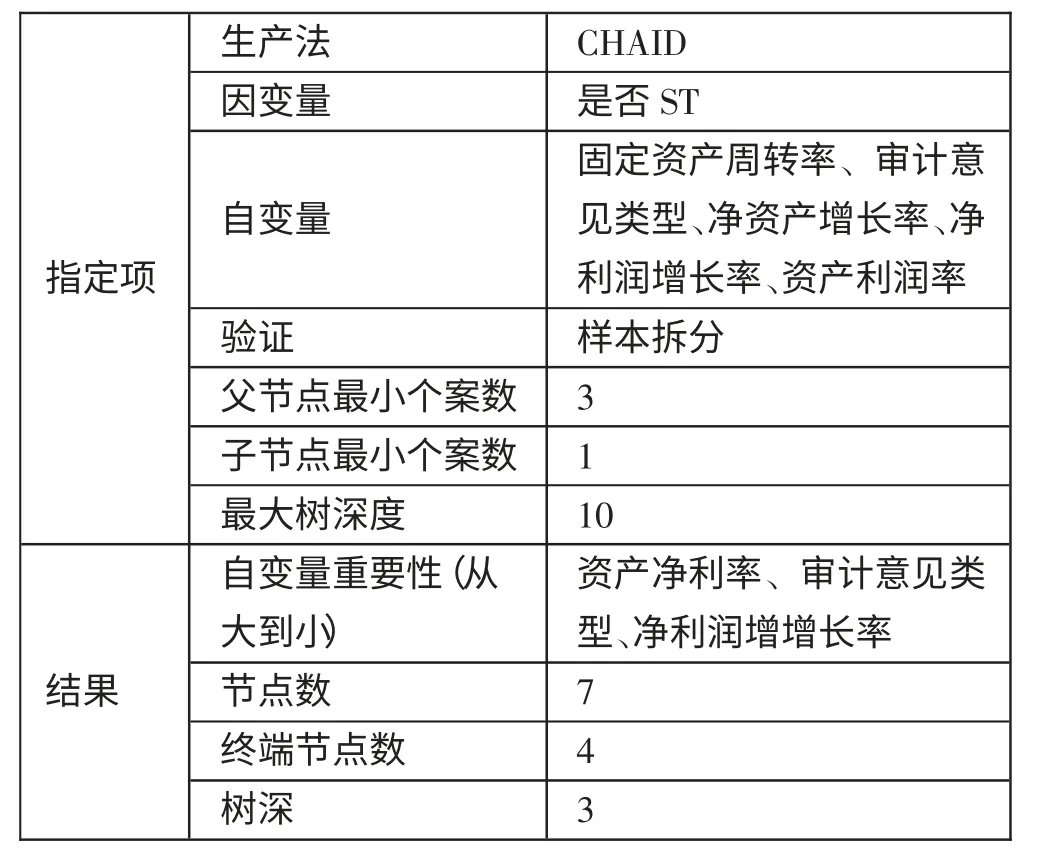
表13 决策树财务预警模型(T-1)年输出结构一览表
决策树财务预警模型(T-1)年的判别分类结果如表14 所示。根据表14,决策树模型对样本公司(T-1)年的财预警结果如下:对ST 公司的预测准确率为95.7%;对非ST 公司的预测准确率为82.6%。预警模型的总体准确率为95.7%,预测的准确性较高。(表14)
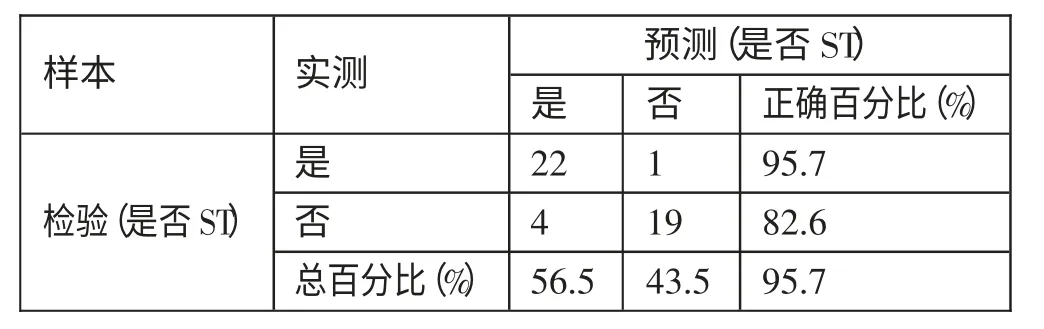
表14 决策树财务预警模型(T-1)年判别分类结果一览表
(三)Logistic回归财务预警模型预测
1、(T-2)年Logistic回归财务预警模型预测。对上文中所选取的样本数据进行多元回归分析,构建出Logistic 回归模型,借助有条件的向后筛选变量的办法,Logistic 回归模型的自变量选了上述五个自变量中的三个,分别是X10净资产增长率,X1资产利润率和X8净利润增长率。最终,得到如公式(1)所示的样本公司(T-2)年财务预警Logistic 回归模型。
公式(1)中,β 表示各变量系数,α 为常数项,ε 为误差项。利用SPSS20.0 对模型进行回归,结果如表15 所示。由表15 可知,净利润增长率X8、净资产增长率X10、资产利润率X1的系数分比为0.254、0.336 和0.667,P 值均小于0.05,表示三项指标与上市公司财务预警具有显著正向关联,可以用这三项指标判断上市公司是不是ST 公司。(表15)
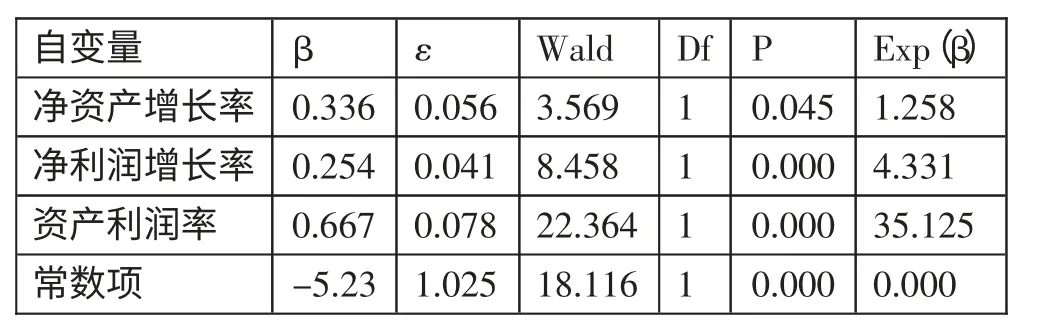
表15(T-2)年财务预警Logistic模型回归结果一览表
表16 显示的是(T-2)年Logistic 财务预警模型的回归分类结果。根据表16 可得,Logistic 模型对样本公司(T-2)年的财务预警结果如下:2 家预测错误,对ST 公司的预测准确率为91.3%;5 家预测错误,对非ST 公司的预测准确率为78.2%。财务预警模型的总体准确率为85.6%,预测的准确性较高。(表16)
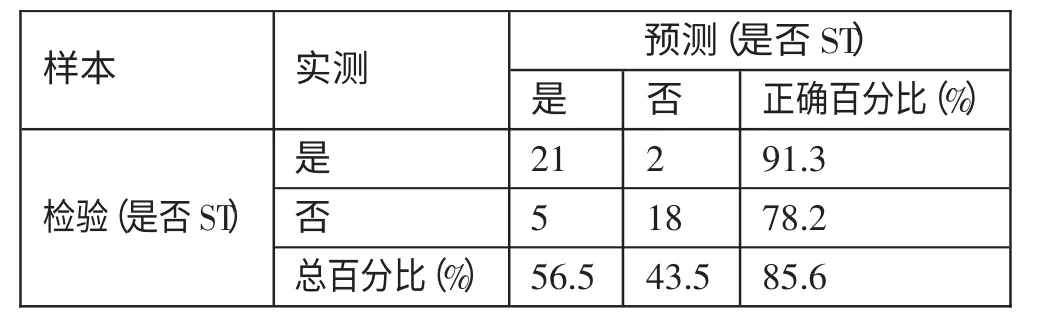
表16 Logistic财务预警模型(T-2)年的回归分类结果一览表
2、(T-1)年Logistic回归财务预警模型预测。对本文所选取的样本数据进行多元回归分析,构建Logistic 回归模型,借助有条件的向后筛选变量的办法,Logistic 回归模型的自变量选了五个自变量中的四个,分别是净资产增长率X10、资产利润率X1、净利润增长率X8和审计意见类型X19。最终,得到如公式(2)所示的样本公司(T-1)年财务预警Logistic 回归模型。
公式(2)中,β 表示各变量系数,α 代表常数项,ε 代表误差项。运用SPSS20.0 对模型进行回归,结果如表17 所示。由表17可以得知,净资产增长率X10、净利润增长率X8、资产利润率X1和审计意见类型X19的系数分别为0.196、0.454、0.825、-2.115,P 值均小于0.05,表示四项指标与上市公司财务预警具有显著正向关联,所以判断是否为ST 公司可以用这四个指标。(表17)
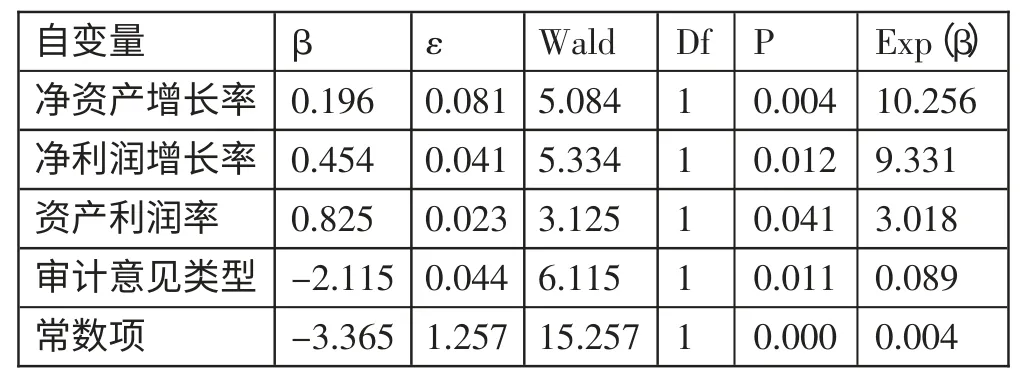
表17(T-1)年财务预警Logistic模型回归结果一览表
Logistic 财务预警模型(T-1)年的回归分类结果如表18 所示。根据表18,Logistic 模型对样本公司(T-1)年的财预警结果如下:对ST 公司的预测准确率为95.7%,因为把1 家ST 公司错误的预测为非ST 公司;对非ST 公司的预测准确率为82.6%,因为把4 家非ST 公司错误的预测为ST 公司。模型总体的准确率为95.7%,预测的准确性较高。(表18)

表18(T-1)年Logistic财务预警模型的回归分类结果一览表
(四)各模型指标筛选的有效性检验。表19 是三个模型对是否为ST 公司进行预测的对比,三个模型分别是神经网络财务预警模型、决策树和Logistic 回归财务预警模型。(表19)
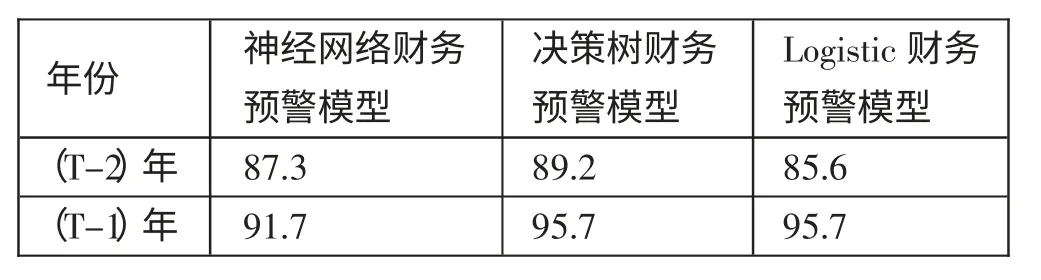
表19 模型有效性对比一览表
由表19 可知,对ST 公司预测的准确度比较高的是决策树和Logistic 回归模型,同时说明神经网络财务预警模型所得到的各变量可以较好地反映出公司的财务状况。此外,越接近财务风险发生的年份(T-1)年,各模型对公司财务风险预测的准确性也越高。
四、结论
本文在对财务预警和数据挖掘的相关概念予以阐述的基础上,构建了基于财务与非财务指标的上市公司财务预警体系,并用上市公司(T-2)年和(T-1)年的各项指标作为样本数据,对各数据进行显著性检验,进而构建神经网络财务预警模型,通过模型预测出公司是否是ST 公司,得出的结论是:模型对(T-2)年和(T-1)年预测的准确率均处于较高水平,分别为87.3%和91.7%。同时,筛选出对样本公司财务状况具有显著影响的5 个关键指标,分别为固定资产周转率、审计意见类型、净资产增长率、净利润增长率和资产利润率。
此外,为进一步验证模型对指标筛选的有效性,基于样本公司被特别处理(T-2)年和(T-1)年的相关指标数据,构建决策树与Logistic 回归财务预警模型,结果表明:二者对样本公司是否为ST 公司的预测具有较高的准确率,表明基于神经网络的上市公司财务预警模型所确定出的各变量能够较好地反映出公司的财务状况,代表性较强,能够较好地应用于上市公司财务预警当中,帮助上市公司更加全面地了解自身财务状况,有效应对财务风险。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
成都信息工程大学学报(2019年3期)2019-09-25
今日农业(2019年12期)2019-08-13
电子制作(2018年16期)2018-09-26
中国交通信息化(2018年5期)2018-08-21
现代园艺(2017年22期)2018-01-19
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
火控雷达技术(2016年3期)2016-02-06
