
基于双分支点流语义先验的路面病害分割模型
2024-04-09 01:41庞荣杨燕冷雄进张朋刘言
智能系统学报 2024年1期
庞荣,杨燕,冷雄进,张朋,刘言
(1.西南交通大学 计算机与人工智能学院, 四川 成都 611756; 2.可持续城市交通智能化教育部工程研究中心,四川 成都 611756; 3.招商局重庆公路工程检测中心有限公司, 重庆 400067; 4.国家山区公路工程技术研究中心,重庆 400067)
我国公路投资固定资产累计10万亿元,公路总里程接近520万公里[1]。完善的公路路网和交通体系为推动国家经济快速发展和加快城市化进程提供坚实的保障[2]。但是目前车多路多的严峻形势,对公路养护提出了更高的要求,其中裂隙和坑槽等道路病害严重威胁到行车安全和人民生命健康,及时发现道路病害能避免非人为因素,保障车辆驾驶安全[3]。传统人工路面病害识别检测方法效率低下并且极具主观性,急需引入路面病害智能化高效检测,来加快智慧交通养护的发展,提高识别准确率的同时实现降本增效[4]。
基于数字图像处理方法的路面病害识别算法需要先使用直方图均衡、灰度变换等技术进行预处理,再使用投影法或者边缘检测对图像进行分割,使用人工设计的卷积核进行特征提取,最后通过反向传播训练神经网络实现路面病害识别。基于机器学习的路面病害识别算法的特征提取需要依赖人工经验,通过机器学习图像特征提取算法自行挖掘特征表示,常见的算法有尺度不变特征变换算法和 方向梯度直方图算法。但是传统机器学习算法是基于大量假设条件通过详细数学推导而设计出来的,不具有通用性。而基于深度学习的路面病害识别通过车载摄像头采集RGB路面图像,利用车载边缘端设备的数据传输服务将图片传输到云计算平台并利用深度学习图像算法进行识别,具有较强的鲁棒性。
虽然深度学习方法相对更加鲁棒,但是目前此类算法仍然存在许多难点:1) 采集图像的质量和清晰度较低,路面病害与道路的几何结构特征对比不明显,影响算法识别率。2) 路面病害尺度不一致且相对复杂的真实路面背景普遍较小,类别不平衡问题极其严重。3) 目前大部分巡查设备的车载摄像头安装在车底并垂直地面进行病害采集,利用此方法采集的图像识别效果好,具有背景简单、病害相对背景占比大、清晰度高等特点,但是存在道路病害不完整,重复识别等问题。
针对上述问题,本文提出了一种基于双分支点流语义先验的裂隙、坑槽路面病害分割模型,可以对前置摄像头采集的低质量路面图像进行裂隙、坑槽病害分割。该网络模型由双重自注意力的语义先验模块、语义局部增强模块和稀疏主体采样点流模块组成,并采用双分支结构同步进行训练。其中,双重自注意力的语义先验模块运用高效自注意力机制和互协方差自注意力机制分别对图像的二维空间和特征通道进行语义特征的提取。语义局部增强模块利用深度可分离卷积对语义先验特征进行局部聚合,并利用全连接层进行升维和降维操作,切换特征空间维度进行特征聚合。稀疏主体采样点流模块可以融合跨层和本层语义特征并利用稀疏采样的方式对病害前景进行特征提取和传播,以缓解类别不平衡问题。
本文的主要贡献如下:1)提出一种基于双分支语义先验网络,并运用高效自注意力机制和XCiT自注意力机制分别对二维空间和特征通道进行语义特征提取,以提高低质量复杂背景的病害识别率。2) 引入语义局部增强SLeff模块提高局部特征聚合能力。3) 提出了一种新的稀疏主体点流模块,并与传统特征金字塔网络相结合,进一步缓解路面病害的类别不平衡问题。4) 构建了一个真实场景的道路病害分割数据集,并在该数据集和公开数据集上与多个基线模型进行对比实验,验证了模型的有效性。
1 路面病害识别相关工作
传统路面病害分割检测主要依赖数字图像处理技术,其过程一般包括以下步骤:1) 定义每个图像像素的各种梯度特征;2) 使用二值分类器判断像素点所属类别。路面病害分割检测算法总体可以分成基于阈值化,显著性和图像边缘3大类[5-7]。Sheng 等[8]提出一种基于梯度提升决策树的路面裂缝检测方法,该方法通过结合多层次特征来描述裂缝,并充分利用了裂缝的结构化信息,使用梯度提升决策树算法训练模型。Sun等[9]使用领域加权对病害附近像素进行加权计算,然后使用局部阈值化对加权结果进行精细化分割,最后为了解决病害连接问题将膨胀法运用在病害特征上,取得良好结果。曹建农等[10]提出将均值漂移与直方图模式判别方法对已分块图像进行平滑处理,根据图像直方图模式特征判断有无病害,结合多方向搜索进行分割。然而上述方法都是基于人工设计特定特征提取模块,无法自适应不同病害环境,不具有通用性。
随着深度神经网络在计算机视觉领域的不断发展,高效智能化路面病害识别成为可能。基于深度学习的路面病害检测主要分为深度病害目标检测[11-13]和深度病害语义分割[14-16]两大类。这两大类检测方法根据特征提取网络的不同又可以分为基于卷积神经网络和基于视觉Transformer的病害识别算法。实际项目中对路面病害识别采用目标检测的方法占主流,而基于语义分割的病害识别方法相对较少,因此具有较大的研究空间。
Zhang等[17]提出一种基于深度卷积神经网络的路面裂缝检测方法,将切割独立的小块图像输入神经网络进行分类,并将分类结果组合成一整张概率图,其中高亮部分作为病害区域。韩静园等[18]将全卷积神经网络用于路面裂缝分割,分析通道特征的关系,在特征金字塔网络的池化层加入挤压和激励模块,利用权重对原始特征在通道上进行重标定,自适应地为裂缝边缘、图案和形状等特征分配权重。Yang等[19]提出一种用于路面裂缝检测的特征金字塔和层次增强深度卷积网络,该网络以特征金字塔的方式将上下文信息集成到低层特征中进行裂纹检测。
由于Transformer所具备的长距离上下文建模能力和并行计算能力使其在自然语言处理领域取得巨大成功,因此相关学者开始尝试将其应用在计算机视觉领域[20]。Xie等[21]提出一种简单高效且鲁棒性强的语义自注意力分割模型(segmentation transformer, SegFormer),该模型由层次化自注意力编码器层和仅由几个全连接层构成的解码器2部分组成。Strudel等[22]提出的Segmenters是基于最新的视觉自注意力模型的研究成果,将图像分割成块并将它们映射为一个线性嵌入序列,用编码器进行编码,再由Mask Transformer将编码器和类嵌入的输出进行解码,解码器可以通过用对象嵌入代替类嵌入来直接进行全景分割。Carion等[23]提出的基于自注意力的目标检测算法通过在解码器上附加一个掩码头并扩展到全景分割任务,并获得有竞争力的结果。
2 基于双分支点流语义先验的复杂路面病害模型
模型整体框架如图1所示,主要由自注意力层、语义先验层与稀疏主体采样点流模块组成。模型整体流程如下:输入图像通过图像块划分层变成统一大小的图像块,利用通过线性投射层和分层窗口自注意力模块对前置摄像头采集的真实路面病害图进行特征提取;然后通过基于语义先验模块指导后续模块的特征更新方向;通过稀疏主体点流模块对病害前景特征点进行采样,并利用采样点进行训练。最后利用双分支训练结构同步完成自注意力层和语义先验层的更新优化。另外,本文利用语义局部增强模块对语义先验层输出的语义特征张量在更高维度的特征空间进行局部语义聚合。
2.1 基于双重注意力机制的语义先验模块
大部分语义分割任务都是对已经预训练好的骨干网络进行微调,以适配当前任务。但是直接对预训练好的骨干网络进行微调缺乏语义指导,忽略了整体网络在编码阶段提供的语义上下文信息。基于此,本模型引入Semask模型[24]的思想,在特征提取骨干网络中添加图像语义信息,每个先验语义模块都为后续特征提取模块的微调提供指导意义,使得整体网络的语义优化朝着更加合理的方向。具体来说,本模型设计了一个新的语义解码器对中间语义先验信息提供监督,使用基于双重自注意力的语义先验模块,用来捕获全局整体图像特征在空间和通道2个维度的关系。对于图像空间级别的特征语义提取,本文采用高效自注意力机制[25];对于特征通道维度级别的语义特征提取;本文采用XCiT自注意力机制[26]。相较于传统的注意力计算方式,同时对这2个维度分别建模可以获得更多的上下文信息和关系。基于双重自注意力的语义先验模块整体结构图2所示。
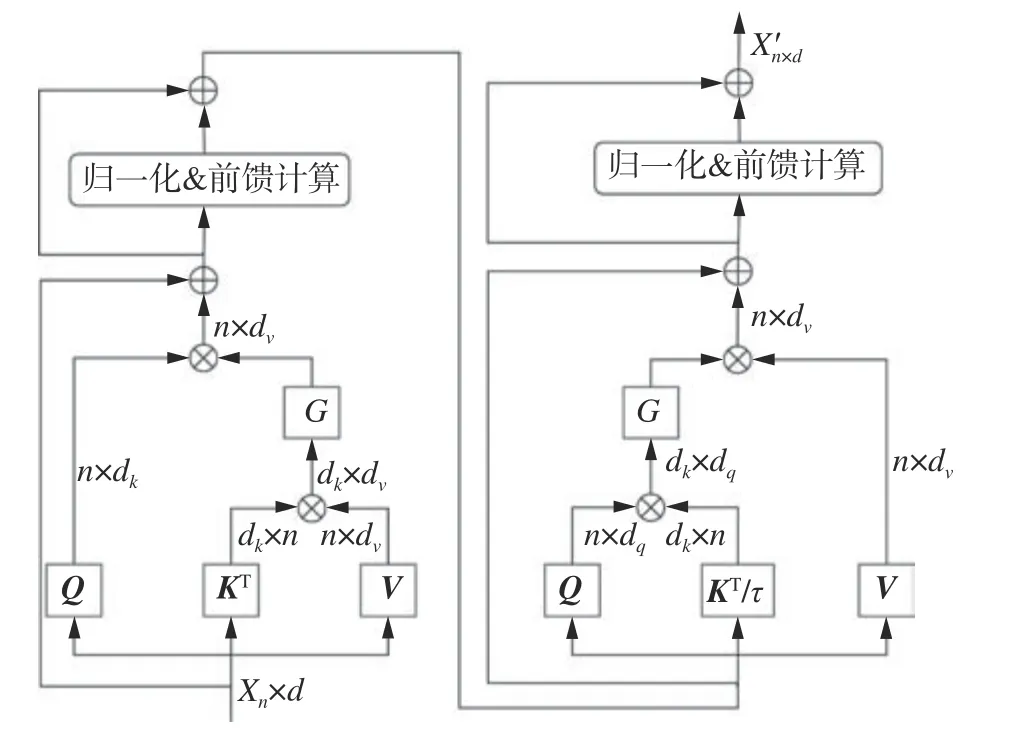
图2 基于双重注意力的语义先验模块整体结构Fig.2 The overall structure diagram of semantic prior modules based on dual attention
双重自注意力模块中的高效注意力机制的运算方式为
式中:张量Q∈Rn×dq,张量K∈Rn×dk,张量V∈Rn×dv,ρq、ρk分别表示张量Q和张量K沿矩阵每一行和每一列应用Softmax归一化函数。高效注意力改变传统注意力机制中间特征矩阵的乘法顺序,将归一化的张量K与张量V相乘,再将生成的全局上下文向量与归一化的张量Q相乘生成新的语义特征。其具有线性的时间和空间复杂度,同时与传统的自注意力机制有相同的表达能力,使用矩阵乘法的结合律来交换2个矩阵乘法的顺序,大大减小注意力机制运算次数,从n×n减小到dk×dv。
由于格拉姆矩阵(Gram)和协方差矩阵的特征谱非零部分等价,因此Gram矩阵和协方差矩阵能够互相用对方的特征向量表示,而原始自注意力计算过程可以看成类似Gram矩阵的计算过程。因此对于特征通道维度的语义信息提取,本文抛弃了传统沿图像块维度进行自注意力矩阵乘法的计算方式,改用基于互协方差自注意力机制来重新对特征维度进行建模,进一步提高运算效率,减少运算次数。互协方差自注意力机利用特征通道之间的注意力操作替代图像块维度之间显示完全成对交互计算,将图像块维度投影的键标准化张量K与图像块维度投影的查询标准化张量Q做乘法操作,得到关于特征通道的互协方差矩阵,并将该矩阵与值张量Q相乘得到特征通道的注意力张量。最后使用分组自注意力机制,对输入特征在通道维度进行分组,只对位于对角线的通道分组应用互协方差注意机制,避免对所有通道进行计算降低运算复杂度。值得注意的是,为了使得互协方差矩阵权重分布更加合理,互协方差自注意力机引入了可学习的温度参数τ。基于通道特征的互协方差自注意力公式为
综上所述,整个语义先验模块的完整流程为
式中:EA为二维图像高效注意力操作,XA为通道XCiT注意力操作,EAres和XAres分别为注意力计算中间结果,LN为层标准化。
2.2 融合局部增强信息的语义先验模块
虽然Transformer网络架构能够克服卷积的归纳偏置所带来的局限性,但是其训练需要大量数据集[27],其模型无法通过简单几层网络轻易捕捉本文所构建的小样本路面病害图像的几何低维拓扑结构信息。受到CeiT模型的启发[28],本文在语义先验模块中引入语义局部增强SLeff结构对语义信息进行局部聚合操作,该模块的详细设计如图3所示。
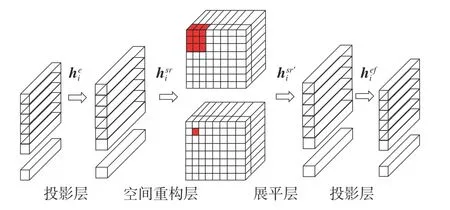
图3 语义局部增强模块结构Fig.3 The structure diagram of semantic local enhancement module
假设输入图像通过第i层特征提取网络和双注意力语义先验模块得到语义特征向量hi∈Rn×c,该向量首先经过线性投影层将维度扩展到n×e,然后根据图像原始Token的排列顺序将二维语义向量hei∈Rn×(c×e)重组为三维张量为了聚合局部特征,SLeff模块利用深度可分离卷积将新重组的特征矩阵进行卷积运算,最后将特征向量展平,并经过一个线性投影层恢复成与输入大小相同的语义特征向向量∈Rn×(c×e),其中n表示中间特征语义向量的行数,c表示特征向量通道的维度。语义局部增强模块SLeff流程为
式中:GELU为GELU激活函数,BN表示层归一化函数,Linear1和Linear2表示线性投影层,SpatialReStore表示像素重排函数,DWConv表示深度可分离卷积函数,Flatten表示特征矩阵展平函数。
2.3 稀疏主体点流采样模块
基于自注意力的语义分割模型需要图像中的每个像素点与全局像素点进行交互计算,但对于复杂背景占比较大的路面病害图,如果直接进行全局关系的建模就会造成大量计算的冗余,无法充分挖掘小面积前景的特征表示。此外,对于目前主流的特征提取网络,随着网络层数的增加语义特征包含的信息逐渐抽象和高级,但是语义特征分辨率却在逐渐减小,该特性会导致小面积的前景特征随着网络层数的增加而逐渐消失,不利于病害的识别。本文提出的稀疏主体点流模块通过在当前FPN层采样部分病害前景特征像素点作为重点关注对象,只将该部分像素点与全局像素点进行建模。同时该模型将相邻层特征进行下采样融合,利用下层高分辨率特征的具象语义信息补充本层低分辨率的抽象语义信息。针对传统点流方法没有考虑融合本层特征,本模块又对采样点所在层进行采样点自注意力聚合,并将其与跨层特征相结合,真正意义上完成了不同阶段的特征融合。稀疏主体点流采样模块通过稀疏注意力机制将相邻特征层的信息相关联,避免大量背景噪声点参与全局建模,减少运算次数,提高运算效率,缓解类别严重不平衡问题。同时跨层特征融合将不同层的分辨率信息与语义信息进行互补,兼顾高分辨率信息和高语义信息的相互统一,提高对复杂背景下小面积病害的识别能力[29],具体原理和操作如图4所示。
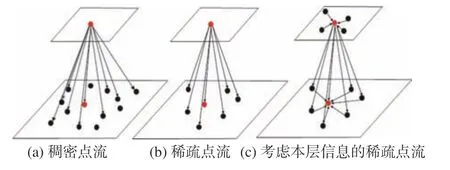
图4 考虑本层节点聚合信息的稀疏主体点流优化Fig.4 Sparse subject point flow optimization graph considering aggregation information of local nodes
假设图片经过编码骨干网络得到4组不同的中间特征张量ti。首先将本层语义特征张量ti与相邻层特征张量ti-1相叠加,叠加后的特征通过卷积操作得到融合低层具象特征和高层抽象特征的主体特征选择信息流张量ci。然后对原始特征图的主体特征选择信息流张量的非0特征值点与对应二维坐标相映射,并根据该映射完成对特征张量ti的更新。为了达到稀疏特征点的目的,选择更新后语义特征张量ti中特征值大小前top-n的点作为兴趣点,并根据兴趣点的坐标信息进行采样,最终得到稀疏语义特征向量。根据FPN结构的相邻特征大小倍率关系,可以计算出语义特征张量ti-1中对应主体特征选择信息流张量的非0特征值点集合的二维坐标。为了关联相邻FPN网络的特征,进一步提高其表达能力,还将本层稀疏采样点之间进行自注意力操作,通过2次矩阵乘法操作计算不同层之间语义特征的注意力矩阵,并将该矩阵与当前层稀疏语义特征向量相乘后求和,得到最终更新完成的全局稀疏语义特征张量。最后根据语义特征向量ti-1的采样坐标将对应位置的值插入到ti-1中(对应图5扩散操作),进而完成语义特征向量ti-1的更新操作,最终得到i-1层融合了i层语义信息的特征语义向量。稀疏主体点流结构如图5所示。
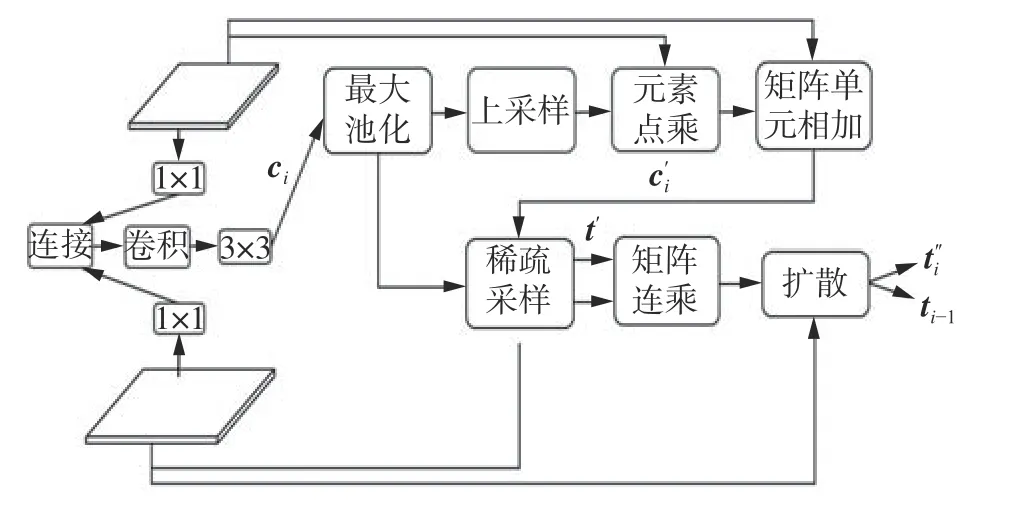
图5 稀疏主体点流结构Fig.5 Sparse subject point flow structure diagram
稀疏主体点流模块具体操作流程为
式中:Interpolation表示插值操作,AdaptiveMax-Pool2d表示自适应最大池化操作,Update表示根据采样点进行更新操作,Bmm表示矩阵乘法操作,Scatter表示扩散操作。
3 基于双分支点流语义先验的路面病害分割模型实验分析
3.1 数据集和指标
实验使用公开数据集Crack500和采集自自研车载自动化巡查项目的路面病害语义分割两种数据集。其中,Crack500数据集包含训练集1 896张、验证集348张、测试集1 124张图像。而自研巡查车路面病害数据集通过前置摄像头录制路面视频并传输到边缘服务器上,并隔固定时间间隔进行帧采样。该数据集收集了从2022年3月-9月重庆部分路面病害数据,每张图片的分辨率规整为1 080×720的PNG格式图像,一共包含1 000张路面病害图,训练集验证集的比例为3∶1,包含3个语义类别,分别为横向裂缝、纵向裂缝和坑槽。本实验采用的语义分割评价指标包括平均交并比(mIoU)、平均准确率(mPrecision)、召回率(recall)、F1得分和参数量(param)。各项指标表示如下:
式中:k表示种类数(不包含背景),pii、pjj、pij和pji分别表示预测正确属于该病害、预测正确不属于该病害、预测该类病害不属于该类的假类和预测不属于该类的病害属于类(如果第i类为正类)。本实验如果在mIoU相差不大的情况下,即使出现mIoU偏低的情况,也着重观察平均准确率、召回率及F1得分,原因如图6所示,由于人工对低质量路面病害图仅仅靠肉眼观察后打标不可能做到像素级别,而所提供数据集的Ground Truth相较于预测结果而言反而有漏打少打的情况,因此仅仅依靠计算mIoU会出现效果好的模型反而mIoU较低的情况,无法说明模型的准确性,因此着重考虑后面3个指标。

图6 人工路面病害打标Ground Truth与模型预测结果对比可视化Fig.6 Visualization of comparison between Ground Truth and model prediction results for artificial pavement disease marking
所有实验均在Pytorch-GPU-1.8.1和Python-3.7上实现,并在单张NVIDIA GeForce RTX 3 090(显存24 G)上运行。为了实验的公平,所有实验模型均采用基准学习率为γ0=0.001的AdamW优化器,并采用poly学习率衰减,设置训练迭代次数为80 000,批处理大小为4。
3.2 实验结果对比
本文在上述2个数据集上将所提出模型与其他语义分割模型进行比较,如表1和表2所示。比较方法分为2类,基于CNN的语义分割算法和基于视觉Transformer的语义分割算法,基于卷积网络包括以ResNet为骨干网络的Ccnet[30]、Deeplabv3[31]、Deeplabv3+[32]及Hrnet系列[33]和Cgnet[34];基于视觉Transformer的分割模型包括以VIT为骨干网络的Setr[35]、Segmenter[22]和Segformer[21]。

表1 不同语义分割模型在自研路面病害数据集上的结果对比Table 1 Comparison of results of different semantic segmentation models on self-developed road surface disease datasets

表2 不同语义分割模型在Crack500公开数据集上的结果对比Table 2 Comparison of results of different semantic segmentation models on Crack500 public dataset
在2个数据集上,基于Transformer的语义分割模型的效果要远差于CNN,是因为自注意力网络训练需要大规模数据集才能充分挖掘全局关系,而2个数据集中训练集数量远远不足。但是,本模型使用Transformer骨干特征网络却在2个少量样本的数据集上比所有卷积方法在Flops、mPrecision、Recall和F1-score4个重点指标上都高,说明了该算法在训练少样本的路面病害样本上具有巨大潜力。同时可以观察到在自研数据集上,本文方法的mPrecision指标与Deeplabv3+接近;但是Flops远低于该方法,说明本文方法在相同精准度的情况下具有更快的运算速度;同理,本文方法与基于ResNet101的Ccnet模型在Recall指标接近,但是Flops减少了接近2倍,进一步说明本文模型的有效性(注:虽然Hrnet18网络的参数量仅9.64 M,但是本文不将其作为最佳参数量结果的原因是该网络表现其他指标极差,没有参考意义。同理认为所有模型中浮点运算次数最低的为本文的模型,而不是Segformer)。而在公开数据集上,由于数据集质量大幅度提高,所有方法的指标相较于自研数据集都有大幅度提升,但是本文所提模型表现大幅优于基于所有对比方法,进一步验证了本模型在高质量语义分割数据集上更具鲁棒性和有效性。
表3给出不同大小的 Swin-Transformer 骨干网络细节参数。在表4中本文对Swin Transformer 3种不同编码器变体进行实验,其中Swin-T-FPN表示利用Swin-Tiny作为编码器,FPN作为解码器展示使用不同骨干相同网络效果对比。变体具体参数如表3所示,基于Swin-Transformer的tiny版本的骨干网络在所有指标表现最好;相反,使用更大版本的Swin-Transformer特征骨干网络反而会影响模型的精度,在各项指标中都有大幅度的下滑。原因是更大的模型虽然拟合效果更好,但是由于实验使用的数据集质量较低,数量较少,针对小数据集,大模型更容易出现欠拟合的现象。也就是说,相同训练参数配置的下,大模型可能会一直陷入一个局部次优解,无法对模型全局参数有个更好的更新。

表3 不同大小的Swin-Transformer骨干网络细节参数表Table 3 Detailed parameter table of Swin-Transformer backbone network of different sizes

表4 Dual-SePointFlow模型使用不同大小Swin-Transformer骨干网络效果对比Table 4 Comparison table of effects of Dual-SePointFlow model using Swin-Transformer backbone networks of different sizes
3.3 消融实验
在本节实验中,将对双分支训练结构、语义先验模块和稀疏点流主体模块进行消融实验,分析本文设计的模块对于真实复杂路面病害识别的有效性。表5展示了3种结构的消融结果,最简单的Swin-Transformer+FPN模型出人意料的召回率最高,表明该方法查全率高,但是查准率非常低,综合两者的F1得分非常低;原始的semask模型相较于第1个模型添加了最简单的语义先验模块,其模型牺牲较多的查全率去提高查准率,但是效果甚微,F1得分非常低,效果不理想。在原始semask基础上添加稀疏点流模块,查准率小步上升,但是召回率进一步下降。而采用新设计的双重语义先验模块牺牲较少查准率的同时大幅度提高查全率,F1得分也得到显著提高,证明了双重语义先验模块的有效性。最后结合局部增强模块得到最好的结果,验证该模块的有效性。
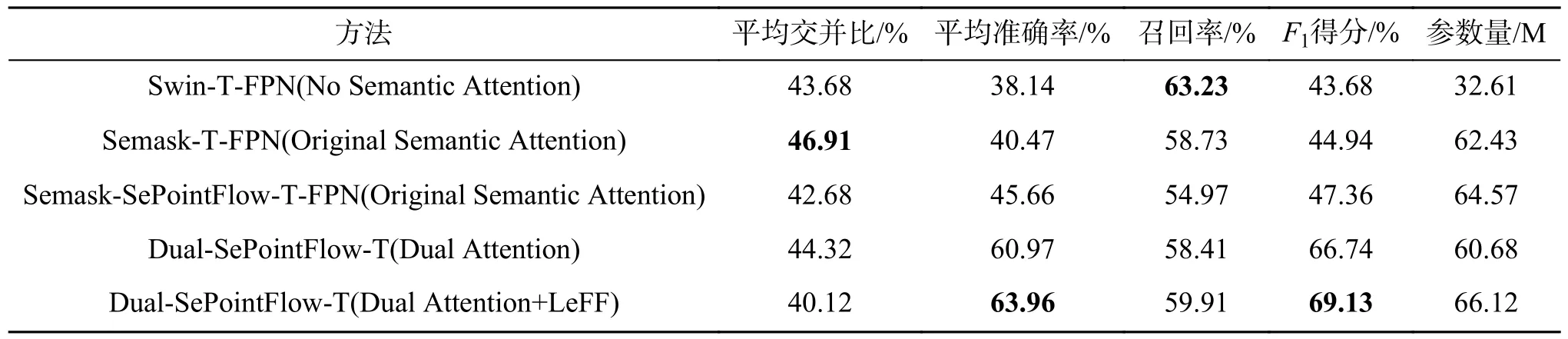
表5 Dual-SePointFlow不同模块消融验证实验效果对比Table 5 Comparison of ablation validation experiments on different modules of Dual-SePointFlow
3.4 可视化结果分析
本节主要展示在自研车载自动化巡查项目的路面病害语义分割数据集上的可视化结果分析。图7给出了不同经典语义分割模型的实验结果对照。基于卷积的分割模型中Cgnet预测的细小细节最多,Ccnet和Hrnet基本上无法预测细小裂缝细节。而对于较大的裂缝,所有卷积模型表现良好。基于Transformer的分割模型对于细小裂缝识别总体表现很差,但是对于较大裂缝的识别效果比卷积更好,预测结果更加完整。总体而言,在小数据集上基于卷积的分割模型效果更胜一筹。而本文方法效果最好,基本上准确预测了大坑槽和细小的裂缝细节,证明了本文模型的有效性。

图7 不同语义分割模型实验结果对照可视化Fig.7 Comparison visualization of experimental results of different semantic segmentation models
图8给出了本文模型在自研路面病害数据集上的消融实验结果对照。纯Swin骨干加FPN网络结构预测结果最差,无法提取病害整体关系,因此出现一条裂缝被识别成好几种病害。而添加最原始的语义先验模块,缓解数据集不够导致无法提取病害全局特征。进一步添加稀疏主体点流模型,只关注病害特征点,预测病害的完整度更加好,最后使用本文的语义先验模块,预测结果光滑平整,基本上不会出现病害不连续的情况,验证了本文所设计模块的有效性。

图8 Dual-SePointFlow模型消融实验结果对照可视化Fig.8 Comparison visualization of ablation experimental results of Dual-SePointFlow model
4 结束语
本文提出了一种基于双分支点流语义先验的真实路面病害识别模型。针对路面病害数据集小、图像质量差等问题,提出了双分支语义先验模块来指导骨干特征提取网络更好地优化;针对前置摄像头采集图像病害占比小的问题, 提出了稀疏主体点流模块,只对部分病害前景采样点进行计算,同时融合不同层与自身层的特征信息进行更新,进一步提高识别精度的同时缓解了病害类别严重不平衡问题。为了训练和验证模型,本文构建了一个真实路面病害分割数据集,通过大量实验验证本文方法不仅能在真实环境下有效地识别路面病害,而且针对小样本和类比不平衡的情况也具有好的效果。由于类似的全景路面病害数据集很少,本文只在本数据集上表现良好,并验证本模型的有效性。但是想要模型做到强泛化能力和强鲁棒性,具有一定的挑战性和研究价值。未来如果有更多全景路面数据集公开,还可以进一步探究如何更好挖掘复杂背景与前景的关系,提高其检测和分割的识别率。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
数学物理学报(2021年1期)2021-03-29
五邑大学学报(自然科学版)(2020年4期)2020-12-09
成都信息工程大学学报(2019年3期)2019-09-25
传媒评论(2017年3期)2017-06-13
自动化学报(2017年5期)2017-05-14
山西大同大学学报(自然科学版)(2016年2期)2016-12-12
第二课堂(课外活动版)(2016年2期)2016-10-21
探测与控制学报(2015年4期)2015-12-15
东南法学(2015年2期)2015-06-05
