
基于密集多尺度特征和双注意力模块的皮肤病变分割
2024-03-12 11:39:42罗健旭
华东理工大学学报(自然科学版) 2024年1期
费 承, 罗健旭
(华东理工大学信息科学与工程学院, 上海200237)
在皮肤黑色素瘤的临床诊断中,目前普遍采用的皮肤镜成像技术首先获取放大或缩小后的皮肤病变区域透镜图像,接着需要对病变区域进行精准分割以提高后续过程中医生诊断治疗的准确性和可靠性。但是人工分割费时费力,可重复性差,即使是经验丰富的医生也可能受各种因素影响出现漏分、错分现象,因此引入计算机辅助诊断 (Computer Aided Diagnostic, CAD) 系统实现皮肤病变区域的自动分割以帮助医生进行临床评估、诊断具有重要意义。
早期皮肤病变分割算法大多基于阈值分割法、区域生长法和边缘分割法。例如,Grana 等[2]定义了病变斜率和病变斜率规律,然后基于Catmull-Rom 样条法计算病变边界;Garnavi 等[3]基于颜色空间分析确定最佳颜色通道,然后基于聚类的直方图阈值法进行边界检测。这些方法虽然取得了一定的分割效果,但是通常需要人为干预且分割效果仍有较大的提升空间。
随着深度学习的不断发展,卷积神经网络(Convolutional Neural Network, CNN)凭借其出色的特征表征能力已经成为目前分割任务的主流算法。全卷积网络(Fully Convolutional Network, FCN)[4]创新性地提出了编码解码架构,实现了像素级别分类,奠定了后续分割网络的基本架构。在该架构的基础上,UNet 使用对称设计和跳跃连接结构在医学图像分割任务上取得了较好的表现,并成为了后续医学分割领域的基本网络结构[5]。在这之后,皮肤病变分割算法大多是FCN 或UNet 的变体。例如,文献[6-7]在FCN 网络的基础上进行了改进,使得网络的分割效果均有了一定的提升;文献[8]采用DoubleUnet 将两个UNet网络组合起来,其中第2 个UNet 用于进一步细化第1 个UNet 产生的掩码结果,同时DoubleUnet还引入了ASPP 模块以获得多尺度特征来缓解皮肤病变区域大小尺寸各异的问题,此外其还使用了SE 模块来减少冗余信息、传递最为相关的特征;文献[9]一方面使用Fire Block 来减少学习参数,另一方面引入注意力机制来强化与皮肤病变区域相关的特征并抑制无关特征。虽然这些网络在皮肤病变分割任务上取得了较好的表现,但是仍存在一定的局限性:(1)ASPP 模块倘若要获取更多的多尺度信息就意味着需要更多的学习参数,并且该模块如果为追求较大的感受野而采用较大的膨胀率会导致信息丢失,影响最终分割效果;(2)网络中使用的注意力机制是从局部特征中获取信息,而忽略了全局上下文信息;(3)网络使用的注意力机制较为单一;(4)没有将多尺度信息和注意力机制结合起来共同解决皮肤病变分割难题。
针对以上问题,本文提出了一种基于U 型网络结构的DDAnet。首先,DDAnet 使用了密集连接的DenseASPP 模块[10],该模块以较少的学习参数获取到了更多的尺度信息并生成了更大的感受野;其次,DDAnet 利用双注意力模块来编码全局上下文信息,指导网络分别在通道和位置上对相关特征和无关特征分别进行强调和抑制。同时,不同于大多数方法采用的串联方式,DDAnet 将DenseASPP 模块和双注意力模块并行连接,这样一方面能够确保双注意模块不会影响、破坏多尺度特征,另一方面使得解码器的输入既包含了多尺度特征,又包含在通道和位置上得到重新配准的特征。除此之外,由于使用了跳跃连接结构,解码器的输入特征会包含局部细节信息和高级语义信息两部分,DDAnet 在每个解码模块中使用通道注意力模块(Channel Attention Module,CAM)进行通道特征选择,促进网络更加关注有利于分割的特征。最后,本文在传统二值交叉熵损失函数的基础上引入Dice 损失函数来克服皮肤病变分割任务中正负样本不平衡的问题,最终网络的分割性能得到提升。
1 方 法
1.1 网络概述
DDAnet 整体采用的是编码解码结构,其网络框架如图1 所示。对于给定的皮肤透镜图像,首先将其通过编码器进行特征提取,在该框架中,编码器采用的是预训练的ResNet34[11]。在编码器的下采样过程中,图像的分辨率不断减小,特征通道不断增多,并依次得到包含局部细节信息的低级特征图和包含丰富语义信息的高级特征图。接着,高级特征图一方面通过DenseASPP 模块进一步得到多尺度信息;另一方面通过由CAM 和位置注意力模块(Position Attention Module, PAM)构成的双注意力模块,分别在通道和位置上进行特征的重新配准[12],配准后的2 个特征图通过相加进行融合。在得到DenseASPP模块和双注意力模块的输出后,将两者按通道进行拼接输入解码器以恢复到原始图像的分辨率。解码器由3 个解码模块和1 个上采样模块构成,每个解码模块将前一层的高级特征图通过反卷积操作放大两倍后,再将其与来自编码器的低级特征图相拼接,由于这两部分所提供的信息不同,因此使用CAM 对它们重新分配权重以强调那些相关程度较高的通道特征。最后上采样模块直接将特征图放大到原始尺寸,再经过一个1×1 卷积层得到最终分割结果。
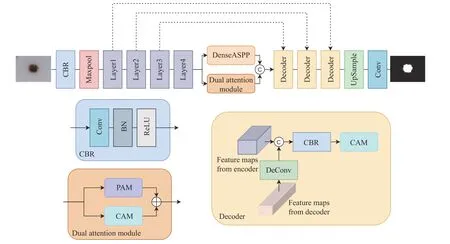
图1 DDAnet 网络架构Fig.1 Network architecture of DDAnet
1.2 DenseASPP 模块
DenseASPP 模块通过密集连接的方式将膨胀率不同的空洞卷积连接起来,其中空洞卷积是基于标准卷积的卷积核,向其相邻参数间填充一定数量的0,从而实现了在不引入额外参数的情况下扩大了卷积的感受野。下面以一维情况为例说明空洞卷积的算法原理,对于给定的输入特征图x,空洞卷积的输出特征图y在i位置上的值可通过下式计算得到:
其中:d表示膨胀率,w[k] 表示卷积核的第k个参数,K表示卷积核尺寸。关于密集连接,这种连接方式意味着DenseASPP模块中某一个空洞卷积层的输入是其之前所有空洞卷积层输出的拼接,并且模块最终输出整合了所有空洞卷积层的输出特征图,如图2 所示。这种特征重用策略既避免了特征的重复学习,又提取到了新的特征,进而提高了模块整体的特征表征能力。基于式(1),定义HK,d(x) 表示卷积核尺寸为K,膨胀率为d的空洞卷积,则第l层空洞卷积的结果可以表示为:
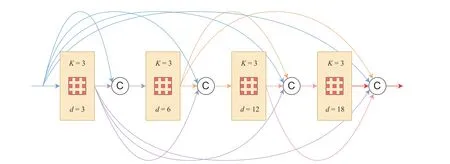
图2 DenseASPP 模块Fig.2 DenseASPP module
其中:dl和yl分别表示第l层的膨胀率和输出,[···]表示拼接操作。
郭村有八百年历史,是旧时宁国、徽州、池州三府交界之地,兴旺的时候,村里有十座祠堂,店铺毗连,商贾云集。
另外,密集连接方式允许特征图通过不同膨胀率的空洞卷积层,而不同的通过方式则意味着不同的尺度,因此仅采用一定数量的空洞卷积层即可产生非常丰富的多尺度信息。例如,由膨胀率为3、6、12、18 的空洞卷积层组成的DenseASPP 模块能够产生15 种尺度,远远超过相同情况下ASPP 模块所产生的尺度。
1.3 CAM
在特征图中,某一通道对应着某一特定的特征,而不同特征之间又存在着一定的联系,CAM 正是基于这种联系来显式地建立通道之间的相互依赖关系,进而强调那些关联性强的特征,并突出重要特征。CAM 的结构如图3 所示。对于输入特征图A∈RC×H×W,首先将其维度转换为RC×N,其中N=H×W,接着将A与其自身的转置做矩阵乘法,再将得到的结果经过 softmax 激活函数即可获得通道注意力权重图X∈RC×C:
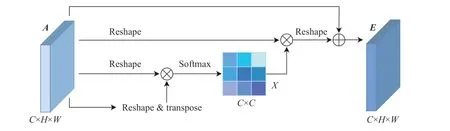
图3 通道注意力模块Fig.3 Channel attention module
其中:xji表示第i个通道对第j个通道的影响程度。通道注意力权重图在与A做矩阵乘法后再将得到的结果转换到RC×H×W维度,最后该结果乘以一个初始值为0 的可学习参数 γ ,再与维度为RC×H×W原始输入特征图A按像素相加,则产生最终输出E∈RC×H×W:该输出特征图E的每个通道是输入特征图A的所有通道的加权和,表明通道间的依赖关系得到建立,从而相关特征得到强化,并且各特征表示之间的区分度也得到了提升。
1.4 PAM
全局上下文信息在分割任务中极为重要,而该信息通常需要通过聚合空间特征来细化得到,传统CNN 为实现此目标需要堆叠大量的卷积层,进而导致训练十分困难,因此本文采用PAM 基于局部特征建立高效的上下文联系,该模块将全局信息编码到局部特征中,从而增强了这些特征的表征能力。PAM 的结构如图4 所示。对于只包含局部信息的输入特征图A∈RC×H×W,首先将其通过3 个不同的1×1卷积层分别得到特征图B∈RC8×H×W、C∈RC8×H×W、D∈RC×H×W,其中用于生成特征图B和C的分支进行了特征降维,而生成特征图D的分支保持通道数不变,这是因为特征图B和C用于计算得到注意力权重图,而PAM 是位置维度上的注意力机制,通道压缩后不但对位置注意力权重图的计算影响不大,而且还能减少计算量。特征图D的通道维度直接决定PAM 输出的通道维度,为了保证其输入输出维度不变,生成特征图D的分支不能进行特征降维。在得到了这3 个特征图后,将它们的维度分别转换为和RC×N,其中N=H×W。接着将C的转置与B做矩阵乘法得到的结果输入 softmax 激活函数计算得到位置注意力权重图S∈RN×N:
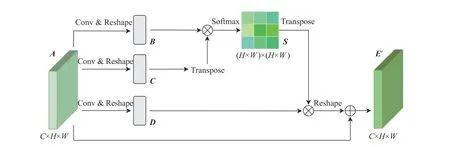
图4 位置注意力模块Fig.4 Position attention module
其中:sji表示位置i对位置j的影响程度。再将特征图D与位置注意力权重图S的转置做矩阵乘法,并将得到的结果的维度还原到RC×H×W,最后该结果乘以一个初始值为0 的可学习参数 η 后与输入特征图A按像素相加得到输出特征图E′∈RC×H×W:
该输出特征图E′在每个位置上的特征都是由输入特征图A上所有位置特征加权求和得到的,因此其能捕获所有位置的交互信息,并有选择性地聚合全局上下文信息。
1.5 损失函数
交叉熵损失函数适用于大多数语义分割场景,但是在皮肤病变分割任务中,由于病变区域通常只占整张皮肤透镜图像的一小部分,前景(病变区域)像素远小于背景(非病变区域)像素,因此直接使用交叉熵损失函数训练网络会使得网络模型严重偏向于背景,进而影响分割效果。所以本文在二值交叉熵损失函数的基础上,结合Dice 损失函数作为总的目标损失以解决此问题:
其中:N代表图像中的像素总数,yi∈{0,1} 表示像素i的真实标签,pi∈[0,1] 表示像素i的预测结果。
2 实验部分
2.1 实验数据集及数据预处理
为了评估DDAnet 的分割性能,本文在ⅠSⅠC2018数据集[13-14]上实施了一系列实验。该数据集包含2 594张皮肤透镜图像以及对应的真实标签,随机筛选2 000张图像用于网络训练,剩下的594 张图像用于测试。另外,由于该数据集中的图像尺寸不一,因此将它们统一缩放到 384×512 分辨率输入网络。同时为了避免因训练数据量较小而导致的过拟合问题,本文还采用了数据增强策略,包括水平翻转、垂直翻转、随机旋转以及随机调整亮度和对比度。
2.2 评价标准
对于网络分割性能的评估,本文采用了5 种评价指标,分别是Jaccard 相似系数(JⅠ)、Dice 系数(DC)、准确率(Acc)、敏感度(Sen)和特异性(Spec),它们的计算公式如式(10)~(14)所示,其中JⅠ和DC是度量分割结果的主要指标。
其中:TP 和TN 分别表示被正确预测的病变和非病变区域的像素个数,而FP 和FN 分别表示被错误预测的病变和非病变区域的像素个数。
2.3 实验环境及相关参数
本文中所有实验均基于Ubuntu 18.04.5 系统下PyTorch 深度学习框架,计算机硬件配置为Ⅰntel Core i9-10980XE CPU,NVⅠDⅠA GeForce RTX 3090 24GB GPU。网络训练过程中使用的是Adam 优化器,其初始学习率设置为0.000 1,并且该学习率会在训练过程中动态衰减。训练批次设置为8,训练总代数设置为120。在上述参数设定下,训练完成后,网络均能得到收敛。
2.4 实验结果
2.4.1 损失函数对网络的影响 为了验证本文采用的目标损失函数对网络的分割性能有所提升,分别用二值交叉熵损失、Dice 损失以及二者结合作为目标损失函数来训练DDAnet,实验结果如表1 所示。从表中可以看出,单独使用二值交叉熵损失来训练网络取得的分割效果最差,这是因为该损失无法解决皮肤病变分割所面临的正负样本不平衡问题;而单独使用Dice 损失时分割精度有所提升,这主要归结于Dice 损失是区域相关的损失,其计算损失时不局限于当前像素,而是综合考虑了整个前景区域,因此正负样本不平衡问题才在一定程度上得到了缓解。但倘若网络将整个前景区域分割错误,Dice 损失就无法学习到正确的梯度下降方向,进而导致在训练过程中损失振荡严重,且极端情况下会出现梯度饱和现象。现将二者结合起来,一方面Dice 损失从全局上进行考察,侧重前景区域的挖掘;另一方面二值交叉熵损失逐像素进行引导,并在Dice 损失缺乏指导时提供指引,从而网络在此损失下产生了最好的分割效果。
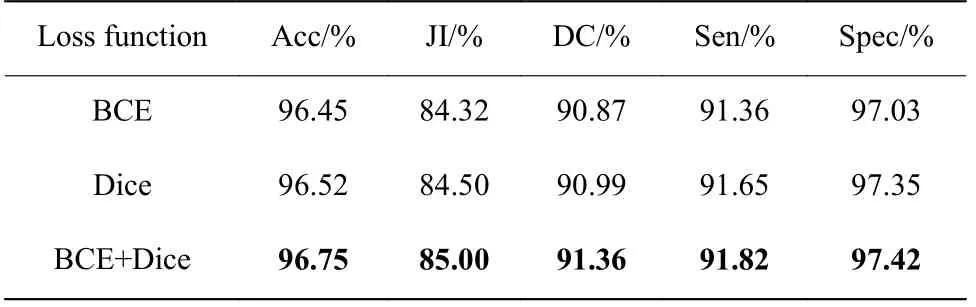
表1 不同损失函数下DDAnet 的分割结果Table 1 Segmentation results of DDAnet with different loss functions
2.4.2 各模块对网络的影响 为了评估各模块对网络分割性能的影响,本文设计了4 组对比实验:(a) 完整的DDAnet;(b) DDAnet 去除DenseASPP 模块;(c)DDAnet 去除CAM;(d) DDAnet 去除PAM。实验结果如表2 所示。从结果可以看出,DDAnet 去除任一模块后,分割结果在各评价指标上都有所下降。其中,去除掉PAM 后下降最为明显,JⅠ和DC 分别下降了1.65%和1.28%;去除CAM 后,JⅠ和DC 分别下降了1.39%和1.06%;去除DenseASPP 模块后,JⅠ和DC 分别下降了1.32%和0.96 %,这表明DenseASPP模块、CAM 和PAM 都在一定程度上提升了网络整体的分割性能。
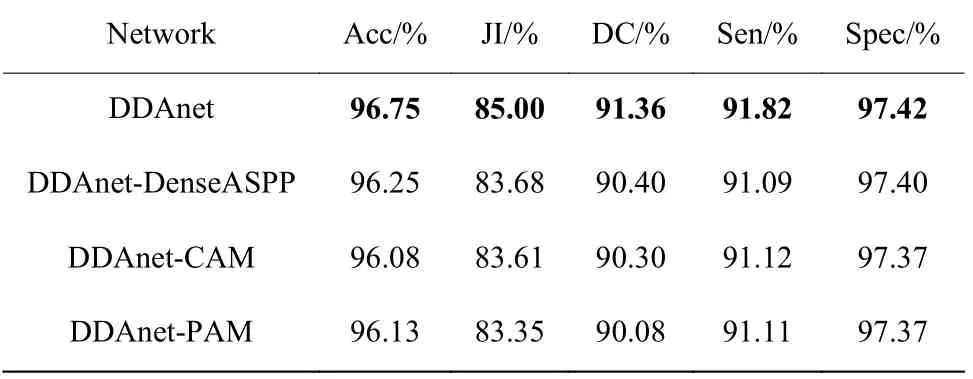
表2 不同模块对网络分割性能的影响Table 2 Ⅰmpact of different modules on network segmentation performance
2.4.3 同类研究对比 为了证明DDAnet 分割皮肤病变区域的可靠性和优越性,本文将其与同类的研究方法进行了对比,实验结果如表3 所示。从表3 中可知,DDAnet 在Acc、JⅠ和DC 指标上均优于其他分割网络,其得分分别为96.75%、85.00%和91.36%。与医学分割任务中常用的UNet 网络相比,DDAnet 在这三项指标上比UNet 分别高出了2.13%、7.96%和6.94%;与分割精准度较高的ADAM 相比,DDAnet在这三项指标上比ADAM 分别高出了2.05%、0.60%和0.26%。虽然在Sen 和Spec 指标上,DDAnet 并未取得最佳结果,但是总体来看,尤其是以分割准确程度来衡量,DDAnet 相比于其他分割网络更加优越、可靠。

表3 DDAnet 与同类研究方法的分割结果对比Table 3 Comparison between the segmentation results of DDAnet and those of other similar research methods
同时,为了更加直观地展示DDAnet 的分割效果,本文基于上述方法中源码公开的分割网络进行了可视化对比分析,结果如图5 所示。图5 中每一列包含一张皮肤透镜图像和各网络的分割结果,分割结果由网络预测图和真实标签对比得到,图中的橙色、红色、绿色和黑色分别对应TP、FN、FP 和TN。理想的分割结果是皮肤病变区域为橙色,而非病变区域为黑色。对于病例1,由于病变区域和非病变区域之间像素差异较小,边界十分模糊,因此大部分网络都无法识别出病变区域的具体位置,其中UNet 和AttentionUnet 甚至都认为图像中不存在皮肤病变,而DDAnet 仍能较为准确地划分出两者的边界;对于病例2,非病变区域中有部分皮肤颜色不同于正常皮肤,且与病变区域皮肤颜色接近,除了ResUnet++和DDAnet 外,其余网络均被干扰,而DDAnet 在JⅠ和DC 指标上更优于ResUnet++;对于病例3、4,病变区域周围的气泡给分割带来了很大的干扰,虽然以MobileNet 为backbone 的DeepLabv3+和CENet 表现优于其他算法,但是和DDAnet 相比仍存在一定差距;对于病例5,病变区域内部像素存在一定差异,并且与非病变区域对比度低,这就导致大部分网络只能识别出明显的病变区域,而漏掉不明显的部分,但是DDAnet 却能够相对全面地捕获到所有病变区域。从以上对比分析可知,尽管皮肤病变分割任务中存在诸多挑战,但是DDAnet 仍能提供出色的分割结果,直观地表明了DDAnet 相比于其他分割网络的优越性。
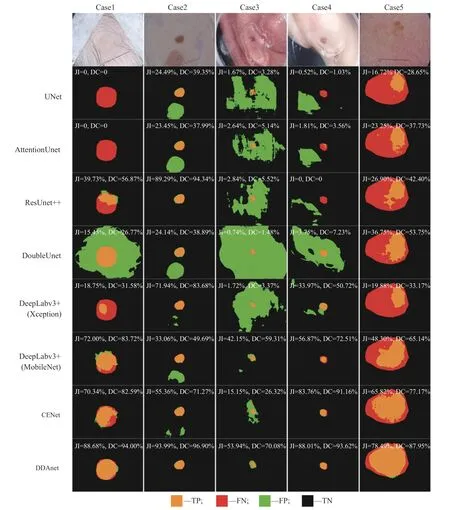
图5 可视化对比分析Fig.5 Visual comparative analysis
3 总 结
本文提出了一种基于密集多尺度特征和双注意力模块皮肤病变分割网络DDAnet,该网络基于U 型网络结构,以预训练的ResNet34 作为编码器对输入图像进行特征提取,所提取到的高级特征输入到并行连接的DenseASPP 模块和双注意力模块,其中DenseASPP 模块通过产生丰富的多尺度信息,解决了皮肤病变区域大小尺寸各异的问题;而由CAM 和PAM 组成的双注意力模块通过编码全局上下文信息,对特征进行重新配准,分别在通道和位置上
强调相关特征、抑制无关特征,从而进一步提升了分割精度。在ⅠSⅠC2018 数据集上的实验结果表明DDAnet 具有十分出色的分割表现,优于其他的分割网络,并且即使面临病变区域内部像素差异大、边界模糊、周围存在气泡等难题时,DDAnet 依然能够产生准确、可靠的分割结果,说明其在临床诊断中具备辅助医生进行皮肤病变分割的潜力。
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
江西教育·职教版(2022年9期)2022-04-29 00:44:03
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
今日农业(2019年15期)2019-01-03 12:11:33
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
CHIP新电脑(2016年3期)2016-03-10 14:22:03
