
基于CTSA-Net的急性肾损伤风险预测研究
2024-03-09 01:34张青松陈春晓陈利海
生物医学工程研究 2024年1期
张青松, 陈春晓 △,陈利海
(1.南京航空航天大学 生物医学工程系,南京 211106;2.南京市第一医院麻醉科,南京 210006)
0 引言
急性肾损伤(acute kidney injury, AKI)是重症监护病房(intensive care unit, ICU)中常见的异质性并发症之一[1-2]。AKI不仅是患者死亡的独立危险因素之一[3-6],还与住院时间及住院费用的增加高度相关[7-8]。
AKI通常被定义为血清肌酐的显著升高或尿量的显著减少[9-12]。总体而言,AKI是一种异质性疾病,发病机制复杂[13],涉及多种危险因素[2,14]。因此,充分利用临床数据,构建预测模型对AKI高风险患者进行早期识别、降低AKI的发生率及改善患者预后[13-16]具有重要意义。
随着医疗信息数字化技术的发展,电子健康记录(electronic health record, EHR)系统构建了规模庞大且复杂的医学数据库。机器学习作为大数据分析的有效方法也被逐渐应用于AKI的风险预测。Koyner等[17]收集了30多万条住院病例的EHR数据,基于梯度提升决策树法构建模型,在发病前24和48 h预测2期或以上AKI的受试者工作特征曲线下面积(area under the receiver operating characteristic curve, AUC)分别为0.90和0.87。Petrosyan等[18]构建了一种随机森林和传统逻辑回归混合预测模型,基于心脏手术患者的术前参数构建模型,对1期及以上AKI预测的AUC为0.74。然而,患者入院后的各种生理参数常随时间发生变化,基于机器学习的模型利用参数的静态值,忽视了数据的时间依赖性。
近年来,深度学习在时间序列分析领域取得了迅速发展,也被逐渐应用于AKI预测。Tomašev等[19]基于循环神经网络(recurrent neural network, RNN)模型对患者的血清肌酐变化进行预测,预测患者48 h内发生AKI风险的正确率为55.8%。Alfieri等[20]使用ICU患者的尿量数据构建卷积神经网络(convolutional neural networks, CNN)模型,对2期以上AKI提前12 h预测的AUC为0.89。然而,血清肌酐和尿量均为AKI的晚期非特异性标志物,预测AKI时通常还需考虑其他风险因素。Pan等[21]基于RNN提出一种自校正机制和正则化方法,在公开数据集MIMIC-Ⅲ和Philips eICU上的AUC分别为0.893和0.871,但是提前预测窗口较短。Rank等[22]纳入心胸外科手术后患者的96种临床参数,对2期或以上AKI进行连续预测,总体AUC为0.893,优于临床医生的表现,但该研究并未纳入1期AKI。
上述研究结果表明,深度学习在AKI预测方面具有巨大潜力,但仍存在EHR数据未被充分利用、提前预测窗口较短及缺少连续预测等不足。因此,本研究基于MIMIC-III数据库的患者数据,提出了一种CNN和两阶段交叉注意力的混合网络模型(convolutional and two-stage attention network, CTSA-Net),实现对1期及以上AKI的每小时连续预测。模型的两阶段交叉注意力支路、CNN支路及特征融合模块可增强对时间序列数据的全局表示以及局部细节的感知能力,从而充分利用两种特征的优势,提高对AKI的连续预测性能。
1 材料和方法
1.1 研究人群
本研究使用MIMIC-III数据库[23]验证模型性能,该数据库由美国麻省理工学院计算生理学实验室发布,记录了2001~2012年期间五万余名ICU患者的数据。本研究作者取得由美国国立卫生研究院的《保护人类研究受试者》培训课程证书(编号:57111944),申请并获得使用MIMIC-III数据库的权限,豁免患者知情同意。
1.2 患者选择及标签划定
纳入标准:(1)年龄在18~90岁的患者;(2)患者首次入住ICU的记录;(3)在ICU停留时间大于等于48 h且小于等于60 d的患者;(4)基线肌酐值,即入住ICU前最后一次测量的血清肌酐值低于4 mg/dL的患者。
排除标准:(1)人口统计学信息存在缺失的患者;(2)ICU期间无尿量记录或血清肌酐测量的患者,或存在连续缺失10%以上的患者。
根据KDIGO的诊断和分期标准,符合以下情况之一的患者即可被诊断为AKI(1期或以上):(1)48 h内血清肌酐升高超过26.5 μmol/L(0.3 mg/dL);(2)7 d内血清肌酐升高超过基线1.5倍;(3)尿量持续6 h以上小于0.5 mL/(kg·h)。在本研究中,符合该标准的患者标签被划定为阳性,否则为阴性。最终,本研究纳入6 884名患者,其中阳性4 790例,阴性2 094例。每例患者的观察时间从进入ICU开始,到患者出院、满足阳性标准或入住ICU满7 d为止。
1.3 纳入参数选择及数据预处理
在专业医生的指导下,本研究从MIMIC-III数据库中纳入47个与AKI发生潜在相关的临床参数构建模型。所有的输入参数及其分组下:
(1)人口统计学(2种,静态):性别、年龄;
(2)生命体征(8种,时间序列):心率、呼吸率、体温、外周氧饱和度、血糖水平、收缩压、舒张压、平均动脉压;
(3)实验室检查(18种,时间序列):肌酐、白细胞计数、血红蛋白、红细胞比容、血小板、氯化物、血尿素氮、碳酸氢盐、pH、氧分压、二氧化碳分压、钾、葡萄糖、镁、部分凝血活酶时间、凝血酶原时间、红细胞计数、国际标准化比率;
(4)流体(1种,时间序列):尿量;
(5)合并症(14种,静态):充血性心力衰竭、冠心病、先天性心脏病、瓣膜性心脏病、心房纤颤、高血压、慢性阻塞性肺病、糖尿病、肾病、肝病、动脉瘤、淋巴瘤、肥胖、贫血;
(6)用药(4种,动态):利尿剂、非甾体抗炎药、血管加压药、镇静剂。
本研究对人口统计学和合并症中的静态参数进行二进制编码。对于生命体征、实验室检查及尿量等时间序列参数,使用线性插值填充缺失值。由于患者用药时间随机,因此,本研究对其进行二进制编码,在药物施用后,立即在单个时间点处将其值设置为1。针对所有的时间序列参数,按照式(1)进行缩放,并按照式(2)进行归一化,以减轻数据中异常值的影响。
(1)
(2)
其中,Max(Xscaled)、Min(Xscaled)分别为缩放后所有值的最大和最小值。
对于提取的时间序列参数,将数据统一间隔为1 h,并对缺失值进行线性插值。此外,对序列尾部进行填充,以统一序列长度,并在模型中对填充的无关值进行掩膜处理。
1.4 CTSA-Net模型
本研究提出的CTSA-Net急性肾损伤预测模型整体结构见图1。该模型的两个并行支路用于提取多维时间序列输入的不同风格特征。同时,在两个支路间使用特征融合模块进行特征耦合。最后,对两个分支的分类器输出加权求和,获得最终预测结果。

图1 注意力支路、CNN支路和特征融合模块实现细节
1.4.1注意力支路 注意力支路使用块嵌入方式对序列进行块划分,不仅可减少输入特征向量的数量,降低模型复杂度,还可以保持时间序列的局部性。具体细节见图2。按照一定的窗口与步长将序列划分成多个块后,进行正余弦位置编码,嵌入位置信息。同时,使用卷积及长短期记忆单元进行特征提取,得到词嵌入向量。最终,融合位置嵌入和词嵌入向量输出块的特征。
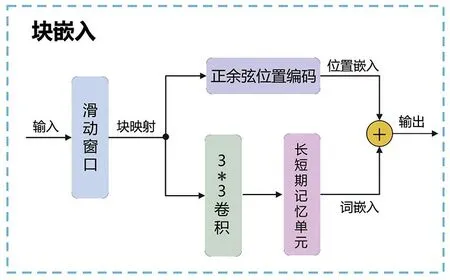
图2 块嵌入
两阶段注意力包括时间注意力和维度注意力,见图3。时间注意力阶段以块嵌入的输出作为输入,对于D维时间序列中第d维度所有时间步的向量X:,d,对每个维度应用多头自注意力捕捉该维度下的跨时间依赖:
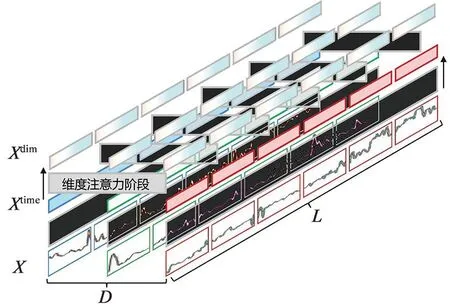
图3 两阶段注意力
(3)
(4)
式中,1≤d≤D,LN为层标准化,MHSA(Q,K,V)为多头自注意力,其中Q、K、V用作查询、键和值,MLP为前馈神经网络。在时间注意力阶段之后,相同维度的时间段之间的依赖关系在Xtime中被捕获,而后将Xtime作为维度注意力阶段的输入。
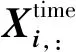
(5)
(6)
(7)
(8)
式中,1≤i≤L。
1.4.2卷积支路 卷积支路的卷积块使用1*1 卷积变换通道数、3*3 空间卷积进行特征提取,并引入残差连接。卷积核在重叠的特征图上滑动,从而保留精细细节的局部特征。
1.4.3特征融合模块 为融合全局表示和局部特征,特征融合模块将CNN支路的局部特征输入到注意力支路,以丰富其对局部细节的感知。将注意力支路提取的全局上下文特征反馈到CNN支路,以增强其对全局信息的感知能力。上采样和下采样分别采用插值和池化进行。
1.4.4损失函数 本研究分别对CNN和注意力支路计算交叉熵损失,训练时,为两部分分配不同的权重系数α,模型整体损失如下:
(9)

1.5 训练与测试
本研究使用的CPU为AMD Ryzen 7 5800H;GPU为NVIDIA GeForce RTX 3060 Laptop;操作系统为Windows 11;编程语言为Python 3.7;深度学习框架为PyTorch 1.13,按照4∶1的比例将数据集划分为训练集和测试集。训练时,使用五折交叉验证调整超参数,优化器采用Adam,初始学习率设置为0.001,并使用余弦退火调整学习率。测试时,在观察期内选取AKI发生时、发生前24、48、72 h四个时间点和观察期内随机选取的时间点作为预测点。在五个预测点,模型输入该时间点前的数据进行预测。
1.6 评价指标
本研究使用的评价指标有AUC、准确率(accuracy, Acc)、敏感性(sensitivity, Sens)、特异性(specificity, Spec)、阳性预测值(positive predictive value, PPV)、精确率-召回率曲线下面积(area under precision-recall curve, PR-AUC)以及F1分数。相关计算如下:
(10)
(11)
(12)
(13)
(14)
其中,TP、TN、FP和FN分别为真阳性、真阴性、假阳性和假阴性。
2 结果
2.1 对比实验
为验证CTSA-Net模型性能,本研究将其与AKI预测领域常用模型以及时间序列分类领域较新的模型进行了比较,包括长短期记忆网络[24](long short-term memory, LSTM)、Transformer[25]、TimesNet[26]、Autoformer[27]。
图4为不同模型在五个预测时间点的ROC曲线。表1展示了不同模型的AUC、Acc、Sens、Spec、PPV以及F1分数,并采用Bootstrap法计算AUC的95%置信区间。在五个预测时间点, CTSA-Net模型均取得了最高AUC值,分别为0.946、0.907、0.895、0.879和0.860,同时Acc及多项指标也显著高于其它模型。图5为CTSA-Net的ROC和PR曲线。在五个预测时间点的PR-AUC分别为0.979、0.960、0.949、0.939和0.939。

表1 不同预测时间点CTSA-Net模型与其它模型性能对比
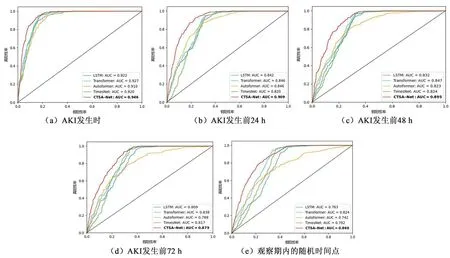
图4 不同预测时间点不同模型的ROC曲线
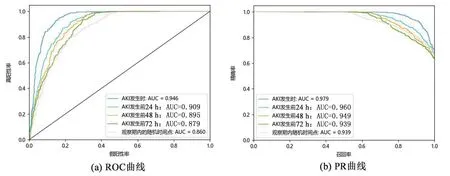
图5 CTSA-Net在不同预测时间点的预测
2.2 消融实验
为验证本研究CTSA-Net模型各模块的作用,对块嵌入、时间注意力、维度注意力、CNN支路及特征融合模块进行消融实验,设计了四组实验:(1)仅使用时间注意力,记为TA;(2)使用块嵌入和时间注意力,记为Patch-TA;(3)使用块嵌入、时间注意力及维度注意力,记为Patch-TA-DA;(4)使用块嵌入、时间注意力、维度注意力、CNN支路及特征融合模块,记为CTSA-Net。
表2展示了四组模型在四个预测点的各项评价指标。图6为四组模型在不同预测点的ROC曲线。结果显示,在四组模型中,CTSA-Net在AKI发生时、发生前24、48 h以及观察期内的随机时间点四个预测点取得了最高的AUC。相较于TA模型,在五个预测时间点,AUC分别提高了0.19、0.61、0.48、0.41和0.34,模型的整体分类性能取得了较大提升。
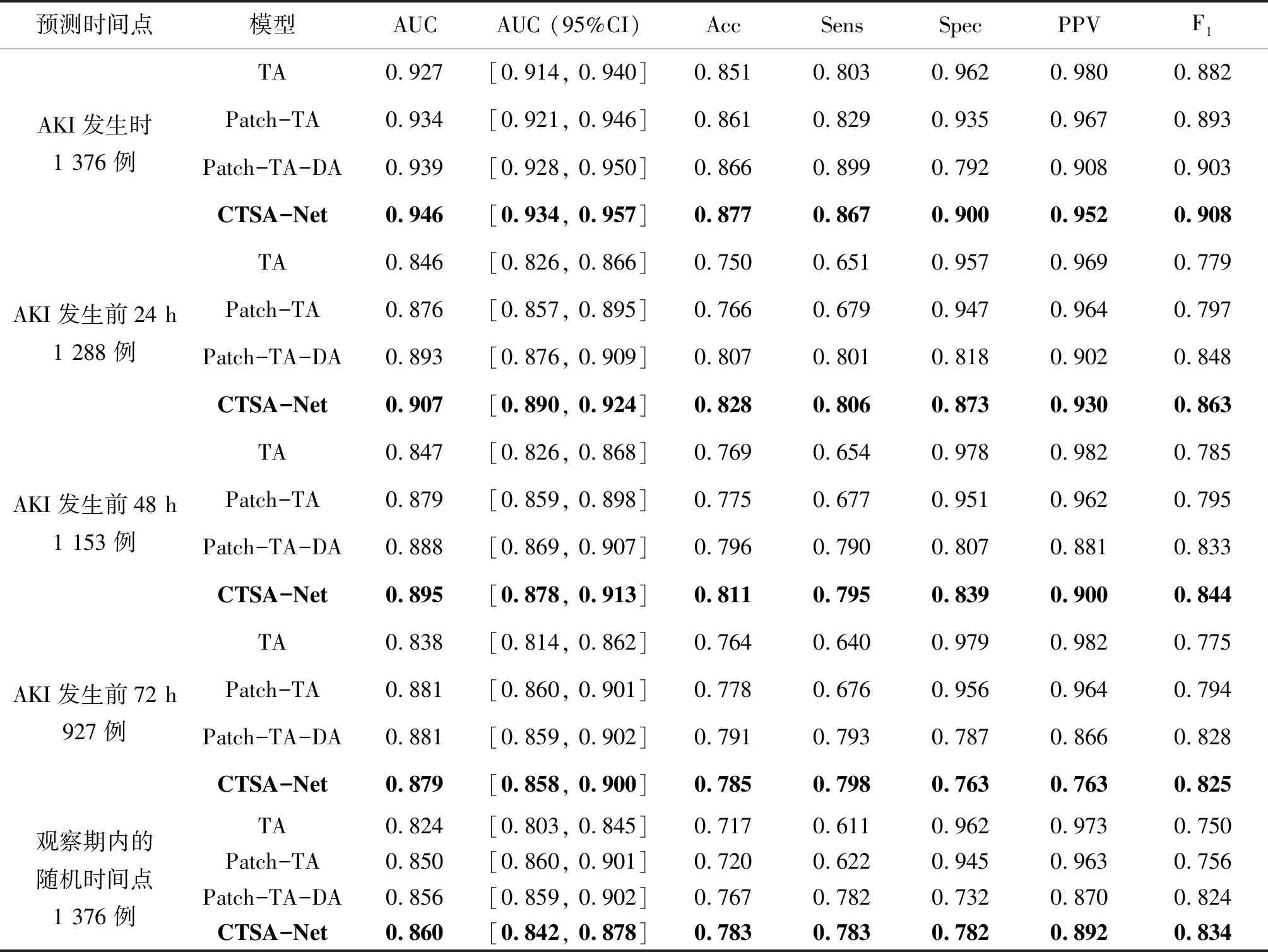
表2 不同预测时间点四组模型性能对比
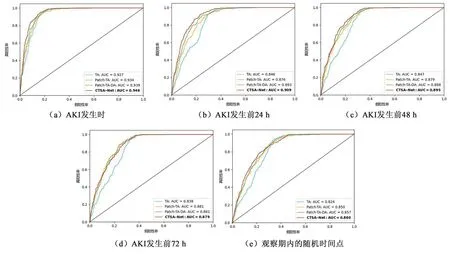
图6 不同预测时间点四组模型的ROC曲线
3 讨论
本研究基于MIMIC-III数据库中患者的47种临床参数,提出了一种CNN结合注意力的混合网络(CTSA-Net),可对1期及以上的AKI进行每小时的连续预测。
在对比实验中,在AKI发生时、AKI发生前24、48、72 h以及观察期内的随机时间点五个预测点,CTSA-Net均取得最高的AUC和准确率,其它指标也表现优秀,说明CTSA-Net连续预测性能较好。PR曲线显示,在不同的预测点,模型在保证较高召回率的同时,仍有较高的精确率,说明模型总体分类性能较好,鲁棒性强。
在消融实验中,块嵌入极大地增强了模型对序列局部特征的感知能力。维度注意力的实验说明关注参数间的关系具有意义。而引入CNN支路和特征融合模块有效利用了局部和全局特征,进一步增强了模型性能。
然而,本研究仍存在一定的局限性。为了更好地应用于临床实践,需要验证模型在临床数据上的性能。此外,需对模型的可解释性进行研究。未来会评估模型在临床数据上的性能,并对各模块的贡献进行分析,帮助医生理解模型的预测依据,辅助医生进行临床决策。
4 结论
针对过去研究存在的临床时间序列数据未被充分利用、提前预测窗口较短及缺少连续预测等不足,本研究基于MIMIC-III数据库,提出了一种CNN结合两阶段交叉注意力的混合网络模型(CTSA-Net),可对1期及以上AKI进行每小时的连续预测。CTSA-Net的CNN支路引入卷积模块,以保留时间序列的精细局部特征。注意力支路的块嵌入对原始序列进行分块映射,既保持了时间序列的局部性,又减少了输入特征向量的数量,降低了模型复杂度。在时间注意力的基础上引入维度注意力,捕捉多元时间序列维度间的关系。此外,两个并行支路间的特征融合模块将CNN支路的局部特征与注意力支路的全局表示耦合,弥补了CNN难以捕捉全局表示和注意力机制,忽略局部特征细节的问题。在不同的预测时间点,CTSA-Net预测模型均表现出良好的分类性能。将该模型集成到EHR系统中对患者实时监测,可辅助医生进行临床决策。
猜你喜欢
西安石油大学学报(自然科学版)(2022年5期)2022-10-08
小雪花·成长指南(2022年1期)2022-04-09
中华诗词(2019年7期)2019-11-25
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
电信科学(2016年9期)2016-06-15
灯与照明(2016年4期)2016-06-05
电测与仪表(2016年13期)2016-04-11
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01
电工技术学报(2014年7期)2014-11-15
