
基于篇章图模型的中文事件时序关系识别
2024-03-26 02:39李培峰
中文信息学报 2024年1期
李 婧,徐 昇,李培峰
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
事件时序关系描述了不同事件发生的先后顺序[1](如前(BEFORE),后(AFTER)等)。在该任务中,事件通常指一个单独的词语,例如,在句子S1中,事件“示威”发生在“受伤”之前,因此,“示威”和“受伤”的时序关系为“BEFORE”。事件时序关系识别是自然语言处理中的一个重要课题,获得了越来越多的研究者的重视,该任务对于特定领域的相关工作有很大帮助。例如,在自动摘要[2]中,可以通过理清事件发展的顺序而梳理文本脉络,有效进行摘要的推理与生成;在自动问答[3]中,可以为一些涉及到时间关系的问题提供线索,为其匹配更加合理的答案。
S1: 在警方驱散示威人群的过程中,至少有5个人受伤。
近年来,比较流行的事件时序关系语料库有TimeBank[4]和TimeBank-Dense[5]等,然而这些语料库都只聚焦于句子级事件时序关系,即两个事件出现在同句或者邻句中。句子级事件时序关系不适合应用于篇章级别的自然语言处理任务中,如文本时间轴构建和故事时间线构造等。此外,受限于语料库,目前绝大多数事件时序关系识别研究聚焦于英文,中文事件时序关系识别研究进展较慢。相对于英文而言,中文表达方式更多变,句间连接词更少,给该任务带来了更大挑战[6]。
为了进一步挖掘整篇文章中各事件间的时序关系,本文将研究篇章级中文事件时序关系识别,研究对象包括同句、邻句和跨句的中文事件时序关系。相较于句子级中文事件时序方法,篇章级方法可更多地考虑到相距较远的两个事件间的时序关系,这对于一些篇章级别的下游任务有很大的现实应用价值。如图1所示,本文在该篇章中标出了6个事件实例(用事件触发词表示),为了简化此图,只列出了其中5个时序关系(实际上任意两个事件实例间都存在某种时序关系),包括同句、邻句和跨句关系。该篇章围绕一个主题展开,包含多个事件实例。为了梳理清楚事件的发展脉络,将所有事件实例进行时序关系识别很有必要。如果仅仅在句子级研究时序关系,那么一整条时间轴将会被割裂,从而无法很好地梳理篇章脉络及大意,无法为下游任务服务。
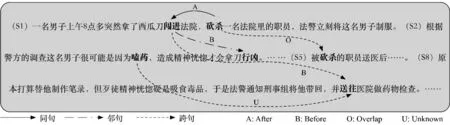
图1 篇章级别事件时序关系识别示例图
相较句子级事件时序关系识别,篇章级任务更加困难。由于跨句的两个事件在物理上孤立,事件之间缺乏必要的句法级别的交互信息(如连接词、共用的事件论元等)。因此,模型很难学习到两者之间的联系,从而难以识别两者的时序关系。Reimers等人[7]和Naik等人[8]指出,在现有的语料库中,篇章级事件时序关系标注的流行程度较低,这使得以前仅考虑事件对局部特征的模型不适用于篇章级事件时序关系识别,例如,最短依存路径(Shortest Dependence Path,SDP)[9]。此外,传递性是事件时序关系的特有属性,篇章级事件时序关系识别任务更需要利用不同事件实例间的时序关系传递性特性,以达到利用中间事件实例作为桥梁来连接相隔较远事件实例的效果。
针对以上挑战,本文提出一种基于篇章图模型的中文事件时序关系识别模型,主要贡献如下: (1)本文提出一种事件时序关系识别方法,有效地通过两种图模型提升篇章时序关系识别性能; (2)本文通过篇章图模型将一个篇章中的所有事件相互连接交互信息以加强跨句的时序关系识别性能; (3)在篇章级中文事件时序关系语料上的实验表明,本文方法的性能优于现有最好的方法。
1 相关工作
目前几乎所有事件时序关系语料库都集中在英文上,例如,TimeBank[4],TimeBank-Dense[5]和MATRES[10],这些语料库都只标注了句子级时序关系,却忽视了篇章级时序关系。在TimeBank-Dense的基础上,Naik[9]等人第一次构建了一个篇章级别的英文事件时序关系语料TDD。中文事件时序关系语料库相较于英文更加少,Li等人[6]创建的由700多条句子组成的时序语料库和TempEval[1]中的一个小型事件时序关系数据集都规模太小。大部分中文事件时序关系识别的研究都在ACE2005-extended时序关系语料库[11]上展开,该语料库将一篇文章中预先定义类型的事件两两之间全部标注上时序关系,包括同句、邻句和跨句,由此形成了全连接的篇章级中文事件时序关系语料库。
绝大部分的事件时序关系识别研究是句子级且针对英文。在英文上,传统的统计学习方法[12-14]专注于提取文本中的各种特征,如实体特征,词性特征和形态学特征等,并在此基础上使用分类器进行分类,如支持向量机,决策树和最大熵分类器等。
随着机器学习的发展,近期的工作多数使用神经网络来进行事件时序关系识别。受Xu等人[15]的启发,Cheng和Miyao[16]使用最短依存路径作为双向长短期记忆网络的输入来识别同句和邻句的事件时序关系,在不使用任何手工特征的情况下,取得了和当时最好的模型相当的性能。Zhang等人[17]构建了一个句法导向图模型来获取事件间深层次的联系。为了获取更加丰富的特征表示,联合学习[18]和多任务学习[19]的方法也被应用于该任务中。为了克服输入端信息过少的限制,外部知识库被用来增加更多的信息以达到更好的分类性能[20]。相较于句子级别的事件时序关系识别,较少的工作集中在篇章级别任务上。
篇章级事件时序关系识别相关研究较少。Naik等人[8]在篇章级语料库TDD上复现了一些常规的方法(如MAJORITY、Bi-LSTM)。Liu等人[21]将每篇文章看作一个无导向的图,结点代表事件,边代表事件间时序关系,通过遮掩边的方法来训练模型让其学习事件间的时序依赖关系。
只有很少的研究集中在中文上。与英文上的研究类似,早期的工作都是使用统计学习的方法,如概率决策树(Probabilistic Decision Tree)[22]和朴素贝叶斯模型(Naive Bayesian Classifier)[23]等被用来分析句子间的时序关系。Li等人[11]第一次使用词汇特征、句法特征和全局优化的方法(如事件相关性和连接约束)进行篇章级别的中文事件时序关系识别。
综上所述,无论在英文上还是中文上,大多数方法只是针对句子级别的事件时序关系识别。本文提出了一种篇章级事件时序关系识别方法,通过事件句间的相邻关系来构建篇章级别的图模型,让相隔较远的事件词之间可以进行信息交互,以达到让事件间的关系可以互相传递的目的。
2 基于篇章图模型的中文事件时序关系识别方法
本文构建两种图卷积神经网络(Graph Convolutional Network,GCN)[24],分别编码事件句的句法信息和交互篇章中所有的事件信息,再结合事件句的语义信息,对一个篇章中所有的事件对进行时序关系识别,模型图的总体架构如图2所示,共包含四个模块: 1)语义信息编码模块: 将事件词所在的事件句进行拼接,同时添加事件词相关的属性信息,获取完整的语义信息; 2)句法信息编码模块: 根据以事件词为起点的最短依存路径构建句内图模型,获取与事件词高度相关的句法信息; 3)事件信息交互模块: 根据事件词所在事件句的相邻关系构建篇章图模型,让事件词之间可以更好地交互信息; 4)时序关系分类模块: 将上述特征进行融合,使用Softmax对其进行时序关系的分类预测。下面针对模型的相关模块进行详细说明。
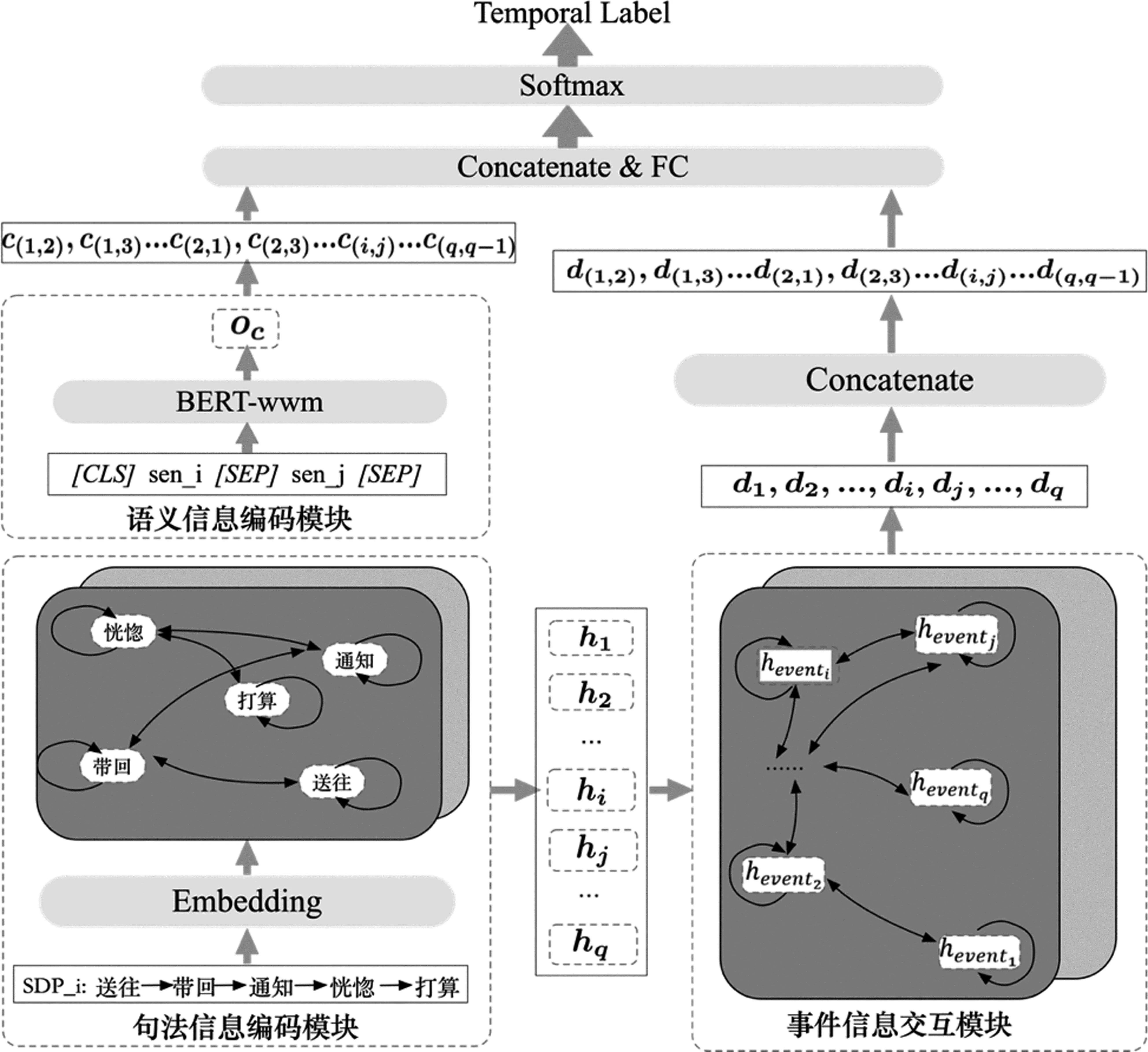
图2 模型架构图
2.1 语义信息编码模块
为了更好地获取事件句完整的语义信息,在输入端,本文将两个事件句进行拼接,用[E1]和[E2]分别表示两个事件词的开始,[E1/]和[E2/]分别表示两个事件词的结束。介于BERT[25]在处理序列相关任务上较优的性能,本文选用BERT在中文上的变体BERT-wwm[24]作为事件句的编码器,并在事件词后面添加与之密切相关的五种属性(时态(Tense),类型(Type),极性(Polarity),泛型(Genericity),形态(Modality))以进一步扩充事件词的特征[26]。五种事件属性信息插入事件词的后面,事件词开始标签[E1][E2]和结束标签[E1/][E2/]分别插入两个事件词开始之前与属性信息结束之后。输入端构造如式(1)所示。
(1)
其中,[CLS]表示句子的开始,两个[SEP]用来分隔两个句子和表示句子的结束。{w1,…,wm}和{t1,…,tn}分别表示两个事件句。m和n为两个事件句的长度。{wi,…,wj}(i≥1,j≤m)和{tk,…,tl}(k≥1l≤n)分别表示两个事件词,长度分别为j-i+1,k+1。两个事件词的五种属性分别表示为attributes_1={e1,e2,…,e5}和attributes_2={f1,f2,…,f5}。取BERT-wwm输出端的[CLS]的表示ci作为两个事件句融合后的语义表示,记q为一个篇章中所有事件的个数,将篇章中所有事件对语义向量两两融合后表示为oc={c(1,2),c(1,3)…c(2,1),c(2,3)…c(i,j)…c(q,q-q)}(i≠j),(q*(q-1))/2为篇章中所有的时序关系数。
2.2 句法信息编码模块
句法信息在很大程度上可以帮助模型理清一句话的结构,从而排除一些无用的冗余信息。本文使用最短依存路径作为与事件词相关的句法结构信息,以获取与事件词高度相关的句法信息。最短依存路径是句法树中两个特定词之间连接到某个相同结点的最短路径,Cheng等人[16]首次将该方法应用于事件时序关系识别任务且提出一种公共根的假说。本文中使用的最短依存路径是从事件词为起点,以每个事件句的根结点为终点,构造一条从事件词到根节点的最短依存路径。
图卷积神经网络[27]通过邻居结点之间的传播和聚合来学习更加丰富的特征,被广泛用于学习图结构的高级特征,并取得了显著的效果。因此,本文使用GCN作为句法信息的编码器,以最短依存路径上的词语为结点,词语间是否有依存关系为边(有关系则为1,否则为0),边为双向且加入自环,构造一种句子级别的图模型。结构如图2的句法信息编码模块所示,其输入端的SDP为图1中句子S8的最短依存路径。
在图模型的输入端,本文使用Li[28]等人提出的一种中文词向量,将最短依存路径上的词语通过该词向量映射为实值向量集合iadp={i1,i2,…,is},其中s为最短依存路径的序列长度,该向量集合作为图模型的结点特征,图模型的传播如式(2)所示。
(2)
2.3 事件信息交互模块
篇章级别的事件时序关系大多数关系都为跨句关系。由于跨句的事件实例相隔较远距离,语义不连续,句子结构无法通过Cheng等人[16]提出的虚拟根相连。因此,此前专注于研究同句和邻句的时序识别方法并不适用于跨句。提升篇章级别事件时序关系识别的性能,必须要提升跨句事件时序关系的识别准确度。鉴于时序关系特有的传递性,本文将一个篇章中所有的事件构建成篇章级图卷积模型,通过节点之间的特征传递聚合,以补充两个相隔较远的事件词之间的额外信息,以此来提升跨句事件时序关系分类的性能。
在构建篇章级别图模型时,以一个篇章中所有的事件词作为结点,以两个事件词所在的事件句是否相邻作为边,若相邻则为1,否则为0,且为双向的关系,对每个事件句都加入自环,如图2中的事件信息交互模块所示。这样可以通过相邻句的不断传播扩散特征,来丰富跨句事件词的特征,以达到将跨句事件相连的目的。
图模型的传播公式与2.2节相同。该篇章级别图模型与2.2节的句内图模型不共享参数,图模型的层数设置为2,在输入端,事件词的特征为2.2节中的h,σ为ReLu函数。事件特征集合中的每个事件词在句内图模型中都聚合了其所在的最短依存路径的句法特征,因此在篇章级图模型中每个事件将携带丰富的句法特征,通过将句法特征进行传播融合以连接本来无法相连的跨句事件词。在图模型的输出端,获取一个篇章中所有事件词的表示d={d1,d2,…,di,dj,…,dq},将两两事件表示进行拼接,得到od={d(1,2),d(1,3),…,d(2,1),d(2,3),…d(i,j)…,d(q,q-1)}(i≠j),其中,d(i,j)=di⊕dj,⊕表示拼接,每个篇章中的时序关系数为(q*(q-1))/2。每个拼接的事件对除了包含了自身事件句的句法特征,还融合了篇章中其他事件句的句法特征,以帮助模型进行时序关系识别。
2.4 时序关系预测模块
该模块将上述模块所获得的所有事件对(T个)的语义信息Oc以及融合后的句法信息Od进行全连接融合,使用激活函数ReLu进行非线性融合,再使用Softmax进行时序关系分类预测后得到结果O。计算公式如式(3)所示,其中,Oc为T*m的语义矩阵,Od为T*n的句法矩阵,m和n分别为语义模块和句法模块的维度数。W和b分别为全连接层的权重矩阵和偏置。本文采用学习率为3e-5的Adam优化器来最小化交叉熵损失(Cross-Entropy)并且通过反向传播来更新参数。
O=Softmax(ReLu(W* (oc⊕od)+b))
(3)
3 实验
本节首先介绍数据集和实验相关参数的设置;接着对比本文的模型和其他模型运行效果;最后进行消融实验分析。
3.1 实验设置
本文采用Li等人[11]标注的基于ACE2005-extended中文事件时序关系语料库,该语料库标注了每两个事件词之间的时序关系并形成了一个全连接图,该语料库标注了四种时序关系: 前(BEFORE)、后(AFTER)、重叠(OVERLAP)和未知(UNKNOWN),样本统计如表1所示。可以看出,跨句的事件对占比高达71.8%,这足以说明跨句的事件时序关系识别对于篇章级别的事件时序关系识别非常重要。
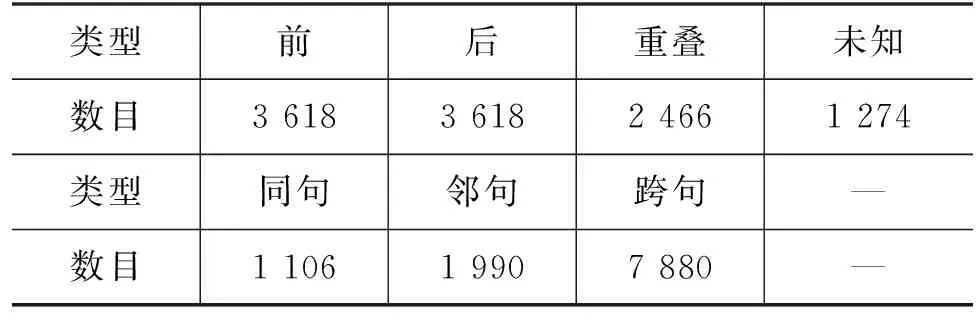
表1 ACE2005-extended样本统计
本文采用和Li[11]等人一致的数据划分和评测标准。采用五折交叉验证(具体划分与Li一致)并且使用相同的评估指标Accuracy,该指标在该任务中与Micro-F1相同,因为每两个事件间的时序关系必然属于上述四种时序关系之一。
本文使用Pytorch作为深度学习的框架,在每一折中本文训练15个epochs,batch的大小为2,并加入Early Stopping和Dropout防止过拟合,分别设置为5和0.5。外部词向量的维度为300,BERT-wwm的输出维度为768。
3.2 实验结果
为了验证本文提出模型的性能,本文将与其他6个基准系统比较,具体如下:
(1)MAJORITY: 给所有事件对的事件时序关系分配一个占比最多的时序标签;
(2)GIM[11]: 使用传统机器学习进行时序关系推理的方法,输入端使用多种特征,结合自反性和传递性进行全局优化;
(3)DGIM[11]: 在GIM基础上融入了事件相关性约束、连接约束、事件同指约束等全局优化方法,是目前在ACE2005-extended上中文事件时序关系分类任务效果最优的方法;
(4)SDP[16]: 在TimeBank-Dense语料库中首次使用SDP,将SDP上的词语、词性、依存关系拼接作为双向长短期记忆网络(Bi-directional Long Short-Term Memory,Bi-LSTM)的输入,本文将其模型复现后在中文语料库上进行实验;
(5)GCN[29]: 在TimeBank-Dense语料库中利用图卷积神经网络获取最短依存路径上不相邻的词语的依存关系。本文将其复现后在中文语料库上进行实验;
(6)TRIMI[26]: 利用BERT-wwm和Bi-LSTM分别编码语义信息和联合SDP上的句法信息,在ACE2005-extended上进行实验。
表2给出了基准模型和本文所提出模型的整体和三个子类别(同句、邻句和跨句)的Micro-F1。可以看出,本文所提出的模型在整体Micro-F1获得了最优性能71.87%,且本文所针对的跨句时序关系识别性能比目前最优的模型TRIMI提升了1.68。此外,通过相邻事件句的信息交互可以将两个事件句的语义信息和句法信息相连接,邻句的识别性能提升0.82。然而,同句的识别性能相较于TRIMI下降了0.4,这可能是由于同句的事件之间本身具有较强的语义信息和句法连结,篇章图模型的传播聚合为其引入了一些冗余信息,使得模型混淆进而无法正确判断其时序关系。表2中的实验结果充分证明了本文方法在篇章级别事件时序关系识别任务中的有效性。
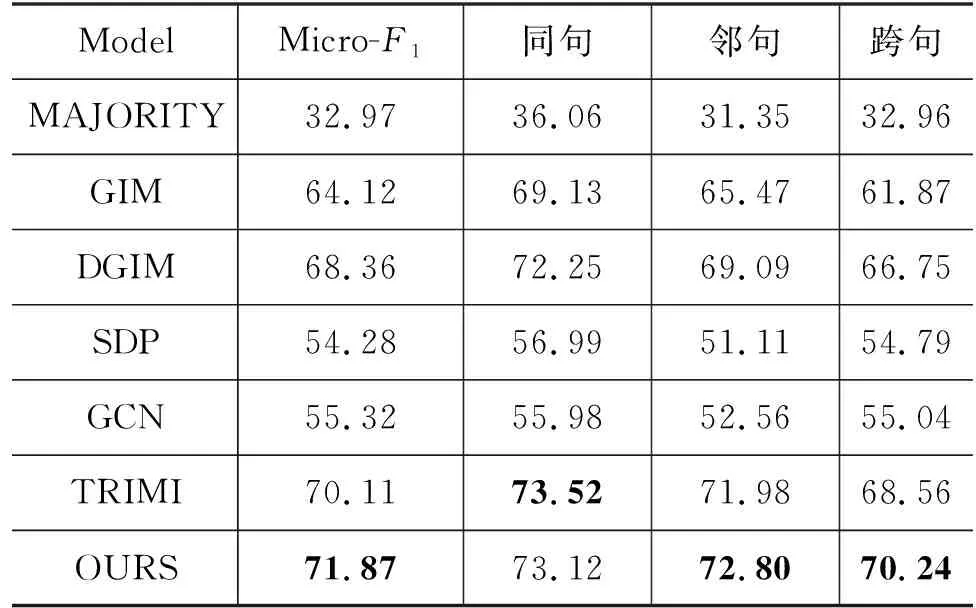
表2 不同模型在ACE2005-extended事件时序关系语料库上的结果(显著性测试: p<0.05)(结果省略%)
从表2可以看出,在未依赖大量手工标注特征的情况下,本文所提出的方法与传统的统计学习的方法GIM和DGIM相比,在总体Micro-F1获得了更优的性能(+7.75/+3.51)。虽然DGIM针对该任务融合了多种约束进行全局优化,然而在三个子类别尤其在跨句上,本文所提出的方法相较于DGIM提升了3.49。由此可见,篇章级图模型的构造对跨句的事件时序关系识别有很大的帮助。
神经网络方法SDP和GCN主要是针对同句事件时序关系识别,因此应用于篇章级事件时序关系语料库ACE2005-extended时,并未取得很高的性能。此外,由于ACE2005-extended语料库中同句占比很小(11.1%),这两种方法在同句事件时序关系识别上也并未取得很好的性能。而本文所提出的方法在整体和三个子类别的性能上都相较于SDP和GCN有了很大的提升,这说明本文根据最短依存路径构造的句内图模型和篇章级别的图模型可以很大程度上提升篇章级别的事件时序关系识别性能。相较于目前最优的模型TRIMI,除了同句该子类别外,本文提出的方法都获得了一定的提升,即使TRIMI中也使用了Bi-LSTM编码句法结构信息,但本文采用图模型来编码句法信息,并接着将篇章中的所有事件信息进行交互,使得跨句事件可能获得更多的信息,足以说明本文提出方法的有效性。
3.3 实验分析
为了验证本文所提出不同信息对整体、同句、邻句和跨句的影响,本文设计了以下消融实验: (1)-句内GCN: 删除句内图模型。即直接使用外部词向量Embedding后的事件词表示作为篇章级图模型的输入; (2)-篇章GCN: 删除篇章级图模型。即在图2中删除事件信息交互模块;(3)句内GCN替换为Bi-LSTM: 将句内图模型替换成Bi-LSTM。即在句法信息编码模块中,将最短依存路径作为Bi-LSTM的输入,将最后一个时间步的双向向量表示拼接后作为篇章级图模型的输入。结果如表3所示。若去除本文模型中的句内GCN(-句内GCN),而直接使用编码后的事件词作为篇章级图模型的结点,性能在整体下降了0.94,且在三个子类别上皆有所下降(-0.56/-1.07/-0.62)。这是由于句法信息对提升事件时序关系识别的性能有所帮助,GCN可以很好地聚合不相邻词语间的特征。以这样的事件词表示来构建篇章级GCN的节点,可以为其他事件提供更多有关本事件的信息,以弥补输入端信息过少的缺陷。
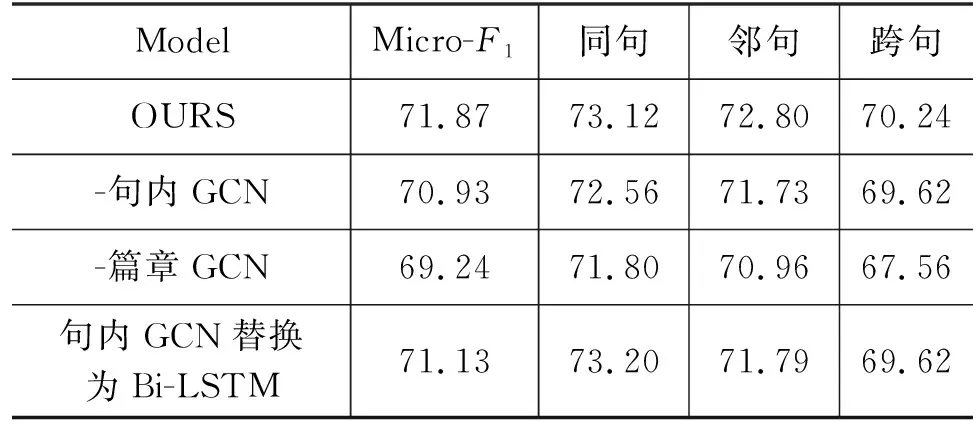
表3 消融实验结果(结果省略%)
删除篇章级图模型(-篇章GCN),整体和跨句的性能下降较多(-2.63/-2.68),因为篇章级别的事件时序关系中绝大部分还是跨句,而针对于跨句的事件时序关系识别。本文使用篇章级GCN将不同事件之间的特征进行传播聚合,若去除了该部分,则跨句的性能会大幅下降。跨句的事件都独立存在,不连续的语义和句法信息都容易导致模型将其错误分类。如图1所示,其中S1中的“砍杀”和“送往”的时序关系是“AFTER”,然而仅靠两个事件句无法将两个事件词进行相连。由于输入到篇章图模型的事件词表示都融合了最短依存路径信息,因此通过中间句子的事件词“嗑药”、“行凶”等,可以将S1中的砍杀的主人公“一名男子”与S8中的“精神恍惚的歹徒”进行连接,进一步判断“砍杀”和“送往”的时序关系为“AFTER”。对比实验结果证明本文提出的图模型GCN能更好地提升跨句的事件时序关系识别性能。
此前Bi-LSTM通常被应用于编码最短依存路径,而相较于Bi-LSTM,GCN作为最短依存路径的编码器性能更优(+0.74),这是因为Bi-LSTM是按照时间步来处理词语,即使有正和反两个方向,SDP上离得较远的词语在传播的过程中依然会丢失一些特征,无法获取长期依赖,而GCN是通过邻居结点来不断地传播聚合,相较于Bi-LSTM可以更好地保留特征。
4 结论
本文提出了一种基于篇章图模型的中文事件时序关系识别方法。该方法利用句内图模型编码最短依存路径,构造篇章级别事件图来交互信息,再加以进一步融合两个事件句的语义信息,以更好地进行篇章级别事件时序关系的识别。在ACE2005-extended上的实验表明,本模型在跨句和整体性能上都取得了最佳性能。
猜你喜欢
中国农业信息(2023年3期)2023-03-18
中华诗词(2021年3期)2021-12-31
中国农业信息(2021年3期)2021-11-22
大连民族大学学报(2021年2期)2021-07-16
天津外国语大学学报(2020年1期)2020-03-25
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
电子制作(2016年15期)2017-01-15
语言与翻译(2015年4期)2015-07-18
河南科技(2014年15期)2014-02-27
