
基于深度学习的云平台负载均衡优化研究
2024-03-28 05:52梁朕齐
信息记录材料 2024年2期
梁朕齐
(海南师范大学 海南 海口 571127)
0 引言
在当今信息技术高速发展的背景下,云计算作为一种灵活、高效的计算模式受到了广泛的关注和应用。 云平台的负载均衡作为云计算中至关重要的一环,对系统性能、资源利用和用户体验具有重要影响。 负载均衡是根据服务器的计算能力和系统资源,在不同的计算节点上动态分配和调度负载任务,以实现负载的合理分配和优化。 然而,云平台的复杂性和动态性给负载均衡带来了一系列挑战。
传统的负载均衡方法往往基于启发式规则或静态的负载分配策略,无法有效应对云平台中负载波动、负载不均衡和动态扩展等问题。 由此产生的低资源利用率、高响应延迟和不稳定的用户体验成为云平台面临的主要瓶颈。因此,需要一种新的、基于深度学习的负载均衡优化方法,以适应云平台不断变化的负载情况并改善整体性能[1-3]。
深度学习作为一种强大的机器学习技术,可以通过对大量数据的学习来构建复杂的模型,从而实现对负载情况的预测和动态调整。 这为负载均衡的优化提供了新的思路和方法。 通过本研究的成果,期望为云平台负载均衡优化提供一种创新的方法,推动深度学习技术在云计算领域的应用和发展。 通过提高系统性能和资源利用率,为云计算用户提供更稳定、高效的计算平台。
1 云平台负载均衡所面临的挑战
云平台负载均衡是一项重要的技术,它能够分配云平台上的网络流量,将请求合理地分发给多台服务器,以确保系统的稳定性和性能优化。 不同时间段和用户行为,云平台的负载可能会出现不同的波动,需要确保在高峰期和低谷期都能够有效地平衡负载。 负载波动、负载不均衡、扩展性是云平台负载常见的挑战。 云平台确保在高峰期和低谷期都能够有效地平衡负载,也需要确保每个服务器资源充分利用。
(1)负载波动:云平台的负载通常是动态波动的,可能会因为用户量的增加、特定时间段的高峰访问等原因而出现负载的激增。 负载均衡器需要能够即时感知到负载的波动,并快速调整负载分配策略,将流量合理地分发到各个服务器上,确保系统的可扩展性和稳定性。
(2)负载不均衡:在云平台中,不同服务器的负载可能会不均衡,可能是硬件性能不同、应用负载分布不均等原因导致。 负载均衡器需要能够根据实际情况,动态地调整负载分配策略,使得负载能够均衡地分配到每个服务器上,以确保服务器的资源得到充分利用,并提高整个系统的性能和稳定性。
(3)扩展性:云平台通常需要能够快速扩展和收缩计算资源,以适应负载的变化。 负载均衡器需要能够无缝地集成新的服务器,并动态地调整负载分配策略,以确保新加入的服务器能够参与到负载均衡中,并保持整个系统的高效性能。 同时,当负载减少时,负载均衡器还需要能够及时地释放不需要的服务器,以节省资源并提高成本效益。
2 传统负载均衡方法
传统负载均衡方法主要基于启发式规则和静态策略来实现负载的均衡分配。 常见的方法包括轮询、最小连接数和加权轮询等[4-6]。 这些方法易于实现和部署,但无法针对云环境的动态负载进行及时调整。 此外,在负载波动和负载不均衡的情况下,传统方法可能导致资源利用率低、响应延迟高以及用户体验不佳。
(1)轮询法:将请求依次分配给不同的服务器,按照一定的顺序轮流处理请求。 这种方法简单高效,但无法根据服务器的实际负载情况进行动态调整。
(2)最小连接数法:根据服务器的当前连接数来决定将请求分配给哪个服务器。 连接数较少的服务器将更容易获得新的请求,从而实现负载均衡。 可以有效地避免某个服务器过载,但对于处理时间长的请求可能存在不公平问题。
(3)加权轮询法:在轮询法的基础上引入权重概念,给不同的服务器分配不同的权重值。 权重值越高的服务器将获得更多的请求分配。 通过合理地设置权重值,可以按照服务器的性能和处理能力进行负载均衡。
3 基于深度学习的负载均衡研究
近年来,基于深度学习的负载均衡方法受到了广泛关注。 深度学习技术可以通过对大量历史负载数据的学习,构建复杂的模型来预测和调整负载分布。 研究者采用不同的深度学习模型,如卷积神经网络、循环神经网络和深度强化学习等,在负载均衡中取得了一定的成果[7-8]。
其中,卷积神经网络(convolutional neural network,CNN)被广泛用于特征提取和负载预测。 研究人员首先通过对历史负载数据进行输入,CNN 可以学习到负载的时空特征,并预测未来负载趋势。 其次,门控循环单元(gate recurrent unit, GRU)能够捕捉负载之间的时序关系,从而更好地进行负载预测和调整。 还可利用卷积神经网络模型对网络流量进行特征提取和预测,实现云服务中的负载均衡。 再次,一些研究探索了深度学习在网络流量分类方面的应用,通过卷积神经网络对网络流量进行精确分类。最后,结合深度强化学习和软件定义网络技术,提出基于深度强化学习的负载均衡算法,实现智能的负载均衡决策。 由于网络环境的动态性,基于深度学习的负载均衡模型可能会出现漂移现象。 模型在训练数据上表现良好,但是在实际部署环境中的性能可能会下降。 因此,负载预测需要一种可长期依赖的模型。
4 实验过程
4.1 数据集介绍
本文所采用数据集为阿里云2018 年发布的集群公开数据集cluster-trace-v2018。 其包含大约4 000 台机器在8天内的资源使用情况。 本文随机采用其中一台机器资源使用情况,2 800 条有效数据记录。 训练集和测试集比例为7 ∶3。
在特征选择方面,随机森林通过评估每个特征的重要性来确定其对目标变量的贡献程度。 它通过计算在决策树多次划分中特征带来的平均不纯度的减少来衡量特征的重要性。 较高的重要性分数意味着相应的特征在分类中的贡献较大,考虑保留。 本文通过随机森林特征选择,筛选出重要的数据。
4.2 基于GRU 的云平台负载均衡预测模型设计
GRU 是一种循环神经网络(recurrent neural network,RNN)的变体,它被广泛应用于自然语言处理等任务中,如图1 所示。 相较于传统的RNN 结构,GRU 在信息传递和记忆方面具有更强的能力,并且能够更好地解决长期依赖问题[9]。
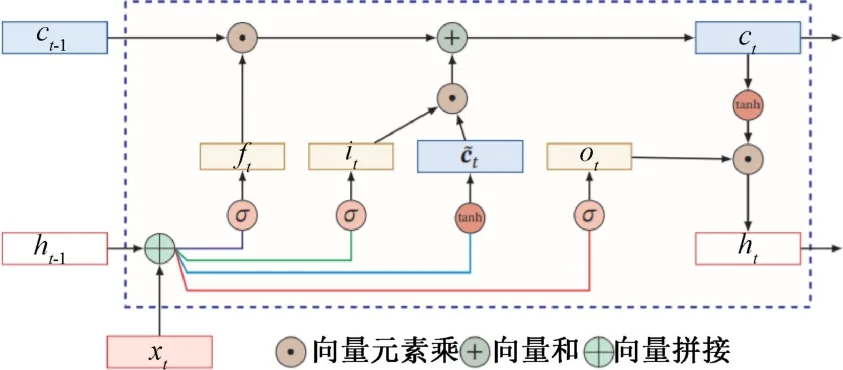
图1 GRU 网络结构图
GRU 的核心思想是引入了两个门控单元,即重置门(reset gate)和更新门(update gate),用于控制信息的流动和记忆的更新。 首先,重置门通过考虑上一个时间步的输入和当前时间步的输入,来决定哪些信息应该被遗忘。 然后,更新门通过综合考虑上一个时间步的输入和当前时间步的输入,来控制从过去的记忆中保留多少信息,以及从当前输入中添加多少新信息[10]。
相比于传统的RNN 结构,GRU 具有更强的表达能力和更好的计算效率。 由于引入了门控机制,GRU 能够选择性地忽略一些不相关的信息,并且能够更好地处理梯度消失和梯度爆炸的问题。 此外,GRU 的记忆更新方式相对于长短期记忆(long short-term memory,LSTM)更加简洁,参数更少,使得训练过程更加高效。
4.3 实验评价与分析
如图2 所示,64 个样本,在模型预测任务中能够产生与原始序列趋势基本一致的预测结果。 这意味着,当使用GRU 模型对时间序列数据进行预测时,模型的输出会尽可能地保持与原始序列的趋势相似。 通过GRU模型的训练和学习过程,模型会自动学习到序列数据的内在规律和模式。 GRU 模型通过对序列中的历史数据进行分析和学习,能够捕捉到其中的趋势和周期性变化,并用以预测未来的发展趋势,即预测值与实际观测值在形状和趋势上相似,表明该模型具有一定的预测能力和准确性。
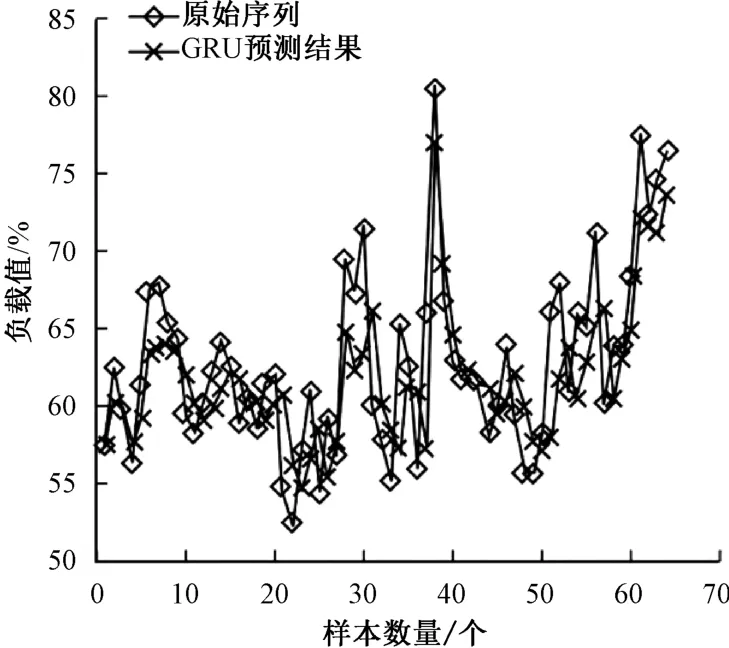
图2 GRU 模型预测结果
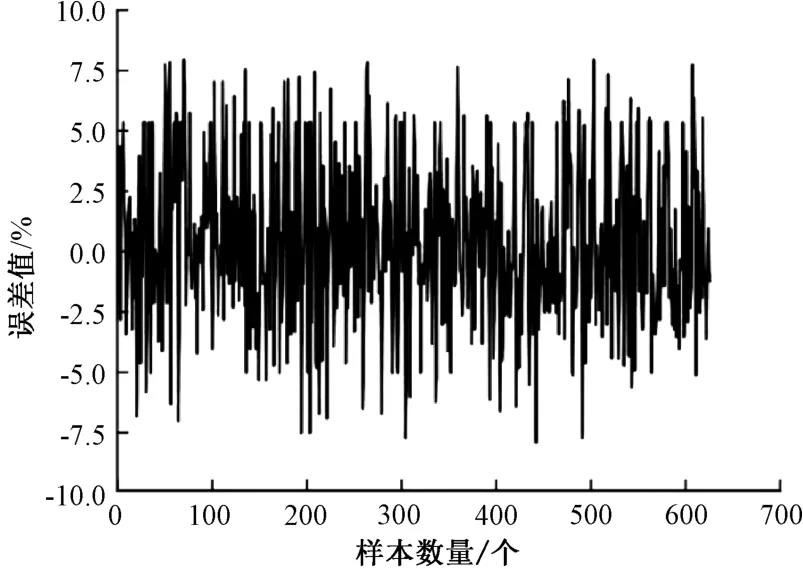
图3 模型预测误差结果
经过训练后,本文利用的GRU 模型得到的预测数据与真实数据之间的误差大多集中在-5.0 到5.0 之间,表明该模型的预测精度较高。 这意味着在大多数情况下,该模型能够准确地预测目标变量,并且预测结果与实际观测值非常接近。 误差集中在较小的范围内,说明模型在预测过程中具有较低的偏差和较小的离散度。 这表示模型在学习过程中已经成功地捕捉到了数据的规律和趋势,并能够通过合理的预测使得预测值与实际观测值之间的差异最小化。
4.4 评价指标
为了评估模型的准确率,本文采用了多个模型评价指标来评估负载均衡模型的性能,包括平均绝对误差(mean absolute error,MAE)、平均绝对百分比误差(mean absolute percentage error,MAPE)、均方误差(mean square error,MSE)、均方根误差(root-mean-square error,RMSE)以及决定系数(R2)。 这些指标可从不同角度度量模型的预测准确度、误差大小和拟合程度,其中n表示负载预测值个数,yi表示真实负载值表示预测负载值表示负载平均值。 由公式(1)~公式(5)来表达:
4.5 模型对比
将本文模型与差分自回归移动平均模型(autoregressive integrated moving average,ARIMA)、深度学习LSTM 模型和Refined-LSTM 模型进行对比。 从表1 可以看出本文提出的GRU 模型预测精度较高、训练速度快、预测时间短。

表1 模型对比
5 结语
基于深度学习的云平台负载均衡优化研究说明,可以对云平台负载进行动态且智能的分配和管理,合理优化负载均衡以降低运行成本,实现系统的可伸缩性,确保在高负载情况下平台仍能保持高效运行,同时确保资源在不同用户之间公平分配,减少任务响应时间,提高用户体验和满意度。 深度学习算法可以基于历史和实时数据进行学习和分析,进而通过不断地学习和调整,实现对未来负载需求的预测,能够实时地优化资源分配,适应不同的工作负载和系统需求。 未来,研究人员可以从强化对流量模式和行为的学习方面进行研究,深入挖掘流量数据的隐含模式和行为规律,提高负载均衡算法对不同应用场景的适应性和学习能力。
猜你喜欢
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
铁道通信信号(2020年9期)2020-02-06
铁道通信信号(2019年9期)2019-11-25
数学大王·趣味逻辑(2019年5期)2019-06-13
小学科学(学生版)(2019年5期)2019-05-21
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
经济技术协作信息(2018年30期)2018-11-22
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
网络安全和信息化(2017年10期)2017-03-08
