
Prompt learning in computer vision:a survey*
2024-03-06 09:17:36YimingLEIJingqiLIZilongLIYuanCAOHongmingSHAN
Yiming LEI, Jingqi LI, Zilong LI, Yuan CAO,Hongming SHAN
1Shanghai Key Laboratory of Intelligent Information Processing, School of Computer Science,Fudan University, Shanghai 200438, China
2Institute of Science and Technology for Brain-Inspired Intelligence, Fudan University, Shanghai 200433, China
3MOE Frontiers Center for Brain Science, Fudan University, Shanghai 200433, China
4Shanghai Center for Brain Science and Brain-Inspired Technology, Shanghai 201210, China
†E-mail: ymlei@fudan.edu.cn; hmshan@fudan.edu.cn
Received May 31, 2023; Revision accepted Oct.17, 2023; Crosschecked Jan.5, 2024
Abstract: Prompt learning has attracted broad attention in computer vision since the large pre-trained visionlanguage models (VLMs) exploded.Based on the close relationship between vision and language information built by VLM, prompt learning becomes a crucial technique in many important applications such as artificial intelligence generated content (AIGC).In this survey, we provide a progressive and comprehensive review of visual prompt learning as related to AIGC.We begin by introducing VLM, the foundation of visual prompt learning.Then, we review the vision prompt learning methods and prompt-guided generative models, and discuss how to improve the efficiency of adapting AIGC models to specific downstream tasks.Finally, we provide some promising research directions concerning prompt learning.
Key words: Prompt learning; Visual prompt tuning (VPT); Image generation; Image classification; Artificial intelligence generated content (AIGC)
1 Introduction
Prompt learning was first proposed in the natural language processing (NLP) community, which endows language models with the ability to model raw texts directly (Lu YN et al., 2022).Specific research directions include pre-trained models,prompt engineering, and prompt fine-tuning.Based on the great success of prompt learning, it is noteworthy to discuss how prompt learning improves computer vision (CV) tasks, which can inspire more valuable research and vision applications.As shown in Fig.1,for a wide range of CV tasks, prompt embedding,yielded by traditional prompt and prompt learning,is a direct controlling condition that endows outputs of generative models with animated contents and improves the performance of discriminative models.
For the past decade, vision tasks have been largely enhanced by convolutional neural networks(CNNs) and corresponding techniques such as attention mechanism and skip connection.Various CNN variants have progressively improved the performances of tasks including image classification,object detection, and semantic segmentation.Because the Transformer has empowered NLP models with generalized representations, the vision Transformer(ViT)has triggered a new revolution in the CV community (Dosovitskiy et al., 2021; Khan et al., 2022;Han et al., 2023; Shamshad et al., 2023).For the vision tasks, current ViT-based networks have surpassed the corresponding CNN counterparts with a relatively equal magnitude of trainable parameters.In addition to these high-level recognition tasks,ViT works well in low-level image processing tasks, such as image denoising,deblurring,and deraining.
People ask me, How do you do it? Praise helps-Muriel is a joy to me, and life is good to both of us, in different ways. And we have family and friends who care for us lovingly.

Fig.1 Pipeline of learning with traditional and learnable prompts.Prompt learning is a critical technique in current AIGC tasks.Apart from human-understandable prompts, learnable prompts have been proposed to further enhance specific tasks
Because the Transformer has been successful in both CV and NLP fields, the large-scale visionlanguage models (VLMs) pre-trained on large numbers of image-text pairs, have subverted the learning paradigms of many visual tasks and serve as the foundation of prompt learning in CV.A typical framework is contrastive language-image pretraining(CLIP), which aligns visual and textual features through contrastive learning (Radford et al.,2021).Compared with CLIP, A Large-scale ImaGe and Noisy-text embedding (ALIGN) conducts the same contrastive learning scheme and pre-trains the image and text encoders using more training data with noisy samples (Jia C et al., 2021).This kind of pre-trained model formulates the image classification problem as an image-text matching scheme,enriching the learning information against the traditional one-hot approximation.Notably, these methods have amazing few-shot, zero-shot learning, and image-text retrieval capabilities, and hence, CLIP provides follow-up research with fundamental learning paradigms and powerful image and text encoders.
The success of CLIP is inseparable from the prompt engineering and prompt ensemble, which help learn generalized multi-modal representations.In the NLP community, prompt-based learning enables language models to predict the probability of raw text directly, where the prompt refers to a language template describing the corresponding category information (Liu PF et al., 2023).This framework allows successful pre-training of large-scale language models (LLMs) using massive raw texts; for example, the texts are crawled from the Internet directly.Although the effectiveness of applying prompt engineering for VLMs has been validated in CLIP, only hand-crafted language templates are used, which hinders further performance improvement for downstream tasks, such as “a photo of a[CLS]” and “a blurry photo of the [CLS],” where“[CLS]” denotes the class token.To achieve more generalized prompts for facilitating downstream image classification,Zhou KY et al.(2022a,2022b)proposed to learn trainable prompts through contrastive learning.Then,many studies on language prompting emerged and intended to learn more explainable text tokens correlated with image features.In addition,inspired by such language-driven prompt learning,visual prompting aims at adapting large models to downstream tasks depending on the constructed image prompt inputs, which is different from the aims of language prompting(Bahng et al.,2022;Bar et al.,2022; Xing et al., 2022; Chen AC et al., 2023; Zhu JW et al., 2023).
Based on the efficient prompt learning paradigms mentioned above, language-driven prompting facilitates traditional deep generative models like generative adversarial network (GAN)based methods (Goodfellow et al., 2020).Recently,since the denoising diffusion probabilistic model(DDPM)(Ho et al.,2020)was proposed for image-toimage translation,diffusion-based generative models have attracted much attention and surpassed GANs in many image generation tasks including image editing and image inpainting.A popular method called Stable-Diffusion was used to conduct a diffusion process in the low-dimensional latent space, and obtained high-resolution image synthesis results on various tasks such as super-resolution and inpainting, requiring relatively low computational costs(Rombach et al.,2022).
While she was wondering by what magic the Beast had transported them and herself to this strange place she suddenly heard her father s voice, and rushed out and greeted him joyfully69
wheredOT(k) is the OT distance obtained by innerloop optimization using the Sinkhorn algorithm(Cuturi,2013):
1.The pre-trained large-scale multi-modal models.The large-scale VLMs, such as CLIP (Radford et al., 2021), BLIP (Li JN et al., 2022), and ViLT (Kim et al., 2021), and speech-language models including Whisper(Radford et al.,2023),provide researchers with powerful image and text encoders.These models capture high-level contextual information effectively, facilitating efficient connections between multi-modal prompts and images.Consequently, the optimization process in the training phase is streamlined as the model can focus on conditional generation or editing tasks rather than learning to extract context.

Fig.2 Overall structure of this survey.We provide each research direction with some selected methods
To collect the papers reviewed in this article,we entered the search terms “prompt learning,” “visual prompting,” “image generation/inpainting/editing with prompt,” and“vision-language models” into the Web of Science with the time range from 2020 to 2023.With the survey, our motivation is to cover as many important papers as possible.Therefore,we searched for related articles using Google Scholar,PubMed, IEEE Xplore, and so on.Specifically, in Section 2, we choose mainly CLIP as the foundation model to introduce the current vision-language alignment paradigm.In Section 3, we choose the most popular basic methods of language prompting and visual prompting that have already been highly cited on Google Scholar,and then,we select application works that are correlated with these basic methods.In Section 4,we focus more on image-generation tasks and hotly discussed diffusion models such as Stable-Diffusion.In Section 5, we focus on prompt tuning on ViTs and VLMs, which is effective in improving the tuning efficiency of Transformer backbones and is critical to LLMs and VLMs.Consequently, the articles we selected are closely related to the prompt learning topic and highly related to artificial intelligence generated content(AIGC).
Margie always looked forward to the arrival of Christmas, and this year was no different as winter began to settle like a warm blanket around Colby Point. Everyone was in a flurry, for at the church Margie and her family attended, the congregation was preparing to share their Christmas wishes with each other. Since Cleo couldn’t make it to church, and Bill didn’t like to leave her alone for too long, he was in the habit of dropping Margie off at church early on Sunday mornings; the aunts would bring her home.
2 Vision-language pre-training
Hence, prompt tuning is an effective tool for landing specific downstream tasks by adapting learned knowledge of large models.
But I did. I was so weak my legs trembled. I could never have crossed that squirming deck if Benny hadn t supported me. The kid was stronger than he looked. He helped me down the steps and steered12 me to the bench where Dad was sitting with his head drooping13 on his chest.
The dark gallery seemed darker than ever as he turned away, but he went back to the kitchen and inquired who slept in the room at the end of the passage. The scullery maid, they told him, whom everybody laughed at, and called ‘Donkey Skin;’ and though he perceived there was some strange mystery about this, he saw quite clearly there was nothing to be gained by asking any more questions. So he rode back to the palace, his head filled with the vision he had seen through the keyhole.
wherexand{wi}represent image features and text features generated by image and text encoders,respectively,Kis the number of classes, sim(·,·) denotes the cosine similarity, andτis the learnable temperature.
Bootstrapping language-image pre-training(BLIP) is a vision-language pre-training framework that transfers flexibly to both vision-language understanding and text generation.It effectively uses noisy web data by bootstrapping the captions,where a captioner can generate synthetic captions and a filter removes the noisy ones (Li JN et al.,2022).
For me, volunteering was a personal journey into unexpected enrichment and inspiration. I helped small children revel29 in another realm of physical and spiritual being, a space only their horses could create for them. I saw these children empowered and renewed by their equine companions. I rediscovered my deep love for horses and drew lessons from their gentle ways. And last but not least, I learned that giving yields greater generosity30 than it asks.

Fig.3 Framework of contrastive language-image pre-training (CLIP): (a) contrastive pre-training using imagetext pairs; (b) inference using the pre-trained image and text encoders (Reprinted from Radford et al.(2021),Copyright 2021, with permission from the authors)
Kim et al.(2021) proposed the vision-andlanguage Transformer (ViLT), which tackles twomodality information in a single unified manner.It differs from previous VLM models mainly in its convolution-free embedding of pixel-level inputs.Removing deep text and vision embedders generates the lightweight visual inputs, which scales down the model size and speeds up the running.Simultaneously,it maintains comparable performance to Pixel-Bert(Huang ZC et al., 2020)on downstream tasks.
Most of the existing VLMs share the same architecture of textual embedder-tokenizer from pretrained BERT(Devlin et al.,2019).Such generalized text encoders with large numbers of parameters are trained on huge amounts of data,so prompt learning often fixes their pre-trained parameters, which will be discussed in the next section.
3 Vision prompt learning
Prompt learning has emerged as an effective technique for enhancing large pre-trained NLP models.Given its potential, researchers have become interested in studying learnable prompts in VLMs,such as CLIP, to enhance their generalizability and thereby achieve superior zero-shot and few-shot learning performance.In this section, we categorize current vision prompt learning methods into two categories, i.e., language prompting and visual prompting.In Table 1, we briefly summarize some selected works involving image-text alignment, language prompting,and visual prompting.
3.1 Language prompting
Language prompting refers to constructing learnable language contexts as text encoder inputs,and these tokens are trained during cross-modal contrastive learning.As summarized in Liu PF et al.(2023), prompt-based learning models the probability of text directly in language models,which is similar to that in vision models: the language prompting in vision models also aims at modeling text prompts as probabilities,and these can be discrete forms like“a photo of a[CLS]” or continuous forms of learnable vectors/variables(Zhou KY et al.,2022a).However,language prompting in vision tasks often depends on a language model to conduct vision-language alignment.
3.1.1 Methods and algorithms
CoOp was first proposed to introduce learnable prompt contexts, i.e., parameter vectors, to VLMs(Zhou KY et al.,2022b).The prediction probability is defined as follows:
whereg(·) denotes text encoder that is differentiable,tirepresents the prompt for theithclass,i.e.,ti={v1,v2,...,vM,ci},vm’s (m=1, 2,...,M)areMlearnable context vectors, and each of them has the same dimension as word embedding ofci.CoOp fixes the CLIP pre-trained text encoder and updates the learnable contextsvmwithout adding much training cost.Note that CoOp is a supervised learning framework in which gradients of context vectors are back-propagated from the final classifier using cross-entropy loss.

Table 1 Summary and comparison of typical prompting methods
Although CoOp generalizes better than CLIP on downstream tasks, it suffers from performance degradation when encountering new classes;i.e.,the CoOp learned prompts lack the ability to transfer to new classes.To address this weakness,Zhou KY et al.(2022a)proposed a conditional context optimization(CoCoOp), which enables the context learning process to be conditioned on visual features by introducing an additional meta-net for establishing relationships between latent visual features and learnable contexts.The prediction probability is defined as follows:
where the context embeddingsti’s are conditioned on visual features, i.e.,ti={v1(x),v2(x),...,vM(x),ci}, andvm(x) =vm+π(m=1,2,...,M) whereπ=hθ(·) is the meta-net parameterized byθ.Different from CoOp, which updates only learnable prompt contexts, CoCoOp requires learning the additional parametersθof the proposed meta-net.Experimental results on the same 11 downstream tasks, such as Standford-Cars and FGVCAircraft, evaluated by CLIP and CoOp, have shown that CoCoOp exhibits improved performance on new classes over CoOp under the few-shot setting, confirming that instance-conditional prompts are capable of generalizing to new classes.
Despite the effectiveness of CoOp and CoCoOp in learning generalized prompt contexts, they are still constrained by class-specific prompts, and it is challenging for them to generate explainable context words.Different from CoOp and CoCoOp, decomposed feature prompting (DeFo) proposed by Wang F et al.(2023) abandons the prompt learning paradigm where the class tokens are contained in prompts.DeFo aims at decomposing visual features by applying learnable prompts.The key difference is that DeFo does not require the prompts contain specific class tokens, so each query image corresponds tonlearnable query prompts, wherenis a hyperparameter.However, DeFo needs an additional linear layer attached on top of the image encoder, which is used to map feature vectors to logits with the dimension ofC, the number of classes.Note that the number of textual queries is independent of the number of classes in DeFo.During the training process,the textual queries and the additional linear layer are trainable for conducting vision-language alignment.Interestingly, the learned text embeddings of DeFo are more interpretable than those learned by CoOp and CoCoOp, where reasonable words can be obtained by retrieving a dictionary through similarity matching between learned prompts and vectors in this dictionary (Zhou KY et al., 2022b; Wang F et al.,2023).
Current prompt learning methods can prompt for the target image,but are less generalizable in the realistic scenario where one image contains multiple intrinsic attributes and extrinsic contexts that are difficult to fully describe with a single prompt.To address this issue, Chen GY et al.(2023) proposed to enhance prompt learning with optimal transport(PLOT) by aligning each image with multiple classaware prompts.Specifically, PLOT holds the key distinction that the final prediction probability is obtained by measuring the optimal transport(OT)distance between visual features and multiple prompt vectors,which is defined as follows:
Because huge computational resources are required to adapt Transformer-based image and text encoders to other scenarios,the prompt-based visual fine-tuning method, named prompt tuning, is worth studying (Jia ML et al., 2022).It is well known that the Transformer-based vision encoders are significantly larger than their CNN counterparts, e.g.,ViT-Huge (Dosovitskiy et al., 2021); therefore, we need an effective and efficient approach to better adapt these large models to downstream tasks rather than fully fine-tuning all the parameters.Inspired by prompting in NLP and VLMs, directly using the learnable prompts as Transformer input helps pretrained ViTs achieve comparable performance with only 1%or fewer parameters to be tuned(Yao et al.,2021;Ge CJ et al.,2022;Ju et al.,2022).
whereuandvare probability simplexes,andFandGare matrices of visual features and prompts, respectively.From Fig.4, we can see that PLOT performs better on most of the downstream tasks than CoOp and CoCoOp.In addition, Selvaraju et al.(2017) showed that the learned multiple prompts indeed focus on varying regions in the images using Grad class activation mapping (CAM).Consequently, both quantitative and qualitative results demonstrate the effectiveness of aligning images with multiple prompts instead of a single prompt.
How fragrant11 and beautiful it was! Every flower that could be thought of for every season of the year was here in full bloom; no picture-book could have more beautiful colors

Fig.4 Comparisons of classification accuracy on 11 downstream tasks (Reprinted from Chen GY et al.(2023),Copyright 2023, with permission from the authors)
Prompt distribution learning, i.e., ProDA, was proposed to model prompt distribution for effectively adapting large VLMs to address downstream tasks (Lu YN et al., 2022).ProDA learns low-bias prompts from a few samples and captures the distribution of diverse prompts simultaneously.This handles the varying visual representations during training.Probabilistic prompt learning(PPL)stems from the probability distribution perspective to address dense prediction tasks such as segmentation (Kwon et al.,2023);it aligns visual features and class-aware multiple prompts in the latent space via distribution alignment.
For continual learning, Wang ZF et al.(2022)proposed a novel approach, learning to prompt(L2P), to generate prompts that are effective in continual learning and can be used to adapt to new tasks without forgetting the previous ones.Hierarchical prompt(HiPro)learning was proposed for multi-task learning, which learns a set of hierarchical prompts that can be used to solve multiple tasks simultaneously.FedPR is a federated learning method for magnetic resonance imaging (MRI) reconstruction.It learns a set of visual prompts in the null space of the data distribution to improve the reconstruction performance.These three methods are all evaluated on various benchmarks and have shown promising results(Feng et al.,2023).
3.1.2 Applications of language prompting
Based on the prompt learning discussed above,the potential of this technique has been well explored.A successful application is modeling consistent ordinal information via vision-language alignment.Li WH et al.(2022) proposed OrdinalCLIP,which breaks the barrier of traditional ordinal regression methods that learn with categorical labels.OrdinalCLIP enforces visual features to approximate language prototypes of ranks via measuring Kullback-Leibler (KL) divergence between similarity matrices obtained by visual and language features.Although OrdinalCLIP does not achieve improved regression performance compared with stateof-the-art ordinal regression methods such as convolutional ordinal regression forest (CORF) for age estimation (Zhu HP et al., 2022) and meta ordinal regression forest(MORF)for medical lesion progression (Lei et al., 2022), ordinal regression is a typical topic in machine learning, but it is still inferior in modeling non-equivalent ordinal relationships among visual features,which we argue is more realistic in real-world applications.Prompt learning has the potential to establish more real relationships among ranks via informative textual descriptions.
Recently, the segment anything model (SAM)has caught great attention in the CV community.Kirillov et al.(2023) built a huge dataset with 1.1 billion segmentation masks and trained the masked auto-encoder(MAE)based image encoder(He et al.,2022) and off-the-shelf CLIP-pre-trained text encoder in a supervised manner using dice loss (Milletari et al.,2016)and focal loss(Lin TY et al.,2017).SAM shows surprising capability in segmenting any unseen images.It allows users to provide multimodal prompts like masks, points, boxes, and texts.This amazing model demonstrates the potential of prompts used in vision models and user-friendly application scenarios of multi-modal prompting.
She was very soon arrayed in costly robes of silk and muslin, and was the most beautiful creature in the palace; but she was dumb, and could neither speak nor sing
CLIP-Lung was proposed using textual knowledge in medical datasets to facilitate medical image classification(Lei et al.,2023a).Specifically,it aligns textual attributes and class texts of lung nodules to the corresponding image features,and then generates fine-grained attention maps correlated with small lesions.Yu Y et al.(2022) applied prompt learning for COVID-19 diagnosis through modeling the conditional probability of vocabulary conditioned on learnable prompts.Language prompting also enhances interpretability of deep neural networks through global and local alignments between language and image features(Lei et al.,2023b).
In summary, language prompting provides visual features and image encoders with extra learning targets.We argue that the trainable language contexts act as noisy class information,informally,a Gaussian distribution centered at the specific classes,which helps improve the generalizability and robustness of visual features.
3.2 Visual prompting
Visual prompting refers to constructing learnable image tokens,i.e.,visual perturbations as shown in Fig.5, as input of an image encoder, and these learnable tokens are trained to adapt large-scale vision models.As we can see,this kind of learnable visual prompt plays a role similar to language prompts in LLMs, where the prompted model will perform a new task with perturbations.
3.2.1 Methods and algorithms
Visual prompting is used in the field of CV and adapts pre-trained visual models to new downstream tasks without requiring task-specific fine-tuning or modifications to the model architecture(Lin Y et al.,2023).It was first defined in Bahng et al.(2022)to mimic the prompting idea in NLP.Fig.5 illustrates the framework of visual prompting.It has been explored under different names, such as model reprogramming or adversarial reprogramming in the CV domain.These techniques aim to repurpose pretrained vision models for new tasks by leveraging universal input patterns and output label mappings.Visual prompting offers the advantage of parameterefficient fine-tuning,requiring less parameter storage and training data compared to full fine-tuning.It has been applied to various scenarios, including blackbox source models, cross-domain transfer learning,and improving metrics like adversarial robustness and fairness.
One approach to visual prompting treats the problem as image inpainting.The goal is to fill in the missing parts of a concatenated visual prompt image,which is created by combining input-output image examples.Bar et al.(2022)demonstrated that leveraging an appropriate inpainting algorithm trained on a curated dataset can lead to surprisingly effective results.They trained a masked auto-encoder on an unlabeled dataset comprising figures from academic papers and applied visual prompting to pretrained models for various image-to-image tasks such as foreground segmentation, single object detection,colorization,and edge detection.
To investigate the efficacy of visual prompting in adapting large-scale models in CV, built upon recent approaches like prompt tuning and adversarial reprogramming, Bahng et al.(2022) proposed to learn a single image perturbation that enables a frozen model to perform a new task.The authors demonstrated that visual prompting,particularly for models like CLIP, is effective and robust to distribution shift, achieving competitive performance over standard linear probes.They also analyzed various aspects such as the downstream dataset,prompt design, and output transformation in relation to adaptation performance.

Fig.5 Hierarchical relationships among different prompting methods: language prompting, visual prompting with image perturbations, and multi-modal prompting
Many approaches have attempted to prompt with images, similar to prefix tuning in NLP.For instance, colorful prompt tuning (CPT) focuses on extending the capabilities of language-based models by training vision encoders and using continuous image embeddings as visual prefixes or colored blocks and color-based textual prompts for visual grounding (Yao et al., 2021).However, these approaches primarily aim to enhance language models rather than specifically investigating the efficacy of visual prompting in enhancing vision models.
To address the adaptation of pre-trained VLMs like CLIP to downstream tasks via prompt tuning,Xing et al.(2022) proposed a novel dual-modality prompt tuning (DPT) paradigm that simultaneously learns text and visual prompts.They introduced a class-aware visual prompt tuning (CAVPT)scheme, which dynamically generates class-aware visual prompts by performing cross-attention between text prompt features and image patch token embeddings.This encoding captures both task-related and visual instance information, ultimately improving the concentration of the final image feature on the target visual concept.Experimental results on 11 datasets demonstrated the effectiveness and generalization ability of the proposed method.
Chen AC et al.(2023) delved into the technique of visual prompting and explored its effectiveness given ruleless label mapping between source and target classes.The authors proposed the iterative label mapping based visual prompting (ILMVP)framework,which automatically re-maps source labels to target labels to improve the accuracy of visual prompting on target tasks.Additionally, they integrated label mapping into the text prompt selection of CLIP to enhance its target task accuracy.
Visual prompting and model reprogramming have gained attention in CV research.Visual prompt tuning(VPT),a related technique restricted to ViTs,enables to learn prompting parameters at intermediate layers of a source model and to extract modalityrelated prompts, which has enhanced multi-modal tracking tasks.Visual prompt multi-modal tracking (ViPT) was proposed to learn a few modalrelevant prompts for adapting large ViTs to downstream tracking tasks(Zhu JW et al.,2023).
3.2.2 Applications of visual prompting
Painter is based on the idea of task prompts (Wang XL et al., 2023).Taking semantic segmentation as an example, task prompts indicate the concatenations of input images and the corresponding segmentation target.Then the target inputs are also concatenations of images and blank images to be predicted.Furthermore, Painter can tackle various tasks such as object detection,deraining, and depth estimation.Liu WH et al.(2023)proposed explicit visual prompting to simultaneously address low-level structure segmentations,including camouflaged object, forgery, shadow, and defocus blur detection.To enhance the performance of traditional CNN models on target tasks like Flowers102,Chen AC et al.(2023)proposed to couple the design of label mapping with visual prompt training,which significantly improved the classification accuracy of CNNs such as ResNet.To build a consistent relationship between language and visual information in image classification, Mao et al.(2023) proposed a new object recognition benchmark that requires the model to simultaneously predict the right categorical labels and the rationales;this rationale knowledge is transferred from LLMs such as GPT-3.For transfer learning, Oh et al.(2023)proposed black-box visual prompting (BlackVIP) to adapt pre-trained visual models to downstream tasks,which beats traditional fine-tuning and visual fine-tuning strategies.
Hence, visual prompting is complementary to language prompting for enhancing image encoders,and is also regarded as perturbation or augmentation of input images with respect to class texts.Furthermore,the combination of these two modalities of prompts enables the interaction between vision and language information while improving performance in unseen classes or tasks.
3.3 Multi-modal prompting
Based on the success of language and visual prompt learning, the combinations of these two modalities of prompts have caught much attention in recent years.MaPLe is a novel prompt learning framework that uses both vision and language modules of CLIP to improve alignment between these two representations.It demonstrates state-of-theart results toward unseen new categories and domain transfer.The design promotes strong coupling between the cross-modal prompts to ensure mutual synergy and discourages learning independent unimodal solutions (Khattak et al., 2023).Instruction-ViT conducts multi-modal prompts for instruction learning.It uses prompt tuning to adapt pre-trained models to different downstream tasks, reducing the number of trainable parameters while improving the performance on unknown tasks (Xiao et al., 2023).Unified-IO is a framework that integrates various vision tasks, including image classification, object detection, depth estimation, and image inpainting (Lu JS et al.,2023).We can see that appropriate cooperation among various prompt modalities can facilitate a wide range of applications.
Consequently,prompts have been proven to play a crucial role in LLMs, and in recent years, vision models have also been using prompts to improve scalability for multiple downstream tasks.
4 Prompt-guided generative models
Hence, a notable advantage of prompt-guided inpainting using diffusion models is its ability to accurately recover missing regions by leveraging prior prompts, which is a challenge to overcome with conventional inpainting methods.
Conventional text-condition GAN related methods have been widely studied (Reed et al., 2016a,2016b; Zhang H et al., 2017; Xu T et al., 2018; Tao et al., 2022), without interacting with humans or language information.The advanced prompt-based generation models have emerged as a prominent approach for enhancing human-in-the-loop conditional generation in vision-language models.Notable applications such as Stable-Diffusion (Rombach et al., 2022), DALL-E (Ramesh et al., 2021, 2022),and MidJourney (https://en.wikipedia.org/wiki/Midjourney) have been developed and achieved widespread recognition globally.
“You have already rewarded me,” said the nightingale. “I shall never forget that I drew tears from your eyes the first time I sang to you. These are the jewels that rejoice a singer’s heart. But now sleep, and grow strong and well again. I will sing to you again.”
Different from previous techniques, these models allow users to employ high-level semantic information, including natural language, stick figures, and binary masks, as prompts to generate desired outcomes flexibly.Owing to their versatility and userfriendliness, prompt-guided generative models have emerged as a hotly discussed research direction, encompassing various fields such as prompt-guided image generation and editing, image inpainting, and three-dimensional object generation.
The success of prompt-guided generative models can be attributed to three aspects:
As discussed above,VLMs have empowered various research fields, and we believe that they will further enable more diverse and new vision task formulations and model designs.Therefore, in this paper, we comprehensively review the recent advances in prompt learning for vision tasks after the explosion of VLMs and provide promising research directions.The overall structure of this article is shown in Fig.2.In Section 2, we introduce some largescale VLMs pre-trained with large numbers of imagetext pairs and corresponding image-text contrastive learning schemes.In Section 3, we review the visual prompt learning methods, such as context optimization (CoOp), which enhanced classification performance against CLIP.In Section 4, we review recent popular prompt-guided generative models and relevant tasks such as image editing and inpainting.In Section 5, we show the efficient prompt/fine-tuning strategies for adapting large ViTs to downstream tasks.In Section 6,we discuss some possible research directions integrated with prompt learning.
When cancer starts, for an unknown reason, a wall of calcium9 builds. Then the lump or cancer attaches itself to this wall. When Cocoa jumped on me, the force of the impact broke the lump away from the calcium wall. This made it possible for me to notice the lump. Before that, I couldn’t see it or feel it, so there was no way for me to know it was there.
2.The advanced diffusion-based generative models.In contrast to conventional GAN models that often specialize in specific topics such as human faces (Abdal et al., 2019; Karras et al., 2019, 2020,2021),diffusion models offer enhanced flexibility and strong unconditional generation ability.Such features enable the generation of diverse scenes and facilitate large-scale training, avoiding the limitations of topic-specific approaches.
3.The cross-attention mechanism which has demonstrated its power in harnessing contextual information from different modalities (Lin HZ et al.,2022).Being advantageous because it is easily implemented, cross-attention enables the integration of prompts from diverse modalities, thus significantly enhancing the performance and capabilities of prompt-guided image generation models.
Next, we summarize and discuss image generation, image editing, and image inpainting tasks.Some popular methods are summarized in Table 2.
4.1 Image generation
A highly successful approach for prompt-guided image generation is the latent diffusion model(Rombach et al., 2022), also known as Stable-Diffusion,which performs diffusion in the latent space of pretrained auto-encoders and generates images iteratively to reduce inference time.During training,the prompts of various modalities are first encoded by a domain-specific network and then interact with the intermediate layers of the diffusion model by crossattention mechanisms(Vaswani et al., 2017;Lin HZ et al., 2022).
Fig.6 shows the architectures of two popular latent diffusion models, Stable-Diffusion (Rombach et al.,2022)and Imagen(Wang S et al.,2023),which share similar designs.Both models perform diffusion in the latent space,resulting in a considerable reduction of computational costs.Stable-Diffusion supports several kinds of prompts, including semantic maps, text, representations, and images.For each modality,a domain-specific encoder is used to translate the prompt for the generation model; such an encoder could be either a pre-trained model or the one that is to be trained simultaneously with the diffusion model.GLIDE is a text-guided diffusion model that enables text-conditional image synthesis for photorealistic image generation(Nichol et al.,2022).The authors explored two kinds of guidance,CLIP guidance and classifier-free guidance.
Although diffusion models have emerged as new state-of-the-art large-scale generative models,recent works have made attempts to train GAN with a similar strategy by scaling up the model and leveraging text prompts.Kang et al.(2023) introduced Giga-GAN, a novel GAN architecture that avoids previous limits and showcases GANs as a feasible choice for text-to-image synthesis.GigaGAN achieves competitive performance against diffusion models while significantly reducing inference time, making it an efficient option for prompt-to-image synthesis.
These fundamental generation models have been employed to accomplish a diverse array of astounding downstream tasks,including image editing,image inpainting,and others.
He found them both sitting hand in hand on the step in front of the altar, and immediately knew his daughter again, and took her in his arms, thanking God and her deliverer
4.2 Image editing
Image editing refers to the process of altering an image to make it more visually appealing or to convey a specific message.Generally, image editing involves removing unwanted regions like specks and scratches, rotating and cropping images, correcting for lens aberrations, sharpening or softening the image,making color changes,and adding special effects to the image.
Traditional image editing methods are almost all based on GANs (Perarnau et al.,2016;Wang TC et al., 2018;Ling et al.,2021).For text-guided diffusion models,DreamBooth allows users to personalize text-to-image models by fine-tuning them with just a few images of a subject (Ruiz et al., 2023).Given just a few images of target subjects as input,Dream-Booth fine-tunes a pre-trained text-to-image model to bind a unique identifier,i.e.,a unique prompt with a specific subject.ControlNet presents a framework
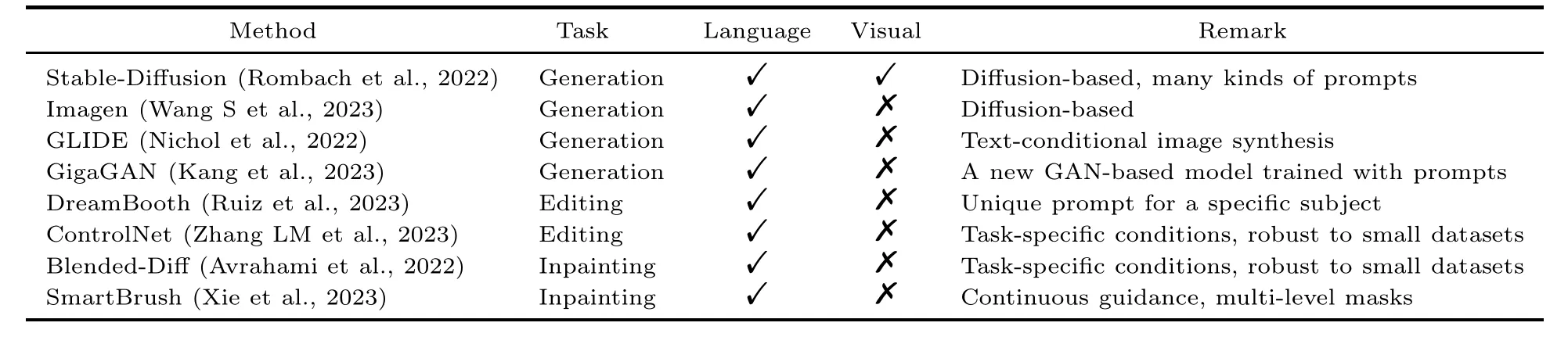
Table 2 Summary and comparison of typical generative models

Fig.6 Prompt-guided image generation framework: (a) Stable-Diffusion (Reprinted from Rombach et al.(2022), Copyright 2022, with permission from IEEE); (b) Imagen (Reprinted from Wang S et al.(2023),Copyright 2023, with permission from IEEE).These two models use a similar design, incorporating the crossattention mechanism to fuse the prompt into the generation model (i.e., the latent diffusion model in both cases)
to control pre-trained large diffusion models to support additional input conditions.ControlNet learns task-specific conditions,and the learning is robust to small datasets.Adding conditional control to textto-image diffusion models allows users to guide image generation more precisely,resulting in more accurate and tailored outputs (Zhang LM et al., 2023).The Imagic method is also a text-conditioned diffusion model; it differs from previous methods in requiring only one image of one object for training (Kawar et al., 2023).
In summary, diffusion models with prompt conditions satisfy the nature of language-intervened image editing where the models can generate mimic results relative to target prompt inputs.
4.3 Image inpainting
Image inpainting is a technology that aims to fill in the missing regions of an image based on the available surrounding pixels while conforming to human visual perception and cognition.With the advancements in deep learning techniques, image inpainting has emerged as a prominent research field.In contrast to traditional approaches that rely on similarity-based filling using neighboring pixels or patches (Barnes et al., 2009; Xu ZB and Sun, 2010;He and Sun, 2014; Lee et al., 2016), deep learning based methods have the ability to perform dynamic restoration at the pixel level.These methods often employ a two-stage framework, wherein the image is restored in a coarse-to-fine manner, addressing the limitation of a restricted receptive field (Iizuka et al., 2017; Yu JH et al., 2018, 2019).To address the coherent limitation of the receptive field, selfattention models and Fourier-based convolutional networks have been introduced(Zhou YQ et al.,2021;Suvorov et al., 2022).By incorporating larger or global receptive fields, these network architectures effectively capture the undisturbed structural information presented in images.Although the current methods have achieved excellent results,these architectures lack control of the results,particularly when dealing with large holes where existing areas may not provide sufficient contextual information.Recent advancements in multi-modal inpainting methods have shown significant improvements by allowing models to inpaint using prompts such as class labels, text descriptions,and masks.
One approach for prompt-guided inpainting is TDANet, which trains networks end to end and involves aligning image-text pairs (Zhang ZJ et al.,2020).However,this kind of method often yields suboptimal results in aligning high-level contexts with low-level details.Building on the recent success of diffusion-based conditional and text-to-image generation models, researchers have proposed to directly extend the unconditional DDPM model to image inpainting tasks by performing resampling at each reverse step, thereby transforming the task into unconditional generation (Lugmayr et al., 2022).Inspired by its remarkable generalizability,blended diffusion(Blended-Diff)(Avrahami et al.,2022)adapts the pre-trained unconditional diffusion model and employs the CLIP score to encourage the output to align with the provided text prompts, as illustrated in Fig.7b.As shown in Fig.8, Imagen successfully edites the puppy using both mask and language prompts.Blended-Diffeffectively integrates language priors from CLIP to generate the inpainted object.Smartbooth further emphasizes the importance of the mask prompt to constrain the shape of the inpainted object.
On the other hand, further fine-tuning the model can potentially lead to high-quality results,albeit at the expense of increased computational cost.Approaches such as GLIDE (Nichol et al.,2022), Stable-Diffusion (Rombach et al., 2022), and SmartBrush(Xie et al.,2023)employ supervised finetuning of text-to-image conditional diffusion models for image inpainting tasks, specifically focusing on inpainting the correct contextual information within the masked regions.SmartBrush (Xie et al., 2023)introduces a novel approach that enables continuous guidance of the inpainting process using text and object shapes,allowing for different levels of mask precision,as shown in Fig.7a.This allows users to inpaint images with provided masks, such as the specific shape of a cat.The distinctive aspect of SmartBrush lies in its training process, which involves using instance segmentation masks and local text descriptions from a pre-trained BLIP (Li JN et al., 2022).As a result, SmartBrush not only facilitates precise image inpainting but also leverages the mask precision information from a trained U-Net.This allows SmartBrush to effectively preserve the background even without a precise mask during the inference stage.The qualitative and quantitative evaluations demonstrate that SmartBrush achieves superior results in terms of visual quality, mask controllability,and background preservation,as presented in Fig.8c.
Deep generative models are extensively trained to approximate complicated,high-dimensional probability distributions.The trained models can then be used to estimate the likelihood of observations and to create new samples from the underlying distribution.Popular models include GAN (Goodfellow et al.,2020)and variational auto-encoder(VAE)(Kingma and Welling, 2013).Recently, diffusionbased generative models (Ho et al., 2020) have attracted much attention and outperform traditional GAN-based methods in both quantitative and qualitative image generation results.Furthermore, because large VLMs can effectively incorporate linguistic prompts into vision models,prompt-guided image generation theories and applications have been developed and garnered considerable attention from both the academic and industrial communities.
5 Prompt tuning
Although prompt learning has achieved amazing progress recently,there exists an inevitable problem,i.e.,the difficulty for general users to train such large models from scratch due to the requirement of huge computation resources.Therefore,researchers began to explore new parameter-efficient tuning methods for better using its representation ability.In this section, we will introduce prompt tuning methods that have great potential for general users to benefit from pre-trained knowledge.Table 3 illustrates the summarization and comparison of typical prompt tuning methods.

Fig.7 Two popular prompt-guided inpainting frameworks: (a) SmartBrush (Reprinted from Xie et al.(2023),Copyright 2023, with permission from IEEE), which uses language and mask as prompts; (b) Blended-Diff(Reprinted from Avrahami et al.(2022), Copyright 2022, with permission from IEEE), which uses language as a prompt on a pre-trained DDPM model

Table 3 Summary and comparison of typical prompt tuning methods
5.1 Prompt tuning on ViTs
Scaling laws (Kaplan et al., 2020) drive models to larger scales.While larger ViT models typically perform better, their generalization ability remains limited.This means that even big models need to be fine-tuned on downstream tasks to achieve satisfactory performance.However, fully fine-tuning the entire pre-trained visual model on different tasks and data distributions can be computationally expensive.Therefore, it is imperative to study parameterefficient tuning methods for pre-trained models,such as ViT, to reduce computational costs and improve efficiency.
VPT was proposed to efficiently fine-tune ViTs by posing trainable prompt vectors at the input layer of ViTs(Jia ML et al.,2022).The authors proposed two versions: VPT-Deep, which includes trainable prompts in the intermediate layers of ViTs,and VPTShallow,which does not.Note that the total number of fine-tuned VPT parameters is smaller than 1%of the number of backbone parameters.For the classification performances on downstream tasks, VPT surpasses adaptor-based strategies (Houlsby et al.,2019;Pfeiffer et al., 2020a,2020b).
VPT for generative transfer learning was proposed to learn a set of visual prompts that can be used to improve the transferability of generative models.The method is evaluated on various benchmarks and has shown promising results (Sohn et al.,2023).
Learning with long-tailed data is a challenging problem in machine learning/deep learning, where the imbalanced data distribution of different classes dramatically guides the model to overfit major classes while being less generative to tailed classes.Existing works fine-tune the models pre-trained on large-scale unlabeled datasets, suffering from high costs in computation and overfitting to long-tailed data.To address this issue, Dong et al.(2023)proposed long-tailed prompt tuning (LPT) to adapt large VLMs to long-tailed image classification tasks.LPT is a two-stage framework in which shared prompts at the shared prompt tuning stage, patch tokens, and class tokens are fine-tuned, while the group prompt tuning stage is used for learning groupspecific prompts by matching class-token-grouped prompts.LPT surpasses VPT in long-tailed tasks using different backbone networks including ResNet-152 (He et al., 2016) and ViT-B (Dosovitskiy et al.,2021).
5.2 Prompt tuning on VLMs
VLMs leverage semantically rich verbal information to learn visual information under language supervision.Models trained in this manner exhibit strong transferability and achieve performance improvements, particularly in zero-shot and few-shot scenarios.Prompt tuning can also be employed to efficiently fine-tune VLMs.
In The Magic Circle, by Donna Jo Napoli, the Hansel and Gretel tale is told from the witch s perspective. The witch is under a spell that makes her eat children. She crawls into the oven knowing that Gretel will push her in and burn her, thus freeing her from the life she despises.
TCM(Yu WW et al.,2023)is a novel approach to scene text detection that leverages prompt learning to enable flexible model adaptation.The method uses two elaborate prompt generators that plug into a pre-trained VLM, allowing the image and text embeddings to interact and fill in missing information in single modality embeddings.To further improve the quality of the embeddings, an additional matching loss is proposed to constrain the similarity between the curated embeddings.The experiments demonstrate that TCM has great transferability,making it a promising approach for scene text detection.
V-VL (Ju et al., 2022)is a prompt-based learning method that guides a pre-trained image-based VLM toward video understanding tasks, such as action recognition, action localization, and textvideo retrieval.To achieve this goal, learnable prompts are appended to the text-tokenized results and then fed to the text encoder.Furthermore, VVL employs a Transformer encoder based temporal modeling method to aggregate the image features.This approach enables the frozen pre-trained image-based VLM to adapt well to various video understanding tasks.The experiments conducted on zero-shot and few-shot scenarios demonstrate strong generalization.
VoP focuses on adapting pre-trained CLIP to video-text retrieval tasks in a parameter-efficient manner.Huang ST et al.(2023) proposed visualtext dual prompts and inserted them in each layer of frozen encoders.To address spatial-temporal modeling without introducing additional modules, they proposed three different visual prompts conditioned on position, context, and function, separately.This approach enables the pre-trained model on images to be transferred to the video domain.With only 0.1%trainable prompts,VoP achieves a 1.4%average relative improvement compared to full fine-tuning.Overall, VoP provides an efficient and effective way to adapt pre-trained models to video-understanding tasks.
The maiden50 did as he told her, and then the wolf breathed over the flowery grave, and, lo and behold51! the Prince lay there sleeping as peacefully as a child
As we can see, prompt tuning has shown great potential for transferring pre-trained models to a wide range of downstream tasks.Adapters(Houlsby et al., 2019) can be used as an alternative method to achieve parameter-efficient tuning.DenseVit-Adapter (Chen Z et al., 2023) focuses on injecting both task-and input-specific knowledge into the pretrained model through a lightweight adapter.CLIPAdapter (Gao et al., 2021) is a modality-agnostic adapter that allows VLMs to balance pre-training learned knowledge with newly learned knowledge from few-shot samples.VL-Adapter (Sung et al.,2022) unifies various image- and video-text downstream tasks in a single vision and language framework,enabling efficient fine-tuning of the pre-trained VLM with adapters in a multi-task setting.In addition to these methods,LoRA(Hu et al.,2022)can be trained on downstream tasks in a parameter-efficient manner and has shown great potential in the field of CV(Smith et al.,2023).
Current widely adopted AIGC techniques shine in innovatively and accurately injecting human language into generative models,making generated contents reflect meaningful semantic information.A critical process in such AIGC models is visionlanguage alignment that yields powerful and generative image and text encoders for various kinds of downstream tasks including discriminative and generative modeling.Therefore, before introducing visual prompt learning, we briefly review the fundamental VLMs and the corresponding contrastive learning scheme.As shown in Fig.3,CLIP is the first large-scale pre-trained model for image-text alignment (Radford et al., 2021), and was pre-trained on four billion image-text pairs.ALIGN (Jia C et al.,2021) uses the same contrastive learning paradigm as used in CLIP to align images and text by training the Transformer encoders on a dataset even larger than that used in CLIP.The prediction probability of zero-shot CLIP is defined as follows:
6 Future directions
Although visual prompt learning has been widely studied and applied in many applications, it remains in its early stages of development.This section reviews and highlights some promising directions in prompt learning.
6.1 Image classification
Based on the paradigm of classification via image-text matching brought from cross-modal contrastive learning, such as CLIP, there has been a notable enhancement in the performance of image classification benchmarks, especially in zero- and few-shot settings.In addition, prompt learning has shown critical effects in adapting pre-trained models to downstream tasks and specific scenarios,like generalization to new classes (Zhou KY et al., 2022a).However, to further unlock the potential of prompt learning for image classification, two primary challenges persist: (1) Adapting or training large-scale models to specific scenarios suffers from domain shifts between target texts and pre-training textual data; (2) More explainable learned prompts are required to facilitate the interpretation of classification models, which is the key to explainable AI in the future.Hence,prompt learning will be effective in real applications and in interpreting AI models.
6.2 Semantic segmentation
The current popular segmentation model may be SAM (Kirillov et al., 2023), which is a large model trained on huge numbers of image-prompt pairs.In addition to its amazing performance, it allows multiple kinds of prompts for the users to choose,including points, boxes,and texts.Recently,more and more studies have shown that SAM fails in some real scenarios, like medical image segmentation.This poses a valuable research topic on integrating domain-specific knowledge into SAM-like large segmentation models.We think that efficient prompt learning, which can connect language and target regions in the images, will enable a humanin-the-loop segmentation paradigm to sense human knowledge.
6.3 Open-vocabulary object detection
Open-vocabulary object detection (OVOD) differs from traditional object detection in that the detectors of OVOD are trained on base classes existing in the training set, and should be able to recognize new classes.Vision and language knowledge distillation(ViLD)directly employs the CLIP text encoder to obtain text embedding,which is subsequently used to classify object proposals and act as supervision of training detectors(Gu et al.,2022).Because ViLD is a two-stage detection method, Ma et al.(2022) proposed HierKD, a one-stage OVOD detection framework,which distills the knowledge of CLIP at global and instance levels.For novel classes, HierKL outperms previous you only look once (YOLO) based zero-shot detectors.To avoid the obstacle of handcrafted prompts used in ViLD,Du et al.(2022)incorporated learnable prompts into OVOD,and the proposed DetPro significantly improved performances upon ViLD under various experimental settings.Although OVOD has been explored toward applying knowledge of LLMs, we still need an elegant way of reducing distribution shift between the base and new classes, even for more specific scenarios such as medicine, remote sensing, and auto-driving, where the text annotations are difficult to acquire.
6.4 Multi-task learning
Multi-task learning is a classical problem that aims at performing multiple tasks using a single model or a single ensemble model, i.e., multiple outputs corresponding to various tasks such as classification, regression, and reconstruction.Based on multi-modal prompting,multi-task learning intrinsically correlates well with constructing multi-modal prompts; then we need to develop effective learning targets and efficient training strategies to enhance the performance of multiple tasks.Another kind of multi-task learning refers to multiple distributions of training data; for example, Liu YJ et al.(2023)proposed HiPro learning, which targets at solving a new benchmark that involves different kinds of classification datasets including fine-grained recognition like Flowers102, scene recognition, action recognition,and general recognition.This work triggers the building of fine-grained relationships between tasks and corresponding prompts in a real application;e.g.,multiple diseases in a clinic should possess their own specific prompts.
6.5 Chain-of-thought
Chain-of-thought (CoT) is a concept in LLMs,where researchers found that eliciting complex multistep reasoning through step-by-step answer examples can significantly improve the ability of LLMs to perform complex reasoning, as shown in Fig.9(Kojima et al., 2022; Wei et al., 2022; Zhang ZS et al., 2022).CoT prompting allows LLMs to “infer the answer like a human” instead of generating answers directly.There are two primary paradigms in CoT prompting: one employs a straightforward prompt to facilitate step-by-step reasoning in a zeroshot manner, and the other presents several manual demonstrations sequentially in a few-shot approach.Ge JX et al.(2023) applied CoT in prompt tuning,which differed from those prompt learning methods like CoOp and CoCoOp, because they made a chain of prompts before the text encoder, with all the prompts in the CoT chain being conditioned on visual features, and this generalized better in new classes than CoCoOp.Because language information is the key to CoT, multi-modal prompting will be a more promising way of using the CoT concept.For example, researchers have explored CoT for multimodal reasoning in science question answering (Lu P et al.,2022).
In conclusion,CoT is a powerful and innovative concept that enhances the performance and capabilities of large-scale models, leading to improved context awareness and semantic consistency by enabling better understanding and connection of diverse ideas and concepts.On the other hand, with the rapid development of VLMs and LLMs, CoT is an effective tool for enhancing vision models by injecting CoT into a wide range of applications of languageor rationale-specific scenarios like medicine and auto-driving.
6.6 Prompt for medical image analysis
Medical data are intrinsically involved with images of different modalities and corresponding text or language annotations.Low-level medical image processing such as denoising and deblurring acts as a critical part of high-level tasks such as classification and segmentation.It is worthwhile to explore how class-related textual information can affect joint learning of high- and low-level tasks, and whether the prompt embeddings are beneficial for the performances of both tasks especially for disease diagnosis(Lei et al., 2021;Xu ZH et al.,2022).
On the other hand,multi-modal prompting can effectively leverage language and visual information,which will help the model learn consistent feature spaces.Therefore, this is helpful for explainable AI for medical diagnoses.
6.7 Prompt for weather forecasting
In weather forecasting tasks, the accumulated massive NLP-formatted data in the past could not be effectively used.It is a valuable research direction to combine prompt learning to enable forecasting models to better understand weather conditions by leveraging textual knowledge.

Fig.9 The framework of multi-modal chain-of-thought (CoT) (Zhang ZS et al., 2023), an example of lung nodule malignancy recognition using computed tomography (CT) images.The framework of CoT can be divided into two stages: rationale generation and answer inference
Furthermore, the results of time-series prediction tasks are often limited, typically consisting of only future numerical values.By incorporating prompt learning in conjunction with NLP,it becomes possible to introduce a wider variety of supervisory information.Xue and Salim (2022) proposed prompt-based time-series forecasting (PromptCast)and achieved superior prediction performance compared to various neural network models in tasks such as temperature prediction.In the context of precipitation nowcasting, Cao et al.(2023) demonstrated that adjusting the learning order and weights of multiple forecasting tasks can significantly improve the prediction performance of nowcasting models, highlighting the importance of task formulation.The integration of prompt learning with meteorological forecasting is a highly promising research direction.
6.8 Prompt for gait recognition
Gait recognition involves using the biological gait pattern to identify an individual’s identity.One of the main challenges in this field is extracting robust and discriminative gait features (Lin BB et al.,2021; Chao et al., 2022).A very recent work,MaskCL (Li MK et al., 2023), introduces gait silhouettes as semantic prompts for the person reidentification task.This allows the model to learn some cross-clothes invariant features.In the gait recognition task,researchers have studied cross-view robust gait features (Lin BB et al., 2021; Li JQ et al.,2023a,2023b)for better recognition performance,which is a significant challenge in this field.Designing gait prompts to learn cross-view robust features is a promising direction for future research in this area.
7 Conclusions
In this survey, we have comprehensively reviewed studies with respect to prompt learning in the CV field.We first introduced the prompt learning strategies in image-text cross-modal frameworks,which have overcome shortcomings like weak generalizability of traditional prompt engineering.Then,for efficiently applying large VLMs for downstream prompt-guided learning, we discussed prompt tuning methods tailored for better adaptation of largescale ViTs.Through richer information contained in prompts, prompt-guided generative models trigger a wide variety of applications such as image generation, image editing, and image inpainting.Finally,we provided some perspectives on prompt learning in the CV field and possible and promising research directions.
In summary, prompt learning has great potential in enhancing existing studies and leading to new multi-modal directions.
Contributors
Yiming LEI and Hongming SHAN designed the structure and logic of the paper.Yiming LEI drafted the whole paper.Yuan CAO reviewed the visual prompt learning part.Zilong LI reviewed the prompt-guided generative models part.Jingqi LI reviewed the prompt tuning part.Yiming LEI and Hongming SHAN revised and finalized the paper.All the authors proofread the paper.
Compliance with ethics guidelines
All the authors declare that they have no conflict of interest.
 Frontiers of Information Technology & Electronic Engineering2024年1期
Frontiers of Information Technology & Electronic Engineering2024年1期
- Frontiers of Information Technology & Electronic Engineering的其它文章
- Recent advances in artificial intelligence generated content
- Six-Writings multimodal processing with pictophoneticcoding to enhance Chinese language models*
- Diffusion models for time-series applications:a survey
- Parallel intelligent education with ChatGPT
- Multistage guidance on the diffusion model inspired by human artists’creative thinking
- Advances and challenges in artificial intelligence text generation*