
基于双层自适应集成残差主成分分析的复杂非线性过程监测
2024-03-12 11:39:40唐徐佳卢伟鹏颜学峰
华东理工大学学报(自然科学版) 2024年1期
唐徐佳, 卢伟鹏, 颜学峰
(华东理工大学能源化工过程智能制造教育部重点实验室, 上海 200237)
随着科学技术的进步,工业过程的生产规模不断扩大并且生产环境变得更加复杂,人们对产品质量和安全生产提出了更高的要求,对复杂工业过程的监测尤为重要。工业分布式系统和传感器的广泛应用可以方便地收集大量数据[1],数据的存储和传输更加高效,为数据驱动方法提供了数据基础[2]。多元统计方法在实际故障监测中被广泛应用,其基本方法有主成分分析(Principal Component Analysis, PCA)、偏最小二乘法、独立成分分析和典型相关分析[3]。为了监测非线性工业过程,Lee 等[4]将核主成分分析(Kernel Principal Component Analysis, KPCA)应用于故障监测,而后基于该思想的监测方法相继被提出。然而,在实际过程中,变量的线性和非线性特征有着复杂的联系,需要进一步研究。为了解决这一问题,Jiang 等[5]提出了一种基于判别算法的并行PCA - KPCA 方法;首先将变量分为线性和非线性两类,接着对变量分别使用PCA 和KPCA 进行监测。Jiang 等[6]进一步解释为一些特征值大的特征可能对故障不敏感。
随着海量数据和日益复杂的工业流程,在线特征选择变得耗时。集成学习方法的出现为敏感特征提取提供了新的思路。集成建模的思想是通过形成和组合大量的基础模型来提高系统性能。利用不同的数据集提取不同的变量,采用不同的组合方法都可以形成差异化子模型。在过程监控领域,Li 等[7]使用了11 种不同核参数的基模型来监控复杂的非线性过程。Zhan 等[8]发现不同的局部和全局占比系数会影响系统性能,而后,整合不同局部全局比例参数的子模型,可以提高模型的监测效果。
基于上述分析,为了提取对当前故障最有效的特征,提出了一种基于PCA 和KPCA方法的集成模型,即自适应集成残差PCA (Adaptive Ensemble Residual Principal Component Analysis, AERPCA)。
1 核主成分分析
KPCA 是最常用的非线性过程监测方法,对于一个标准的数据集X∈Rn×m(其中n和m分别是样本数量及变量个数),对于第i个和第j个样本,核矩阵K计算如下:
其中:K需要中心化为,ker 代表核函数,常用的核函数是高斯核函数,新的特征可以通过以下方式得到:
其中:n表示样本个数, αi和di分别代表第i个特征向量和特征值。
通过计算累积百分率(Cumulative Percent Variance,CPV)方法,可以得到主成分数量kN。对于样本点s,样本数据xs∈Rm,其第i个主成分的计算方法为:
其中:t代表主成分;核向量ks∈Rn,其第i个元素为[ks]i=ker(xi,xs)。
为了进行系统监测,指标T2和Q分别用于主空间和残差空间的监控,对于样本点s,两个指标的计算式分别如下:
其中: Λ=diag(di) ,控制限和Qlim都是通过核密度估计(Kernel Density Estimation, KDE)[4]计算得来。
2 基于双层自适应集成残差PCA 的故障检测
2.1 双层自适应集成残差PCA
图1 示出了AERPCA 的整体结构,其中PL,dL表示将选出的特征放在前面,其余特征放在后面。图2 示出了每个残差空间对应的集成KPCA 子模型的计算步骤,其简化了KPCA 子模型的挑选步骤,其中PN,i,dN,i表示在第i个残差空间下KPCA 的特征值和特征向量。
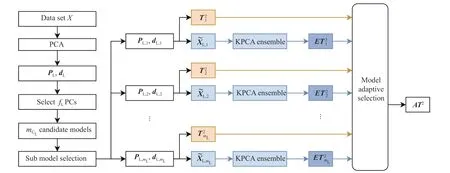
图1 AERPCA 的整体结构Fig.1 Overall structure of AERPCA
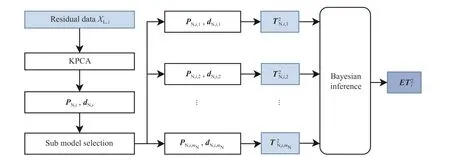
图2 集成KPCA 的结构Fig.2 Structure of KPCA integration
该模型主要由以下3 个步骤组成:(1)在主空间中生成mL个PCA 子模型;(2)在每个残差空间中生成对应的综合KPCA 子模型;(3)通过使用自适应算法选择最终模型。具体为:
(1)第1 层:PCA 特征层。对于第iL个PCA 子模型,随机选择fL个特征,用以形成主空间线性特征,剩余的残差空间线性特征组成。由=可获得由所选主成分(Principal Component, PC)所构成的得分矩阵,由此可将原始数据矩阵分解为以下两部分:
对于第iL个线性子模型,在样本点xs,其主空间的监测指标计算如下:
(2)第2 层:KPCA 特征层。考虑到有效信息分散在剩余空间中,为了聚集这些信息,就需要将提取得到的非线性特征做进一步划分,以形成KPCA 子模型。对于第j个KPCA 子模型,在样本点xs下,其监测指标为:
在获得用于聚集有效残差特征的残差子空间之后,使用贝叶斯集成来组合这些子空间以获得监测指标并监控整个残差空间。贝叶斯推理方法将监控结果与加权平均相结合,以获得最终概率结果[9]。在残差空间的新样本xs,其第j个KPCA 子模型发生故障的概率计算如下:
其中: F 和 N 分别表示异常和正常状态;p(F) 和p(N)分别表示异常和正常状态的先验概率,值分别为 1−α 和 α ; α 表示置信水平,通常为95%~99%。异常和正常状态的条件概率计算分别如下:
在获得所有mN个KPCA 子模型的后,第i个集成KPCA 子模型的监测指标计算如下:
2.2 差异子模型生成策略
在本模型中,所有PCA 和KPCA 子模型都是由差异子模型生成策略产生的。在本小节中,将以第iL个PCA 子模型为例,说明子模型的生成原理,其中1 ≤iL≤mL。
对于PCA 方法,通过分解协方差矩阵 Σ ,将得到特征向量矩阵和特征向量通过随机选择fL∈[1,m] 个具有相同权重且不同的特征向量来获得候选PCA 子模型。重复mCL次上述操作,其中mCL≫mL,可以获得mCL个候选PCA 子模型。
对于第iCL候选子模型,∈Rm表示挑选出的特征,其每个元素由0 和1 组成,其中1 表示相同位置的特征被选择,若该特征不被选择则值为0。表示两个子模型之间的差异。在生成mCL个候选子模型之后,通过筛选机制,挑选出差异最大的mL个PCA 子模型。
筛选机制采用了一种自底向上的层次聚类算法single-linkage clustering[10]。首先,将每个候选模型用作基模型,然后在算法的每个步骤中将两个最近的聚类进行聚合。其中,对于两个簇A和B,其距离可以由式(14)计算得来:
当达到预设的聚类数量即预期的子模型数量mL时,将在每个类别中随机选择一个代表性模型作为PCA 子模型。
2.3 自适应模型挑选策略
为了让每个子模型对最终指标具有相同的影响,就需要将mL个PCA 子模型和mL个集成KPCA子模型的监测指标标准化。对于i个PCA 子模型,标准化后的监测指标如下:
自适应模型选择的原理是:在该样本点的滑动窗口w中,选择具有最佳监测效果的模型。具体来说,使用故障检测数(Fault Detection Number, FDN)判断子模型的监测效果,如果子模型的故障报警率(Fault Alarm Rate, FAR)太高,那么此时的FDN 是无效的。因此,一部分验证数据被用来挑选出FAR ≤1−α的子模型。当没有达到窗口w的宽度时,则由所有模型的平均值作为此时的监测指标AT2。对于样本xs,自适应模型选择的公式为:
其 中 :best=index[max(FDN(pT12,s),FDN(PT22,s),···,FDN())],代表在区间 [s−w,s] 中具有最佳监测效果的模型编号。滑动窗口w是一个待定的参数,建议取值为 50 ∼250[11]。
2.4 AERPCA 故障检测步骤
2.4.1 离线建模阶段检测步骤
(1)训练集Xtr和验证集Xver标准化,并确定模型的相关参数:置信度 α 、自适应选择的窗口w、PCA 子模型的个数mL、每个残差空间的KPCA 子模型个数mN。
(2)由训练集Xtr计算得到协方差矩阵,而后对其特征值分解,以获得PCA 的特征向量矩阵PL和特征值向量dL。
(3)使用子模型生成策略,生成mL个PCA 子模型,而后计算每个子模型的负载矩阵、得分矩阵和残差空间,其中,i=1,2,···,mL。
(5)使用子模型生成策略,为每个残差空间产生mN个KPCA 子模型,而后使用贝叶斯集成这mN个子模型,以形成该空间下的监测指标。
(6)使用验证集Xver计算与,接着使用KDE 方法计算控制限。
(1)将在线数据标准化为Xte,而后输入到模型中。
(2)使用Xte计算每个PCA 子模型的监测指标和残差空间。
(4)使用式(15)~式(17),将PCA 子模型与集成KPCA 子模型集成起来,以形成最终的监测指标AT2。
(5)如果AT2>=1 ,代表故障已经发生了。
3 实验验证与分析
3.1 田纳西-伊士曼标准数据集
由文献[4]提出的基于真实工业过程的田纳西-伊士曼工厂(Tennessee Eastman Plant, TEP)过程已被学术界广泛用作标准测试平台。在过程数据中,有52 个变量和21 种故障,详细描述可在文献[12]中找到。数据集有两种,分别是500 个样本的正常数据和960 个样本的测试数据,如果该数据集包含故障,则故障在第161 个样本点引入。
本研究选择了22 个测量变量XMEAS(1)~XMEAS(22)和11 个操纵变量XMV(1)~XMV(11)进行监测。500 个样本的数据集用于训练模型参数,960 个样本的验证集用于确定子模型的控制限。KPCA、串行PCA (serial PCA, SPCA)、自适应残差PCA(Adaptive Residual PCA, ARPCA)和AERPCA 使用高斯核函数。文献[13]指出,核的宽度为c=500m时,将取得较好的性能,其中m代表变量个数。SPCA、KPCA、PCA 和ARPCA的PC 数量为CPV=85%时的数量。为了消除噪声的影响,选择CPV 为99.9%的特征作为备选特征,PCA和KPCA 的备选特征数分别为26 和60。表1 列出了通过试错法得到的AERPCA的具体参数。

表1 AERPCA 中的参数设置Table 1 Parameter setting of AERPCA
3.2 AERPCA 不同层级间的比较
通过模型不同层级间的比较实验,来显示每层特征选取与集成的作用,其比较实验结果如表2 所示。自适应PCA(Adaptive PCA, APCA)表示通过选择不同的线性特征形成不同的模型。ARPCA 表示将每个残差空间中的Q指标也作为子模型,监测指标为FAR 与FDR。根据TEP 数据的特点,可进一步定义为:
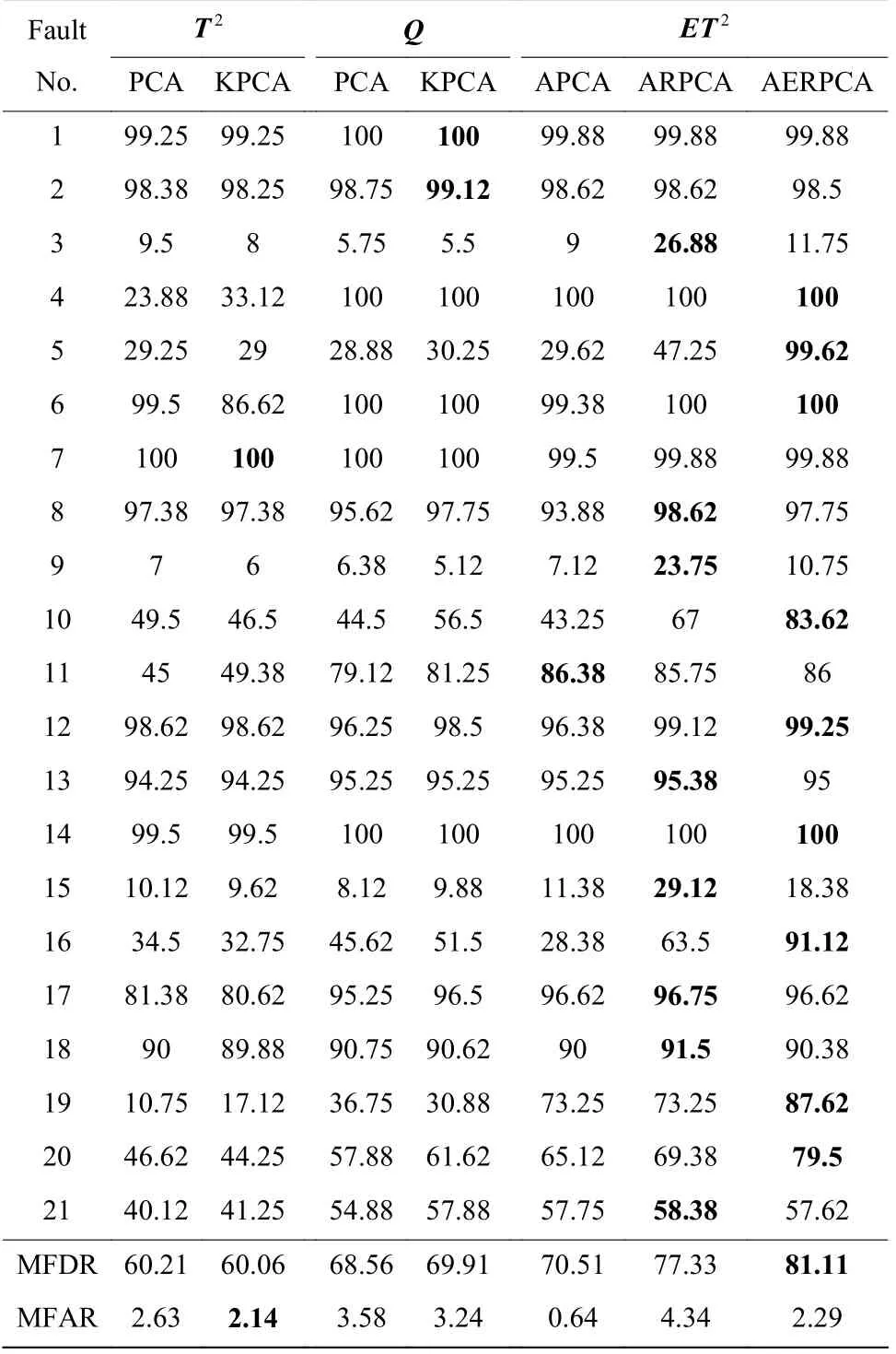
表2 每个层级之间的比较Table 2 Comparison between each level
其中 FF 和 TF 分别表示过程正常但被诊断为故障与过程有故障且被诊断为故障的样本数。MFDR(Mean FDR)和MFAR (Mean FAR)分别代表21 个故障的平均FDR 和FAR。
由表2 可知,首先,APCA 的检测效果优于PCA,PCA 使用正常运行数据来选择特征。而APCA 选择差异化的特征来形成模型,这样就可以选择特征值小但对故障敏感的特征。
其次,ARPCA 的检测效果优于仅集成PCA 主空间子模型的APCA。原因是APCA 的残差空间中的故障信息没有被使用。而某些故障在残差空间呈现,但在主空间中很难检测到。因此,在子模型中加入残差空间的监测,也有助于提高监测效果。
最后,AERPCA 的检测效果优于ARPCA。具体来说, AERPCA 的MFDR 比ARPCA 的MFDR 高3.78,而AERPCA 的MFAR 相比ARPCA 略微下降了2.05。在ARPCA 中,对故障敏感的特征在残差空间中的比例很小,这就降低了Q指标的故障监测效果。鉴于残差空间具有很强的非线性,KPCA 可以提取更有效的特征。
3.3 对故障10 的分析
故障10 是由物料温度导致的随机故障。图3和图4 分别显示了PCA、KPCA 和AERPCA 的监测图。在故障监测图中,蓝色表示正常状态,红色表示此时发生故障,虚线表示控制限,在PCA、KPCA 监测图中,Q指数的监测性能最好。AERPCA 进一步提高了监测性能:当误报率为1.2%时,83.6%的故障可以被发现。
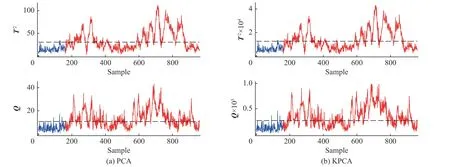
图3 TEP 故障F10 的监测图Fig.3 Monitoring charts for the TEP fault F10
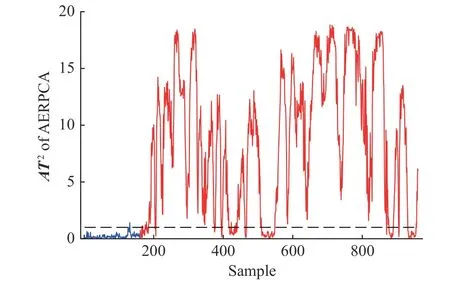
图4 TEP 故障F10 的AERPCA 监测图Fig.4 Monitoring charts of AERPCA for the TEP fault F10
为了进一步解释子模型的作用,图5 和图6 分别显示了自适应模型挑选策略选择的模型编号及每个子模型的监测图。其中图5 纵轴编号1~4 代表PCA 子模型1~4,5~8 代表集成KPCA 模型1~4。由图5 可见主空间的模型没有被选择。
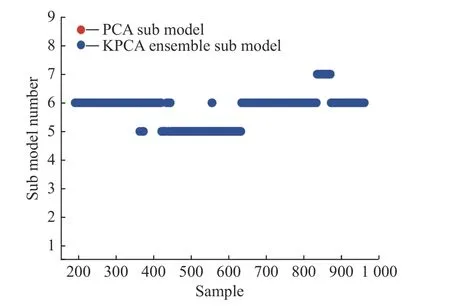
图5 TEP 故障F10 的自适应挑选子模型过程Fig.5 Adaptive process of each base model for the TEP fault F10
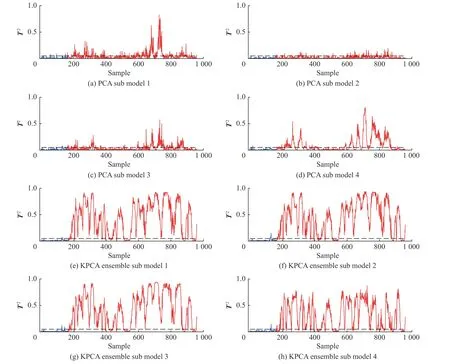
图6 TEP 故障F10 的每个子模型的监测图Fig.6 Monitoring charts of each sub-model for the TEP fault F10
与KPCA 和PCA 的监测图类似,刚开始主空间的监测效果也不理想。因此,自适应算法所选择的在线模型都来自于残差空间,而且在不同的时间选择不同的模型。为了进一步分析这种不同选择的原因,分别选择了样本453、454、455 和样本873、874、875,分析TEP 故障F10 在样本区间的监测图,如图7所示。

图7 TEP 故障F10 在不同样本区间的监测图Fig.7 Monitoring charts for the different sample intervals of the TEP fault F10
在453~455 区间,所有残差模型的监测效果都比主空间中的PCA 子模型效果明显。因此,在线挑选的是残差模型。然而,同一故障在不同的时刻会发生变化,因此并不是由一个特定的模型完成所有时间的监测,而是出现了模型间的切换,最终由不同的模型监测。对于873 号样本,选择了残差空间中的KPCA2。对于873、874、875 号样本,只有PCA3子模型和KPCA1 子模型可以同时监测这3 个样本点的故障。所选出来的残差模型更敏感,确实可以更好地监测当前过程。
3.4 相关方法实验对比
为了进一步验证所提出的AERPCA 模型的有效性,将该方法与经典的KPCA 集成方法(Ensemble KPCA (EKPCA)[7]和Ensemble Global Local Preserving Projections (EKGLPP)[8])进行比较,并同时比较了PCA 整合方法 (CPCA)[14],以及PCA和KPCA 组合方法如SPCA[15]。表3 示出了这些模型的MFAR 和MFDR,其中较好的数据用粗体字表示。
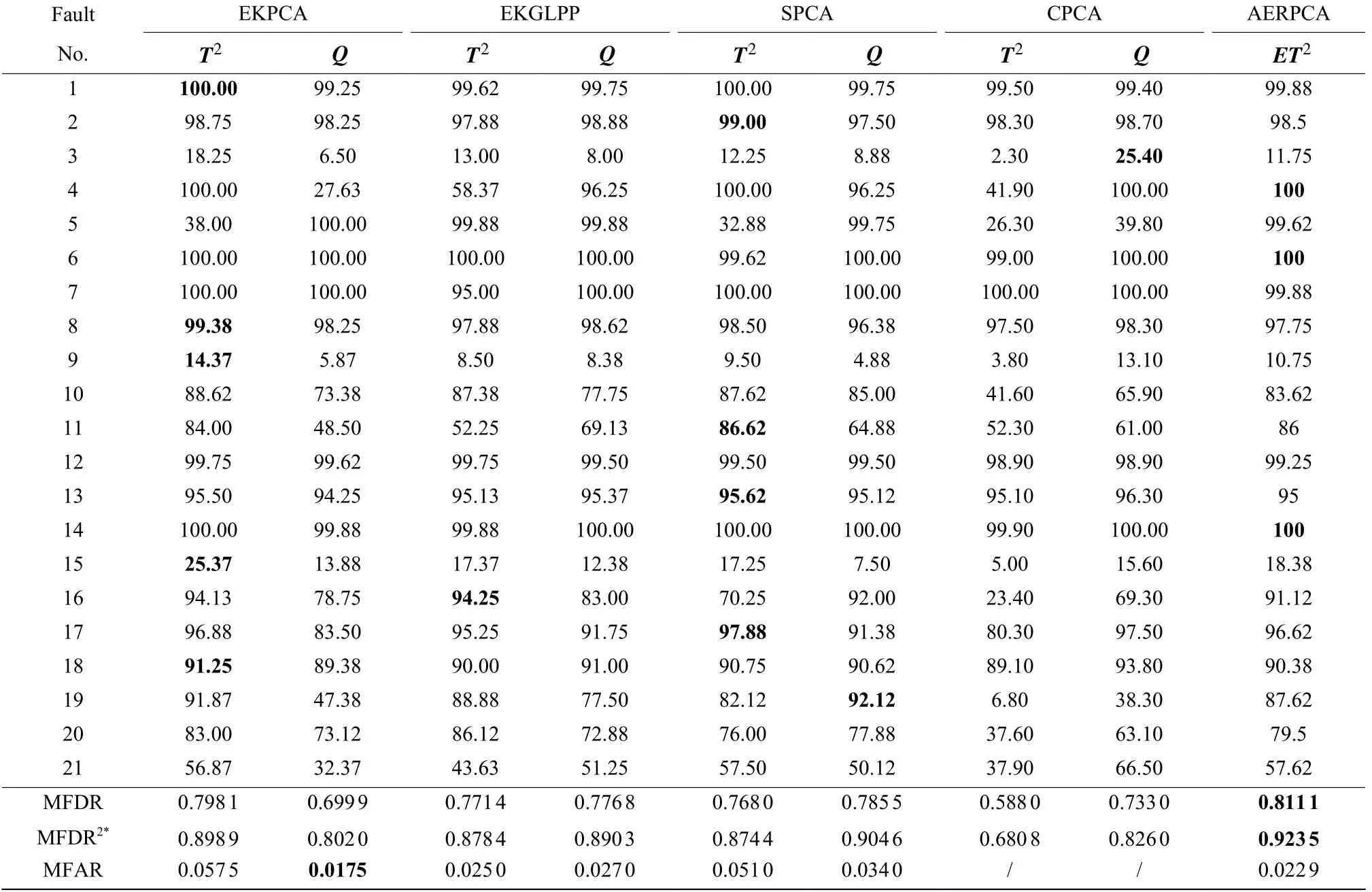
表3 相关方法实验对比Table 3 Result comparison with relevant methods
由表3 可知,SPCA 取得了良好的效果,在残差空间的MFDR 为78.55%。该方法使用PCA 和KPCA来表达特征信息。然而,基于离线数据的建模不能适应不断变化的故障。
CPCA 是PCA 集成方法,在残差空间有更好的识别效果。其MFDR 为73.30%,表明残差空间中存在更多的故障信息。然而,为残余空间建立一个整体的Q指数不能完全突出有效信息,而且可能会受到噪声的干扰。此外,仅从PCA 的角度提取故障信息并不适合监测复杂的工业过程。
EKPCA 和EKGLPP 是KPCA 的集成方法。与单一KPCA 相比,集成模型有一定优势。然而,与本研究中的方法相比,仅有KPCA 模型的集成有一定的缺陷。原因是KPCA 方法对某些故障信息的提取可能没有简单的PCA 方法好。在AERPCA 中,主空间的PCA 子模型是通过使用差异化的特征来构建的,每个残余空间都由差异化的KPCA 模型来监控。AERPCA 模型不仅从不同角度提取故障信息,而且还考虑了故障敏感特征,使用自适应算法,能够选择最符合当前故障的模型,因而获得了更好的结果。
4 结 论
本文提出了一种基于集成思想的双层特征提取模型AERPCA,以充分提取复杂工业过程中的故障信息。在双层特征提取中,首先选择不同的PCA 特征来构建子模型,以聚合具有小特征值却对故障敏感的特征。然后考虑到残差空间的有效特征分散与非线性,使用集成KPCA 模型完成残差空间的划分和聚合。在得到不同的特征组合后,采用自适应方法,根据在线数据选择具有最佳监测性能的模型。最后,不仅与自身不同层级间的实验比较,还与现有方法,如基于集成思想的模型和混合等方法进行了比较。实验结果显示了所提出模型在复杂工业监测中的优势。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
自动化学报(2019年6期)2019-07-23 01:18:32
当代陕西(2019年10期)2019-06-03 10:12:04
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
数学学习与研究(2017年3期)2017-03-09 18:12:42
中国老区建设(2016年1期)2016-02-28 09:32:00
