
基于TF-IDF 和多头注意力Transformer 模型的文本情感分析
2024-03-12 11:39:54高佳希黄海燕
华东理工大学学报(自然科学版) 2024年1期
高佳希, 黄海燕
(华东理工大学信息科学与工程学院, 上海 200237)
随着信息化社会的海量文本数据流转,如何高效地从非结构化、信息量庞大的用户评论中有效地挖掘隐藏的情感倾向变得极其重要[1-2]。情感本身是一个主观的概念,涉及到人们对于某些人、事或物的看法、观点、评价[3]。文本情感分析通常是指对文本中所蕴含的情感信息进行分析、总结的过程,又称为意见挖掘、评价抽取等。文本情感分类是对文本的主观信息进行分析,对文本所要表达的情感倾向性的好坏及其情感倾向强度进行判断[4-5],例如在危险辨识系统中,通过预训练-微调的方式建立事故案例文本的分类模型,实现对事故案例文本的自动分类[6]。
随着机器学习算法的广泛应用,基于机器学习算法处理文本情感倾向分析问题被广泛提出。文献[7]用朴素贝叶斯算法对文本进行训练,提取词性和位置关系作为文本特征,然后在分类阶段引入布尔权重为所提取的特征词分配不同的权重进行情感分类。文献[8]用最大熵、支持向量机等多种经典机器学方法,逐步提高分类准确率。文献[9]通过对词语所在语句的语境和该词语与语句中其他词语的依赖关系进行分析,构建了基于情感的二分类模型。
传统的机器学习方法采用高质量的标注数据集来进行情感分析,准确率相对于基于情感词典的方法更高,然而,传统的机器学习方法需要高质量地选取和构造文本情感特征,当面对庞大且复杂的数据集时,情感特征并不能得到很好的构造与选取[10-11]。随着深度神经网络的发展[12],研究者们采用深度学习算法处理文本情感分析问题时,在解决文本数量庞大的数据集上取得了优异成果[13]。文献[13]用字级别的词向量来表示文本的特征,然后用卷积神经网络(Convolutional Neural Network,CNN)模型对文本进行训练,得到文本的情感分类。文献[14]提出双向长短时记忆网络(Bi-directional Long Short-Term Memory,Bi-LSTM)对已经向量化文本进行训练获得其文本特征,然后利用自注意力(self-attention)机制动态地调整所获取的文本特征的权重,利用Softmax分类器实现对文本的情感归类。文献[15]将待分类文本采用文档主题生成模型( Latent Dirichlet Allocation,LDA)进行主题分类训练,然后将所得的文本特征矩阵作为输入,传递到门循环单元(Gate Recurrent Unit,GRU)和 CNN 的融合模型中对文本的情感倾向进行分类。文献[16]通过深度学习和情感词典两种方法分别进行特征提取并情感分类,用Transformer 框架算法得到评论文本的特征词位置特征映射以及文本语义,之后采用自注意力机制调整特征的权重,得到的文本特征融合实现文本的情感分类。
深度神经网络文本模型在处理文本情感分析问题上是较好的解决思路,但长短时记忆网络(LSTM)模型的处理速度较慢且容易导致梯度爆炸等问题[17],而CNN 模型由于最大池化机制会过滤大量文本底层信息[18],面对多类型语料库时难以对语义充分编码,同时针对情感分析的文本预处理中只能去除通用的停用词,而不能去除某领域专有名词的问题。本文构建了一种基于TF-ⅠDF(Term Frequency-Ⅰnverse Document Frequency)和多头注意力Transformer模型的文本情感分析方法,实现了对多类别评论语料库的文本情感准确分析。在文本预处理阶段,利用TF-ⅠDF 算法对评论文本中不影响文本情感倾向的停用词进行过滤,对文本进行初步特征提取,之后利用多头注意力Transformer 模型的编码器对向量化后的文本进行训练并合并多个独立注意力池化层,得到深层文本特征,进而更好地分析文本情感,在具有多类型文本的电商、外卖评论数据集上进行了验证。
1 基于TF-ⅠDF 的文本预处理算法
1.1 词向量空间模型
词向量空间模型在文本处理、语义相似度分析、信息检索等领域被广泛使用。由于文本信息不能作为神经网络模型的输入数据,因此,在词向量空间模型中将文本转变为词向量空间中的数值向量形式,一个文本被看作是由若干个不同的术语构成的集合,每个术语代表文本的一个维度且可根据其在文本中的重要性进行权值化。假设文本Dj由n个异构维度组成,则文本Dj可以表示成一个n维词向量,即Dj=(Wj1,Wj2,···,Wjn) ,其中Wji代表第i个术语在文本Dj中的权重。
1.2 TF-IDF 算法
评论数据集文本信息包含不同类别的词语,有些词语对文本的情感倾向没有任何影响,且占用较大空间内存,导致模型训练时间倍增。因此,在将文本转化为词向量前,需要对这一部分词进行删减。自然语言处理(NLP)领域一般通过停用词词典来剔除停用词,再对复现次数进行统计,保留词频较大的词语。当评论文本为某一类产品的评论时,如对书籍的评论中会大量出现“目录”、“回头客”等信息,这些信息对文本情感几乎没有影响。当产品类别单一时,可采用手动添加停用词的方法,但当商品类别复杂如电商评论文本时,由于包含产品类别较多,手动添加停用词是一项非常复杂、繁琐的工作。因此,采用基于TF-ⅠDF 算法去除停用词,对多类别评论文本通道中的停用词进行删选,其预处理流程如图1 所示。
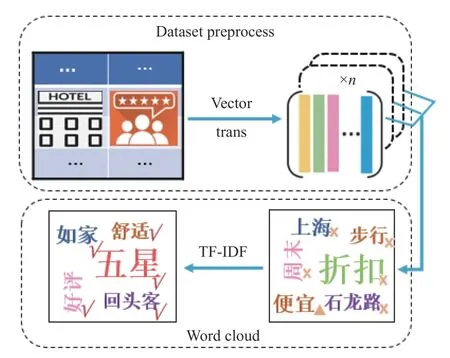
图1 TF-ⅠDF 语料预处理流程Fig.1 TF-ⅠDF data preprocessing process
TF-ⅠDF 算法以统计的形式对文本关键词进行数据挖掘,评估文本中某些词语在整篇文本中的重要程度。当某个字或词出现在某个文本中的频率很高,但出现在同一数据库的其他文本中频率又很低,那么就认为这个词能够体现出该文本的特征。TF 是词频,指某个词语在当前文本中出现的次数;ⅠDF 指逆文本频率指数,是文本中出现某个词语的文本数在数据集中所占的比例。基于TF-ⅠDF 算法的文本预处理算法步骤为:
步骤1 对输入文本进行分词处理,分词后得到文本(j):
步骤2 根据词(wi)在文本j中出现的次数ni j计算其TF 值:
步骤3 在数据集中查找所有包含wi的文件数,记为di,并根据数据集大小D计算wi的ⅠDF 值:
步骤4 根据 TFij, IDFij所得结果,计算词语wi的TF-ⅠDF 值。
通过式(1)~式(4)可得到文本j中所有词语的TF-ⅠDF 值,之后由大到小输出文本。若评论语料库采用传统的文本预处理方法,会导致保留下的词语包含大量产品的专有名词,因此采用TF-ⅠDF 算法进行文本预处理,得到词语云图,从而筛选出更能表达出文本的情感特性,大幅提高后续模型对文本解码的效率。
2 基于多头注意力Transformer 文本情感分析模型
2.1 多头注意力机制
自注意力机制是Attention 机制的一种类型,又称内部注意力机制,是一个与单个序列的权重系数以及该序列所在位置相关的注意力机制。在语义解码过程中进行寻址进程,向量化评论文本数据输入时,自注意力机制首先将输入的文本转化成嵌入向量的形式,然后再根据嵌入向量得到查询向量(Q),键向量(K)和值向量(V),当Q确定时,根据Q与K之间的相关性,就可以找到与其所对应的V,从而可以得到该注意力机制的最终输出值。
将自注意力机制的工作过程划分为3 层,其具体计算流程如图2 所示,其中 sim 表示相似性,a表示权重系数,A表示注意力值。

图2 自注意力机制的具体计算流程Fig.2 Specific calculation process of the self-attention mechanism
自注意力机制根据Q与K的相关性计算所对应的V,其中相似性计算包含点积模型、放缩点积模型、双线性模型等,其计算公式分别如式(5)~式(7)所示,其中d为向量的维度。
之后进行归一化处理,通过引入函数对上述得到的权重进行归一化处理,可以使重要元素的权重更加突出。以Softmax 函数为例,值向量对应的权重系数为:
将权重系数ai与对应的值向量V进行加权计算,获取最终的注意力值:
多头注意力机制(Multi-head-attention)也是注意力机制的一种,由多个Self-attention 机制交互形成,其结构如图3 所示,其计算表达式为:
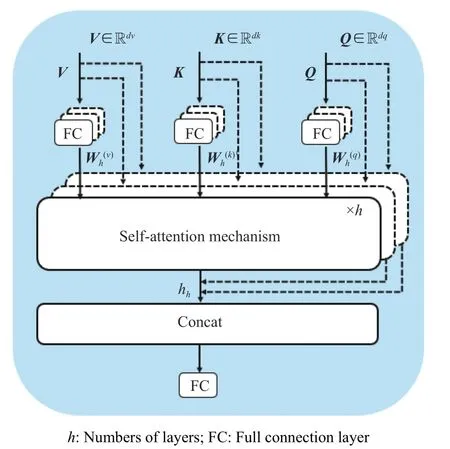
图3 多头注意力机制的结构图Fig.3 Structure diagram of multi-head attention mechanism
其中, headh为多头注意力机制第h个头计算得到的注意力值,其计算方法与自注意力机制计算方法(式(9))相同;WO为注意力机制层的权重矩阵。相对于单一的自注意力机制只能从整体上对进行注意力计算,多头注意力机制可以通过对K,Q,V的各维度进行线性映射的方法,得到多组不同的K,Q,V所对应的值向量,将映射后得到的值向量进行拼接后,再一次进行注意力映射,得到最终的值向量输出,实现不同序列位置的不同子空间的表征信息都能够用来进行数据处理,从而避免了单一注意力机制在去均值操作时模型丢失现象的发生。
2.2 基于多头注意力Transformer 模型的文本特征提取
Transformer 模型最早提出于2017 年,是GPT(Generative Pre-Training)模型与BERT(Bidirectional Encoder Representation from Transformers)模型的基础。Transformer 模型采用encoder-decoder 架构(图4),图4 所示的N为编码器或解码器的个数, σ 为sigmod 函数的输出值。在解码块及编码块内部完全采用注意力机制代替传统深度学习中的卷积神经网络(CNN)和循环神经网络(RNN)网络。Transformer模型在训练文本时不需要循环,而是并行处理所有文本,同时Transformer 模型内部的注意力机制还可以将距离较远的单词与当前单词结合起来,大大提高了文本训练的速度。
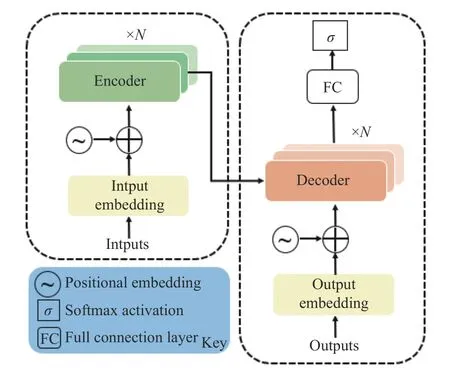
图4 Transformer 模型结构图Fig.4 Structure diagram of transformer model
由于Transformer 模型内部编码器不包含卷积神经网络和递归循环网络,舍弃了卷积操作而且不具备对文本时序的处理能力,这将导致词语在文本中的位置发生变化时,注意力机制的计算结果不会产生任何变化。因此,在多头注意力Transformer 模型中引入了位置编码机制,在文本输入Transformer 模型之前,对词语的位置进行编码,得到词语的位置嵌入,将其余词语本身的词嵌入进行相加作为编码器和解码器的输入,词语位置嵌入(PE)的计算公式为:
其中, pos 为位置信息,i为维度索引,dmodel为向量的维度。通过式(11)将词语所在的位置映射为一个dmodel维的位置向量。由式(12)三角函数积化和差公式可知,位于 pos+m位置的词语,其位置向量可以表示为 pos 位置向量的线性变换, 因此,使用式(10)计算词语的位置嵌入,不仅可以得到词语的绝对位置信息,还可以得到词语的相对位置信息。
本文不需要生成额外的其他文本形式,因此只需要使用Transformer 模型的编码器结构,编码器由多个相同的编码块组成,编码块则由多头注意力层和前馈神经网络(Feed-forward Neural Networks,FNN)两部分构成,其结构如图5 所示。
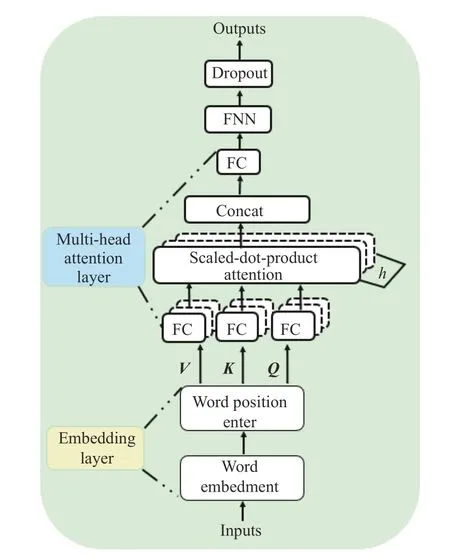
图5 多头注意力Transformer 编码器结构Fig.5 Encoder structure of multi-head-attention transformer
多头注意力层是编码块的第一层,它由多个缩放点积自注意力机(Scaled-dot-product-attention)组成,当输入为x时,多头注意力层通过h个不同的线性变换对x的查询向量Q,键向量K,值向量V进行投影,最后将不同的注意力机制值拼接。多头注意力层的输出同公式(10),其中:
其中,Z为前馈神经网络的权重系数;W1,W2为前馈网络的权重;b1,b2为前馈网络的偏置。
基于以上框架设计思路,本文使用TF-ⅠDF 算法和多头注意力Transformer 模型对评论文本所蕴含的情感倾向进行分析实验。首先利用TF-ⅠDF 算法对文本含义影响较小的词语进行过滤,并将过滤后的评论文本转化为词向量形式,然后输入多头注意力Transformer 模型进行迭代训练获得文本特征,最后由分类器softmax 根据所获得的文本特征对文本进行正例(POSⅠTⅠVE)和负例(NEGATⅠVE)分类。
3 实验分析
3.1 实验环境和数据集
本实验在 Ⅰntel(R) Core(TM) i7-8750 CPU @ 2.20 GHz 和Windows10 64 位操作系统的设备上进行,运行环境为Anaconda 4.7.10。为防止训练过程抖动,优化方法采用Adam 算法,实验采用earlystopping防止过模型拟合,表1 列出了具体的超参数。

表1 实验超参数Table 1 Experimental hyperparameters
选用waimai_10k 语料库和电商评论语料库两种多相异类型的数据集进行实验,waimai_10k 语料库来源于某外卖平台的评论信息,是一个多类型、不均衡的数据集,包含已标注的 11 987 条评论,其中NEGATⅠVE 评论7 987 条,POSⅠTⅠVE 评论4 000 条。电商评论语料库包含多种商品类型,包含62 774 条已标注的电商评论信息,其中POSⅠTⅠVE 评论31 728条,NEGATⅠVE 评论31 046 条。为方便记录,waimai_10k 语料库记为Wm_10k,电商评论语料库记为Ec_60k。为了充分验证本文算法的检测效果,选择全部原始数据集作为实验数据,且不预先进行任何特征处理或非平衡数据处理。将两种语料库数据集的实验数据按照比例划分为训练集、验证集和测试集,训练样本约占70%,验证样本约占10%,测试样本约占20%。
3.2 实验指标设置
3.2.1 评价指标 对于waimai_10k 语料库和电商评论语料库,本实验采用损失函数值(Loss)、准确率(Accuracy)、召回率(Recall)、精确率(Precision)、F1值等作为模型泛化能力评价指标,具体计算公式如下:
式(16)中,C为文本特征向量c的集合;pˆc、pc分别为文本真实、预测的极性标签;θ为模型训练过程中的参数; Θ 为θ的集合;λ为正则化L2 参数(L2 为范数最小平均误差)。式(17)~式(20)中TP 表示正例预测为正例的个数,FP 表示负例预测为正例的个数,FN 表示正例预测为负例的个数,TN 表示负例预测为负例的个数。为了更好地描述模型准确率、召回率、精确率以及F1 值等评价指标,引入了混淆矩阵的概念。
3.2.2 文本长度指标(Maxlen) 考虑到模型输入的样本长度对最终结果有较大的影响,如果输入样本的长度设定值过大,则需要向数据中填充的零过多,如果输入样本的长度设定值太小,数据需要舍弃的信息又太多。为了得到较为准确的数据,对分词后数据集中所有的评论文本的长度进行统计,得到长度分布如图6 所示。可以看出在语料库Wm_10k和Ec_60k 样本数据中,85%的文本书样本的Maxlen在20 左右,因此选定作为TF-ⅠDF 算法中的词语数。
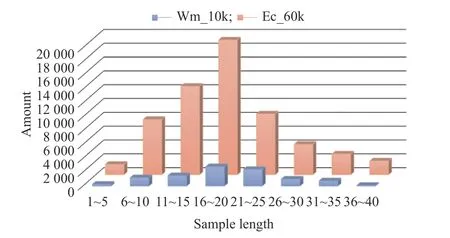
图6 样本长度分布图Fig.6 Diagram of sample length distribution
3.2.3 训练次数指标 在多头注意力Transformer模型中,若训练次数(Epoch)太少,情感分类的准确率会太低;训练次数太多,会造成时间和内存的浪费。因此,本文在输入样本数(Maxlen)为20 的情况下,对训练次数进行了实验,并对每次训练的损失函数值、准确率进行了记录,结果如图7 所示。当训练次数超过14 次时,分类的准确率与损失函数值的变化率已拟合,因此,综合训练时间及运行所占用内存考虑,最终实验的训练次数选为14 次。

图7 不同训练次数的准确率(a)与损失函数(b)Fig.7 Accuracy (a) and loss (b) of at different training numbers
3.3 实验指标设置
本文提出的基于TF-ⅠDF 和多头注意力Transformer模型的参数设置为:Maxlen 为20,训练次数为14,全连接层输出维度为3,优化器为Adam。将本文模型与LSTM、GRU、Att-BiLSTM 、Att-BiGRU、Transformer等模型进行对比,实验结果如图8 所示。相对于LSTM、 GRU 等算法,利用基于Transformer 模型算法处理情感分析不仅分类结果更加准确,在训练时间上也明显优于 LSTM、BGRU 等算法。
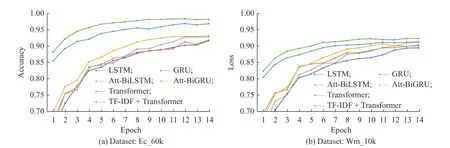
图8 不同模型的实验对比曲线Fig.8 Comparison curves of model experiments
以Ec_60k 数据集为例,本文模型的准确率达到了98.17%,比LSTM、GRU、Att-LSTM、Att-BGRU和Transformer 模型分别提高了6.51%、6.31%、5.41%、5.02%、1.33%。通过图8 可以看出,本模型第一次训练结束的准确率就明显高于其他几种文本情感分析模型。此外,从准确率的变化过程来看,本模型的收敛速度明显快于其他几组模型。同时实验均设置了不同文本评论数据集Wm_10k 作为对照组,凸显出本文算法的有效性,且在更大量数据集上有更优的表现。
为进一步验证评估本文提出的基于TF-ⅠDF 与多头注意力Transformer 文本情感分析模型的性能,将其与LSTM、Att-BiLSTM 等模型在情感分析任务中的精确率、召回率以及F1 值进行对比,结果如表2所示。本模型的文本情感分析模型在精确率、召回率及F1 值上都取得了最大值。

表2 不同模型的评价指标Table 2 Evaluation indicators of different model
4 结束语
构建了一种基于TF-ⅠDF 和多头注意力Transformer模型的文本情感分析模型。在文本预处理时,引入TF-ⅠDF 算法代替传统分词及去除停用词的工作,对评论文本中停用词进行过滤,进而将过滤后的文本向量化后,作为多头注意力Transformer 模型的输入进行训练及分类。通过在多类型评论文本的电商和外卖评论语料库上进行实验,证明了该方法处理多类型文本情感分类问题的可行性,相较于LSTM、GRU、Att-BiLSTM、Att-BiGRU 和Transformer 等模型,本文所提出的基于TF-ⅠDF 和多头注意力Transformer的文本情感分析模型可更准确地实现文本的情感分类。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
传媒评论(2017年3期)2017-06-13 09:18:10
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
语言与翻译(2015年4期)2015-07-18 11:07:45
