
基于关键实体和文本摘要多特征融合的话题匹配算法
2024-03-09 02:42孙润元陈贞翔
郑州大学学报(工学版) 2024年2期
纪 科, 张 秀, 马 坤, 孙润元, 陈贞翔, 邬 俊
(1.济南大学 信息科学与工程学院,山东 济南 250022;2.济南大学 山东省网络环境智能计算技术重点实验室,山东 济南 250022;3.北京交通大学 计算机与信息技术学院,北京 100044)
随着现代科技的迅速发展,人们习惯于从网络获取新闻资讯、搜索热点新闻。然而,随着使用网络浏览新闻的频率不断上升,人们对于新闻资讯的要求也越来越高,希望浏览到相关且更加多元化的新闻。
现有的新闻检索往往采用关键词检索算法或文本匹配算法[1]。基于关键词的检索[2]缺少新闻文本语义的概括,检索出的新闻大多不相关,存在检索不准确、相关性差等问题。在基于文本匹配的新闻检索方面,传统的方法[3]更多是在关注文本词形和词汇层面的相似性,但是词汇往往存在一词多义现象,并且用词汇代替整句的语义不够完整。深度学习文本匹配模型[4]侧重于文本语义向量的构建以及交互,但是过分关注文本语义的相似性,忽视新闻文本的话题概括,检索出来的新闻过于相似,极易降低阅读观感,在实际应用中无法满足用户需求。
针对上述问题,本文提出一种基于关键实体和文本摘要多特征融合的话题匹配算法。由于关键实体和摘要可以概括文本的话题,因此该方法基于关键实体提取和文本摘要技术,将融合得到的关键实体特征和摘要特征作为概括文本话题的深层次语义特征,与通过交叉注意力机制(cross-attention)交互的文本语义特征一起,共同参与文本话题匹配的判断。在搜狐公开数据集上进行对比实验,结果表明该算法性能优于目前比较流行的深度学习文本匹配算法。
1 相关工作
1.1 文本匹配
随着自然语言处理(NLP)的发展,文本匹配技术有了很大的进展。文本匹配通过文本中蕴含的语义信息,判别文本之间的矛盾性和相似性,可以应用于很多场景,比如信息检索[5]、对话系统[6]等。
目前,基于深度学习的文本匹配技术可分为表示型文本匹配、交互型文本匹配和预训练语言模型的文本匹配3种。表示型文本匹配是先将待匹配的两段文本进行编码得到向量表示,然后计算向量的相似度,更侧重对语义向量的构建,它的优势是结构简单、易于实现,如SimLSTM[7]模型。交互型文本匹配则是在输入层就进行词语间的匹配,不仅注重整个文本的语义表示,也关注局部文本的表示和交互,注重挖掘语义焦点,ABCNN[8]模型是交互型文本匹配模型。预训练语言模型的匹配方法则是利用预训练加微调的方式完成文本匹配任务,预训练语言模型利用海量的语料数据可以学习到通用的语义表示,进而实现下游文本匹配任务。
近年来,随着预训练语言模型BERT[9]的广泛使用,出现了一系列基于BERT的预训练模型,例如RoBERTa[10]、NEZHA[11],还有将主题信息融入预训练语言模型BERT的tBERT[12]模型和将主题过滤加入文本匹配任务[13],以及将关键词信息融入预训练语言模型BERT的KeywordBERT[14]、DC-Match[15],这些预训练模型为额外信息融入BERT提供了基础。
1.2 命名实体识别
命名实体识别(NER)旨在识别文本中具有特定含义的实体,比如人名、地名、组织名、机构名等。近年来,基于深度学习的NER取得了优异的表现。深度学习模型对输入数据进行特征提取,再使用非线性激活函数提高模型的表达能力,完成多层神经网络的训练和预测任务。Huang等[16]使用双向长短期记忆网络(BiLSTM)和条件随机场CRF的方式解决命名实体识别问题,至今仍在命名实体识别方面被广泛应用。Li等[17]提出了W2NER模型,通过构建词与词的关系,统一了普通扁平NER、嵌套NER和不连续的NER等3种NER任务模型,在NER方面有了很大的进展。
1.3 文本摘要
文本摘要旨在通过算法精练提取文本的主要内容,将文本转化为包含关键信息的简洁摘要。随着文本摘要技术的发展,产生了2条技术路线:抽取式文本摘要和生成式文本摘要。抽取式文本摘要通过算法从原文中抽取关键信息组成摘要。Liu[18]将抽取式摘要分解为序列标注和句子排序任务进行建模。生成式文本摘要是模型根据原文的内容,自动生成文本摘要,它允许摘要中出现新的词语,具有较高的灵活性。Zhang等[19]提出了Pegasus模型,将输入文本中的重要句子遮蔽,再利用文本其他句子生成被遮蔽的重要句子,加深了模型对文档的理解,实现了生成式摘要任务。
2 问题定义
假设用S表示源新闻集,T表示目标新闻集,sx为S中的一个源新闻样本,tx为T中的一个目标新闻样本。给定源新闻-目标新闻对{sx,tx},为它设置一个状态标签yx∈{0,1},其中1代表源新闻和目标新闻话题匹配,0代表源新闻和目标新闻话题不匹配,{sx,tx,yx}为一个训练样本。根据上述定义,n个训练样本组成了训练数据集,如式(1)所示:
Dtrain=((s1,t1,y1),(s2,t2,y2),…,(sn,tn,yn))。
(1)
本文利用训练数据集Dtrain构建模型,f为模型损失函数,判断当前源新闻sx′和目标新闻tx′是否匹配的标签yx′,如式(2)所示:
yx′=f(sx′,tx′)。
(2)
3 话题匹配算法
这一节将介绍本文提出的话题匹配算法,包括基于关键实体和文本摘要的深层次语义特征提取、基于交叉注意力(cross-attention)的文本交互以及融合文本交互特征和深层次语义特征的匹配。话题匹配模型架构如图1所示。

图1 整体架构图
3.1 深层次语义特征提取
深层次语义信息是新闻文本的关键实体和文本摘要信息,本文将关键实体特征和文本摘要特征通过双向LSTM[20]进行特征融合,得到新闻文本的深层次语义特征。
3.1.1 实体提取器
本文采用W2NER模型进行命名实体识别,在人民日报NER数据集训练模型,实体生成器如图2所示。

图2 实体生成器
首先将新闻文本输入基于预训练语言模型的BERT,转化成向量形式。给定新闻样本s,其对应的长度为l的字符序列s=[x1,x2,…,xl],通过BERT处理之后获得s中的每个字符的表示向量如式(3)所示:
v=BERT(s)=[v1,v2,…,vl]。
(3)
为了进一步增强上下文的联系,采用双向LSTM来生成包含上下文信息的向量表示,如式(4)所示:
h=BiLSTM(v)=[h1,h2,…,hl]。
(4)
接着采用CLN(conditional layer normalization),构造出词对信息矩阵 (word embedding ),叠加距离信息矩阵(distance embedding)和区域信息矩阵(region embedding)后,通过不同空洞率的空洞卷积进行特征提取。
然后叠加以上3个embedding,通过不同空洞率的空洞卷积进行特征提取,将得到的特征连接到一起,形成词对网格表征Q。Q为预测层MLP的输入,而预测层中双仿射分类器(biaffine)的输入是来自编码层(BERT+BiLSTM)的输出。词对关系包括None、NNW、THW-*3种关系,None表示2个字没有关系,不属于同一个实体;NNW表示这2个字是在同一个实体中相邻的位置;THW-*表示这2个字在同一实体中,且分别是实体的结尾和开始。给定向量表示h,使用2个MLP来分别计算词对(xi,xj)的向量表示si和oj。然后,使用双仿射分类器来计算词对(xi,xj)之间的关系分数,如下所示:
si=MLP(hi);
(5)
oj=MLP(hj);
(6)
(7)
式中:U、W和b为可训练参数;si和oj分别表示第i个和第j个单词的向量表示。
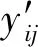
(8)
通过组合biaffine和MLP预测器的得分计算词对(xi,xj)的最终关系概率yij,如式(9)所示:
(9)
W2NER模型预测字和字之间的关系,相当于一个有向的词图。解码的目的是根据确定的路径找到字和字的NNW关系,得到预测的实体及其类型,最后得到实体集合E=(e1,e2,…,eo)。
3.1.2 关键实体筛选
将实体词的TF-IDF关键性、词出现的频率、词在词的集合中是否合群、词词之间的相似度和词句之间的相似度作为关键实体的筛选特征。
(1)TF-IDF关键性因子。TF-IDF是一种统计方法,用以评估一个词对于一个语料库中一份文件的重要程度,常用于关键词检索。TF-IDF关键性因子权重如式(10)所示:
(10)
(2)词频因子。统计实体集中各个实体词出现的频率,为不同词频的实体赋予不同的权重,如式(11)所示:
(11)
式中:n为实体出现的次数。
(3)词的合群性因子。在数据集上采用jieba分词训练word2vec词向量模型[21]。通过word2vec查找不同类词的方法找出不合群的实体,并为其赋不同的权重。式(12)为不合群词权重,式(13)为合群词权重:
(12)
(13)
(4)词词相似度因子。通过word2vec词向量模型编码各实体,以实体为节点,相邻节点的边权重为向量相似度,计算当前词与剩余词的相似性。统计每个实体词的边权重之和,作为此实体的词词相似度,对每个实体的词词相似度进行归一化,如式(14)所示。
(14)
式中:eni代表第i个实体的向量;cos(·)代表余弦相似度的计算;n为实体个数。
(5)词句相似度因子。通过word2vec模型编码各实体和句子,计算其相似度,作为词句相似度因子,其中sen代表通过word2vec编码的句向量,如式(15)所示:
(15)
最后,组合特征权重如式(16)所示:
(16)
根据实体集中各个实体的组合特征权重的不同进行排序,取前两个作为关键实体,得到关键实体集合K=(k1,k2)。
3.1.3 文本摘要生成器
本文采用IDEA研究院CCNL提出的基于中文数据集悟道语料库(180 GB版本)预训练的中文Pegasus模型large版本[22],对新闻文本进行文本概括,得到新闻准确、简洁的信息。
基于摘要提取的目的,Pegasus模型首先对于文本中的重要句子进行选取,受词和连续span mask的启发,Pegasus模型选择了遮蔽这些重要句子即间隔句,并且拼接它们形成伪摘要,相应位置遮蔽掉的间隔句用[MASK]来替代。然后通过decode恢复这些遮蔽掉的间隔句,加深模型对于文本语义的理解,达到生成文本摘要的目的。
3.1.4 基于BiLSTM的深层次语义特征融合
本文设计了一个基于BiLSTM的特征提取网络如图3所示,对文本摘要特征和关键实体特征进行特征融合,BiLSTM可以捕获上下文信息,提取更深层的语义特征[23]。

图3 基于BiLSTM的特征提取网络
该网络是一个并行网络,通过文本摘要提取的新闻文本s、t得到摘要Ms、Mt,通过预训练语言模型BERT进行编码,得到摘要中的每个字符的向量表示。然后通过平均池化,分别得到文本摘要特征向量ps、pt。同样,通过实体提取和关键实体筛选的新闻文本s、t得到的关键实体集Ks、Kt,通过预训练语言模型BERT进行编码,得到Ks、Kt中的每个字符的向量表示。然后通过平均池化分别得到关键实体特征向量qs、qt。
接下来,将源新闻文本的文本摘要特征向量ps和源新闻文本的关键实体特征向量qs进行拼接,再通过BiLSTM进行特征融合,得到源新闻文本的深层次语义特征向量m。同样,将目标新闻文本的文本摘要特征向量pt和目标新闻文本的关键实体特征向量qt进行拼接,再通过BiLSTM进行特征融合,得到目标新闻文本的深层次语义特征向量n。其中,BiLSTM是双向LSTM,分别对序列进行正向和反向处理,获取上下文的联系,得到全局特征。
3.2 基于cross-attention的文本交互
在这一部分,对源新闻文本和目标新闻文本进行交互,增进彼此的联系,更好地获取待匹配新闻文本之间的差异,如图4所示。
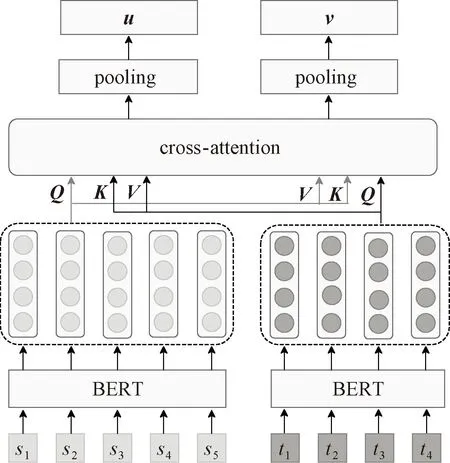
图4 基于cross-attention的文本交互
首先,对源新闻文本s通过预训练语言模型BERT,得到s的特征向量Ps,即BERT模型的最后一层输出。同样,将目标新闻文本t通过预训练语言模型BERT,得到t的特征向量Pt。虽然BERT可以有效地编码语义信息,但是s和t之间的交互信息没有被探索,缺少彼此的交互和联系。因此,利用交叉注意模块来增进文本之间的跨序列交互。与自注意力机制不同,交叉注意力机制的输入来自具有相同维度的不同序列,查询来自一个序列,而键和值来自另一个序列。
具体地,首先将通过BERT得到的向量Ps、Pt,送入cross-attention的输入中,用于计算查询、键和值,将它们分别打包成矩阵Q、K、V。
Q和K之间的点积的相似性决定了V的注意分布。m个头部的多头注意函数具有m个并行的自注意函数。对于第i个头部,输入的Q、K、V转换如下:
(17)
(18)
(19)
(20)
(21)
(22)
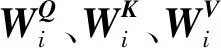
多头自注意函数的计算过程表示如下:
(23)
(24)
式中:dh代表每个头部的输出特征的维数。
进一步,将每个头部得到的特征向量拼接,与权重矩阵Wo计算后压缩成一个矩阵,m代表总共的头数,公式如下:
hs=concat(hs1,hs2,…,hsm);
(25)
ht=concat(ht1,ht2,…,htm);
(26)
MA(Qs,Kt,Vt)=hsWso;
(27)
MA(Qt,Ks,Vs)=htWto。
(28)
再通过由2个全连接层和一个ReLU激活函数组成的FFN层,在各个时序上对特征进行非线性变换,提高网络表达能力。
通过cross-attention,可以得到新闻文本s和t各个字的交互向量表达,然后通过平均池化操作,得到新闻文本s和t的交互特征向量u、v。
3.3 融合文本交互特征和深层次语义特征的匹配
基于cross-attention的文本交互模块得到了源新闻文本的交互特征u、目标新闻文本的交互特征v,而后用|u-v|得到源新闻-目标新闻文本交互特征的差异,|u-v|为特征向量按位相减并取绝对值的操作。深层次语义特征提取模块得到了源新闻文本的深层次语义特征m、目标新闻文本的深层次语义特征n,而后用特征向量|m-n|得到源新闻-目标新闻文本深层次语义特征的差异。将文本交互特征向量及其差异和深层次语义特征向量及其差异拼接,得到融合的特征向量(u,v,|u-v|,m,n,|m-n|)。然后,将向量(u,v,|u-v|,m,n,|m-n|)通过BN层进行归一化,通过ReLU增加神经网络各层之间的非线性关系,最后通过全连接层进行降维,预测匹配的结果。
4 实验
4.1 数据集
本文的数据集来源于2021搜狐校园文本匹配算法大赛话题匹配的真实数据集[24]。该数据集包含源新闻文本、目标新闻文本和标签,若2段新闻话题相同或相似,标注为1,否则标注为0。
该数据集包括短文本和短文本的匹配、短文本和长文本的匹配、长文本和长文本的匹配3部分,数据统计结果如表1所示。其中短文本为100以内的文本,长文本为200字以上的文本。实验将3个数据集的训练集和验证集合并,训练一个话题匹配模型,分别在3个测试集上测试,实验结果证明模型在不同长度的文本上均有效果。
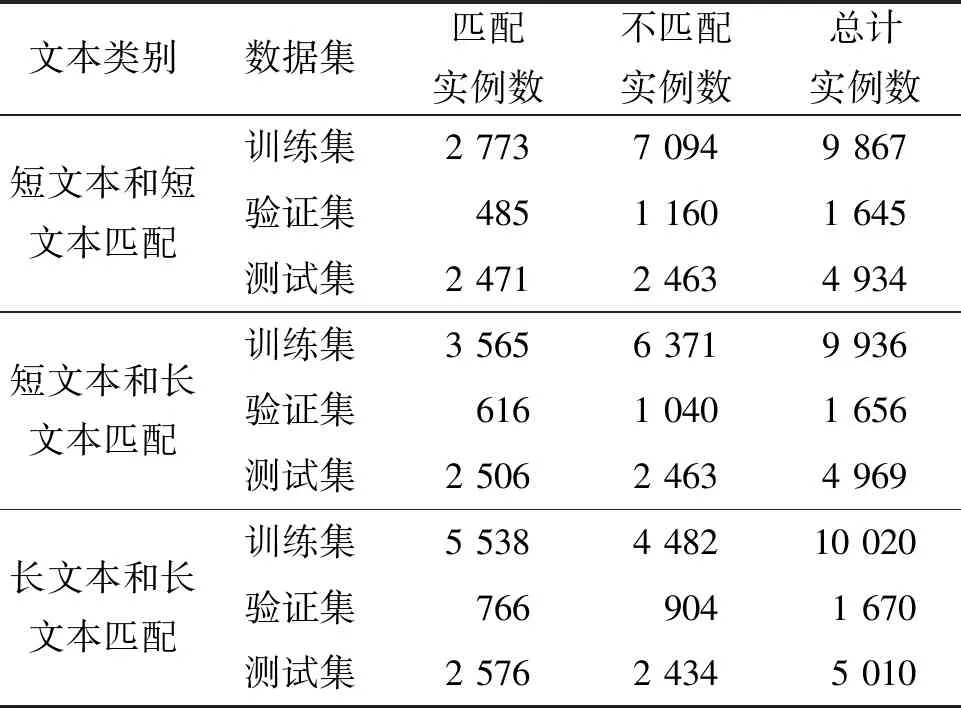
表1 实验中使用的搜狐数据集
4.2 基线方法
本节将本文提出的算法和以下6个基准的文本匹配算法进行性能比较,其中ABCNN和SimLSTM模型采用的word2vec词向量是使用搜狐数据集进行无监督训练得到的。
ABCNN:交互型文本匹配模型,采用CNN抽取上下文信息,在输入层和卷积的输出层添加注意力机制对序列进行交互,进而得到文本匹配结果。
SimLSTM:表示型文本匹配模型,通过2个LSTM网络得到句子表征向量,用全连接层构成的分类层得到匹配结果。
BERT:预训练语言模型,BERT采用基于自注意力机制的Transformer,将源新闻、目标新闻文本通过BERT进行微调,实现文本匹配任务。
SBERT[25]:SBERT模型采用孪生网络结构,分别对源文本和目标文本输入BERT网络,输出2组表征句子语义的向量u、v,拼接向量u、v、|u-v|,预测文本匹配结果。
Erine3.0[26]:基于Ernie、Ernie2.0,百度不断增大语料库,并且融合知识图谱进行知识强化的预训练任务,得到百度的预训练语言模型Erine3.0。通过微调,可进行文本语义匹配任务。
4.3 评价指标
实验部分综合利用准确率Acc、精确率P、召回率R、F1指标来评价算法,如下所示:
(29)
(30)
(31)
(32)
本文的实验环境如下:Intel(R) Xeon(R) Platinum 8255C CPU@2.50 GHz+24 GB内存,深度学习框架为Anaconda Python3.0+PyTorch 1.8.1。
4.4 参数设置
在关键实体提取模块,根据实验发现,关键实体个数设置为 2时效果最好。在命名实体识别模块,使用BERT获得768维的词向量,学习率设置为 10-3,批样本数设置为8,采用 Adam 优化器,可以获得更好的收敛效果。在话题匹配模块,根据统计,新闻文本平均输入长度为 260,文本摘要最大输入长度为100,关键实体最大输入长度为20,以此设置相关参数。同时,学习率设置为2×10-5,批样本数设置为 16,迭代次数为2,采用Adam 优化器,可以获得较好的收敛效果,但模型容易过拟合,因此采用dropout层解决模型过拟合问题,在训练过程中每 200 步保存一次模型,保留效果最好的模型。
图5展示了关键实体筛选模块的关键实体个数对实验结果的影响。其中,k=1、k=2、k=3、k=4,分别代表了将按照组合特征权重排好序的实体,选取前1、2、3、4个作为关键实体;k=all代表把文本的所有实体都参与深层次语义特征的提取。综合来看,k=2时,指标R、F1在短短匹配、短长匹配、长长匹配数据集上均为最高,指标Acc和P也表现较好。因此,选取前2个实体作为关键实体。当k=all时,效果较差,同时也证明了关键实体提取模块的有效性。
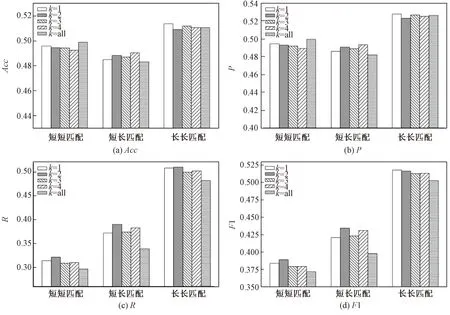
图5 不同关键实体个数的性能变化
4.5 对比实验
为了验证本文方法的有效性,选取了表示型、交互型、预训练语言模型3种类型的文本匹配方法进行对比实验。表2展示了所有算法在真实数据集上取得的实验结果。其中,ABCNN 模型为交互型文本匹配模型,采用CNN可较好地提取文本局部信息,捕捉文本细节,通过注意力机制增进两句话之间的交互,但是过分注重文本细节的匹配,不利于文本话题匹配。SimLSTM模型为表示型文本匹配模型,仅在匹配层获取向量差异,缺少语义之间的交互,编码句子语义时损失较大。BERT、Ernie3.0模型采用大规模语料库预训练,SBERT模型采用BERT进行语义表示,但是这3个模型忽视文本话题的概括,在话题匹配方面效果不好。

表2 对比实验结果
总体上看,本文提出的算法各项指标比较均衡,在3个测试集中,召回率和F1都取得最好的效果,在准确率、精确率方面也与其他模型的最优效果相近。因此,证明了本文提出的基于关键实体和文本摘要多特征融合的话题匹配算法的有效性。
4.6 消融实验
为了验证本文方法中各模块的有效性,移除了模型中特定的部分,进行了消融实验。表3展示了消融实验结果,其中,M1为移除了深层次语义特征提取模块;M2为移除了基于BiLSTM的深层次语义特征融合模块,即将文本摘要特征、关键实体特征直接拼接参与话题匹配。M3为移除了交叉注意力模块,用BERT最后一层的[CLS]向量作为句子语义向量,进行匹配。

表3 消融实验结果
从消融实验结果可以看出,各模块对准确率和精确率影响较小,但对召回率和F1值有较大的影响。去除了深层次语义特征提取模块后,各指标明显降低。去除BiLSTM提取关键实体和文本摘要的全局特征,在不同数据集中,召回率和F1也有所降低。去除cross-attention文本语义特征交互模块后,短文本和短文本的匹配以及长文本和长文本的匹配中指标均下降,是由于待匹配文本长度相近时,通过BERT模型得到的语义特征差距较小,添加交叉注意力机制进行交互,可以更好地关注待匹配文本的语义信息,更好地捕获语义特征的差异,提升话题匹配效果。然而,当待匹配文本长度相差过大时,文本语义特征相差较大,本文模型添加交叉注意力机制后仅在R和F1指标上有提升。
5 结论
本文提出了基于关键实体和文本摘要多特征融合的话题匹配算法,通过提取文本的关键实体和摘要,获得文本的深层次语义特征,更好地概括新闻文本话题,再通过交叉注意力机制获得文本之间的交互特征,增进文本向量之间的联系,使得文本深层次语义特征和文本交互特征共同作用于文本话题匹配结果。在真实数据集上进行的实验表明,本文的方法要优于目前流行的深度学习文本匹配算法,对文本话题匹配有较好的检测效果。
后续工作可以通过关系抽取或事件抽取的方法进一步提取文本深层次语义特征,提升文本话题匹配结果。目前公开的话题匹配数据集不多,可以制作更大的数据集来进行进一步实验。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
中学生数理化(高中版.高考理化)(2021年6期)2021-07-28
中国外汇(2019年18期)2019-11-25
许昌学院学报(2018年4期)2018-05-02
哲学评论(2017年1期)2017-07-31
中华建设(2017年1期)2017-06-07
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
NBA特刊(2014年7期)2014-04-29
