
声誉评估的联邦学习激励机制设计与研究
2024-03-28 05:53巫朝霞通信作者
信息记录材料 2024年2期
熊 诚,巫朝霞(通信作者)
(新疆财经大学统计与数据科学学院 新疆 乌鲁木齐 830012)
0 引言
随着科技的不断进步和社会经济的日益繁荣,人类社会不断地产生和利用海量的数据。 数据量呈现出爆炸式的增长,推动了机器学习的飞速发展,并使其在各行各业得到广泛应用,例如医疗的智能诊断[1]和自动驾驶的路线规划[2]等。 然而,在许多应用场景中,数据可能涉及个人或机构的敏感信息。 传统机器学习需要将所有数据集中到一个服务器上进行训练和分析,这样可能会导致数据隐私泄露和数据安全威胁等问题。
为了解决机器学习这一安全问题,谷歌在2017 年提出了一种新的分布式机器学习架构,称为联邦学习(federated learning, FL)[3]。 联邦学习不再使用集中存储的数据来训练模型。 它要求参与者使用自己的数据在本地训练模型,并将不包含原始数据的本地模型发送到模型聚合服务器。 通过服务器上的模型聚合,最终得到全局模型,实现了数据隐私保护和模型共享。
联邦学习面临的一个关键问题是如何鼓励数据所有者参与任务,因为在联邦学习中数据所有者需要贡献数据和承担本地模型训练的开销。 因此,需要一种激励机制来促进数据所有者的参与,同时保证联邦学习模型的高质量。 常见的方法是根据每个参与者的贡献来给予奖励,如斯塔克尔伯格(Stackelberg)博弈[4]和公允价值博弈[5]。此外,联邦学习任务可能会遭到恶意参与者的干扰,例如提供低质量的局部模型或虚报他们的贡献。 为了防止这些问题,需要有合理的模型质量评估机制和任务参与者管理规则。 通常,基于声誉的管理规则和奖励机制可以激励任务参与者诚实合作[6]。 但目前这些激励机制对模型质量、全局模型聚合等问题研究比较少。
本文提出了一种基于声誉评估的联邦学习激励机制,从本地模型评估和全局模型聚合两个方面进行优化。 该机制实施声誉评估,对数据所有者的贡献进行公正评估,并引入损失函数根据贡献度动态调整本地模型优化策略,从而给予更多的奖励。 可以有效地激励数据所有者参与联邦学习,并提供高质量的数据来训练本地模型。 本文的主要贡献包括:
(1)本文提出了一种基于模型质量和贡献评估的声誉机制,用于提高联邦学习的效率和安全性。 该机制利用声誉评估,对数据所有者的贡献进行公正衡量,避免恶意节点的作弊行为。 声誉评估不仅作为奖励分配的依据,激励数据所有者提供高质量的数据和模型,也作为模型聚合的权重,惩罚恶意节点的行为,提高全局模型的鲁棒性和协作性。
(2)采用PolyLoss 作为基础损失函数,根据贡献动态调整本地模型训练优化策略,从而优化联邦学习模型质量。
(3)本文在公共数据集MNIST 和CIFAR-10 上进行了大量的仿真实验,验证了本文激励机制的有效性和鲁棒性。
1 相关工作
近年来,联邦学习因其在数据隐私保护方面的优势而受到了学术界和工业界的广泛关注。 Lim 等[7]在智能医疗应用中使用联邦学习来实现网络边缘的隐私保护协作模型训练。 Fu 等[8]提出了一种基于拉格朗日插值可验证联邦学习的解决方案,以解决工业物联网大数据传统集中学习中的问题。 尽管上述学者针对联邦学习的隐私保护和性能问题提出了优化方案,但是本地设备仍然缺乏参与联邦学习的动力。
在联邦学习网络中,如何激励用户参与任务并贡献高质量的数据是最重要的研究课题之一。 为了解决这个问题,一些研究者设计了不同类型的激励机制,旨在通过奖励或惩罚等方式促进用户积极、可靠地参与联邦学习。Fan 等[9]提出了一种基于数据质量的反向拍卖激励机制,并利用智能合约实现了边缘节点之间的自动和可审计的拍卖过程。 Zeng 等[10]提出了一种轻量级的激励机制,利用多维拍卖的方法,并确保边缘节点纳什均衡,从而有效地选择优质的边缘节点参与联邦学习。 Dong 等[11]引入了博弈论来设计激励节点参与模型训练任务的策略通过采用斯塔克尔伯格博弈论方法制定以市场为导向的架构,以分析所有参与者的最优行为。 Zhan 等[12]通过设定了一个总预算,根据客户端的各自贡献进行奖励来鼓励边缘节点参与模型训练。 Sun 等[13]设计了一种联邦学习激励机制,利用声誉评分来筛选出质量较差的模型,并采用一种基于声誉评分的用户选择策略,以优化最终的聚合模型。
这些文献关注联邦学习的性能、激励和管理问题,但是很少系统地考虑联邦学习任务中的数据质量、模型聚合和奖励分配问题。 本文基于现有研究,结合数据质量、声誉评估和奖励分配,提出了一种能够提升联邦学习模型质量的激励机制。
2 系统设计
2.1 系统架构
本文提出了一种基于声誉评估的联邦学习系统,如图1 所示。 该系统主要由以下4 个部分组成。

图1 基于声誉评估的联邦学习系统
(1)客户端。 每个客户端都是一个独立的实体,拥有自己的私有数据集,不与其他客户端共享。 同时,每个客户端也拥有自己的私有网络,利用私有数据集对网络进行训练和优化,并基于联邦框架参与分布式协作。
(2)服务器。 服务器拥有自己的网络,主要负责聚合各个客户端的梯度信息,更新并分发最新的网络参数,充当中心服务器角色。
(3)基于声誉激励的梯度聚合模块。 服务器在收到各个客户端的梯度后,不是简单地进行平均,而是根据每个客户端的声誉进行筛选和加权。 具体来说,服务器首先根据一定的标准计算每个客户端的声誉值,如果声誉值低于设定的阈值,那么该客户端的梯度将被视为无效,不参与本轮的聚合;反之将声誉值的比例作为权重,参与本轮的聚合。
(4)恶意节点检测模块。 用于识别和排除基于声誉评估的联邦学习系统中的恶意梯度。 恶意梯度是指那些声誉值过低的梯度,它们可能来自被攻击或篡改的节点,或者是故意发送错误信息的节点。
2.2 基于模型质量的声誉评估
本文针对现有的激励机制过于关注数据所有者的参与度,而忽视了模型质量的系统性考量的问题,特别是数据质量和模型性能对全局模型的影响,提出了一种基于声誉评估的联邦学习系统。 该系统的核心是一个声誉评估聚合模块,它可以根据每个客户端在本地训练的模型的性能和上传数据的数量和质量,给每个客户端分配一个声誉分数,反映其对全局模型的贡献程度和可信度。
当联邦学习中心服务器下发全局模型ωt,客户端下载全局模型,并使用本地数据集Dn来训练模型。 训练完成之后上传本地模型在获取所有本地模型之后,声誉评估聚合模块使用所拥有的数据集来测试本地模型。即通过公允价值博弈这种基于损失的边际方法,用于测试局部模型的质量。 它衡量了本地模型对全局模型聚合的影响。 设为声誉评估聚合模块对客户端n的评估结果。
式(1)中,ωt表示通过使用集合P 中所有节点的局部模型聚合的全局模型,而表示在没有节点n的局部模型的情况下聚合的全局模型。G(·)是模型精度测量的函数。
基于这些测试结果,构建了声誉评估机制,主要包括以下几个步骤:
(1)设置全局声誉向量λ。 其维度为本地客户端数目,初始值为1。 在服务器对梯度不断聚合的过程中,声誉向量λ 不断优化。 λ 表示各客户端上传梯度对聚合过程中的贡献度。 贡献度越大的梯度整体参与聚合的份额越大,反之越小。
(2)客户端梯度选择。 参与训练的客户端上传梯度之后,服务器将所有梯度计算出再进行均值计算。 然后,将所有从小到大排序,将排好序的值一分为二。 前半部分的所代表的梯度认为是合理梯度,给予σ1的奖励,后半部分给予σ2的惩罚奖励,得到奖惩向量η。 将这些向量累积到全局声誉向量,更新到最新的值。 更新过程如式(2)所示。
(3)设置声誉阈值h。 其维度为本地客户端数目,初始值数值为σ1。 在服务器对梯度不断聚合的过程中,任何低于此阈值的梯度不参与聚合。 聚合公式如式(3)所示。
式(3)中,n 和k 分别表示客户端编号和贡献参数编号。只有声誉值大于σ1的客户端的梯度才参与聚合。 本文算法参数聚合过程如算法1 所示。

从算法1 可看出,声誉变量λ 在聚合的过程中不断进行更新,达到动态的平衡。 每一次更新之后均会进行归一化处理,使得每一个客户端的聚合份额均分布在0 ~1 之间,便于和聚合阈值进行对比,优化全局模型的聚合方式。
2.3 声誉驱动的本地模型训练
联邦学习的目的是在不共享数据的情况下,通过协同训练,实现一个高质量的全局模型。 为了提高全局模型的性能,每个参与联邦学习的数据拥有者也需要提供高质量的本地模型。 PolyLoss 损失函数[14]是一种创新的损失函数,可以通过调整多项式系数灵活地适应不同任务,提高各种模型在多个任务和数据集上的预测性能。 与传统的损失函数相比,PolyLoss 表现出更优秀的性能。 因此,为了更好地优化本文模型的损失,本文引入了PolyLoss 作为基本损失函数。 文献[14]的研究表明,Poly-1 的简单性和有效性在分类应用中表现更加优秀。 给定客户端Pn,数据集具体定义如式(4)所示。
每个客户端的声誉反映了其本地模型的质量和性能,声誉越高,模型越优秀。 为了提高联邦学习模型的质量,本文根据Focal Loss 设计了基于声誉的全局判别损失函数作为损失函数。 每个节点基于自身声誉动态调整本地模型的训练优化策略,从而优化联邦学习模型的质量。 具体定义如式(5)所示。
结合两个损失函数PolyLoss 与基于声誉的全局判别损失函数,得到本文总损失函数为式(6)所示。
式(6)中,β 为超参数,用于平衡两个损失。
2.4 奖励分配
传统的联邦学习奖励分配的方法通常是根据每个节点的数据量占总数据量的权重来确定。 然而,不诚实的所有者可能会夸大他们的贡献,从而获得更多的奖励。 为了解决这个问题,本文提出了一种基于声誉加权贡献的奖励分配算法。 在奖励分配阶段,根据每个节点的声誉分数和数据量来计算其权重,并用加权平均的方法分配奖励。 这种方法可以有效地提高奖励分配的公平性和激励性,还可以提高联邦学习的效率和安全性。 基于此,数据所有者n的效用函数表示为式(7)。
式(7)中,Mn为客户端n 数据集的数据量,R 是学习任务的预算,Cn表示客户端n 在训练模型时的单位成本。 单位成本通常包括计算花销和通信花销如式(8)所示。
3 实验验证
3.1 实验设置
本文实验设置了12 个客户端、3 个服务器,选择两个公共数据集MNIST 和CIFAR-10 进行实验。 MNIST数据集具有60 000 个训练样本和10 000 个测试样本。CIFAR-10 数据集共有10 类样本,每类都有6 000 个图像,分为5 000 个训练图像和1 000 个测试图像。 为了说明本文算法在非独立同分布(non-independent identically distribution, Non-IID)数据集的情况下的自适应性,分配给各客户端的数据被人为地设置为Non-IID。此外,来自恶意节点的数据会根据其恶意程度篡改数据标签,从而模拟不同质量的数据。 0%、10%、20%的错误率分别对应于相反的数据质量。 例如,如果实验需要准确率为80%的模拟数据,则20%的数据标签被人为设置为错误。
本文使用BiLSTM 和ResNet 模块作为神经网络训练模块,所有客服端以及服务器内置的神经网络均为同构神经网络。 输入样本规模为32 × 28 × 28 × 3,训练轮次为5 000 次,学习率为0.001,截断损失为100,优化函数为Adam Optimizer。 设置奖励因子σ1为0.7,惩罚因子σ2为0.3。 在训练过程中,通过网格搜索法调整式(6)中的超参数β并获得最佳值为1。
3.2 对比方法及实验结果分析
为了评估本文算法性能,本文选择了ResNet,BiLSTM两种算法在数据集MNIST 和CIFAR-10 进行实验。 同时,为了验证本文算法的鲁棒性,对ResNet 和BiLSTM 两种算法进行差分隐私保护。 实验的评估指标是精确率和召回率的调和平均数(F1 值)。 为了公平起见,所有方法都采用与本文实验相同的实验设置。
为了验证本文提出的算法的有效性,在MNIST 和CIFAR-10 数据集上进行了实验,结果如图2 所示。 由图2 可知,本文算法在3 个指标下都优于其他两个算法。 在F1 值为评估指标的条件下,本文算法在CIFAR-10 数据集上的F1 值比算法BiLSTM 提升了1.000%、比算法ResNet 提升了0.695%;在MNIST 数据集上的F1 值比算法 BiLSTM 提升了 1.944%、 比算法 ResNet 提升了0.814%。
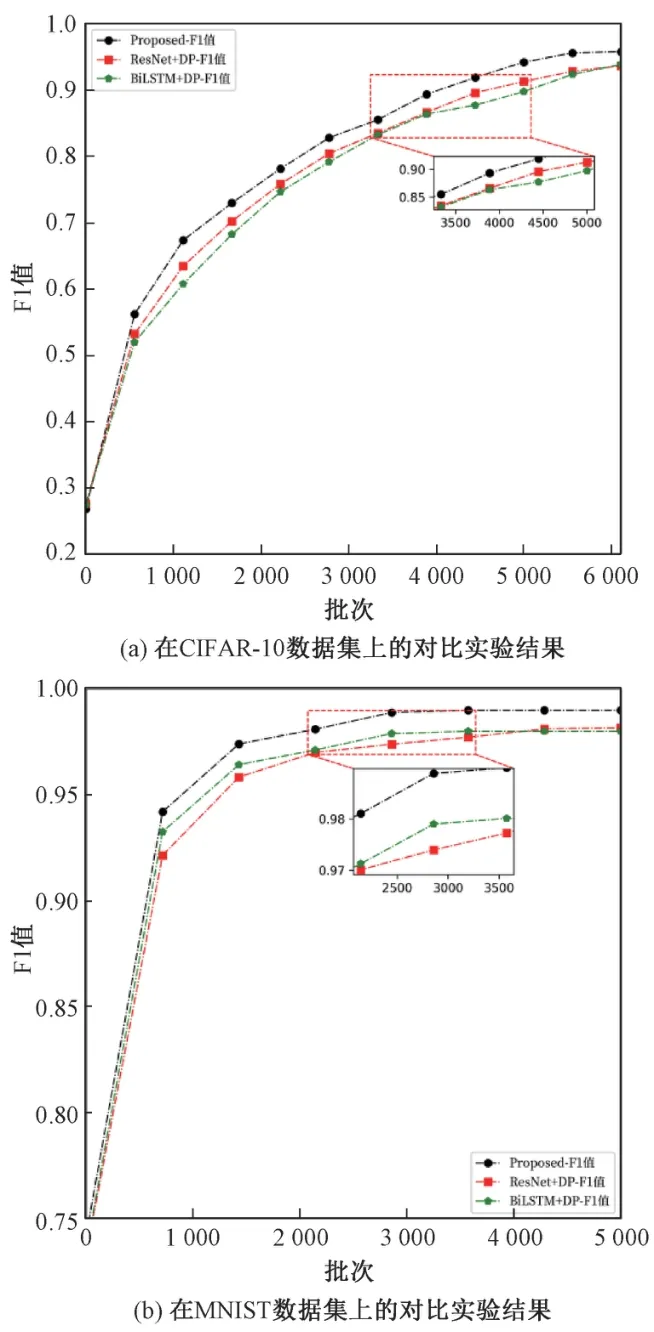
图2 本文算法与其他算法的对比实验图
3.3 鲁棒性验证
在CIFAR-10 和MNIST 两个数据集上进行投毒实验,投毒比例分别是10%和20%。 投毒实验是通过标签随机替换实现的。 本文算法与对比算法仅在F1 值指标上进行了对比实验。 图3 展示了本文算法与另外两种算法在数据集MNIST 和CIFAR-10 上的对比实验结果。
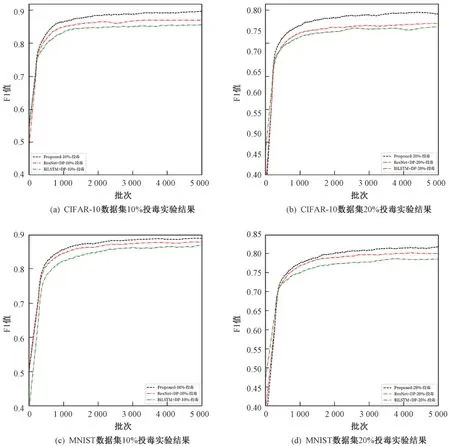
图3 投毒实验对比结果
实验被设置为恶意节点的数量分别为10%和20%。为了使效果最明显,每个恶意节点都提供质量为0%的数据。 比较不同级别的恶意节点占用对任务的影响,从图3中可以清楚地看出,本文提出的算法对恶意节点具有相对的抵抗力。
4 结语
如何鼓励数据所有者参与联邦学习并贡献高质量的数据是联邦学习面临的一个关键性问题。 本文提出了一种基于声誉评估的联邦学习激励机制,从本地模型评估和全局模型聚合两个方面进行优化。 首先,设计了一种基于模型质量和贡献评估的声誉机制,以公正地衡量数据所有者的贡献,避免恶意节点的作弊行为。 同时,声誉评估不仅作为奖励分配的依据,激励数据所有者提供高质量的数据和模型,还作为模型聚合的权重,惩罚恶意节点的行为,提高全局模型的鲁棒性和协作性。 此外,还提出了一种基于PolyLoss 的损失函数,根据声誉评估动态调整本地模型优化策略,从而提高联邦学习模型的质量。 最后,在公共数据集上进行了仿真实验,验证了该激励机制的有效性。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
家庭影院技术(2020年10期)2020-12-14
考试与评价·高二版(2020年3期)2020-09-10
家庭影院技术(2019年7期)2019-08-27
金桥(2018年4期)2018-09-26
智富时代(2018年7期)2018-09-03
智富时代(2018年7期)2018-09-03
中国科技信息(2016年16期)2016-09-10
中国卫生(2014年5期)2014-11-10
