
大语言模型在中学历史学科中的应用测评分析
2024-03-12 04:07申丽萍何朝帆曹东旭朱云彬吴永和
现代教育技术 2024年2期
申丽萍 何朝帆 曹东旭 朱云彬 吴永和

摘要:大语言模型一经发布便获得广泛关注,但其在实际应用特别是教育领域的应用还存在诸多局限与挑战,因此需要对大语言模型在中文语境下的能力与风险进行测评。基于此,文章首先收集整理了一个包括10万条客观选择题与10套中学主观题测试卷的中学历史数据集,并在以ChatGPT、GPT-4和讯飞星火为代表的大语言模型上测试了该数据集中题目的回答表现。然后,文章详细分析了测试结果,发现虽然当前大语言模型的突出能力在于能够产生完整且流畅的表达,但其在中学历史知识测试中仍远低于适龄学生的平均水平,大语言模型应用于教育领域仍存在可靠性较差、可信度较低、具有偏见与歧视、推理能力不足、无法自动更新知识等问题。最后,文章针对大语言模型在中文语境下教育领域的应用提出建议,以期助力大语言模型在教育领域发挥更大的作用,为学生、教师带来更好的学习和教学体验。
关键词:大语言模型;ChatGPT;讯飞星火;教育应用;测评
【中图分类号】G40-057 【文献标识码】A 【论文编号】1009—8097(2024)02—0062—10 【DOI】10.3969/j.issn.1009-8097.2024.02.007
引言
自2022年11月30日美国人工智能研究公司OpenAI发布生成式交互工具ChatGPT以来[1],生成式大语言模型(Large Language Models,LLM)迅速进入主流,引起了前所未有的关注,国内外各大AI科技巨头也纷纷投入其中,相继发布各自的LLM。LLM通过模拟人类的语言交流,进行文本生成、代码生成和图像生成,深刻地影响着人类的生产生活方式,其应用场景非常广泛[2],包括问答功能、多语言润色与翻译、教育功能、内容概述等[3],可以帮助用户提高工作效率、生活质量和服务质量,帮助企业提高客户满意度和忠诚度、产品的竞争力和市场占有率[4]。然而,在进行实际应用时LLM仍存在一些局限和挑战,其生成内容包含较大的不可解释性和不稳定性,在安全、隐私和伦理方面也具有较大风险,这引起了全球范围内的关注和担忧。特别是在教育领域,以上局限会引发教育生态的潜在风险,包括知识异化的风险、学生主体性异化的风险、教学过程异化的风险、数字伦理风险、数字教育治理风险等[5]。
对此,美国教育部于2023年5月发布人工智能教育报告《人工智能与教学的未来》,指出针对当前人工智能在教育領域的大规模应用风险制定政策法规是当务之急[6]。同年6月,全国信息技术标准化技术委员会教育技术分技术委员会暨教育教育技术标准化委员会批准成立“教育通用人工智能大模型”系列标准工作组,以制定相关框架、数据、测评和安全标准,促进我国可信、安全、高效、好用的教育通用人工智能大模型的发展。除了相关的政策制定,大量国内外研究还对以ChatGPT为代表的LLM进行了传统自然语言任务和各种考试能力的测评[7][8],试图量化LLM的应用能力与风险,但这些测评大多以英文为主,中文语境下教育领域的测评还相当缺乏[9],其在中文语境下教育领域的测评效果与风险还有待验证。为此,本研究以中学历史学科为例,通过收集整理超过10万条客观选择题和10套中学主观题测试卷的中学历史数据集,对ChatGPT、GPT-4等LLM在历史知识掌握、审题、主客观答题等方面的能力进行测评和比较,分析大语言模型在历史学科中的应用成效与不足,为其在中文语境下教育领域的实际应用提供参考与指导。
一 研究现状
当前,ChatGPT、讯飞星火等一系列大语言模型在已有的公开自然语言数据集上都展现出了优秀的甚至最好的结果[10]。然而,这类传统数据集可能已不再适用于评估LLM或已被其用于训练,因此有大量研究者尝试使用真实的人类考试题目对LLM进行测评。例如,GPT-4参加了美国律师资格考试Uniform Bar Exam、法学院入学考试LSAT、美国高考SAT数学部分和阅读与写作考试等。在这些考试中,GPT-4的得分高于88%的人类应试者[11]。但LLM也并非全能,其在一致性、错误示例响应以及逻辑推理等方面仍有待提高,如Borji[12]对ChatGPT的错误进行了全面分析,并总结出主要的错误类型,包括推理逻辑混乱、事实错误、数学与编码能力较差和容易输出偏见内容等。
随着LLM在英文数据集上的评测已日趋成熟,其在中文数据集上的评测也逐渐进入研究者的视野,如有研究者测试和对比了ChatGPT[13]、文心一言[14]、盘古[15]、WeLM[16]、LaMDA[17]在中文情感分析、自动摘要、阅读理解和闭卷问答上的性能表现,并测评了ChatGPT在中文语境下的问答知识错误和风险,以及错误混淆、事实不一致等诸多风险,认为ChatGPT在自然语言处理的经典任务中表现较好,但在闭卷问答方面出现错误的概率较高。此外,复旦大学研究团队创建的评估大语言模型语言理解能力和逻辑推理能力的测评框架GAOKAO-bench收集了2010~2022年全国高考卷的题目,但仅包括1781道客观题和1030道主观题。可见,LLM在中文语境下教育领域的测评仍然不足。
二 研究设计
为填补LLM中文教育领域测评研究匮乏的现状,本研究尝试通过中学历史题测评多个大语言模型在教育领域的应用能力与局限。
1 测评数据集
本研究从作业帮、百度题库等知名教辅资料网站分别搜集了国内中学历史(包括初中和高中历史)的客观选择题超过10万条,并与来自上海不同知名中学的两位资深初高中历史老师开展深度合作,获得原创初、高中试卷(以主观题为主)各10套,形成了一个用于测评LLM的中学历史数据集,具体如下:
(1)客观选择题
本研究首先从教辅资料网站分别获取初、高中历史客观选择题约10万多条。考虑到ChatGPT仅支持纯文本形式输入,本研究删除了带图片以及重复的题目,验证筛选了初中题目6万多条和高中题目8万多条(如表1所示),其中包含答案解析的初、高中题目分别有2万多条、5万多条。每个客观选择题包含问题描述、选项、正确答案、背景知识、题目解析(可选)等。其中,问题描述的长度一般不会超过50个中文字符,选项一般包含4个,且每个选项的长度平均为10个中文字符。客观选择题主要通过判断和引用历史事实以及分类、判断、总结考察大模型的知识储备能力和逻辑推理能力。
(2)主观题
本研究与上海两所知名中学开展合作,分别设计了初中、高中历史学科的测试卷各10套,筛选出初中题目41条,高中题目58条,共99条。每道主观题一般提供4~5个相关材料,并围绕材料和中学教育的知识点设计3个小题,以对大语言模型学习能力、知识掌握能力、材料阅读和知识归纳概括能力进行综合量化测评。
2 测评方法
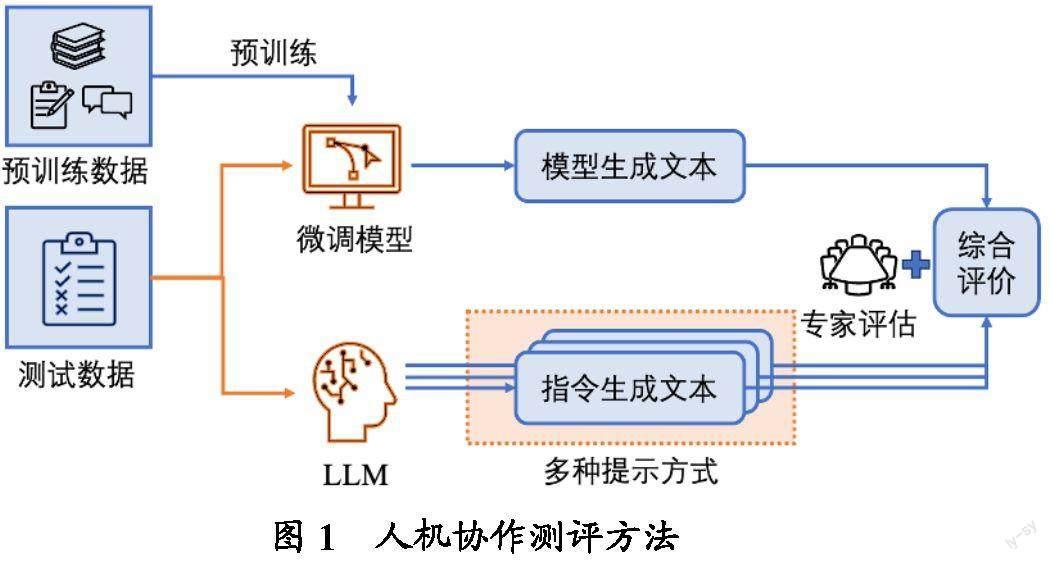
本研究设计了一种人机协作测评方法,如图1所示。其中,客观选择题主要基于微调模型和LLM进行自动评测,主观题主要基于专家进行评估。
(1)客观选择题测评方法
对于客观选择题,其答案确定并唯一,只需判断模型是否输出了正确选项,因此针对这种题型可采用简单、高效的大规模自动测评。由于目前还无法访问GPT-4和讯飞星火的API,因此本研究只测试了ChatGPT的答题情况,并针对答题准确率进行统计和分析。考虑到生成式大语言模型无法对历史学科数据集进行训练或微调,本研究将它与深度学习预训练-微调语言模型(Bert、Roberta、T5)进行比较。例如,本研究使用历史客观选择题数据集作为一项分类任务微调预训练语言模型,使其将题目选项作为分类标签,对比其与大语言模型在测试数据集上的准确率。
另外,本研究希望进行更有启发性的实验,使大语言模型更好地应用于中文教育领域,因此进行了知识融合的测试,即在提问中添加相关的知识点,以测评大语言模型在给定相关知识情况下的理解能力是否有提升。
由于生成式语言模型的本质仍然是概率模型,因此即使输入相同,每次生成的输出也可能完全不同。如果模型每次生成的答案都一样,那么模型对该答案的确信度就是100%。基于此定义,本研究进行了大语言模型对答案确信度的分析,即多次相同输入的多数决采样测试,来判断ChatGPT答案的随机性或确信度。
(2)主观题测评方法
不同于客观选择题的自动测评,主观题由专业老师进行评阅和打分。主观题同时测试ChatGPT和New Bing/GPT-4的性能,从以下五个方面进行评分:
①得分率,即该题的分数,评价方式与批改学生试卷一致。
②知识点完整性(踩点率),即回答覆盖标准答案的给分点数量。
③史实错误率,即回答中是否存在历史事实和知识点的错误。
④逻辑合理性,即回答是否清晰易懂、逻辑是否合理,而与回答的正确性无关。
⑤语言自然通顺性,即语言表达是否自然通顺,是否符合中文的表达习惯,是否存在语法、拼写等方面的错误。
除此之外,ChatGPT、New Bing/GPT-4以及讯飞星火分别参加了初、高中在校生的一次模拟考试。阅卷时,教师知道哪些是LLM完成的试卷,但并不知道具体由哪一个模型完成,以此测评ChatGPT、New Bing/GPT-4和讯飞星火的答题能力及其对应的学生层次。
三 研究结果与分析
1 客观选择题的结果
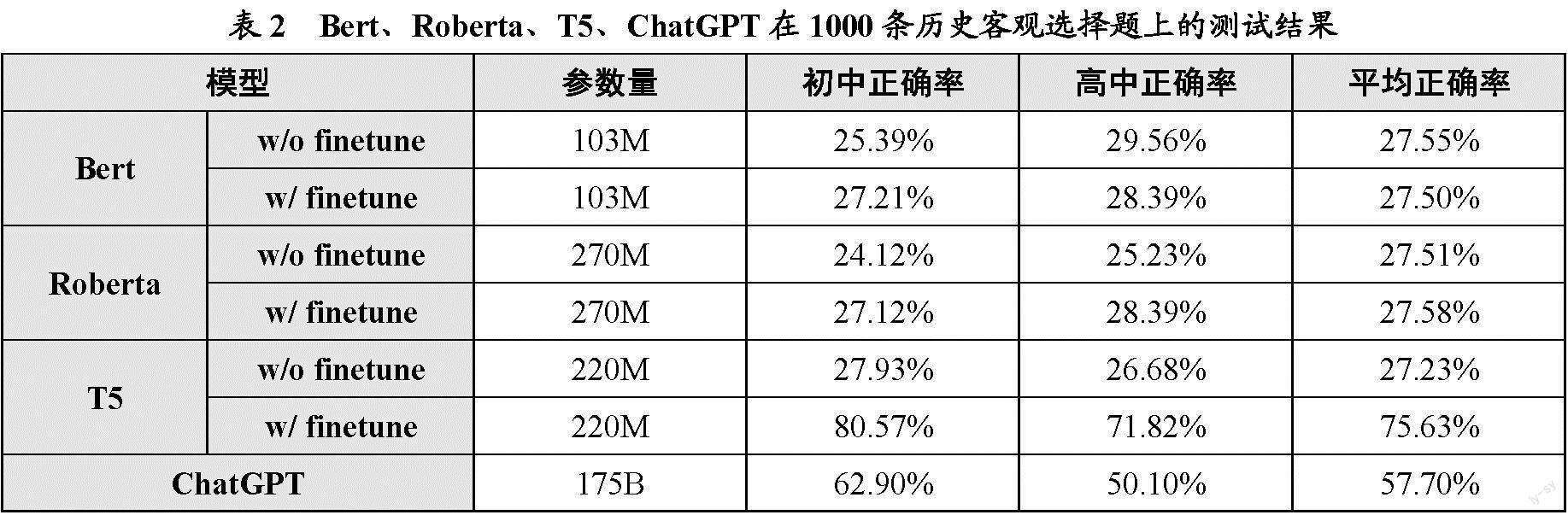
根据上述测评方法,本研究对比了LLM与预训练-微调模型在历史客观选择题上的测试结果,即Bert、Roberta、T5、ChatGPT在1000条历史客观选择题上的测试结果,如表2所示。其中,预训练模型结果中同时给出了使用微调(w/ finetune)和不使用微调(w/o finetune)的结果。微调数据集使用总数据集中筛选出不包含1000条测试集的约8万个样本。由表2的测试结果可知,在不经过训练的情况下,ChatGPT的参数量最多,且表现最佳:在初中题目上有超过60%的正确率,在高中题目上也有高于50%的正确率,平均正确率约为57%。用历史客观选择题对Bert、Roberta、T5三个模型进行微调之后,Bert、Roberta几乎没有提升,T5的准确率大幅提高,平均达到75.63%。
融合知识是将相关知识直接添加到提问中用于辅助大语言模型作答,包括详细的题目解析和题目背景两种知识。表3是ChatGPT对两种知识融合方式在初、高中各1000题上的测试结果,可以看出:在提问时增加一定的相关知识会提高ChatGPT的性能,特别是在融合详细题目解析时,初中客观选择题的正确率从62.9%提升到了91.7%,高中客观选择题的正确率从50.1%提升到了68.5%。
表4展示了ChatGPT回答确信度的测試结果。本研究对初、高中各500题分别进行三次相同输入,结果表明三次生成答案相同的分别只有54.8%、42.4%;其中,回答正确的占比更低,高中题目中ChatGPT回答的三次生成答案相同且回答正确的仅占三成。可见,ChatGPT的答案生成还不够稳定,其确信度还有待提高。
2 主观题的结果
除客观选择题外,本研究还同时对ChatGPT和New Bing/GPT-4针对初、高中试卷主观题的答题能力进行了评测。由于评阅初中卷和高中卷的老师不同,两者的主观题试卷难度并没有可比性,因此本研究主要关注同一年级试卷中ChatGPT和New Bing/GPT-4模型的结果对比情况,并进行了分析。
ChatGPT与GPT-4主观题的测试结果如表5所示,可以看出:ChatGPT与New Bing/GPT-4在答题得分率上的表现皆不尽如人意。虽然GPT-4的得分率在初中水平测试中获得了大幅的提升,但踩点率相比于ChatGPT却下降了很多,这也体现了New Bing/GPT-4在答题上的保守性(在保证正确率的前提下再丰富作答角度)。在史实错误率上,New Bing/GPT-4得益于联网搜索和更完善的模型,相较于ChatGPT有更加精确的史料引用能力,错误率大大降低,这也直接提升了New Bing/GPT-4逻辑推导的合理性。两个模型的逻辑合理性和语言自然通顺性都达到了较高的水平,能包含基本的论点、论据和结论,以对材料进行较强的总结和记忆,并通顺、自然地表达观点。
3 模拟考试的结果
为了测评大型语言模型的答题能力是否与适龄学生相当,本研究选用三个大语言模型——ChatGPT、New Bing/GPT-4、讯飞星火,在完全相同的环境下分别面向初、高中学生开展模拟考试,其成绩与排名如图2所示。其中,图2(a)为初中卷得分分布统计表,纵轴表示分数,满分30分;横轴表示按分数高低排序后的学生序号。图2(b)为高中卷得分分布统计表,纵轴表示分数,满分100分;横轴表示按分数高低排序后的学生序号。
由图2可知,ChatGPT、New Bing/GPT-4、讯飞星火在初中卷的得分情况比较接近,而高中卷中New Bing/GPT-4的成绩遥遥领先于ChatGPT和讯飞星火。但遗憾的是,三者的整体排名相对比较靠后,在初中共137位被测者(134位被测学生与3个被测模型)中,三个模型的排名分别为:New Bing/GPT-4、ChatGPT排名122,讯飞星火排名128;而在高中89位被测者(86位被测学生与3个被测模型)中,三个模型的排名分别为:New Bing/GPT-4排名60、ChatGPT排名84、讯飞星火排名86。
4 讨论与分析
从以上结果可知,当前LLM的突出优势在于其能够产生完整且流畅的表达,且语法和写作能力已接近甚至超过人类的平均水平,但在中学历史知识测试中仍然远远低于适龄学生的平均水平,并低于微调后的中型预训练生成模型。本次测评结果反映了LLM存在易输出偏见内容、不可靠性、低可信度、逻辑推理能力不足、数据具有时限性等问题,大模型典型错误案例如表6所示。
①偏易输出偏见内容。LLM训练数据的全球性,从根本上决定了其价值观不可能与我国社会的主流价值观完全一致。例如,针对表6的问题1,ChatGPT的回答是维护人权,GPT-4的回答是支持科索沃独立,而正确答案应为加强对巴尔干的控制。
②不可靠性。在测试的99个主观历史题目中,ChatGPT的38条回答出现了不同程度的历史事实错误或史实捏造。例如,针对表6的问题2,GPT-4和ChatGPT都无法正确回答“两弹一星”具体所指的内容,正确答案应为原子弹、导弹、人造卫星。
③低可信度。在对500道高中客观选择题进行三次相同输入,ChatGPT回答的三次生成答案相同的比例约占42.4%,其中只有30%的答案相同且回答正确,如表4所示。可见,ChatGPT的答案生成还不够稳定,其确信度还有待提高。
④逻辑推理能力不足。虽然GPT-4表现了比ChatGPT、讯飞星火更强的推理能力,但与本研究合作的上海知名中学的两位历史老师认为,对于历史学科而言,GPT-4的很多回答并没有聚焦核心史实的论证,也较少联系材料,虽然其能够辩证地看待观点分析的题目,但是缺乏对深层次观点的关注和论证。例如,针对表6的问题3,ChatGPT忽略了“导致清朝北洋舰队全军覆没的战役”和“威海卫战役”之间的强关联。
⑤数据具有时限性。LLM的知识完全来源于所训练的数据,它无法感知世界,无法自动更新知识,因此无法回答超出训练数据截止日期之后的事件和知识。例如,针对表6的问题4,ChatGPT和GPT-4明确表示无法回答2021年9月之后的事件;讯飞星火训练数据的截止日期未知,也同样无法回答2022年11月11日的事件。
四 总结与建议
本研究以中学历史学科为例,探讨了大语言模型在教育领域的应用能力与存在的局限,通过收集整理超过10万条题目的中学历史客观测试数据集和原创初、高中主观题试卷,在以ChatGPT、GPT-4和讯飞星火为代表的LLM模型上进行了大量实验和分析。结果表明,当前LLM的突出能力在于其能够产生完整且流畅的表达,其语法和写作能力已接近甚至超过人类平均水平,但在中学历史知识测试中仍然远远低于适龄学生的平均水平,在知识储备、逻辑推理等方面还存在提升空间。在教育领域,LLM出色的文本生成能力,可以用于学生的学习和教师的辅助教学,因此在应用时应该趋利避害,用积极的批判态度去拥抱代表更高生产力的新技术。针对LLM在中文语境下教育领域的应用,本研究提出以下建议:
①学生方面,可以合理利用LLM提供的建议、思路或提示,但不建议完全照搬大语言模型的输出结果。特别是对于低年级、低龄段的学生,大量的生成文本会含有冗余或完全错误的内容,甚至会突出中西方價值观的差异,这些都非常容易误导学生,使其在学习过程中产生疑惑。因此,学生在使用LLM进行学习的过程中要学会运用批判性思维,分辨是非曲直。对此,大模型是一个非常好的对话工具,能够循循善诱地为学生答疑解惑,提供引导式的学习体验和跨学科知识的支持。
②教师方面,需尽可能发挥LLM的辅助教学作用。在99道主观题中,ChatGPT在8个回答中正确引用了超出课本的知识和史料记载等,因此可以在教学过程中将其作为辅助的教学材料,对课堂教学进行补充。在能够判断大语言模型的回答是否正确的前提下,使用大语言模型进行批判性的知识索引和审查可以提高教师的教学水平。其中,GPT-4的理论性更强,答题的正确率较高,因此可以提供更多的教学和解题思路。此外,大模型具有强大的语言理解和生成能力,可以帮助教师进行作文批改,从而为学生提供个性化的分析与指导,实现对学生的因材施教。
③科研人员方面,解决LLM存在的诸多局限和问题是重要的研究任务。教育是特殊的应用领域,具有知识准确性、意识形态正确性、过程可解释性等要求。要达到这样的目标还有大量的工作尚待完成,如获取特定的学科相关训练数据、融合学科知识图谱、保护用户隐私数据、去除有害的或存在偏见的内容等。当前科研人员亟须解决LLM存在的诸多局限和问题,探索数字教育与智能教育的新范式,通过构建可控、可信、安全、绿色、好用、高效的教育通用人工智能大模型,建立有教育温度、以育人为本的人工智能及其智能教育环境,才能更好地赋能、赋智教育,推进教育数字化发展。
④管理人员方面,需要制定相应的政策和标准,规范LLM功能、框架、数据和评测标准,防止LLM在教育产品中的滥用。虽然对于LLM在中文语境下教育领域应用的研究正在不断推进,但是如何保证应用过程中的规范性同样重要,这就需要管理人员针对LLM的相关使用规则做出明确规定,引导正确的研究和应用方向,从而推动构建适应未来世界的教育模式,形成“思维比知道重要、问题比答案重要、逻辑比罗列重要”的学习评价新思维[18]。
综上所述,LLM在中文语境下教育领域的应用既面临挑战,也有较大的发展潜力。通过解决模型的不足,不斷优化模型,并与教育大数据对齐,可以让大模型才能更好地赋能、赋智教育。期待大语言模型在教育领域发挥更大的作用,为学生和教师带来更好的学习与教学体验。
参考文献
[1]Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. Advances in Neural Information Processing Systems, 2022,35:27730-27744.
[2]Bubeck S, Chandrasekaran V, Eldan R, et al. Sparks of artificial general intelligence: Early experiments with GPT-4[OL].
[3]Park J S, OBrien J, Cai C J, et al. Generative agents: Interactive simulacra of human behavior[A]. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology[C]. 2023:1-22.
[4]Eloundou T, Manning S, Mishkin P, et al. GPTs are GPTs: An early look at the labor market impact potential of large language models[OL].
[5][9][13]张华平,李林翰,李春锦.ChatGPT中文性能测评与风险应对[J].数据分析与知识发现,2023,(3):16-25.
[6]US Department of Education. AI and the future of teaching and learning: Insights and recommendations[OL].
[7][10]Zhao W X, Zhou K, Li J, et al. A survey of large language models[OL].
[8]Nunes D, Primi R, Pires R, et al. Evaluating GPT-3.5 and GPT-4 models on Brazilian university admission exams[OL].
[11]OpenAI. GPT-4 technical report[OL].
[12]Zeng W, Ren X, Su T, et al. Pangu-α: Large-scale autoregressive pretrained Chinese language models with auto-parallel computation[OL].
[14]Wang S, Sun Y, Xiang Y, et al. Ernie 3.0 titan: Exploring larger-scale knowledge enhanced pre-training for language understanding and generation[OL].
[15]Zeng W, Ren X, Su T, et al. Pangu-α: Large-scale autoregressive pretrained Chinese language models with auto-parallel computation[OL].
[16]Su H, Zhou X, Yu H, et al. Welm: A well-read pre-trained language model for Chinese[OL].
[17]Thoppilan R, De Freitas D, Hall J, et al. Lamda: Language models for dialog applications[OL].
[18]沈書生,祝智庭.ChatGPT类产品:内在机制及其对学习评价的影响[J].中国远程教育,2023,(4):8-15.
Evaluation and Analysis of Large Language Models Application in of Historical Discipline Middle Schools
Abstract: Large language models (LLMs) have received wide attention since its release, while there are still many limitations and challenges in their practical application, especially in the field of education. Therefore, it is necessary to evaluate the capability and risk of LLMs in the Chinese context. Based on this, this paper firstly collected and sorted out a historical dataset for middle school students including more than 100,000 objective multiple choice questions and 10 sets of subjective questions, and tested the answer performances of the questions in the data set of the LLMs represented by ChatGPT, GPT-4 and IFLYTEK Spark. Then, the paper analyzed the test results in detail and found that although the outstanding ability of the current LLMs lay in its ability to produce complete and fluent expression, and its performance in the history knowledge test of middle school was still far below the average level of school-age students.
The application of LLMs in education still had some problems: such as poor reliability, low credibility, prejudice and discrimination, insufficient reasoning ability and inability to update knowledge automatically. Finally, some suggestions were proposed for the application of LLMs in the field of education in the Chinese context, in order to help LLMs play a greater role in the educational field and bring better learning and teaching experience for students and teachers.
Keywords: large language models, ChatGPT, IFLYTEK Spark, education applicational, evaluation and analysis
猜你喜欢
演艺科技(2016年11期)2016-12-24
演艺科技(2016年4期)2016-11-16
电脑知识与技术(2016年24期)2016-11-14
商(2016年30期)2016-11-09
考试周刊(2016年71期)2016-09-20
考试周刊(2016年44期)2016-06-21
考试周刊(2016年34期)2016-05-28
