
自动化行政裁量中算法风险感知的特征与演化研究
——基于网络舆情的大数据分析
2024-03-05 11:34刘天颖
公共行政评论 2024年1期
梁 昕 刘天颖
一、引言
近年来,随着人工智能、大数据等新兴技术的快速发展,人类开启了第四次工业革命,开始迈入智能化时代(姜李丹、薛澜,2022)。算法已日渐嵌入人类社会的生产和生活中,其影响力的广度、强度和精度在历史上都不曾出现(邱泽奇,2022)。在“放管服”改革以及“互联网+政务服务”的推动下,传统以人为主导的行政裁量逐渐转变为基于算法的自动化行政裁量,目前已广泛应用于行政处罚、行政审批、行政给付和行政评级等领域(刘星,2022)。在此过程中,一方面,政府对算法进行赋权,使算法成为公权力的延伸;另一方面,公民向算法让渡个人权利,导致了算法权力的扩张,深刻影响着公私“权力-权利”的边界甚至重塑着国家与社会秩序(肖红军,2022)。
算法嵌入行政裁量可以实现技术赋能,显著提升行政裁量的效率和国家治理效能;然而同时也带来了前所未有的算法风险,如算法“黑箱”、算法歧视、算法垄断、算法操纵等(邱泽奇,2022)。特别是在行政裁量情境下,政府和算法的实控者(如地方官员、程序员等)存在委托-代理关系,由于算法“黑箱”问题的存在,信息不对称较为严重,从而引发代理人出于自身利益操纵算法的道德风险问题,并可能给公民政治经济、人身自由等基本权利带来较大的风险,甚至危害社会秩序和政治稳定(孟天广、李珍珍,2022)。
近年来,算法风险治理的相关研究呈急剧上升的趋势,也取得了一系列研究进展,主要集中在算法权力、算法伦理、算法透明等方面,并提出立法、行政规制、行业公约和社会规范等治理手段(Grimmelikhuijsen,2023;Meijer et al.,2021)。然而,公民作为受算法权力影响的重要主体,关注公民算法风险感知的研究却较为有限。相关研究也大多采用小范围调查问卷和心理量表测量结合的方法,对风险感知的影响因素和机制进行探讨。尚缺乏基于大数据对公众算法风险感知的探索,特别是缺乏针对行政裁量情境中,公众对算法风险感知的异质性特征和动态演化趋势的研究。网络空间的公众舆论是分析公众认知、态度和情感的重要手段,具有大样本、动态性和客观性的优势,目前已大量应用于公众认知和情绪的研究中。
2022年,河南部分村镇银行储户健康码被赋红码(以下简称“赋红码”事件),人民网针对此事发表《赋“红”一时爽,后果必须扛》评论,引发了网络舆论针对算法风险的广泛探讨。本研究基于微博平台上该事件的发文数据进行挖掘和分析,描述了公众对于行政裁量中的算法风险感知特征,重点探讨了风险感知的时空演化特征、多主体的异质性以及风险沟通中的话语体系差异。通过数据挖掘、自然语言分析、空间分析等多种方法,本文尝试回答以下两个研究问题:
第一,公众对行政裁量中算法风险的感知具有怎样的时空演化特征?
第二,不同主体在针对算法风险的沟通中呈现何种异质性特征及其动态演化规律?
二、文献综述
(一)自动化行政裁量中的算法权力
算法在不同的历史时期、不同的应用场景中有着不同的含义,在技术、系统、社会等层面也被赋予了不同的理解。从本质上来讲,算法是一种求解的逻辑,即“为了解决一个特定问题或者达成一个明确目的所采取的一系列步骤”(Diakopoulos,2015)。在计算机科学领域,算法是一种较为狭义的概念,指利用数学模型与计算机逻辑指令求解最优方案(Gillespie,2014),如决策树、神经网络等都是机器学习的经典算法。随着数字时代的发展,算法概念逐步超越计算机科学的专业术语,拓展到更广泛的社会领域,泛指人机交互下进行系统决策的一套机制(丁晓东,2020),如自动化判决、辅助决策等。
近年来,随着移动互联网、人工智能等新兴科技的发展,算法无论是在人群覆盖的广度,还是嵌入人类生产生活的深度上,都达到了历史上前所未有的水平(邱泽奇,2022),逐渐彰显出“颠覆性的潜力”(凯伦·杨、马丁·洛奇,2020),深刻影响了人类政治、经济、社会等各个领域。行政裁量对算法的依赖日益加重,甚至在一定程度上赋权于算法,这样就产生了“自动化行政裁量”,即以大数据、人工智能等新一代数字技术为支撑,按照一定的算法程序,以半自动化或者全自动化的形式作出行政裁量,又称为行政裁量数字化(刘星,2022)。行政裁量也由传统以“人”为中心的规则建构,转变为依托“算法”进行裁量,形成人机协同的深度融合关系。
目前,自动化行政裁量已广泛应用于行政处罚、行政审批、行政给付和行政评级等领域。在行政处罚方面,我国在全国范围内覆盖了电子交通监控系统,对超速等交通违章实现自动处罚。在行政审批方面,2018年,深圳市推出“无人干预自动审批”行政审批模式,自动核查申请人资料并决定是否通过。在行政给付领域,我国也在贫困资格认定、贫困补助发放等领域进行了大量尝试。在行政评级方面,2020年,国务院下发《关于依法科学精准做好新冠肺炎疫情防控工作的通知》,鼓励公众使用动态健康码,其基于大数据和算法分析自动判断健康风险等级,用“红码”“黄码”“绿码”进行标识。
随着行政裁量中算法的深度嵌入,大量判断裁决已交由算法执行,而看似理性中立的计算结果隐藏着规则的施加,算法权力也相伴而生。算法权力是以算法为工具实施的影响力或控制力(陈鹏,2019;赵一丁、陈亮,2021)。现有文献对算法权力的形成机制进行了不同角度的探讨(张爱军、王首航,2020)。一种观点认为,“算法即法律”(Lessig,1999),代码建构了数字空间的规则,与人类社会的制度具有同样的规制效应(Micklitz et al.,2021)。而另一种观点则认为,原生的算法权力仅存在于数字空间中,而通过人类的“赋权”,算法才获得了影响人类社会的权力。
(二)算法风险
随着算法权力在行政裁量中的日益扩张,其带来显著收益的同时也伴随着巨大的风险。现有文献对算法风险已有不同视角的探讨,主要集中在以下三个维度。一是从国家和社会的宏观角度出发,学者提出了“算法利维坦”的概念(张爱军,2021)。在人工智能时代,人们日渐依赖算法,如果无法约束算法权力的膨胀,很可能演化成“算法利维坦”,成为绝对权威,使公民、国家、社会的运行制度发生异化。二是从政府与公权力的视角出发,政府赋予算法的权力也可能被算法的代理人用于谋取私利,甚至进行社会控制和政治权力再生产(孟天广、李珍珍,2022)。由于算法生产的专业性,政府无法直接生产算法,而是通过代理人(包括算法开发者、设计者、部署者和应用者等)进行算法的设计、部署和维护(肖红军,2022)。代理人可能有意地操纵算法牟利(张婧飞、姚如许,2022)。然而,由于信息不对称以及算法“黑箱”问题的存在,政府和公众不但很难对代理人的行为进行过程监督,甚至对行为结果的监督也非常困难。这个过程就产生了委托-代理关系带来的道德风险问题。三是从公民个体角度出发,算法权力与公民权利是此消彼长的关系,算法权力的扩张意味着公民权利在一定程度上被侵蚀,给公民的权利保障也带来了一定的风险。
不同于传统风险,算法风险具有较强的独特性,具体表现为以下四个方面。首先是广泛性,中国互联网接入人口如果以家庭为单位计算,几乎全部人口均受到算法的影响。算法风险触及的广度是传统风险不曾出现的(邱泽奇,2022)。其次是深入性,由于算法权力是公权力的延伸,其带来的影响也可以深入至公民自由权、平等权等人类最基本的权利。以美国“卢米斯”案为例,法官参考COMPAS系统计算的结果判处卢米斯6年有期徒刑,引发了算法是否会干预司法公正的激烈争论。再次是隐蔽性,由于算法的专业性和信息的严重不对称性,算法的代理人可以非常隐蔽地修改代码,使算法附加部分代理人的利益。面对算法“黑箱”,政府和公众都很难实现透视,甚至当算法被篡改时毫无察觉。最后是综合性,在自动化行政裁量过程中,人和算法是深度绑定交互的共同体,因此当问题和风险产生的时候,很难准确地进行归因,很难判断是人的问题、算法的技术问题还是两者交互产生的问题。由于原因的综合性和复杂性,算法风险治理往往难以确定责任主体。
有关算法风险影响的研究主要围绕社会治理、公共部门组织和个人层面三个维度展开。一是从社会治理角度来说,算法风险的产生对社会公平正义产生负面影响。以2016年美国大选为例,社交媒体上传播的虚假信息成为私人达到政治目的的工具(Ng &Taeihagh,2021),在危害使用者隐私的同时,影响到了社会公平的核心价值。此外,当算法被用于如社会信用评分、犯罪风险评级等对公众进行评价的系统时,出现的系统信息泄漏、信息错误等风险会影响到社会的稳定(Zhang,2020)。二是从公共部门的视角出发,政府采用算法行政裁量产生的偏差会对公共部门的信任造成不可估量的危害。例如,当政府用于检测福利欺诈的人工智能系统失灵,福利欺诈事件层出不穷时,公众对政府的信心会受到严重打击(Bodo &Janssen,2022)。三是从个人层面展开讨论,算法出现在人员招聘、警务预测等自动化裁量系统中涉及性别、种族等特征的歧视风险,显著影响到个人的权益。例如,加拿大的犯罪评估方法因为对黑人和土著囚犯的系统性偏见而饱受批评(Zajko,2021)。
(三)算法风险感知及其影响
随着算法深度嵌入人类社会的生产生活,算法“黑箱”、算法歧视、算法垄断、算法剥削等(张恩典,2020)各种算法带来的负面影响屡见报端,使公众的算法风险感知日渐强烈。传统风险研究一般认为风险是客观意义上不利后果与发生概率的乘积,而大量研究也表明,人对风险的认知并不是完全客观的,也是基于人们的认知、经验等主观的建构(Fischhoff et al.,1978)。Slovic(1987)认为,风险感知是人们依靠自身的直觉与经验对事件产生的负面影响进行判断与评估,并产生对风险的认知与态度。算法风险感知可定义为公众因算法技术的应用而感知到的不确定性以及后果严重性(刘春年等,2023),包括算法焦虑感知(查道林等,2022)、算法歧视感知(Alon-Barkat &Busuioc 2023)和算法控制感知(裴嘉良等,2021)等多重研究维度。
现有研究已经对算法、大数据、人工智能等新兴信息技术的风险感知做出了探索,主要集中于两个方面。一是风险感知的测量,包括公式化测量、社会文化测量以及心理测量三种方式。其中,心理测量应用最为广泛,主要通过问卷调查,利用心理学的测量指标来评估公众对风险的感知(Slovic,1987)。二是风险感知的影响因素。传统的心理测量范式强调风险感知受到个体属性和心理因素的影响,包括性别、年龄、受教育程度、个人经历、心理距离等。在此基础上,学者们逐渐认识到风险感知不仅受到个人因素的影响,还受到社会环境的影响。由此发展出风险的文化理论,将社会文化因素,如文化背景、价值观、社会规范、信任等变量纳入风险感知的研究之中(Dake,1991)。
公众风险感知可以在很大程度上影响风险治理的政治、经济和社会行动,例如公众对人工智能的风险感知可能影响到技术接纳和公众参与。此外,由于在行政裁量的情境下,算法是公权力的延伸,与政府深度绑定,公众对算法的风险感知也会发生外溢,进而影响政府信任,从而改变政府-公民的二元关系,是算法风险治理中的重要因素(贾开、薛澜,2021)。
综上所述,现有文献已对行政裁量中的算法权力和算法风险进行了丰富的探讨,但仍有以下不足。一是已有文献对算法风险的探讨大多为自上而下的视角,从公民视角出发分析算法风险感知则相对较少;二是公众算法风险感知研究多采用调查问卷,缺乏基于大样本数据的探讨;三是现有针对算法风险感知的研究大多为静态截面研究,缺乏对风险感知动态演化以及多主体异质性特征的分析。本文基于大数据的视角,结合机器学习、自然语言处理等算法,可以解释大样本下公众风险感知特征与演化规律,在理论上可以拓展风险感知的研究范式,在实践上有助于为政府的算法风险治理提供更加精准的模型。
三、研究方法
(一)案例背景
2022年6月13日,有网友在社交平台反馈称,多名前往郑州沟通村镇银行的“取款难”储户被赋“红码”(魏少璞,2022),此事迅速引发舆论关注。2022年6月17日,郑州市纪委监委启动调查问责程序。6月22日,郑州市发布关于部分村镇银行储户被赋红码问题调查问责情况的通报。据统计,共有1317名村镇银行储户被赋红码,其中446人系入郑扫场所码被赋红码,871人系未在郑但通过扫他人发送的郑州场所码被赋红码(彭静、王欲然,2022)。2022年7月8日,人民网评论文章《又现红码,河南怎么了?》再次冲上微博热搜,一些人在山东、辽宁等地的河南村镇银行储户再次向媒体反映称,自己的健康码再次被远程赋“红码”。当日,郑州市大数据管理局回应称,由于系统升级过程中出现技术问题,晚8时已全部恢复正常。2022年7月11日,河南省地方金融监管局公告,对涉事客户本金开展先行垫付工作。至此,该事件进入尾声。
本文选取“赋红码”事件作为本文研究案例的原因有如下两点。一方面,该事件中自动化行政裁量直接影响了公民的权利,引发公众强烈的风险感知,产生了严重的社会影响,是一起典型的行政裁量中算法风险的案例;另一方面,“赋红码”事件具有广泛性和持续性的网络讨论高潮,可以基于网络大数据聚焦该案例进行大样本、动态性的分析。
(二)数据收集
本研究第一轮数据收集以“健康码”为关键词爬取了2021年1月1日至2022年12月31日期间发布的微博,共计33890条,并在此基础上对涉及“赋红码”事件的微博进行筛选,因此在第二轮数据收集中,在原始数据的基础上筛选出与案例高度相关的微博,并同时爬取了每条微博下对应的评论内容。因此,数据包括了与该事件高度相关的微博主帖以及所有相关评论。最终从新浪微博平台收集有效微博6108条及评论内容共3220条,抓取12项数据特征值,包括:(1)微博内容;(2)微博识别信息:MID、ID等;(3)用户识别信息:UID、User Name等;(4)用户特征信息:Province、Description等。
(三)数据挖掘
1.信任度与情感分析
本研究依据微博推荐系统的指标,结合安璐和徐曼婷(2022)的信任度计算公式,将微博内容情感得分和微博评论情感得分同时纳入考虑,综合计算每条微博的综合情感值。每条微博W获得的综合情感得分计算方式如式(1)所示,其中θ1、θ2通过熵值法确定取值。
Trust=θ1trust_m+θ2trust_c
(1)
其中,Trust是单一微博整体信任度,trust_m是单一微博内容信任度,trust_c是该微博对应的评论内容信任度。
trust_m=senti_m×ln(m_like+m_trans)
(2)
trust_c=∑senti_mi×ln(c_likei+e)
(3)
式(2)中,senti_m是该微博内容的情感得分,m_like是该微博内容的点赞数,m_trans是该微博内容的转发数;式(3)中senti_mi是该微博第i条评论的情感得分,c_likei是该微博第i条评论的点赞数。
需要说明的是,senti_m代表微博用户对这一话题的情感表达,由于用户的点赞和转发代表着更多人对这一情感表达的认可,因此将点赞和转发两个因素纳入微博内容情感值计算范围;在社交网络中,计算综合情感得分需要同时考虑用户的微博内容收到来自其他用户的正面和负面反应的数量(Asim et al.,2019),故而单一微博的评论内容情感值是每条微博的评论区所有正向情感和负向情感之和。
2.空间分析
有研究指出,由于网络舆论的形成会受到与地理位置相关的文化、认知的影响(罗植等,2012),因此,网络舆论往往呈现出明显的区域性特征。本研究采用空间自相关分析(spatial autocorrelation analysis)中的全局空间自相关分析方法,对微博的空间特征进行探究。全局空间自相关分析是对整个区域的空间特征进行描述,通常采用莫兰指数来测度区域整体上某一属性的空间聚集程度(谌志群、鞠婷,2020)。计算模型如下:
(4)

3.词汇分析
第一,词汇密度。在对文本内容进行分析的时候可以发现,具有一定词汇存储量的作者会偏爱使用一些特定词汇,作者的词汇量能够反映在词汇的出现频率中,因此,词汇的分布频率可以应用到不同类别作者的比较分析中。词汇密度(lexical density)作为一个语言特征,最早由Ure (1971)提出,词汇密度是文中的实词数量与单词总量的比值。Halliday(1985)在Ure的基础上提出了新的计算方法,认为词汇密度是词项数量与篇章小句总量的比值。
第二,词汇变化性。词汇变化性,也称词汇多样性(lexical diversity),是反映篇章作者词汇丰富性的一个语言特征,通常用来测量篇章词汇的适用范围或种类,词汇变化性越高说明用词范围越广;反之,词汇变化性越低,说明用词范围越窄,篇章词汇重复率高。本研究采用Dugast提出的更为复杂的Uber index测量方法(张艳、陈纪梁,2012),相比传统的TTR计算方式更加精确,且不会受到文本长度的影响(Vermeer,2000)。具体的计算公式如下:
(5)
4.内容主题分析
文本分析一直以来都是社会科学领域的重要研究材料,但对于海量微博内容已经无法采取手工编码的方法,因此本研究采取LDA(Latent Dirichlet Allocation)模型进行内容主题分析(Tolbert et al.,2010)。
四、研究发现及讨论
(一)算法权力与算法风险的生成逻辑
基于海量数据和人工智能算法的自动化行政裁量具有传统方法无可比拟的优势。从政府视角出发,算法为政府进行技术赋能,显著地拓展了政府的行政能力。从公民视角出发,基于自动化行政裁量的效率也得到了显著的提升。例如,在算法辅助下,一半以上的行政许可事项平均时限压缩超过40%(中国互联网络信息中心,2022)。
由于自动化行政裁量的巨大优势,应用不断推广和深入,加强了政府对算法的行政赋权和个人对算法的权利让渡,在两者共同作用下产生了算法权力,如图1中阶段一所示。一方面,算法权力来源于公权力的延伸,政府的行政赋权范围决定了算法权力的大小。以健康码为例,如果健康风险判断的算法仅在数字空间完成运算和结果的呈现,并不会对公民个体及社会产生影响。然而,通过地方政府的行政赋权(例如针对不同级别健康码制定管控措施,使其成为个人获得出行、复工等资格的必要证明),健康码的算法便有了直接影响居民行动的权力。另一方面,算法权力也来源于公民权利的让渡。例如,在健康码的使用中,公民让渡了隐私权等,使算法权力进一步扩张,重塑了公私“权力-权利”的边界(如图1中实线所示路径)。

图1 行政裁量中算法权力与算法风险分析框架
在自动化行政裁量情境下,算法权力由于其人机深度融合的特点,形成了一种新型的行政权力,具有独特的广泛性、精准性与责任模糊性等特点。传统的行政权力有明确的权力边界,但由于算法“黑箱”问题的存在,政府和算法的代理人之间存在着严重的信息不对称,代理人可能通过干预算法,逾越权力边界牟利,导致算法权力的异化,进而导致算法风险。传统行政权力有明确的赋权机制,权责对应,责任主体清晰,但算法问题的归因十分困难(张婧飞、姚如许,2022)。这使得算法权力的滥用更加隐蔽,也给算法权力的治理带来更大的挑战。在“赋红码”案例中,部分代理人干预算法,给不符合条件的人群赋红码,算法权力的异化造成严重不良社会影响,导致了公众对算法风险的广泛舆情(如图1虚线所示路径)。基于此,以下通过大数据分析对算法权力及其带来的新型的风险进行深入的剖析,主要包括空间特征分析、时间特征分析以及多主体异质性分析三部分。
(二)“赋红码”事件中公众舆情的空间特征分析
1.数量与信任值空间特征分析
空间特征分析结果显示,对该事件讨论最集中的区域为河南省、北京市、上海市等。河南省作为事件的发生地,当地的网友对这一事件高度关注。北京作为国家的政治中心,人民网等政府和媒体网络账号集中于北京,因此北京地区的微博讨论也位居前列。此外,江浙沪沿海地区网友对该事件的关注度也很高,说明东部发达地区的公众对算法权力和算法风险的关注度较高,也印证了经济高水平城市在网络空间上保持较高的优势度的研究结论(丁志伟等,2022)。
综合情感值的分析结果显示,“赋红码”事件导致全国几乎所有省份的民众都产生了对政府算法权力和算法风险的负面感知,综合情感值较低,证明当政府算法系统出错时会对民众的信任和情感产生较大伤害(Bodo &Janssen,2022)。然而,情感值最低的地区并不是“赋红码”事件的发生地河南,而是浙江省和辽宁省,这和涉事人员的地区分布相一致。从《人民日报》公布的数据来看,涉事的储户中有446人系入郑扫场所码被赋红码,871人系未在郑但通过扫他人发送的郑州场所码被赋红码。因此,对“赋红码”事件产生较为严重消极情绪的并非仅是事件的发生地河南的民众,而且包括诸如浙江省等外地储户大量分布的地区。
2.莫兰指数分析
根据微博数量分布计算莫兰指数并绘制散点图,如图2所示。微博数量分布的莫兰指数为0.031,结合散点图分布和莫兰指数值,表明微博的数量分布在一定程度上具有正向的空间自相关性,存在空间聚集的现象。典型如上海市、山东省和江苏省整体数量分布呈现出明显的高高聚集的趋势,说明东部沿海地区等经济较为发达的地区网络使用的聚集性较高(丁志伟等,2022),这也是这些地区对“赋红码”事件的关注度更高的原因。新疆维吾尔自治区、西藏自治区、贵州省等地区由于经济发展、信息化水平等自身条件相对较弱,互联网综合设施发展较慢,整体对网络舆论的关注度较低。北京市和河南省虽然微博数量较大,但聚集效果不够显著,是因为其邻近的山东省、河北省和江苏省的数量位于100—500条区间,与北京市和河南省1000条左右的数量差距较大,无法形成高高聚集的态势。
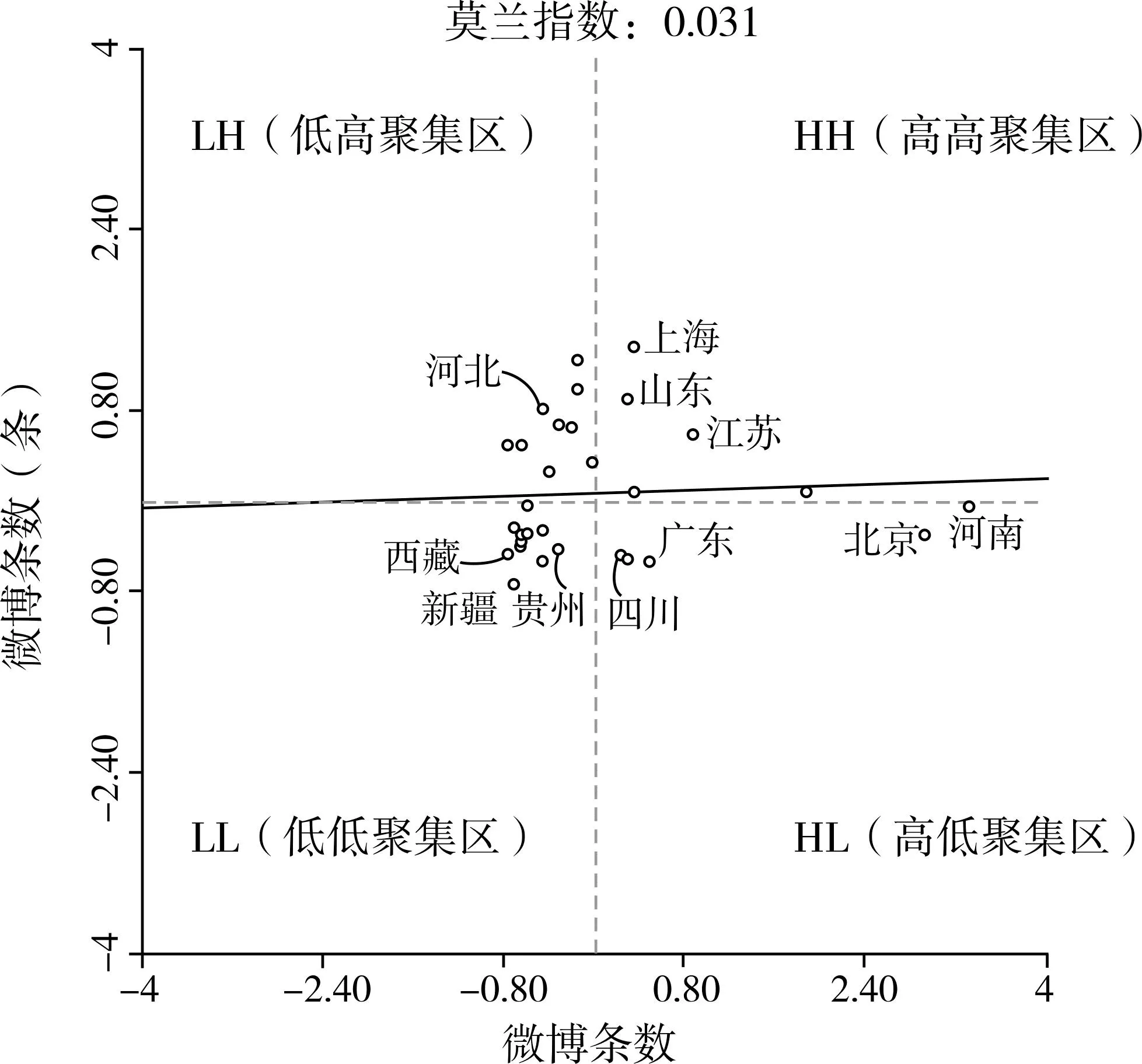
图2 微博数量的莫兰散点图
(三)“赋红码”事件中公众舆情时序演化特征分析
1.演化阶段和传播趋势
依据“赋红码”事件过程中的政府和官方媒体信息发布,以及整个事件不同时期的公众参与度和传播效率差异,本研究以2022年6月13日为事件的开始节点,将事件发展划分为爆发期、第一段高峰期、停滞期、第二段高峰期以及衰亡期五个阶段(见图3),分别观察在政府或者官方媒体发布信息后,微博相关主题内容的传播趋势和传播效力。
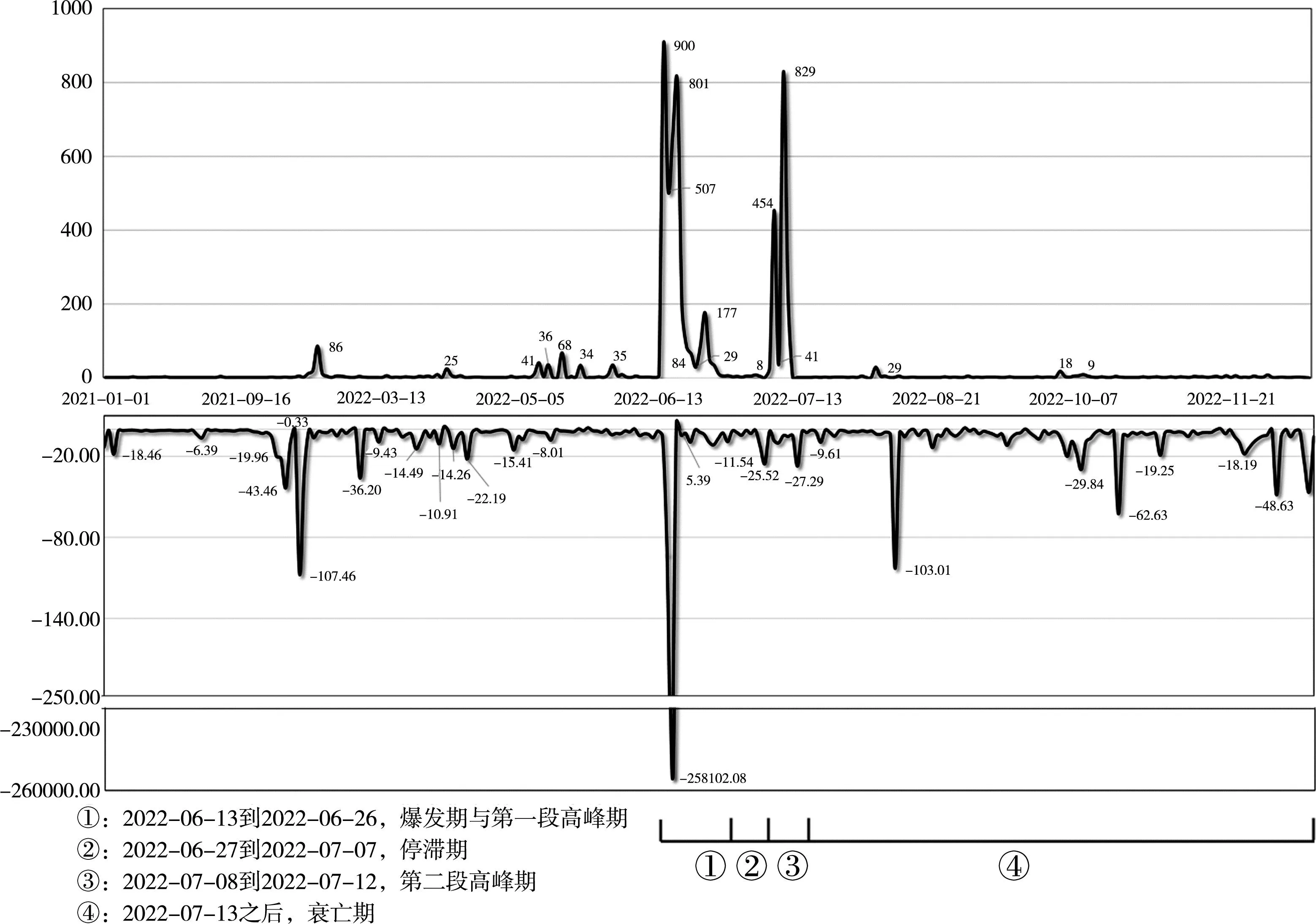
图3 微博数量和信任度的时间序列折线图
由于“赋红码”事件的爆发期较短,并很快进入了高峰期,因此本研究将两个阶段合并讨论。爆发期与第一段高峰期,时间为2022年6月13日至26日,起因是6月13日有网友在微博上对“赋红码”事件发文,赋红码问题第一次进入微博网友视野,随即引发大量舆论关注,单日相关微博数量最高达到900条。可以看出,突发事件对形成网络舆论热点话题具有显著的驱动作用(刘自强等,2023),相对应的是这个阶段网友对该事件的情感值也达到了最低值,整个舆论对健康码的自动裁量结果呈现较为负面的反馈。6月22日,郑州市发布关于部分村镇银行储户被赋红码问题调查问责情况的通报,这样的官方机构回应更容易刺激网络舆情话题热度的快速提升(刘自强等,2023),再次引发了6月23日一波较小的讨论波峰。
第二阶段为停滞期,时间是2022年6月27日至7月7日,该阶段赋红码相关微博数量增长缓慢,综合情感值虽还处于负向的状态,但相对平稳,民众并没有出现极端负面情绪。
第三阶段为二次爆发期,时间为2022年7月8日到7月12日。7月8日人民网在微博发布了一篇名为《又现赋红码,河南怎么啦?》的帖子,该帖子的转发量、评论量和点赞量分别达到了5.2万、1.2万和12.2万,官方媒体的回应导致有关“赋红码”事件的热度急剧上升(马续补等,2020)。虽然微博数量接近于第一阶段,但不同的是,此阶段公众的情感值并没有出现骤然下降。一方面,由于2022年7月8日郑州市大数据管理局进行了官方回应,称由于系统升级过程中出现的技术问题,导致健康码异常,并称在晚上8时已经恢复正常;另一方面,2022年7月11日,河南省地方金融监管局发布公告表示,会对无法兑付的客户本金开展先行垫付工作。无论是政府的回应速度还是解决问题的有效性都较第一次爆发期显著提升,因此公众的情感波动较小,没有产生剧烈的下降。
第四阶段为衰亡期,时间为2022年7月13日之后。在经过短暂的二次爆发期后,相关微博数量进入平稳状态,每日数量基本在20条左右徘徊,这一事件的讨论热度逐渐下降。
2.不同阶段的主题演化分析
本研究利用LDA算法对“赋红码”事件的不同阶段进行了主题分析,结果如图4所示。
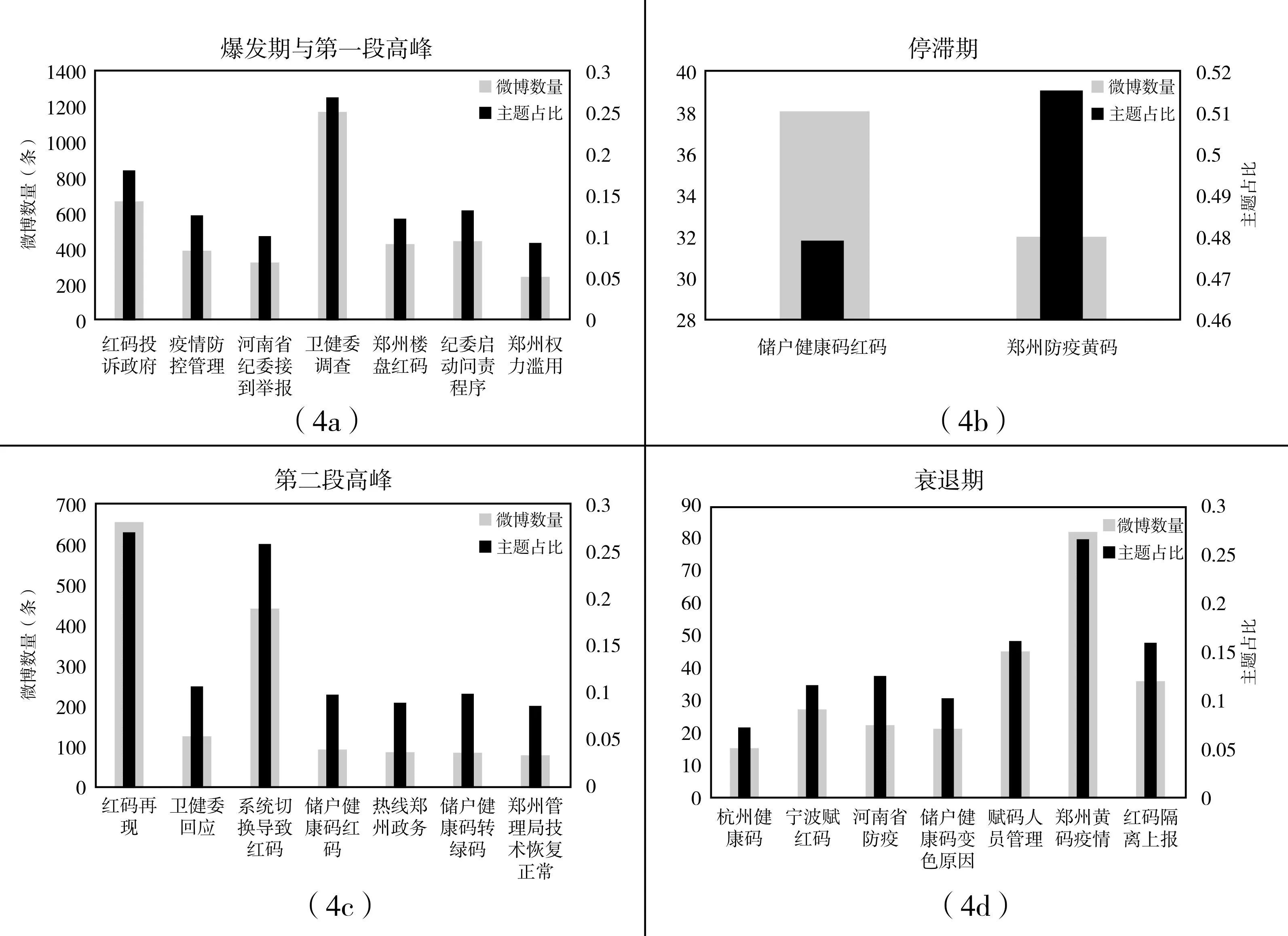
图4 各阶段微博内容聚类分析结果
爆发期与第一阶段高峰期的舆情可聚类为7个主题。其中,卫健委的调查行为和调查结果受到了最多网友的关注,是对舆情事件较为宏观的讨论(曹树金、岳文玉,2020)。此外,占比第二高的主题是民众向政府进行投诉的讨论,反映出民众权利意识的日益增强(张博,2016),通过投诉的方式达到与政府主动交流的目的。
第二阶段虽然舆情暂时处于停滞期,但民众主题的焦点会关注到一些相关的衍生话题,产生涟漪效应(丁乐蓉、李阳,2023)。从侧面体现公众在“赋红码”事件后对地方政府基于算法的自动裁量行为产生了消极情感态度,对算法风险的恐惧等负面情绪远超过对算法带来便利的正面感知,对政府的自动化裁量行为的评价较为负面。
在第三阶段,舆论主要关注的是红码再现和系统切换导致红码两个主题,一个是对红码再次出现这一现象的讨论,关注度最高;一个是对政府回应结果的讨论。从两个讨论主题可以看出,在第三阶段,地方政府针对“赋红码”的回应是非常迅速的,民众对问题本身的讨论和对政府解决方法的讨论几乎在同一时间发生,说明政府风险沟通的及时性和有效性直接影响了舆论传播的特征。既有研究也指出,政府在面对突发公共事件处理网络舆论时,及时透明的信息有助于负面舆情的减弱(胡象明、刘腾,2023)。
在第四阶段,舆论对“赋红码”事件本身的讨论占比下降,关注焦点转移至其他地区的健康码赋码使用的讨论,说明在舆论衰退期,容易产生与原始事件相关度不大的衍生话题(陈婷等,2016)。但从内容主题来看,公众认识到算法权力的滥用会侵害公民个人的权利,使公民对自动化裁量持更加谨慎的态度,更关注不同地区的健康码判定的规范性。
(四)风险沟通中多主体异质性分析
1.不同主体的演化特征分析
本研究选取了新浪微博中的五大类用户作为研究对象,即普通公众、意见领袖、行业专家、新闻媒体和政府机构。普通公众是指非认证的个人微博账号,包括所有在微博上进行发言的个人网友;意见领袖是指粉丝数量超过1万人、具有一定关注度和活跃度的个人账号(栾轶玫、张雅琦,2020);行业专家指微博认证的律师、法官等在某一行业较为权威的个人账号;新闻媒体是指官方注册的具有新闻媒体资质的账号,如人民网、新华网等;政府机构是指政府的官方账号,如郑州发布等。普通公众、意见领袖和行业专家皆为自然人账号,新闻媒体和政府为机构账号。
从发文数量上来看(见图5),所有用户都对“赋红码”事件投入了相当的关注度,不同主体发文量随着时间总体变化趋势是一致的。值得注意的是,普通公众的微博数量最多,单日发博量将近900条,是网络讨论的主体;意见领袖对这一事件的关注度也较高,意见领袖与公众的关注通常是呈现高度相关性(汪翩翩等,2020)。此外,政府机构作为政府官方发言渠道,会考虑到政府官方发言会对社会公众产生一定的引导作用(师硕、王国华,2022)。
从情感值变化来看(见图5),“赋红码”事件后各主体均产生了较为负面的感知,特别在第一阶段,负面情感的绝对值为前期的5000倍左右。具体来看,事件中负面情感最严重的是意见领袖,其负面情感值约为官方媒体的2000倍,是负面情感的主要来源,在舆情演变和治理过程中发挥着重要的舆论引导和推动作用(刘迪、张会来,2020)。普通公众在事件中的舆论则较为温和,相比意见领袖,其负面情感的波动并不剧烈。行业专家和新闻媒体则从更专业的角度对“赋红码”事件涉及的算法风险进行了探究,呈现出正向的情感值,显示了主流专家和媒体对政府健康码的自动化裁量持积极的态度,传达出此次“赋红码”事件归因于算法代理人的看法,可以通过解决算法应用中的委托-代理问题来进行治理,有助于化解普通公众的部分负面情绪(赵晨阳等,2021)。
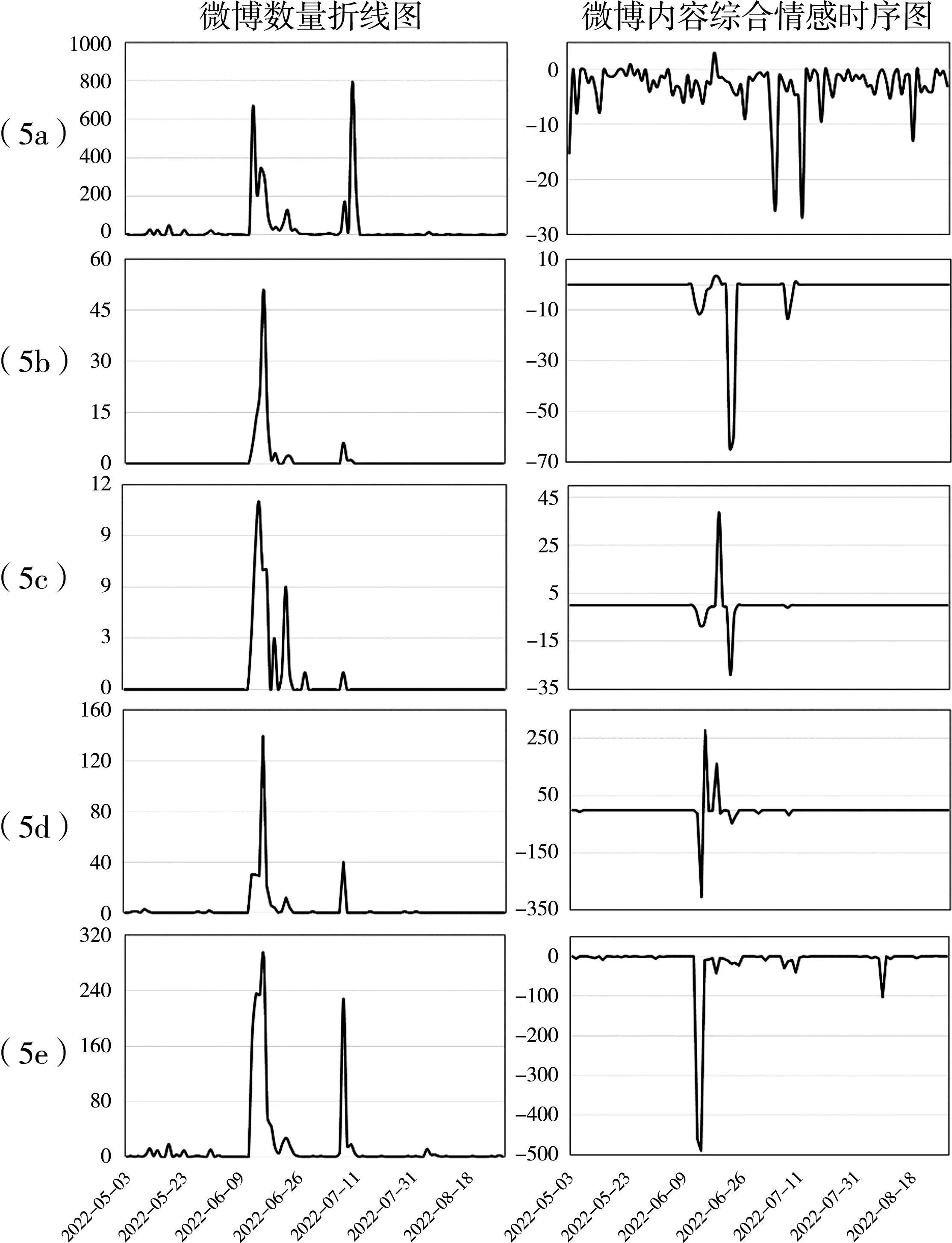
图5 不同主体的微博数量和综合情感值的时序演化
2.不同主体的话语特征分析
第一,不同主体的词汇密度比较。为有效比较各主体的组间差异,本研究对各主体的词汇总数、频次、句子总数等方面进行数据测量,进而获得不同主体的微博文本的词汇密度。本研究同时采用Ure和Halliday的测量方法,分别计算各行业的词汇密度,统计数据如表1所示。

表1 不同主体微博内容词汇密度及多样性
第二,不同主体的词汇多样性比较。从分析结果可以看出,普通公众的词汇变化性最大,说明文本内容的异质性最强;政府机构的微博文本内容词汇变化性最小,说明内容一致性最强,这与不同主体的发言特征相一致。普通公众对“赋红码”事件有着高度异质性的表达,不同的观点、态度和视角都在网络空间碰撞,是社交媒体平台的信息扩散者和讨论推动者。政府机构账号作为政府部门在微博上的直接发言渠道,其微博内容代表政府对“赋红码”事件的官方态度,不附加任何的评论和解释。行业专家、意见领袖和新闻媒体三个主体的异质性介于政府和公众之间,其中行业专家发表意见的异质性位居第二,体现了专家群体对该事件也呈现出较为异质性的观点,对行政裁量中的算法权力与算法风险的认识尚不统一。
3.不同主体关注焦点的聚类分析
本研究使用k-means算法对不同主体的微博内容进行聚类分析,获得主题词和含有主题词的观点,归纳不同主体的舆论焦点(见表2)。各主体共同关注的焦点为“赋红码”事件的处理办法;同时,政府机构和意见领袖共同关注到了算法权力滥用的问题,希望地方政府对公众有关算法的决策和运用给出具体解释,政府机构独特的政治背景和意见领袖自我的观点输出都能有效引导舆情发展方向(赵晨阳等,2021);此外,政府机构和新闻媒体聚焦于算法嵌入行政裁量的风险,如健康码数据库信息泄漏的问题,意识到“赋红码”事件并非孤立的,本质是算法带来的风险问题;政府机构、新闻媒体与意见领袖的焦点一致性说明了以政府机构和传统媒体为代表的官方话语,与以普通大众和精英个体为代表的民间话语逐渐走出了“对抗”角色(何舟、陈先红,2010),两种话语空间开始逐渐产生交叠,这一结果也印证了汪翩翩等(2020)的舆情研究。
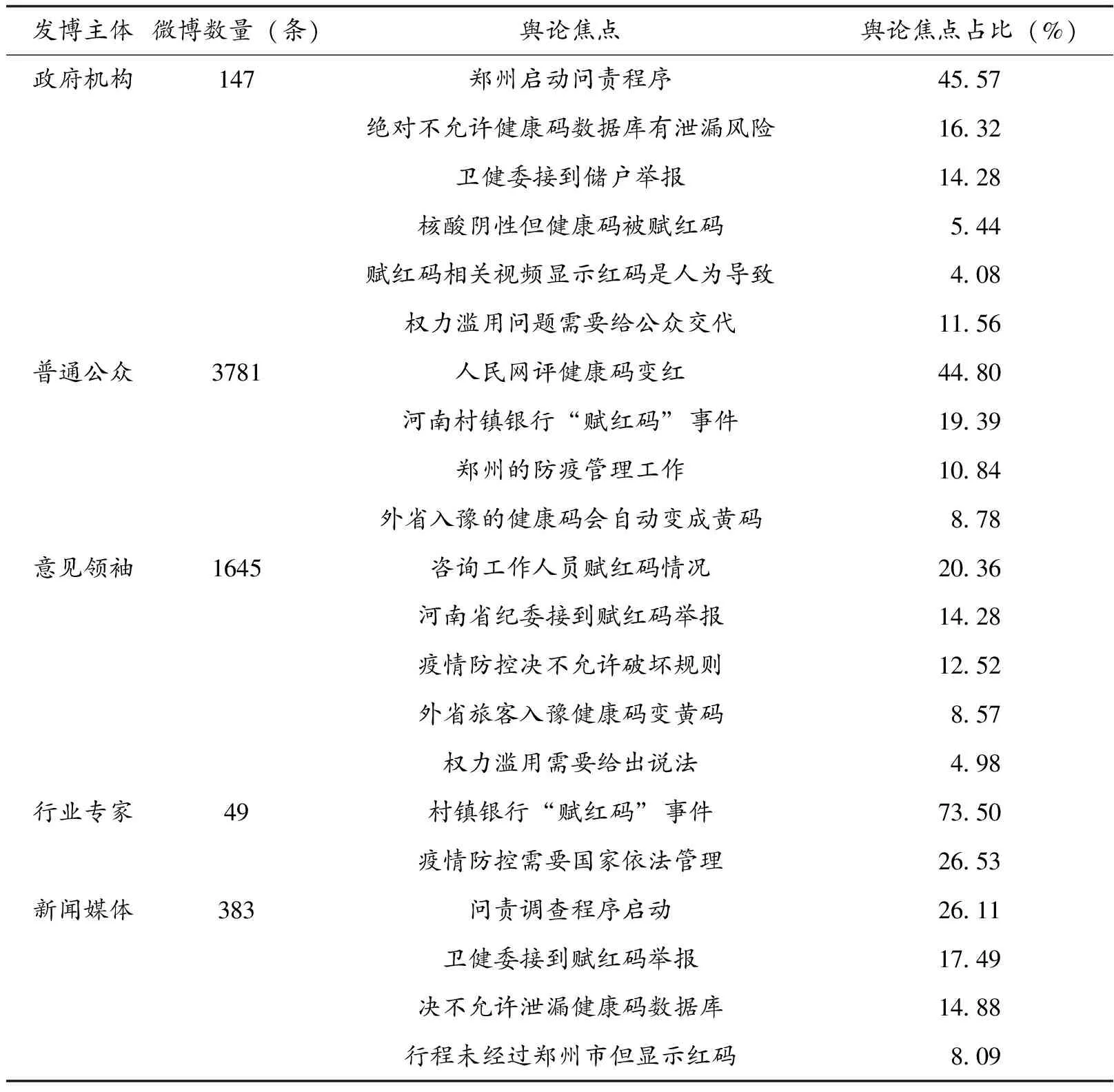
表2 不同主体舆论焦点的聚类分析
五、研究结论与政策建议
随着自动化行政裁量的应用越来越广泛和多元,在政府的行政授权与公民的权利让渡双重作用下,导致算法权力扩张、异变、寻租等风险。本文针对具有典型性的“赋红码”事件,利用大数据、自然语言处理、空间分析相结合的方法对网络舆论进行分析,探究公众在该事件背景下算法风险感知的特征及动态演化的过程。本文主要发现如下。
首先,公众对算法风险高度敏感。两次“赋红码”事件于网络曝光后,舆论都在24小时内迅速发酵,关注量剧增。对于可能侵害到自身基本权利的算法风险,公众展现出高度的敏感性。但两次“赋红码”事件的舆论情感值差异较大,第一次出现了情绪的低谷,而第二次的负面情绪波动相对平稳。细分至不同主体,意见领袖的情感值最为负面,是引领负面情绪的关键主体。反之,专家和媒体在过程中则呈现出正面的情感。从空间角度看,网络舆论具有高度的空间聚集性,除了事件发源地河南,北京和东部沿海等经济发达地区对该事件的关注度也更聚集。从时间角度看,事件发展可划分为五个阶段,公众关注的主题也发生了演化。不同主体关注的主题有显著的差异,普通公众更加关注事件的问责,政府和媒体则聚焦于权力滥用,意见领袖则关注到地方政府对算法的授权。
其次,对比其他舆论事件产生的风险感知。本研究发现,算法风险与其他舆论事件产生风险感知具有显著差异。一是覆盖范围更广泛。传统舆论事件具有显著的区域聚集效应,一般事件当地舆论较为集中,随着距离增加呈衰减趋势(刘耀辉等,2022)。本研究的结果发现,算法风险事件的覆盖范围远超传统风险事件,并且不随空间距离衰减。二是影响更深入。算法权力是行政权力的延伸,因此算法风险带来的权利侵害相比于其他风险具有更大威胁,引发的算法风险感知也更加强烈。三是较强的隐蔽性。面对算法“黑箱”,民众很难对算法背后机制进行透视。以“赋红码”事件为例,许多上访公民开始在健康码变红时并未发现问题,以为是因为轨迹重合存在健康风险。后来舆论曝光才逐渐发现健康码存在问题,此时该问题已经隐蔽地存在了一段时间。四是风险归因模糊。传统行政权力有明确的赋权机制,权责对应,责任主体清晰。而算法权力则因为人机深度绑定,无法准确归因(Zhai et al.,2023)。以“赋红码”事件为例,关于归因引发大量的舆论争论。
从“赋红码”事件全国微博数据的分析挖掘,我们可以看出,政府在算法风险治理方面依然面临较大挑战。首先,行政裁量中算法权力的边界尚不清晰。算法权力来自于政府的行政赋权与公民的权利让渡,在这一过程中公私“权力-权利”的边界被重塑。旧的边界已被打破,而新的边界无论是明确的法律法规还是隐性的社会规范都尚未建立,容易出现个人主体性的丧失和正当的法律程序被架空的风险(赵宏,2023)。其次,自动化行政裁量中的委托-代理关系很可能导致道德风险和权力寻租(廖晓明、徐文锦,2021)。而算法“黑箱”问题的存在,加剧了算法代理者的道德风险和权力寻租问题。“赋红码”事件就是典型的案例,本应用于防疫的健康码被地方政府中少数代理人滥用,产生严重的负面后果。如果算法的委托-代理问题得不到很好的治理,代理人的道德风险问题仍会不断重演。最后,关于算法风险的沟通仍需进一步优化。从两次“赋红码”的舆情演化来看,虽然关注度和讨论量相接近,但是第一次“赋红码”的负面情感波动较为剧烈,而第二次则显著平缓。因为政府在第二次“赋红码”问题出现当天就与公众进行了风险沟通,公示了问题原因及处理结果。由此可见,政府作为信息的发布者,及时向公众传播真实且有效的信息是正确的风险沟通方式,可以提升公众信任,避免消极态度的产生(丁博岩等,2023)。
本文以“赋红码”事件为典型案例,利用微博大数据探索公众对自动化行政裁量中算法的风险感知,对算法风险的研究方法和系统认知具有理论贡献。同时,研究结论对行政裁量中的算法风险治理也提出了具体的政策建议,为政府在算法风险治理上提供了一定的数据支持,具有较强的实践意义。本文的主要局限在于,现有大数据文本分析仍停留在算法风险感知的时间、空间、异质性等特征描述上,而对算法风险的产生机制与治理逻辑无法进行深入的分析。这是本文的不足之处,也是下一步主要的研究工作。
猜你喜欢
党的生活(江苏)(2021年4期)2021-06-04
法律方法(2021年4期)2021-03-16
党的生活(江苏)(2020年10期)2020-11-26
党的生活(江苏)(2020年9期)2020-11-07
World Journal of Stem Cells(2020年8期)2020-09-18
党的生活(江苏)(2020年6期)2020-08-27
电影(2019年6期)2019-09-02
劳动保护(2018年8期)2018-09-12
博客天下(2015年12期)2015-09-23
清风(2014年10期)2014-09-08
