
自动飞行员复诵指令生成方法研究
2024-02-29 06:28:40潘卫军蒋培元李煜琨王腾陈宽明
科学技术与工程 2024年4期
潘卫军, 蒋培元, 李煜琨, 王腾, 陈宽明
(中国民用航空飞行学院空中交通管理学院, 广汉 618307)
国际民航组织指出,2025年以后,空中交通流量预计将以每年3%~6%的速度增长[1],因此,对空中交通管制员(air traffic controllers, ATCO)的需求也将逐年增加。空中交通管制员通过甚高频无线电向飞行员发出管制指令来实现对空中交通的管理。根据空中交通管制(air traffic control, ATC)中安全和可靠性规定,收到指令的飞行员必须要对管制指令进行正确快速的复诵以确保飞行员正确理解了管制员发出的指令[2]。对于管制人员而言,ATCO需要完成相应的基础课程以及模拟设备方面的实训才能获得在真实ATC场景下的工作资质。中国管制模拟机培训设置了两个席位,管制培训席位以及飞行员席位。完成一次管制员培训,需要一名专职人员来控制飞行员席位实现管制指令的复诵和响应,这会产生额外的培训成本(包括设备和人员成本)。针对此问题,人工智能技术的发展和应用为解决此问题提供了可能[3-5]。在外国,研究人员的侧重点主要是使用深度学习技术来构建智能系统来辅助ATCO工作。欧盟(European Union, EU)为了减少ATCO的工作量,将语音识别技术应用于空中交通管制中以减少ATCO的工作量[6],提高工作效率[7-8]。Helmke等[9]通过人工智能技术实现了管制员辅助决策系统的构建,缓解ATCO人员的工作压力。然而,这些智能系统对语音识别系统的识别准确率要求较高。一般而言,其识别的词错误率要低于5%才能满足实际应用需求[10]。相较于外国,中国学者主要从管制员培训环节出发,致力于使用人工智能技术提高管制员的培训效率和专业水平,从源头降低错误的产生。陈亚青等[11]基于统计学习技术,采用模版匹配的方法构建了一套模拟机长培训系统来替代机长席位,为自动飞行员研究打下了基础。钟如秀[12]基于科大讯飞语音识别引擎实现了智能管制模拟机自动飞行员系统的设计,结果表明:该系统可以替代模拟机中的飞行员席位,能较好地提升管制学员培训质量。为了促进使用计算机代替人工飞行员席位进行指令应答,黎兰[13]提出了改进的序列到序列(sequence-to-sequence, Seq2Seq)陆空通话对话模型,实验结果表明,复诵指令生成的准确率可以达到93%。Zhang等[14]采用多任务学习来优化深度神经网络模型,实现了管制复诵指令的生成,其复诵准确率为97.19%。然而,上述研究采用的模型较为传统,其模型性能在当前已经进入了瓶颈阶段,进一步打破瓶颈,推动本领域发展迫在眉睫。鉴于此,构建高性能深度学习模型来实现自动飞行员复诵指令的生成,针对中外研究的不足,通过对基于Transformer以及Seq2Seq架构的大规模预训练语言模型进行微调,实现飞行员复诵指令的生成。基于此,为保证模型复杂度处于一定范围同时提高模型准确率,使用集成学习策略来改进模型,实现模型性能的提升。最后,为促进本领域相关工作进展,提出一种新的评价标准来衡量复诵指令生成的质量,该评价标准可在模型的改进方面为研究者提供有价值的参考。
1 相关工作
当前,ATCO培训主要依赖于管制模拟机,具体的培训流程如图1所示。在管制员模拟机培训中,采用智能计算机程序来取代飞行员席位,也即使用智能计算机程序来实现飞行员复诵指令的生成并对指令进行响应,可以有效降低培训成本,提高培训效率。如果将该程序集成到管制员培训系统中还可以克服培训地点这一限制,能够应对实际出勤的困境,提高ATCO培训设备的利用能力。使用人工智能技术来实现自动飞行员复诵指令的生成以及响应其核心技术包括:语音识别(automatic speech recognition, ASR)、管制指令理解(controlling instruction understanding, CIU)、信息抽取(information extraction, IE)、飞行员复诵生成(pilot repetition generation, PRG)、语音合成(text to speech, TTS)以及人机交互技术[15]。其技术框架流程图如图2所示。
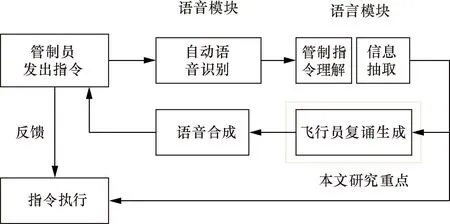
图2 自动飞行员复诵指令生成技术流程图Fig.2 Automatic pilot repetitive instruction generation technology workflow diagram
为了研究自动飞行员系统,首先要对飞行员复诵指令进行深入了解。飞行员复诵指令的一般特征为:①复诵指令文本长度一般小于管制指令文本长度,对于强制性管制指令,其复诵指令要与管制指令含义保持一致;②持续性对话次数少(符合人机对话中属于单轮对话特点)。基于上述特点,可将飞行员复诵指令生成从人机对话任务转化为文本摘要生成任务来处理。当前阶段,文本摘要技术按摘要生成方法分为提取式摘要和生成式摘要[16]。提取式摘要根据词语的重要性来提取关键词,形成摘要。但它只考虑词语的词频,而不考虑句子的语义信息,这导致生成的句子连贯性较差。生成式摘要则通过释义和同义替换来总结句子的重要信息,与提取摘要相比,生成摘要具有更好的表示能力,能够理解句子的上下文语义。在自动文本摘要的任务中,由于输入和输出都是文本序列,这要求模型要更加关注生成句子的语义信息和句子连贯性之间的关系[17]。
长期以来,由于基于统计学的方法在文本表示、理解和生成能力方面的局限性,自动文本摘要的发展缓慢[18]。随着神经网络理论和技术的不断改进,深度学习在许多任务上实现了最优的效果[19-22],尤其是基于编码器-解码器架构的自动文本摘要模型出现之后,基于深度学习的自动文本摘要迎来了新的发展[23]。在当前的背景下,随着序列到序列框架的进步,生成式模型往往优于提取式模型[24]。
对于生成式摘要的研究大多是关于序列到序列的编码器-解码器结构,通过添加各种注意机制、指针生成机制和覆盖机制,或者用卷积神经网络代替循环神经网络来解决摘要生成过程中的各种问题。Rush等[25]第一次在Seq2Seq模型上使用注意力机制来解决标题生成问题。为了进一步提高模型的性能,Nallapati 等[26]提出了指针生成器模型来成功处理词汇量不足(out of vocabulary, OOV)的单词。该模型之后又通过使用覆盖机制[27]进行了改进。由于先前的Seq2Seq架构中的编码器、解码器是由卷积神经网络或递归神经网络来充当,因此这些架构的特征提取能力远不如Transformer模型。基于自注意力架构的Transformer的出现,开启了自然语言处理的新纪元,它确保模型能够学习到更深的语言逻辑和单词的语义信息。相应的模型如BERT (bidirectional encoder representations from transformers) 模型[28]及其变体Roberta (a robustly optimized BERT pretraining approach)模型、GPT-2 (generative pre-trained transformer 2) 模型[29]、BART (bidirectional and auto-regressive transformers) 模型、T5 (text-to-text transfer transformer) 模型等。BERT使用单词的上下文来预测单词,而GPT-2通过前文的单词来预测下文的单词。因此,BERT适合于自然语言理解任务,GPT-2更适合于自然语言生成(natural language generation, NLG)任务。受启发于BERT和GPT-2,BART模型融合二者优点,这使得它比BERT更适合文本生成的场景,相比GPT-2也多了双向上下文语境信息,在生成任务上取得了最优的效果[30]。Google Brain团队设计出一个基于prompt策略的预训练语言模型T5[31],该策略通过引导模型在预训练阶段学到的特定任务相关知识,来降低微调的难度,减少训练时间,使得模型性能得更好的发挥。
2 复诵指令生成的挑战与本文工作
2.1 挑战
(1)随着深度学习模型参数的增加,对于监督学习,需要用大量的数据训练性能优越的模型。在空中交通管制领域,由于数据的保密性,数据的获取非常困难。此外,获得的原始ATC语音数据必须经过专业人员标记后才能使用,使得标注的成本变的昂贵。这使得深度学习技术在该领域的应用和发展带来了很大的挑战。
(2)飞行员复诵指令生成任务既属于摘要生成任务又属于对话响应生成,如何构建合适的模型来适应飞行员复诵指令生成任务是一个难点。
(3)当前常用的评估文本生成质量的方法不能很好地适应飞行员复诵指令生成任务,急需构建一种用于评价飞行员复诵指令生成质量的标准。
(4)在空中交通管制工作中,安全是最重要的考量。因此,评估模型性能的首要标准是模型的准确率。尽管当前基于Transformer架构的大规模预训练语言模型在许多领域都表现出色,但在管制领域的应用中,其性能仍然无法满足实际需求。因此,如何进一步提升模型的性能,且不增加模型的复杂度是需要解决的关键问题。
2.2 本文工作
针对2.1节(1),采用迁移学习的方法,先将模型在其他领域数据上进行训练再应用到本领域进行微调来达到复诵指令生成的目的。针对2.1节(2),NLG任务中又包含神经机器翻译(neural machine translation, NMT)、文本摘要和对话响应生成[32],这三项任务的共同点在于输入和输出都是文本序列,除此之外,相互间又有区别。文本摘要和机器翻译的区别在于,在文本摘要中,生成的摘要通常非常短,不受原文长度的影响。此外,摘要生成的一个关键点是以有损失的方式压缩源文本并保留关键概念,这与机器翻译要求的无损相违背[33]。对话响应生成和文本摘要的区别在于,对话响应生成的文本上下具有逻辑性,对于生成结果的质量,目前没有统一的评判标准[34]。文本摘要中的原文本和生成的摘要文本在语义上要求一致的且摘要长度一般小于源文本的长度[35]。飞行员复诵指令文本生成是一种特殊的NLG任务,既属于对话响应生成任务、又属于文本生成任务。对于一些询问性指令(如收到请回答),其复诵指令的性质属于对话,前后文具有逻辑关系;但大多数管制指令属于强制性指令,其复诵指令的性质属于摘要生成任务,前后文含义保持一致。基于上述飞行员复诵指令文本生成任务的特点,采用摘要生成任务中的预训练模型进行微调的策略来进行飞行员复诵指令的生成是合适的。针对2.1节(3),为实现详细的对生成结果进行评价,首先构建了管制指令文本词典,借助分词工具,对生成的指令文本按粗细粒度信息进行了分割,用于后续指标的计算。考虑到管制指令的特殊性,提出了一种新的评价标准来评估生成的复诵指令文本的质量,该标准比传统的ROUGE(recall-oriented understudy for gisting evaluation)评价标准能更加精确地反映模型的性能。针对2.1节(4),为了实现不增加模型复杂度同时提高模型的性能,采用了机器学习中的集成学习策略。选取4个基础模型构建集成学习模型,将管制指令数据集调整为4个数量不变但内容不同的训练集,每个基础模型在不同类别的训练集上进行训练以确保各基础模型能够学习到不同的文本处理能力。将训练好的4个模型进行装袋,最终输出结果采用基于准确率的加权投票策略。实现了利用多个模型的优势,提高模型的准确率同时避免模型复杂度增加的目的。
2.3 集成学习策略
集成学习是一种机器学习方法,旨在通过结合多个模型的预测结果来提高预测准确度和泛化能力。该方法使用各种投票机制融合不同基础模型的预测结果,从而得到比单个基础模型更准确且模型复杂度不增加的集成模型[36]。图3展示了模型复杂度和误差之间的关系。可以看出,在开始阶段模型的总误差一直在下降,直到达到底部,然后随着模型复杂度的增加而迅速上升。
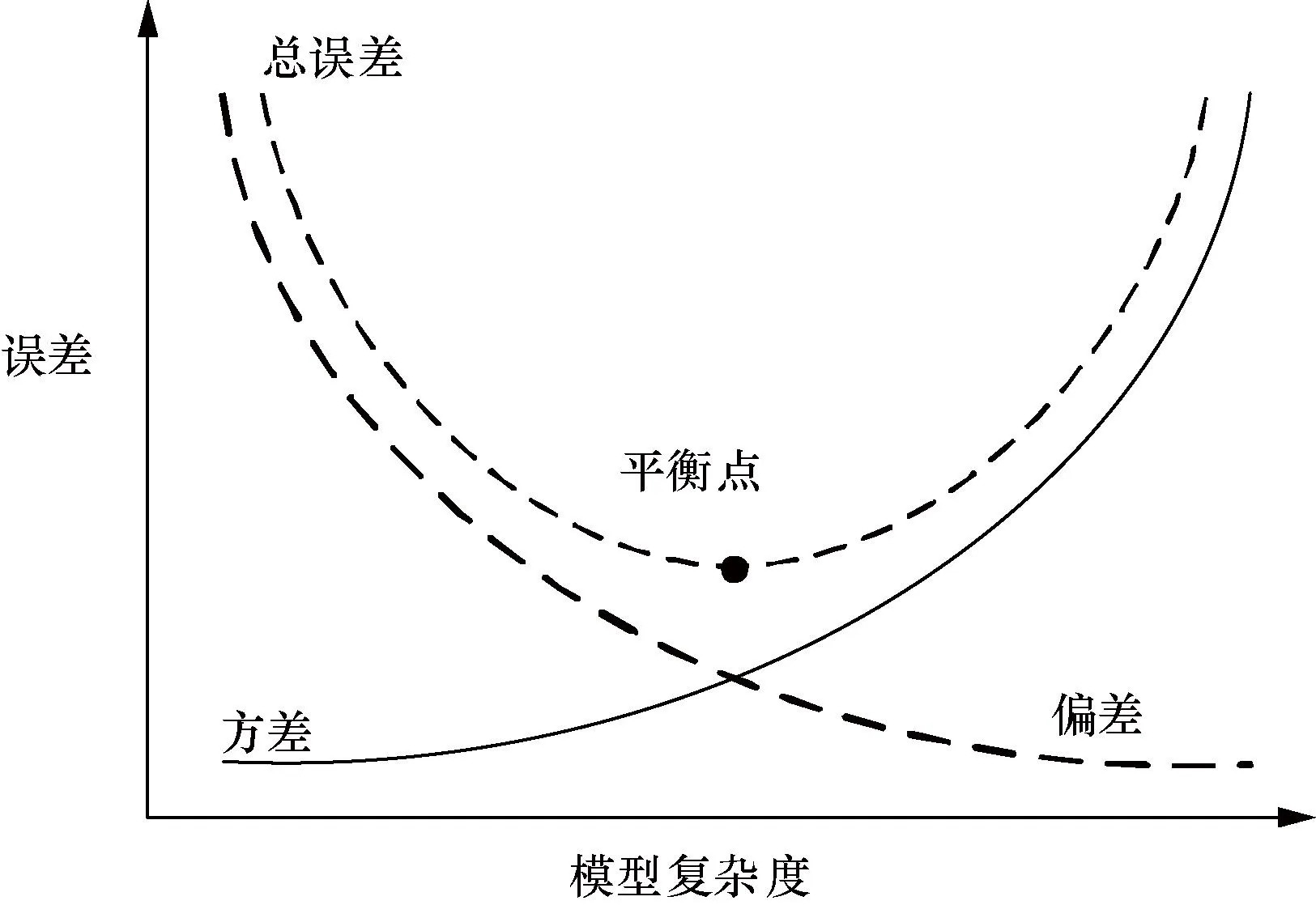
图3 学习曲线和模型复杂之间的关系Fig.3 Direct relationship between learning curve and model complexity
目前,基于Transformer架构的预训练语言模型参数量已达到亿的级别,模型的复杂度达到了较高水平。因此,进一步提高基础模型的复杂度并性价比不高。集成学习的目标是将不同的模型算法无缝集成到一个统一的框架中,以便有效利用每种算法的互补信息,提高性能的同时确保了模型的复杂度处于稳定水平[37]。常用的集成分类方法包括Bagging、AdaBoost、随机森林、随机子空间和梯度增强[38-40]。在飞行员复诵指令生成任务中,使用Bagging集成分类方法进行集成学习模型的构建。图4说明了典型的Bagging集成分类模型的主要思想,该模型由两个步骤组成:①使用多个弱分类器生成结果;②将多个结果集成到一致性函数中,以使用投票方案获得最终结果。其中投票可以是简单的多数表决,也可以是加权投票。这里采用基于准确率的加权投票方式,对每个基础模型的预测结果按照它们的准确率权重进行加权投票。

图4 集成学习模型架构Fig.4 Integrated learning model architecture
对于飞行员复诵指令生成任务而言,对于强制性复诵指令是有标准答案的,因此可以将复诵结果看作字符串,从分类问题的角度进行投票处理。具体投票过程如下。
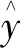
(1)
式(1)中:k=0,1,2,3分别为字符串str0、str1、str2、str3类别,这4个类别的内容可以相同;(yi=k)为指示函数,当yi=k时为1,否则为0;wi为第i个分类器的权重,其计算公式为
(2)
式(2)中:Accui为第i个分类器的准确率。
3 实验验证
3.1 实验数据
本实验依托国家重点研发计划项目中构建的真实陆空通话数据集,其中数据中包含少量管制指令对应的飞行员复诵文本。飞行员复诵文本为实验室人员,基于《空中交通无线电通话用语》(MH/T 4014—2003)标注。最终,得到经预处理后的指令文本数据共11 049对,并将数据集划分为3个子集,其中8 949对用于训练,995对用于验证,1 105对用于测试。其数据涵盖塔台、进近及区调对话,能较好地反映ATC领域中的陆空通话数据分布。表1为摘录数据集中的部分数据实例。
3.2 评价标准
ROUGE通过计算生成摘要和参考摘要之间的重叠单元(如n-grams、单词序列和单词对)来衡量摘要质量[41],该评价标准已经被广泛用于自动摘要生成任务的评估中。其中,ROUGE-1和ROUGE-2作为评估信息性的手段,最长ROUGE-L作为评估流畅性的手段[42]。ROUGE-1和ROUGE-2得分已被证明是最符合人类的判断评估指标。
ROUGE-N的计算公式为
(3)
式(3)中:下标N常取1、2;n为n-grams的长度;Ref为参考摘要的集合;S为参考摘要中的n-gram集合;式(3)中,分子表示生成摘要中的n-grams在参考摘要中出现的次数之和,分母表示参考摘要中的n-grams的总数;Co,match(gn) 为生成摘要和对应的参考摘要中同时出现的n-gram的最大数量;Co(gn) 为参考摘要中的n-gram 数量。
ROUGE-L的计算公式为
(4)
(5)
(6)
式中:LCS为最长公共子序列;len为序列的长度;C为标准序列;S为生成序列;RLCS为召回率;PLCS为精确率;FLCS为ROUGE-L值;β为用于衡量召回率和精确率之间重要性的参数,一般β会设置为较大的值,此时FLCS会更加关注RLCS,β取1,表示准确率和召回率被同等看待。
由于本领域的特殊性,复诵指令必须完全正确才能记作一条合格的复诵指令。飞行员复诵指令要求在不丢失关键信息的情况下,根据ATC规则对管制指令进行响应。根据ATC规则[43],ATCO的指令必须以飞机识别号(aircraft identification, ACID)开始,以明确所通信航空器,而飞行员的指令则要以其ACID结束,以区分ATCO的指令。基于上述复诵指令的特点,仅使用ROUGE评价标准来衡量模型,不能全面的评价模型的性能。如在管制指令数据集中,管制员下达指令:东方五四两四, 由于冲突,加速上到六千九。参考复诵指令为:加速上到六千九,东方五四两四。分词工具分词后:东方五四两四/由于/冲突/加速/上/到/六千九;加速/上/到/六千九/东方五四两四。 当模型生成结果为“加速/上/到/六千九/由于/冲突/东方五四两四”时,使用ROUGE-N及ROUGE-L评价方法计算结果分别如表2、表3所示。但从飞行员复诵指令评价标准的角度来说,该复诵指令是正确的复诵。

表2 示例的ROUGE-1、ROUGE-2计算结果Table 2 Example ROUGE-1 and ROUGE-2 calculation results

表3 示例的ROUGE-LTable 3 Example ROUGE-L
由表2、表3结果可知,虽然ROUGE指标一定程度上可以反映模型性能,但不能更加精细化反映模型性能。因此,针对管制指令文本的特点以及复诵标准,引入针对本领域的一种新的评价标准,关键词评价标准,其评价指标包括:呼号准确率(call sign accuracy, CSA)、动作指令准确率 (action instruction accuracy, AIA)、参数准确率(parameter accuracy, PA)。最后,计算总准确率(total accuracy, TA)。只有当一个指令具有所有3个正确的子因子时,该复诵指令才能被视为正确的指令。具体指标的定义及计算公式如下。
(1)呼号由航空公司简称和航班号组成,呼号准确率计算公式为
(7)
(2)动作指令为ATC指令中的包含动作,如上升、下降、保持等,动作指令准确率计算公式为
(8)
(3)参数是指ATC指令的关键要素包括速度、高度、航向和航路点等指令动作的关键补充信息,参数准确率计算公式为
(9)
式中:N为待测样本的数量;g(i)、q(i) 、h(i)分别为呼号、动作指令和指令参数的特征函数,可表示为
(10)
式(10)中:predi=truthi是指示函数的条件,其中,predi为生成的第i条复诵指令中,呼号、动作参数的值;truthi为参考复诵指令中,呼号、动作参数的值,当二者完全对应匹配时,指示函数值为1,否则为0。
(4)总准确率为有效复诵指令占总的复诵指令的比值。只有当所有呼号、参数和指令动作都与基本事实相同时,该复诵指令才是有效的。总准确率的计算公式为
(11)
式(11)中:T(i)为总精确度的特征函数,其计算公式为
(12)
3.3 陆空通话语料库词典
为便于针对管制指令进行ROUGE评价以及关键词评价,基于收集的某地区空管局标注后的语音数据,参考《空中交通无线电通话用语》,使用Jieba分词工具构建了中文陆空通话分词词典。基于管制指令的结构特点,构建的词典包含:航空公司简称、数字、字母、高度、速度、航向、航路点、专有名词等内容,共计词汇量14 756个。其词汇实例分析如表4所示。

表4 词典实例分析Table 4 Analysis of dictionary case
3.4 实验配置及结果
实验室环境及配置如下:操作系统为Windows10,CPU采用E5-2680 V4@2.40 GHz,GPU为RTX 2080Ti,深度学习框架为Pytorch。各基础模型超参数设置如表5所示。

表5 基础模型超参数Table 5 Basic model hyperparameters
采用预训练加微调的策略来实现飞行员复诵指令的生成。使用10折交叉验证来评估各基础模型性能,各微调模型实验结果如表6、表7所示,集成学习模型试验结果如表8、表9所示。为了进一步增强对基于注意力机制模型的理解,选择一些测试样本来展示模型在生成任务过程中的注意力分布,图5、图6展示了T5模型在预测过程中的注意力分布。可以看出,模型能够较好地输出标准答案。
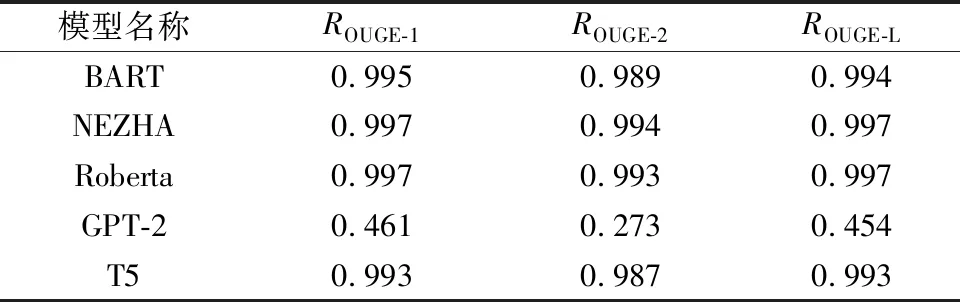
表6 各模型在管制指令文本数据集上的ROUGE得分Table 6 ROUGE scores of each model on the control instruction text data set
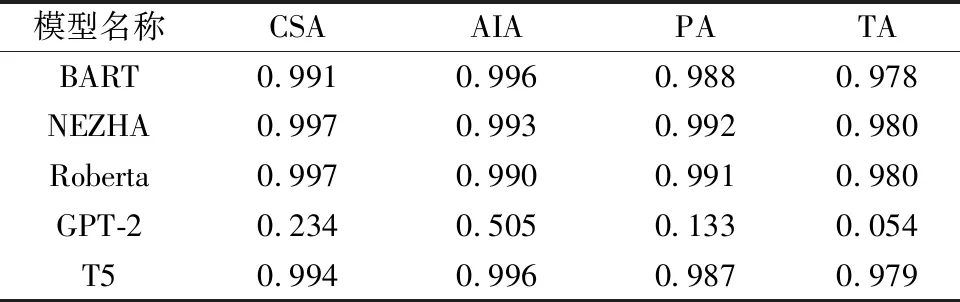
表7 各模型在管制指令文本数据集上的关键词准确率得分Table 7 Key word accuracy score of each model in control instruction text data set

表8 集成学习模型在管制指令文本数据集上的ROUGE得分Table 8 ROUGE scores of the integrated learning model on the regulatory instruction text dataset

表9 集成学习模型在管制指令文本数据集上的关键词准确率得分Table 9 Keyword accuracy scores of the integrated learning model on the regulatory instruction text dataset
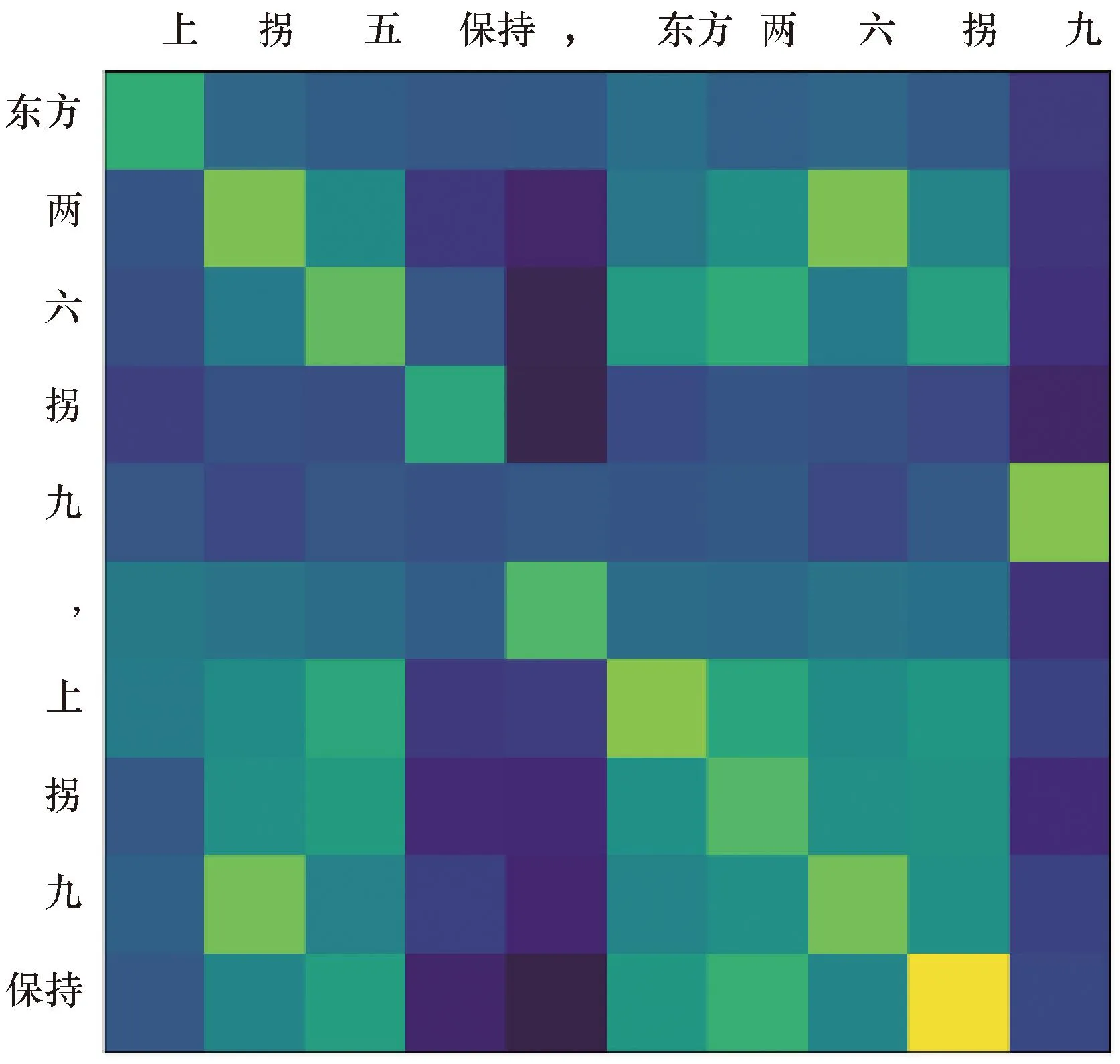
垂直轴表示输入的ATC指令文本;水平轴表示标准复诵结果;每一行色块表示对应步数的输出在标准结果词上的关联程度,颜色越亮,关联越深图5 高度调整指令注意力分布热力图Fig.5 Highly adjusted instruction attention distribution heatmap
由表6、表7可知,GPT-2模型在任务中表现最差,可能原因是GPT-2在进行预测时使用的是具有掩码的注意力机制,这导致模型产生输出时没有将后文的有用信息考虑进来,使得模型在处理输入与输出含义一致的文本生成任务时时效果不佳。而Roberta、T5、BART、Nezha模型则表现相当,这说明了提供双向信息有助于提高复诵生成的准确率。由表8、表9可知,基于加权的投票策略的集成学习模型性能优于不考虑权重仅考虑得票数的集成模型。
4 结论
(1)通过将机器学习中集成学习策略应用于深度学习中,实现了高质量的飞行员复诵指令生成。在管制指令文本数据集上,所采用的方法在飞行员复诵指令生成任务中取得了最先进的效果,模型在基于关键词的评价指标中,整体准确率达到0.987,并且对呼号复诵的准确率达到0.998。
(2)使用10折交叉验证对5个基础模型进行了性能评估。结果表明,基于Transformer解码器构建的预训练模型GPT-2在复诵指令生成任务中存在生成的结果随机性过大的缺点,其可能原因是GPT-2在预测时使用了具有掩码的注意力机制,导致模型在产生输出时不会考虑下文信息,因此在进行输入与输出含义一致的文本生成时表现出较差的性能。此外,基于Transformer架构的预训练语言模型NEZHA、Roberta、T5与基于Seq2Seq架构的预训练语言BART相比,都表现出较好的性能。表明这4个预训练语言模型能够很好地适应输入与输出含义一致的文本生成任务。
(3)目前,文本生成结果的评价标准主要基于ROUGE-N,ROUGE-L,然而,在ATC领域使用这种标准会导致评价结果的偏差,并且无法精细反映模型的性能。因此,针对管制指令的特点,提出一套基于关键词的评价指标体系。通过建立管制指令词典,实现对管制指令文本的分词,来对管制指令文本进行粗细颗粒度划分,最后对各关键词指标进行计算。结果表明,基于关键词的评价指标体系能够克服ROUGE评价方法中存在评价偏差,更全面地反映模型性能。
尽管目前的模型能够准确地完成对管制指令的复诵,但是在回答一些非复诵的指令时,模型仍然不够出色,这主要是由于数据多样性少以及模型本身存在的局限性导致。后续可对多模态数据融合技术以及构建复诵对话管理模块进行研究,以实现更好地非强制性复诵指令的生成。
猜你喜欢
科普童话·神秘大侦探(2023年1期)2023-05-30 12:48:10
小哥白尼(军事科学)(2021年7期)2021-11-20 06:14:48
军事文摘(2021年19期)2021-10-10 13:28:40
意林·全彩Color(2019年4期)2019-05-11 09:07:26
测控技术(2018年5期)2018-12-09 09:04:26
电子测试(2018年18期)2018-11-14 02:30:34
能源(2017年9期)2017-10-18 00:48:41
儿童故事画报·发现号趣味百科(2017年4期)2017-06-30 08:09:31
上海国资(2015年8期)2015-12-23 01:47:27
中共宁波市委党校学报(2014年4期)2014-03-01 01:48:32
