
决策树算法在获取连续流反应器动力学参数中的应用
2024-03-14 09:06:34蒋雄
江西化工 2024年1期
蒋雄
(九江天赐高新材料股份有限公司,江西九江,332599)
0 引言
随着精细化工行业竞争加剧,企业开始使用连续反应器替代间歇反应器[1]。使用反应动力学数据设计连续反应器能有效避免间歇反应器直接转化连续反应器时因浓度分布及停留时间分布不同带来的放大效应[2]。不同化学反应的反应动力学千差万别,而影响反应速率方程的因素众多,因此根据不同化学反应本身特点进行预判随后选择不同的测试方法和测试环境符合企业需求[3,4]。
常用的反应动力学的分析方法有积分法、微分法、半衰期法、作图法、孤立法[5]。常见的动力学测试体系使用间歇釜作为容器,微通道反应器[6]及量热仪[7]因其等温环境而被作为新型的测试容器。在研发人员开展的实际工作中,经常出现反应动力学测试误差大、数据不可信等问题。因此,在方案设计前确定好最佳的反应动力学测试方法和实验设计成为研发人员关注的方向[8]。
当前,关于化学反应动力数据处理的软件研究较多[9,10],但涉及反应动力学方案设计阶段的处理软件鲜有报道。当下,基于机器学习开发的各种机器学习算法正在各行各业铺展开来,其中,决策树[11]、聚类[12]、朴素贝叶斯[13]、支持向量机[14]、随机森林[15]等算法已经基本达到商业化要求和特定场景的商业化水平。其中,决策树算法尤其适合结论多特征多分类问题,将化学反应动力学需要考虑的因素与机器算法结合起来,形成一套基于机器学习开发的动力学反应测试建议系统,在用户进行化学反应动力学测试前,基于已知反应条件推荐最合理的动力学测试方法,这样,既可以减少化工领域研发人员的学习成本,也可以提升企业研发及工艺改进的效率。
1 基础模型
1.1 软件界面
反应动力学涉及反应的本征性质,与一些表观现象之间没有强相关性。先对反应动力学进行拆解,细化成多个不同的维度进行表征,再按照多个维度的表述与动力学分析方法固有的偏差产生点进行比较,可得到具体的化学反应不能运用的动力学分析方法及测试环境;随后,可通过排除法建立起反应本征性质与动力学测试方法和测试环境之间的联系。对于少量的特征与反应动力学分析方法之间产生的数据对,可以直接记忆或者使用excel 等表格进行匹配,但是对于大量的反应特征与动力学分析方法之间产生的数据,则无法通过人工的方法获取,借助计算机学习算法是一条可行的路径。
如下图1 所示,基于反应动力测试系统的运作逻辑,本文设计了一套软件界面用于用户输入关于反应的基本信息,从反应的方程式入手绘制反应网络,以作为反应机理研究的判据。对于复杂反应,反应物网络是否完整直接决定了进行动力学测试时是否会产生不可控因素。
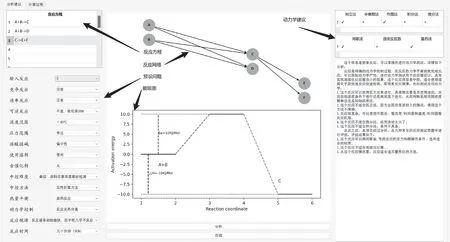
图1 动力学推荐系统界面
随后,在界面内强调有14 个关于反应信息的基础问题,并对每个问题预设2~4 个答案,这样就会产生大量不同的组合选项以应对实际情况下的使用需求。在界面中间的图层是反应物网络绘图区和反应能级图,从反应物网络图中可以清晰地表达反应网络和反应复杂程度,而从能级图中可以看出主反应路线出现的能量变化和反应活化能之间的关系,用以对反应建立基础的印象,选择适合的热量管理/时间管理规则。
在界面右侧,集成了两个表和一个结论区,图表区内清晰表达了在这种情况下建议使用的数据处理方法和使用的动力学测试方法。下方的结论区针对反应的机理,反应的控制规律,反应中控难度,反应使用的数据处理方法及动力学测试方法的具体使用限制进行了文字说明,能指导测试人员了解动力学测试规律。
如图2 所示,简单反应需要研究反应速率,反应受温度、压力、催化剂、中控的影响及表观的反应时间、放热、速率快慢、分离要求以确定反应需要的测试方案和数据处理方法。复杂反应需要考虑反应机理,先明确反应存在竞争、连串、可逆或者组合形式,再将复杂反应转化为简单反应以确定具体的数据处理方案和测试方法。只有竞争反应时需分别测试两反应的动力学过程,了解反应的温度/浓度条件,以及在不同条件下能否控制为一个特定产物。如果通过反应温度/浓度控制可以有效控制,即可转化为简单反应处理,反之需按表观反应动力学进行处理。
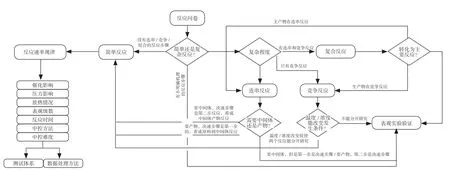
图2 动力学测试软件工作程序
对于串级反应,需明确反应是需要中间体还是产物。对于需要中间体的反应判断指标是中间体能否稳定存在;对于需要产物的反应判断标准为是否有中间体残留。如果反应需要中间体,且表观现象中间体能稳定存在,则一般决速步骤就是中间体继续反应步骤,整个反应只需要进行原料到中间体的简单反应考虑,并遵照上面简单反应的流程来询问并给出建议;如果反应需要产物,中间体有残留,则反应决速步骤是第二步。判断标准是中间体到产物这一段反应为简单反应或对其进行表观动力学测试。
最后,对既有连串又有平行反应的结构来说,需要关注产物所在的主要路线,先研究主要路线上存在的是竞争反应还是连串反应,再按照上面说的连串反应或竞争反应进行分析。在对其他副产物所在的其他反应进行分析时,按照简单反应进行研究。
1.2 动力学问题预设
企业在做反应时的普遍做法是一锅法,先合成产物再进行分离,尽可能获得更高的原料转化率,但该种方法在连续化反应器中并不适合。因此,需要收集实验中的表观实验现象进行动力学方案设计。
本文设计了14 个问题,见表1,每个问题预设2~4 个选项,用于收集反应信息,具体预设方案如下:
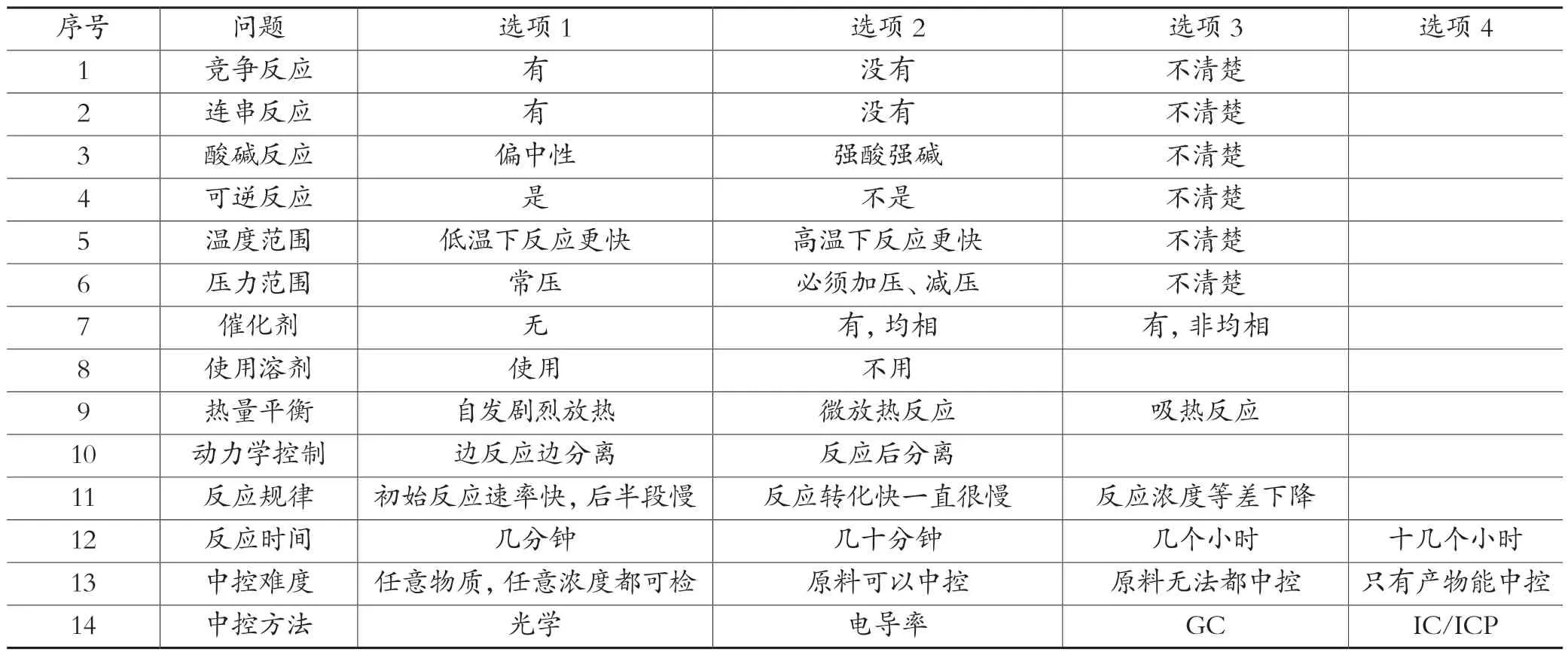
表1 预设问题一览表
通过1,2,3,4 问题对反应的复杂程度进行分析,定义竞争、连串、酸碱、可逆反应。对复杂反应而言,研究反应机理是优化反应路线、减少反应安全风险和三废产量的关键。复杂反应需要将反应中的主要反应和副反应都表达清晰,然后将绘制反应物网络作为研究反应机理的重要手段。通过对5,6,7,8,9,10,11,12,13,14 问题进行分析,主要探究反应过程规律,按照反应规律匹配适合的测试体系和数据分析方法。
2 机器学习算法规律
2.1 数据量
本文共设计14 个问题,每个问题又分别设置2~4 个不同选项,共计产生995329 项组合,根据初始数据和特定的决策依据形成3072 种结论。对于如此庞大的问题组合,如何在各个问题之间做出权衡并找到最佳的动力学测试方法或者其他的建议,必须依靠机器算法来完成。
本文使用机器迭代算法,生成上述14 个问题995329 行,25 列的初始数据库,通过判断14 个问题的答案选项,组合成后续结论项种机理/过程规律/分析能力/数据处理方法/使用测试仪器的标准选项。通过机器学习算法,对产生的数据进行学习,在用户界面返回正确的结论。本文采用数字化方法替代文字进行运算,默认0 代表任意14 个问题中的第一个选项,1 代表第二个选项,2 代表第三个选项,3 代表第四个选项。按照反应机理明确与否,反应规律和中控方法选择动力学数据处理方法。动力学处理方法决定了实验设计方案。如下表2、表3 所示。

表2 五种分析方法算法规律

表3 三种测试方法算法规律
按照反应实际情况,根据机理/规律/中控/热量/时间规律/催化综合考虑适合的测试仪器,作为实验仪器选择依据。
以上结论在确定了使用数据分析方法和测试仪器之后,由软件输出对应的文字信息提示操作者最可能的动力学测试方案。
2.2 算法选择
本文预设多个问题并给出选项,然后根据选项的结果进行判断,形成大量的数据行。就此类机器学习语言的选择而言,常见的做法是决策树/朴素贝叶斯算法/随机森林算法等。本文中数据集按照特定规则产生,结论按照选项进行判断后填充,结论和选项之间存在相关性,不存在过多异常值和噪声,三种方法在此情况下都可以解决问题。本文对三种常见方法进行模拟测试,结果如表4 所示。
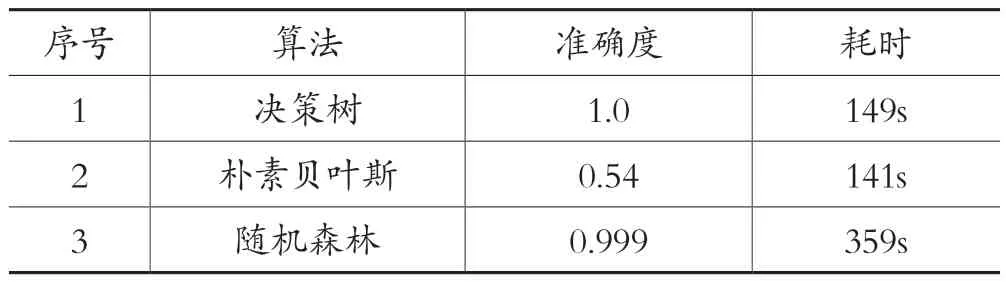
表4 三种算法模拟结论对比表
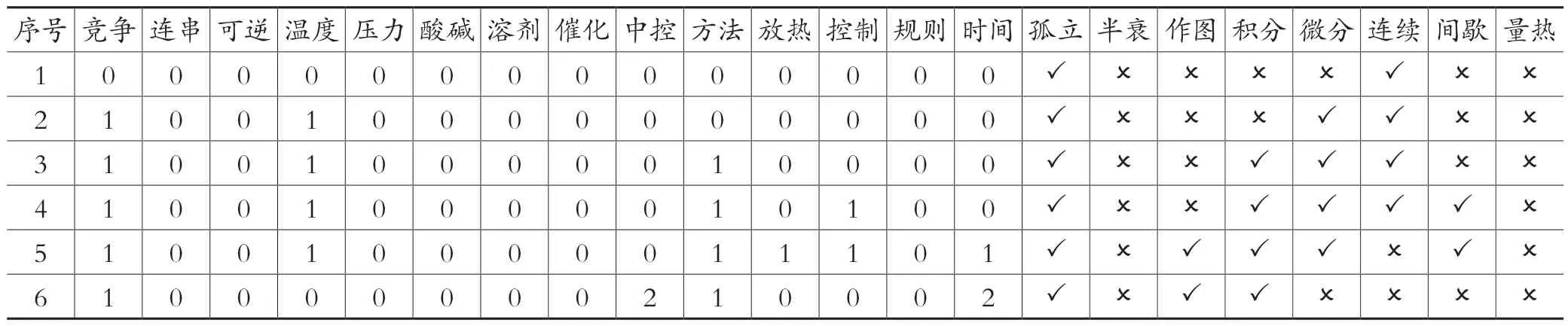
表5 随机测试输入数据结论对比表
本文使用三种算法对同一个数据集进行计算,分别评测三种算法的耗时和准确度。模型使用预训练(30%),将多模型多分类方法作为默认条件。从表4结果可以看出,决策树在准确度和耗时上是最佳的选择,能保持100%准确度和149s 的分析时间;朴素贝叶斯不适合本类问题的求算,出现0.54 的准确度,精度不够;随机森林算法在准确度上完成较好,但耗时较长。
2.3 检验结果
本文根据6 组不同情况对模型结果进行实测,用以验证动力学测试建议系统功能的完整性。从下表可以看出,随机抽取6 组不同组合,机器模型均给出相应的测试建议和结果,结果与预期结果对照,准确度为1.0,符合向研发人员推荐动力学测试的要求。
3 结论
本文通过机器设计一套动力学测试分析建议系统,对常见的反应问题进行预设,对其中问题进行定义并与最终动力学测试的数据处理方法和测试容器进行关联,产生90 余万条原始数据。通过反应方程的输入,能够自动生成反应物网络和可能的主反应能级图,以直观呈现反应复杂程度和反应受热力学控制程度,从而帮助人员确定反应规律。
通过对比机器学习决策树/朴素贝叶斯/随机森林的算法时间和准确度,确定使用决策树作为机器学习的算法,并使用二维数组处理90 余万条数据,决策树运行时间缩减为4s,整体软件运行时间少于1min。此外,通过随机进行6 组预设问题检测,可以获取准确度为1.0 的结果,从而证明该算法能够稳定运行,基本满足企业动力学初步方案设计需求。
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:58:18
中国药学药品知识仓库(2022年10期)2022-05-29 02:59:32
汕头大学学报(自然科学版)(2020年4期)2020-12-14 07:04:58
电子制作(2019年16期)2019-09-27 09:34:56
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2019年15期)2019-08-27 01:12:02
电子制作(2018年16期)2018-09-26 03:27:06
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
中国洗涤用品工业(2016年2期)2016-02-28 19:03:19
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
