
健康筛查发生高尿酸血症风险预测模型的系统评价
2024-03-25 01:32黄思源何欣欣张明凤熊华容石镁虹
包头医学院学报 2024年3期
黄思源,何欣欣,张明凤,熊华容,王 丹,石镁虹
(西南医科大学护理学院,四川 泸州 646000)
高尿酸血症(hyperuricemia,HUA)是一种由于嘌呤代谢障碍或紊乱而导致的血清尿酸水平升高的疾病[1],是指男性患者血清尿酸>420 μmol/L(7 mg/dL)、女性患者血清尿酸>360 μmol/L(6 mg/dL)[2]。我国不同地区高尿酸血症的发病率为5.46%~19.30%[3],其中男性人群发病率最高可达26.2%。高尿酸血症不仅是导致痛风的基础疾病,还会增加患高血压、心脏疾病、糖尿病和慢性肾衰竭的风险[4]。近年来,随着社会经济水平的提高和人们生活方式的改变,高尿酸血症的患病率逐渐增加。但由于其发病隐匿,不易察觉,一旦发现,会给患者及家庭带来严重负面影响。通过预测患者发生高尿酸血症风险并给予及时精准的干预措施,不仅能有效贯穿“早发现、早诊断、早治疗”的三级预防体系,还能降低不良结局事件的发生。目前,国内外关于高尿酸血症风险预测模型的研究较多,但公开发表的预测模型性能和临床适用性仍待进一步验证。因此,本研究通过系统评价国内外健康筛查发生高尿酸血症风险预测模型的相关文献,旨在为高尿酸血症发生风险预测模型的应用、优化以及针对性预防提供参考依据。
1 资料与方法
1.1检索策略 检索The Cochrane Library、PubMed、Web of Science、维普、万方和知网数据库,检索关于健康筛查发生高尿酸血症风险预测模型的研究,检索时限为建库至2021年12月10日。英文检索词包括hyperuricemia、uric acid、gout、prediction model、early-warning、risk prediction、risk assessment、risk stratification、risk score、nomogram、predictor;中文检索词包括高尿酸血症、高尿酸、痛风、预测模型、预测因子、列线图、风险预测、风险评分、风险评估、早期预警、危险分层。具体检索策略以PubMed为例。见图1。
1.2纳入和排除标准 纳入标准:(1)研究对象:年龄 ≥18岁的健康体检者;(2)研究内容:高尿酸血症风险预测模型的开发或验证研究;(3)研究类型:队列研究、病例对照研究和横断面研究。(4)结局指标:发生高尿酸血症;(5)文献语言:中文或英文。排除标准:(1)未建立高尿酸血症风险预测模型的研究;(2)未描述模型构建过程或方法的研究;(3)无法获取全文;(4)会议论文等非正式发表的文献。
1.3数据提取 由2名研究者独立筛选文献、数据提取及文献质量评价。如果存在异议,则由第3位研究人员参与决定。数据提取包括:文献研究信息,国家,研究设计,结局指标,统计方法,模型名称,因子个数,预测因子,样本量,模型性能等。
预测模型的预测性能评估主要是根据区分度和校准度两个重要的维度[5]。区分度代表预测模型区分最终事件是否会发生的能力,最常用的评估指标是受试者工作特征曲线(receiver operating characteristic curve,ROC)下的面积(area under curve,AUC)的值。如果AUC>0.80,则认为该模型区分度极佳,如果AUC>0.75,则认为该模型非常好,如果AUC>0.70,则认为该模型区分度好[6-7]。校准度(Calibration)也是评价风险预测模型的一个重要指标[8],代表疾病风险模型预测未来某个个体发生结局事件概率准确性的重要指标,即模型预测与实际发生风险一致程度,校准度好,代表预测模型的准确性高,校准度差,则代表模型有可能高估或低估疾病的发生风险[8-9]。
1.4文献质量评价 文献质量评价:采用PROBAST工具[10-11],根据研究对象、预测因子、结果和统计分析4个领域中相关20个问题进行文献偏倚风险的评估,适用性则由研究对象、预测因子和结果3个领域进行判断。文献偏倚风险问题的判断标准为每个问题采用“是/可能是”、“可能不是/不是”或“没有信息”进行回答;文献适用性的判断标准为每个问题采用“低适用性风险”、“高适用性风险”、“不清楚”进行回答。
偏倚风险与适用性整体性评价:只有每个领域被评为“低风险”,则才将整体视为“低风险”;只要某个领域中被评为“高风险”,则将整体视为“高风险”;若某个领域被评为“不清楚”而同时其他领域都为“低风险”,则整体为“不清楚”。
2 结果
2.1符合标准的研究及特征 通过检索初步得到1 960篇文献,去重后获得1 818篇文献,其中中文573篇,英文1 245篇。阅读题目和摘要筛选出210篇文献,根据纳入排除标准最终纳入14项研究(图2)。表1总结纳入研究的主要特征。该研究系统评价包括29个预测模型。本系统评价共纳入638 539例健康体检筛查者。7项研究[12-18]是针对2个及以上高尿酸血症风险预测模型的建立及模型间比较,5项研究[13-15,18-19]对高尿酸血症风险预测模型特别关注性别。12项研究[12-17,19-24]设计类型为横断面研究,仅2项研究[18,25]为队列研究。

表1 纳入文献基本特征
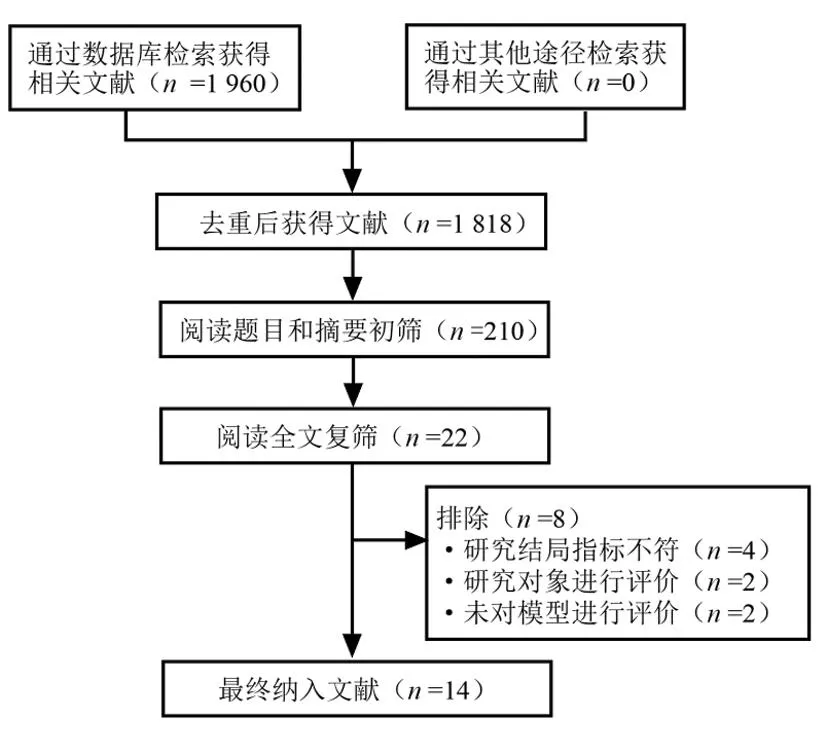
图2 文献筛选流程
符合标准的14项预测模型中,最终纳入模型中的预测因子个数为4~24个,预测模型中预测因子主要分为6类,包括人口统计学资料、人体形态特征、生化检查、治疗、现病史和生活习惯方式,共52个预测因子。模型输入特征中出现频次最高的前5位分别为身体质量指数(n=16,30.77%)、年龄(n=12,23.08%)、甘油三酯(n=9,17.31%)、性别(n=9,17.31%)、总胆固醇(n=8,15.38%)。
2.2文献偏倚风险和适用性评价 文献质量评价采用的工具是PROBAST,其评估的内容主要包括偏倚风险评价和适用性评价。14项研究对象和预测因子的偏倚风险均较低,但7项研究在结果领域偏倚风险较高,纳入研究在统计分析领域偏倚风险均较高。其主要内容如下:(1)7项研究[12-13,15,19-20,22,24]将连续型变量转化为分类变量;(2)4项研究[15,17,22,24]尚未按照PROBAST对缺失值进行处理;(3)4项研究[13-14,20-21]采用单因素分析筛选预测因子;(4)14项研究[12-25]均尚未对数据中出现的复杂性问题进行报道;(5)11项研究[12,14-19,21-24]尚未完整评估模型性能;(6)5项研究[12,15,19,22,24]缺乏模型开发的内部验证;(7)8项研究[12,14-15,17,19-20,22,24]在模型开发后未报告最终模型计算公式和最终的预测模型。研究进行适用性评价,多数研究的适用性为低偏倚风险。具体评价结果见表2。
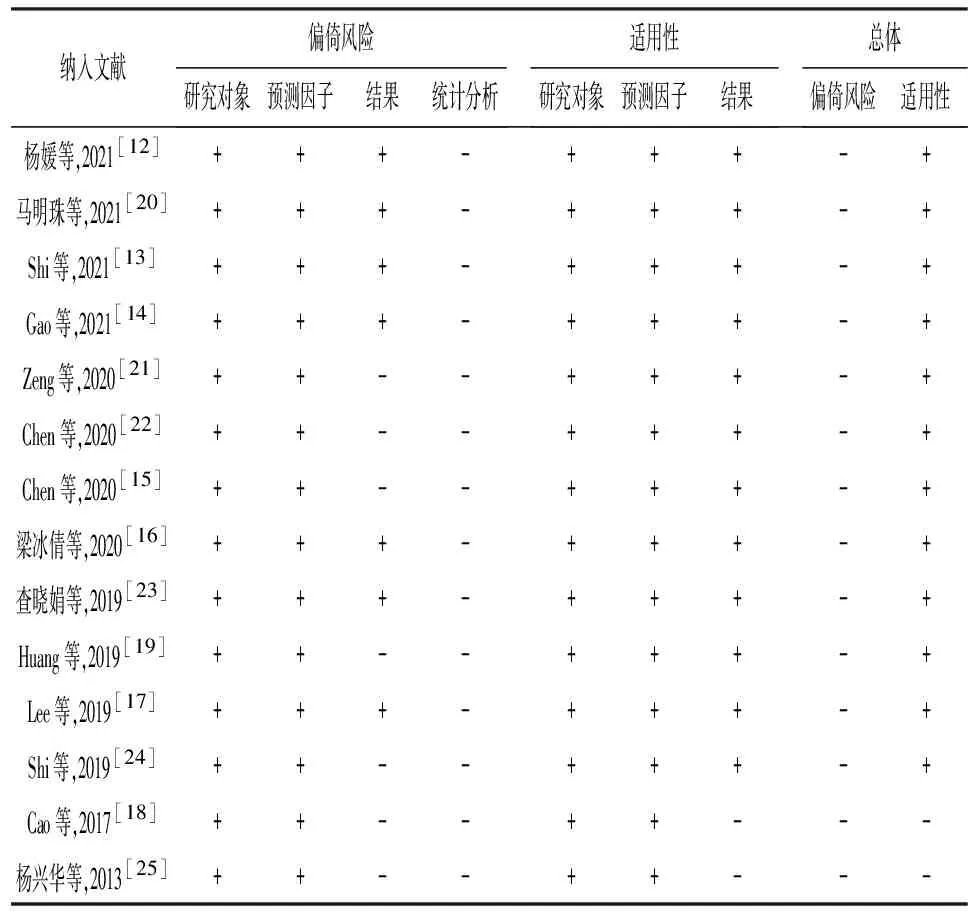
表2 PROBAST评价结果示意表
2.3模型的统计方法 本研究14项研究中12项研究[12-14,16-21,23-25]属于开发模型,3项研究[15,22,24]属于增量更新模型。模型构建的方法新颖多样,其中5项研究[13-14,16-17,21]构建高尿酸血症风险预测模型为非参数模型采用机器学习的算法,其中出现频次最高的方法为随机森林,共3项研究[14,16-17]。本研究中模型建立主要方法是Logistic回归,共12项研究[12-17,19-20,22-25]。4项研究[13-14,20-21]是采用单变量分析方法筛选风险预测模型的预测因子。见表3。

表3 高尿酸血症风险预测模型样本量、训练及模型性能
2.4预测性能 14项研究[12-25]开发模型研究均报道区分度,ROC曲线下面积(AUC)取值范围在0.512~0.827,经过验证后模型的AUC有4项[13,18,21,25]研究报告,其取值范围在0.764~0.814,表明这些模型区分度存在不同程度的差异。4项[13-14,16-17]研究是模型同模型之间的性能比较,但有11项研究[12,14-19,21-24]开发预测模型均未报告预测模型校准度。在模型验证方面,在14项高尿酸血症风险预测模型中,进行内部验证模型有8项[13,14,16-18,20,21,23],其中有2项研究[20,23]采用Bootstrap重抽样方法,有3项研究[13-14,21]采用随机拆分法,其比例有8∶2、7∶3或者2∶1,有3项研究[16-18]采用交叉验证方法,包括简单、10折和5折。有1项研究[21]采用空间验证方法进行外部验证。14项研究最终模型呈现方式也不尽相同,有3项研究[13,20,23]以列线图方式呈现,有1项研究[25]采用的是风险等级方式呈现,并给出高尿酸血症发病概率的计算公式。见表3。
3 讨论
高尿酸血症风险预测模型具有较好的预测性能,但总体偏倚风险较高,本系统评价共纳入14项研究,分别报告高尿酸血症风险预测的参数化模型与非参数化模型之间的比较。10项研究[13-15,19-25]经过验证模型的报告中AUC均>0.7,这表明模型区分度好,仅1项研究[21]AUC>0.8,这表明模型都具有出色的辨别力。但本研究纳入研究偏倚风险均较高,偏倚风险高主要原因在研究对象和分析领域。分析偏倚风险高的原因如下:(1)研究设计局限,缺乏前瞻性队列研究和随机对照试验等高质量研究。12项研究[12-17,19-24]在模型开发研究设计为横断面研究。(2)因子筛选方法过于单一。4项研究[13-14,20-21]采用的是单因素分析进行预测因子的筛选,2项研究[17,24]尚未对筛选预测因子的方法进行描述,容易造成模型拟合度不足。(3)数据的复杂性缺乏考虑。14项研究[12-25]尚未对数据的复杂性进行阐述,可能对读者方面会降低可读性。(4)模型性能的评价缺乏标准化。11项研究[12,14-19,21-24]未评估预测模型校准度,仅评估模型区分度,这会造成模型准确度降低,模型可能会高估或低估疾病的发生风险。(5)缺乏模型开发的内部验证。5项研究[12,15,19,22,24]未对风险预测模型进行内部验证导致模型拟合优度欠考虑。(6)7项研究[12-13,15,19-20,22,24]将连续型变量转化为分类变量,造成预测模型数据信息的损失,导致预测模型准确性欠佳,导致模型的偏倚增高。因此建议研究人员以后进行高尿酸血症风险预测模型的开发、验证或更新研究时,应该参照PROBAST工具对自己研究方案进行设计或进行临床预测报告时使用TRIPOD声明[26]书写报告。
高尿酸血症风险预测模型预测因子分析,纳入模型中的预测因子个数为4~24个,预测模型中最终预测因子可归纳为6个类别,分别为人口统计学资料、人体形态特征、生化检查、治疗、现病史和生活习惯方式。模型中出现最多的5个预测因子分别为:身体质量指数、年龄、甘油三酯、性别、总胆固醇。研究表明,身体质量指数是作为肥胖判断的“金标准”,而肥胖是发生高尿酸血症的影响因素[27]。年龄在高尿酸血症的影响中反而是更小年龄的风险越高[13]。性别作为高尿酸血症的影响因素之一,有12项高尿酸风险预测模型男性发病率要高于女性,一方面可能是由于女性体内雌激素多,可以帮助肾脏加速尿酸的排泄,从而减少尿酸水平[13];另一方面可能是男性与女性饮食习惯的不同,而男性更偏爱高嘌呤饮食和饮酒等不健康的生活习惯[28]。甘油三酯、总胆固醇是反应血脂水平的重要指标,而血脂指标异常同高尿酸血症间是正相关关系[29]。利用这些预测因子可以做好健康科普,可以让民众认识到做好健康生活方式的重要性。身体质量指数、甘油三酯、总胆固醇3个为可控性预测因子,而临床预测模型中加入可控性预测因素则会使临床预测模型的推广更加具有临床意义。因此本研究针对高尿酸血症风险预测模型对普通大众可以进行切实可行的健康教育,落实“预防先行”。
模型统计方法分析,4项[13-14,16-17]高尿酸血症风险预测模型比较类研究中可见3项研究[14,16-17]在相同数据源采用2个及以上机器学习算法和传统Logistic回归比较,前者预测性能更佳,而有1项[13]研究是分类树和传统Logistic回归之间的比较,后者略优。虽然目前机器学习方法在临床上得到广泛推广,但Logistic回归作为一种经典的建模方法有其特定优势,且目前针对预测模型的方法尚无最佳推荐,因此,在进行风险预测模型建模时,应该尽可能多地去尝试多种建模方法,从而寻找预测性能好且操作性强的最佳预测模型。
高尿酸血症风险预测模型的外推性探讨,近年来,风险预测模型是目前临床上广泛关注的焦点。但根据2019年后的12项研究[12-14,16-21,23-25],可见高尿酸血症风险预测模型尚处于发展阶段。虽然10项研究[13-15,19-25]经过验证模型的报告中AUC均>0.7,表现出良好的预测潜力,但是仅1项研究[25]中报道高尿酸血症风险预测模型外部验证。曾有研究[30]表明风险预测模型缺乏严格的外部独立验证的情况,使模型可能提供具有误导性的高预期风险预测。随着近年来临床预测模型的热潮,越来越多疾病相关临床预测模型被建立,而高尿酸血症风险预测模型也不例外,但是这些模型均未进行外部验证,导致这些模型在应用价值上存在缺陷,难以将模型推广到临床上进行使用。
本系统评价的局限性:(1)本系统评价纳入语言为中文或英文,可能存在发表偏倚;(2)本系统评价纳入研究的研究设计不足,多为横断面研究,缺乏前瞻性队列研究;(3)本系统评价研究缺乏内部验证和外部验证,虽然部分研究有提及验证队列,但是并未详细阐述采用的方法且这些研究均未进行外部验证,研究的推广性局限。
这项系统评价共纳入14项研究,研究表明目前建立高尿酸血症风险预测模型正处于蓬勃发展阶段,且当前构建的高尿酸风险预测模型具有良好的预测准确性,但是,这些模型的研究尚缺乏校准度和外部验证,导致目前这些模型存在不同程度的不足,难以在临床上推广应用。因此针对未来高尿酸血症风险预测模型相关研究应仔细考虑当前存在的不足及时进行修正,并且建议研究人员紧跟时代先进的统计技术和严格遵守临床预测模型TRIPOD报告进行设计临床模型,同时未来期待基于前瞻性队列研究的高尿酸血症风险预测的开发和验证模型,以期为临床提供质量佳、可推广的高尿酸血症风险预测模型。
猜你喜欢
保健医苑(2022年1期)2022-08-30
速读·下旬(2021年11期)2021-10-12
中老年保健(2021年4期)2021-08-22
大东方(2019年12期)2019-10-20
中医眼耳鼻喉杂志(2019年2期)2019-04-13
科学与财富(2017年22期)2017-09-10
商情(2017年1期)2017-03-22
中国中医药现代远程教育(2014年11期)2014-08-08
疑难病杂志(2014年12期)2014-04-16
中国中医药现代远程教育(2014年17期)2014-03-01
