
基于分布式技术的动车组车载大数据存储与检索技术研究
2024-03-13 10:20扈海军
铁道机车车辆 2024年1期
扈海军
(1 中国铁道科学研究院集团有限公司 机车车辆研究所,北京 100081;2 北京纵横机电科技有限公司,北京 100094)
近年来,随着复兴号智能型动车组的陆续上线运营,监测数据项点不断扩充,数据量不断增加。国铁集团通过动车组车载信息无线传输系统(Wireless Transit Device System,WTDS)采集动车组运行过程中的重要参数、故障数据及位置数据等实时运行数据,为国铁集团及路内用户、主机企业的相关应用提供数据支撑,保证了动车组的安全有效运行[1-4]。
动车组运营过程中,还存在大量非实时运行数据,主要有采样密度较大的运行数据、自诊断和日志数据等,是动车组故障诊断与运行维护的重要数据,以此为基础进行车辆故障预警、关键零部件性能监测以及零部件剩余寿命预测,指导运维部门对车辆子系统的预防修与计划修,辅助优化修程修制等[5]。
非实时数据到站后通过无线传输到各动车运用所,每列动车组(标准组)日均数据量为2 GB,年均数据量可达720 GB,复兴号动车组数据量更大。如何提高地面系统的数据转储和集中整体能力,统一汇集、存储、管理各车载数据,实现高密度、大容量的数据落地、存储与管理,成为我国动车组在安全运营与健康管理方面开展大数据应用面临的重大挑战[6-8]。
云计算、大数据、物联网等新兴技术的快速发展为解决上述问题提供了可能[9-10]。针对上述问题,文中从实际工程应用角度出发,结合最新分布式技术和大数据技术提出了一种支持存储、检索动车组车载海量数据的系统架构,并设计了分布式存储与检索技术,提升了数据存储能力和数据检索能力。
1 系统体系结构
分布式动车组车载大数据系统是一个可扩展的数据平台,文中采用主、子节点分布式系统架构,如图1 所示,在主节点部署数据服务器集群,汇集各动车运用所存储的非实时数据文件索引信息,并建立动车组车载数据资源目录。主节点用于实现子节点管理及配置、主节点用户查询等主要功能,起到数据服务中心的功能定位;子节点实现动车组非实时数据接收、存储及子节点用户访问等主要功能。

图1 分布式架构
分布式动车组车载大数据系统服务架构如图2所示,自下而上主要包含4 层:

图2 系统服务架构
(1)硬件设备层
动车运用所机房的服务器设备、网络设备、存储设备、负载均衡器、VPN/防火墙等硬件设备。
(2)数据采集层
通过无线端接入技术(WIFI6、AirFlash 等),将动车组非实时数据通过无线局域网发送到Rabbit-MQ 消息队列,并依据订阅的Topic 信息将数据分发给Kafka Connect 服务。Topic 主要承载动车组车载非实时数据的分发,部分数据见表1。Kafka Connect 根据Topic 信息将数据写入到对应类型的Stream 中并存储到相应的Query 中,不同Topic 信息通过Kafka Connect 存储到PostgreSQL 或Influx-DB 数据库中。

表1 Topic 信息类型(车载运行信息)
(3)数据服务层
数据层服务可分为主节点数据管理和子节点数据管理,主节点主要包括查询服务、数据存储、权限验证等进程服务,Web API 服务接收到主节点用户查询服务,对查询条件进行解析并首先访问本地高速数据存储或本地数据存储,如果查询到数据则返回给用户,如果没有查询到数据,则将发起子节点查询服务,最终从子节点返回结果数据。
(4)系统应用层
系统应用层是针对动车组非实时数据传输、存储、查询的过程系统服务,主要包括系统管理、数据处理存储服务、数据查询及检索服务功能。系统管理平台提供了管理的前端,管理人员定义动车组设备及类型、需要传递数据的属性参数,以及数据源配置、数据目的配置、报警参数配置等。通过定义动车组类型及定义需要采集的属性参数,自动生成Json 格式接口规范,所有此类型动车组通过此规范传输数据即可被平台接收和解析。激活动车组设备类型时,管理平台自动生成Rabbit-MQ 的Topic,并根据数据源配置和数据目的配置调用对应的Kafka Connect;同时管理平台会生成KSQL 脚本,并根据脚本自动在Kafka 中创建Stream 和Query。
2 系统关键使能技术
2.1 分布式存储技术
考虑到高频数据采集、海量数据存储以及快速数据检索等场景对分布式存储系统在动态高并发、存储可拓展性、数据可管理性、数据可重用性等方面的需求,文中采用关系数据库(PostgreSQL)、高速数据存储(Redis)、时序数据库(InfluxDB)和实时数据流引擎(KsqlDB)等技术构造支持分布式存储、检索动车组车载海量数据的系统架构,其中PostgreSQL 关系数据库用于各节点应用服务及数据存储功能,Redis 高速数据存储用于应用服务缓存及部分数据存储功能,InfluxDB 时序数据库用于存储动车组硬件采集的时序数据,KsqlDB 是基于Kafka 的实时数据流处理引擎。通过采用上述技术及主、子节点架构,以满足支撑动车组海量数据分布式存储与检索的需求。
动车组在运行过程中驶进某动车运用所时,利用无线通信技术将动车组在前后子节点之间产生的非实时数据快速、有效地传输到地面Rabbit-MQ 服务,后续依据订阅的Topic 信息将数据发送给Kafka Connect。由于数据种类众多,需要根据不同数据类型进行分类处理,Kafka 消息系统根据不同的Topic 分别对数据进行处理并写入相应Stream和Query 中,目的Kafka Connect 根据不同主题的Topic 对主题数据进行相应处理。处理方式主要分为两类:一类是将核心数据信息以及数据目录信息上传至主节点关系数据库中;另一类是将非实时数据存储至PostgreSQL 或InfluxDB 数据库中。
由于分布式关系数据库在面向海量数据存储时,受制于单节点存储的容量及性能限制,需要对分布式关系数据库的存储进行分片设计,常见的分片方式有哈希分片、范围分片、垂直分片、水平分片等方式,文中整体存储原则如下:
(1)对于数据量较小且数据集变化频率相对较低的数据实体采用单表单节点的形式存储,如车辆基础信息、GPS 位置基础信息、故障项信息等数据实体。
(2)对于数据量较大且数据变化频率较高的数据实体则按照节点数量进行分节点存储,按节点划分后,如果单表数据量依然较大,则可以按照时间再次进行拆分,确保各数据表数据量保持在一个合理的水平,有利于提高数据检索效率并便于数据存储拓展。
2.2 分布式检索算法设计
在动车组运行过程中,其产生的非实时运行数据分别存储于运行途径的各动车运用所节点中,具有典型的时空特性,因此动车组运行数据的检索包含时间属性、空间属性和数据属性的过滤过程。其中,时间属性表征动车组的运行时态信息,其时间区间范围较小或者仅包含某个时间采样点,由采集数据的种类和频次决定;空间属性表征动车组运行的地理位置信息,属于随时间不断变化的动态空间信息;数据属性则表征动车组静态数据以及动车组运行过程的动态数据(状态参数信息等)。
动车组时空数据集通过时间、空间和数据属性三个阶段的过滤筛选最终可以获取动车组运行数据集,动车组运行数据集的分布式检索采用如下模式进行,以从子节点检索为例,主要步骤如下:
(1)用户通过主节点服务根据业务需求发起检索需求,首先主节点加载动车组运行过程数据模型信息,根据用户输入的检索条件进行映射并生成时间属性、空间属性和数据属性等检索约束集,作为下一步检索的依据。
(2)生成检索约束集后,主节点根据空间约束条件向本地存储服务发送数据请求,未检索到结果数据,则向子节点发送数据请求,并将检索约束集信息作为数据请求参数。
(3)子节点获取数据请求后,解析检索约束集并根据时间属性约束条件筛选符合条件的数据集。
(4)子节点获取数据请求后,解析检索约束集并根据数据属性约束条件筛选符合条件的数据集。
(5)各子节点准备相关数据、分批分量多次将完整数据逐步反馈至主节点,主节点收集返回的数据并形成完整的动车运行数据集。
3 系统运行流程
通过在动车运用所建设无线端接入技术地面配套系统(包括地面基站、数据服务站点),实现将列车非实时数据传输到地面系统;在数据中心部署地面服务器汇集各动车运用所存储的非实时数据文件索引信息,并建立车载数据资源目录,供各方用户使用,整体系统的运行流程如图3 所示。
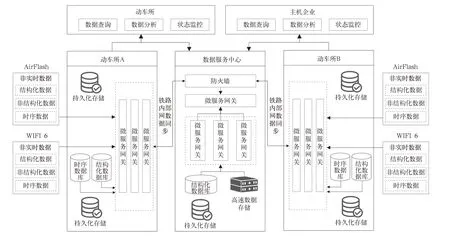
图3 系统运行架构
当动车组进入动车运用所无线覆盖区域后,能够通过无线端接入技术连入动车运用所局域网,自动实现将动车组非实时数据从车载数据中心高速传输到动车运用所数据服务站点。后续动车运用所按照自身的数据运用需求,对非实时数据进行存储、解析、运用。
各动车运用所数据服务站点通过铁路内部网络,将非实时数据文件索引信息同步至数据中心,当数据中心发起数据查询检索请求时,访问本地高速数据存储或本地数据存储,未检索到相应的数据,则依据数据文件索引信息找相应的动车运用所,并通过内部网络向对应的动车运用所数据服务站点发起数据请求。各动车运用所间的非实时数据查询请求,则以数据服务中心为中转,基于其数据目录服务,向对应动车运用所数据服务站点请求所需的数据,数据处理流程如图4 所示。

图4 数据处理流程
4 系统部署
为保证非实时数据应用的稳定性和可靠性,充分利用既有资源,提高共用性和集约型,并保证未来功能扩展的可行性,文中构建的原型系统平台提供了强大的在线水平扩展功能,无需停机维护即可实现运算节点及存储节点的增加,实现在线扩展。节点添加完成之后即可对节点进行角色的分配,新加的节点即刻投入运行。
4.1 服务配置管理
文中采用Helm 对RabbitMQ 消息队列、Kafka Connect 服务、Gitlab 等服务进行统一部署包的模板管理,各节点均可通过模板脚本参数快速完成节点服务的环境搭建及部署。通过Kubernetes 平台的Dashboard 进行资源的统一管理维护,并通过KubeView 资源可视化工具监控所有资源对象的状态和故障。
4.2 节点服务部署
数据服务中心主节点通过功能看板对各节点资源、状态进行统一监控,包括可视化展示主、子节点连接情况及各节点CPU、内存、存储等资源使用信息和功能报警。数据服务中心支持用户查询业务操作,并且可通过数据约束条件汇总查询主节点及相关子节点数据信息,数据服务中心看板如图5 所示、汇总查询结果界面如图6 所示。

图5 数据服务中心看板
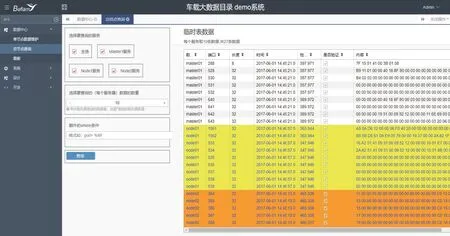
图6 数据服务中心汇总查询界面
4.3 系统性能测试
不同动车运用所保有的动车组数量不同,因此需存储数据量也有所不同。假设1 个典型动车运用所配属20 列动车组,包含10 列复兴号动车组和10 列和谐号动车组,由于非实时数据主要用于健康管理及故障预测数据建模,原始数据不必按照动车组全生命周期进行存储。假设动车运用所以1 年为周期管理非实时数据,按上文列举的动车组日均数据量进行测算,则1 个典型动车运用所存储1 年非实时数据文件所需数据存储量约为30 TB。
基于此,文中标准测试环境是由1 个主节点和6 个子节点组成,子节点用以模拟各动车运用所,各子节点默认1 个计算节点和1 个存储节点(存储容量为40 TB),各节点配置相同,节点之间采用铁路办公内部服务网络(带宽为100 Mbps)。测试内容见表2,系统性能和子节点数量的关系成负相关性,性能变化情况如图7 所示。

表2 测试内容列表
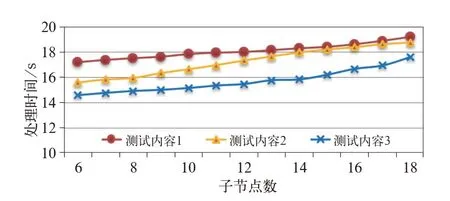
图7 子节点数对系统性能的影响
此外,对于动车组车载大数据应用来说,分布式节点的非实时数据同步时间也是较为重要的指标,因此以某系列动车组为例,单组动车组日数据量约为7 GB,数据类型参照表1,将数据均分至各个子节点,将数据文件索引信息同步至主节点,测试子节点数对同步时间的影响,测试结果如图8 所示,可见,同步时间随着子节点数线性增加。

图8 子节点数对数据索引同步时间的影响
5 结论
基于动车组车载海量数据地面系统面临的问题及实际应用场景,从系统架构方面论证了分布式系统架构的可行性,并针对应用场景的特殊性和系统技术特点,采用基于分布式技术和Kubernetes 云原生技术,设计及搭建了一种由数据服务中心主节点和各动车运用所数据服务站点子节点组成的动车组车载大数据系统,通过原型系统部署及测试,实现了支持分布式数据存储、检索及数据服务功能,验证了文中提出技术方案的可行性和有效性,为更好地对运行中的动车组进行健康管理、进一步强化动车组安全保障能力、改善运维经济性提供数据基础。
为进一步支撑动车组安全运营与健康管理的开展,深化动车组大数据的应用,在后续的研究中将继续对系统进行优化,接入更多动车组全生命周期数据。
猜你喜欢
军事文摘(2021年18期)2021-11-25
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
电脑爱好者(2020年19期)2020-10-20
海峡姐妹(2020年2期)2020-03-03
小哥白尼(趣味科学)(2019年10期)2020-01-18
电子制作(2019年13期)2020-01-14
铁道通信信号(2018年11期)2019-01-19
学苑创造·A版(2018年12期)2018-03-04
制造技术与机床(2017年12期)2017-02-02
