
面向人工耳蜗的改进Wave-U-Net算法
2024-03-09 01:34巩瑾琪叶萍吴逸凡常兆华樊伟许长建
生物医学工程研究 2024年1期
巩瑾琪,叶萍△,吴逸凡,常兆华,樊伟,许长建
(1.上海理工大学 健康科学与工程学院,上海 200093;2.上海微创天籁医疗科技有限公司,上海 200120)
0 引言
听力损失是一种严重的感觉障碍,对人类健康构成重大威胁。在临床上,听力损失被分为传导性、感音神经性和混合性三类,其程度又被进一步划分为0级、轻度、中度、重度和极重度[1-2]。根据世界卫生组织的统计数据,中国是全球听力障碍人口最多的国家,残疾性听力障碍患者高达2 780万,听障儿童超过460万。近年来,由于环境污染等因素的影响,患者人数每年大约增加30万人[3-4]。
人工耳蜗(cochlear implant)被誉为目前世界上最成功的神经假体,能帮助患有传导性听力损失[5]和重度感音神经性听力损失[6]的患者获得或恢复听觉。人工耳蜗在安静环境中,其语音感知效果与正常人群相当,但在噪声环境中的语音感知效果较差[7-8]。通过将同一语音在噪声环境和安静环境下输入人工耳蜗,获得人工耳蜗的电信号,然后通过逆信号处理,可获取人工耳蜗的语音波形图[9]。由图1可知,噪声环境下的语音波形更加杂乱,可影响患者的语音感知效果。因此,通过语音增强和降噪,将噪声环境变为安静环境,可提高人工耳蜗佩戴者的语音感知效果。

图1 逆处理后的语音波形
近年来,人工智能(artificial intelligence ,AI)[10]和硬件设备的性能得到了迅速发展,基于AI算法提高人工耳蜗在噪声环境中的语音感知效果成为研究热点。AI算法在人工耳蜗语音处理模块的应用主要分为两类。第一类是AI环境分类结合降噪算法应用于人工耳蜗,Cochlear、Advanced Bionics和MED-EL等公司已经实现了这类方法的商业化[11]。降噪算法主要包括log-MMSE[12]、Wienerfiltering[13]和KLT[14]等传统降噪方法。这些算法在一致的环境下可在一定程度上提高语音感知效果,但算法的鲁棒性较差[15]。因此,目前人工耳蜗通过降噪算法结合AI环境分类,仅针对分类结果一致的环境进行降噪。然而,自然界中的环境复杂多变,基于语音进行环境分类的准确率难以保证,而且将复杂的自然环境简单分类,也会影响信号处理效果。
第二类是利用AI算法强大的非线性拟合能力,直接对语音信号进行降噪处理,实现语音增强。这类算法已经非常成熟,但受限于人工耳蜗的硬件,目前市面上仍无相应产品,人工耳蜗产品的AI降噪仍仅限于AI环境分类结合降噪算法。Lai等[16]提出了一种将深度降噪自动编码器(deep denoising auto-encoder,DDAE)应用于人工耳蜗的语音处理模块,进行语音增强,实验结果表明,DDAE算法在STOI[17]和NCM[18]上均显著优于传统算法。Wang等[19]在Lai的研究基础上加入分类模块,进一步验证了DDAE在人工耳蜗中的降噪效果。在两个女性争吵说话的情况下,对人工耳蜗植入者的言语识别研究表明,DDAE相比传统算法的言语识别率高出约20%。为进一步优化人工耳蜗的语音增强网络,Fu等[20]将一种端到端全卷积网络(fully convolutional neural networks,FCN)用于人工耳蜗的语音处理模块,结果显示,FCN的STOI指标优于log-MMSE和DDAE。
针对现有人工耳蜗的语音处理模块在噪声环境下的语音感知能力较弱,传统降噪算法的鲁棒性不足,以及AI环境分类结果不理想的问题,本研究提出了一种改进的Wave-U-Net算法。该算法代替了AI环境分类算法和传统降噪算法的结合,实现了纯AI化处理。通过编码器-解码器结构,模型能够挖掘不同尺度的信息,以更全面地理解语音信号[21]。本研究采用了轻量化卷积来降低模型复杂度,并引入了Transformer部分,通过分析语音和噪声信息的相关性,区分语音和噪声,实现降噪,并通过优化数据集增强模型的鲁棒性。
1 实验方法及原理
对使用人工耳蜗的患者,本研究的首要目标是建立一个有效的言语感知系统,使他们能够像听力健康者一样进行交流。本研究的目的是人工耳蜗在安静环境下的言语感知效果优良。因此,采用改进的Wave-U-Net模型,将嘈杂的环境转化为安静的环境,以提高人工耳蜗患者在噪声环境下的言语感知能力。本研究流程见图2:第一部分是语音预处理阶段;第二部分是使用改进的Wave-U-Net模型进行语音降噪,寻找最优解,以增强人工耳蜗在复杂噪声环境下的语音感知效果;第三部分是使用评估指标对处理后的语音信号进行评估,以验证模型性能。
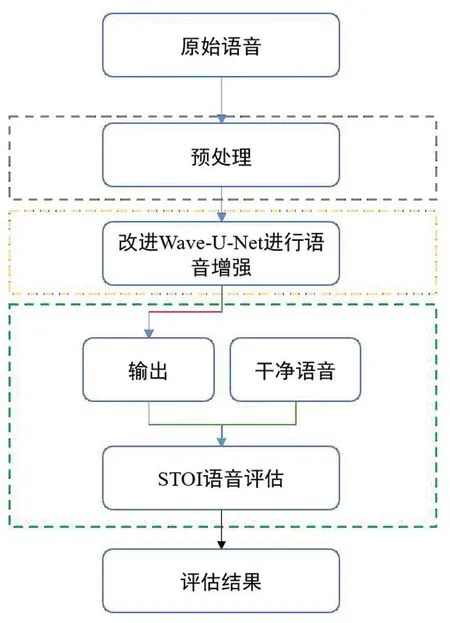
图2 研究流程图
1.1 方法
Wave-U-Net网络结构具有整合并学习语音中低层次和高层次信息的能力,能对语音信号进行多尺度处理,即使在小数据集上也能取得良好效果[22]。低层次信息主要包括语音信号的原始波形数据,如音频信号中的基本特征和频率等局部特征。相反,高层次信息则是对声音更高级别的理解,例如语音中的语调、语速、音调等整体特征。Wave-U-Net网络结构通过层次化结构可实现低层次和高层次信息的分离和整合。网络底层主要负责捕捉低层次细节,随着网络层次的提高,逐渐学习到更抽象和高层次的语音表示。通过跨层连接和注意力机制,结合低层次和高层次特征,以综合全局和局部信息,提高对语音信号的整体理解。然而,Wave-U-Net的卷积模块对噪声与语音的差异敏感度不高,无法很好地区分语音和噪声[23]。因此,本研究将Wave-U-Net作为基本框架,引入Transformer模块,以增强模型在分离语音和噪声方面的能力。然而,直接使用改进模型会导致参数量大、计算成本高,增加处理模块的运算成本。因此,本研究选择使用轻量型卷积模块替代原模型的标准卷积块。
1.2 轻量化卷积
本研究采用轻量化卷积替代标准卷积,以降低模型的复杂性,轻量化卷积的核心是深度可分离卷积(depthwise separable convolution,DWConv)[24]。Li等[25]提出了一种新型的轻量化卷积技术,名为GSConv,在精度和计算成本之间取得了良好的平衡。尽管GSConv主要应用于二维图像领域,但本研究对其进行了调整,将其转化为Wave-GSConv,使其适用于一维语音数据,该卷积模型由标准卷积和DWConv两部分组成,将标准卷积和DWConv的输出特征图在通道维度上进行拼接(Concat)操作,最后进行通道混洗(Shuffle)然后输出,见图3。

图3 Wave-GSConv结构图
1.3 Transformer掩模估计模块
带噪声的语音由噪声信号和清晰的语音信号组成。由于一维卷积受感受野的限制,对语音和噪声区分不敏感[26]。因此,本研究引入了Transformer模块进行加权计算,通过放大两者的特征信息,提高模型的收敛速度[27]。
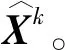
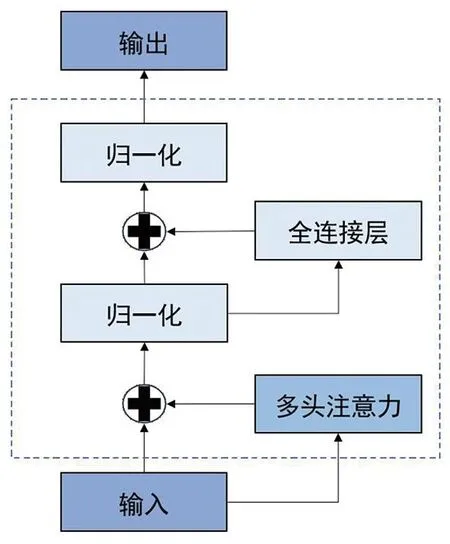
图4 Transformer模块
(1)
(2)
1.4 改进 Wave-U-Net 结构
本研究提出的改进的Wave-U-Net结构,见图5。该结构由编码器和解码器组成,无需进行预处理和后处理(如特征提取和语音恢复),减少了冗余步骤,实现了语音增强。首先,语音数据输入到编码器中,通过Wave-GSConv和下采样进行特征提取。每一层的跳跃连接可整合不同层次的信息。然后,编码器的特征输入到解码器中,通过Transformer模块和上采样,对噪声数据进行抑制。最后,通过一个1*1的卷积层和tanh激活层,输出增强后的语音信号。此外,本研究将改进的算法应用于人工耳蜗的语音处理模块,并与策略编码相连;设置算法的通道数与电刺激的通道数相匹配,以提高语音算法在人工耳蜗中的适应性,使得后续的策略编码通道筛选更加清晰[28]。
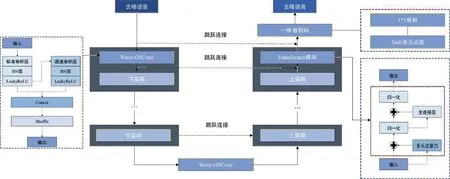
图5 改进Wave-U-Net 结构
1.5 损失函数
在语音增强研究中,模型的损失函数是一个关键因素,可有效指导模型快速且高效地收敛。本研究最初采用均方误差(mean-square error, MSE)[29]作为损失函数来驱动模型的收敛过程。MSE的定义见式(3):
(3)

本研究采用了STOI[30]作为评估语音感知效果的指标。STOI是基于人类听觉感知原理设计的指标,其目标是尽可能地模拟人类对语音可懂度的主观感知。STOI的计算见式(4)。STOI的取值范围在0~1之间,值越接近1,表示处理后的语音的可懂度越高。
(4)

然而,在模型收敛过程中,尤其是当损失函数趋于稳定时,虽然每轮测试集的平均MSE在减小,但平均STOI却出现了降低。处理后数据的语谱图见图6。图中的上行和下行分别表示两条语音训练过程中的MSE、STOI和语谱图的变化。图6(a)代表干净的语音语谱图;图6(b)是经过n轮训练后的MSE、 STOI和语谱图;图6(c)表示经过2n轮训练后的MSE、 STOI和语谱图。由图6可知,随着训练轮次的增加,语音信号的均方误差(MSE)呈现下降趋势,表明处理后的语音信号在数值上更接近于原始语音。理论上,STOI值应随之增大,然而,实际观察到的情况却是STOI值减小。尽管经过更多轮次训练,语音信号的可懂度出现了降低现象。该发现显示,在数值上接近原始语音,并不一定意味着语音的可懂度提高。因此,在主观听觉系统中,STOI和MSE两种评估方法对语音清晰度的感知效果并不等效。换言之,采用MSE作为损失函数并不能确保模型向最优的语音感知效果方向收敛。然而,如果将损失函数替换为STOI,模型的收敛速度会变慢,且容易陷入局部最优值。

图6 处理后数据的语谱图
为此,本研究提出了一种结合STOI和MSE的方法,见式(5)。在训练开始时,通过调节权重α和β控制模型收敛速度。首先,增加MSE的权重α,以使模型快速收敛。随后,逐步增加STOI的权重,同时降低MSE的权重,以使模型趋向于最优解。值得注意的是,α的增长和β的减少都是指数级的。两个参数每5轮变化一次,且每次变化的指数相同。
loss=α(1-STOI)+βMSE
(5)
2 实验结果与讨论
2.1 数据集
本研究的语音数据来自清华中文语音数据集(THCHS-30)[30]。鉴于U-Net网络在小数据集上的优秀表现[31],本研究改进的Wave-U-Net模型从数据集中随机挑选了6 975条清晰的语音样本进行实验。
本研究的噪声数据来自文献[32-33]和上海某公司的室内噪声数据。这些噪声数据包括Babble、语谱噪声(speech-shaped noise,SSN)、white、粉红噪声、交通噪声、公司噪声和风噪。在-5、0、5、10 dB四种信噪比下,本研究将干净的语音与随机选择的三种噪声混合,生成包含噪声的数据集。同时,采用了动态掩模,随机掩蔽带噪语音中15%的噪声信号。由于实际生活中的噪声复杂多变,本研究并未对单一噪声进行测试,而是选择了随机混合,并进行动态掩模噪声,以增强模型的鲁棒性。最后,将数据集分为训练集(5 580条)和测试集(1 395条)。
2.2 实验平台和参数设置
本研究使用Windows 10操作系统;处理器是Intel(R) Core(TM) i7-10870H CPU;运行速度为2.20 GHz,内存为16 GB;使用的GPU是NVIDIA GeForce RTX 2060;编程语言为Python 3.9;深度学习平台为Torch。
在模型对比评估过程中,本研究对所有模型的超参数进行统一配置(初始学习率设定为1×10-4,每个批次的训练样本数为4,设置300个训练周期,每5个训练周期后,学习率将降为原来的90%),旨在确保公平的比较基准,并优化模型性能。
2.3 评价指标
由于人工耳蜗对模型的复杂度有特定要求,因此,本研究选择计算量(GFLOPs)和参数量(Params)综合评估模型复杂度。GFLOPs常用于衡量模型的计算复杂度,而Params则用于评估模型的空间复杂度,即模型占用显存的大小。
此外,本研究基于噪声环境和安静环境下的语音感知效果,将降噪效果视为语音感知的评估。语音感知质量评价(PESQ)是由国际电信联盟推荐并制定为一种客观质量评估标准(P.862.2标准)[34]。一般来说,PESQ的取值范围为1.0(语音质量差)至4.5(语音质量最佳)。为提高模型评估的准确性和可信度,本研究采用了STOI和PESQ两个指标对不同模型处理后的语音数据进行评估。
2.4 增强结果及评估
为提升模型在区分语音和噪声方面的能力,本研究引入了Transformer模块,并进行了对比实验。记录了初始的STOI值,并每隔5轮记录一次STOI的变化值,以此对比分析是否包含Transformer模块的STOI值变化情况,见表1。结果表明,引入Transformer模块后,包含Transformer模块组别的STOI值变化更快。因此,改进后使得模型在区分噪声方面的能力更强,收敛速度更快,更适用于人工耳蜗的语音增强。

表1 Transformer模块的效果对比表
由图7可知,所有评估指标中,传统降噪算法的离散程度最大,表明算法的测试结果较为分散、个体差异大,算法的鲁棒性较低。通过对图表的综合分析,可发现本研究改进Wave-U-Net网络的效果最优。
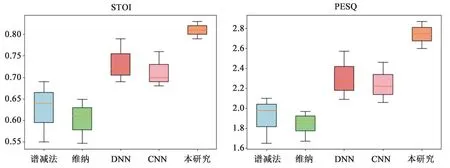
图7 测试集箱型图
为评估模型性能并确保结果的可靠性,本研究使用训练集对所有模型进行了重新训练,并在测试集上评估。将人工耳蜗常用的传统降噪算法(如维纳滤波和谱减法),以及文献中已在人工耳蜗中应用的DNN[16]、CNN[20]和降噪效果优异的Sudo rm-rf[35]算法与本研究算法进行了对比。由表2可知,本研究算法在测试集上的STOI均值为0.81,PESQ均值为2.75,明显优于传统算法。与已应用在人工耳蜗中的DNN、CNN算法相比,性能也有明显提高。然而与Sudo rm-rf算法相比,仍存在一定差距。但当本研究增加了改进Wave-U-Net的编码器和解码器的层数后,发现改进算法可达到与Sudo rm-rf相近的效果。

表2 7种降噪算法在测试集中对应STOI和PESQ值
人工耳蜗对模型的大小和运行时间有特定要求,因此,模型复杂度是一个重要的参考标准。在输入相同数据的情况下,本研究计算了模型的GFLOPs和Params,见表3。与Wave-U-Net相比,本研究改进的Wave-U-Net模型显著降低了计算复杂度。此外,与Sudo rm-rf的复杂度相比,也有很大的降低,且远低于CNN和DNN模型的复杂度。因此,改进的Wave-U-Net模型在降低模型复杂度方面取得了显著效果。

表3 模型复杂度对比
总之,改进后的Wave-U-Net在模型复杂度上满足了人工耳蜗的需求。尽管在降噪效果评分上,不如Sudo rm-rf模型表现出色,这主要是由于模型规模较小所致。随着模型层数的增加,其效果逐渐接近Sudo rm-rf模型,且效果接近时,算法复杂度远低于Sudo rm-rf。此外,与传统算法相比,本模型具有更好的鲁棒性,其降噪效果的离散程度也较低。
3 讨论与结论
本研究针对人工耳蜗在噪声环境下言语感知能力差的问题,提出了一种改进的Wave-U-Net模型。通过采取轻量化卷积,引入注意力机制,改进损失函数,优化数据集结构,面对复杂的噪声环境,实现了STOI为0.81、PESQ为2.75的降噪效果。该结果表明,人工耳蜗在噪声环境下的言语感知效果得到了显著的提升。
然而,本研究仍存在一些局限性。首先,本研究基于噪声环境和安静环境的言语感知效果,将降噪效果作为人工耳蜗言语感知的评估指标。但是,本研究缺少患者真实的言语感知效果,因此,后续需要进行临床实验研究。其次,本研究算法受人工耳蜗硬件系统的限制,并未采取优异的语音增强算法,因此,在算法方面仍有进步空间。尽管如此,本研究成果仍具有重要的参考价值。研究结果可为后续人工耳蜗的语音处理模块提供一定的参考价值。此外,随着研究的深入,未来希望可以融合电极端,真正实现人工耳蜗的端到端AI算法,进一步推动人工耳蜗技术的发展,为听力损伤患者带来更大的福音。
猜你喜欢
中国听力语言康复科学杂志(2021年6期)2021-12-21
北京航空航天大学学报(2021年9期)2021-11-02
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年11期)2019-07-04
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
北京航空航天大学学报(2018年1期)2018-04-20
海南医学(2016年8期)2016-06-08
听力学及言语疾病杂志(2015年5期)2015-12-24
