
Enhancing low-resource cross-lingual summarization from noisy data with fine-grained reinforcement learning*
2024-03-06 09:17YuxinHUANGHuailingGUZhengtaoYUYumengGAOTongPANJialongXU
Yuxin HUANG, Huailing GU, Zhengtao YU‡, Yumeng GAO, Tong PAN, Jialong XU
1Faculty of Information Engineering and Automation,Kunming University of Science and Technology, Kunming 650504, China
2Yunnan Key Laboratory of Artificial Intelligence,Kunming University of Science and Technology, Kunming 650504, China
†E-mail: huangyuxin2004@163.com; ztyu@hotmail.com
Received Apr.27, 2023; Revision accepted Oct.22, 2023; Crosschecked Nov.3, 2023; Published online Dec.27, 2023
Abstract: Cross-lingual summarization (CLS) is the task of generating a summary in a target language from a document in a source language.Recently, end-to-end CLS models have achieved impressive results using large-scale,high-quality datasets typically constructed by translating monolingual summary corpora into CLS corpora.However,due to the limited performance of low-resource language translation models, translation noise can seriously degrade the performance of these models.In this paper,we propose a fine-grained reinforcement learning approach to address low-resource CLS based on noisy data.We introduce the source language summary as a gold signal to alleviate the impact of the translated noisy target summary.Specifically, we design a reinforcement reward by calculating the word correlation and word missing degree between the source language summary and the generated target language summary, and combine it with cross-entropy loss to optimize the CLS model.To validate the performance of our proposed model, we construct Chinese-Vietnamese and Vietnamese-Chinese CLS datasets.Experimental results show that our proposed model outperforms the baselines in terms of both the ROUGE score and BERTScore.
Key words: Cross-lingual summarization; Low-resource language; Noisy data; Fine-grained reinforcement learning; Word correlation; Word missing degree
1 Introduction
Cross-lingual summarization (CLS) is the task of automatically generating a short target language summary based on the source language’s long text, which can be regarded as a cross-lingual text generation task.In recent years, data-driven sequence-to-sequence models have achieved considerable performance in cross-lingual generation tasks such as machine translation (Rippeth and Post,2022),cross-lingual dialogue generation(Kim et al.,2021; Zhou et al., 2023), and video summarization(Li P et al., 2021; Javed and Ali Khan, 2022),and their performance is derived mainly from largescale, high-quality training data.However, due to the paucity of data,the performance of cross-lingual text generation tasks for low-resource languages is unsatisfactory.
The main challenge encountered in CLS tasks is the construction of extensive and high-quality CLS datasets.Currently, a large number of monolingual summarization datasets have been constructed for rich-resource languages such as Chinese and English.For instance, Hu et al.(2015) compiled a dataset named LCSTS,which includes Weibo posts as source texts and Weibo headlines as summaries.On the other hand, the Cable News Network/Daily Mail corpus primarily consists of news articles from the American Cable News Network and the Daily Mail(Hermann et al.,2015).However,acquiring and constructing CLS datasets through direct means remains a highly challenging task.The mainstream method is to use machine translation to translate the source language text or summary of a monolingual summary into the target language.For example,Zhu et al.(2019)used the round-trip translation(RTT)back-translation strategy to construct a CLS dataset.To ensure high-quality summaries,they applied several filtering criteria based on ROUGE(Lin,2004) score, including length consistency, sentence fluency, and meaning preservation.This resulted in a high-quality parallel corpus suitable for CLS research.However, the construction process of CLS datasets based on translation heavily relies on the performance of machine translation models.However, for low-resource languages such as Chinese-Vietnamese,machine translation performance is unsatisfactory,resulting in a significant amount of noise during the data construction process.In particular,the model’s ability to accurately generate summaries is greatly affected when the target language summary,which is used as the reference during training,contains translation errors.
According to statistics, there are about 50% of data with problems such as missing content words and improper word selection, as shown in Fig.1.In Fig.1a, the word “phản hồi (respond)” has been inaccurately translated as “处理(handle),” while in Fig.1b the content word “ví (wallet)” has been left untranslated.Employing such imprecise and incomplete pseudo-summaries as supervisory signals could potentially misguide the model.Drawing from this insight,we propose to introduce the source language summary and align it with the generated target language summary to assess the adequacy of the generated summaries in terms of word omission and accuracy.
Based on the aforementioned analysis and leveraging the alignment information between the source language summary and the generated target language summary,we propose a fine-grained reinforcement learning based CLS approach to mitigate the errors caused by improper word selection and missing content words, which are prevalent in pseudo-target summaries and can lead to misguided model training.To address the issue of improper word selection during the decoding process, we design a reinforcement learning reward by the word correlations between the source language summary and the generated target summary.To tackle missing content words in the generated summary, we penalize the decoder based on the importance of the missing words relative to the source language summary.
We propose a fine-grained reinforcement learning reward that incorporates word correlation and missing degree between the source language summary and the generated target language summary.We combine this reward with the traditional crossentropy loss to optimize the model, thus providing more effective guidance for generating the target language summary.
We conduct experiments on the Transformer framework using the Chinese-Vietnamese and Vietnamese-Chinese CLS datasets.The results show that our method achieves significant improvements compared with previous methods.Additionally,reinforcement learning rewards based on a combination of word correlation and missing degree can help generate a better summary.Our main contributions are as follows:
1.We model the relationship between the source language summary and target language summary from a fine-grained perspective, alleviating error guidance caused by noisy data in CLS tasks.
2.The experimental results show that this method achieves significant improvements compared with previous methods on the Chinese-Vietnamese and Vietnamese-Chinese CLS datasets.
2 Related works
2.1 Cross-lingual summarization
CLS is the task of generating a summary in a target language from a document in a source language.Traditional CLS tasks usually adopt a technical framework of translating first and then summarizing (Leuski et al., 2003; Ouyang et al., 2019) or summarizing first and then translating (Lim et al.,2004;Orˇasan and Chiorean,2008).However,they are often affected by the error propagation of translation and summarization models, and the results are not satisfactory in low-resource languages.Neural network based CLS tasks(Jiang et al.,2022;Wang et al.,2022)are usually seen as similar to machine translation tasks, but the difference is that machine translation maintains the same amount of information in its input and output,whereas CLS requires compression and translation of information.There are typically two types of methods for low-resource language CLS tasks.The first type is summary methods based on zero-shot learning.Ayana et al.(2018)addressed the problem of the lack of source language to target language summary datasets by using a pre-trained machine translation model and a headline generation model as teacher networks to guide the learning of the cross-lingual headline generation model.This approach enables the model to have translation and summarization abilities and to generate cross-lingual summaries under zero-shot conditions.Nguyen and Luu (2022) employed a monolingual summarization model as the guiding teacher network to facilitate parameter learning in the CLS model.The second type of method is based on a multi-task joint learning approach that combines machine translation and summarization models to address the problem of sparse training data (Takase and Okazaki, 2020;Liang et al.,2022).Zhu et al.(2019)proposed an endto-end CLS model based on the Transformer text generation framework.They jointly trained the CLS and monolingual summarization and the CLS and machine translation tasks with parameter sharing at the encoding stage.During the training process,the two tasks were alternately trained to have the ability to generate cross-lingual summaries.Cao et al.(2020)used generative adversarial networks to align the contextual representations of two monolingual summarization models in the source and target languages,achieving bilingual alignment while performing monolingual summarization.Bai et al.(2021)argued that although joint learning of CLS and machine translation can enhance CLS performance by sharing encoder parameters,the decoders of the two tasks are independent of each other and cannot establish good alignment between CLS and machine translation tasks.Based on the analysis,most of the aforementioned works are based on machine translation to construct pseudo parallel CLS datasets from monolingual datasets, targeting languages with rich resources such as Chinese and English, where machine translation performs well and has fewer errors.However,for low-resource languages,the translation performance is unsatisfactory,and constructing CLS datasets through translation can introduce a large amount of data noise.Effective analysis and processing methods for CLS in low-resource and noisy data scenarios are still lacking.
2.2 Reinforcement learning
Reinforcement learning has been widely used in many tasks (Zhao J et al., 2022; Li HQ et al., 2023;Xiong et al.,2023),such as machine translation and text summarization,mainly through global decoding optimization to alleviate the exposure bias problem(Kumar et al.,2019;You et al.,2019).In the summarization task,Paulus et al.(2017)used the ROUGE value between the real summary and the generated summary as a reinforcement learning reward to reward or punish the model and to combine this reward with cross-entropy using linear interpolation as the training objective function,which partially alleviates the exposure bias problem.According to B¨ohm et al.(2019),the correlation between ROUGE and human evaluation is weak when it comes to summaries that have a diverse vocabulary, which suggests that using ROUGE as a reinforcement learning reward may not be reliable.They used the source text and the generated summary as the input to learn a reward function from human-scored summaries, achieving better results than thoses using ROUGE as a reward.Yoon et al.(2021) calculated the semantic similarity between the generated summary and the reference summary based on a language model as a reinforcement learning reward, improving the reward acquisition method of word-level matching ROUGE.For CLS tasks,Dou et al.(2020)used the similarity between the source language summary and the generated target language summary as a reinforcement learning reward to constrain the model to generate better summaries.Inspired by this study,we believe that by better modeling the correlation between the source language summary and the generated summary,we can effectively use the noise-free source language summary to alleviate the noise problem caused by the translation.
3 Fine-grained reinforcement learning for low-resource cross-language summarization
To address the issue of noise in the supervision signal in low-resource cross-language summarization,we propose a fine-grained reinforcement learning method for cross-language summarization based on the Transformer model (Vaswani et al., 2017).To improve the quality of generated summaries and mitigate the impact of noise in pseudo-target language summaries, we design reinforcement learning rewards based on the word correlation and missing degree between the source language summary and the generated target language summary.The reinforcement learning function is then combined with the maximum likelihood estimation function as the training objective to optimize the generated summary.The model structure is shown in Fig.2.
3.1 Model
In traditional CLS models based on the Transformer architecture, given a training set{XA,˜Y B},whereArepresents the source language andBrepresents the target language, each documentXAis mapped to a high-dimensional vector to obtain an input document sequenceXA={x1,x2,...,xN},which is then encoded by the encoder to obtain a vector representationH={h1,h2,...,hN}of the document sequence (Nis the length of sequenceXA).Finally, the decoder generates a summary sequenceY B={y1,y2,...,yM}based on the givenH.During this process, the maximum likelihood estimate between the generated summaryY Band the reference summary ˜Y Bis used as the optimization objective,and the cross-entropy loss function is defined as follows:
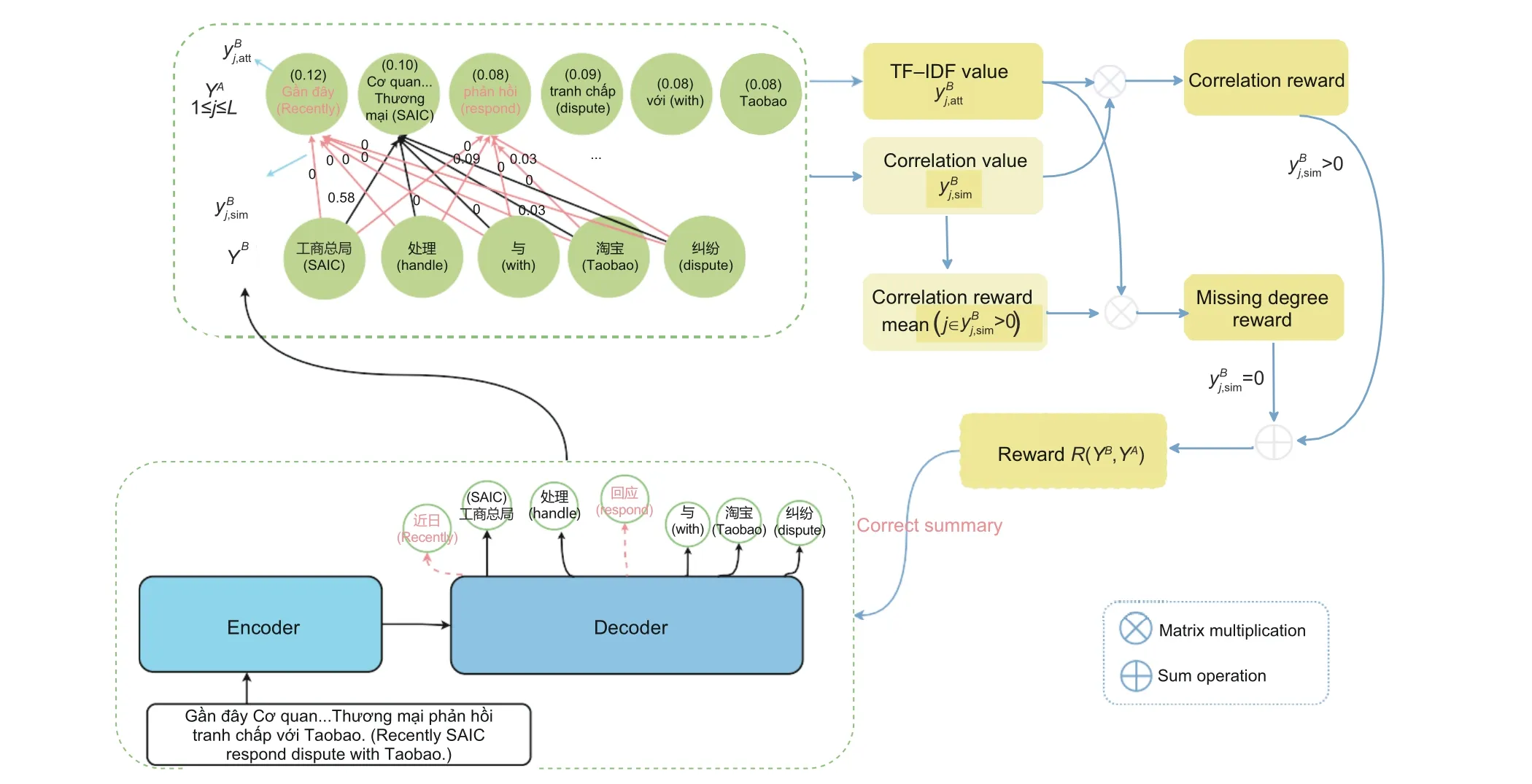
Fig.2 Fine-grained reinforcement learning model structure to improve the quality of model-generated summary by computing word correlation and missingness between decoder-generated summary and source language summary (Words in red represent the updated words.References to color refer to the online version of this figure)
whereMis the length of summarizationY B.
3.2 Reinforcement learning loss based on word correlation and word missing degree
Given the training set{XA,˜Y B}obtained by translating a monolingual summary dataset, we investigate the noise types that account for a significant proportion of errors in ˜Y Bdata, namely, improper word selection and missing content words(detailed analysis is given in Section 4.1.2).Therefore,we introduce the source language summaryY Aas a reference and design a reinforcement learning reward by calculating the word correlation and word missing degree between the source language summaryY Aand the generated target language summaryY Bto weaken the error guidance caused by the pseudotarget language summary as the supervision signal.


In the CLS model, we consider the model as an agent,with the context representation vector obtained at each decoding steptand the summaryyB<tgenerated in the previous time stept-1 being perceived as the environment.During the process of summary generation, the agent needs to choose a word from the candidate word list as the summary word for the current time stept; this selection process constitutes an action of the agent.Upon completing a summary generation, the model receives a rewardR(Y B,Y A).The reward function calculation process is shown in Algorithm 1.By assigning higher scores, the model is encouraged to generate better summaries.We use Eq.(4)to calculate the expected reward:

whereYrepresents all the possibly generated candidate summaries.An exponential search space is constituted in the summary generation process.

Algorithm 1 Reward function design 1: Input: Yidf, Y A→B align /* Input TF-IDF values of source language summary words and correlation table */2: score ←0 /* Total reward score */3: sumwd ←0 /* Total word missingness penalty score */4: Countcor ←0 /* Count the number of times yBj,sim being greater than 0 */5: sumcor ←0 /* Total word correlation score */6: for yAj,idf in Y Aidf do 7: yBj,sim ←sim(yAj ,Y A→Balign )sum 8: if yBj,sim =0 then 9: sumwd ←sumwd -yAj,idf 10: else 11: scorecor ←yBj,sim·yAj,idf 12: score ←score+scorecor 13: sumcor ←sumcor +yBj,sim 14: Countcor ←Countcor +1 15: end if 16: end for 17: if Countcor/=0 then 18: avgcor ← sumcor Countcor 19: score ←score+sumwd ·avgcor 20: end if 21: return score
In practice,a sequenceYSis often sampled from the probability distribution functionP(Y B|XA;θ)to optimize the expected reward; however, this can result in high variance.To address this issue, we adopt the same method as in previous research(Rennie et al., 2017; Kang et al., 2020) and introduce a baseline reward to reduce gradient variance.We use the self-critical policy gradient training algorithm in the training of the reinforcement learning objective,which involves two summary-generating strategies:one whereYSis randomly sampled from the conditional probability functionP(Y B|XA;θ) and the other whereYGis generated by the greedy decoding.The training objective of a summary sentence in reinforcement learning is as follows:
4 Experiments
4.1 Data analysis
4.1.1 Data construction
We constructed two types of CLS datasets:Chinese-Vietnamese and Vietnamese-Chinese.For Chinese-Vietnamese summarization, we used the first 200 000 data samples of LCSTS (Hu et al., 2015) for back-translation to obtain the Chinese-Vietnamese CLS dataset (Zh-Visum).For Vietnamese-Chinese summarization, we crawled Vietnamese monolingual datasets from various news websites, including Vietnam+, Vietnam News Agency, Vietnam Express, and Vietnam News Agency.The collected data were then cleaned and back-translated to obtain 115 798 samples of the Vietnamese-Chinese CLS dataset(Vi-Zhsum),where the translation was performed by YunLing translation (http://yuntrans.vip).We used ROUGE (Lin,2004), BERTScore (Zhang et al., 2020), and MGFScore (Lai et al., 2022) to filter the back-translated data.Taking Zh-Visum as an example, the specific workflow is shown in Fig.3.

Fig.3 Zh-Visum filtering flowchart
Finally, the hybrid objective function for training the CLS model is a linear interpolation of the crossentropy loss function and the reinforcement learning training objective function, expressed as
whereγis the scale factor between the cross-entropy loss function and the reinforcement learning training objective function.
In Zh-Visum, the lowest 50% of the filtered data were removed, leaving 100 000 data samples;due to the relatively high quality of Vi-Zhsum backtranslation,the lowest 30%of the data were filtered,leaving 81 000 data samples.Detailed information on back-translation scores before and after data filtering is shown in Table 1.
4.1.2 Noise analysis
From Table 1, it can be seen that the filtering of the back-translated data effectively improves the quality of Zh-Visum and Vi-Zhsum.However,further analysis of Zh-Visum and Vi-Zhsum revealed that only a small proportion of sentences were completely correct, and that high-quality and large-scale data were needed for training the model.We further analyzed the noise in the cross-lingual data constructed by machine translation according to the types of noise defined in the literature(Zhao H et al., 2013).
We randomly selected 100 pairs of source and target language summaries from the Chinese-Vietnamese and Vietnamese-Chinese CLS datasets and manually marked the noise types in the unfiltered and filtered data using three different filtering methods:ROUGE,BERTScore,and MGFScore.Table 2 shows the noise type statistics.Additionally,50%of the Zh-Visum data and 30%of the Vi-Zhsum data have been filtered.
We can have the following conclusions from Table 2:
1.The proportion of error-free sentences in the constructed cross-lingual summary dataset is relatively small.Even though filtering by evaluation metrics can improve the data accuracy, it cannot avoid noisy data.Therefore,after improving the quality of the dataset, further research is needed on methods for cross-lingual summary generation under noise.
2.In both Vi-Zhsum and Zh-Visum, the types of noise with the first and second highest proportions are inappropriate word selection and missing content words.In Zh-Visum, the data are obtained through back-translation from LCSTS, a short text summary dataset obtained from Weibo using headlines as summaries.The Chinese words used in these summaries are often concise and to the point, making it easy for machine translation to deviate from the correct understanding and ignore some content words.In Vi-Zhsum, errors in word order are also common as Vi-Zhsum is translated from longer texts,and machine translation tends to have weaker comprehension of the logical sequence between words in longer texts, making it prone to mistakes in word order.This type of noise has a weaker impact on the quality of the generated sentences.
In summary, in both Vi-Zhsum and Zh-Visum,the types of noise with the first and second highest proportions are improper word selection and missing content words.Therefore,it is necessary to use data filtering to improve the quality of pseudo-data and continue to weaken the noise.
To verify the effectiveness of the proposed model, we constructed a Chinese-Vietnamese CLS dataset Zh-VisumFilterwith 100 000 samples and a Vietnamese-Chinese CLS dataset Vi-ZhsumFilterwith 81 000 samples, using the method described in Section 3.1.The detailed data are shown in Table 3,where BERT represents using BERTScore to filter Zh-Visum data, MGF represents using MGFScoreto filter Vi-Zhsum data, and RG represents using the ROUGE metric to filter the data.Regardless of the filtering and training method used, the test sets are the same for the same language.

Table 1 Back-translation score for Zh-Visum and Vi-Zhsum

Table 2 The proportion of data of different noise types in Zh-Visum and Vi-Zhsum
4.2 Evaluation metrics
In this study, the quality of summaries generated by the CLS model was evaluated using two evaluation metrics.As with most summarization works,one is based on a statistical method called ROUGE(Lin, 2004), which calculates the co-occurrence degree ofN-grams between the standard summary and the generated summary,and the formula is as follows:
whereGis the generated summary, Ref is the reference summary, gramNis theN-gram phrase,Countmatch(gramN)is the number of overlappingNgrams in the generated summary and the reference summary, and Count(gramN) is the number ofNgrams in the reference summary.Nis usually set to 1, 2, andL(Lis the length of the longest common subsequence).In this study, ROUGE-1, ROUGE-2,and ROUGE-Lare used to evaluate the quality of the generated summary,denoted as RG-1,RG-2,and RG-L,respectively.
The other evaluation method for measuring the quality of generated summaries in a CLS model is based on deep semantic matching, as proposed by Zhang et al.(2020).This method is called BERTScore and uses a pre-trained language model to calculate the semantic similarity between the generated and reference summaries.Nowadays, this method is widely used to evaluate the quality of generated summaries.In Chinese,the pre-trained model used for scoring is“bert-base-Chinese,”while in Vietnamese the pre-trained model used is “bert-basemultilingual-cased.” In the case of using BERTScore for evaluation,the “<unk>” tokens in the generated summaries are replaced with the“[unk]” tokens from the BERT vocabulary.
4.3 Experiment setup
The model code was implemented using the Py-Torch framework.The Transformer encoder and decoder were both set to six layers,with eight attention heads and a hidden vector dimension of 512.The feedforward neural network was configured with a size of 1024.The model used a teacher-forcing strategy,with a label smoothing set to 0.1 and a dropout set to 0.1.The model was trained with the warmup phase of 3000 steps and accumulated a gradient every two steps.During decoding,a beam search strategy with a beam size of five was used.It is worth noting that similar to Wu et al.(2019) and Unanue et al.(2021), for models with reinforcement learning strategies, we used unfiltered Zh-Visum and Vi-Zhsum data for parameter initialization and then trained the model using filtered data.
4.4 Baselines
To verify the effectiveness of the proposed finegrained reinforcement learning approach for Chinese-Vietnamese CLS, we trained and compared the following baseline models on the Zh-VisumFilterand Vi-ZhsumFilterdatasets:
1.Sum-Tra:It is a traditional CLS method that generates a summary in the source language first and then translates it into the target language.
2.Tra-Sum: Similar to Sum-Tra, it is a twostep CLS method that translates the source languagedocument into the target language and then generates a summary in the target language.In Sum-Tra and Tra-Sum,YunLing translation is used as the machine translation model,and an unsupervised extractive method called LexRank (Takase and Okazaki,2020)is used as the summarization model.

Table 3 Experimental data details
3.NCLS(Zhu et al.,2019):This is an end-to-end neural network CLS model based on the Transformer framework.It incorporates two related tasks,monolingual summarization and machine translation, to further improve model performance.
4.MCLAS(Bai et al., 2021):This CLS method is based on the multi-task framework, which sequentially performs monolingual summarization and CLS, using BERT (mBERT) to initialize the Transformer encoder.
5.KDCLS(Nguyen and Luu,2022):It is a novel knowledge distillation based framework for CLS,seeking to explicitly construct cross-lingual correlation by distilling the knowledge of the monolingual summarization teacher into the CLS student.
6.LR-ROUGE(Yoon et al.,2021):This method is similar to the proposed method, but it uses RG-Lto calculate the expected reward.
7.XSIM (Dou et al., 2020): This method employs reinforcement learning to directly enhance a bilingual semantic similarity metric between the summaries generated in a target language and the gold summaries in a source language.
8.LR-MC: The proposed CLS model combines cross-entropy and reinforcement learning as the optimization objective.The expected reward is calculated based on the word missing degree and word correlation between the source language summary and the generated target language summary.
4.5 Analysis of experimental results
We designed experiments from different perspectives to verify the effectiveness of the Chinese-Vietnamese and Vietnamese-Chinese CLS method based on fine-grained reinforcement learning under noisy data.
First, the effects of fine-grained reinforcement learning proposed were compared with those of baseline models.Then, the improvements of word correlation reward and word missing penalty based on reinforcement learning designed under noise were explored, and the respective impacts of these parts on the model were analyzed.Second, the influence of the proportion factor between the cross-entropy loss function and the reinforcement learning training objective function on model performance was investigated.Next, the neural network model was trained using data before and after noise filtering, and the performances of the model under different data were compared.Finally, a case study was conducted for the summaries generated by different models.
4.5.1 Experimental results
The results of comparison between the proposed model and the baselines are shown in Table 4.Here,γrepresents the scale factor between cross-entropy loss and the expected reward;γ= 1 means that no reinforcement learning reward is added.
From Table 4, it can be seen that the proposed method performed the best on both the Chinese-Vietnamese and Vietnamese-Chinese crosslanguage summarization tasks (achieving the best performance withγset to 0.6).The LR-MC model trained on noisy data and then fine-tuned on real data showed further improvement in model performance.LR-MC showed a larger improvement in RG-2 metric, which may be due to the higher quality and better coherence of pseudo-summary texts in real data.When compared with XSIM, the LR-MC model outperformed in both Chinese-Vietnamese and Vietnamese-Chinese cross-language summarization tasks.Additionally, in comparison to KDCLS,LR-MC achieved higher summary quality, particularly exhibiting significant improvements in the Chinese-Vietnamese cross-language summarization task.This outcome can be attributed to the significant linguistic disparities between these two languages, suggesting that the guidance provided by monolingual summarization or translation may not effectively support low-resource CLS.
Compared with directly using the cross-entropy loss function to optimize the model,adding the finegrained expected reward proposed can effectively weaken the noise.Under the Zh-Visum data, RG-1 showed an improvement of 2.59%, RG-2 showed an improvement of 4.19%, RG-Lshowed an improvement of 3.50%,and BERTScore showed an improvement of 0.30%.Similarly, under the Vi-Zhsum data,RG-1 demonstrated an improvement of 2.78%,RG-2 showed an improvement of 1.97%, RG-Lshowed an improvement of 1.87%, and BERTScore showed an improvement of 0.34%.Using the reward expectation calculated by the word correlation and word missing degree between the real source language summary and the generated target summary can further improve the model performance, compared with the method of using ROUGE as the reward expectation and the cross-entropy loss function in RG-L.This shows that the fine-grained reinforcement learning method proposed has good performance in both Chinese-Vietnamese and Vietnamese-Chinese CLS tasks, as well as in noisy data with short or long texts.It can weaken the impact of noise brought by pseudo-target language summaries to some extent.
4.5.2 Ablation experiment
To verify the effect of the reinforcement learning reward based on word correlation and word missing degree on the performance of the model, two single modules were used in the ablation experiment, and the results are shown in Table 5.
According to Table 5, both the word correlation and word missing degree between the source language summary and the generated target summary were helpful in improving the model performance.When calculating only the word missing degree between the source language summary and the generated target language summary as the expected reward(LRmis),the performance decrease was more significant, and when calculating only the word correlation as the expected reward(LRcor), the performance decrease was relatively small.We believe that this is due to two reasons.First, when using only the word missing degree, the information obtained by the model is relatively limited.Second, the word missing degree is designed for the noise type of missing content words,and from the analysis of the noisy data, it can be seen that the proportion of missing content words is smaller than that of improper word selection.
4.5.3γparameter experiment
From Table 6, it can be seen that the model performed the best whenγwas set to 0.6.Asγdecreased, the proportion of reward expectation increased, and the model performance did not reach its optimal level.Based on the experimental results on the decoding of the test set data, it was found that the increase in the proportion of reward expectation resulted in a higher proportion of out-ofvocabulary words in the decoded summary, which was the main reason for the decrease in summary generation quality.
We believe that using reinforcement learning reward as the optimization objective function, the word-level reward based on the source languagecontains more word-level information, but does not include the logical relationships or sequence features between words in the target language.Compared with the Chinese-Vietnamese CLS of short texts,in the Vietnamese-Chinese CLS of long texts, the proportions of word order and logical relationships between words are larger.This is also the reason why the performance of the model decreases more quickly when increasing the proportion of expected reward in the Vietnamese-Chinese CLS.Therefore,even though the word-level reward based on the source language summary designed in this study has an encouraging effect in reducing noise, it is not recommended to use this reward alone to train the model.Using the expected reward in combination with cross-entropy loss can better learn the word order information between target language words while reducing noise.

Table 4 Results of comparison with baseline models

Table 5 Ablation experiment results
4.5.4 Exploring the effect of noisy data on model performance
To fully investigate the impact of noisy data on neural network models,we conducted comparison experiments using the basic Transformer framework.The specific results are shown in Table 7.
Table 7 shows that neural network models were sensitive to noisy data, and that filtering out noisy data was more conducive to model learning when using the same amount of data for training.In the Chinese-Vietnamese cross-language summarization dataset,the data noise was relatively high,and training the model with the top 100 000 high-quality data samples was still more conducive to generating readable summaries than training with unfiltered 200 000 data samples.In comparison,the Vi-Zhsum dataset had a smaller size but relatively high quality.Training the model by filtering out the top 30% of the data resulted in slightly worse performance in RG-2 and RG-Lmetrics than using all data for training,but the noise had a negative impact regardless of the dataset.Therefore, starting from noisy data, it is necessary to study cross-language summarization between Chinese and Vietnamese.
4.5.5 Case analysis
Table 8 presents examples of summaries generated by different summarization models, using the Vi-Zhsum task as an example.From Table 8, it can be seen that the method proposed generated summaries with the highest quality among several summarization models.The base model trained on unfiltered data(Transformer-all)generated less summary information.After further training the model using high-quality data, all models attempted to generatemore informative summaries,but only the Vi-Zhsum fine-grained reinforcement learning summarization model proposed generated the key information: “So far, Vietnam has recorded <unk>patients.”

Table 6 Experimental results at different γ values

Table 7 Experimental results under different noisy data
5 Conclusions
In this paper we analyze and study the noise problem in Chinese-Vietnamese cross-language summarization and propose a fine-grained reinforcement learning cross-language summarization method for the existence of two types of noise in pseudo-target summarization: improper word selection and lack of content words.Using the real source summary and the generated summary as a benchmark,the method calculates the expected reward based on the word correlation and missingness between the source and generated summaries to weaken noise.The traditional cross-entropy loss between the pseudo-target language summary and the generated summary is also retained to learn the word order relationship between the target languages.The combination of reinforcement learning loss and cross-entropy loss is used as the optimization objective for model training,reducing the negative impact of noisy data when directly using pseudo-target language summaries to train the model and enhancing the quality of generated summaries.In addition,the experiments explore the impact of noisy data on neural network models,and the results show that high-quality data are more conducive to model training.
Contributors
Yuxin HUANG designed the research.Yumeng GAO processed the data.Huailing GU drafted the paper.Tong PAN and Zhengtao YU helped organize the paper.Huailing GU and Jialong XU revised and finalized the paper.
Compliance with ethics guidelines
Yuxin HUANG, Huailing GU, Zhengtao YU, Yumeng GAO, Tong PAN, and Jialong XU declare that they have no conflict of interest.
Data availability
Due to the nature of this research, participants of this study did not agree for their data to be shared publicly, so the supporting data are not available.
 Frontiers of Information Technology & Electronic Engineering2024年1期
Frontiers of Information Technology & Electronic Engineering2024年1期
- Frontiers of Information Technology & Electronic Engineering的其它文章
- Comment:ChatGPT:potential,prospects,and limitations*
- Controllable image generation based on causal representation learning*
- Deep3DSketch-im: rapid high-fidelity AI 3D model generation by single freehand sketches*
- TendiffPure: a convolutional tensor-train denoising diffusion model for purification
- Prompt learning in computer vision:a survey*
- Advances and challenges in artificial intelligence text generation*