
基于轻量级UNet的复杂背景字符语义分割网络
2024-03-05 12:13顾天君孙阳光林虎
中南民族大学学报(自然科学版) 2024年2期
顾天君,孙阳光,林虎
(中南民族大学 a.计算机科学学院;b.湖北省制造企业智能管理工程技术研究中心, 武汉 430074)
文字作为人与人基础的交流手段,是信息重要的载体.随着信息产业的迅速发展,文字迫切需要信息化,进而适应日益繁多的需求.现阶段关于光学字符识别(Optical Character Recognition, OCR)的研究和应用已经成熟,其利用光学技术和计算机技术进行字符识别,改变了我们的生活.例如在学习和工作中,只需要通过软件扫描纸质文档就可以生成其电子档版本,且正确率很高,丰富了交流手段并且降低了沟通成本.而现有的OCR 技术对于复杂背景下的字符识别具有应用局限性.出于提高复杂背景下文字识别准确率的考虑,研究出一种适用于复杂背景的字符分割算法符合现阶段的需要.
2014年全卷积网络(Fully Convolutional Networks,FCN)实现对图像端到端的分割,语义分割技术快速发展并被广泛应用于各个领域,如:医学图像[1-3]等,并在其快速发展过程中产生了许多新的语义分割网络,然而现有的语义分割网络大多伴随着计算效率或分割精度的问题[4-6],为语义分割技术在字符采集行业中的应用造成了困难.
为了解决以上问题,本文提出了基于轻量级UNet的复杂背景字符语义分割网络.该网络的主要创新如下:首先,在特征提取模块中抛弃了传统卷积,应用深度可分离卷积[7-10],减少了网络的参数量以及计算量,并使用残差学习模块解决网络退化问题[11-13].其次,对低层特征与高层特征的上采样结果进行特征融合,有效的结合了高层特征与低层特征的优势,具有较高的网络分割精度.后续的实验证明了本文网络在复杂背景字符分割上的有效性.
1 技术原理
1.1 UNet
UNet 是一种基于编码-解码结构的卷积神经网络,其具有两个特点[14]:(1)多尺度的图像信息,在网络的编码过程中不断降低特征的分辨率以获取不同尺度的特征,其中高层特征具有高语义,而低层特征具有高分辨率,使得UNet获取到的图像信息更加全面.(2)跳跃连接结构,为解决特征上采样产生的失真问题,在解码过程中对低层特征以及高层特征的上采样结果进行融合,特征融合结果结合高层特征的高语义以及低层特征的高分辨率,满足了分割对这两方面信息的需求.
1.2 特征提取模块
特征提取模块是语义分割任务的核心元素[15-17],也是网络的重要组成,因此很大程度上决定了网络的规模大小.为了减少网络的参数量以及计算量,本文网络在特征提取模块中将传统卷积变为深度可分离卷积(Depthwise Separable Convolution, DSConv).
深度可分离卷积过程可分为两部分(如图1 所示),首先考虑特征的区域,然后结合不同通道,实现了对输入特征区域和通道的分离[18].其中C、H、W 分别代表特征的通道数、高、宽,第一部分为逐通道卷积,逐通道卷积分开使用,卷积核数量与输入通道数相同,实现了对输入特征所有通道的逐一过滤,参数量以及计算量比传统卷积更少;第二部分为逐点卷积,每个卷积核对输入特征的每个通道都进行卷积计算,其计算结果是各个通道卷积结果的和,卷积核数量为输入通道数与输出通道数的乘积,实现了对过滤后所有通道的逐点卷积,用来获取通道之间的信息,这种分解结构相较传统卷积减少了参数量和计算量.
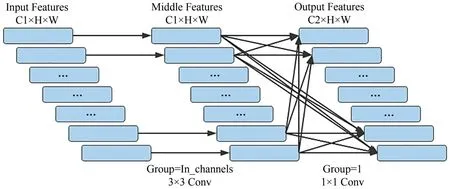
图1 DSConv基本结构Fig.1 Basic structure of DSConv
UNet 的特征提取模块含有两层卷积,输出通道数都与特征提取模块输出结果的通道数相同.本文为了进一步减少网络的参数以及计算量,将第一层卷积的输出通道数设置为特征提取模块输出结果通道数的一半,进一步减少了网络特征提取模块中的参数量以及计算量.
在神经网络中,后一层神经元的输入是前一层神经元输出的加权和,也就是说前一层的特征在后一层被抽象出来了,网络的学习过程也就是调节和优化各连接权重和阈值并不断抽象的过程[19].本文网络在特征提取模块中使用深度可分离卷积代替传统卷积,减少了网络卷积操作的参数量和计算量,使网络更加轻量.但是深度可分离卷积是双层结构,与使用传统卷积相比,特征提取模块的卷积层数也增大了一倍,增大了网络性能退化的风险.为了稳定网络反向传播时各层的权重,解决网络退化问题,本文在特征提取模块中加入了残差学习模块.
综上所述,本文特征提取模块如图2所示,其中X代表输入的特征,模块由直接映射路径以及残差路径组成,其中残差路径由两个DSConv 构成,直接映射路径由1 × 1 Conv 构成,两条路径进行相加并通过ReLU激活函数即为特征提取模块的输出.
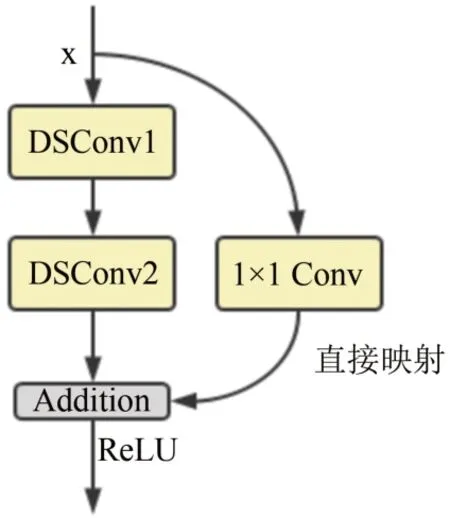
图2 特征提取(FE)模块Fig.2 Feature extraction module
1.3 双线性插值
双线性插值(Bilinear Interpolation)是一种提高图像分辨率的方法,其利用原图像中目标点四周的四个真实存在的像素值来共同决定目标图中的一个像素值,核心思想是在两个方向分别进行一次线性插值[20].传统UNet采用反卷积方式进行上采样,需要耗费大量的参数以及计算量.反卷积方式是通过卷积操作对图像进行尺寸放大,而双线性插值方法不需要参数且计算量与反卷积相比可以忽略不记,出于提升计算效率的考虑,本文使用双线性插值进行上采样.
由于双线性插值是在图像的原有基础上对其像素进行扩充,因此不能改变图像的通道数.为了保证网络跳跃连接结构中低层特征与高层特征上采样结果在通道数上的一致性,本文在上采样前的特征提取阶段中,通过卷积操作调整高层特征的通道数,使得上采样结果的通道数与后面进行融合的特征相同.
1.4 特征融合模块
特征在下采样以及上采样的过程中都会产生一定程度上的失真.与特征上采样相比,下采样的失真相对可以忽略,也保留了更多的细节信息,因此对特征上采样中信息失真问题的处理是提升网络性能的重要影响因素.UNet 在跳跃连接结构中通过拼接的方式融合低层特征与高层特征的上采样结果,以此减少特征上采样的失真.但是这种方式不仅使得特征融合后输出特征的通道数较大,增加了网络的参数量以及计算量.而且这种简单的特征融合方式不能充分体现网络中高、低层特征的关系.综上所述,本文将高层特征上采样结果以及低层特征通过加权求和的方式进行融合.较拼接方式,特征融合结果减少了一半的通道数,间接减少了网络的参数量以及计算量.
1.5 网络模型结构
本文网络原理框架如图3所示,网络可分为四个阶段:初始化(Initialize)、编码(Encoding)、解码(Decode)、输出(Output).在初始化阶段,输入尺寸为128 × 128的三通道待分割图像,通过特征提取模块提取语义信息,初始化阶段共进行一次特征提取,最终输出64 × 128 × 128的特征图.在编码阶段,每次编码首先使用最大池化方式(MaxPool)对特征进行下采样,再使下采样结果通过特征提取模块,提取特征的语义信息,编码阶段共进行四次编码,最终输出512 × 8 × 8的特征图.在解码阶段,每次解码都首先通过双线性插值的方式对特征进行上采样,再通过特征融合模块,将上采样结果与编码阶段中相同尺寸的编码输出特征进行融合,最后使特征融合结果通过特征提取模块,提取特征的语义信息,解码阶段共进行四次解码,最终输出3 × 128 ×128 的特征图.在输出阶段,通过1 × 1 Conv 整合解码阶段的最后特征的各通道并输出结果.
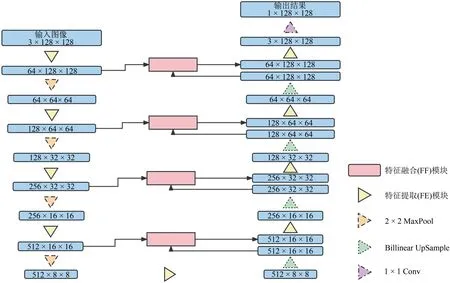
图3 网络原理框架Fig.3 The framework of network
与UNet相比,本文网络在特征提取模块中使用深度可分离卷积代替传统卷积,使得网络轻量化.应用残差学习模块解决网络退化问题.并采用双线性插值方法进行上采样,提高了计算效率.最终得到本文网络.具体结构如表1 所示.相较UNet,改进减少了网络的参数量以及计算量.
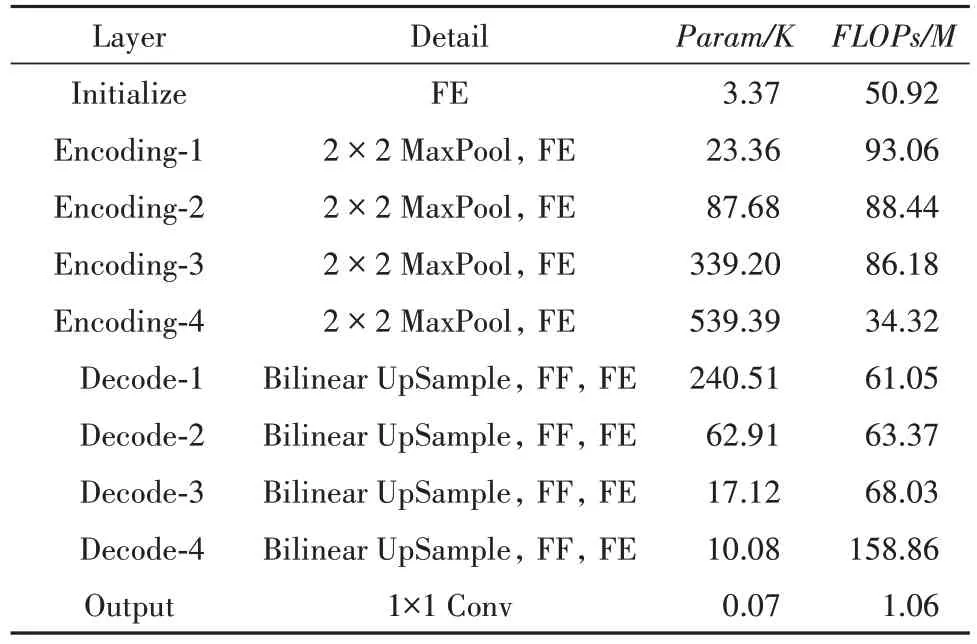
表1 网络整体结构Tab.1 The whole structure of network
1.6 损失函数
神经网络的性能不仅取决于网络的结构,还取决于损失函数的选取.损失函数的作用在于度量模型的预测结果与真实值之间的差异,损失函数的值越小,代表模型的效果越好.交叉熵损失函数具有求导简单、收敛速度快的优点,因此主流的语义分割网络都将其作为损失函数使用,在对图像进行二分类任务时,本文使用二元交叉熵(Binary Cross Entropy, BCE)损失函数,具体函数公式如(1)式:
其中N 代表训练集的大小,g(i)代表第i张图片的真实值,p(i)代表第i张图片的预测值.
2 实验
2.1 样本数据增强
为了验证本文网络的性能,选取77张不同字样的字符图像作为实验数据集的原始字符图像,每张图像的尺寸为128 × 128.由于字符图像的数量较少且实际应用中出现的字符会不完整,为了贴合实际,按1∶20 的比例对字符进行随机残缺,生成1540 张不同的字符图像,并将其与不同背景图片进行图像融合,最终得到本文的实验数据集.从全部样本随机抽取10%作为实验的测试集,剩下的作为训练集.
2.2 实验环境与参数设置
实验使用的深度学习框架为PaddlePaddle 2.0.2,环境为Python 3.7,批处理大小为10,在Nvidia Tesla V100 32GB GPU 上使用随机梯度下降的方式训练模型200 个epoch.在网络的训练过程中,本文采用RMSProp 优化器,并使用ReduceOnPlateau 学习率调度器,设置训练的初始学习率η为0.01、patience 为5、factor为0.1.
2.3 评价指标
本文采用交并比、精确率、召回率以及F分数衡量模型的分割精度.其中交并比(Intersection Over Union, IoU)是指模型的预测结果与标注图之间的交并比,用来衡量模型预测结果与标注图之间的相似度.精确率(Precision)是指模型所有预测出的目标中预测正确的概率,用来度量正例中真正的正例样本的比.召回率(Recall)是指所有的正样本中正确识别的概率,用来度量被正确判定的正例占总的正例的比重.F 分数(F)即精确率和召回率的调和平均数,它同时兼顾了模型的查准率和查全率.样本中的正例代表图像中的字符部分,反例代表图像中的背景部分,具体函数公式如(2)~(5)式:
其中,TP(True Positive)表示真正例,即模型预测为正例,实际也为正例,FP(False Positive)表示假正例,即模型预测为正例,实际为反例,FN(False Negative)表示假反例,即模型预测为反例,实际为正例,TN(True Negative)表示真反例,即模型预测为反例,实际也为反例.
3 实验结果及分析
3.1 与其他网络比较
为了分析本文网络的性能,分别与Paddle 框架自带的经典网络FCN8s、AttaionUNet 和UNet 进行对比.从测试集中抽取了4个样本,并将各模型的预测结果与对应样本的标注图进行比较(结果如图4 所示),其中图4(a)代表待预测的样本,图4(b)代表样本对应的标注图,图4(c)-(f)为不同模型的预测结果.可以看到,在对字符与背景对比度强的部分进行预测时,各模型都能够把字符较为完整地分割出来,在对字符与背景对比度弱的部分进行预测时,各模型漏分与误分的现象开始不同程度上的增多.

图4 不同模型的分割结果对比Fig.4 Comparison of segmentation results of different models
为了更直观地表示各模型的预测结果与标注图的具体差异,使用浅灰色、深灰色、黑色分别代表模型预测结果与标注图的重叠区域、漏分区域、误分区域(结果如图5 所示),其中图5(a)代表样本对应的标注图,图5(b)-(e)为不同模型的预测结果.从FCN8s 预测结果与标注图的对比可以看出,FCN8s无法分割出字符的局部具体细节,在对难度较大的样本进行预测时,误分与漏分的次数过多,难以从FCN8s 的预测结果中辨认出样本具体是哪种字符,因此FCN8s 无法满足实际应用对网络的分割精度要求.从AttaionUNet、UNet、本文网络预测结果与标注图的对比可以看出,这三种网络都能够从复杂背景下的字符样本中较好的分割出字符的具体形状,可以满足实际应用对网络的分割精度要求.

图5 不同模型差异化分割结果Fig.5 Different models differentiate segmentation results
为了进一步分析各网络的性能,在完整的测试集上进行测试.由于测试集含有部分字符内容残缺的样本,而残缺字符与完整字符的样本相比,降低了图像中字符与背景的对比度,增大了模型进行语义分割的难度,因此各模型的分割精度有不同程度上的下降.给出各模型的Params 和FLOPs,从计算效率以及分割精度两个层面上分析各网络的性能(如表2 所示).在计算效率层次上比较各网络的性能,本文网络的Params为1.32M且FLOPs仅为0.70G,而较FCN8s、AttaionUNet 和UNet 网络相比,本文网络的Params 和FLOPs 均降低了一个数量级.在分割精度层面上比较各网络的性能,本文网络在分割精度指标IoU、Precision 以及F上均得分最高.综上所述,本文网络兼顾了计算效率以及分割精度,在满足实际应用中实时性检测要求的同时有着较高的分割精度.
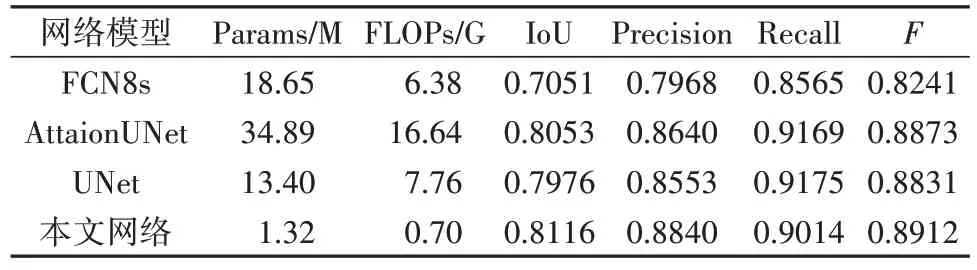
表2 与其他网络的性能对比Tab.2 Performance comparison with other models
3.2 H-DIBCO2018公开数据集测试
为了验证对比网络的鲁棒性,本文在H-DIBCO2018公开数据集上进行实验.H-DIBCO2018 中的样本来源于READ(Recognition and Enrichment of Archival Documents)项目,其中涵盖了从十五到十九世纪的各种收藏,共10 张图像.将其中9 张图像用于训练,剩余的1 张图像用于测试,并将尺寸为1013 × 511的测试图像填充为1024 × 512,以便于网络跳跃结构中编码阶段和解码阶段的特征图操作.由于训练集的数据量较小而图像尺寸较大,使用随机剪裁的方式对训练图像进行数据增广,并统一裁剪结果为尺寸为128 × 128 像素的图像,最终生成1123 张训练样本.为了能更充分的考察各网络的性能,在样本上添加椒盐噪声(噪声比例为0.15),降低了图像中字符与背景的对比度,加大了分割的难度.在训练集上对本文网络与FCN8s、AttationUNet和UNet进行训练,将收敛的网络模型在测试集上进行测试(结果如图6所示).从图中可以看出,本文网络在公开数据集上相较其他网络也具有良好的表现.通过对各模型的性能进行评估(如表3 所示),与FCN8s、AttationUNet 和UNet 相比,本文网络在计算效率以及分割精度上显示了本文网络具有较好的性能.
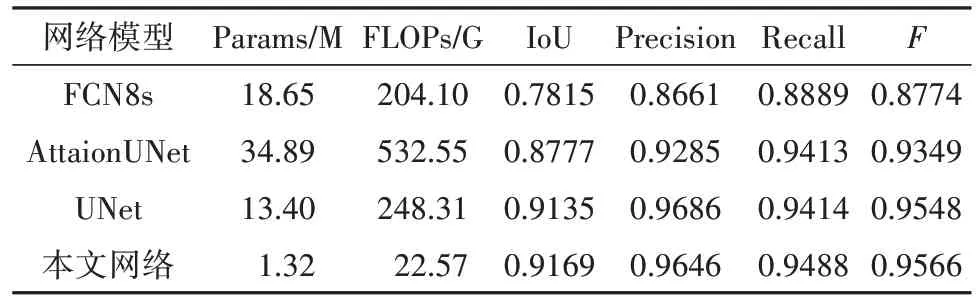
表3 与其他网络的性能对比Tab.3 Performance comparison with other models

图6 H-DIBCO2018数据集测试结果Fig.6 H-DIBCO2018 dataset test results
4 结论
针对目前语义分割网络在复杂字符背景分割中应用困难的问题,本文提出了一种基于轻量级UNet的复杂背景字符语义分割网络.本文在UNet网络结构的基础上对其特征提取模块和跳跃连接结构中特征融合的方式进行改进,并使用双线性插值方法进行上采样.与近年来的其他语义分割网络相比较,测试结果显示本文网络较好的平衡了计算效率与分割精度,为复杂字符背景分割提供了一种集合速度与准确于一体的算法.尽管本文网络取得了较好的成绩,但是改进后的网络仍然存在着细节部位不准确的问题,因此后续的研究会致力于提升网络对字符局部细节分割的准确率,使得网络可以应用在更多的实际场景中.
猜你喜欢
电脑爱好者(2022年15期)2022-05-30
开放教育研究(2020年2期)2020-03-31
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
少儿美术(快乐历史地理)(2018年7期)2018-11-16
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
噪声与振动控制(2015年4期)2015-01-01
