
基于子句抽取的文本摘要自动提取算法
2024-03-12 11:39:52朱兵兵罗勇军丁炜超
华东理工大学学报(自然科学版) 2024年1期
朱兵兵, 罗 飞, 罗勇军, 丁炜超, 黄 浩
(华东理工大学信息科学与工程学院, 上海 200237)
在如今信息数据呈指数增长时代,人们想在短时间内获得有效数据使用自动摘要技术无疑是一个比较好的选择;其中,如何从冗余、非结构化的长文本中提炼出关键信息,并且使得提炼出的信息精简通顺是一个关键问题。目前基于文本摘要自动抽取技术的自动摘要已经应用到社会各领域,如社交媒体综述[1]、新闻综述[2]、专利综述[3]、观点综述[4]以及学术文献综述[5]等。
基于生成方式,自动摘要可分为抽取式摘要和生成式摘要[6]。抽取式摘要[7]从文本中原封不动地截取一些句子作为摘要输出,其本质是转换为一个排序问题,它根据每个句子的重要性赋予其不同的分数,然后选中分数排名靠前的提取单元作为摘要。提取单元可以为句子、词组或词语,而现有方法主要以句子作为提取单元[8]。现如今抽取式摘要中的提取算法以句子为单位已经能够取得不错的效果,但仍具有以下问题:一方面,抽取出的句子存在冗余;另一方面,抽取出的句子包含了一些不关键的信息[9]。生成式摘要是在理解原文的基础上重新生成摘要,而不再以原文句子拼接形式生成摘要。目前对于生成式摘要想要得到理想的结果还是比较困难的,因为需要大量的创新和相应的工作来提升性能。
基于生成技术,自动摘要可分为基于主题模型、基于图、基于特征评分和基于启发式算法等[10]。其中,基于图模型方法的图排序算法充分考虑了文本图的全局信息,同时又不需要人工标注训练集[11]。TextRank 算法及其系列改进算法从生成方式上属于抽取式方法,其中用到的技术为基于图模型技术;仅仅使用文本自身的相关信息和文本自身的结构特点,就能够实现自动摘要的提取[12]。TextRank 算法作为一种抽取式总结方法,正是由于它不需要事先学习和训练多份文件,所以被广泛使用。
TextRank 算法本身并没有对摘要去除冗余的处理。为了提升TextRank 算法的性能,一系列改进算法被提出[11-16]。如为了去除冗余,Fang 等[13]提出了一种新的词句联合排序模型CoRank;李娜娜等[14]、汪旭祥等[15]采用余弦相似度方法;朱玉佳等[16]采用MMR 算法。为了提升摘要的准确率,徐馨韬等[11]把K-means 方法、TextRank 方法和Doc2Vec 模型相结合,提出中文文本摘要自动抽取算法(DKTextRank);黄波等[12]利用每个词的向量,结合其他语句的向量、TextRank 算法和Word2Vec 模型,提高词汇的维度。
然而,TextRank 及其系列改进算法并未有效地解决抽取式摘要所存在的冗余性问题。为此,本文提出基于抽取子句模型的文本摘要自动提取算法(PTextRank),以降低提取摘要的冗余度,并提高摘要的准确性。首先对文本进行预处理,以句号为标记把整个文章分割成单个句子集。然后通过Sinica Treebank[17]方法对句子进行句法成分分析,选择子句作为抽取单元,通过BERT(Bidirectional Encoder Representation from Transformers)构建每个子句的特征向量,然后在矩阵中存储每个子句向量的相似度。最后,将相似矩阵转换成以子句为节点,相似度分数为边的图结构,一定数量排名靠前的子句构成最终的摘要,同时图的结构中也引入标题、特殊语句等信息。本文所述的算法从比句子更细粒度的提取单元出发,将重点信息和非重点信息通过更细粒度的提取单元来区分,从而防止了冗余的内容都被抽取作为摘要的结果。
1 TextRank 及SWTextRank 算法
TextRank 算法是从PageRank 算法衍生出来的一种基于图排序的无监督方法。PageRank 算法用来衡量网页的重要性,以每个网页为节点,网页之间的联系为边构建网络图。因此,TextRank 算法将文本以句子为单位进行拆分,将每句话作为节点在网络图中进行划分,同时将句子之间的相似度作为边。通过网络图的迭代计算,可以得出每句话的重要性得分,最后选出分数较高的几句话作为最终摘要。
TextRank 算法中有权的无向网络图可表示为G=(V,E,W),其中:V为句子表示的节点,E为节点间各个边的非空有限集合,W为各边上权重的集合。假设V={V1,V2,···,Vn} ,则其中Wij是节点Vi与Vj间边的权重数值。通过余弦相似度方法可得出句子之间的相似度矩阵如式(1)所示:
每个句子的权重数值可以结合网络图G和矩阵Sn×n来计算,如式(2)所示任意句子的权重Vi计算公式为:
式中:Ws(Vi) 为句子Vi的权重,d是取值大小为0.85 的阻尼系数,In(Vi) 表示指向句子Vi的句子集合,Out(Vi) 表示节点Vi指向其他节点的集合,Wij表示节点Vi和节点Vj间的相似度,表示上一次迭代后节点Vj的权重值。
边权重在TextRank 算法中的计算过程属于Markov 过程,收敛的权重数值可以通过迭代计算最终得到。一般把句子的初始权重设为1,也就是B0=(1,···,1)T,然后迭代计算至收敛:
收敛时Bi和Bi−1会很接近,一般认为当Bi和Bi−1之间差值小于0.000 1 时收敛,最后,根据每句话的得分,以实际需要选择排序靠前的句子作为摘要。
SWTextRank 算法[15]针对TextRank 算法在自动提取中文文本摘要时只考虑句子间的相似性,而忽略了词语间的语义相关信息及文本的重要全局信息进行了相应改进,使得摘要的准确率得到提高。SWTextRank 算法利用Word2Vec 训练的词汇矢量,综合考虑了句子权重的影响因素,如语句的位置、语句与题目是否具有相似性、重点词语的覆盖、重点语句与提示词等,并通过分析句子的相似性来达到优化语句分量的目的。最后,对所获得的候选句使用余弦相似度进行冗余处理。
2 算法设计
本文提出提取子句的方法,以避免TextRank 算法及其系列改进算法提取的摘要存在冗余的问题,从而减少含有相同语义信息的句子重复出现,使得最终获取的摘要既具有简约性又具有对文章总体意思的总结。本文在句子权重计算时,综合考虑文中的子句位置,子句和题目的相似度,重点语句和提示词等要素,使得最终获得的摘要更准确。一般来说,每一段的首句或者尾句更能表明大意,所以这部分语句的权重也应当加大;和标题相似度很高的句子也应当加大权重;具有概括文章大意词语的句子权重也应当加大。
2.1 基于子句的抽取
在本节中,提出一种抽取单元替代方法,对完整的句子进行截取来提取文档的摘要。因此,使用子句提取来代替之前的整句提取方法。具体来说,提取单元基于句子的选区解析树中的子句节点。图1显示了选区解析树的两个简化示例(图中S(Sentence)、ADVP( Adverb) 、 NP( Noun Phrase) 、 VP( Verb Phrase)、VBD(Verb Past Tense)、SBAR 表示从句性质、 WHNP( Wh-Noun Phrase) 、 CC( Coordinating Conjunction))。选区树中的根节点表示整个句子,而叶节点表示其对应的词法标记。根节点上的提取本质上是提取整个句子,而叶节点上的提取是通过提取单词进行压缩。对非终端节点进行抽取,既能表达相对完整的句子含义又能被人读懂。因此,子句节点如S 和SBAR 成为一个很好的选择。
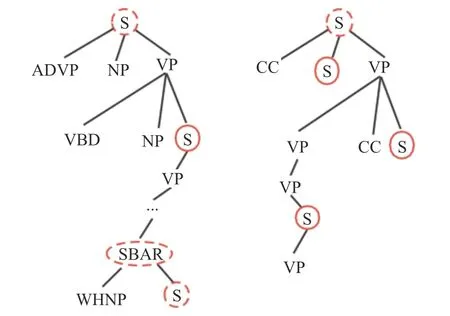
图1 两个简化的选区解析树Fig.1 Two simplified analytic trees of selected area
为了对子句单元进行提取,需要确定哪些单元可以提取。该方法基于选区解析树,其基本思想是基于树中的子句。在实验中,我们采用了Sinica Treebank 中使用的语法标记集。在STB 标记集中有两种主要类型:短语和句子。在本实验中使用子句标签是因为子句中的信息比短语更完整。本文实验中主要是针对中文文本摘要的提取,因此语法标记使用的是中研院Sinica Treebank。中文和英文在句法结构上存在差异,比如英语句子的特点是句子中的每一个成分均可有修饰语,而且修饰语不止一个,每个修饰语都可以很长;一个修饰语还可被另一个修饰语修饰,因此句子结构复杂。中文句子中修饰语少而短,句子由一个一个的分句构成并逐步展开。因此,如果对英文文本进行摘要的提取,语法标记建议使用Penn Treebank。
在给定句子解析树的情况下,遍历它来确定提取单元的边界。具体来说,每个子句都被视为提取单元候选项。如果它的一个祖先是子句节点,我们选择最高级的祖先子句节点(根节点除外)作为提取单元,因为最高级的祖先子句节点包含更完整的信息。如果一个句子没有子句,那么就用整句作为抽取单元。
表1 显示了两个中文句子经过本文子句抽取策略的提取结果。从结果可以看出,通过对子句提取,整个句子被分解成更细粒度的语义单元。因此,本文的子句抽取策略可以提取重要的部分,而不引入不重要的内容。

表1 子句抽取结果Table 1 Clause extraction result
2.2 子句相似度计算
TextRank 算法网络图中的节点间权重影响每句话的最终得分,而节点间权重即为句子间的相似度,所以计算句子相似度就变得特别重要。为了使句子相似度计算更为准确,多种相似度计算方法已经应用在TextRank 算法上,如Word2Vec、Doc2Vec 等。
BERT 是一个语言表征模型,由Google 于2018年推出。它的特点就是不同于以往的单向语言模型或者把两个单向语言模型进行简单拼接的方法进行预训练,而是基于Transformer 采用深度的双向语言表征。与Word2Vec、Doc2Vec 等方法相比,BERT 能够更好地反映出句子之间的关系。本文正是利用BERT 训练的词向量来获得子句的向量进而计算子句与子句之间的相似度。具体算法如算法1 所示,其中T为初始化的词向量集合,S为初始化的句子向量集合,D为原始句子经过STB 抽取子句,对子句进行文本分词、去除符号和停用词得到的词语集合。算法1 的具体实现流程如下所示:
利用官方中文BERT 预训练模型对以下3 个句子进行编码,两种句子的相似度结果,如表2 所示。

表2 不同句子相似度结果Table 2 Similarity results of different sentences
句子A=“要重视文本摘要算法的研究”
句子B=“自动文摘是自然语言处理中的重要内容”
句子C=“今天天气真好,风和日丽”
从所举的例子中可以得出,A、B 两句在语义上较A、C 两句更为相似,但是这3 句话之间都没有相同的词语,每句话之间的语义相似度并未提现。A、B 和A、C 之间的余弦夹角相似度的结果,可以反映出使用BERT 对句子进行向量编码后语义上的差异。可以看出,BERT 训练出的词向量更能体现出句子之间的语义不同,使得最后得出的摘要更能反映原文主旨内容。
2.3 特殊子句的权重处理
本文对特殊位置的子句、包含标题关键词的子句、包含线索词的子句和含有专有名词的子句的权重调整为原来的k倍。在根据式(3)迭代计算收敛后,对k分别取值1.2、1.4、1.6、1.8 进行实验对比,最后抽取前两句作为摘要,根据式(4)~式(6)中平均准确率P、平均召回率R和平均F值最终确定k取1.4 时摘要抽取的效果最好。
其中:ai表示算法生成的第i篇文章的摘要,bi表示数据集中给定的第i篇摘要。
实验结果对比如表3 所示。具体算法如算法2 所示,其中Bi表示句子权重值,函数isSelectCentence()是选择符合上述条件的子句改变其权重。算法2 的具体实现流程如下所示:

表3 不同权重结果对比Table 3 Comparison of results with different weights
2.4 算法实现
基于上述子句抽取、句子相似度计算及特殊句子的权重处理策略,改进后的PTextRank 算法的实现过程如算法3 所示。算法中对文本的处理、子句向量的计算和算法1 相同。Wij表示利用余弦相似度计算子句向量间的相似性,Sn×n是把Wij存放在如式(1)的矩阵中。然后根据式(2)计算出子句权重值Ws(Vi),选择符合条件的子句进行权重调整,根据式(3)迭代计算至收敛得到每个子句的分数。最后根据分数排名得到最终的摘要。算法3 的具体实现流程如下所示:
3 冗余度分析
TextRank 算法迭代计算后按照句子分数从大到小的顺序选择前几个句子形成最终的摘要,因为前几句的语义是相近的,此时的摘要就会形成冗余。原文作者为了强调重要信息,可能会用不同形式的句子,在原文的不同位置重复原文的主旨内容。如果不同位置相似的句子都成为摘要句,那么在最终形成的摘要中就会有相似的句子造成信息冗余。
为了分析冗余问题是否存在,本文采用基于计数统计和人为判断两种方法进行实验和分析。本文选取了TTNewsCorpus_NLPCC2017 数据集为样本。在此数据集上分别进行TextRank、SWTextRank 以及PTextRank 算法的冗余度分析。首先定义一个冗余度量,即n元重叠率,计算每对句子之间的ngram 重叠。这种重叠的计算方法如式(7)所示:
根据表4 的数据显示, TextRank 算法和SWTextRank 算法在冗余度上都远远高于参考摘要的冗余度。在词汇层面的统计之外,还进行了人工评价,结果与n-gram 的重叠率相匹配,这表明TextRank 和SWTextRank 两种算法都存在冗余的问题。

表4 各种算法和参考摘要的冗余度Table 4 Redundancy of various algorithms and reference abstracts
4 性能分析
本节进行了两个性能分析实验:实验1 比较了PTextRank 算法与TextRank 算法和SWTextRank 算法的性能,实验2 比较分析了PTextRank 算法与典型网络在线摘要生成系统的摘要生成结果。
4.1 PTextRank 算法与TextRank、SWTextRank 算法的对比
本节以计算准确率P、召回率R和平均值F值为评价指标, 将PTextRank 与TextRank 算法和SWTextRank[15]进行比较;实验中所采用的数据集是TTNewsCorpus_NLPCC2017。首先获取数据集中article 和summarization 两部分当中的article 部分,然后通过本文的PTextRank 算法和TextRank 算法、SWTextRank 算法分别生成每篇文章的摘要。
实验结果如表5 所示。
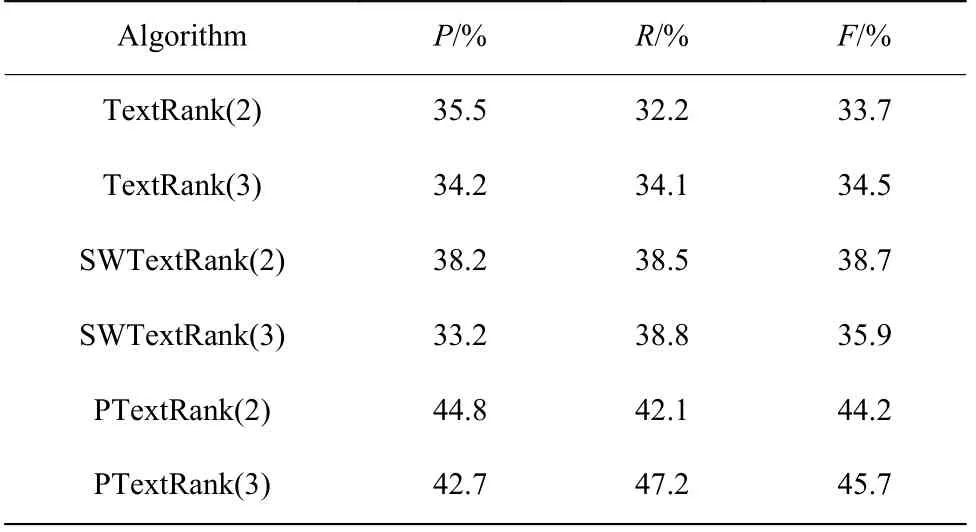
表5 各种算法的实验结果对比Table 5 Comparison of experimental results of various algorithms
通过表5 的数据对比可以发现,从P、R、F这3 个指标来看,PTextRank 算法所产生的摘要效果要好于另外两个算法所产生的,更加接近数据集中给定的标准摘要。其中SWTextRank 算法在生成摘要句为2 句和3 句时根据式(4)计算得出的准确率为38.5%和38.8%,而PTextRank 算法根据式(4)计算出的准确率为44.8%和42.7%。所以可以看出,PTextRank算法至少提高了6%的准确率。实验结果说明,在提取摘要的过程中考虑了文本的整体结构信息、句子的位置以及句子与标题的相似度等因素,并结合TextRank 算法,能够提高摘要的质量。通过表4的数据表明,在使用子句抽取模式代替原来的抽取整句后,PTextRank 算法对其进行了进一步的冗余优化处理,使得生成的摘要效果优于SWTextRank 算法。
4.2 与典型网络摘要生成系统的摘要生成结果对比
本部分选取数据集中的两篇文章,将PTextRank算法生成的摘要、在线自动摘要系统(http://kgb.ling join.com/nlpir/)生成的摘要与数据集中给定的摘要比较,结果如表6 所示。在线自动摘要系统所使用的算法是以TextRank 算法为基础,首先使用Word2Vec生成词向量并自定义Embedding,得到词语的Embedding 后以词向量的平均值作为句子的向量表示。其次使用余弦相似度计算句子之间的相似度并构成如式(1)的相似度矩阵。最后根据式(2)和式(3)迭代得到句子的TextRank 值,并对TextRank 值排序得到最终摘要。根据表6 的结果可知在线自动摘要系统和PTextRank 算法生成的摘要都能够较好地表达原文的内容。因本部分只选择两篇文章抽取摘要数据量较小,在线自动摘要系统和PTextRank 算法生成的摘要在准确率P、召回率R和平均值F基本无差别。从摘要冗余度看,根据式(7)计算二元重叠率,可以得出在线自动摘要系统生成的摘要二元重叠率分别为22%和13%;PTextRank算法生成的两篇摘要二元重叠率分别为10%和6%。可以看出PTextRank 算法生成摘要的冗余度远远小于在线自动摘要系统生成摘要的冗余度。

表6 摘要结果对比Table 6 Summary results comparsion
5 结束语
自动摘要一直是自然语言处理中的主要研究方向。本文针对目前抽取式摘要在提取中文文本摘要时存在的不足,提出了改进的PTextRank 算法。对于在抽取摘要时以句子为单位会造成抽取出的摘要存在冗余问题,本文使用STB 对每个句子进行语法标记,选择每个句子的子句,没有子句的就用整句作为抽取单元,进而以子句代替原来的整个句子为抽取单元。通过实验与分析表明,与以句子为单位抽取模式相比,子句提取具有更好的效果。抽取式摘要抽取出的句子之间衔接生硬、不够自然等问题将作为下一步待解决的工作。
猜你喜欢
上海航天(2024年1期)2024-03-08 02:52:28
四川师范大学学报(自然科学版)(2023年1期)2023-03-12 07:23:28
当代陕西(2020年17期)2020-10-28 08:18:18
计算机集成制造系统(2020年8期)2020-09-11 02:49:36
人大建设(2018年5期)2018-08-16 07:09:00
西夏学(2018年2期)2018-05-15 11:24:42
山西建筑(2017年29期)2017-11-15 02:04:38
黑龙江交通科技(2017年7期)2017-09-20 03:40:35
电信科学(2017年6期)2017-07-01 15:44:57
黑龙江交通科技(2016年11期)2016-03-11 08:46:57
