
基于改进InfoGAN的字体多风格融合模型
2024-03-25 01:58:26陈芯芯王江江
大连民族大学学报 2024年1期
陈芯芯,王江江
(大连民族大学 a.计算机科学与工程学院; b.大连市汉字计算机字库设计技术创新中心辽宁 大连 116650)
汉字是一种内涵丰富、外观多样化的字符系统,由于汉字的形状与书写风格多样,对汉字多风格特征抽取后融合难度较大。在完成字体图像多风格迁移融合学习过程中,并不需要关注图像的所有特征,只需要关注字体图像的风格特征,此时如果可以把字体的风格特征从整体维度中解耦融合出来,就能更好地控制生成效果。InfoGAN[1]的设计目的就是将这些杂乱无章的特征清晰化规律化,通过解耦方式将多风格特征融合出来以控制图像的生成。
多风格字体融合生成技术研究意义重大,Yunjey Choi等人[2]提出了多个域之间图像转换的StarGAN模型,以解决生成过程中图像域的可拓展性和鲁棒性较差问题;李金金等人[3]提出了IBN-Net,将实例标准化和批标准化结合形成残差网络的基础模块,实现了多种风格域的无监督字体风格迁移;Xiaoxue Zhou等人[4]在多尺度内容和风格特征融合的基础上,构建了一个风格传输网络,可以同时完成多个字体的风格迁移;陈丹妮等[5]提出了一种SSNet网络,结构网络和语义网络负责源域字体特征的提取,可提高生成多风格汉字图像的质量;Jianwei Zhang等人[6]提出了一种结构语义网(SSNet)的汉字排版生成方法,该方法利用结构模块中解开的笔画特征,语义模块中预先训练的语义特征来生成多风格目标图像;Licheng Tang等[7]提出了一种通过学习细粒度的局部样式和空间对应关系的内容和参考字形,使用交叉关注机制关注参考字形中局部样式和细粒度样式表示的方法,生成多风格样式融合的字体图像。
本文通过改进深度学习的现有模型多风格融合出生成字体图像的关键风格特征,通过控制多风格融合出的关键风格特征,进行不同字体风格特征的融合。
1 改进的InfoGAN特征多风格融合模型
本文InfoGAN[1]是在传统的生成对抗网络(GAN)基础上加入了一个额外的噪声向量,可以用来融合输入图片的多风格特征。通过将噪声向量分解为多个部分,每个部分对应于输入图片的不同特征,可以使生成器生成更多样化的图片。
具体来说,InfoGAN的生成器输入由三部分组成:噪声向量(Latent Code)、条件向量(Conditional Code)和分类向量(Class Code)。其中,噪声向量和条件向量是原始GAN中的输入,分类向量是额外加入的向量。在训练过程中,分类向量是由判别器预测得到的,用于指导生成器生成具有特定类别的图片。通过对噪声向量分解,可以将其分成两部分:一个部分用于控制输入图片的全局特征,例如位置、角度等;另一个部分用于控制输入图片的局部特征,例如颜色、纹理等。这样,生成器就可以根据噪声向量的不同部分生成具有不同全局和局部特征的图片。
本文在InfoGAN原有基础上,修改了输入向量的维度,增加了通道注意力模块,使其可以融合出更多字体图像的相关特征,针对大小写英文字母的网络模型如图1。
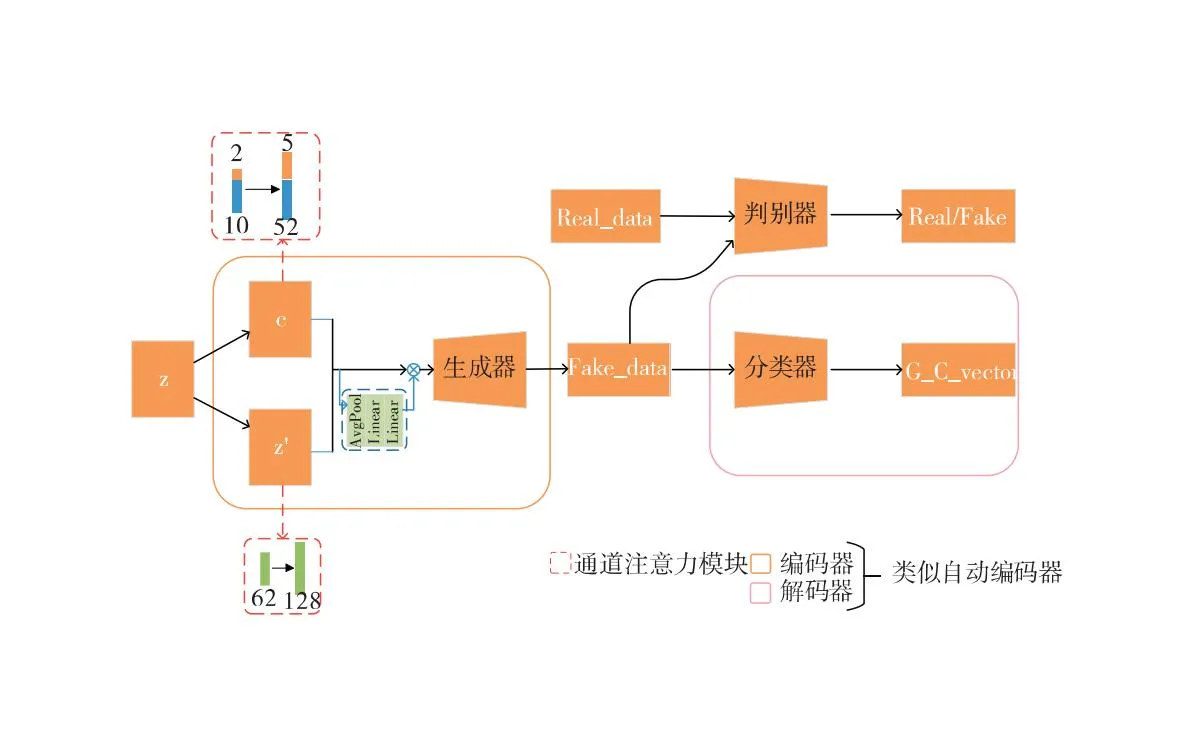
图1 改进的InfoGAN特征多风格融合网络模型
输入向量的“固定”部分包含离散和连续两部分,针对52位大小写英文字母数据集,本文将离散的潜码数保持原模型的1位不变,离散潜码的维度由10维改为52维,连续潜码数由2位变为5位;针对中文数据集,选取常用的500个汉字图像,将离散的潜码数保持原模型的1位不变,离散潜码的维度由10维改为500维,连续潜码数由2位变为5位。添加的通道注意力模块由一个自适应的平均池化层和两个全连接层组成。具体的网络结构见表1。
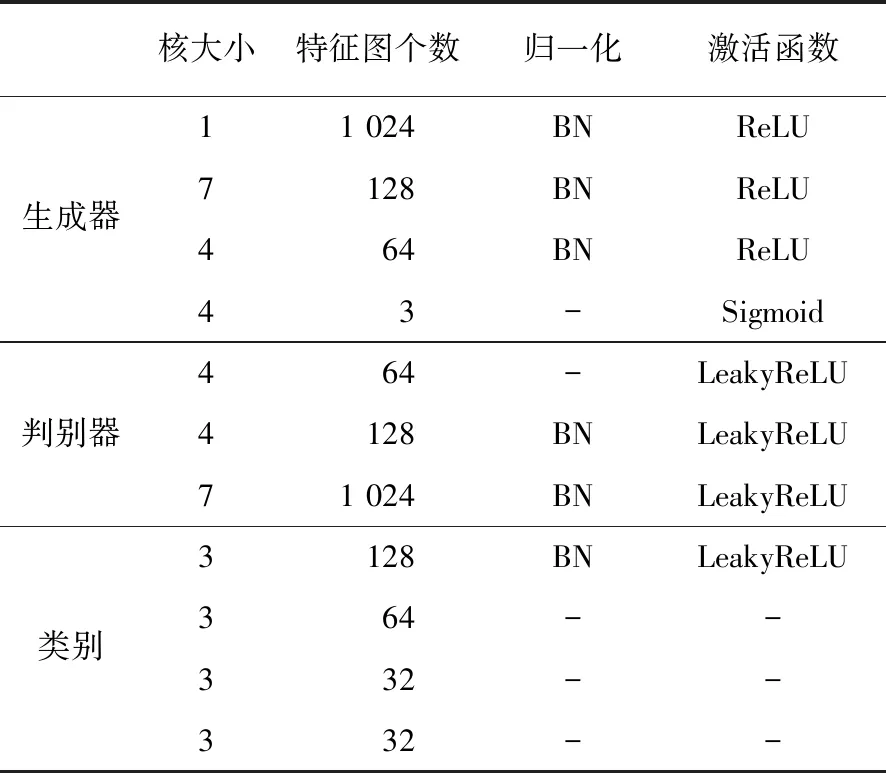
表1 改进的InfoGAN网络结构
1.1 字体图像特征多风格融合
基于InfoGAN的多风格融合的核心是分离特征或者提取特征。神经网络中的神经元以某种方式单独学习完整的概念,一个神经元可能学会特定的物体,而不明显依赖于其他神经元。通常,学习到的特征往往是混杂的,它们在数据空间中以一种无序而复杂的方式被编码。如果这些特征是可以分解的,那么这些特征就更容易理解,就可以更方便的使用这些特征进行编码如图2。

图2 InfoGAN的特征解耦示意图
改进的InfoGAN可以最大化相互信息以用来可学习表示,分离离散的和连续的潜在因素从而扩展到复杂的数据集,并且不需要太多训练时间。
InfoGAN可以通过无监督的方式学习到数据的高层语义特征,并且可以通过控制隐变量来生成具有不同特征的数据。其中生成器的输入被分成了两部分:随机噪声Z和由多个隐变量构成的Latent Code、c,即可解释的隐变量。其中,c有先验的概率分布,可以是离散数据,也可以是连续数据,用来表示生成数据的不同特征。通过改变离散特征表示(Categorial Latent Code),可以生成不同种类的字母或汉字。通过改变连续特征表示(Continous Latent Code),可以生成不同风格的字母或汉字。
1.2 通道注意力模块
基于CNN的通道注意力[8]是一种注意力机制,它可以根据每个通道的重要程度,来增强有用的特征,减弱无用的特征。
本文的通道注意力模块如图3。具体来说,输入一个H×W×C的特征F,首先,对每个通道的特征图分别进行全局最大池化和平均池化,得到两个1×1×C的向量。然后,用一个共享的两层全连接网络把这两个向量非线性变换成另外两个1×1×C的向量。其次,把这两个向量加起来并用一个Sigmoid激活函数,得到一个1×1×C的权重系数向量Mc。最后,将Mc乘以输入的特征F,得到一个新的特征。
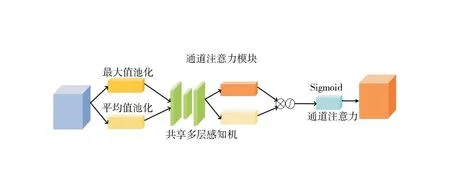
图3 通道注意力模块
1.3 损失函数
为了保证生成图像的生成质量和细节特征,本文设计了五种损失函数,模型训练时使用不同损失函数的线性组合。
Dversarial Loss[9]:最终的优化目标是让生成器Ladν最小,判别器Ladν最大,对抗损失Ladν如公式(1)所示:
Ladν=Ex∈pdata[logD(x,y)]+Ez∈pinput[log(1-D(G(x)))]。
(1)
Self Rebuilding Loss[10]:为了保证字体图像编码和解码过程中没有信息丢失或模型引起失真,改进的InfoGAN模型应具有自我重建的能力,即能够根据编码器提取的结构和风格信息重新生成原图像。自重建损失Lrec如公式(2)所示:
(2)
Consistency Cycle loss[11]:由于InfoGAN采用无监督训练方式,生成的增强图像可能会丢失原始图像的结构信息。因此,采用了循环一致性损失,以保证增强前后图像的结构尽量相似,具体如公式(3)所示:
(3)
Consistent Style Loss[12]:为了生成的清晰和失真图像与原图保持了相同的风格,以便风格特征提取更一致,引入了风格一致性损失,具体公式如(4)所示:
(4)
Consistency Structure Loss[13]:为了让生成图像与原图像的结构更一致,还加入结构一致损失来强化生成前后的结构特征一致性,其具体公式如(5)所示:
(5)
1.4 评价指标
为了验证本文提出的模型的性能,通过以下三个评价指标进行定量分析。
(1)均方根误差是衡量预测值与真实值之间的偏差差距。RMSE的值越小,表示预测模型的精度越高。其中x表示汉字字体生成网络生成的融合图像,y表示期望目标汉字字体图像。其计算公式如(6)所示:

(6)
(2)内容相似度是通过VGG19网络的分类器提取两张图像的高级特征,这些特征之间的欧氏距离越小,两张图像的SIOC越高。
dF(F1,F2)=
(7)
根据上述高级特征向量之间的欧氏距离可得内容相似度如公式(8)所示:
(8)
(3)风格相似度是通过卷积层得到特征图组成的Gram矩阵,Gram矩阵之间的欧氏距离越小,两张图像的风格越相似,风格相似度评价标准可根据计算特征之间的相关性 构建Gram矩阵,比较两张图像的Gram矩阵可以体现风格损失的情况。
dG(G1,G2)=
(9)
根据上述Gram之间的欧氏距离可得风格相似度如公式(10)所示:
(10)
2 实验及实验结果分析
2.1 实验数据集与实验环境
本文使用Adam优化算法来训练生成器和判别器,设置批处理大小为4,初始学习率为0.000 2,从GB2312字符集中选取了10个数字和52个大小写英文字符,构成了西文数据集,从GB2312字符集中选取了常用的9 169个中文汉字构成了汉字数据集。
本文的实验环境采用Intel Xeon(R)CPU E5-2620 v4@2.10 GHz×32处理器,64 GB 内存,配备2张Tesla K40C显卡,在Ubuntu 18.04操作系统下,配置Python 3.6.5、深度学习框架PyTorch、Keras,使用CUDA9.0和CuDNN实现GPU加速。
2.2 实验结果分析
本文将训练数据分为西文数据集和中文数据集两部分,分别进行训练和测试。西文数据集包括41 600张训练集和10 400张验证集,中文数据集包括24 000张训练集和6 000张验证集。
中文数据集多风格融合的汉字的粗细如图4。InfoGAN的优点是它不需要任何监督信息,而是自动地发现数据中的潜在结构和变化因素。
本文在InfoGAN模型中加入条件变量,使得生成器模型可以针对不同的条件生成不同的风格图片。部分不同西文和中文风格融合后的效果图如图5。中文融合部分的实验效果是用不同的字体从不同的方面进行融合。

图5 中西文多风格融合示例图
2.3 实验方法对比
本文对比了VAE[14]、Beta-VAE[15]和InfoGAN等特征多风格融合方法生成字体图像的质量和多样性如图6。从图中可以看出本文提出的方法在字形、纹理、风格等融合方面均略好于其他方法。

图6 不同方法对比实验示例
此外,通过定量指标或定性指标来评估不同模型的表现见表2。在两组字体图像中,RMSE指标比VAE平均低1.00个百分点,比Beta-VAE平均低1.02个百分点,比InfoGAN平均低1.34个百分点;SIOC指标比VAE平均高0.76个百分点,比Beta- VAE平均高1.12个百分点,比InfoGAN平均高0.48个百分点;SIOS指标比VAE平均高0.83个百分点,比Beta-VAE平均高1.01个百分点,比InfoGAN平均高1.07个百分点。说明本文方法生成的字体融合图像与参考图像的均方根误差最小,模型预测精度最高;内容相似度和风格相似度最高。通过这些实验结果,可以证明本文提出的方法具有较强的特征解耦能力和图像多风格融合能力。

表2 定量评价
2.4 消融实验
为了评估该模型的效果和探究其内部机制,进行了消融实验。使用改进的InfoGAN模型,在200种字库和9 000张字体图像的训练集下进行训练。对比了使用CAM融合和不使用CAM融合两种方式的效果差异。结果表明,改进后的模型能够更好地保留不同汉字书法风格的特征,并生成更加自然、流畅的汉字书法风格。比较原始的InfoGAN模型,具有更好的多风格融合效果。模型改进前后的部分对比示例图如图7。

图7 模型消融实验示例图
加入CAM模块的消融实验定量分析见表3。从表中数据可以看出加入CAM模块的改进是有效的。
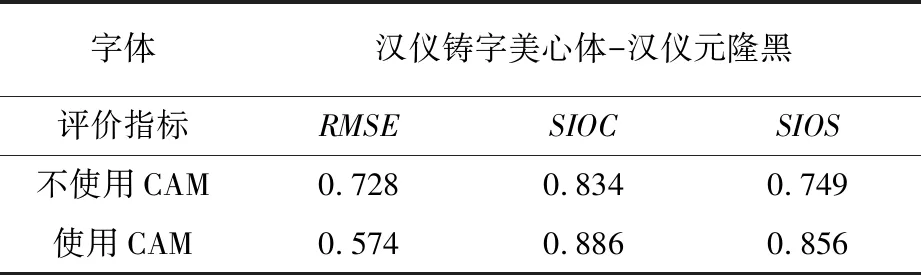
表3 模型消融实验定量评价
3 结 语
通过改进的InfoGAN模型。对不同字体的特征进行提取,将这些特征分解为不同的子空间,即多风格融合。然后再将这些特征进行融合,生成新的字体。因此,可以生成大量具有不同风格的字体,且生成的字体与原始字体的特征关系可以被保留,因此生成的字体质量较高。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
四川工商学院学术新视野(2021年3期)2021-11-05 07:24:58
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
娃娃乐园·综合智能(2020年2期)2020-03-12 10:30:28
人间(2016年24期)2016-11-23 18:48:44
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
现代计算机(2016年11期)2016-02-28 18:35:14
新高考·高二数学(2015年11期)2015-12-23 18:17:44
小雪花·成长指南(2014年10期)2014-10-31 18:10:08
山西大同大学学报(社会科学版)(2014年6期)2014-01-22 06:09:30
