
基于云计算的大规模数据处理技术研究
2024-03-28 05:53马红梅
信息记录材料 2024年2期
马红梅
(伊犁开放大学 新疆 伊宁 835000)
0 引言
大规模数据处理已经成为当今社会和经济环境中的一个关键驱动力,无论是在科学研究、商业分析、医疗保健还是社会媒体等领域,数据都在不断积累和膨胀[1-3]。 然而,传统的数据处理技术在面对这种数据激增时往往显得力不从心。 因此,云计算作为一种强大的计算和资源存储技术,为大规模数据处理带来了新的机遇。 通过将数据和计算分布在云端服务器上,云计算可以有效地缓解数据中心的压力,提供高性能计算和存储服务。
在国际上,云计算和大规模数据处理已经受到广泛的关注和研究。 各大科研机构和高校积极投入到云计算技术的研发中,提出了许多有影响力的理论和实践成果[4-6]。 例如,亚马逊的AWS、微软的Azure 和谷歌的GCP等云服务提供商已经建立了庞大的云计算基础设施,为全球用户提供了各种云计算服务。 在国内,云计算和大数据处理也引起了学术界和产业界的广泛关注。 中国的互联网巨头如阿里巴巴、腾讯和百度等公司已经投资了大规模的云计算基础设施,并积极开展与大数据处理相关的研究和产品开发。
本研究旨在探讨如何充分利用云计算的优势,构建一个高效、安全和可扩展的大规模数据处理系统,以应对不断增长的数据挑战。 主要研究包括阐述云计算的概念和特点,以及提出云计算大规模数据处理框架。 在此基础上,着重研究了关键技术,包括分布式存储与计算、并行计算与任务调度以及数据安全与隐私保护。 深入研究这些内容旨在为云计算环境下的大规模数据处理提供更好的解决方案,以满足现代社会不断增长的数据处理需求。
1 云计算模型构建
1.1 云计算的概念
如图1 所示,云计算是一种计算模型,通过网络将数据库、代码和移动设备与云计算中心连接起来,以弹性、按需的方式满足广泛应用的需求。 其核心特点包括多租户共享资源、可伸缩性、高可用性和自服务性。
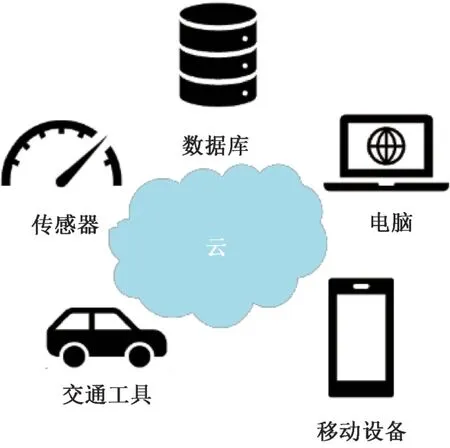
图1 云计算的概念
该计算模型为大规模数据处理提供了理想平台,因为其多租户共享资源使得大规模数据的存储和处理更加经济高效,可伸缩性使得系统能够适应不断增长的数据量,高可用性确保数据始终可用,自服务性则使用户能够根据需要自主管理和配置资源,从而满足大规模数据处理的复杂需求。
1.2 云计算大规模数据处理的总体框架
如图2 所示,本研究提出了一个基于云计算的大规模数据处理总体框架,主要分为数据采集和存储层、数据处理引擎、任务调度和管理等几个关键组成部分。
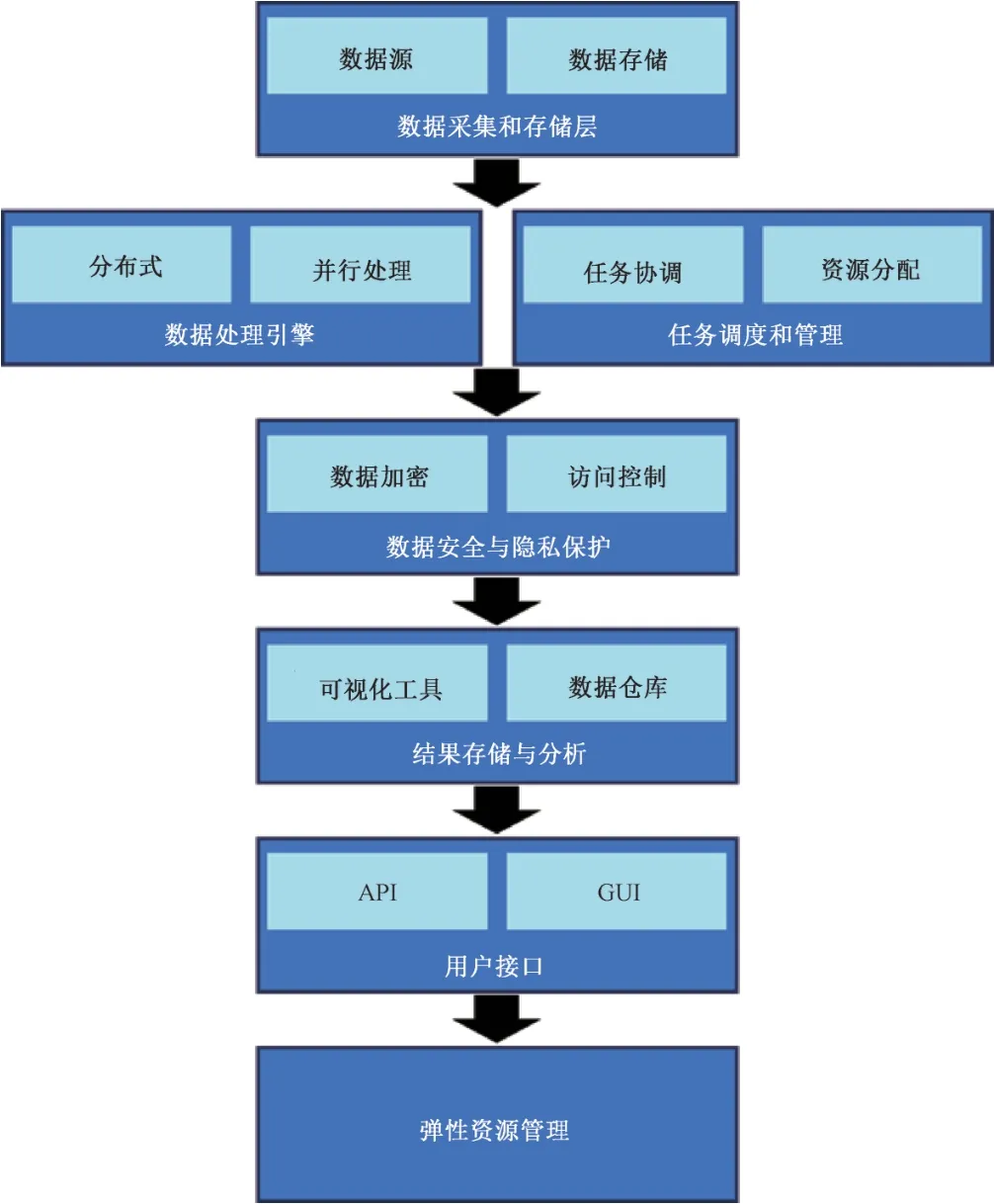
图2 云计算大规模数据处理总体框架
(1)数据采集和存储层:这一层负责收集各种数据源的信息,并将其存储在云计算环境中,可以使用分布式存储系统来确保数据的高可用性和容量扩展性。
(2)数据处理引擎:数据处理引擎是大规模数据处理的核心,支持分布式计算和并行处理。 典型的数据处理引擎包括Hadoop[7-8]和Spark[9]等,它们能够处理大规模数据集,并提供高吞吐量和低延迟。
(3)任务调度和管理:任务调度和管理组件负责协调数据处理任务,确保它们在云计算资源上有效地分配和执行。 这有助于实现任务的并行处理和负载均衡。
(4)数据安全与隐私保护:保护数据的安全和隐私至关重要。 这一层涵盖了数据加密、访问控制等安全机制,以确保数据不被未经授权的用户访问或泄露。
(5)结果存储与分析:一旦数据处理完成,处理结果需要被存储和分析。 这一层包括数据仓库和可视化工具等,以支持用户从数据中提取有价值的信息。
(6)用户接口:用户接口允许用户与云计算大规模数据处理系统进行交互,提交任务、监控任务执行进度,并访问处理结果。 用户接口可以是图形用户界面(graphical user interface, GUI) 或应用程序编程接口(application programming interface, API)。
(7)弹性资源管理:云计算环境的一个重要特点是资源的弹性分配。 这一层负责根据任务需求自动调整云资源,以满足不断变化的负载。
2 大规模数据处理的关键技术
分布式存储与计算、并行计算与任务调度、数据安全与隐私保护是云计算大规模数据处理技术的3 个关键部分[10]。
(1)分布式存储与计算允许数据分布式存储,确保数据的冗余和高可用性。 同时,分布式计算引擎能够将数据分成小块并分配给多个计算节点并行处理,有助于提高数据处理的速度和可伸缩性。
(2)并行计算与任务调度涉及将数据处理任务分解成多个子任务,并以并行的方式执行它们,能够充分利用云计算资源,以加速数据处理。
(3)数据安全与隐私保护确保用户的数据不受恶意攻击、泄露或滥用,维护了用户的信任。 因此,本研究聚焦于这3 方面关键技术的研究。
2.1 分布式存储与计算
假设一个大规模数据集,将其分为n个数据块,分别存储在不同的存储节点上,即D ={D1,D2,…,Dn} ,同时将任务分为m个子任务,分别分配给不同的计算节点进行并行处理,即T ={T1,T2,…,Tm}。
定义一个数据块的处理函数f(Di) ,表示对数据块Di进行处理的操作,可能涉及计算、过滤、聚合等操作。 同时,将每个子任务的执行时间定义为ti,Tj的处理时间为Tj的所有子任务的执行时间之和,如式(1)所示。
为了保证任务的高效执行,需要将子任务合理地分配到计算节点上,以最小化整体任务的处理时间。 为此,本研究使用贪心算法,通过考虑每个子任务的处理时间和节点的处理能力来进行决策。 假设每个计算节点的处理能力分别为c1,c2,…,cn,其中ci表示第i个计算节点的处理能力,将子任务Tj分配给处理能力最大的节点,以最小化整体任务的处理时间如式(2)所示。
式(2)中,argmax 表示取最大值的操作。
在处理数据时,本研究采用MapReduce 分布式计算框架,将数据块分配给不同的计算节点进行并行处理。 具体而言,对于每个数据块Di,可以将其映射到计算节点进行处理,如式(3)所示。
式(3)中,Map操作将数据块Di映射到计算节点,进行局部处理,Reduce操作将各个计算节点的处理结果进行汇总和整合,得到最终的处理结果。
2.2 并行计算与任务调度
假设有m个子任务需要在n个计算节点上执行,每个任务具有不同的处理时间,任务的处理时间可以用ti表示。 同时,每个计算节点的处理能力不同,可以用ci表示,其中i表示计算节点的索引。 并行计算的任务是将这些子任务分配给计算节点,以最小化整体任务的完成时间。整体任务的完成时间表示为T,如式(4)所示。
式(4)中,xi,j是一个二值变量,表示任务j是否分配给节点i执行,xi,j =1 表示任务j被分配给节点i执行,否则为0。
为了最小化T,本研究采用最短作业优先算法(shortest job first, SJF)的变种。 具体而言,将任务按照处理时间从小到大排序,然后将它们分配给计算节点:
(1)将任务按照处理时间从小到大排序:t1≤t2≤…≤tm;
(3)将任务按照处理时间从小到大依次分配给计算节点,直到所有任务都被分配;
(4)计算整体任务的完成时间T。
2.3 数据安全与隐私保护
为了确保云计算大规模数据处理框架中的数据安全与隐私保护,本方法采用一种经典的数据加密算法——高级加密标准(advanced encryption standard, AES)的变种。在该算法中,重点考虑数据的加密和解密过程,以确保数据在存储和传输过程中的安全和隐私。
对于要存储在云环境中的数据D, 使用AES 算法进行数据加密。 AES 算法使用一个密钥K来对数据进行加密,加密后的数据记为E(D,K),如式(5)所示。
当需要访问和处理数据时,用户需要提供密钥K来对数据进行解密,如式(6)所示。
式(6)中,AES-1表示AES的解密函数。
在数据传输过程中,可以采用安全套接层(secure socket layer,SSL)协议或传输层安全(transport layer security, TLS)协议,以确保数据在传输过程中的保密性和完整性。 这可以通过公钥加密算法和数字签名来实现,以保护数据不受未经授权的访问和篡改,如式(7)、式(8)所示。
式(7)、式(8)中,Kpublic表示公钥,Kprivate表示私钥。 该思路的目标是通过强大的加密技术来保护数据的安全和隐私。 它可以在云计算大规模数据处理框架中用于数据存储和传输过程,确保数据不受未经授权的访问或篡改,同时保护用户的隐私信息。
3 结语
本研究深入探讨了基于云计算的大规模数据处理框架,强调了云计算的概念、特点以及其在应对当今不断增长的数据挑战中的潜力,并提出了一个综合框架。 然后,介绍了大规模数据处理技术,包括分布式存储与计算、并行计算与任务调度以及数据安全与隐私保护等关键组成部分,以构建高效、安全和可扩展的大规模数据处理系统。在数据安全与隐私保护方面,提出了一种基于高级加密标准的算法,以确保数据在存储和传输中的安全性。 同时,在并行计算与任务调度方面,探讨了一种基于最短作业优先算法的变种,以实现任务的高效执行。
以上框架和算法的研究还有许多潜在的改进和扩展空间。 首先,可以进一步优化任务调度算法,以考虑更多因素如负载均衡、资源利用率等,从而提高系统的性能。其次,数据安全与隐私保护领域仍在不断演进,未来的研究可以集中在更高级的加密技术、访问控制机制和隐私保护策略上,以适应不断变化的威胁和法规。
本研究为大规模数据处理领域提供了一个全面的框架和关键技术,为云计算环境下的数据处理提供了有益的参考和解决方案。 未来的研究将进一步推动云计算和大数据处理领域的创新,以满足不断增长的数据需求和安全性要求。
猜你喜欢
心理学报(2022年4期)2022-04-12
水泵技术(2021年3期)2021-08-14
电子制作(2019年14期)2019-08-20
制造技术与机床(2019年4期)2019-04-04
测控技术(2018年7期)2018-12-09
当代贵州(2018年21期)2018-08-29
电子制作(2017年20期)2017-04-26
信息通信技术(2015年6期)2015-12-26
中国惯性技术学报(2015年1期)2015-12-19
华东理工大学学报(自然科学版)(2015年4期)2015-12-01
