
融合目标词上下文序列与结构信息的框架识别方法
2024-03-26 02:39闫智超苏雪峰李欣杰柴清华韩孝奇赵云肖
中文信息学报 2024年1期
闫智超,李 茹,2,苏雪峰,4,李欣杰,柴清华,韩孝奇,赵云肖
(1.山西大学 计算机与信息技术学院,山西 太原 030006;2.山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006;3.山西大学 外国语学院,山西 太原 030006;4.山西工程科技职业大学 现代物流学院,山西 晋中 030609;5.中译语通科技股份有限公司,北京 100043)
0 引言
框架语义网[1](FrameNet,FN)是以美国著名语言学家Fillmore提出的格语法理论[2]及框架语义学[3]为基础构建的一个框架语义知识库,其中每个框架均代表特定语义场景,每个场景对应相关语义角色(框架元素)。表1展示了框架Creating(创造)和Manufacturing(制造)的定义和核心框架元素。除英文FrameNet外,日本、德国、巴西等国科研工作者相继创建了面向本国语言的FrameNet。山西大学于2006年开始创建汉语框架语义知识库(Chinese FrameNet,CFN)[4]。基于框架语义的框架语义角色标注(Frame Semantic Role Labeling,FSRL)能细粒度地表示特定词(目标词(1)在给定的上下文中能够激活框架的词或者短语统称为目标词。)在句子中所能激活的语义场景(框架(2)框架语义学把词义、句子意义和文本意义统一用框架进行描述,框架是和一些激活性语境相一致的一个结构化的范畴系统。)以及该场景对应的语义角色。因此,FSRL被广泛地应用于机器阅读理解[5]、文章摘要抽取[6]和关系抽取[7]等多种自然语言处理任务。如图1(a)所示,目标词“produce”激活了“Creating”框架,“genes that”和“toxins against insect pets”分别是框架“Creating”的语义角色“Cause”和“Entity”。

图1 目标词produce所激活的框架及框架语义角色、依存句法信息和PropBank角色信息
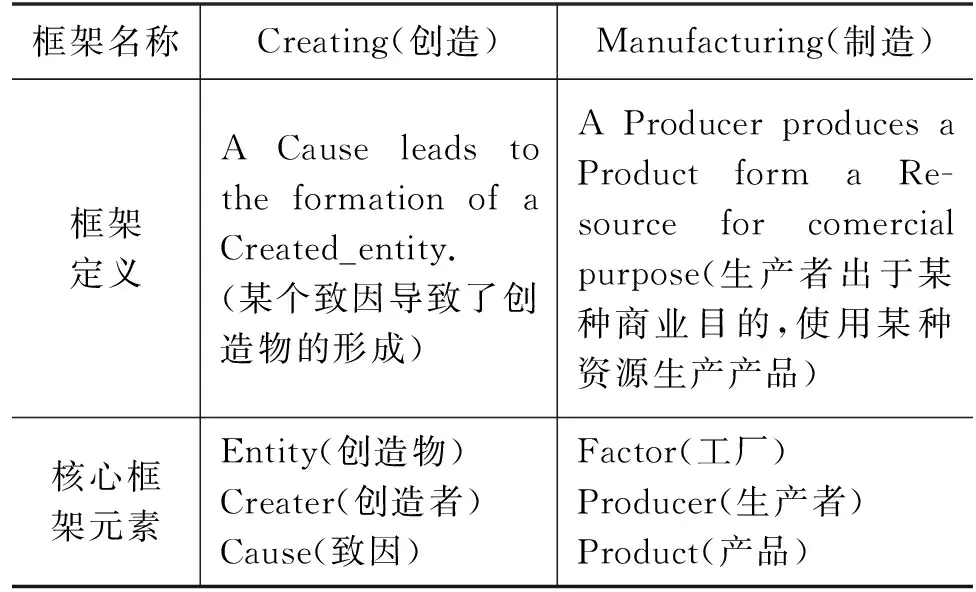
表1 Creating和Manufacturing框架及核心框架元素
框架识别(Frame Identification,FI)是进行FSRL的前提,其目标是为句子中给定的目标词寻找一个可以激活的框架,其形式化表示如式(1)所示。
(1)
其中,wt是目标词,fi是框架库中的第i个框架,C是目标词的上下文集合,F是框架集合。不同于PropBank式的语义角色,FSRL中的语义角色是框架特定的,每一个框架都有其相应的语义角色,所以在进行FSRL之前首先要识别目标词所激活的框架。通过FI可以将FSRL任务中原本需要在上千个标签中进行分类的场景转换到一个更小的语义角色集合中,压缩搜索空间,提升标签识别的精度。
FI是一个具有挑战性的工作,在基于特征工程的方法中,在手动选择文本特征后通过机器学习模型获取目标词的上下文表示,特征选择好坏是制约该方法的主要因素。随着技术的发展,深度模型根据目标词的上下文自动学习目标词的上下文特征,这样虽能克服人工特征选择所存在的些许问题但仍具有以下两个方面的不足: a)采用序列建模的方式对目标词及其上下文进行建模,忽略了目标词及其上下文之间的结构信息,如目标词与其周围词之间的依存结构,动词目标词与其语义角色成分之间的结构关系; b)采用统一的模型对目标词进行表示(在框架语义中,目标词的词性可以是动词、名词、形容词等),忽略了不同词性目标词在句法和语义结构上的差异。
针对问题a),本文提出了同时融合目标词上下文序列信息和结构信息(如句子级的PropBank语义角色标注和依存分析信息)的深度神经网络模型,克服现有方法在结构信息建模方面的不足。例如,图1(b)描述了动词“produce”的PropBank语义角色信息;例句c中描述了动词“produce”的依存句法信息。利用这些结构信息有助于模型判别句子中目标词“produce”所激发的框架。针对问题b),考虑目标词的词性,将不同词性的依存特征分别建模,在此基础上构建集成学习模型。本文的贡献主要包括:
(1) 提出一种融合依存句法和语义角色结构信息的框架识别方法,该方法可同时捕捉序列与结构的目标词上下文信息。
(2) 鉴于不同词性的目标词具有不同的语义结构特征,本文细粒度地分析了不同词性目标词的结构信息对框架识别的影响。在此基础上,构建了一种集成的框架识别学习模型。
(3) 本文设计了详细的对比实验,在中文数据集CFN和英文数据集FN1.7上取得了目前最好的框架识别性能。实验证明本文提出的融合目标词上下文序列与结构信息的框架识别方法的有效性,以及基于细粒度结构信息的集成学习方法的有效性。
1 相关工作
2007年SemEval中Baker等[8]提出了针对FI的评测任务。早期研究人员主要采用传统机器学习算法进行框架识别。Johansson 和Nugues[9]通过特征工程提取文本特征后使用SVM来进行FI任务。Das等[10]引入条件模型在所有目标词、框架和原型之间共享权重,将手动设计的特征输入到模型,将框架名称作为监督信息来识别目标词的框架。
近些年来,分布式特征的表示以及基于神经网络的模型被广泛的应用于FI。基于此,框架识别的方法有两种。第一种是基于特征工程的方法,通过依存特征学习目标词的分布式表示。如Hermann等[11]提出了一种将可能的框架标签和目标词所在上下文的句法关系映射到相同特征空间的WSABIE算法。Hartmann等[12]提出了SimpleFrameId,将句子中所有词向量的平均作为上下文的表示,同样使用WSABIE算法进行相同的操作。赵红燕等[13]在CFN数据集上将依存关系对上下文进行特征抽取后使用DNN学习更抽象的目标词表示。第二种是使用深度神经网络自动学习目标词的上下文表示,和早期的工作类似,都是将离散的框架标签作为监督信息。Swayamdipta等[14]使用Bi-directional LSTM[15]构建分类器。Botschen等[16]使用图片和文本融合的多模态算法模型来提升框架识别的性能。Peng等[17]采用了FI和FSRL联合学习的模型,提出从多个数据集中学习语义解析的公式。Jiang等[18]将句子、词元定义、框架定义拼接,丰富了目标词的上下文信息。郭哲铭[19]利用BERT[20]作为表示层,提出基于Bi-GRU[21]的融合全局和局部注意力机制方法在CFN数据集上取得了不错的效果。Su等[22]使用了框架关系、框架元素联合建模,在FN数据集上取得了最好的效果。
图卷积神经网络[23](Graph Convolutional Network,GCN)首次将卷积的操作引入图中。Li等[24]在方面情感分析任务中,使用双重GCN融合需要判定情感词汇的依存信息,在多个数据集上取得不错的性能。Veyseh等[25]使用了基于门控机制的GCN融合了依存信息,在多个数据集上达到了最好的性能。Zhang等[26]采用了多任务的模型架构,使用GCN在细粒度观点分析任务中取得了不错的效果。Tian等[27]使用了注意力GCN在关系抽取任务上达到了最好的性能。以上工作说明,通过GCN学习依存特征不但可以增强目标词的表示能力,而且可以学习到一定的结构信息。
早期的框架识别方法通过手动设计与目标词关联的依存结构信息作为特征,学习目标词的表示。而在以深度模型为主的方法中,使用监督信号自动学习目标词的特征表示,融合了一定的语义和依存特征。以上框架识别方法虽然取得了不错的效果,但是还存在两方面的问题: (1)基于深度模型的方法在一定程度上过度融合上下文信息,为目标词的表示引入噪声,且对结构信息的学习较差。(2)没有考虑到不同词性的依存特征对框架识别的影响。基于此,本文针对上述问题,采用深度模型学习目标词上下文表示,使用GCN学习角色或依存结构特征。此外,进一步考虑目标词的词性,研究不同词性的依存特征对框架识别的影响。
2 融合序列与结构信息的框架识别模型
为了增强目标词的表示,本文结合多词性的结构信息,提出了一种融合序列与结构信息的框架识别模型。模型结构如图2所示,该模型包含: 1)结构信息提取层: 提取目标词所在序列的PropBank角色或依存结构信息; 2)编码层: 利用BERT对上下文序列进行编码; 3)语义结构关系表示层: 根据结构信息提取对应的语义表示并使用GCN将目标词和该表示进行建模; 4)标签预测层: 将GCN学习到的结构信息和目标词的表示拼接后通过分类器进行分类。另外,我们细粒度的考虑了不同词性的结构信息特征,采用了多模型的标签融合得到最后的预测结果。
2.1 结构信息提取层
目标词所在上下文的结构信息可以指导语义结构关系表示层对该信息进行融合表示。因此,本文采用AllenNLP[28]对目标词所在上下文进行结构信息提取以增强目标词的表示。其中结构信息分为PropBank角色信息和依存句法信息。所用依存分析和角色标注模型为当前公开的最好模型,在公开的英文数据集上分别获得了95%和86%的性能表现。
2.1.1 结构信息分析
本文中结构信息主要包括依存结构和语义角色信息两类,与目标词相关的这两类信息对于判别目标词所能激活的框架具有重要的作用。如对句子“Iran received assistance to help it produce nuclear weapons”分别进行PropBank角色标注和依存分析和框架语义角色标注后的结果如图1(b)和图1(c)所示,其中b的上方为框架语义角色信息,下方为PropBank语义角色信息,c的上方为依存句法信息。依存信息中“DEP”代表“依赖关系”,“DOBJ”代表“直接宾语”。框架语义角色信息中,“Producer”表示“生产者”,“Product”表示“产品”。“生产者(it)”和“产品(nuclear weapon)”对于判别目标词所激发的框架为“Manufacturing”具有较强的指导作用。
2.1.2 PropBank角色与依存句法信息分析
在框架识别时,框架语义角色是未知的,因而框架语义角色信息难以使用。然而对于动词目标词,其PropBank角色信息中“ARG0”代表“施事”,“ARG1”代表“受事”往往与框架语义角色信息重叠或对应,如图1(b)中的下方所示,通过“ARG0”和“ARG1”正好可以找到“it”与“nuclear weapon”与框架语义角色“producer”和“product”对应。因此,本文将PropBank角色信息作为结构信息融合到目标词的表示中,从而丰富目标词的语义表示,有助于识别目标词在当前上下文中所能激活的框架。
在图1(c)所示的依存信息中,我们可以通过目标词的“DEP”与“DOBJ”两个依存关系分别找到“it”和“weapon”两个词。这两个词与目标词“produce”的框架语义角色“producer”和“product”对应成分存在部分重叠。所以将依存信息融合到目标词的表示中,有利于丰富目标词的语义表示,从而获得更好的框架识别性能。
2.1.3 结构图的构造
我们使用了与目标词直接关联语义块作为结构信息,其邻接矩阵表示为A=(aij)∈m×m,m为该目标词结构信息中包含的语义块数量s与目标词数量之和。aij的定义如式(2)所示,其中wi为句子中的第i个语义块。此外,每个语义块的起始和终止位置信息分别表示为pi和li,目标词所在上下文结构信息的对应位置信息表示为P={[p1,l1],…[pi,li],…,[ps,ls]},并传递给编码层。
(2)
2.2 编码层
为获取目标词所在上下文的向量表示,本文采用基于Transformer[29]的BERT作为编码层将上下文的语义信息融入到目标词的表示中。

式中的Ws∈n×m,bs∈m是可学习参数,其中Ht和由式(5)、式(6)所示。目标词和依存信息可由多个token组成,因而需要对多个token对应的隐藏层Ht和进行加权平均操作(avg),得到整个词的表示。
其中,Pi[0]和Pi[1]分别表示第i个结构信息中语义块的起始位置和终止位置。
2.3 语义结构关系表示层
GCN将卷积运算从传统数据推广到图数据中,使其可在非欧式空间中提取特征。其核心思想是通过学习一个函数映射f(·),利用该映射,图中的节点每个vi可以聚合其自身特征xi与邻居特征xj,其中j∈N(vi)用于生成节点vi的新表示。
使用GCN作为语义结构关系提取层可借助该模型强大的空间特征提取能力,进一步将结构信息和目标词的关系融合到目标词的表示中。本文构建了两层GCN网络,并且两层网络之间通过ReLu函数进行连接,其提取层的网络结构如式(7)所示。
R1=GCN(ReLu(GCN(A,M)))[k]
(7)

2.4 标签预测层
将编码层获取的目标词表示rt和语义结构关系表示层获取的结构信息表示R1拼接后进行线性变换和非线性激活得到当前表示所属于每一个框架的概率pt,如式(8)所示,其中L代表线性变换层。最后取概率最大的位置作为当前预测的结果类别,如式(9)所示。
数据集的长尾分布是一个普遍存在的现象,并且经过我们的统计发现,FN1.7数据集也是呈现长尾分布,各类样本的分布数量如图3所示,故损失函数选用FocalLoss[30](以下简称FL)代替传统的交叉熵损失函数,FL针对数据中样本类别的不平衡问题,为难以学习的样本和容易学习的样本添加一个权重,让模型更加专注于难以学习的样本,进一步提升模型的鲁棒性,如式(10)所示。
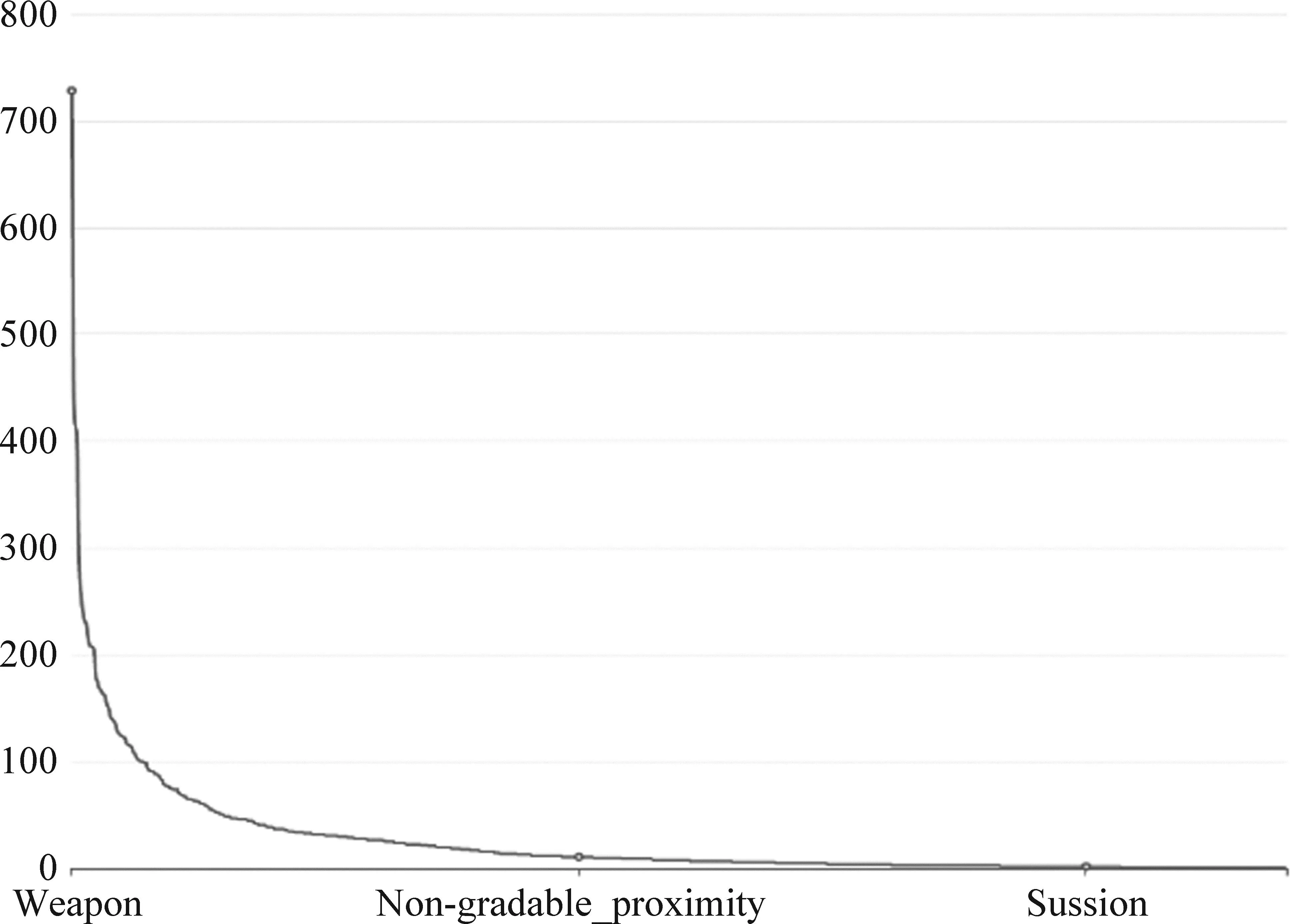
图3 FN数据集各类框架数量分布
FL=-(1-pt)γlog(pt)
(10)
其中γ为难度平衡系数,pt是预测的概率,(1-pt)γ称为调制系数,用来降低易分类样本的权重。
2.5 模型融合层
在FrameNet中,目标词的词性是多种多样的,可以是动词、名词、形容词等。由于不同词性目标词的结构信息不尽相同,所以有必要根据目标词词性的不同细粒度选择不同的结构信息来丰富目标词的语义表示。如图4所示,句子“Reality hit when he was unable to reconcile with his wife and end up on the street”中的词元分别是“hit”,“when”,“unable”,“wife”,“end up”,“street”,激活的框架分别是“Impact(撞击)”、“Temporal_ collocation(时间性共现)”,“Capability(能力)”、“Personal_ relationship(人际关系)”、“Transition_to _state(过渡到一种状态)”,“Roadways(道路)”。不同词性目标词的结构信息往往包含了多个语义块,每个语义块对于当前目标词的贡献度往往是不同的,1)名词: “AMOD”(形容词)和“POBJ”(介词宾语)两种关系通常是比较重要的; 2)动词: “ADVMOD”(状语),“DEP”(依赖关系)和“DOBJ”(直接宾语)两种关系是比较重要的; 3)形容词: 根据它所处的位置不同,和它依存的成分也是不同的,如果处于非核心的位置,它往往是和名词有“AMOD”的关系,如果处于核心的位置,则“NBUBJ”(名词主语)、“DEP”、“AMOD”等的一些关系比较重要; 4)副词: 它所直接修饰的成分较少,一般情况下,只修饰动词,只和动词会有“ADVMOD”的关系; 5)介词: 它的“POBJ”(介词宾语)是比较重要的。因而,本文为不同词性的目标词构造不同的邻接矩阵A,分别为每个词性的结构信息在整体的数据集上训练了一个模型,通过硬投票的方式进行融合得到最后的框架识别模型。整个投票过程如式(11)所示。

图4 各类词性在同一句子中的依存
(11)

3 实验设计与分析
3.1 实验数据
本文所需实验数据来自FN1.7的标注数据和CFN标注数据。其中FN数据集一共816个框架。CFN数据集一共619个框架,训练集、验证集、测试集的划分如表2所示。

表2 数据集划分
我们同时统计了FN1.7中Train和Test的五类词性占比,如图4所示。Train和Test中的分布基本是一致的,名词、动词、形容词、介词、副词是最多的。
3.2 评价指标及实验环境
3.2.1 评价指标
本实验使用Accuracy作为评价指标,具体定义如式(12)所示。
(12)
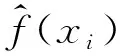
3.2.2 实验环境
本文的实验环境为pytorch1.8.0+cu111,所用的GPU为一块RTX3090,CPU为AMD Ryzen 9 3900X。
3.3 参数设置
本文实验所设参数如表3所示。

表3 FN数据集实验参数
3.4 实验结果及分析
3.4.1 总体分析
为了验证提出的融合序列与结构信息的框架识别方法的有效性,我们设置了如下框架识别模型进行对比实验: (1)使用BERT作为baseline;(2)SimpleFrameId、BERT-onehot和KGFI三个对比模型;(3)直接融合动词角色信息和非动词依存信息的BERT_Prop_Dep _GCN_Focal(BPDGF);(4)使用投票方式融合动词角色信息和非动词依存信息的BERT_Prop_Dep_GCN_Focal_Vote(BPDGF_ Vote)。实验结果如表4所示。
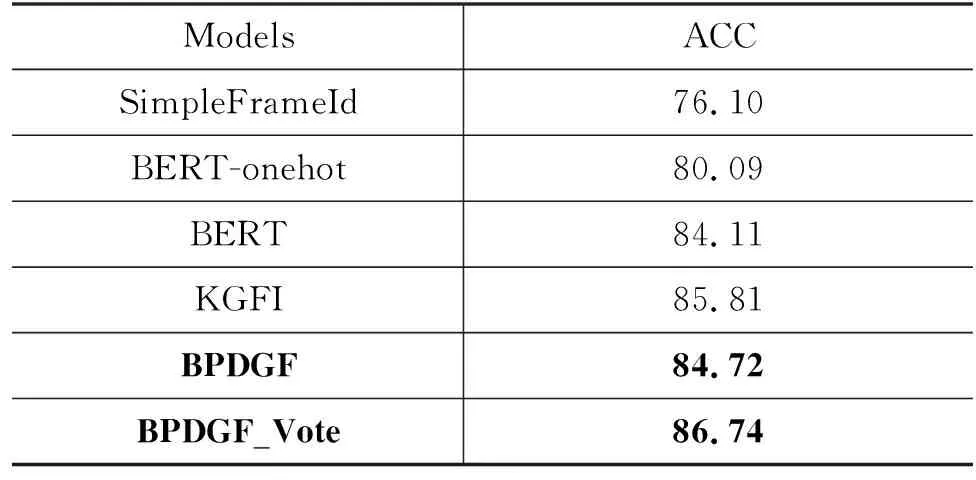
表4 FN1.7实验结果 (单位: %)
由实验结果可见,直接将动词的角色信息和非动词的依存信息融合学习的模型BPDGF相对于baseline提升了0.61%,表明结构信息对于框架识别有一定的促进作用,但统一建模会影响模型性能。而我们在细粒度考虑不同词性对于模型的影响后,构建的模型BPDGF_ Vote相对于Baseline和KGFI提升了2.63%和0.93%(这里采用的是KGFI中没有使用词元过滤的实验结果)。证明了细粒度的结构信息对于框架识别有着更高的作用。
3.4.2 依存信息及FL对性能的影响
为了确定不同词性和FL对于FI任务的影响,我们针对不同词性的目标词,分别添加依存信息,在BERT_Dep_GCN(BDG)、BERT_Dep_GCN_ Focal (BDGF)两个模型上进行实验,其中BDG使用了传统的交叉熵作为损失函数,实验结果如表5所示。在使用FL代替交叉熵损失函数后,模型的表现都有了不同幅度的上升,并且在给形容词性目标词添加依存信息并使用FL后达到了最好的86.47%的准确率,相较于Baseline提升了2.36%。

表5 不同词性依存信息实验结果 (单位: %)
进一步分析,对某个词性的目标词单独添加的依存信息是否只提升了当前词性目标词的识别性能?为了确定这个问题,我们分别统计了模型BDGF在五种词性的目标词上分别加依存信息后在Test上每种词性的正确率,即BDGF_n、BDGF_v、BDGF_adv、BDGF_adj、BDGF_prep五个模型在Test上不同词性的正确率,统计结果如表6所示。在为不同词性单独添加依存后,模型在除它本身以外的其他词性上的表现分别得到了不同程度的提升,说明依存信息除了可以提升当前词性目标词的识别能力外,由于依存信息通常会关联到其他目标词,故对于和它依存的其他目标词也有一定的提升作用。

表6 不同词性添加依存后在Test上各类词性的正确率 (单位: %)
具体而言,对于模型BDGF_n,相较于模型BDGF_v来说,在动词上取得了更好的性能表现,出现这样的结果是因为句子中名词的与动词会存在各种修饰关系,如图5中的“agreement”和“construct”,它们之间存在了“INFMOD”的关系。在训练时,该依存的动词获得了进一步的信息增强,故而取得了更好的模型表现。而添加了动词依存和形容词依存的模型BDGF_v和BDGF_adj分别在介词和名词取得了最好的效果是因为介词通常修饰动词,形容词通常修饰名词,因此在这两个词性上可以获得更好的效果。

图5 名词依存中的动词成分
3.4.3 不同结构信息对性能的影响
为了探究在动词上的角色信息与依存信息对于框架识别的作用哪个更好,我们设计了单独给动词分别添加角色和依存信息的模型BPGF和BDGF。实验结果如表7所示,BDGF的正确率达到了85.81%。将依存信息改变为角色信息后,BPGF正确率达到了85.95%,相较于Baseline提升了1.84%,比BDGF高出0.14%。说明动词的角色信息对于FI任务是优于动词的依存信息的。
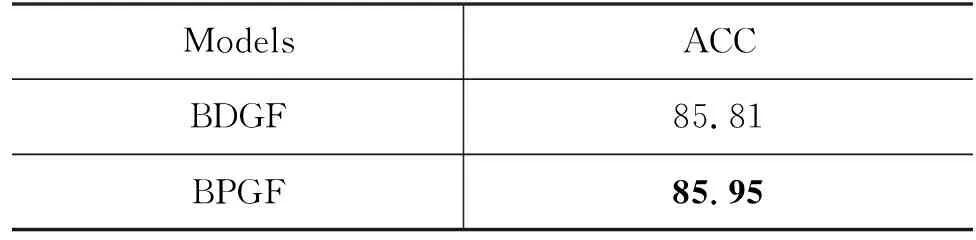
表7 FN1.7实验结果 (单位: %)
例如,图1(b)和图1(c) 分别展示了例句的角色信息和依存信息,通过模型BPGF可以正确的识别为“Manufacturing”框架,而使用依存信息构建的模型BDGF识别为“Causing”,从目标词的角色信息和依存信息的对比来看,角色信息的优势在于能够获取到更多的与框架语义角色重叠的信息,可以为目标词提供更加丰富的语义信息,有利于指导模型的学习。
同时,为了验证模型的有效性和泛化能力,我们在CFN数据集上进行了实验,实验结果如表8所示。由于CFN数据集中目标词都是动词,故使用了BDFG和BPFG模型,并以BERT作为baseline。两个模型在CFN上分别提升了1.37%和1.76%,BPFG的性能比BDFG高0.39%,进一步证明对于FI任务,由于角色信息贴近框架语义角色信息,更有利于促进FI。因此,角色信息是优于依存信息的。

表8 CFN数据集实验结果 (单位: %)
3.4.4 不同融合方式添加的结构信息对性能的影响
在进行角色或依存信息提取后,我们考虑两种给目标词添加特征的方式: (1)通过GCN融合到目标词的表示中,将得到的表示R1进行分类(direct);(2)进行线性变换后,拼接到原始的目标词表示中(cat)进行分类,如式(12)所示。
实验结果如表9所示。实验证明,不管是通过融合方式还是拼接方式,都对FI任务有一定的提升作用,但是使用拼接方式的效果好于融合方式。因为采用GCN进行特征提取时会引入一部分随机初始化的权重信息,这一部分权重会影响分类的结果而使用拼接的方式将这部分权重的比例减少,从而降低了这部分特征对于整体特征的影响。

表9 使用拼接和直接进行分类实验结果 (单位: %)
3.5 案例分析3.5.1 融合动词角色信息的框架识别案例
由于只有动词才有语义角色,故在分析过程中只选取动词所能激活的框架进行分析。例如,在句子(1)“Because turning welfare recipients into tax payers just makes sense.”中,目标词是“turning”,在该上下文中所激活的框架是“Cause_change”,但是“turning”在句子(2)“But Jamaica is not simply turning blindly into a small version of its brother bigger.”中所激活的框架是“Under- go_change”,这种一词多义现象也是框架识别的挑战。在我们的baseline模型中,句子(1)中的“turning”被识别为“Undergo_ change”,即没有正确的识别。我们的模型BERT_Prop_GCN_Focal(BPGF)可以正确识别为“Cause_ change”框架,“turning”所在的句子(1)和句子(2)的依存特征如图6所示。通过对比我们发现,只通过BERT对序列进行建模后,无法明显的区分“turning”在两个句子中的特征,而两句话中和目标词关联的成份有明显的不同,因此通过GCN建模后能够学习到同一个目标词在两个不同的场景中的区别,故能够正确的识别“turning”所在上下文的能够激活的框架。

图6 同一目标词在不同句子中的角色信息
3.5.2 融合形容词依存信息的框架识别案例
名词框架是FN1.7数据集中数量最多的框架,名词中的多义词可以通过修饰名词的形容词来进行限定,通过这一方法缩小了多义词的范围,提升了模型的学习能力。对于例句“A popular optional excursion is an hour's detour to Guangzhou Zoo”,目标词“popular”的依存信息如图7所示。对于形容词“popular”在baseline模型中识别为“Hit_or_miss”框架,对于名词“excursion”,识别为“Arriving”框架,两个目标词所能激活的真实框架分别是“Desirability”和“Travel”。
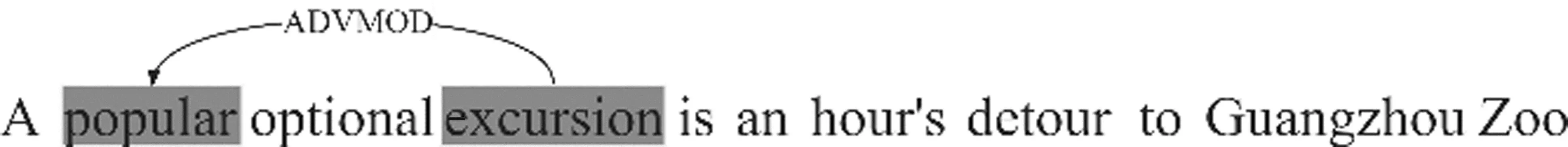
图7 目标词popular的依存信息
“excursion”的含义有“旅行、涉猎、移动等”,“popular”的含义有“受大众喜爱的、普通的等”,对二者通过依存信息链接后,出现的语义组合有“受大众喜爱的涉猎、受大众喜爱的移动等”都不符合常识,只有“受大众喜爱的旅行”是符合常识和人类的语言习惯。因此,通过依存信息链接的多个词可以互相关联,进一步丰富目标词的语义表示,有助于提升框架识别的性能。
4 总结
本文提出了一种融合上下文结构信息的框架识别模型,在模型中我们通过BERT对文本序列建模,使用GCN捕获目标词的上下文结构信息特征。在结构信息的选取上,我们考虑不同词性目标词的结构信息对于框架识别的影响,采用标签融合的方式,将使用了不同词性结构信息得到的模型融合,获得了不错的性能提升,并在词性为动词的目标词上证明了角色信息对于框架识别的提升作用优于依存信息。对于多词性结构信息的融合问题,我们采用了直接硬投票的集成方法,探讨更优雅的集成方法是我们之后工作的一个重点。
猜你喜欢
今日农业(2021年19期)2022-01-12
小资CHIC!ELEGANCE(2022年1期)2022-01-11
中老年保健(2021年11期)2021-08-22
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
数学物理学报(2020年3期)2020-07-27
现代出版(2020年3期)2020-06-20
开放教育研究(2020年2期)2020-03-31
法大研究生(2017年1期)2017-04-10
现代语文(2016年21期)2016-05-25
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
