
InstructGPT在命名实体识别任务中的表现和挑战
2024-03-26 02:39邱锡鹏牟小峰黄萱菁
中文信息学报 2024年1期
孙 瑜,颜 航,邱锡鹏,王 定,牟小峰,黄萱菁
(1.复旦大学 计算机科学技术学院,上海 200433;2. 美的集团AI创新中心,广东 佛山 528311)
0 引言
大规模语言模型(Large Language Models, LLMs),如GPT-3系列[1-3],由于其不依赖下游数据微调即可取得较好的性能表现[4-5],在自然语言处理(Natural Language Processing, NLP)社区引起了热烈讨论。具体而言,大规模语言模型只需要使用适当的提示(Prompt),就可以在零样本(Zero-shot)设定下取得不错的性能[4,6];对于少样本(few-shot)问题,大规模语言模型可以利用上下文学习(In-context Learning, ICL)[1,7]或者思维链(Chain-of-Thought, COT)[8]提示来提高性能。
尽管过去的文献[1,5]已经证明了大规模语言模型在自由生成任务和多项选择任务中表现十分出色,但他们在结构化抽取任务,如命名实体识别(Named Entity Recognition, NER)中仍然面临挑战[9]。目前,没有工作对大规模语言模型在命名实体识别上的能力进行全面的研究,因此,本文设计了一系列实验,深入研究了InstructGPT在命名实体识别任务上的表现及面临的挑战。具体地,本文主要回答了下面两个问题:
(1) InstructGPT在不同设定和不同领域上表现得怎么样?为了回答这个问题,本文分别在生物医学领域和通用领域上,进行了零样本学习和少样本学习。其中,通用领域在中英文的常规数据集和英文的嵌套数据集上都进行了实验。为了增加可信度,本文沿用了之前工作[5]中采用的提示作为基准来解决零样本的命名实体识别任务。除此之外,由于抽取实体本质上是结构化抽取任务,模型的输出需要满足一定的格式才能从中成功地解析出实体。为了实现这个要求,本文设计了一个结构化提示,从而指导InstructGPT生成格式化的文本。零样本场景下两种提示的例子如图1所示。在少样本设定下,本文探索了上下文学习和思维链两种方法。上下文学习时,本文沿用了之前广泛使用的提示方法[9]。目前的思维链方法主要在推理任务中使用,本文是第一个将该方法引入到命名实体识别任务中的。少样本场景下的两种提示的例子如图2所示。结果显示,InstructGPT无论在生物医学领域还是通用领域的数据上的表现,都和微调模型的表现有巨大的差距。其中,在零样本命名实体识别任务上,InstructGPT仅能达到微调模型性能的11%到56%,在少样本命名实体识别上,InstructGPT的性能最多达到72%。

图2 少样本命名实体识别提示的例子
(2) 为什么InstructGPT在命名实体识别任务上表现得不理想?InstructGPT在很多生成式的任务上的表现与微调模型性能相近,甚至更好。然而,InstructGPT却在命名实体识别上没有达到预期效果。为了探究阻碍InstructGPT成功抽取实体的原因,本文从两个方面来仔细评估了模型的输出: 无效生成和虚假预测。无效生成包括输出无法成功匹配解析格式的“格式无效”,和输出的实体片段不在输入句子中的“片段无效”。结果表明,10%~70%的输出句子存在无效生成的问题,严重影响了解析过程。零样本场景给出更详细的指令或者少样本场景增加示例的个数可以有效减少“格式无效”。然而,“片段无效”仍是一个亟需解决的问题。此外,无效性可能会直接导致生成的句子解析失败,从而不能识别预测成功的实体。本文称这种情况为虚假预测。虚假预测除了存在导致性能偏低的“虚假错误预测”,还存在导致性能偏高的“虚假正确预测”。当无效性问题严重时,“虚假正确预测”的数量甚至增加到40%。未来的工作在保证预测正确性的前提下,仍需从根本上提升InstructGPT等大模型抽取实体的能力。除此之外,针对嵌套命名实体识别任务,本文还统计了InstructGPT生成的实体中嵌套实体的比例,即实体嵌套率,发现其远低于数据集中的比例。并且,抽取嵌套实体的正确率也不足一半。这说明大模型在处理嵌套实体方面还是面临挑战的。
总的来说,本文的贡献主要体现在以下个四方面:
(1) 本文首次详细探究了InstructGPT在命名实体识别任务上的表现,覆盖了生物医学领域和通用领域、常规场景和嵌套场景的数据,并在零样本和少样本设定上都进行了实验。本文提供的实验结果可以作为之后研究的基准。
(2) 首次提出将思维链应用到命名实体识别任务上,并为生物医学领域和通用领域的数据设计了不同形式的思维链,并对其性能进行了测试。
(3) 本文从两个指标出发,对InstructGPT的输出进行了错误分析,发现了输出的无效性是阻碍InstructGPT性能提升的重要因素。通过分析无效生成问题导致的虚假预测问题,本文发现,解决无效生成问题并不一定会提升InstructGPT在命名实体识别上的性能。未来工作可以针对本文列举的无效生成类型,首先保证模型生成的正确性,其次设计更好的抽取实体的方法。
(4) 首次针对性地研究了InstructGPT在嵌套命名实体识别任务上的表现,发现InstructGPT的实体嵌套率和嵌套正确率较低。通过增加上下文示例的数量可以一定程度上增加InstructGPT生成嵌套实体的比例和识别的正确率。
1 任务定义
命名实体识别作为一个基本的结构化抽取任务,旨在从原始文本中抽取实体片段,并将它们分类到预定义的类型中。例如,“复旦大学是上海市的一所综合性大学。”中,“复旦大学”是组织类别的实体,“上海市”是地点类别的实体。本文为了提升效率,InstructGPT需要一次性从句子中抽取出所有类型的实体片段并分类。即,上面句子的输出应该为“组织: 复旦大学;地点: 上海市”。最后,模型的原始输出被解析成结构化的实体,从而进行评测。
2 提示的设计
为了充分研究InstructGPT在命名实体识别任务中的表现,本节详细描述了在不同设定和领域中提示的设计。
2.1 零样本命名实体识别
零样本学习时,本文使用的提示由3个部分构成: 任务指令、候选句子、指示词。如图1所示,本文为零样本命名实体识别设计了两种提示。图1中从上到下的示例分别来自生物医学领域、英文通用领域和中文通用领域。
2.1.1 原始提示
作为基准,本文沿用了之前工作的提示,其中任务指令是关于命名实体任务的描述,并给出需要抽取的实体类别。在抽取可能包含嵌套实体的句子的时候,本文在任务指令后面添加了“Notice that there may exist nested entities.”。候选句子由“Sentence:”/“句子: ”拼接待抽取的句子。指示符是“Entity:”/“实体: ”。原始提示的示例如图1(a)所示。
2.1.2 结构化提示
正如第1章所讨论的,InstructGPT在其生成格式方面展现出了相当大的灵活性。因此,设计提示来指导InstructGPT生成理想的格式化输出对于实现有效的解析至关重要。因此,本文修改了任务指令部分,添加了输出格式的详细指令。中英文关于输出格式的描述有所不同。其余两个部分与原始提示一致。如图1(b)所示,结构化指令部分用下划线标出。
2.2 少样本命名实体识别
少样本学习时,本文使用的提示由四个部分构成: 任务指令、示范(Demonstration)、候选句子、指示词。除了新增的示范部分,其他部分都与零样本学习的原始提示相同。如图2所示,本文使用了两种常见的大模型少样本学习方法,即上下文学习和思维链。不同方法的改变只存在于示范部分。图2中从上到下的示例分别来自生物医学领域、英文通用领域和中文通用领域,并只拼接了一个示范作为例子。
2.2.1 上下文学习
受到之前工作的启发[5],本文设计的示范部分由几个完整训练示例组成,即训练示例构成的候选句子、指示词以及模型输出。其中训练示例的输出应与最终期望的模型输出具有相同的格式。图2(a)给出了三种情况下的上下文学习输入输出的例子。
2.2.2 思维链
与上下文学习不同,思维链[8]的示范部分由几个推理链组成。其中每个推理链都包括了一系列中间推理步骤,即原理(Rationale)和答案。本文是第一个将思维链提示应用到命名实体识别上的研究,并为不同领域的数据设计了不同的推理链。如图2(b)所示,推理链部分用下划线标出。
对于生物医学领域,本文首先从维基百科检索出实体的条目页面,并选择定义句子(通常在文档开头)作为推理链。如果该实体没有条目,则随机选择一个包含该实体的句子。之后,在推理链后拼接“Therefore”开头的结论作为答案部分。对于通用领域,本文受到了triggerNER[10]的启发。triggerNER是通过选择特定的单词和短语作为解释性标注来识别实体。对于CoNLL03数据集,本文直接使用triggerNER的标注;对于其他通用领域数据集,本文使用该技术原理,人工标注了解释性单词和短语。之后,将这些解释性单词和短语用自然语言描述,作为推理链;用“Therefore/因此”开头的结论作为答案。
3 实验
本章节首先介绍了本文使用的9个数据集,然后展示并分析讨论了实验结果,来分别回答前面提出的两个问题。
3.1 数据集
本文在三个生物医学领域、四个常规通用领域和两个嵌套通用领域的命名实体识别数据集上进行了实验。沿用过去的工作,本文只在1 000条测试数据上评估InstructGPT的表现,如果测试集数据少于1 000条,则使用全部测试集。每个实验使用相同部分的子数据集。
3.1.1 生物医学领域数据集
本文选择了BLURB基准数据集[11]中的三个数据集。其中生物创新V化学-疾病关系语料库(BioCreative V Chemical-Disease Relation corpus)[12]包含了PubMed摘要中标注为疾病(BC5CDR-disease)和化学(BC5CDR-chem)实体的句子,生物创造II基因提及(Biocreative II Gene Mention, BC2GM)[13]数据集则包含了PubMed摘要中的基因标注。
3.1.2 通用领域数据集
本文选择了四个常用的通用领域的常规命名实体识别数据集,其中,两个是英文,两个是中文。对于英文数据集,本文使用了CoNLL03[14]数据集和OntoNotes5[15]数据集,其中OntoNotes5数据集本文只保留了非数字的实体类别;对于中文数据集,本文使用了MSRA[16]数据集和OntoNotes4[17]数据集。除此之外,本文还选择了两个常用的英文嵌套命名实体识别数据集,分别是ACE04[18]和ACE05[19]。
3.2 结果: InstructGPT在不同设定和不同领域上表现得怎么样?
本节的实验旨在探究InstructGPT在低资源场景下解决命名实体识别任务的能力。表1展示了生物医学领域数据集的实验结果,表2和表3分别展示了通用领域常规实体和嵌套实体数据集的实验结果。少样本学习时,本文分别在拼接1个、5个和10个示例的情况下测试。每个结果都是5次实验结果的平均值,下标表示标准差(例如,76.811表示76.8±1.1)。

表1 生物医学领域数据的主要结果 (单位: %)

表2 通用领域数据的主要结果 (单位: %)

表3 通用领域嵌套实体的主要结果 (单位: %)
3.2.1 生物医学领域
在生物医学领域,本文对比了微调BioBERT[20]预训练模型的结果。零样本学习时,InstructGPT在生物医学领域数据集上能达到41%~61%微调模型的表现。本文发现结构化提示对零样本学习似乎没有影响,甚至会对疾病和化学类别实体的提取产生负面影响。
在少样本学习时,InstructGPT在少样本的生物医学领域的数据上的表现达到了51%~80%微调模型的能力。增加示例数量(从1个到10个)在上下文学习和思维链方法中都有益于F1的提高,分别平均有+10.3和+41.6的增长。但是,仅使用一个示例时,思维链方法的F1相较于上下文学习平均下降了25.2。这是由于思维链方法的生成中,原理部分的结构比较复杂,InstructGPT难以保证有效输出,导致了严重的解析失败问题,从而表现不佳。一旦示例数量增加,InstructGPT在生物医学领域数据集上使用思维链的性能优于只使用上下文学习。
3.2.2 通用领域
在通用领域的常规命名实体识别数据集上,本文对比了微调RoBERTa[21]预训练模型的结果。在通用领域的嵌套命名实体识别数据集上,本文对比了微调BERT[22]预训练模型的结果。由于该篇工作没有汇报完整的实验结果,因此我们也只在表格中展示了F1。在零样本常规实体的抽取上,InstructGPT大概能达到20%~56%微调模型的性能;在嵌套命名实体识别数据上大概能达到20%~29%微调模型的性能。另外,本文发现,在常规实体的抽取上使用结构化提示可以显著提高性能,F1平均提高了8.7。这意味着通过修改提示指导InstructGPT生成更加格式化的输出对于通用领域实体识别是有效的。嵌套实体抽取中使用结构化提示反而一定程度上损害了性能。
在少样本学习时,随着上下文示例数量的增加,在常规命名实体识别任务上,上下文学习和思维链的性能分别平均提高了14.4和24.8;在嵌套命名实体识别任务上,则分别提高了11.9和15.5。对于通用领域常规实体的提取,实验发现思维链在常规实体抽取上的用处不大。其原因可能是实体触发词与实体本身之间没有强烈的因果关系,导致不能激发模型潜在的推理能力。并且由于思维链的输出结构更加复杂,反而会一定程度上损害模型的表现。值得注意的是,在每个设置中,OntoNotes5的性能明显低于其他数据集。这是由于OntoNotes5有11个类别,远远多于其他数据集的3、4个类别。InstructGPT在解决很多类别的分类时,也面临了巨大的挑战。思维链方法运用在嵌套实体中可以一定程度上提升性能,这可能是由于ACE04和ACE05数据集中有很多指代词被标注为实体。思维链的使用帮助InstructGPT利用上下文的逻辑来抽取实体。
总体而言,与微调模型相比,实验发现InstructGPT在每个命名实体识别数据集上的表现都不尽人意。具体来说,InstructGPT只能通过零样本提示实现11%~56%的性能。即使添加了示例样本,InstructGPT的F1最多也只能达到72%。通过之前的观察,本文建议在解决通用领域的命名实体识别问题时,可以使用结构化提示来提升最终的性能。面对少样本问题时,思维链提示在生物医学领域更有可能表现良好;而对于通用领域的少样本学习,上下文学习足以胜任。
3.3 结果: 为什么InstructGPT在命名实体识别任务上表现得不理想?
正如前文所述,尽管在许多设定下进行了尝试,InstructGPT的结果与微调模型之间仍存在显著差距。本节对输出文本进行了详细的分析,发现了导致结果不理想的一个重要原因是无效生成。这种无效性问题还会导致虚假预测问题,使得目前获得的结果不完全准确。在嵌套命名实体识别时,本文发现InstructGPT的嵌套实体识别率偏低,说明在识别嵌套的实体上还面临挑战。
3.3.1 无效生成
由于命名实体识别任务本质上是一个结构化抽取任务,因此最终目的是得到结构化的实体。要将InstructGPT输出的非结构化文本解析成结构化的实体,其生成的输出必须是格式化的,才能成功地匹配解析。基于这个特性,本文引入了“格式无效”这一指标,表示模型输出的格式与期望格式不符。主要体现在解析阶段无法区分不同实体类型之间的实体,或者无法区分类别词和实体。例如,图3中的(1)就是“格式无效”的一个例子。此外,命名实体识别任务要求抽取的实体片段必须完全属于原始句子。由于实体有各种表达方式,InstructGPT可能会生成该实体的其他形式,从而导致匹配解析失败。此外,单数和复数的使用不一致也会导致此问题。本文为此定义了“片段无效”指标来记录不符合该要求的实体片段的数量。例如,图3中(2)就是“片段无效”的一个例子。
除此之外,本文还引入了“无效句子”,来记录具有任何以上两种类型无效性的句子的数量。三种无效性的结果如图4所示。在每个子图中,“格式无效”和“片段无效”的单位都是片段数量,基于左边的Y轴,而“无效句子”的单位是句子数量,基于右边的Y轴。值得注意的是,生物医学领域数据集的“格式无效”在零样本学习和上下文学习时始终为0。这是由于生物医学领域的数据集都只有一个实体类型,解析过程中不需要格式匹配来区分不同实体类型。
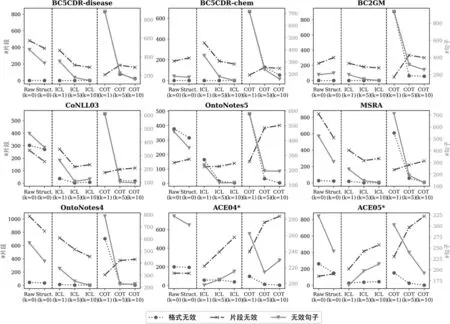
图4 无效生成的统计数据图
总的来说,无效生成问题有三个值得注意的结论: (1) 在零样本学习时添加结构化提示或者在少样本学习时增加示例数量都有助于提高输出格式的正确性。从图3中可以看出,增加结构化提示后,“格式无效”平均减少了34个;将示例数量从1个增加到10个,“格式无效”在上下文学习中平均减少了42个,在思维链上平均减少了536个。(2) 使用思维链方法时,如果只拼接一个示例,InstructGPT很难模仿复杂的推理过程。如图4所示,每个数据集在只使用一个示例的思维链方法中,都有相当多的“格式无效”,达到了600到900个片段。增加示例的数量可以显著缓解这个问题,如可以将无效的片段数降低到个位数。(3) “片段无效”问题更具挑战性,并且使用现有的大模型学习方法难以解决。通过提示或者示例引导InstructGPT生成格式化的输出,几乎可以将“格式无效”降至零;但几乎每个数据集的每个场景中,“片段无效”都超过了200个。InstructGPT在中文数据集上的“片段无效”问题尤为严重。
3.3.2 虚假预测
上一节描述的无效生成问题可能会导致InstructGPT的输出面临解析失败的问题。解析失败会导致预测正确的实体没有被解析出来,即判别为预测错误的句子实际是正确的,使最终性能偏低,本文称之为“虚假错误预测”。直觉上,设计更好的提示或者更好的解析方法可以缓解无效生成的问题,进而减少“虚假错误预测”,从而得到更好的性能。然而,通过收集InstructGPT存在无效生成的句子,本文发现,解析失败还会使一些预测错误的实体躲过与目标实体匹配的过程,使得预测错误的句子被错误判别为正确预测,使最终性能偏高,本文称之为“虚假正确预测”。本文将这两种情况统称为虚假预测。
存在“虚假错误预测”的句子,一旦模型的输出被更好地解析,就可能纠正这些虚假错误,性能就可以进一步提高。从表2、表3和图4中可以看出,零样本中增加结构化提示或者少样本中增加样本数量时,“格式无效”的数量减少,F1也相应地有所提升。
“虚假正确预测”的统计结果见图5,每个子图的单位都是句子数量,每个柱体的高度是正确预测的数量,包括“真实正确”(实心部分)和“虚假正确”(斜线部分)。如果InstructGPT预测正确并且输出的句子不存在无效生成问题,则表示该测试用例是真实正确的。“真实正确”部分表明,添加结构化提示比仅使用一个示例更有用,同时添加的示例越多,真实正确的数量也越多,表示模型能力越好。如果InstructGPT预测正确但是输出句子存在无效生成,则认为该测试用例是虚假正确的。实验表明,原始提示和使用一个样本的思维链方法均面临了严重的“虚假正确”问题。正如3.3.1节描述的,这两种情形下,InstructGPT的输出存在很多“格式无效”问题。这个问题可以通过添加结构化提示和增加示例数量缓解。
总之解决InstructGPT生成的无效性并不能保证最终结果的提高。如果解决的“虚假错误预测”问题多于“虚假正确问题”,则最终性能会提升;反之,性能会下降。因此,为了从根本上提升InstructGPT在命名实体识别任务上的表现,未来工作首先应该解决虚假预测的问题,保证最终的性能是真实的。阻碍性能真实性的主要问题之一是无效生成问题。减少输出格式与期望格式不匹配的“格式无效”问题的一个主要方法是使用结构化提示或添加更多示例。如何确保模型输出的片段有效,仍是InstructGPT在这种结构化抽取任务上的瓶颈。未来的工作可以更多地关注提升大规模语言模型在片段定位上的能力。
3.3.3 嵌套实体识别率
在嵌套命名实体识别场景下,实体之间可能存在嵌套关系,即一个实体包含了其他实体。本文统计了各个实验设定下,InstructGPT抽取的嵌套实体数、抽取正确的实体数和总的实体数。为了公平对比,还计算了嵌套正确率=抽取正确的嵌套实体数量/嵌套实体数量,实体嵌套率=嵌套实体数量/总的实体数量。表4对比了上述统计数据与测试集中实际的数量。
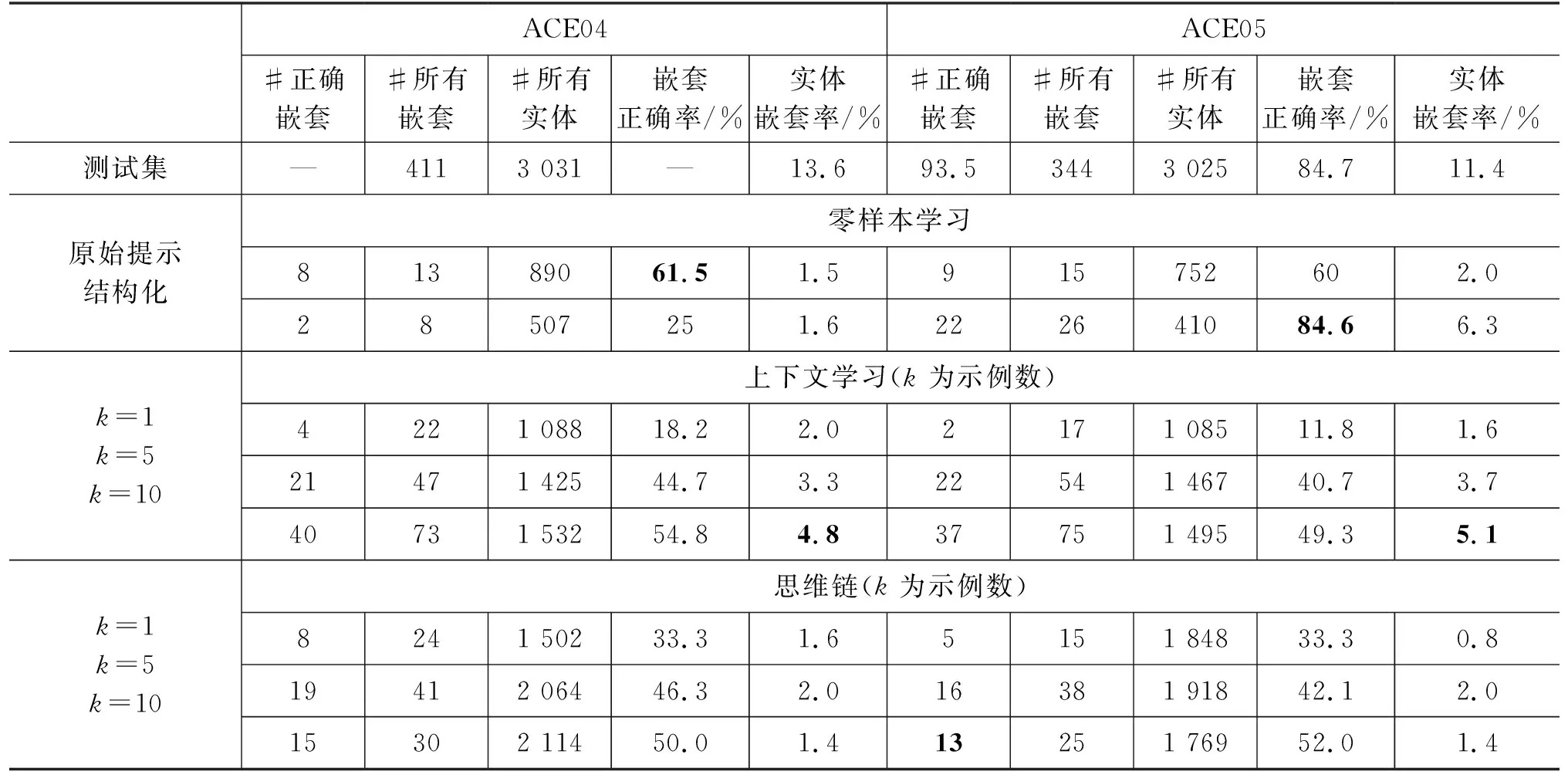
表4 嵌套实体识别率统计
本文发现,InstructGPT生成的实体嵌套率远远低于实际的比例,最多只能达到5%,这说明InstructGPT还是更倾向于预测常规的实体。而预测出来的嵌套实体中,模型也通常只能做对不足50%,这说明定位到正确的嵌套实体位置对于InstructGPT来说还是一项重大的挑战。除此之外,上下文学习的场景下,InstructGPT倾向于生成更多的嵌套实体,本文推测通过添加存在嵌套实体的示例,可以挖掘模型识别嵌套实体的能力,而这比用指令指导InstructGPT生成嵌套实体更有用。而思维链提示中复杂的推理句子,让InstructGPT模糊了嵌套实体的位置,更注重抽取需要推理的代词实体。另外,增加上下文示例的数量可以一定程度上增加嵌套正确率。
4 相关工作
近些年,大规模语言模型[1,4,6,23]如雨后春笋般涌现。他们庞大的模型规模带来了强大的能力,尤其是在零样本学习和少样本学习上展现了惊人的效果。在解决零样本任务时,大规模语言模型仅需要适当的提示就能在很多任务上达到和微调模型同样的效果[5]。在解决少样本任务时,大规模语言模型仅通过上下文学习便表现出令人惊叹的泛化能力[1]。一些先前的工作[8,24]探索了思维链提示,即利用推理链进一步激发大规模语言模型的推理能力。在他们之中,GPT-3系列[1-3]是最受关注的模型。在这个系列中,InstructGPT[3]引入了来自人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF),是第一个与用户对齐的模型。因此,本文选择探究InstructGPT的能力。
使用大规模语言模型解决自然语言处理任务中的零样本学习和少样本学习时,主要有两种方法。其一,一些工作[25-27]使用大规模语言模型来标注没有标签的数据,并使用这些伪标签对小规模预训练语言模型(Pre-trained Language Models, PLMs)进行微调。然而,命名实体识别是一项词元级别的标注任务,InstructGPT很难直接对句子中的实体片段进行标注。其二,一些研究[5,28]直接应用大规模语言模型进行推理。本文也采用这种方法直接评估模型的表现。之前也有一些工作[9,28]评估了这种方式下命名实体识别任务的性能,但他们只在特定领域进行了少样本的上下文学习。目前,还没有工作全面地研究InstructGPT在各种领域的命名实体识别上各种设定下的性能和输出的分析。本文对命名实体识别的性能和面临的挑战进行了详细分析。
5 研究与展望
本文对InstructGPT在命名实体识别任务中的表现进行了全面研究,实验的数据集覆盖了生物医学领域和通用领域,其中通用领域还考虑了中英文常规数据集和英文嵌套数据集。本文分别在零样本学习和少样本学习中各采用了两种提示,来评估InstructGPT的表现。实验发现,InstructGPT在命名实体识别中的表现并不理想,离微调小模型还有很大差距。经过实验统计分析,这主要是由于输出中存在“格式无效”和“片段无效”问题,使得解析过程失败。为了减少无效性问题,本文建议使用结构化提示或增加示例样例的数量来帮助InstructGPT克服“格式无效”的问题。除此之外,解决“片段无效”也是至关重要的,并且是未来使用大规模语言模型解决结构化抽取的重点研究方向。本文发现生成无效导致的虚假预测问题,不仅可能使结果偏低,也可能导致结果偏高。因此,未来工作仍需要从其他思路来进一步提升InstructGPT抽取实体的能力。对于更加复杂的嵌套实体来说,InstructGPT也面临了很大的挑战。InstructGPT的识别实体的嵌套率远低于数据集中本来的比例。因此,如何使得大模型识别更多的嵌套实体也是未来工作的一大难点。此外,本文是第一个在命名实体识别任务中实现思维链提示的研究。实验观察到,相比通用领域,思维链在生物医学领域中更有效。并且,使用思维链提示需要足够数量的示例以避免严重的“格式无效”问题。总之,本文探究了使用InstructGPT在命名实体识别任务中存在的限制和潜在的改进方法。希望本文的发现能为未来的大规模语言模型研究提供有价值的见解。
猜你喜欢
作文周刊·小学一年级版(2023年40期)2023-10-18
系统工程学报(2021年4期)2021-12-21
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
新世纪智能(语文备考)(2019年10期)2019-12-18
山东冶金(2019年5期)2019-11-16
中学生数理化·七年级数学人教版(2018年9期)2018-11-09
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
计算机工程(2014年6期)2014-02-28
河南科技(2014年23期)2014-02-27
