
基于自注意力机制与词汇增强的中文医学命名实体识别
2024-03-21 02:25罗歆然李天瑞
计算机应用 2024年2期
罗歆然,李天瑞,贾 真
(西南交通大学 计算机与人工智能学院,成都 611756)
0 引言
医学命名实体识别(Medical Named Entity Recognition,MNER)是医学知识抽取的一项基础任务,旨在从医学文本中识别特定的命名实体,如药物、疾病、检查和医疗设备等。MNER 技术对于医学信息的自动化处理和分析具有重要意义,在许多医学自然语言处理(Natural Language Processing,NLP)下游任务中发挥重要的作用,如医疗信息检索[1]、医学知识图谱构建[2]和智能医疗问答系统[3]等。
相较于通用领域的命名实体识别(Named Entity Recognition,NER),MNER 任务存在医学实体的复杂嵌套问题,例如:疾病实体“大肠杆菌肠炎”内层嵌套了部位实体“大肠”、微生物实体“肠杆菌”“杆菌”,疾病实体“肠炎”,实体内部嵌套的多层实体使MNER 在众多序列标注文本中难以探测实体边界信息。在将医学实体映射到特征向量空间时,由于存在未登录词(Out-Of-Vocabulary,OOV)的问题,无法得到含有医学语义信息的向量。比如,“十二指肠溃疡”可能会被切分,其中“十二”被作为数字映射到数字特征向量空间,从而造成语义偏差。MNER 的实体嵌套和语义偏差问题来自实体边界难以正确划分和缺乏医学相关的语义知识。因此,MNER 需要结合医学领域的语言特点和先验知识,采用合适算法提高实体识别的准确性。与英文不同,中文文本序列由单个字符构成,通过标点符号划分句子语义,缺乏分割单词的清晰边界和带有语义信息的单词词干。因此,从输入表示的角度,中文NER 可分为基于分词的方法、基于字的方法和基于字词的方法。基于分词的方法[4-5]先使用分词工具将句子分割为单词,再将这些序列进行实体识别,但分词错误会积累大量噪声,不适合中文MNER 任务高精度的需求;基于字的分割方法[6-7]虽然性能较好,但缺少单词附带的整体语义信息,当面对医学领域的复杂嵌套实体和未登录的专业术语时,该类方法的泛化能力还有待提升。
针对上述中文NER 的限制,Zhang 等[8]首次提出了将词汇信息集成到字符序列中的栅格结构(Lattice-LSTM)。如图1 所示,该结构将一个文本序列与一个单词词典匹配,通过拓展长短期记忆(Long Short-Term Memory,LSTM)网络,使用额外的通路连接潜在单词的开始与结尾字符之间的存储单元。栅格结构为中文NER 带来显著的效果提升,在单个字符中融合与该字符有关的潜在单词可以丰富字符的语义特征,有效缓解单词边界难以探测的问题,有利于医学文本中复杂嵌套实体的识别。但也存在一些不足:1)栅格结构为有向无环图的拓展,且不同字符之间添加单词节点数不一致,限制了每次只能处理一个字符,模型无法在GPU(Graphics Processing Unit)中并行化计算。2)由于LSTM 的单向顺序性,每个字符只能获取以它作为结尾的单词信息,对于单词内部的字符不具备词汇信息的持续记忆能力,造成严重的信息损失。
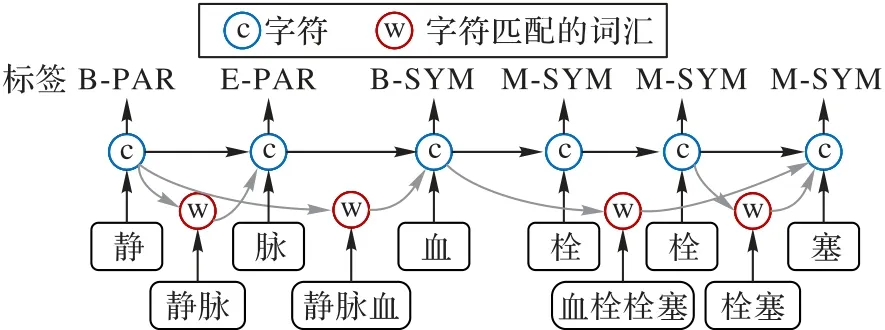
图1 Lattice-LSTM的结构Fig.1 Architecture of Lattice-LSTM
以图1 为例,栅格结构将单词信息“血栓栓塞”编码到“塞”中,但是对于“血”“栓”“栓”这3 个内部字符却无法有效获取单词信息,而“血栓栓塞”的语义和边界信息对这3 个字符正确识别为B-SYM、B-SYM 和M-SYM 标签起到重要的辅助作用;同时,栅格结构中某些单词对中文NER 任务无效,这些需要被抑制的单词信息通常与上下文相关,如文本序列中的单词“血栓栓塞”能区分“静脉血”不是实体,而“静脉”是标签为PAR 的实体。3)栅格结构只适配于LSTM 结构,可迁移性差。
受文献[9-10]中将栅格结构的输入集成到Transformer[11]结构的启发,针对中文医学文本的语言特点和栅格结构的不足,本文提出一种融合注意力机制的自适应词汇增强模型AMLEA(Attention-based Model of Lexicon Enhanced Adaptively),通过基于双线性注意力(Bilinear Attention)机制的词汇适配器(Lexicon Adapter,LA)将词汇信息集成到文本序列中的每个字符中,并使用自注意力(Self-Attention)机制编码词汇适配器中不同单词之间的信息交互。本文的主要工作如下:
1)将基于有向无环图的栅格结构转换为线性的字词对序列(Charactor-Word Pair Sequence),并利用Transformer 结构中全连接的自注意力机制对序列中的不同词汇输入单元建立依赖关系,使每个字符所匹配的不同单词之间直接交互信息,以抑制无效单词并激活具有边界和语义信息的单词。
2)在词汇适配器中设计双线性注意力为每个字符动态计算不同潜在单词的权重,提取相关程度高的匹配词修正字符向量的语义偏差,提高中文医学命名实体识别的性能。
3)设计AMLEA 与各基线模型的对比实验,实验结果表明,所提模型可以有效缓解中文MNER 中实体嵌套和未登录词识别歧义的问题,同时将预训练模型BERT(Bidirectional Encoder Representation from Transformers)[12]用 于AMLEA 的字符编码,显著提高模型的识别精度。
1 相关工作
NER 的研究方法包括基于规则和字典的方法、基于传统机器学习的方法和基于深度学习的方法。其中,基于深度学习的方法[13-14]是目前主流的研究方向。本文模型主要研究如何将词汇信息高效、准确地作为先验知识集成到字符中以缓解中文MNER 的实体嵌套和OOV 问题,所以分别介绍了基于字词的中文NER 和MNER 的相关研究。
1.1 基于字词的中文命名实体识别
单词中的边界和语义信息能有效增强基于字的中文NER 模型,将词汇信息集成到字符信息的主流方法主要有两类。
第一类方法是在动态的栅格结构中融合词汇信息。Zhang 等[8]在LSTM 结构中增加了一个额外的词汇存储单元对潜在的单词进行编码,巧妙地将词汇信息与字符嵌入兼容;Gui 等[15]提 出LR-CNN(CNN-based Chinese NER with Lexicon Rethinking)模型,采用卷积神经网络(Convolutional Neural Network,CNN)解决LSTM 无法并行计算的问题,通过Rethinking 机制缓解模型中高层词汇冲突的情况;Li 等[10]设计了一种将相对位置编码和词汇信息融合至Lattice 的结构,并利用Transformer 实现了GPU 的并行计算。这类方法通常可迁移性较差,并且受制于栅格结构的特殊性,不能充分利用词汇信息,导致大量词汇表征损失。
第二类方法是将栅格结构转换成图结构,并使用图神经网络(Graph Neural Network,GNN)编码。Gui 等[16]提出了一种基于GNN 的词级特征融合方法,利用图网络携带的全局信息捕获字符之间的非顺序依赖关系,采用递归聚合机制解决中文单词识别歧义的问题;Sui 等[17]提出了基于协作的图网络(Collaborative Graph Network,CGN),结合三种模式的图注意力网络(Graph ATtention network,GAT)提取特征,解决Lattice-LSTM 无法获取词汇内部信息而造成的特征损失问题。然而,序列结构对中文NER 任务有着重要的支撑作用,因此这类图网络通常需要LSTM 作为底层编码器感应时序信息,模型结构较复杂,并且图构建也需要耗费大量计算资源。
1.2 医学命名实体识别
在MNER 领域中,Li 等[18]利用Lattice-LSTM 融合词汇信息,并增加嵌入语言模型(Embeddings from Language Models,ELMo)学习电子病历中的上下文信息;Ju 等[19]通过动态叠加扁平NER 层,用学习到的内层实体信息更新外层实体的识别,以此解决医学实体嵌套的复杂问题;罗凌等[20]将汉字的笔画序列输入ELMo 改进字符输入特征单一的问题,然后构建基于多任务学习的网络充分利用数据信息;Xu 等[21]采用一种有效的字符串匹配方式将疾病字典和疾病字符配对,提出了一种结合字典注意力层的BiLSTM-CRF(Bi-directional Long Short-Term Memory-Conditional Random Field)模型;吴炳潮等[22]利用BiLSTM-CRF 网络识别跨领域共享的实体块信息,再通过基于门机制的动态融合层将源领域的信息集成于目标领域的共享实体块,并在CCKS 2017 数据集上验证了模型的有效性;Li 等[23]提出了一种融合词汇和字根特征的BERT-BiLSTM-CRF 模型,利用BERT 模型增强中文临床记录文本的上下文语义信息;文献[24]中将字向量输入双向门控循环单元(Bi-directional Gated Recurrent Unit,BGRU),学习上下文特征,再利用注意力机制捕获关键语义表征,与本文不同的是,该方法没有引入词汇信息等外部知识,注意力仅用于字向量的特征提取,没有利用双线性注意力赋予词汇相应的权重。以上结合BiLSTM-CRF 的模型并没有利用BiLSTM(Bi-directional Long Short-Term Memory)对字符编码的上下文特征交互词汇信息或是直接采用Lattice-LSTM 结构,融合词汇的方式容易引入大量噪声,降低了MNER 模型的识别性能。
本文提出的AMLEA 在不影响原字符序列结构的情况下,在充分利用词汇信息的同时能抑制与字符无关的词汇,很好地克服了现有词汇融合模型中的不足,并且所提模型便于根据不同的医学细分领域选择合适的词典进行自动匹配,与现有的预训练模型BERT[12]也能很好地兼容,从而提升了模型面对海量复杂医学文本的鲁棒性。
2 模型构建
本文提出的中文医学命名实体识别模型AMLEA 的总体架构如图2 所示,该模型由特征表示、特征编码和标签解码三部分组成。首先,将字嵌入输入BiLSTM层学习医学文本中字符序列的上下文特征;然后,将输出的字符向量与经过自注意力层的词汇向量组成字词对序列并输入词汇适配器,实现字词信息的融合并得到隐藏层输出;最后,将隐藏层的输出输入到CRF(Conditional Random Field)解码层进行序列标注。
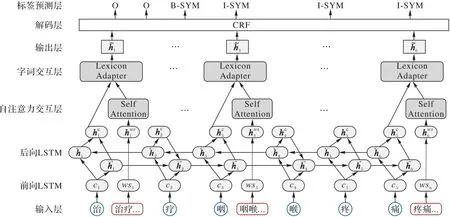
图2 AMLEA的总体架构Fig.2 Overall architecture of AMLEA
2.1 字符编码层
LSTM 是循环神经网络(Recurrent Neural Network,RNN)的一种变体,为了解决RNN 在反向传播时带来的梯度消失和梯度爆炸问题,以及难以建模句子中的长距离依赖关系的问题,在RNN 的基础上增加了门控单元控制信息的更新、存储和传递。
LSTM 由3 个门控单元和1 个记忆单元ct构成,门控单元分别为遗忘门ft、输入门it和输出门ot,具体的计算过程如式(1)~(6)所示:
其中:Wx、Wh、b是需要学习的网络参数,σ表示激活函数Sigmoid,Xt表示当前时刻的输入向量,遗忘门ft控制上一时刻的记忆单元ct-1需要遗忘的信息总量,输入门it控制当前时刻的候选状态应该存储的信息量,输出门ot控制当前时刻的记忆单元ct需要向外界输出多少信息。
但是LSTM 只能获取句子单向的字符序列,即t时刻的字符能学到t-1 时刻字符携带的语义信息,但t-1 时刻的字符不能学习后文段落的信息。为了提取文本的上下文特征,本文采用BiLSTM 编码字符向量,它由前后双向的链式LSTM 结构组成,最后拼接两个LSTM 单元的前向和后向隐藏层输出信息。在t时刻BiLSTM 的隐藏层状态为ht=,嵌入后的字向量经过BiLSTM 编码后可以得到维度为的输出向量其中dm为单个LSTM 的隐藏层神经元个数。
2.2 注意力机制
当一个滑动窗口包含多个单词时,若采用全连接的神经网络学习它们的特征,会使参数的学习变得异常复杂。注意力机制可以将文本序列进行特征降维,然后编码为固定长度的向量,以便输入后续的全连接层。注意力机制通过计算句子中每个字符的权重给予模型针对性的学习指导,给出了3个计算参数查询Q、键K和值V。这3 个参数由输入向量X与矩阵W相乘得到,通过对X的线性变换加强模型的拟合能力,从而训练矩阵W,使模型学到更多该文本序列的语义信息。
注意力函数的计算如式(7)所示,计算过程可以总结为3 步。首先,将嵌入层的输出向量X分别与维度为dk的矩阵W做乘积运算,得到3 个参数Q、K和V。然后,将Q和K相乘计算两者的相关性,经过Softmax 归一化处理后得到注意力矩阵;除以的目的是降低字符间的权重方差,避免训练过程中因权重较小造成的梯度消失问题。最后,根据得到的权重对V加权求和,得到具有混合关系的向量表示。
词汇间利用注意力机制进行信息交互的过程如图3 所示,其中字母A、B、C 分别为单词“甲肝”“肝病”“甲肝病”的向量表示,图中计算以“甲肝”为例,展示了该单词与匹配到字符“肝”的潜在单词间的权重关系,从而建模词与词之间的依赖关系。多头注意力机制(Multi-Head ATTention mechanism,MH-ATT)实质上是多次计算单头注意力机制,然后将其结果进行拼接,目的是学习向量在不同语义空间的表示。面对复杂的医学文本,需要对某一特征进行多维度的学习,不同的注意力矩阵使模型从多个角度理解文本信息,赋予模型更深层次的句意理解。
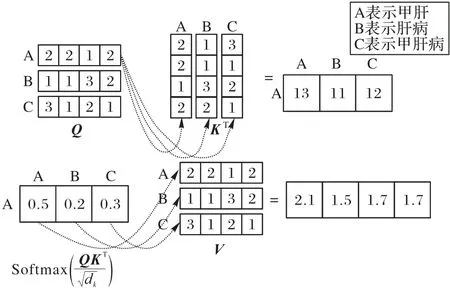
图3 自注意力计算过程Fig.3 Computational process of self-attention
2.3 字词对序列
由于中文的特殊性,一个句子通常由单个字符序列构成,为了给每个字符融入词汇信息,本文将字符和它匹配的词汇组成一个如图4 所示的字词对序列。
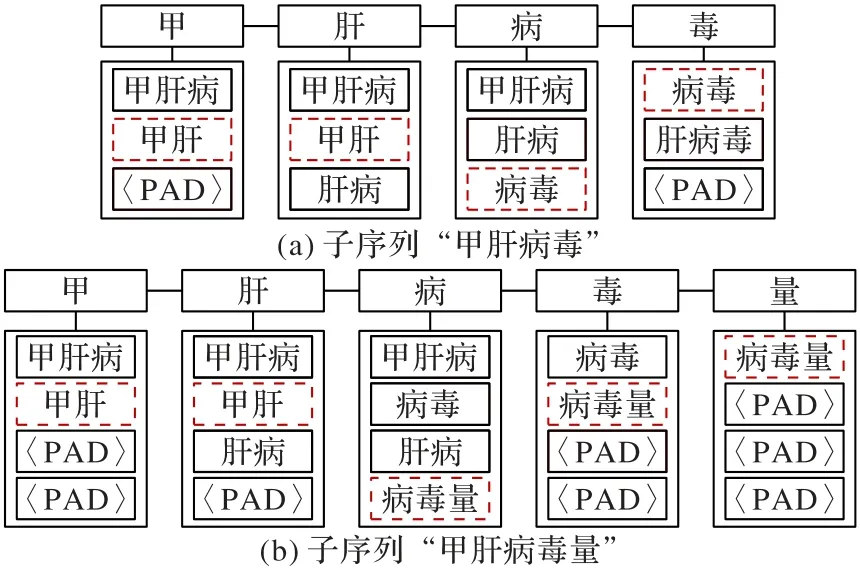
图4 字词对序列Fig.4 Character-word pair sequence
本文中字词对序列的构建过程为给定一个字符数为n的中文句子sc={c1,c2,…,cn}以及中文词典D,通过将字符序列与词典D进行匹配,搜索句子中所有潜在单词。具体地,本文利用词典D构建了单词前缀树(TrieTree),然后遍历句子中所有的字符子序列,通过前缀树查找对应的字符子序列,将潜在的单词归纳至每个字符。如图4(a)所示,对于一个字符子序列“甲肝病毒”,可以匹配到4 个潜在单词:“甲肝”“甲肝病”“肝病”和“病毒”。接着,将每个匹配到的单词分配给它所包含的每个字符,如单词“肝病”会被分配给组成该单词的字符“肝”和“病”。本文将第i个字符ci匹配到的所有单词构建成单词序列wsi={wi1,wi2,…,wim},其中m=4 表示单词序列的窗口大小,用特殊值“填充长度不满m的单词序列。最后,组合每个字符和其指定的单词序列,将中文句子转换为一个字词对序列scw={(c1,ws1),(c2,ws2),…,(cn,wsn)}。
2.4 词汇适配器
对于字词对序列scw,每个位置都包含字符级特征信息和单词级特征信息。与现有的多信息融合模型一致,本文的目标是将词汇信息融入字符。受近期关于对预训练模型BERT[12]进行多模态信息融合研究[25-26]的启发,在中文大规模语义建模过程中,通过在字符编码中设计一种适配器融入词汇、字形、拼音和偏旁部首等多元特征,在预训练过程中能对不同领域的文本进行有效的信息增强。本文利用词汇适配器直接将每个单词序列的词汇信息注入它对应的字符。
词汇适配器以一个字符和匹配的单词序列作为输入,对于下标位置为i的字词对(ci,wsi),本文将字符和单词序列中的每个单词通过嵌入层获取字向量和词向量并记为其中表示词向量的集合,字向量以及潜在单词序列中第j个单词的词向量的计算如式(8)和式(9)所示:
其中ec(⋅)和ew(⋅)分别表示预训练的字向量和词向量查询表。
如图4(a)所示,对于一个字符,在特定的上下文环境中可能与多个单词匹配,然而不同单词提供的语义和边界支持通常有着较大差异,如单词“甲肝”和“病毒”的重要性更高,图中标红虚线框的单词表示需要获得更多的关注,因为它们是该子序列的正确分词形式。而单词“甲肝病”和“肝病”的优先级较低,所以需要抑制这些单词对字符增强特征的作用,以免指导模型学习很多错误的训练参数。同时,如图4(b)所示,对于同一个字符,在不同上下文语境中需要关注的单词信息不同,这种差异性可以通过匹配的单词序列中单词的内部交互较好地反映,如字符“病”和“毒”匹配的单词序列在增加单词“病毒量”后,需要关注的单词就从“病毒”变为“病毒量”。本文首先通过自注意力机制进行单词内部的信息交互,将单词向量映射到新的语义空间,随后通过一个字到词的双线性注意力映射,从所有匹配的单词中选出最相关的单词。
如图5 所示,本文使用与Transformer 编码层相同的自注意力结构,对于第i个字符对应的单词序列向量,通过使用多头注意力机制实现不同单词间的信息交互,然后使用逐位置的前馈网络(Position-Wise FeedForward Network,PWFFN)对每个单词信息编码,同时引入两层残差网络(Residual Network,ResNet)以防止模型退化,并使用层归一化(Layer Normalization,LN)进行规范化处理,最终将单词序列映射到一个新的语义空间主要计算过程如式(10)和式(11)所示:

图5 Transformer编码器结构Fig.5 Structure of Transformer encoder
其中多头注意力机制中头的数量Nhead=8。
本文将位置为i的字词表示向量输入到如图6所示的词汇适配器中,整个计算过程如式(12)~(15)所示,其中字向量每个词向量为了对齐两种表示向量的维度,引入非线性变化对词向量进行维度对齐:
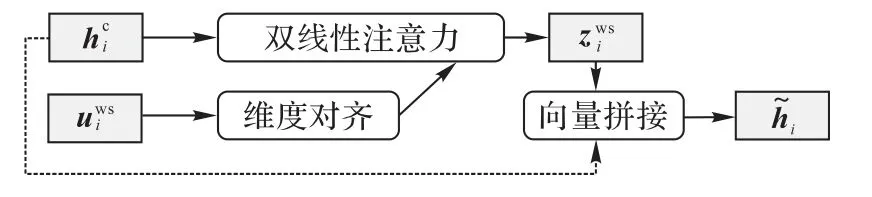
图6 词汇适配器结构Fig.6 Structure of lexicon adapter
为了从所有匹配的单词中选出相关度最高的单词,将位置为i的单词表示定义为其中接着通过双线性加权方式计算字符与每个单词的相关性权重ai∈Rm:
最后,本文将加权得到的词汇信息向量与字符序列拼接,得到最终的表示向量
2.5 CRF解码层
在通过词汇适配器结合词汇信息和字符信息后,将序列的最终表示形式输入到CRF 层进行序列标注。具体地,将经过BiLSTM 层和注意力交互层的编码向量输入CRF 结构,计算每个标签之间的转移概率。如式(16)所示,对于标签序列y={y1,y2,…,yn},概率分布定义为:
其中:第一项是交叉熵,第二项是正则化项,λ是L2正则化权重,Θ表示模型参数的集合。
3 实验与结果分析
3.1 数据集
本文实验数据来自CHIP2020 发布的中文医学文本实体关系抽取数据集,该数据集共有实体11 类,分别为疾病、药物、检查、部位、预后、症状、流行病学、社会学、手术治疗、其他治疗和其他,其中“其他”类实体用于“疾病”和“其他”类实体进行就诊科室、阶段和预防三类关系的抽取。本文将提供的用于训练的数据按照7∶1.5∶1.5 划分为训练集、验证集和测试集,其中训练集用于迭代训练过程中的各种模型参数;验证集用于超参数的调优,以进一步提高模型的整体性能;测试集用于衡量模型训练的效果,判断预测标签与真实标签的出入。经过数据预处理后,共计得到14 339 条数据,数据集的划分情况及各实体种类的统计信息如表1 所示。

表1 数据集统计结果Tab.1 Dataset statistical results
3.2 实验方案
3.2.1 评价指标
本文采用命名实体识别任务常用的评价指标精确率P(Precision)、召回率R(Recall)及F1 值(F1)作为本次评估模型的标准。其中精确率表示在所有被预测的医学实体中正确预测出的实体占比,召回率表示在已标注的医学实体中被正确预测出的实体占比,F1 值是为了兼顾这两种评价指标提出的衡量标准,是两者的调和平均。一般地,设E={e1,e2,…,em} 为拥有正确标签的实体集合,E'={e'1,e'2,…,e'm}为被模型预测出的实体集合,NT=|E∩E'|代表预测正确的实体数,|E|代表标注实体的总数,|E'|代表预测实体的总数,则P、R、F1的计算过程如式(18)~(20)所示:
3.2.2 实验设置
本文字向量和词向量的维度设置为200,字向量使用均匀分布初始化,在下游任务的训练过程中,字向量和词向量与模型参数一起更新。词向量使用腾讯中文词向量,共计包含200 万预训练词向量,设置每个字符最多融合3 个词向量,与字符进行适配后,自动构建了一个含有58 621 个单词的词典。
在超参数的选择上,采用Adam 优化器进行训练,其中CRF 层的初始学习率为3 × 10-4,模型其余参数的初始学习率为6 × 10-5。为了防止训练过拟合,将权重正则系数λ设置为0.05,在BiLSTM 层设置比例为0.15 的Dropout,在词汇适配器和自注意编码层中设置比例为0.25 的Dropout,batchsize 设为16,文本序列的最大长度设置为256。
3.2.3 基准模型
本文选取Lattice-LSTM 作为实验对比的基准模型,另外选取FLAT(Flat-LAttice Transformer for Chinese NER)和基于字符的模型BiLSTM-CRF、ATT-BiLSTM-CRF、BGRU-att-CRF、CAN-NER(Convolutional Attention Network for Chinese Named Entity Recognition)验证本文方法的有效性,6 个对比模型的如下所示。
1)Lattice-LSTM[8]:该方法在LSTM 基础上增加用于存储词汇的结构,通过门控循环单元利用字符序列中的词汇信息减少分词错误。
2)BiLSTM-CRF[6]:命名实体识别中效果较好的一种通用框架,BiLSTM 能很好地学习序列结构和上下文信息。
3)ATT-BiLSTM-CRF[27]:在BiLSTM 隐藏层之后引入自注意力机制,有利于提取字符的重要特征。
4)BGRU-att-CRF[24]:将字向量输入双向门控循环单元,然后将隐藏层向量输入注意力层提取有效信息,没有引入词汇信息。
5)FLAT[10]:通过Transformer 结构将Lattice 结构平铺至字符序列,并引入了字符和词汇的位置信息。
6)CAN-NER[7]:使用具有局部注意力机制的CNN 和具有全局注意力机制的BiGRU 编码文本信息,没有引入其他外部表征。
3.3 实验结果与分析
3.3.1 模型对比实验结果分析
将本文提出的AMLEA 与6 个对比模型进行比较分析,实验结果表明,本文提出的自适应词汇增强模型具有较好的性能。
实验结果如表2 所示,比起引入了词汇信息的基线模型Lattice-LSTM 和FLAT,本文模型在精确率、召回率和F1 值上都有较大幅度的提升,F1 值达到67.96%。说明词汇适配器的引入能使字符充分利用与它相关性高的单词表征,并且BiLSTM 结构学习的上下文语义信息也能促使子词序列的正确表示,例如词汇“窦性心动过速”会将子序列“心动”的向量映射到接近“窦性”词汇向量的医学语义空间中,而不表示为其他语境中的“心动”向量。另外,本文模型与其他没有融合词汇信息的模型对比,F1 值提升了1.37~2.38 个百分点,说明本文模型能有效引入医学领域的词汇信息,相较于其他模型的词汇融合方式,可以抑制噪声词汇,避免无效单词的错误传播,进而使每个字符融合正确的词汇边界信息。最后,在兼容BERT 模型的实验中,本文使用BERT 的预训练嵌入层初始化字符向量,比较了配备BERT[12]之后的AMLEA 与普通的BERT+BiLSTM-CRF 标注模型的结果,F1 值提升了1.62 个百分点。实验结果表明,本文模型使用BERT 的预训练嵌入层有着可观的语义信息增强效果,对底层嵌入信息的利用更全面。推测原因可能是将单词与字符信息集成在同一平面上,在有效利用词汇信息的同时保留了字符序列模型中上下文依赖建立的方式,使得模型具备强大的迁移能力和拥有轻量级的参数。
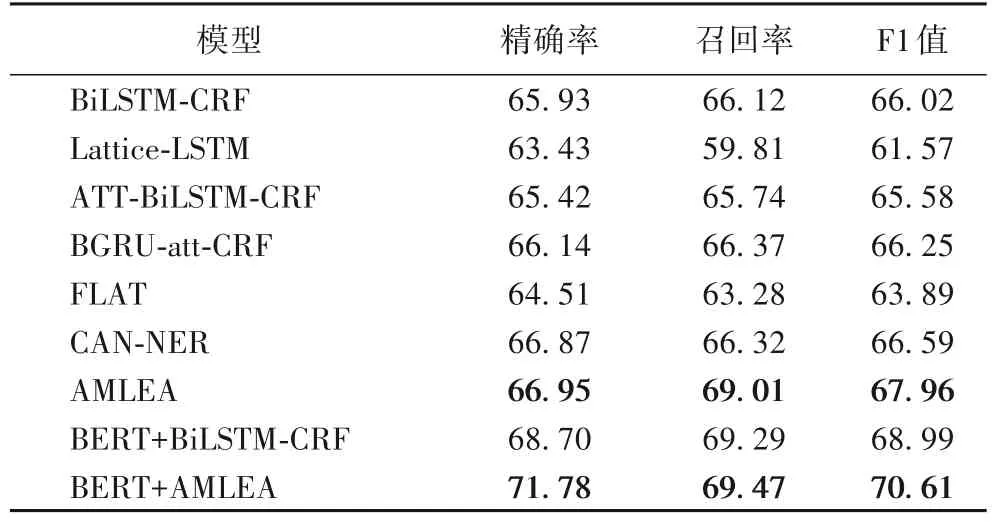
表2 不同模型的实验结果 单位:%Tab.2 Experimental results of different models unit:%
3.3.2 细粒度实体实验结果分析
为分析AMLEA 在不同实体粒度上的实验效果,本文在该数据集上列出了11 类实体的识别标签,最终细粒度实验结果如表3 所示。
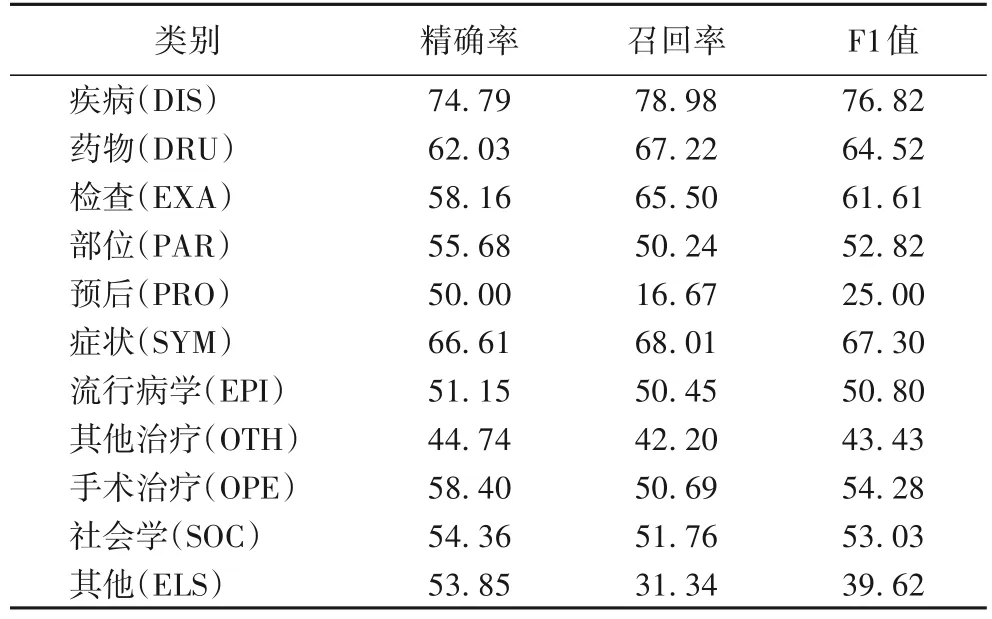
表3 细粒度实体识别实验结果 单位:%Tab.3 Experimental results of fine-grained entity recognition unit:%
可以看到,“疾病(DIS)”的F1 值远高于其余类别的实体。推测这是因为该类别实体数量占比约44%,数量较充足,字符能够匹配的词汇覆盖范围更全面,使得词汇适配器和自注意力结构能够充分训练。这一原因也体现在训练过程中“疾病”类别的拟合能力和训练速度优于其余实体类别。反观“症状”“药物”“社会学”和“检查”的实体占比约为20%、8%、8% 和7%,F1 值分别为67.30%、64.52%、53.03% 和61.61%,说明较少的数据量会导致匹配的词汇信息较少,在字词交互阶段训练不充分,因此性能没有“疾病”类别的效果好。但“社会学”的F1 值远低于同等数量级的实体类别,甚至持平数量占比分别为3%和2%的“部位”和“手术治疗”这两类实体。经过研究发现,“社会学”这类实体涵盖范围较为广泛,包括“纤维蛋白的沉积”这类的发病机制和“自主神经调节功能差”这样的病理生理,模型容易将这类实体归类到“症状”之类的实体,通过查看“社会学”的召回率和精确率发现,它的召回率比精确率要低些,但“症状”“药物”和“检查”的召回率比精确率高1.4~7.34 个百分点,充分说明了“社会学”这类实体的多样性及所在语境的复杂情况。同样,“手术治疗”“其他治疗”“流行病学”和“部位”的数占比分别约为2%、3%、3%和3%,所以在相同的参数设置中,这4 类的实体识别效果欠佳,数量分布不均容易导致模型欠拟合,从而不能充分的融合词汇信息。
3.3.3 词汇注意力效果分析
本文对字符和与它匹配的潜在单词进行了注意力权重可视化分析,本文选取了测试集中的一句话,“3.大肠杆菌肠炎常发生于5~8 月,病情轻重不一”作为案例分析。其中疾病命名实体为“大肠杆菌肠炎”,与它对应的子序列有“大肠”“肠杆菌”“杆菌”“大肠杆菌”和“肠炎”。如图7 所示,可以直观地看出经过词汇适配结构的交互后,前4 个字符与“大肠杆菌”的关联性更强,后2 个字符与“肠炎”的关联性更强。由于本文的词典中并没有“大肠杆菌肠炎”的完整词汇与它对应的词向量,所以不能直接将该词标记为疾病实体,但“大肠杆菌”和“肠炎”的融入,能使字符边界的划分更加明确,并且抑制类似“肠杆菌”这样的无关词汇。
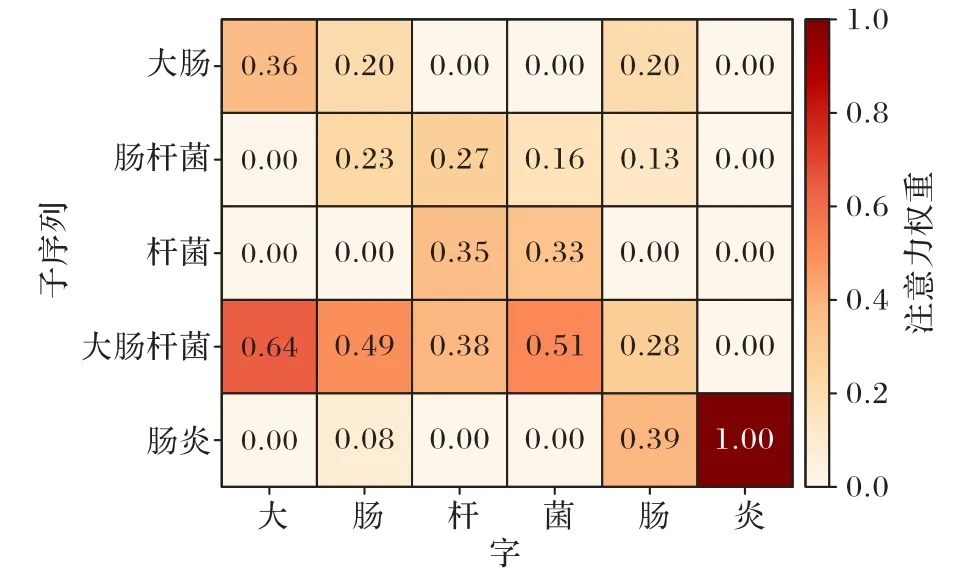
图7 注意力可视化示例Fig.7 Example of attention visualization
3.3.4 消融实验
为了探究AMLEA 中每个结构的有效性,本文对模型进行消融实验,结果如表4 所示。可以发现,在移除掉自注意结构后(w/o self-attn),模型F1 值下降0.49 个百分点,这表明通过自注意结构进行单词信息内部交互的有效性;在移除掉词汇适配器的实验中(w/o LA),每个字符匹配到的单词序列在经过自注意结构后,本文将多个单词向量逐元素相加并求平均值后,得到的词汇向量作为最终词汇表示,并与字符最终表示拼接后输入解码层,结果表明模型的性能损失为2.29 个百分点,这表明词汇适配器在本文模型中发挥了关键的作用;将词汇适配器中字符与词汇信息的结合方式从拼接变为逐元素相加并求平均值后(repl concat),模型的总体性能轻微下降,这表明拼接方式是最终结合两种信息更有效的手段,比起逐元素相加,它使得字符向量与词汇向量之间能保持一定的信息独立性。
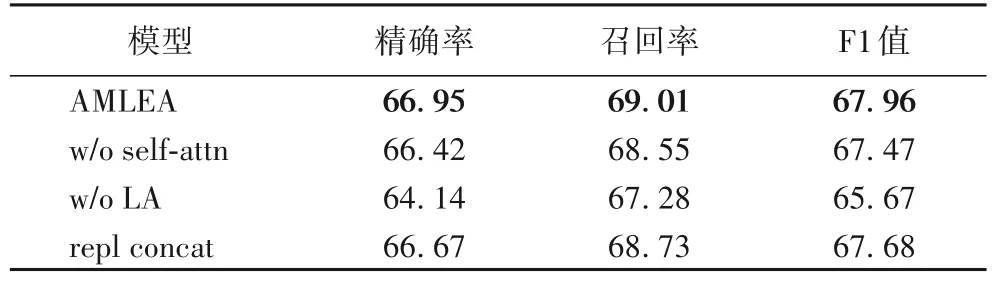
表4 消融实验结果 单位:%Tab.4 Results of ablation study unit:%
4 结语
本文提出了一种基于注意力机制与词汇融合的中文医学命名实体识别模型,将编码后的字符序列与经过自注意力层的词汇向量进行匹配,通过词汇适配器的融合后,字符被注入潜在单词中与实体最相关的单词语义信息,增强了字符的边界信息和上下文语义信息,缓解了中文医学实体识别中嵌套实体边界检测模糊化和未登录词识别歧义的问题。但本文方法也存在一定的局限性:一方面,细粒度实验表明该方法的模型效果很大程度取决于数据量的大小和标注的准确性;另一方面,该方法选取的是医学领域的数据集进行测试,构建一个高质量的医学领域词典是模型性能提高的关键。后续的工作会收集大量医学语料和已有的中文医学预训练模型,构建专业性的医学词典来提高领域实体识别的精确率。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30
小雪花·成长指南(2022年1期)2022-04-09
小学生学习指导(低年级)(2019年12期)2019-12-04
中国外汇(2019年18期)2019-11-25
电子制作(2019年19期)2019-11-23
少儿美术(快乐历史地理)(2018年7期)2018-11-16
哲学评论(2017年1期)2017-07-31
传媒评论(2017年3期)2017-06-13
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
