
命名数据网络中基于分级的数据缓存方法
2024-03-05 12:13:16侯睿沙莫金继欢
中南民族大学学报(自然科学版) 2024年2期
侯睿,沙莫,金继欢
(中南民族大学 计算机科学学院,武汉 430074)
命名数据网络(Named Data Networking, NDN)已经成为未来互联网体系结构有效的解决方案之一[1].在NDN 中,数据内容请求者(Consumer)将所需数据内容名称封装在Interest 包中,发送至NDN 核心网络去寻找目标信息[2];内容发布者(Publisher)将Consumer 所需数据内容封装成Data 包对Consumer 做出响应,Data 包沿Interest 包传输路径反方向返回至Consumer,完成数据交互.
NDN 中有三种数据结构,即内容存储(Content Store, CS)、待定兴趣表(Pending Interest Table,PIT)和转发信息表(Forwarding Information Base,FIB)[3].CS 负责缓存所接收到的Data 包中的数据内容;PIT 用于记录还未获得响应的Interest 包封装的数据内容名称和接口信息;FIB用于转发Interest包.
由于NDN 固有的泛在缓存(Cache Everything Everywhere, CEE)机制存在路由器中数据内容多样性低以及频繁的数据替换等问题.因此设计一种优化的分布式缓存方法,对降低网络内缓存冗余度,提高Consumer获取数据的时间效率有着重要意义.
1 相关研究
针对NDN 中数据内容的缓存问题,PSARAS 等人提出一种基于概率的缓存方法(ProbCache)[4],该方法通过计算传输路径上路由器对数据的缓存概率,并将数据缓存在概率最大的路由器上,以此减少网络的内容副本.但基于概率缓存方法存在较大的随机性,缺乏对多次被请求的数据内容(内容热度)的考虑;LAOUTARIS 等人提出一种下一跳缓存方法(Leave Copy Down, LCD)[5]将数据缓存在数据返回路径上命中路由器的下一跳路由器,使得请求频率高的数据缓存在靠近Consumer 的路由器中.但随着对同一内容的请求增多,传输路径的路由器中会缓存相同的内容副本,没有从根本上解决数据冗余的问题;ZHANG等人提出一种基于数据请求节点的就近缓存方法(Consumer-based Proximity Caching Algorithm, CPCA)[6],将热度高的数据内容优先缓存在靠近Consumer 的路由器中,提高缓存命中率,同时降低热度高的数据内容的传输跳数,该方法的不足在于靠近Consumer 的路由器存在高频替换的问题;CHAI 等人提出一种基于介数的缓存方法(Betw)[7],该方法首先为路由器定义了介数概念,即经过某一路由器的传输路径越多,该路由器的介数越大,之后将数据内容缓存在介数最大的路由器上,这种方法降低了网络的数据冗余,但数据内容都缓存在介数最大的路由器中时,由于CS的缓存容量有限,热度高的数据内容可能会被替换;GUO 等人提出一种基于数据内容热度与节点介数的缓存方法(HotBetw)[8],通过计算数据内容热度和路由器介数来决定Data 包的缓存位置.热度高的数据内容缓存在介数最大的路由器中,热度低的数据内容随机缓存在传输路径上的任意路由器中,当热度高的数据内容数量多时,这种方法中介数大的路由器存在高频替换的问题;GUO 等人提出一种基于内容类型的隔跳概率缓存方法(Content Type based Jumping Probability, CTJP)[9],该方法将数据业务进行分类,同时计算传输路径上路由器的缓存概率,从而降低网络内数据冗余,但该方法的请求时延并不理想;CHEN 等人提出一种区分服务的缓存方法(DiffCache)[10],该方法将数据业务分为无需缓存、尽力缓存和减少延迟三类,分别给三类业务赋予权值,并计算数据内容在每个节点的缓存概率,但在缓存容量变化范围内,尽力缓存和减少延迟两种业务的缓存比例波动较大;ALHOWAIDI 等人提出一种使用软件定义网络(Software Defined Networking,SDN)实现的数据缓存管理方法[11],该方法将大于CS存储空间的数据进行分块,分别缓存在不同路由器中,通过建立控制器,同时控制器向路由器发布配置指令的方式来通知路由器存取数据块,从而实现大数据文件的分布式缓存,文件预存取方法没有考虑到文件缓存的最佳位置,数据请求时延的变化不够明显.
2 分级数据缓存方法
2.1 方法原理
为了进一步提升NDN 网络的数据缓存和传输性能,本文针对以上方法中存在的数据内容多样性低、频繁替换等问题提出一种分级数据缓存方法(Hierarchical data caching, HDC).首先将 Interest 包和Data包格式进行改进,如图1所示:
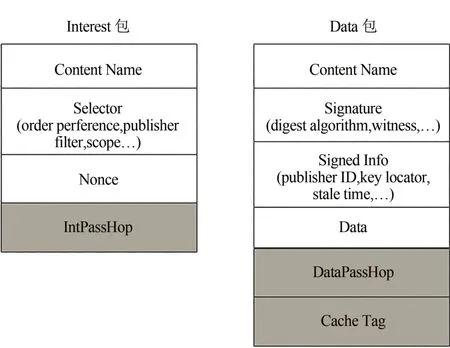
图1 改进后的Interest包和Data包的格式Fig.1 Improved format of Interest packets and Data packets
Interest 包增加IntPassHop 字段,用来记录Interest 包转发过程中经过的路由器数量;Data 包增加DataPassHop字段和CacheTag字段,中DataPassHop字段用来记录Data 包沿途返回过程中到达的路由器数量,CacheTag 字段用来决定数据缓存在传输路径的哪一个路由器中.
HDC 方法的核心在于将传输路径上的路由器进行分级,同时根据Data 包的CacheTag 字段值决定数据的缓存位置.图2为传输路径分级示意图.

图2 分级数据缓存示意图Fig.2 Schematic diagram of hierarchical data cache
如图2 所示,传输路径上共有T个路由器,将T个路由器分成n级,其中第1 到第n-1 级路由器数量均为T/n,第n级路由器数量为T/n+T%n.
为了验证分级数量对于网络传输性能的影响,本文尝试将传输路径分为一到五个等级,并根据缓存命中率(Cache Hit Ratio, CHR)[12]、平均路由跳数(Average Route Hop, ARH)[13]和平均请求时延(Average Request Delay, ARD)[14]进行对比分析.
不失一般性,分析实验中设定路由器数量为500 个,其中设置了1 个Publisher,网络边缘设置10 个Consumer,路由器中CS 容量平均为50 Kbyte.假设Interest 包发送过程符合Zipf 分布[15],Zipf 系数越大,Consumer 请求数据内容的重复度越高,其系数值设定为0.9.
图3~5 分别为五种分级情况CHR、ARH、ARD的对比结果:

图3 不同分级数量缓存命中率Fig.3 Cache hit ratio with different levels

图4 不同分级数量平均路由跳数Fig.4 The average route hops with different levels
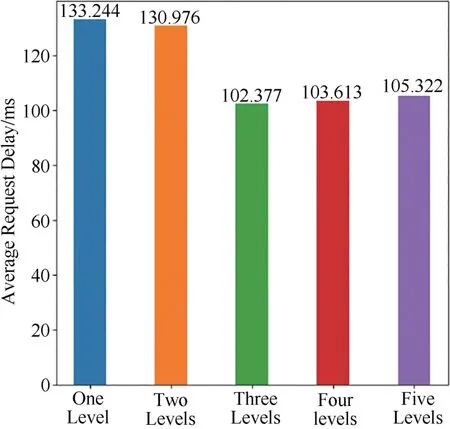
图5 不同分级数量平均请求时延Fig.5 The average request delay with different levels
从实验结果可见,将传输路径分为三个等级时,全网平均CHR 最高,ARH 和ARD 最低.因此,在接下来的分析中,本文将路由器的级数分为三级.
2.2 HDC方法
在HDC方法中,靠近Consumer的路由器被划分为第一级,靠近Publisher的路由器被划分为第三级.
将Interest 中IntPassHop 字段值设为L, Data 包的DataPassHop字段值设为M,传输路径中路由器总数为T.第一、二、三级路由器数量分别为:
根据以上分级方法,传输路径的路由器划分会出现均匀划分和非均匀划分两种情况,如图6 和7所示:
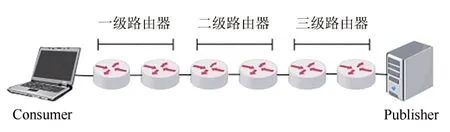
图6 均匀划分Fig.6 Uniform division
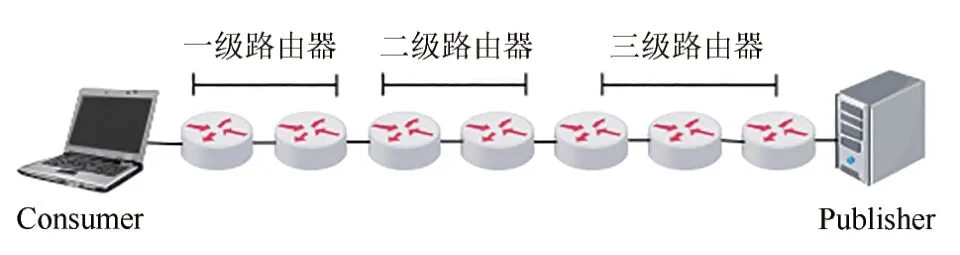
图7 非均匀划分Fig.7 Non-uniform division
Data 包中的CacheTag 字段值决定了数据内容被缓存的路由器.
CacheTag字段值设为K,计算如下:
当Consumer 第一次请求名为data1 的数据内容时,K的取值范围是(0,C3),传输过程中Data包每到达一个路由器K值减1,当K=0时将Data 包缓存在路由器A 中,缓存完毕继续向Consumer 转发Data包,在其他路由器上不再进行缓存操作.
当Consumer 第二次请求名为data1 的数据内容时,Data包从路由器A发出,此时K取值范围是(C3-M+1,C2+C3-M),传输过程中Data 包每到达一个路由器K值减1,当K=0时将Data 包缓存在路由器B中,缓存完毕继续向Consumer 转发Data 包,在其他路由器上不再进行缓存操作.
当Consumer 第三次请求名为data1 的数据内容时,Data 包从路由器B 发出,此时K的取值范围是(C2+C3-M+1,T-M),传输过程中Data 包每到达一个路由器K值减1,当K=0时将Data 包缓存在路由器C 中,缓存完毕继续向Consumer 转发Data 包,在其他路由器上不再进行缓存操作.
当Consumer 第四次请求名为data1 的数据内容时,如果路由器C 是距离Consumer 最近的路由器,则路由器C 向Consumer 转发Data 包.如果路由器C不是距离Consumer最近的路由,则Data 包从路由器C 发出,此时K=T-M,传输过程中Data 包每到达一个路由器K值减1,当K=0时将Data 包缓存在距离Consumer 最近的路由器D 中,缓存完毕继续向Consumer转发Data包.
HDC缓存过程伪代码如下:
算法1:Publisher 接收到Interest 包后进行处理,并将Data包返回至Consumer

Algorithm 1 Publisher process interest packet Input: Interest packet arriving at the Publisher Output: Data packet returned to Consumer T ← interest.ip //Total number of routers C3 ← T/3 + T%3 //Number of routers at C3 data.ct ← rand(0, C3) //Set CacheTag value
算法2:路由器接收到Interest包后进行处理,并将Data包返回至Consumer
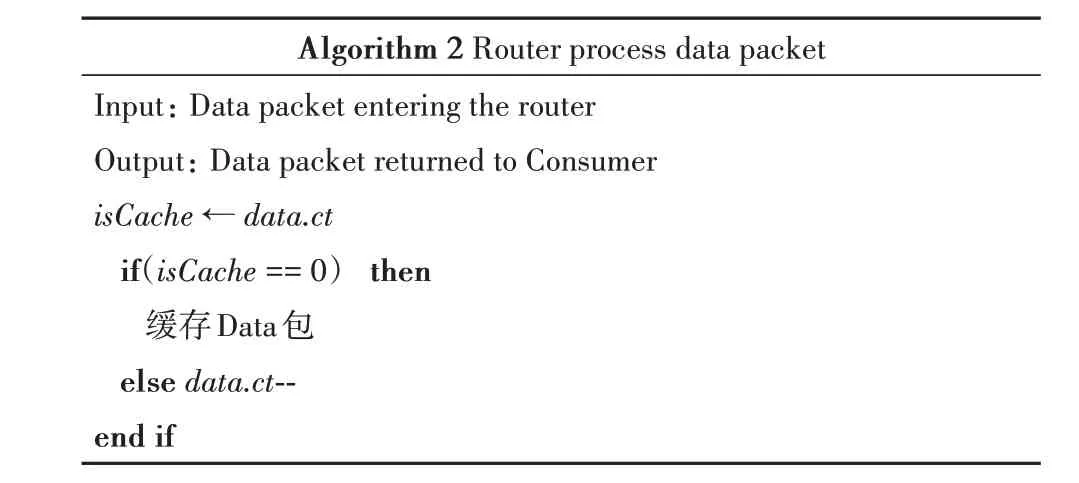
Algorithm 2 Router process data packet Input: Data packet entering the router Output: Data packet returned to Consumer isCache ← data.ct if(isCache == 0) then缓存Data包else data.ct--end if
算法3:Interest 包在路由器中被命中,路由器将Data包返回至Consumer

Algorithm 3 Interest packet hit in router Input: Interest packet entering the router Output: Data packet returned to Consumer T ← interest.iph + data.dph M ← data.dph C3 ← T/3 + T%3 C2 ← T/3 C1 ← T/3 if Data包缓存在C3中then data.ct ← rand(C3-M+1, C3+C2-M)else if Data包缓存在C2中then data.ct ← rand(C2+C3-M+1 , T-M )else if Data包缓存在C1中then data.ct ← T-M end if
3 仿真与性能分析
采用ndnSIM平台进行仿真实验,随机生成一个具有500 个路由器的网络拓扑,在网络中设置1 个Publisher,在网络边缘设置10 个Consumer,仿真时间50 s,缓存替换方法为最近最少使用替换算法(Least Recently Used, LRU).考虑到真实网络环境中路由器缓存容量远小于网络中数据内容总量,本文将缓存容量比R=C/N(路由器缓存容量/内容总量)的值设置为(0.01,0.05)之间,数据内容的请求模式服从Zipf 分布,将链路上队列在传输过程中可容纳的最大Data 包数量设置为20 个.实验参数见表1:
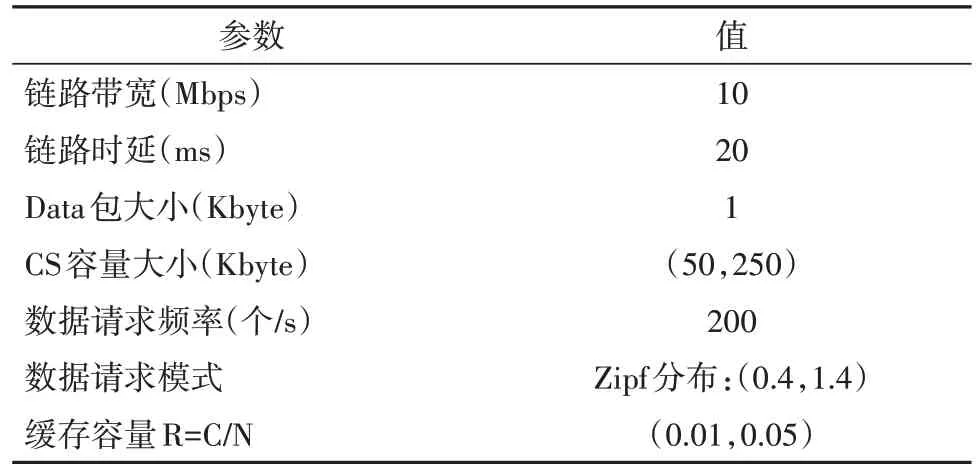
表1 实验参数Tab.1 Experiment parameter
本文将HDC 方法与CEE 方法、ProbCache 方法、LCD 方法从CHR,ARH 和ARD 等三方面进行对比分析.
图8 所示为R=0.02 且α=0.7 时四种方法的缓存命中率对比.实验分别从R 在(0.01,0.05)之间和α在(0.4,1.4)之间进行对比实验.

图8 四种方法的缓存命中率对比Fig.8 Comparison of cache hit ratio of four methods
图9所示为当α=0.7且R 在(0.01,0.05)之间时,四种方法缓存命中率变化.从图中看到,随着R 增大,路由器缓存的Data 包增多,四种方法的缓存命中率都有所提高,其中CEE 方法的命中率最低,HDC方法在R变化范围内缓存命中率最高.
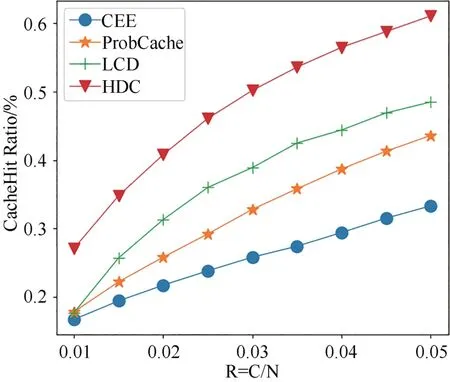
图9 不同缓存容量比下四种方法缓存命中率的变化Fig.9 Variation of cache hit ratio of four methods with different cache capacity ratios
图10所示为当R=0.02且α在(0.4,1.4)之间时,四种方法的缓存命中率变化.从图中看出,四种方法的缓存命中率随着α的增大而提升.其中LCD 方法的缓存命中率只有在α=0.5 时小于ProbCache 方法的缓存命中率, HDC 方法在α值变化范围内缓存命中率对比其他三种方法具有明显优势.
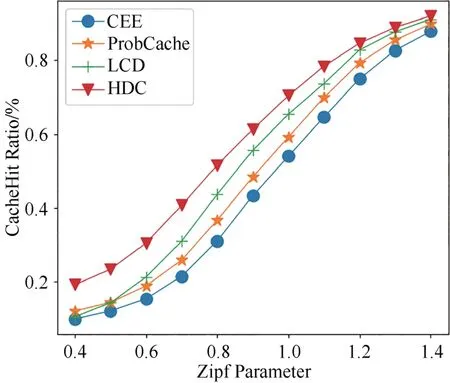
图10 不同Zipf系数下四种方法缓存命中率的变化Fig.10 Variation of cache hit ratio of four methods with different Zipf parameter
图11所示为R=0.02且α=0.7时四种方法的平均路由跳数对比.从图中看出CEE方法的平均路由跳数最高,HDC方法的平均路由跳数小于其他三种方法.
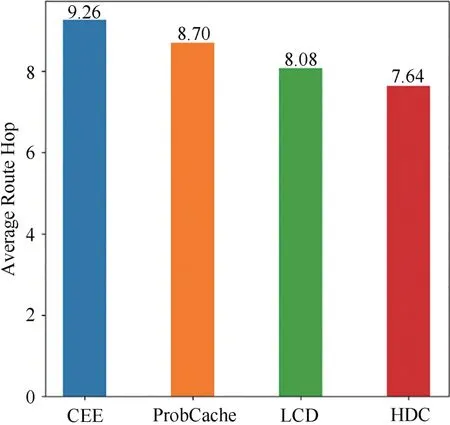
图11 四种方法的平均路由跳数对比Fig.11 Comparison of average routing hops of four methods
图12 所示为当α=0.7 且R 在(0.01,0.05)之间时,四种方法平均路由跳数变化.从图中看出,随着R 的增大,四种方法的全网平均路由跳数呈现下降趋势.其中HDC 方法的平均路由跳数减少最多,且在R比值变化范围内平均路由跳数最低.
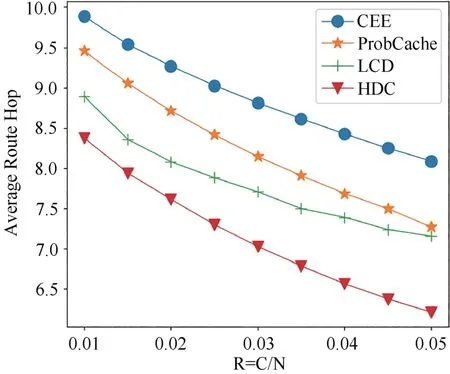
图12 不同缓存容量比下四种方法平均路由跳数的变化Fig.12 Variation of average route hops of four methods with different cache capacity ratios
图13所示为当R=0.02且α在(0.4,1.4)之间时,四种方法的平均路由跳数变化.从图中可以看出,随着α的增大,四种方法的平均路由跳数趋于相同,在α值变化范围内HDC 方法的平均路由跳数始终小于其他三种缓存方法,在α=0.4 时LCD 方法的平均路由跳数大于ProbCache 方法,其他情况下ProbCache方法优于LCD方法.

图13 不同Zipf系数下四种方法平均路由跳数的变化Fig.13 Variation of the average route hops of four methods with different Zipf parameter
图14 所示为R=0.02 且α=0.7 时,四种方法的平均请求时延的对比.从图中看出,HDC 方法的平均请求时延明显小于其他三种缓存方法,其中CEE 方法的平均请求时延最大.

图14 四种方法的平均请求时延对比Fig.14 Comparison of average request delay of four methods
图15 所示为当α=0.7 且R 在(0.01,0.05)之间时,四种方法平均请求时延变化.从图中看出,当R比增大时,四种方法的平均请求时延都明显降低,其中HDC 方法在R 比值变化范围内平均请求时延一直最低.CEE 方法的平均请求时延虽然也得到显著降低,但在R 比值变化范围内对比其他三种缓存方法平均请求时延最大.

图15 不同缓存容量比下四种方法平均请求时延的变化Fig.15 Variation of average request delay of four methods with different cache capacity ratios
图16所示为当R=0.02且α在(0.4,1.4)之间时,四种方法的平均请求时延变化.从图中看出,四种方法的平均请求时延随着α的增大而降低,且随着α的增大,四种方法的平均请求时延趋于相等.在α的变化范围内,HDC 方法的平均请求时延一直小于其他三种缓存方法.
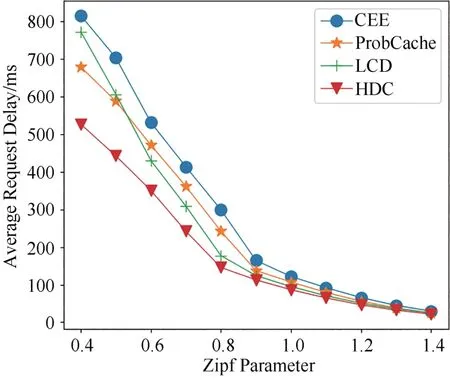
图16 不同Zipf系数下四种方法平均请求时延的变化Fig.16 Variation of average request delay of four methods with different Zipf parameter
4 结语
本文为解决NDN 存在的缓存冗余等问题,提出一种基于分级缓存的方法,通过对传输路径上的路由器进行分级,根据数据内容热度将其缓存在相应等级的路由器中.仿真结果显示,所提方法对比CEE、ProbCache 和LCD 方法,网络的缓存命中率得到了提升,同时降低了平均路由跳数和平均请求时延.
猜你喜欢
科教新报(2022年24期)2022-07-08 02:54:21
电子制作(2019年23期)2019-02-23 13:21:12
中国生殖健康(2019年11期)2019-01-07 01:27:44
长江丛刊(2018年31期)2018-12-05 06:34:20
测控技术(2018年6期)2018-11-25 09:50:10
NBA特刊(2017年8期)2017-06-05 15:00:13
系统工程与电子技术(2016年7期)2016-08-21 13:59:18
电测与仪表(2016年17期)2016-04-11 12:38:28
中国防伪报道(2015年4期)2015-12-27 00:52:35
梧州学院学报(2015年3期)2015-02-28 17:55:16
