
基于知识图谱的中性几何模型装配特征语义重建方法
2024-04-10 12:59刘鸣飞鲍劲松
计算机集成制造系统 2024年3期
凌 威,刘鸣飞,鲍劲松,2,3+
(1.东华大学 机械工程学院,上海 201620;2.东华大学 上海市现代纺织前沿科学研究基地,上海 201620;3.东华大学 纤维材料改性国家重点实验室,上海 201620)
0 引言
装配特征是零件上具备装配语义的一组几何基础形状的集合,例如孔轴、凹穴和键槽等[1]。现有企业的产品模型主要以中性几何模型文件格式(如STEP和glTF)储存,大多数工业CAD软件只能以模型树读取装配体的层级结构以及模型的几何形状信息。对于中性几何模型文件格式来说,这类模型并不具有装配特征语义,而是以点、线、面等几何语义形式来储存信息[2-3],难以直接从中性几何模型中构建出装配特征语义。中性几何模型通常是企业经过脱敏处理后储存文件的一种格式。由于在产品模型储存时就会缺失装配特征语义信息,本文所提研究方法从构成中性几何模型的底层点、线、面信息出发,重建出中性几何模型的装配特征语义。
许多专家学者在特征语义重建领域做出了诸多努力,目前已经存在多种特征语义重建的方法,如基于规则推理的方法和基于学习的方法。基于推理的方法主要是对装配体进行区域合理分解,以图的形式表示模型的几何形状,通过设计规则将图与标准属性邻接图进行匹配从而推理出特征语义,在基于规则推理的方法中,BABIC等[4]通过逻辑规则设计将CAD模型中的几何图元进行特征匹配,施建飞等[5]和JIAN等[6]通过构建飞机结构件模型的属性邻接图进行特征语义识别,ZHAO等[7]和WOO等[8]提出了一种基于增量体积分解和组合策略的工艺特征语义构建方法,王军等[9]通过提取加工特征面提出了基于痕迹的特征识别方法。基于规则的方法通常只能识别B-Rep边界表示模型中的特征,不适用于丢失了拓扑结构的文件格式,且存在可扩展性差,计算消耗大,鲁棒性差,难以处理复杂相交特征等问题。
基于学习的方法是将三角网格模型进行体素化或转为点云数据,将数据输入到三维深度网络进行特征学习,或者通过多视图的方法将图片作为二维卷积神网络(Contolutional Neural Network,CNN)的输入进行特征学习。在基于学习的方法中,ZHANG等[10]使用深度3D CNN从机械零件CAD模型学习零件的加工特征,SHI等[11]采用多视图的方法构建了特征识别器 MSVNET识别加工特征,高玉龙等[12]和吕超凡等[13]通过特征提取和点云深度学习对点云数据集进行特征识别。三维学习特征的方法训练噪声大,分辨率不稳定,存在训练时间较长以及局部信息丢失等缺点。二维学习特征虽然减少了训练时间,但是在复杂场景下会出现物体的物理干涉或者遮挡现象,无法学习模型内部的特征。
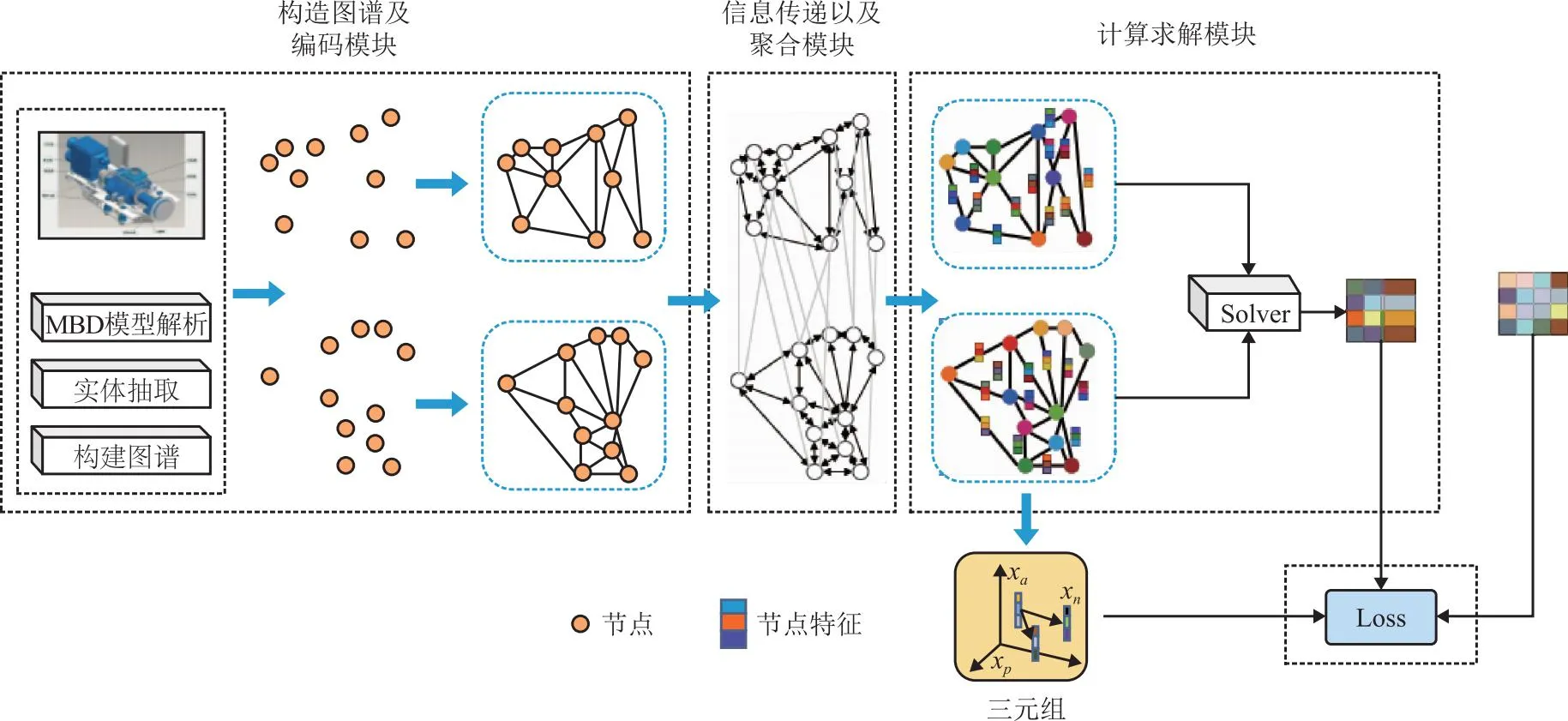
知识图谱作为一种具有图结构的语义网络[14],以语义三元组(“实体-关系-实体”与“实体-属性-值”)的形式简洁、直观地描述信息元素及元素间的关系[15-17]。知识图谱能够高效地处理具有复杂语义关系的数据[18],可以有效地表示中性几何模型的点、线、面语义信息。图匹配神经网络是一种用于图数据的深度学习模型,能够学习图之间的相关性和相似性[19-20]。中性几何模型通常是企业经过脱敏处理后储存文件的一种格式,由于在产品模型储存时就会缺失装配特征语义信息,本文的目的是从构成中性几何模型的底层点、线、面信息出发,基于知识图谱的方式表示中性几何模型的底层几何语义,通过图匹配神经网络与标准特征库的的特征子图进行相似度遍历,完成子图装配特征语义的匹配,从而实现对缺失了装配特征语义的中性几何模型进行语义重建。鉴于此,本文提出一种新的基于知识图谱的构建中性几何模型的装配特征语义方法。首先通过分析中性几何模型的特性对装配体模型文件进行解析,生成装配实体和装配约束两种数据结构,经实体映射完成中性几何模型几何语义知识图谱模式层和数据层的构建,然后根据节点/边的语义信息和邻接结构信息与标准装配特征库的图网络结构进行相似度计算,从而识别出对应的装配特征。最后以上海某企业风力发电机机舱装配体部件为例,验证了该方法框架的可行性。
1 装配特征识别方法研究框架
1.1 问题描述
中性模型的提出是为了解决不同模型文件格式之间的数据传输与通信问题而建立的产品数据交换规范。中性几何模型作为中性模型的一个子集,其构成要素主要包括点、线、面以及三角面片等基本几何单元,如glTF、OBJ以及STL文件都属于中性几何模型的范畴。这类模型在CAD软件中通常只能够以模型树的形式表示装配体的层级结构信息,并不能够直接读取其装配特征语义信息。
根据文献[21]提出的定义,装配特征语义可以分为装配特征实体语义与装配特征约束语义,如图1所示。装配实体语义指参与装配的具体实例,如螺栓-螺母连接、孔轴装配特征等实例。在产品建模时由一系列的点、线、面以及其之间的关系构成装配实体。装配约束语义指参与配合的几何元素实例和实例间的约束关系,如参与配合的几何元素为平面,且平面间重合或者存在一定间距。因此本文给出如下两种基础定义。

图1 装配特征信息
定义1基于知识图谱的中性几何语义模型KG-NGSM(knowledge graph-based neutral geometric semantics model),将中性几何模型中的模型层级结构信息与构成模型的底层点线面信息通过知识图谱以“节点-关系-节点”与“节点-属性-值”的组织形式表示。为了实现中性几何模型几何信息元素以及元素间关系的形式化、规范化描述,定义了如图2所示的KG-NGSM={AE∪GE∪SR},其中:

图2 KG-NGSM模型框架
AE表示装配元素,包含装配体总成单元类,组件单元类,零件单元类等实体类型。装配元素单元的实例属性为名称和id。
GE表示几何元素,主要包含构成零件实体的面单元类、边单元类、顶点单元类等实体类型。面单元、边单元的实例属性为类型和id,顶点单元的实例属性为坐标和id。
SR表示语义关系,装配元素以及几何元素间的广义语义关系如表1所示。

表1 语义关系定义
定义2装配特征约束数据类型。装配约束数据类型可以通过CAD API可编程接口进行构建。以Soildworks 2022为例,配合信息对象为MateEntity、Mate、MateGroup[22],其中MateEntity对象代表参与配合的几何元素,Mate对象代表装配特征间的配合类型,具体如表2所示。
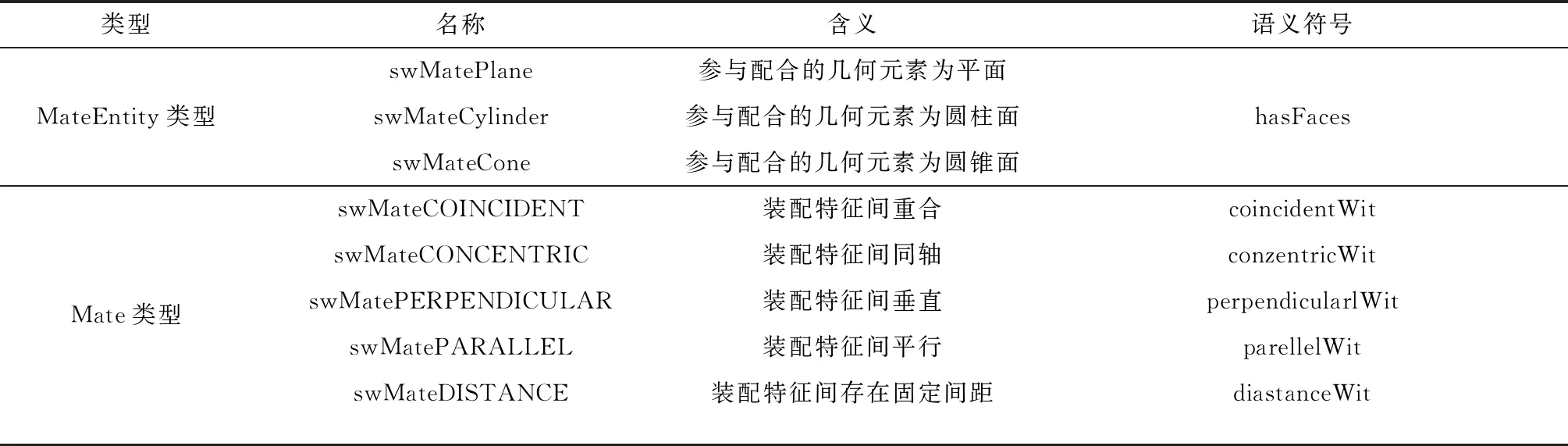
表2 装配特征约束数据类型
1.2 研究方法框架
本文基于文件解析和知识图谱提出了中性几何模型的装配特征语义构建框架。如图3所示为装配特征语义重建流程图。

图3 研究框架
(1)模型构建 通过CAD软件构建中性几何模型(glTF、OBJ和STEP等)作为装配特征语义重建框架的输入源:中性几何模型数据集,其中主要包含装配单元和几何信息以及对应的属性和值。
(2)文件解析 将中性几何模型数据集作为文件解析器的输入源,首先使用CAD API接口构建装配特征约束语义信息。在3dMAX软件中将中性几何模型数据集导出为glTF格式的文件作为装配特征实体语义构建的输入源,通过Python接口解析glTF 中JSON文件和Buffer文件提取几何体、面、边、点信息,通过实体关系映射为类、属性和值。
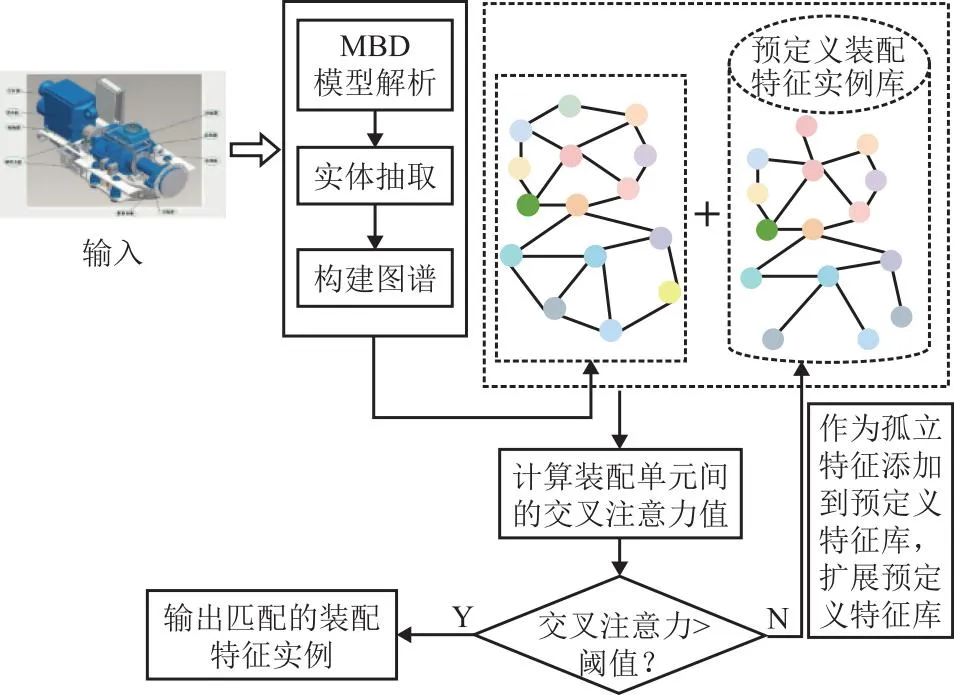
(3)特征识别 映射完成后的实体关系信息为构建图谱的三元组输入源。读取拓扑信息构建中性几何模型的几何语义图谱。由于一个完整的装配体知识图谱节点数量庞大,关系复杂,需要按照相应的零件层级关系或者是路径关系拆解成一系列子图谱。构建邻接矩阵与装配实体语义库进行相似度匹配,从而识别出装配实体信息,否则将该特征作为孤立特征添加到装配实体语义库中,扩展装配实体语义库。
(4)储存数据 将抽取出的装配特征约束语义信息和装配实体语义信息进行信息整合,最后统一归纳到数据库中。
2 产品几何语义建模方法
2.1 几何信息抽取及映射方法
中性几何模型几何/拓扑信息的提取是构建KG-NGSM的前提。根据本文提出的研究框架,首先对中性几何模型进行信息抽取,由于在众多CAD格式文件中glTF文件能够直观地描述产品中零件、连接件的基本信息及其之间的连接关系,因此选择glTF文件作为图谱数据层中实例三元组的数据来源。glTF是由KhronosGroup设计和定义的,用于有效地传输3D内容转移网络,其组织结构如图4所示。其中储存几何语义的主要节点代表的含义如表3所示。

表3 glTF文件各节点含义
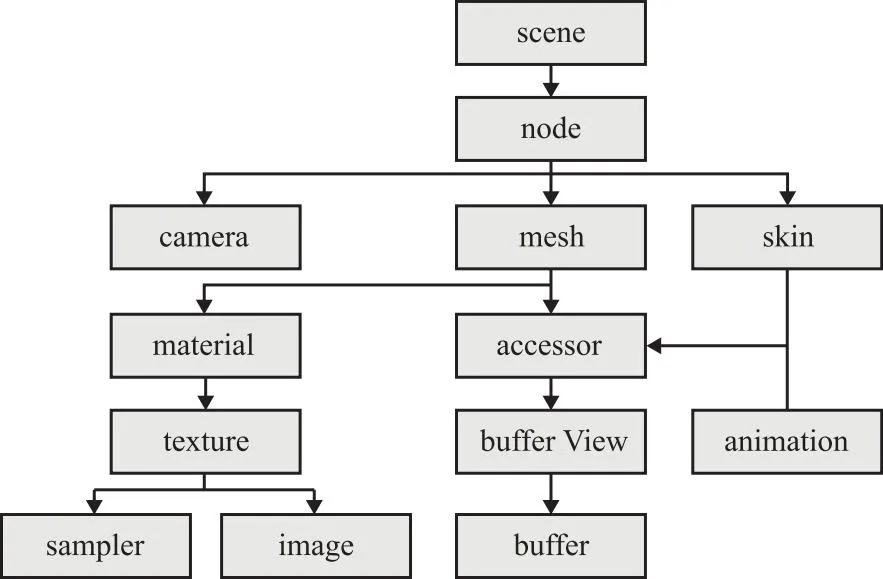
图4 glTF组织结构
由上可知,首先需要对其中的node、mesh、accessor、bufferView、buffer节点进行解析并抽取几何信息。glTF JSON的scene可以包含一个节点数组,每个nodes可以索引到相应的子节点位置,对nodes节点进行解析以获取中性几何模型的装配层级结构语义,如图5所示。meshes可能包含多个网格primitives,代表呈现网格所需的几何数据。每个网格primitives都可以表示几何元素是否应该呈现为点、线或者是三角面片的形式,每个属性都通过将属性名映射到包含属性数据的访问器的索引来定义。通过解析meshes节点可获取构成产品实体的几何语义。例如,属性可以定义顶点的坐标和法向量, buffers包含用于三维模型、外观几何学的数据。bufferViews、accessors和buffers的关系如图5所示,每个buffers引用一个二进制数据文件,使用一个URI。它是具有给定字节长度的一个原始数据块的源。对该原始数据块进行解析以获取几何体的点、线、面等几何语义信息。
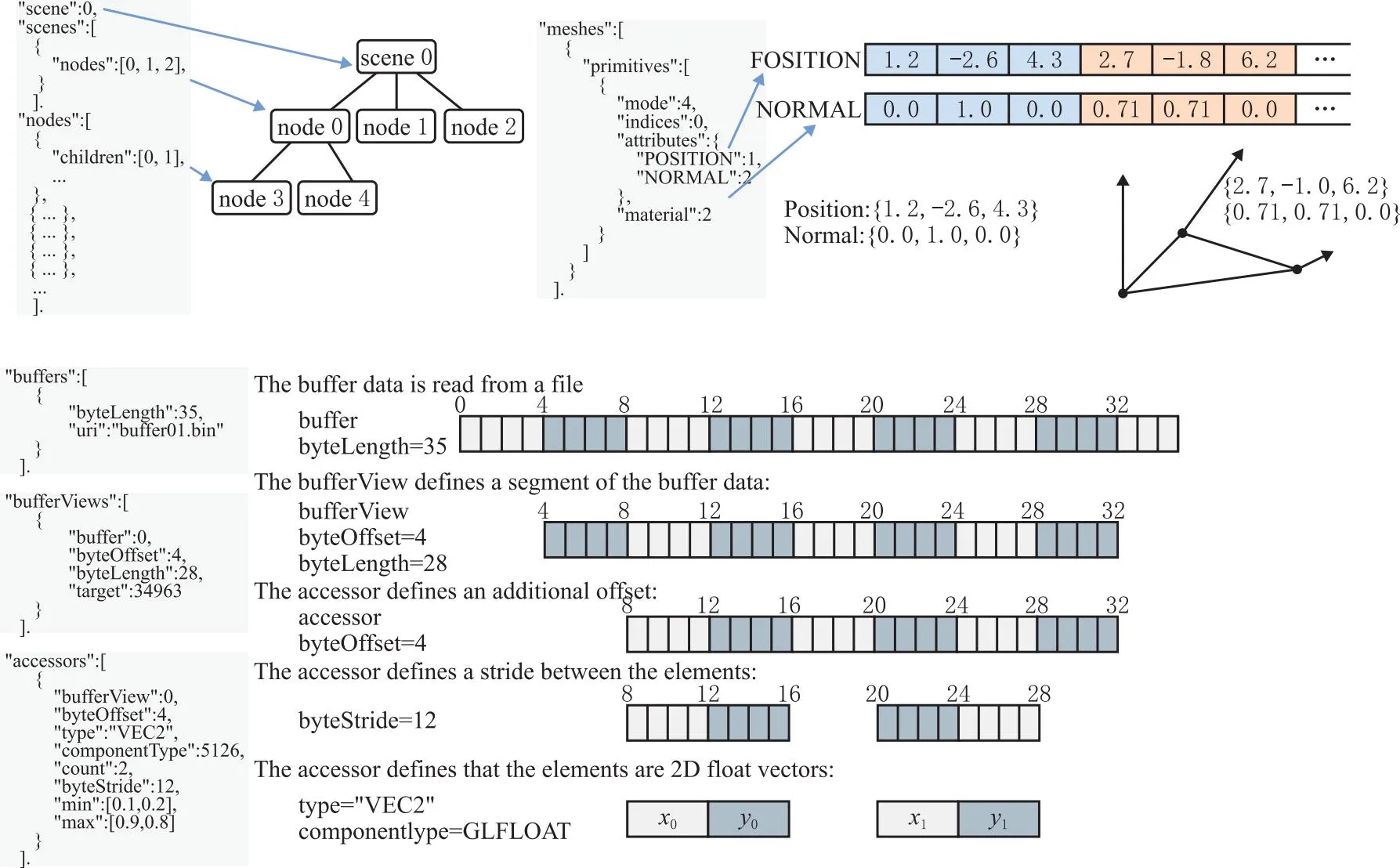
图5 glTF nodes、meshes、buffers数据对应关系
glTF文件中的几何语义包含装配元素之间的实体名字和连接关系,以及组成几何体的低级几何元素语义。glTF中包含的这些信息无法被计算机程序直接处理,因此需要通过glTF解析接口将glTF中的几何语义信息转为计算机程序容易处理的JSON文件,以该文件作为生成KG-NGSM的实例三元组数据来源。实体映射过程以及JSON设计格式如图6所示。
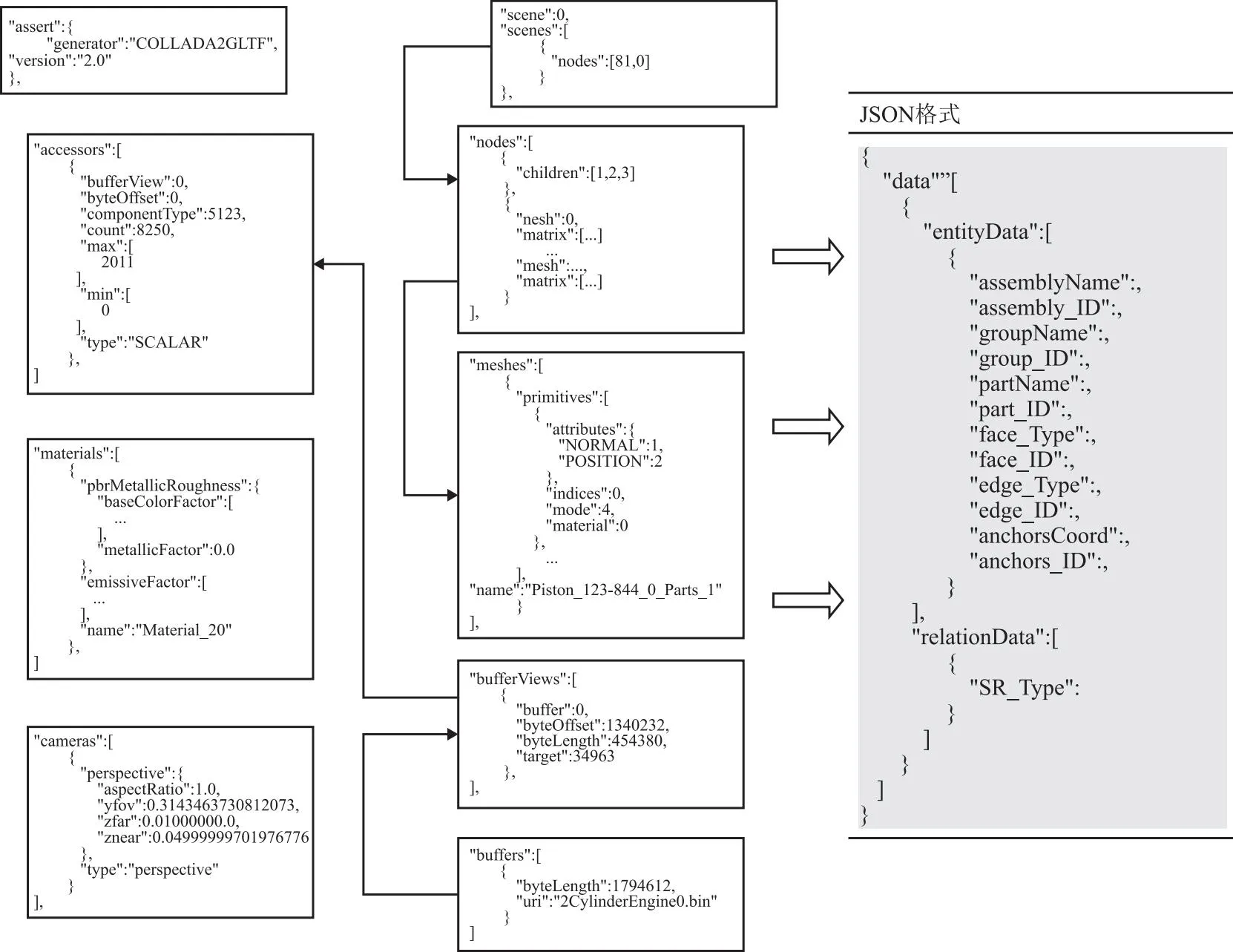
图6 实体映射及JSON格式设计
其中:data中存储的是对glTF进行解析后的结果,entityData存储的是装配单元以及几何元素语义信息,relationData存储的是关系语义。包含装配体总成单元类,组件单元类,零件单元类等实体类型名称和id,面单元、边单元的类型和id,以及顶点单元的坐标和id等语义信息。根据以上各节点关系以及数据类型,本文解析glTF模型文件,抽取模型几何信息的算法如表4所示。

表4 glTF几何语义抽取流程
2.2 装配约束语义抽取方法
在1.1节装配工艺信息的组成与定义中,装配特征信息包括装配特征实体信息以及装配特征间的约束关系,其中装配约束关系可以通过解析基于CAD API可编程接口获取的特征配合信息进行构建。如同轴配合约束的提取以及三元组表示如图7所示。从CAD系统中利用API函数,通过遍历匹配特征树对象提取匹配约束信息,并以三元组的形式表示。
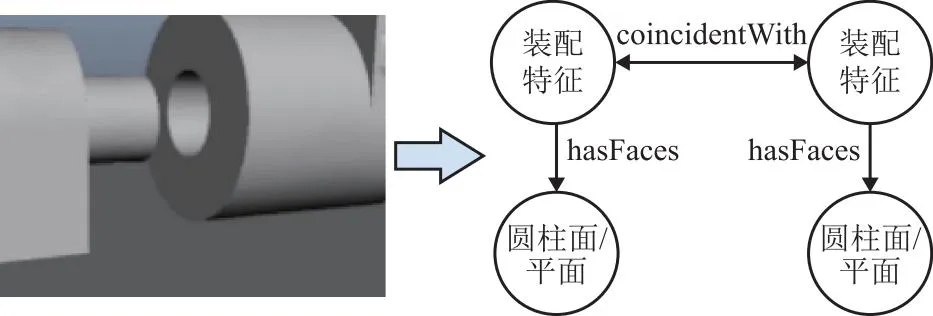
图7 同轴配合及三元组表示
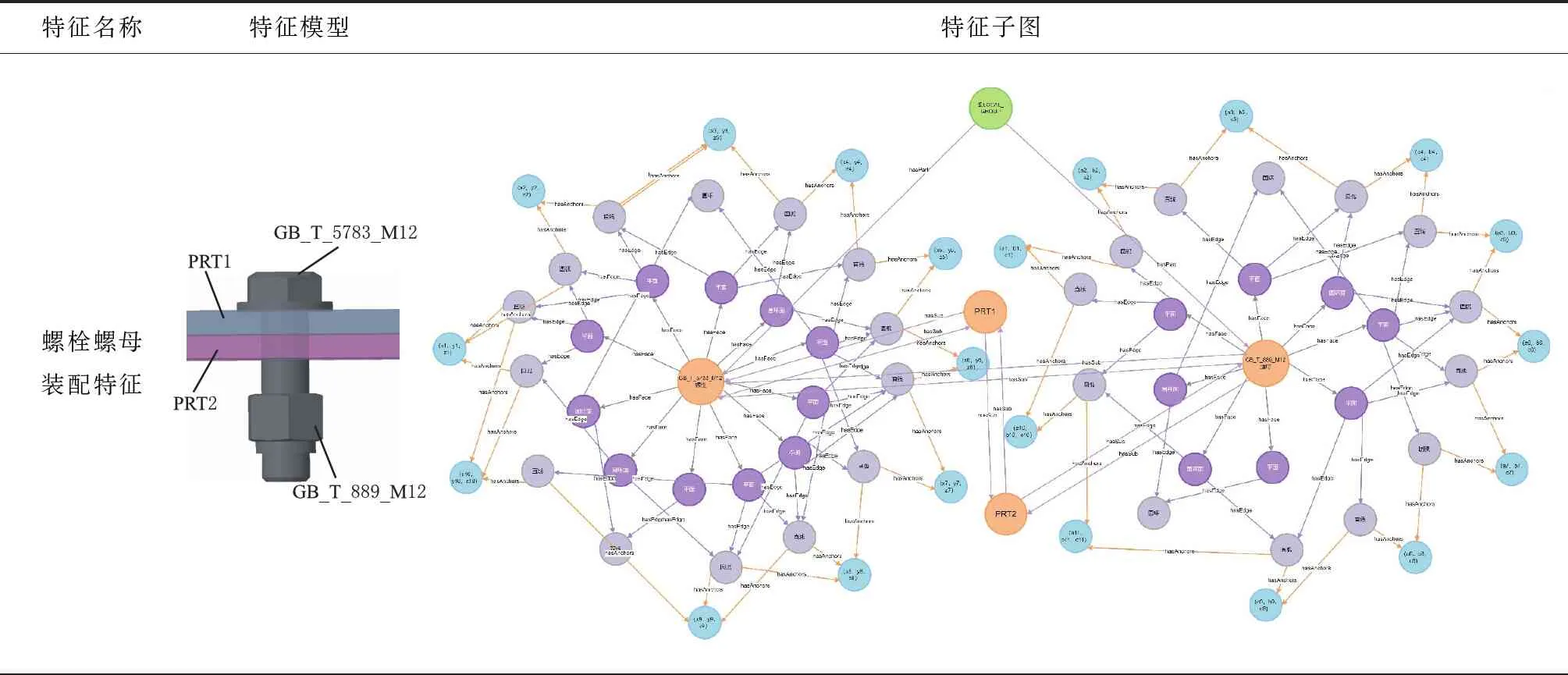
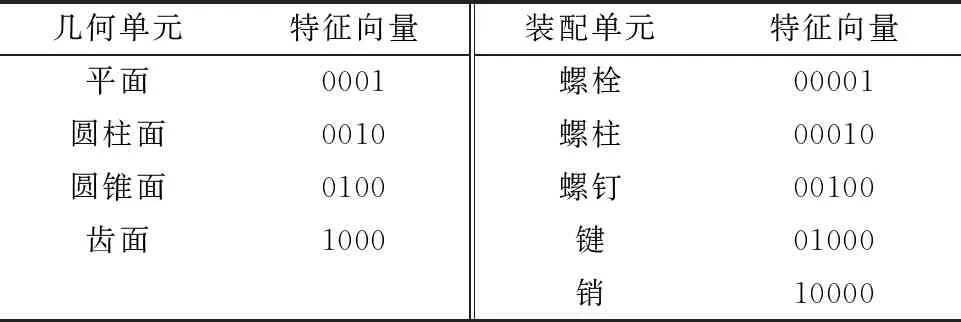
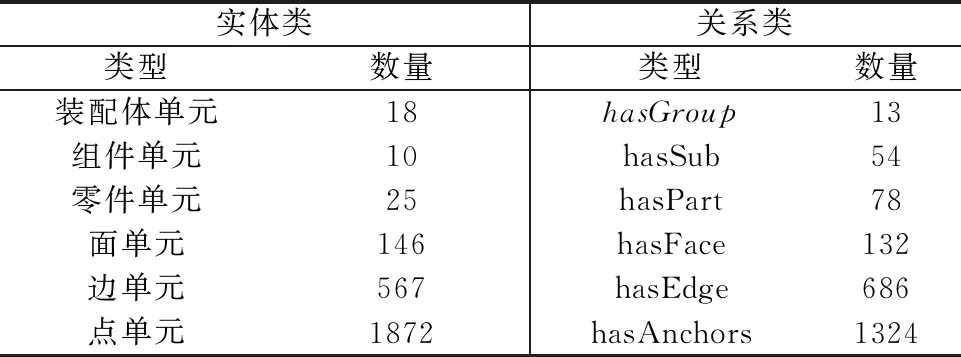
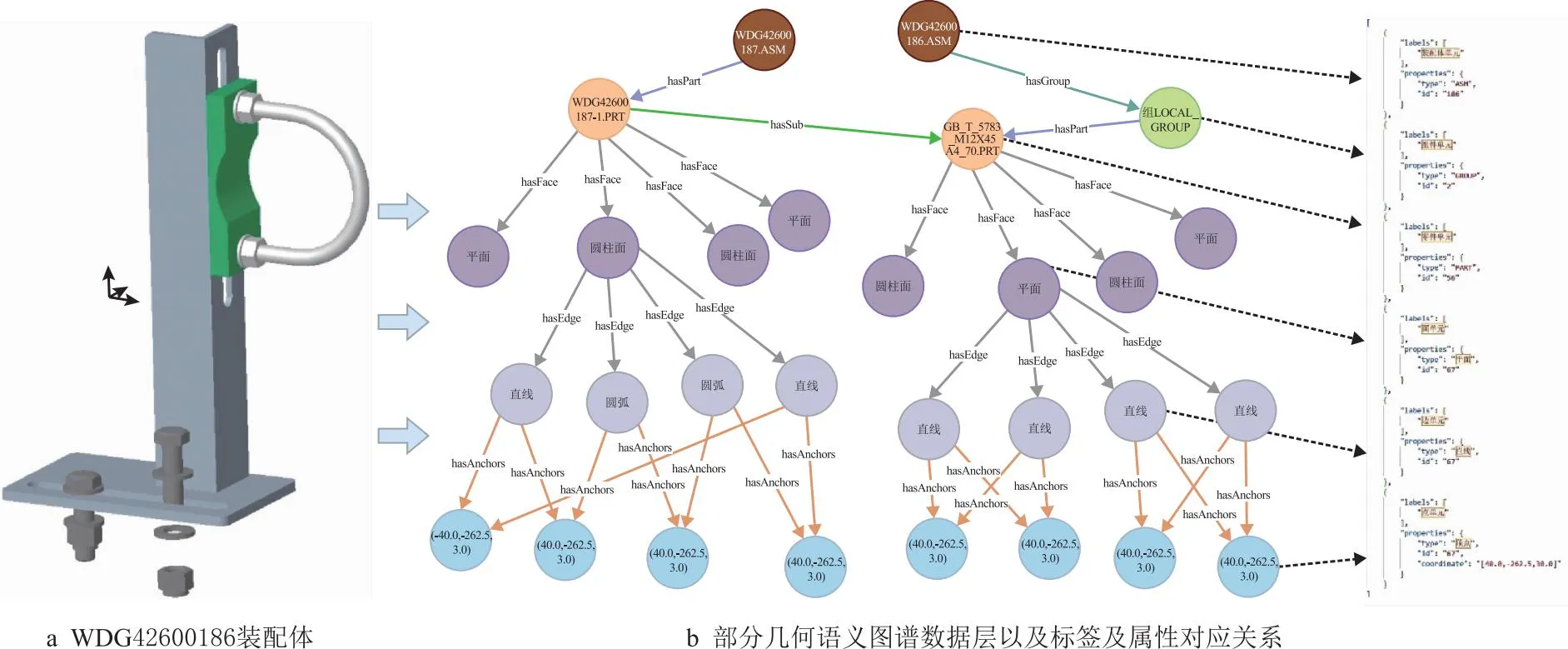
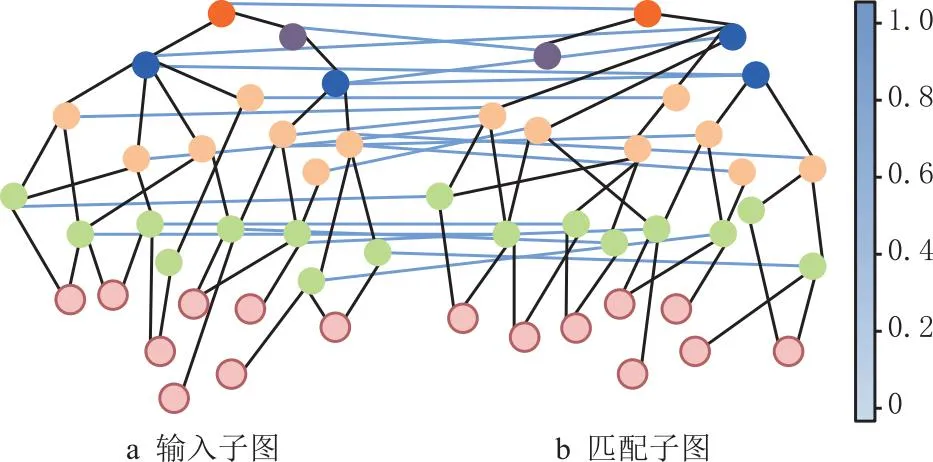
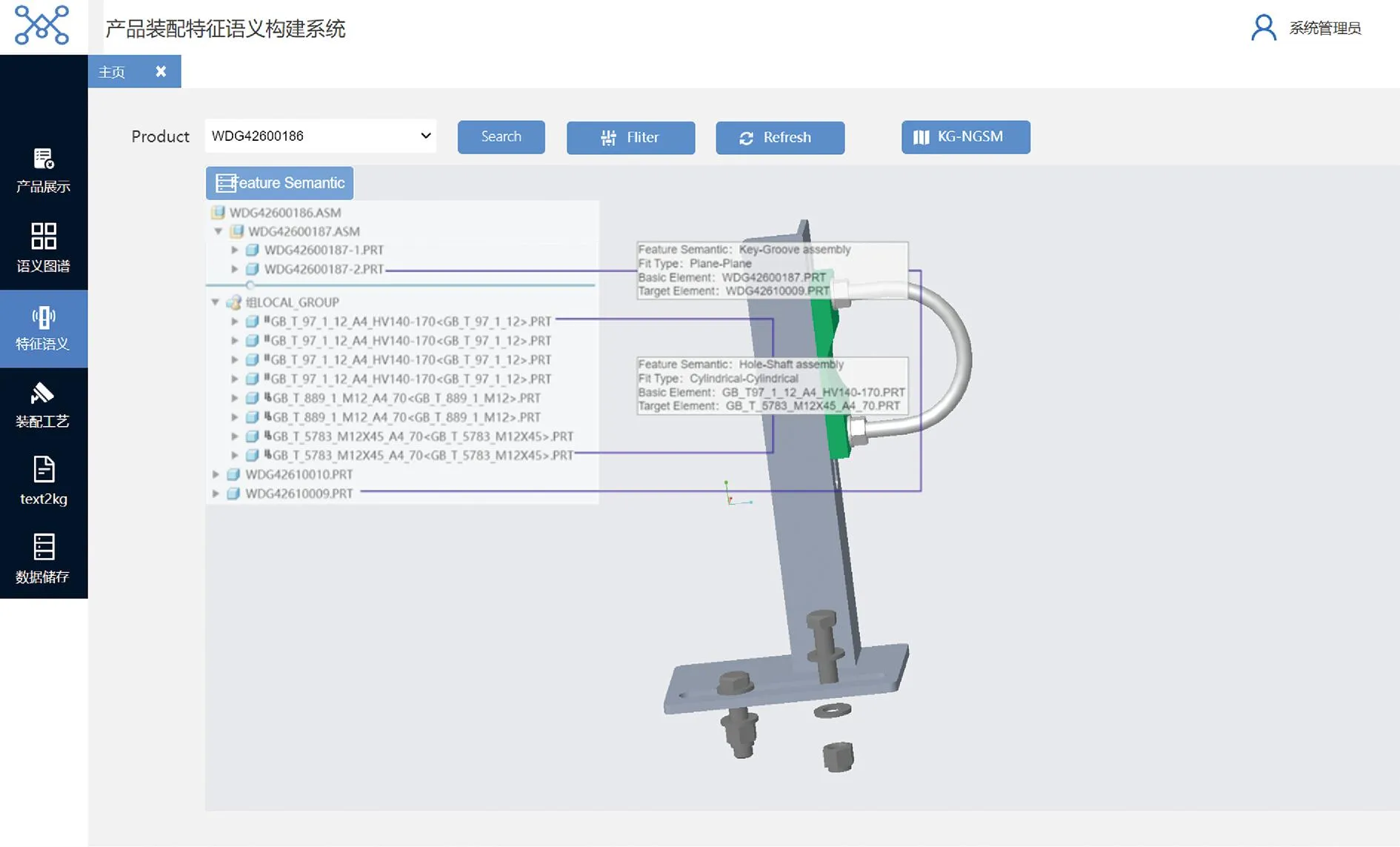
由于Mate与MateEntity储存于MateGroup对象中,形式为Mate(Component1 图8 MateGroup对象解析流程 在装配设计的工程中,基于知识图谱可计算性的思想,根据2.1节描述的方法,将待识别的装配特征模型转换为由装配特征数据层构成的知识图谱G。以图G为匹配项,研究基于图匹配神经网络的相似装配特征项检索方法,从而构建出装配特征语义信息。基于知识图谱的特征识别流程如图9所示。 图9 特征语义重建流程 首先对glTF中性文件进行解析提取出其中的几何元素信息,将其映射为类、属性和值,并将他们以知识图谱的形式表示,将知识图谱G进行属性分解获得一系列子图。然后构建预定义装配特征实体库,计算知识图谱G与预定义装配特征实体库中的图谱的交叉注意力值,与阈值比较。若交叉注意力值大于阈值,则输出匹配的装配特征实例,否则将该特征作为孤立特征添加到预定义特征库中,扩展预定义特征库。 装配特征语义能否有效地重建出来,很大程度上取决于预定义特征库中是否包含该类特征语义,即特征原型子图是否保存至预定义特征数据库中。因此,需要在装配特征语义匹配之前创建预定义特征库。通过大量的实例分析,得出风力发电机机舱中几种典型的装配特征语义原型子图,如表5所示。 表5 特征库常见装配特征子图示例 在表5中,以螺栓螺母装配特征子图为例,图中绿色节点代表组件单元节点,橙色节点为零件单元节点,紫色节点为面单元节点,灰色节点为边单元节点,浅蓝色节点为顶点单元节点,红色虚线部分表示待装配件PRT1与PRT2和螺栓螺母连接件。由于螺栓螺母在设计中属于同一组件,因此在图中与组件节点LOCAL_GROUP存在hasPart语义关系。该特征子图是路径以组件单元为起点,以hasPart→hasSub→hasFace→hasEdge→hasAnchors为路径的子图。通过在知识图谱中表示螺栓GB_T_5783_M12和螺母GB_T_889_M12的几何元素,描述了参与螺栓螺母配合的零件PRT1和PRT2的几何与拓扑关系。而孔轴装配特征子图由于孔和轴的型号规格的多样性,因此特征库中的子图仅表示了孔轴装配特征的接触部分几何元素。该特征子图是路径以零件单元为起点,以hasSub→hasFace→hasEdge为路径的子图,表示了孔轴装配特征接触部分的几何拓扑关系。 给定两个图G1=(V1,E1)和G2=(V2,E2),其中V和E分别代表节点和边的集合。图匹配神经网络能够计算两个图之间的相似度得分s=(G1,G2),将两张图的节点和边根据其语义信息以及邻接结构信息映射至向量空间。经过信息传播器与聚合器,经计算图向量间的欧式距离从而判断图结构的相似程度[23]。其思想与寻找识别装配体中装配特征实体需要考虑装配体层级结构、几何元素(对应节点的语义)、连接关系(对应边的语义)等因素一致。图匹配神经网络由以下3个部分组成[24]: (1)编码层 首先输入一对由装配体层级结构数据层与装配体几何元素数据层构成的知识图谱G1=(V1,E1)与G2=(V2,E2),其中G1代表待匹配的装配特征实体项,G2代表预定义特征库中的装配特征实体项。通过编码层将节点和边转为状态向量来计算G1和G2的相似度。 使用one-hot来表示装配单元节点以及几何元素节点的特征向量,若以上两类节点的语义不同则相似度计算为0,相同则表示为1,如表6所示。在以hasSub→hasFace→hasEdge→hasAnchors的路径训练GMN(graph matching networks)模型时,该路径涉及到了图谱子图中的装配单元节点。因此表6中也列举了装配单元的特征向量,增强子图所包含的语义信息,提高图匹配的准确效率,保证装配特征语义重建的准确性。 表6 部分几何单元、装配单元的特征向量 节点与边的MLP编码器如式1与式2所示。 (1) eij=MLPT(ij)(xij),∀(i,j)∈E1∪E2。 (2) (2)传播层 传播层是图匹配神经网络的关键环节,用于衡量图结构中的节点或边的相似程度,包括信息流计算、匹配流计算与更新节点状态3个部分。 信息流mj→i为某条边和对应节点的状态信息,如式3所示: (3) 根据G1和G2中节点间的匹配程度,匹配流计算指不同节点间的交叉注意力值来获取差异信息,交叉注意力权重αj→i的计算过程如式(4)所示: ∀i∈V1,∀j∈V2且j′∈T(j)(V2)。 (4) (5) (6) (7) 其中:i为节点;j为i的一阶邻接节点;j′表示另一张图中与i同类型的节点;Sum为向量求和函数。 通过式(7),装配单元节点的状态向量能够在计算过程中捕捉组件的单元语义、几何单元语义以及装配结构等邻接关系,提高计算图结构间相似度的准确率。 (3)聚合层 聚合层主要是将节点的最终状态向量几何输入至聚合层中获取图结构的状态向量,本文采用0-1权重向量加权求和所有的节点状态向量,如式(8)与式(9)所示: (8) (9) (4)损失函数 本文将输入图对相似的标签设为+1,否则为-1,计算两张图的状态向量间的欧式距离构建Loss函数,如式10所示: (10) 其中:DB为数据库;l∈{-1,+1};γ为边界值,且0≤γ<1。 根据图匹配神经网络的结构,提出如图10所示的结合几何语义的图匹配算法。其中构造图谱以及编码模块主要是完成中性几何模型信息的抽取,提取节点初始特征构造知识图谱,信息传递及聚合模块是基于跨图注意力机制进行信息传递更新状态向量,匹配求解模块主要是将源图和目标图的节点和边嵌入至高维度空间中,计算向量间的欧式距离来判断两个图之间的相似程度。 图10 相似特征项检索流程 表7 相似装配特征实体检索流程 本文以上海某风力发电机企业的风机为对象进行装配特征语义的构建,如图11a所示。首先基于glTF文件与2.1节中的几何语义抽取以及映射方法,根据解析结果中的id值引用构建装配单元、几何单元节点及其名称、id属性与装配结构关系,最终得到构建装配特征语义的“体-面-边-点”信息。使用Python、Neo4j、JavaScript等工具构建风力发电机装配体知识图谱数据层。对照语义映射以及JSON表设计过程,风机装配体WDG42600186对应的几何语义部分知识图谱如图11b所示。图中褐色节点为装配体单元节点,绿色节点为组件单元节点,橙色节点为零件单元节点,紫色节点为面单元节点,灰色节点为边单元节点,浅蓝色节点为顶点单元节点。图11b以JSON格式列举了部分节点的属性值。表8为WDG42600186部分几何单元/装配单元节点数据统计。 表8 图谱节点数据统计 图11 风机装配体几何语义图谱构建 首先基于几何语义图谱的数据层知识子图来训练图匹配网络模型,然后将待识别的几何语义知识子图与预定义装配特征库中的子图输入至图匹配网络进行相似特征实体的检索,最后根据计算交叉注意力值来识别相似的装配特征实体语义,完成装配特征语义的构建。 在训练图匹配神经网络时,以组件单元为起始节点,以hasSub→hasFace→hasEdge→hasAnchors为路径从几何语义知识图谱中抽取局部子图谱。在构建训练样本时,随机在原有子图上删除节点或边来生成新的验证集与测试集,以p=0.2的概率随机删除子图中的边作为正样本对,以p=0.5的概率随机删除子图中的四条边作为负样本对。循环5次,总计生成1180个图对,其中训练集占比0.8,测试集占比0.2。 本文采取的训练环境为Pytorch1.8.1+Python3.9,batch-size为20,α为0.001,优化器采用Adam。其中,模型参数节点状态向量设置为32,边状态向量设置为16,图状态向量设置为128,MLPT(i)编码器为32×64×32,MLPT(ij)为16×32×16,MLPm为80×160×32,MLPgate为32×64×32,MLPG为32×64×128。 模型准确率的影响因素主要为传播层数以及边界值γ,本文采取的组合参数为传播层数1至传播层数5,边界值γ∈{0,0.2,0.4,0.6,0.8}。对比不同参数组合下模型在测试集的准确率,如图12所示。从图中可以发现,当传播层数为4,边界值γ为0.6时,模型对图相似性的判断最为准确。 图12 不同参数组合下图对相似性判断准确率的变化 以上海某企业风电机组传动链WDG42600186装配体为例,基于训练后的图匹配神经网络检索预定义特征库中的相似装配特征实体。首先通过第2章描述的方法抽取模型的几何语义信息并构建几何语义图谱,将局部子图作为训练后的图匹配神经网络的输入,其形式如图13所示。图中红色节点代表装配体单元,灰色节点代表组件单元,橙色节点代表面单元,绿色节点代表边单元,粉红色节点代表点单元。本文以0.7为阈值,将输入图与预定义特征库中的子图进行遍历计算交叉注意力值。若该输入子图的交叉注意力值大于阈值,则在预定义特征库中读取匹配子图的相关特征语义,从而构建出输入子图的装配特征语义信息,否则考虑将该输入子图的特征信息作为孤立特征扩展预定义特征库。 图13 子图注意力计算 根据本文提出的方法,最终将构建的装配特征语义以JSON文件形式保存至MongoDB数据库中,方便为后续装配过程提供装配信息(如图14)。 图14 装配体结构层次及特征信息 根据上述装配特征语义构建方法,本文基于Visual Studio Code 2022开发平台,React框架以及JavaScript工具语言开发一个集成化的装配特征语义构建系统。该系统面向风机行业的风力发电机产品,可以实现风机产品几何语义信息的抽取、装配特征等非几何语义信息的提取,如图15所示。该界面展示的是风机装配环节的风电机组传动箱二级行星轮系,从导入风机产品模型开始,可以按照模型零件名称进行查询与筛选,按照产品-组件-零件的层次关系展示风机模型的树结构信息,并将抽取出来的几何语义信息以知识图谱的形式表示,同时展示该行星轮系各个零部件的几何语义信息表。 图16展示了风电机组WDG42600186装配体的几何语义图谱,如图所示图谱的路径关系为hasGroup→hasPart→hasFace→hasEdge →hasAnchors,且节点与关系支持查询。WDG42600186的几何语义图谱相关节点与关系的数据统计以表格形式展示。图17为产品装配特征语义提取界面,根据上述基于几何语义图谱与图神经网络的特征语义构建方法,快速准确地构建WDG42600186装配体的相关装配特征语义。例如螺栓GB_T_97_1_12_A4_HV140-170与螺母GB_T _5783_M12X45_A4_70之间存在装配关系,装配关系为孔轴装配,配合类型为圆柱面-圆柱面,且装配基本件为螺栓GB_T_97_1_12_A4_HV140-170,待装配件为螺母GB_T _5783_M12X45_A4_70。该系统可以为风机装配环节提供装配信息,可以辅助装配操作人员的实际装配过程。 图16 语义图谱界面 图17 特征语义界面 由于中性几何模型缺少装配特征语义信息,需要构建中性几何模型的装配特征语义信息用于风机产品的装配环节。本文提出基于中性几何模型的几何语义信息的抽取方法,抽取几何语义生成知识图谱,并基于图神经网络计算图谱相似度构建出风机产品的装配特征语义信息,主要工作如下: (1)提出了基于知识图谱的中性几何语义模型KG-NGSM,对中性几何模型的装配元素、几何元素以及装配关系进行统一规范化的表达。提出一种面向中性几何模型的几何语义抽取方法,以glTF模型为例,抽取中性几何模型的几何语义,通过设计JSON格式将几何语义进行统一管理。 (2)基于知识图谱与图匹配网络实现装配特征语义的构建,首先通过CAD接口实现装配特征约束的提取,其次把从中性几何模型中抽取出来的几何语义以知识图谱三元组的形式表示,利用图匹配网络计算图谱的相似图信息从而完成产品特征语义信息的构建。 (3)开发面向风机产品的装配特征语义构建系统,实现风机产品模型装配特征语义的构建,为管理人员以及装配操作人员提供装配辅助功能。现场使用结果表明,该系统对于指导风机产品实际装配环节具有一定效果。 本文所研究的内容关注于装配特征语义中装配配合种类的表达与重建过程,并未将装配关系中的配合类型(间隙配合、过盈配合、过渡配合)的表示与重建纳入研究范围。因此为了保证装配特征语义重建的完整性,本文未来的研究可以基于二维CAD文件,装配工艺手册等文件类型,利用表格划分和自然语言处理技术自动提取出风力发电机的装配配合类型,从而将相应装配语义定义在知识图谱中。后续工作也可以尝试基于知识图谱进行装配序列规划,从而加强装配特征语义构建的全面性。
3 产品装配特征语义构建方法
3.1 装配特征语义构建流程
3.2 基于图匹配神经网络的相似装配特征实体项检索
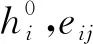


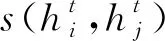
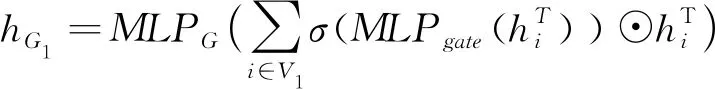



4 案例验证与分析
4.1 几何语义知识图谱构建
4.2 相似特征项检索


5 系统实例展示

6 结束语
猜你喜欢
少先队活动(2020年12期)2021-01-14
英语学习(上半月)(2019年9期)2019-10-10
同济大学学报(自然科学版)(2019年2期)2019-04-02
中成药(2017年3期)2017-05-17
电子科技大学学报(2016年2期)2016-08-31
米娜·女性大世界(2016年8期)2016-08-17
领导科学论坛(2016年9期)2016-06-05
工业设计(2016年11期)2016-04-16
华东师范大学学报(自然科学版)(2014年1期)2014-04-16
食品工业科技(2014年11期)2014-03-11
