
基于多阶段特征提取的鱼类识别研究
2024-03-06 01:45吕俊霖陈作志李碧龙蔡润基高月芳
南方水产科学 2024年1期
吕俊霖,陈作志,李碧龙,蔡润基,高月芳
1. 中国水产科学研究院南海水产研究所,广东 广州 510300
2. 华南农业大学,广东 广州 510642
鱼类自动识别是渔业智能化的重要一环,在海洋生态学[1]、行为分析[2]、水产养殖管理[3]、健康监测[4]等领域应用广泛。鱼类由于种类多,体型大小不一,姿态多样,不同品种鱼类的外形、色彩、纹理及尺寸等相似,且数据采集中存在姿态、视角、光照、遮挡、背景干扰等因素,导致出现同种鱼类样本间差异大、不同种类之间相似性高等问题,识别难度大。而人工鉴别又耗时耗力,且高度依赖专家的经验和技能。准确识别鱼类,对于物种多样性保护和渔业可持续管理至关重要。传统的鱼类自动识别研究采用人工设计的特征对鱼类表观进行特征表达,这类特征针对性强,可靠性高,特定场景效果好;但特征表达能力有限,较难捕获高级语义特征和复杂内容,导致其泛化能力和鲁棒性差,难以应用于实际中的复杂环境。
随着深度学习技术在人脸、指纹等目标识别任务中的成功应用[5-6],近年来,卷积神经网络(Convolutional Neural Network, CNN) 在水产物种自动识别中应用越来越广泛,并取得了较好的识别效果[7-11]。Zhuang 等[7]设计了一种多模态网络模型,利用成对文本描述来区分高度相似的鱼类;李均鹏等[12]提出了一种基于迁移学习的海洋鱼类识别方法,该方法通过迁移学习和模型融合的有效结合提升模型的鲁棒性和泛化性。针对鱼类不同的局部特征可刻画其类别,姚润璐等[13]对鱼类图像进行分割,获取鱼背、鱼尾等部位,提取其形态和纹理等精细特征,并结合反向传播神经网络进行识别;Christensen 等[14]开发了一种Lightfish 网络模型,用于水下恶劣条件下的鱼类识别和分类。此外,针对复杂水下环境采集的数据分辨率低的情况,Pramunendar 等[15]提出了一种基于反向传播神经网络的图像增强模型,通过选择合适的插值方法和网络配置提升图像的分辨率,进而提高鱼类识别的精度。
在自然界中,鱼类物种遵循长尾分布,即少部分鱼类占大数据样本,而多数鱼类却仅有少量样本,导致收集的数据集中类别分布不均衡。由于头部类别的样本量远大于尾部,易导致模型在头部类别 (多样本类别) 过拟合、尾部类别 (少样本类别)欠拟合,进而影响总体的识别性能。为缓解长尾分布带来的识别性能下降,目前的主要解决策略是重采样[16]和重加权[17-19]。Zhou 等[20]提出了一个统一的双边分支网络 (BBN),同时进行表征学习和分类学习,在此基础上设计了一种累积学习策略,使网络首先学习通用模式,然后逐渐加权尾部数据,提升识别性能。Wang 等[21]研发了一种基于学习平衡和鲁棒特征的长尾识别框架,通过构建注意特征增强模块,挖掘原始样本的类相关和变异相关特征,并对其进行聚合合成,以缓解原始数据集的类别不平衡。Pang 等[22]构建了一个分层块聚合网络,以促进不同的即插即用策略的相互学习,同时设计了一个数量感知平衡损失和解耦训练策略对其优化,增强网络的特征提取能力,进而提升长尾目标的识别性能。不过,上述方法多是通过牺牲头部识别性能以换取尾部识别性能的提升,总体性能虽得以提升,但由于缺少与重要特征结合进行识别,尾部类别识别的过拟合问题仍有待解决。
针对上述问题,本研究提出了一种基于多阶段特征提取的深度网络 (Multi-stage Feature Extraction Network, MF-Net) 模型进行鱼类识别,该模型首先使用预处理模块对图片进行预处理,然后构建多阶段特征提取模块,以学习到具有鲁棒细粒度表达能力和判别性能的高级特征,在此基础上,使用一个标签平滑损失函数以缓解鱼类类别不平衡问题。为验证该模型的有效性,构建了一个包含500 个类别的鱼类数据集进行实验对比和消融分析,并利用公开的蝴蝶数据集进行实验对比分析。
1 材料与方法
1.1 材料
通过渔业调查项目、网络爬虫技术等收集开放环境下 (如不同地域、季节、天气等) 各种姿态的鱼类图片数据,对其进行清洗、检测、专家鉴定等处理后构建鱼类数据集。该数据集包含500 种淡水和海洋鱼类,共32 768 张图片。其中,每类样本量多于200 张图片的鱼类有4 种,低于15 张图片的有10 种,数据集存在类别分布不均衡。如图1 所示,该数据集的特点如下:

图1 原始鱼类数据集特点Fig. 1 Characteristics of raw fish data
1) 鱼目标与背景相似:复杂多变的开放环境使得部分鱼类拥有环境保护色;此外,部分鱼类存在纹理与背景高度重叠及严重遮挡等情况。
2) 光线变化大:因水下环境光照条件差、亮度分布不均及光散射等原因,导致鱼类图片的颜色和纹理等存在失真情况。
3) 姿态各异:因拍摄角度不同,获取的鱼类图像有多种不同的视角,导致同一类别鱼类存在较大的表观差异。
4) 图像存在多目标:鱼类群体活动导致采集的鱼类数据存在多个目标。这些数据特性会降低识别精度,给鱼类自动识别带来极大挑战。此外,不同种类的鱼在形状、纹理、颜色等多种外观存在较高的相似性 (图2),进一步增加了识别难度。

图2 类间相似和类内差异Fig. 2 Subtle differences between species and dramatic changes among same species
1.2 MF-Net 识别模型
MF-Net 识别模型主要包括预处理模块、多阶段特征提取模块和标签平滑损失函数3 个部分(图3)。预处理模块对输入的鱼类图像通过卷积层和层归一化处理,将其映射到高维空间,以便后续模型获取图像丰富的判别特征;多阶段特征提取模块由多个MF-Net block 和下采样层构成,每一个特征提取块由影子卷积模块Ghost Module[23]、批量归一化、深度卷积、压缩和激励 (Squeeze and excitation, SE) 注意力机制、GELU (Gaussian error linear units)激活函数和路径丢失Droppath 构成。该模块通过对特征图的内在规律进行学习,进而从预处理后的特征图中学习到具有判别性的局部和全局特征。在训练过程中采用标签平滑损失函数对模型参数进行修正学习,以缓解数据类别的不平衡,提升模型的识别性能。

图3 MF-Net 模型结构Fig. 3 Structure of MF-Net
1.2.1 预处理模块
预处理模块采用卷积核大小为4×4、输出通道为96、步长为4 的卷积层和层归一化的组合,将输入的图像数据映射至高维空间(图4)。在高维空间中,深度学习模型可以关注图像数据中的重要特征信息,并可捕捉特征之间复杂的非线性关系。
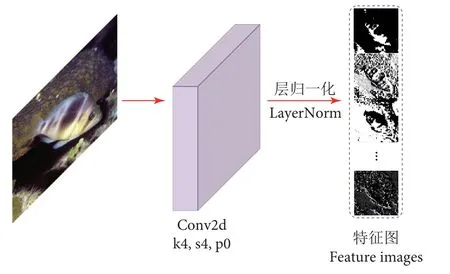
图4 预处理模块Fig. 4 Pre-processing module
1.2.2 MF-Netblock 模块
如图5 所示,在第一层残差结构中,输入的特征图首先经过影子卷积模块 Ghost Module,将提取的特征图传入到卷积核大小为 3×3、步长为1、填充为1 的深度卷积结构中,并对其批量归一化。在此基础上,通过SE 注意力机制对通道特征进行加权,后将特征图输入第二个Ghost Module,使用路径丢失Droppath 以一个固定的概率对该路径进行随机失活,以提升模型的泛化能力,然后与捷径分支的输出相加,并将结果传入第二个残差结构。当输入与输出特征图的尺寸不匹配时,可通过深度可分离卷积对输入的特征图进行维度调整。

图5 MF-Net block 结构Fig. 5 Structure of MF-Net block
第二层残差结构由2 个Ghost Module 及GELU激活函数组成,输入特征图在经过第一个Ghost Module 后,其输出特征图经过高斯误差线性单元激活函数的激活后,传入第二个Ghost Module,并使用Droppath 对该路径按一定的概率进行丢弃,然后与捷径分支的输出相加,并将该结果作为输出。在这一个残差结构中,输入、输出特征图的维度相等,捷径分支上的输出即为第一层残差结构的输出。
第一层残差结构主要对鱼类的一些浅层特征进行提取,并通过SE 注意力机制对特征图加权,使得MF-Net 模型更加关注图片中目标的关键特征。第二层残差结构主要是将第一层残差结构提取的浅层特征图映射到更高的维度,进一步提取到鱼类更加丰富的特征。
此外,MF-Net 模型中,在各个阶段之间添加1 个独立的下采样层。下采样层由池化核为 2×2、池化步长为2 的最大池化层构成,这样可在降低特征图的空间维度、减少网络中的参数数量及提高模型计算效率的同时保留特征图中的重要信息。此外,该下采样设计还可为网络引入了一定程度的平移不变性。
1.2.3 标签平滑损失函数
参考Szeged 等[24]的方法,本研究在训练过程中使用标签平滑损失函数对模型参数进行调整,以缓解数据分布不平衡带来的影响,其公式为:
式中:H(p,q) 和H(u,q) 均表示交叉熵损失函数,用于度量两个概率分布之间的差异性;n表示类别个数;p(xi) 表示样本xi的真实分布,p'(xi) 表示样本平滑后的分布;q(xi) 表示模型所预测的概率分布;u为人为引入的均匀分布;ϵ表示标签平滑的系数,为超参数,ϵ∈(0,1)。
1.3 MF-Net 模型训练
基于上述损失函数对模型进行训练。具体步骤如下:
1) 模型初始化:使用凯明均匀分布算法初始化除网络层外的所有卷积层的权值系数,使其均值为 0;使用正态分布算法初始化全连接层的权值系数,使其符合均值为0、方差为1 的正态分布。
2) 模型训练:将训练集传入MF-Net 中进行特征学习,并将经 Softmax 函数计算后得到的预测标签与真实标签使用标签平滑 (Label smoothing)损失函数计算网络模型的损失值。使用反向传播算法对MF-Net 的权值系数进行更新,使损失函数值不断地向全局最小进行逼近。
3) 模型测试:训练后的 MF-Net 在测试集进行测试,并输出在测试集的识别准确率。
4) 模型保存:将较优的模型权值系数保存到本地后,进行下一次的模型训练。
1.4 评价准则
为验证模型性能,以MF-Net 在测试集的第一准确率Acc-1 和前五准确率Acc-5 作为本网络模型的评价标准。Acc-1 指模型输出的概率最大的预测标签与真实标签相符的准确率;Acc-5 指模型输出概率前五的预测标签中包含真实标签的准确率。计算公式为:
式中:A为准确率;TP 为真实的正样本数量;TN 为真实的负样本数量;FP 为虚假的正样本数量;FN 为虚假的负样本数量。
为了进一步比较模型之间的性能,引入精确率、召回率、F1-score 这3 个评价指标。
精确率 (Precision,P) 的公式为:
式中:TPk表示第k个类别的真实正样本数量;FPk表示第k个类别的虚假正样本数量;n表示类别个数;通过计算出每个类别的精确率,再对其取平均值获得多分类的精确率。
召回率 (Recall,R) 的公式为:
其中,FNk表示第k个类别的虚假负样本数量;先计算出每个类别的召回率,再对其取平均获得多分类的召回率。
F1-score 的公式为:
通过公式(3) — (7) 计算最终的F1-score,F1-score 是精确率和召回率的调和平均数。
为比较各模型的性能,进一步引入模型的浮点运算次数 (FLOPs)、参数量 (Params) 和延迟(Latency)。浮点运算次数是网络模型复杂度的衡量指标,也是网络模型速度的衡量标准。参数量为在模型进行训练时所需训练的参数总数。网络模型预测一张图片所需的时间,即为延迟。
2 模型性能对比实验
2.1 实验环境与参数设置
本实验的环境为:64 位的Ubuntu 18.04 操作系统,图形处理器(Graphics Processing Unit,GPU)型号为NVIDIA GeForce GTX 1080 Ti,中央处理器 (Central Processing Unit, CPU)的型号为Intel(R) Core i7-6700 CPU @3.40 GHz,集成开发环境为 PyCharm2021.3.2 + anaconda3.0,采用Pytorch 1.12.1 作为深度学习框架构建与部署网络模型,并使用CUDA 版本并行并行计算框架。
模型迭代次数设置为180,批处理量为32。相对平滑损失函数中的平滑参数设置为0.1。训练时优化器选择AdamW 优化器,优化器的学习率变化中的最大参数设置为0.004,权重衰减系数的参数设置为0.05,一阶矩动量的指数衰减速率设置为0.9,二阶矩动量的指数衰减速率设置为0.999。其余的参数均为默认值。
此外,在网络模型训练时,学习率的动态变化分为两个阶段。第一阶段使用Warm-up 策略[25]调整学习率的变化,初始学习率为0,最大学习率为0.004,Warm-up 策略的epoch 数为12;第二阶段使用余弦退火算法对学习率进行调整,初始学习率为0.004,最小学习率为0.000 001,余弦退火算法[26]的最大epoch 数为168。
2.2 与通用目标识别算法对比分析
为验证该MF-Net 模型的识别性能,基于构建的鱼类数据集,将其与主流的通用目标识别方法ResNet-50[5]、GhostNet[23]和ConvNext[27]进行实验对比分析。基线为ResNet-50,其损失函数为交叉熵损失函数,ResNet-50 (标签平滑)表示模型采用的损失函数为标签平滑损失函数,所有模型均采用在ImageNet 的预训练参数,并使用默认参数与设置,结果见表1。
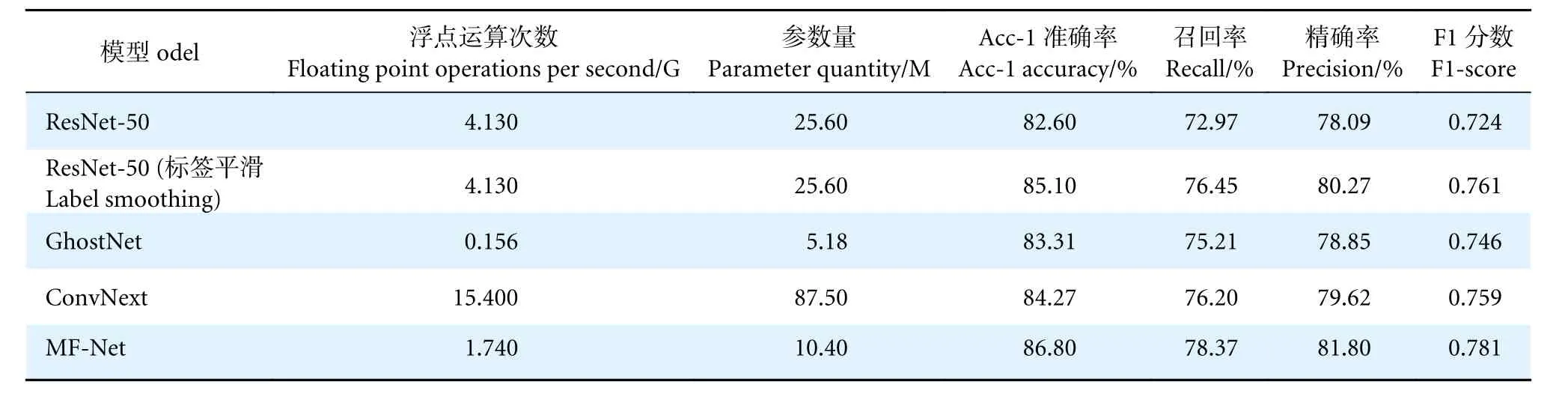
表1 主流识别模型性能对比Table 1 Comparison of different generic recognition methods
从表1 可以看出,MF-Net 模型的识别效果最好 (86.80%),其Acc-1 准确率比ResNet-50、Ghost-Net、ConvNext 和ResNet-50 (标签平滑) 分别高出4.2%、3.49%、2.53%和1.7%。主要原因在于MFNet 的多阶段特征提取可以获得更好的特征表达。另外,在浮点运算、参数量、精度、召回率及F1-score 等方面,该模型均优于ResNet-50 和ConvNext 模型,进一步表明MF-Net 模型的有效性。
2.3 长尾蝴蝶数据集下模型性能对比
为验证MF-Net 模型的细粒度特征提取和识别能力,在公开的长尾蝴蝶数据集[28]中进行实验对比,其中58 066 张图像为训练集,14 086 张图像为测试集。基于该数据集,将所提出的MF-Net 模型与双通路瀑布式 (Dual Route Cassaded, DRC) 模型、BBN 长尾模型和主流通用目标识别模型进行性能对比,参照公开数据集的设定,头部类别定义为含有大于等于100 张图片样本,尾部类别定义为含有小于等于30 张图片样本,并统计头部类别和尾部类别的平均精度,实验结果见表2。可以看出,DRC 和BBN 由于出现得较早,总体识别精度比常规模型低,但头部和尾部类别的识别性能较常规模型有所提升。MF-Net 模型在Acc-1 和头尾部类别的准确率上均为最优,表明MF-Net 模型不仅可提升长尾数据整体识别性能,同时也可提升头部和尾部的识别性能。
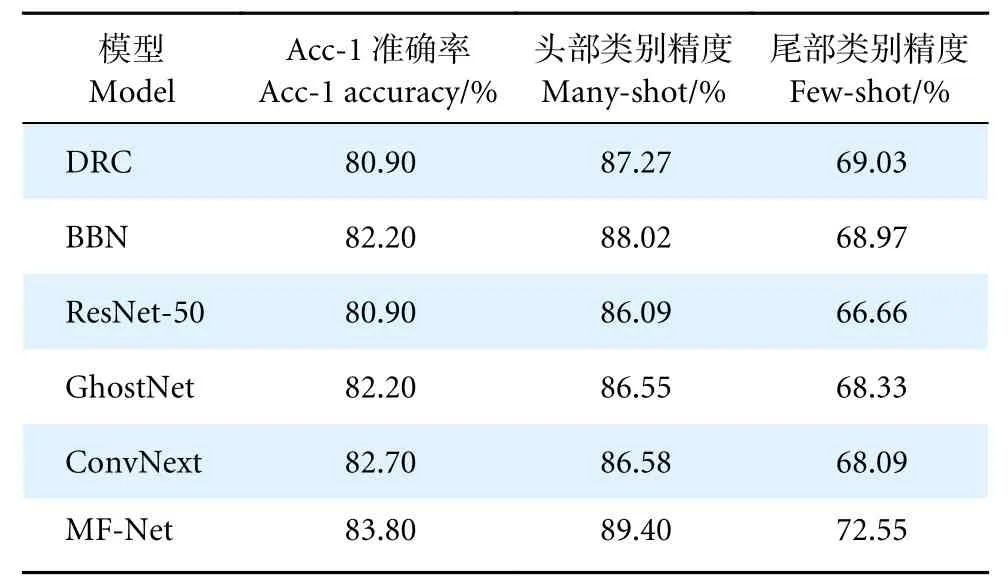
表2 蝴蝶数据集下不同长尾模型识别性能Table 2 Comparison of accuracy with different long-tailed methods on butterfly dataset
2.4 与长尾识别算法对比分析
为验证该MF-Net 模型对长尾数据的识别能力,选择有代表性的长尾识别模型BBN 和DRC[17]在鱼类数据集上进行识别实验,结果见表3。在识别精度方面,MF-Net 模型的性能最优,Acc-1 准确率为86.8%,较BBN 和DRC 模型分别高出2.43%和3.21%。主要原因是BBN 和DRC 模型对长尾数据中头部类数据的识别性能较弱,进而对整个数据集的识别准确率产生影响,而MF-Net 模型由于多阶段提取局部和全局特征,可以在保证头部数据性能的同时,进一步提升尾部数据的识别性能,从而提升了整体性能。

表3 鱼类数据集下不同长尾识别模型对比Table 3 Comparison of different long-tailed methods on fish dataset
3 消融实验验证
为进一步验证本研究MF-Net 模型中各模块的有效性,基于鱼类数据集,设置了以下5 个消融实验进行对比分析。
3.1 预处理模块结构消融分析
不同的预处理模块对模型性能影响有差异。对MF-Net 模型,使用不同预处理模块进行消融实验:第一组通过卷积层、批量归一化、ReLU 激活函数及最大池化的组合完成对图像数据预处理操作;第二组对图像数据中采用的卷积层、批量归一化、ReLU 激活函数的组合完成预处理操作;第三组使用卷积层、层归一化的组合对图像数据进行预处理操作。鱼类识别结果如图6 所示。可以看出,卷积层和层归一化的组合可更有效提升模型的性能。

图6 MF-Net 模型不同预处理方式的识别结果Fig. 6 Recognition results based on different pro-processing strategies in proposed MF-Net
3.2 主干网络模块消融分析
block 结构是网络模型的重要组成部件,在此设计不同的block 结构以验证所提结构的有效性。其中,Gbneck 为GhostNet 模型的block 结构,ResNet-Bottleneck 为ResNet 模型的模块结构,MFNet block (first residual)为MF-Net 网络中的第一层残差结构,MF-Net block 为本研究算法所采用的结构,结果如图7 所示。
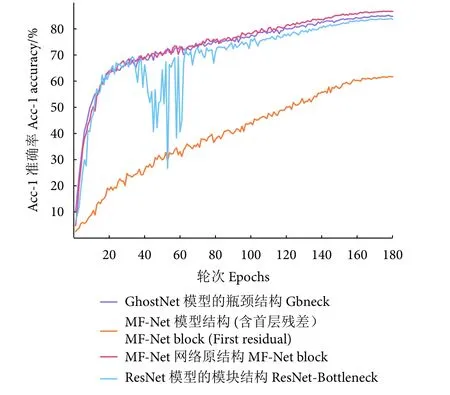
图7 MF-Net 模型不同block 结构的识别性能Fig. 7 Recognition results based on different block structures in proposed MF-Net
结果显示,不同的block 结构对最终鱼类识别的效果影响显著,如在主干网络中采用MF-Net block (First residual) 结构,其Acc-1 准确率仅61.80%,与Gbneck 结构和MF-Net block 结构相比,分别低23.3% 和25.0%。这是因为不同的block 层主要进行特征提取,结构不同提取的特征也不同。此外,MF-Net block 结构的识别性能最佳(86.80%),说明多阶段提取结构可以更好地捕获到鱼类更具判别性的细粒度局部特征和全局特征。
3.3 下采样消融分析
为验证该MF-Net 模型中下采样的有效性,设计不同的下采样方式进行分析,结果如图8 所示。可以看出,模型使用下采样策略时,其识别性能明显高于无下采样的情形,在鱼类识别Acc-1 准确率上,独立设置下采样结构的MF-Net 高于未设置下采样结构的1.4%,而使用最大池化采样的MFNet 模型识别性能最佳,表明下采样在降低特征图空间维度的同时还可保留特征的重要信息。
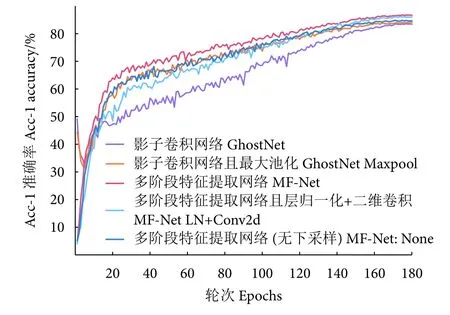
图8 MF-Net 模型中不同下采样策略Fig. 8 Recognition results based on different down sampling strategies in proposed MF-Net
3.4 损失函数消融分析
在网络训练中,损失函数指导模型的参数更新,进而影响模型的性能。为验证该MF-Net 模型损失函数的有效性,采用不同的损失函数进行实验对比分析,其Acc-1 和Acc-5 的实验结果见图9。可以看出,无论是Acc-1 还是Acc-5 的准确率,均为基于标签平滑损失函数的识别性能最佳,分别为86.80%和95.90%,分别高于交叉熵损失函数、加权交叉熵损失函数和焦点损失函数2%、2.3%、2.5%和0.2%、0.9%、0.4%,表明标签平滑损失函数可有效缓解数据分布不平衡问题,从而提升鱼类识别性能。
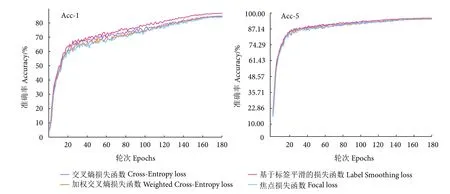
图9 基于不同损失函数的识别性能Fig. 9 Recognition results based on different loss functions in proposed MF-Net
3.5 平衡数据集的消融分析
为验证该MF-Net 模型损失函数对长尾分布数据集的有效性,从本研究构造的鱼类数据集中选出50 个类别,每类50~90 张样本数据构造一个平衡数据集。在平衡数据集上与交叉熵损失函数进行实验对比分析,结果见表4。可以看出,在其他设置相同的条件下,采用改动损失函数进行实验对比,可以看到在分布均衡的数据集上,尽管识别精度相对不平衡的数据集有一定提升,但标签平滑损失函数与交叉熵精度接近,这表明平衡的数据集交叉熵和标签平滑损失函数分类效果接近。此外,由于识别精度达到90 以上,因此召回率和F1-score与Acc-1 准确率更加接近。

表4 平衡鱼类数据集下不同识别模型损失对比Table 4 Comparison of different recognition methods with different losses in balanced fish dataset
4 结论
本研究提出了一个多阶段特征提取模型MFNet,用于开放复杂环境下的鱼类识别。该方法使用了一个预处理模块以提升计算效率,并通过构建的多阶段特征提取模块,以学习识别目标中具有判别性的局部特征和全局特征。在此基础上,采用标签平滑损失函数以降低数据类别分布不均衡带来的影响,从而增强模型的识别性能。实验结果表明,该模型在本研究所提出的鱼类数据集和公开的蝴蝶数据集上均获得了较好的识别效果。在未来工作中,拟在增加鱼类类别的基础上,构建新的主干网络结构,探索细粒度特征学习、损失函数设计与类别分布不均衡之间的关联,进一步提升鱼类的识别精度。
猜你喜欢
海洋信息技术与应用(2022年1期)2022-06-05
儿童时代·幸福宝宝(2020年9期)2020-09-08
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
金色少年(奇趣科普)(2016年8期)2016-09-21
公民与法治(2016年10期)2016-05-17
新校长(2016年8期)2016-01-10
计算机工程(2015年8期)2015-07-03
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
