
基于主成分分析的果蝇算法优化支持向量机回归的红枣产量预测
2024-02-29 07:12:30李晋泽赵素娟李宁李俊成刘森马继东
科学技术与工程 2024年4期
李晋泽, 赵素娟, 李宁, 李俊成 , 刘森 , 马继东*
(1.东北林业大学机电工程学院, 哈尔滨 150040; 2.太原理工大学矿业工程学院, 太原 030024)
在中国发生新冠疫情以来,人们更倾向于选择有营养价值的水果来提高自身免疫力,而红枣内含有众多微量元素以及营养元素成为人们的首选,在后疫情时代红枣的重要性日渐明显,因此精准预测红枣的产量及变化趋势是迫在眉睫的。但由于气候、自然灾害、市场环境等一系列不可控因素的影响,红枣产量的预测具有极大的复杂性和不确定性。
目前产量预测方法主要包括时间序列分析法、回归分析法、灰色理论分析法以及神经网络等智能算法[1]。但单一预测模型所用的数学原理不同,且容易产生较大误差,因此以组合模型进行预测研究。李欣等[2]以灰色预测模型GM(1,1)、多元回归预测模型、时间序列预测模型为基础模型,分别对其赋予权重,得到组合预测模型。文彦飞等[3]利用萤火虫算法对支持向量机回归(support vector regression,SVR)以及长短时记忆神经网络(long short-term memory neural network,LSTM)进行参数寻优,构建组合预测模型。李鹏飞等[4]以陕西苹果产量为例,将反向传播(back propagation,BP)神经网络、移动平均自回归(autoregressive integrated moving average,ARIMA)和最小二乘支持向量回归(least squares support vector regression,LSSVR)模型分别赋予权重进行集成研究。范小虎等[5]将极限学习机(extreme learning machine, ELM)模型与SVR模型融合,最大限度地提升了武器系统剩余寿命预测的泛化能力。在人工神经网络方面,文献[6-7]使用神经网络对河南省的粮食产量进行预测。高心怡等[8]提出混合智能算法的支持向量机预测模型并以此来预测粮食产量。陈灿虎等[9]以BP神经网络为基础模型,利用差分进化改进灰狼算法,建立了粮食预测模型。杨培红等[10]为缓解停车难现象,建立了基于轻量级梯度提升机(light gradient boosting machine,LightGBM)-SVR-LSTM的停车区剩余车位预测模型,并用3种评估指标进行效果验证。路思恒等[11]以影响粮食产量的8个指标为基础,建立了基于云南省粮食产量预测的BP神经网络模型。廖志豪等[12]、梁琪尧[13]采用遗传算法对传统BP神经网络的超参数进行优化,构建组合预测模型(genetic algorithm-back propagation,GA-BP)预测模型。郭利进等[14]建立灰色预测和BP神经网络模型,构建基于诱导有序加权算术平均算子(induced ordered weighted arithmetic,IOWA)组合灰色神经网络预测模型。曾庆扬等[15]构建了PCA与BP神经网络组合模型。由于SVR对于小样本预测具有良好的效果,Fan等[16]利用FOA搜索SVR的最优参数,提出了车位预测的FOA-SVR组合模型。时雷等[17]结合灰色系统和机器学习模型的优点,提出了基于SVR残差修正的灰色BP神经网络模型。由于影响粮食产量的因素很多,并且随机性较强,赵桂芝等[18]采用混沌理论将原始样本进行了空间重构,发挥粒子群算法(particle swarm optimization,PSO)全局搜索能力强的特点,对支持向量机(support vector machine,SVM)进行参数优化,从而组合建立模型,但是存在着容易陷入局部最优的问题。王林生等[19]利用主成分分析法选取6个主控因素,建立了PSO-ELM玛湖油田水平井产量预测模型并得到了较好的应用效果。由于目前针对产量预测的研究大都是以历史数据、天气等因素为导向来预测长期的结果。尹丽春等[20]、Zhao等[21]引入随机森林算法,设计出一种关于粮食产量短期预测的模型。李晔等[22]结合灰色预测模型和马尔可夫理论,同时利用新信息优先的思想,构建新维无偏灰色马尔可夫模型,以此来对小麦产量进行中长期预测。
SVR作为一种新型的机器学习算法,它可以有效地避免神经网络存在着学习记忆不稳定,容易陷入局部极值、网络泛化能力与预测能力存在矛盾等问题,为此,采用SVR为基础模型,用果蝇优化算法(fruit fly optimization algorithm,FOA)来优化其参数。由于目前针对红枣产量预测的研究方法较少,且红枣已经是人们日常生活中不可分割的一部分。鉴于此,主要以预测红枣产量为主要目标,以1992—2020年山西地区红枣产量数据为例,建立基于主成分分析的果蝇算法优化支持向量回归的预测模型 (principal component analysis fruit fly optimization algorithm support vector regression,PCA-FOA-SVR),将该模型与SVR、基于主成分分析的果蝇算法优化反向传播神经网络(principal component analysis fruit fly optimization algorithm back propagation,PCA-FOA-BP)等做对比,用评价指标来确定算法的优劣,最后通过GM(1,1)预测未来数据,并用PCA-FOA-SVR模型对未来产量的进行预测,对基于机器学习的智能预测方法提供一定的参考。
1 模型简介
1.1 材料来源
数据取自《中国农村统计年鉴》,共有27个样本,其中取前17个样本作为训练集,剩余10个样本作为测试集,其中以乡村人口、小型拖拉机、农用水泵、节水灌溉类机械、乡村办水电站、灌溉面积等17个特征值作为输入变量,以红枣产量作为输出变量。因数据维度较大,为避免造成预测不精准的现象,因此对其进行主成分分析(principal component analysis,PCA)降维,所选取的特征值k取5,于是便得到了27×5的一组数据,将其放入FOA-SVR模型中训练。
1.2 PCA主成分分析
PCA主成分分析可以有效去除对红枣产量影响较小的因素,消除冗余信息,使问题简单化,具体求解步骤如下。
步骤1确定分析变量,收集数据。假设有m个样本、n个变量,用m×n的矩阵Z表示样本集。
步骤2计算标准化转换后的协方差矩阵C。
(1)
步骤3计算协方差矩阵C的单位正交的特征向量与对应的特征值。
步骤4根据降维要求,确定k的大小,将C的特征值从大到小排列,选取前k个特征值所对应的特征向量。
步骤5将这些特征值向量作为行向量,求解出降维矩阵P。
步骤6将降维矩阵P乘以原矩阵Z即可降维,得到Y=PZ。
1.3 SVR支持向量机回归
支持向量机回归其目的是找到一个多元回归函数,从给定的数据集中预测未知对象的预期输出属性[23]。
它的训练结构设计由输入层、隐藏层和输出层组成,当训练集在输入层与隐藏层间实现了非线性变换之后,将能够在输出空间中实现线性回归。因此,假设如果隐藏层的维度够大,则SVR将能够趋近于任何一个非线性的映射关系,其SVR的基础模型为[24]
f(x)=ωTφ(x)+b
(2)
式(2)中:f(x)为线性回归函数;φ(x)为映射函数;ωT为ω的转置,ω与b均为未确定的参数。
由于对实际问题进行预测时,不可避免地会出现偏差,因此,SVR允许因此存在ε的最大误差,则回归问题转换为
(3)
式(3)中:lε为引入的不敏感损失函数;C为常数;m为自变量的个数;f(xi)为预测值;yi为真实值。
(4)
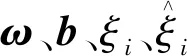
(5)
式(5)中:K(x,xi)为核函数,选取高斯径向基函数为核函数。
σ为高斯径向基函数的带宽,可表示为
(6)
1.4 果蝇优化算法对SVR进行参数优化
SVR的参数一般包括不敏感系数、惩罚因子和核函数参数,它们的参数对于模型的精度以及推广能力具有至关重要的作用,如表1所示。因此如果参数选取合适,就会得到稳定且准确的模型[25]。

表1 参数选择对SVR的影响Table 1 Impact of parameter selection on SVR
利用果蝇优化算法对SVR的参数进行寻优,并通过不断迭代寻找最优的参数(c,g),其中,c为惩罚因子g为核函数参数,从而使目标函数的值最小,具体步骤如下。
步骤1初始化参数。设置算法的最大迭代次数50次,种群数量为100,搜索区间[-1 000,1 000]。
步骤2随机初始化果蝇群体的位置。随机初始化果蝇种群位置InitXi和InitYi。
步骤3赋予果蝇个体利用嗅觉搜寻食物的随即距离和方向R,可表示为
(7)
步骤4计算味道浓度判定值。由于无法得知食物位置,因此先估计与原点的距离Di,再计算味道浓度判定值Si,此值为距离倒数。
(8)
步骤5适应度评估。计算果蝇个体位置的味道浓度Qi,可表示为
Qi=Fitness(Si)
(9)
步骤6确定最优个体。找出该果蝇群体中味道浓度最低B和最佳索引I的果蝇。
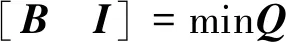
(10)
式(10)中:Q为味道浓度。
步骤6飞行。保留最佳味道浓度值与其坐标XI、YI,其他果蝇均飞向该位置。
(11)
步骤8循环。循环执行食物搜索直到算法迭代次数达到50次。
1.5 GM (1,1)基本理论
在GM (1,1)模型中,首先要对原始序列进行一次累加生成,使构造处理的数据具有一定的规律性,进而构建一阶常微分方程,进行求解,具体建模过程如下。
步骤1给定观测序列,设序列有N个观测值。
x(0)={x(0)(1),x(0)(2),…,x(0)(N)}
(12)
步骤2通过一次累加形成新序列。
x(1)={x(1)(1),x(1)(2),…,x(1)(N)}
(13)
步骤3设年份t和累加生成序列x(1)的一阶常微分方程。
(14)
式(14)中:a为常数;u为发展灰度。
步骤4当t=t0时,x(1)=x(1)(t0),此时微分方程的解为
(15)
步骤5将k+1替换t可得
(16)
1.6 PCA-FOA-SVR模型建模步骤
利用PCA-FOA-SVR模型对红枣产量预测的流程如图1所示,具体建模步骤如下。
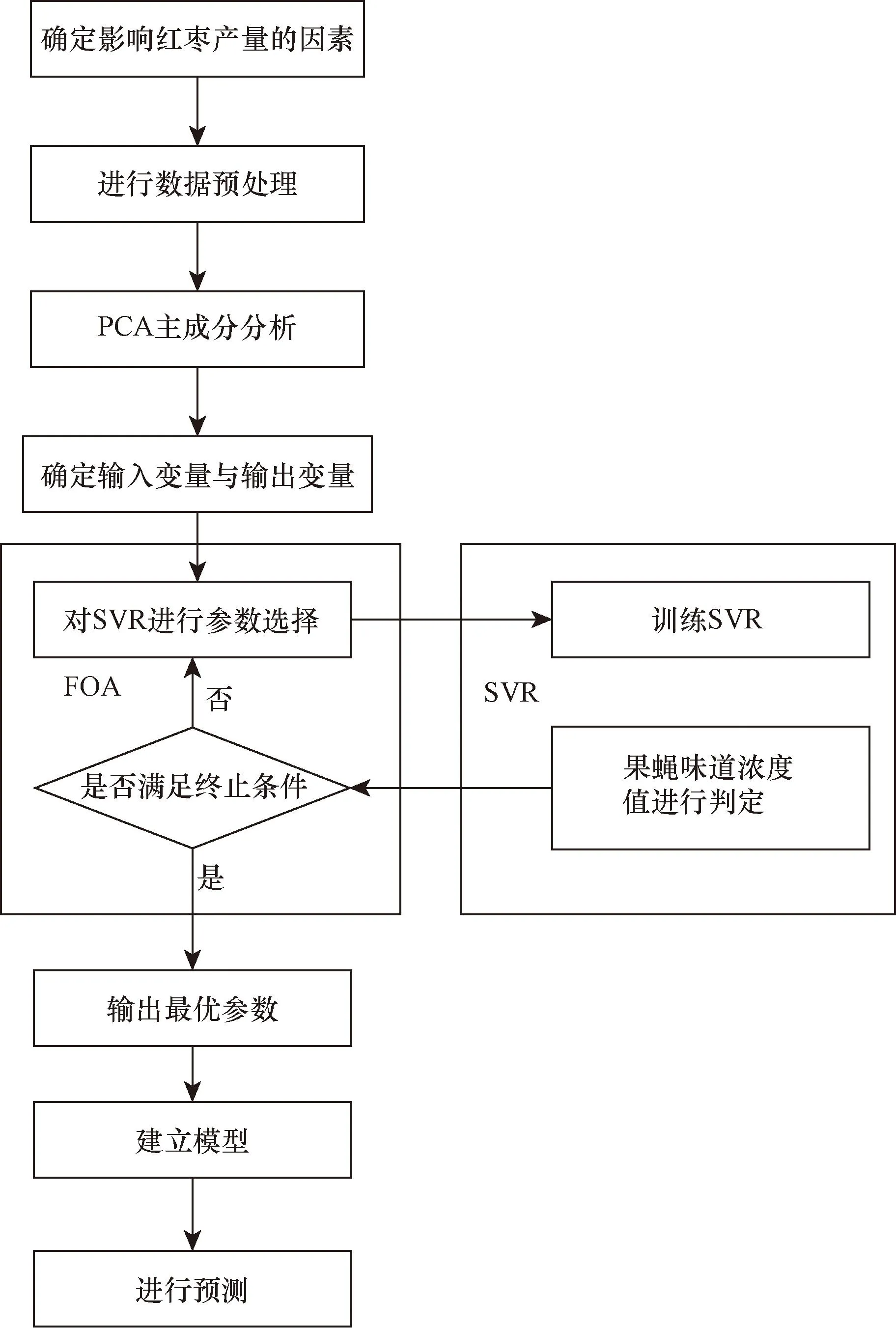
图1 PCA-FOA-SVR预测模型Fig.1 PCA-FOA-SVR prediction model
步骤1选取训练样本,确定影响红枣产量的因素,并对样本进行数据预处理。
步骤2对样本进行主成分分析,消除掉冗余信息,选取主成分维度,得出降维矩阵。
步骤3确定SVR模型的超参数,包括核函数类型为RBF、核函数参数g、惩罚因子c等。
步骤4将SVR模型的超参数作为FOA的搜索空间,并对其进行初始化,生成随机果蝇个体100个。
步骤5计算每个果蝇个体的适应度,即使用SVR模型计算出该个体的误差值,并将误差值转化为适应度值。
步骤6根据每个果蝇的个体适应度值,更新果蝇个体的位置和速度,模拟果蝇在搜索食物时的行为。
步骤7根据每个果蝇个体的位置和速度,确定SVR模型的超参数,并进行模型训练,更新SVR模型的参数。
步骤8重复步骤4~步骤7,直到达到预设的停止条件。
步骤9利用最优参数建立PCA-FOA-SVR模型,并对山西省红枣产量进行预测。
2 结果与分析
2.1 模型训练
SVR模型为网格搜索,范围为[-1 000,1 000],且以10的倍数进行搜索,搜索空间较大。因此通过FOA对SVR的惩罚因子与核函数参数进行寻优处理,不断训练模型得出惩罚因子c为190,核函数参数g为137时,迭代次数达到最小,预测值与真实值最为接近,模型达到最优,预测结果如图2所示。
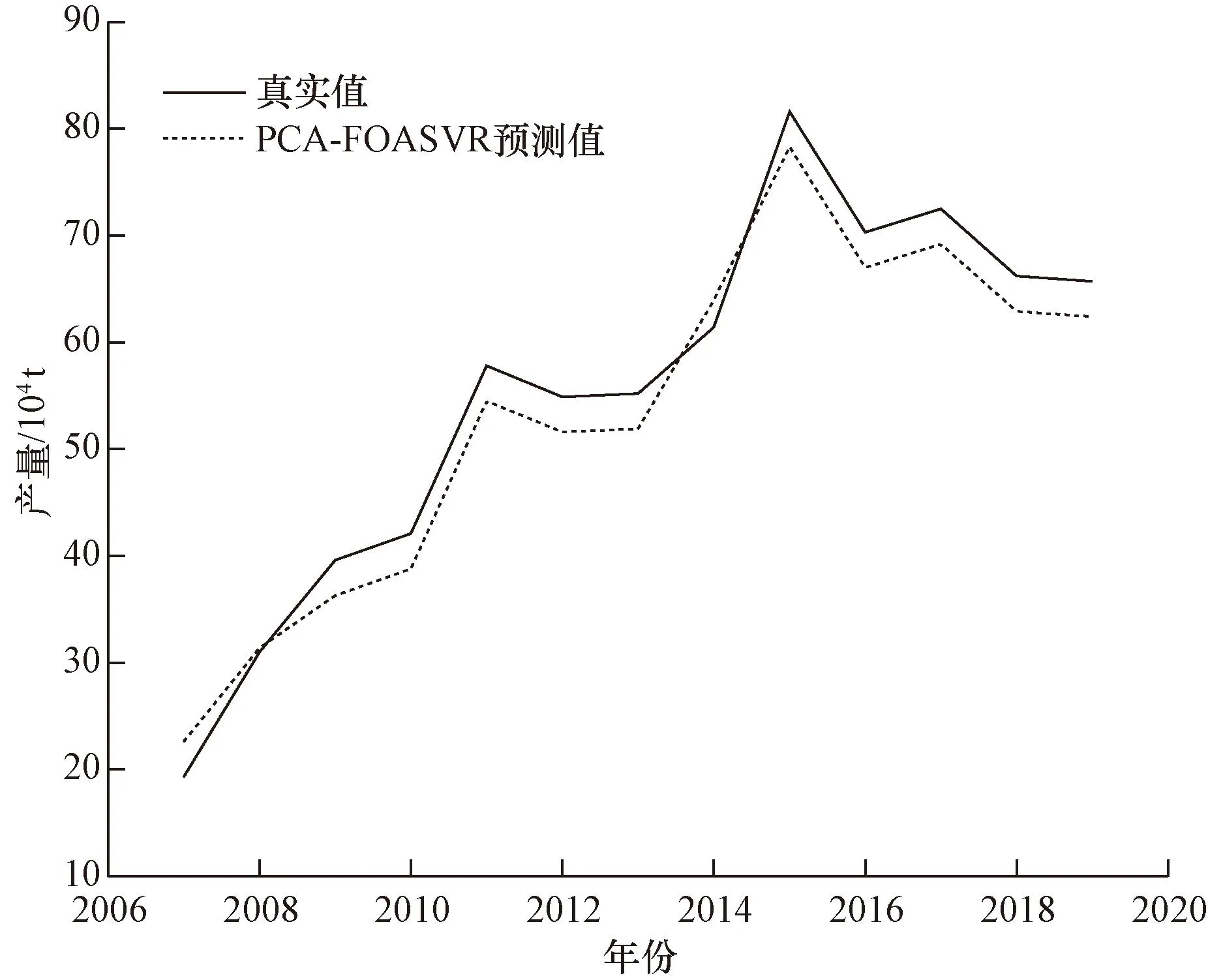
图2 PCA-FOA-SVR预测结果Fig.2 PCA-FOA-SVR prediction results
从图2中可以看出:PCA-FOA-SVR的预测走势与真实值走势一致,且误差值较小,预测的效果较好。
2.2 模型预测性能对比分析
选取SVR、PCA-SVR、BP、PCA-FOA-BP作为对比模型,设置BP神经网络训练次数为1 000,学习速率为1×10-2,训练目标最小误差为1×10-5,神经网络层数为五层神经网络。用前80%的数据作为训练样本,后20%的数据作为测试样本,PCA-FOA-SVR与PCA-FOA-BP的目标值随迭代次数的变化情况对比结果如图3所示。
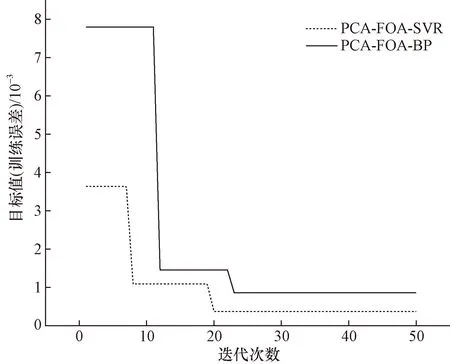
图3 迭代次数的变化情况对比Fig.3 Comparison graph of changes in the number of iterations
由图3可知,在算法迭代初期,PCA-FOA-SVR的目标值就断崖式下降,并且随着迭代次数的不断增加,目标值在趋于稳定后再次下降,并最终在迭代次数达到第20代的时候逼近于算法的最优值;PCA-FOA-BP的迭代次数在第23代的时候达到最优,因此PCA-FOA-BP的收敛能力和全局寻优能力均弱于PCA-FOA-SVR,SVR、PCA-SVR、BP、PCA-FOA-BP对比结果如图4所示。
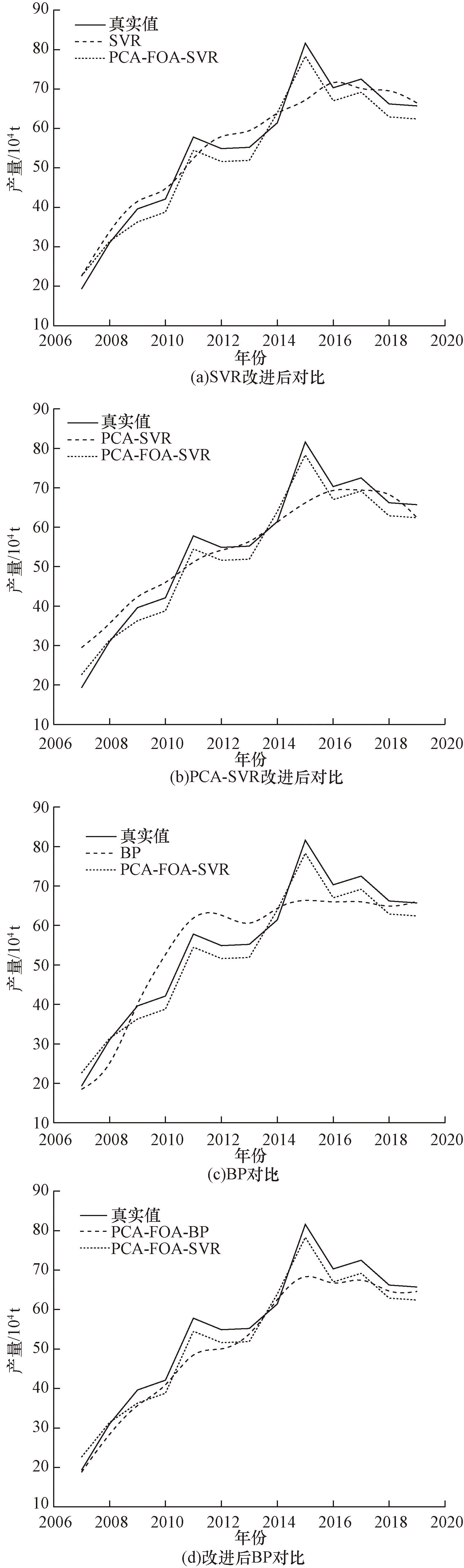
图4 各模型单独对比结果Fig.4 Individual comparison results of each model
观察图4可知,4种模型的预测值均与真实值的走势相似,且PCA-FOA-SVR的预测结果与真实值最为贴近,整体效果最优,这说明在多种因素的影响下,该模型表现出良好的适用性,能够直观的展现出各年份山西地区红枣产量的变化规律。
用均方根误差(root mean square error,RMSE)、平均绝对误差(mean absolute error,MAE)、决定系数R2作为评价指标来评估模型的有效性,其计算公式分别为
(17)
(18)
(19)
各模型的评估指标对比结果如表2所示。可以看出,PCA-FOA-SVR模型的RMSE要显著低于SVR、PCA-SVR、BP、PCA-FOA-BP,这说明经过PCA主成分分析对原始数据进行降维处理,通过果蝇优化算法对SVR的惩罚因子和核参数进行寻优后,对SVR模型具有一定程度的优化。由RMSE可以看出,PCA-FOA-SVR模型的误差离散性最小,多次差异较小,相对比SVR、PCA-SVR、BP、PCA-FOA-BP模型来说,PCA-FOA-SVR模型的RMSE分别提高了41.7%、46.9%、54.1%、33.5%。从MAE指标来看,PCA-FOA-SVR模型的MAE分别提高了26%、26.7%、44.8%、19.7%,由此可以看出,PCA-FOA-SVR模型的精度最高。从R2可以看出,PCA-FOA-SVR模型分别提高了6.67%、9.09%、14.29%、4.35%,且PCA-FOA-SVR的R2达到0.96,说明模型拟合优度最好。
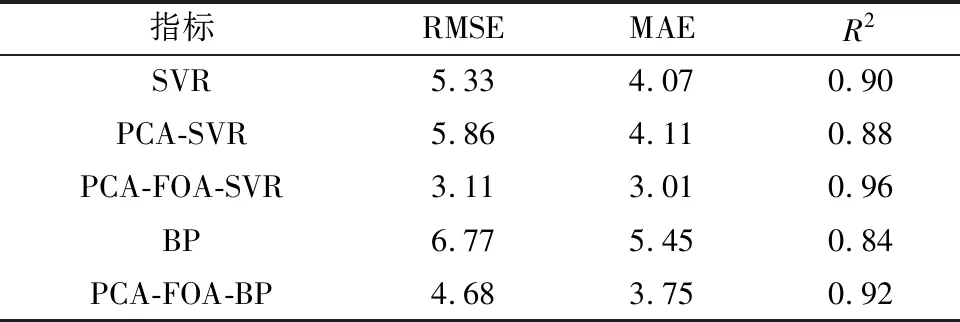
表2 各模型评估指标对比Table 2 Comparison of evaluation indexes of each model
2.3 模型应用
因为PCA-FOA-SVR相对SVR、PCA-SVR以及BP、PCA-FOA-BP来说具有较高的预测精度,且稳定性较强,因此使用该模型对未来10年的产量进行预测。但是因为未来各变量均为未知,因此首先根据GM(1,1)模型对2020—2030年的山西省红枣产量的影响因素进行预测,再用PCA-FOA-SVR模型对产量预测,预测结果如图5所示。
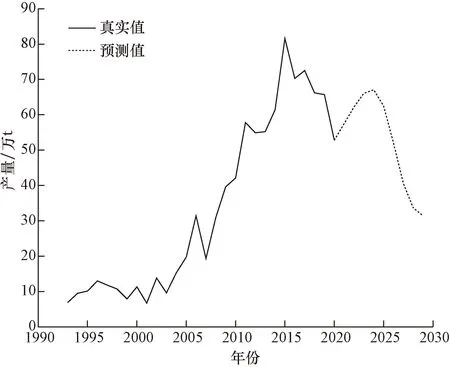
图5 未来产量预测Fig.5 Future production forecast chart
从图5中可以看出,山西省红枣产量会在未来5年内持续上升并在2025年达到顶峰,然后呈现下降趋势,具有一定的波动性,可能是红枣内含有众多营养成分,人们对于红枣的需求开始增加;其次灰色预测对于未来数据的获取存在一定量的偏差。
3 结论
以山西省1993—2020年的红枣产量及17个维度的因素作为基础数据,建立基于主成分分析的果蝇算法优化支持向量机回归的红枣产量预测模型,并分别与SVR、PCA-SVR、BP、PCA-FOA-BP4模型进行对比,以RMSE、MAE、R2作为评价指标得出以下结论。
(1)PCA-FOA-SVR的RMSE、MAE、R2分别为3.11、3.01、0.96,较SVR模型分别提高了41.7%、26%、6.7%;较PCA-SVR模型分别提高49.6%、26.7%、9.1%;较PCA-FOA-BP模型分别提高33.5%、19.7%、4.3%,由此可以看出基于主成分分析的果蝇算法优化支持向量机回归红枣产量预测模型误差离散性小,精度最高且拟合优度最好。
(2)通过GM(1,1)对未来数据进行预测,利用PCA-FOA-SVR模型对未来10年山西省红枣产量进行预测,并得到在2025年红枣产量会达到一个峰值。
本次研究中考虑了17个维度的指标作为输入变量,但未考虑人们的消费习惯、极端天气等多种因素,后续研究可考虑加入变量,完善数据量,对产量作为更精准的预测。
猜你喜欢
学苑创造·A版(2023年10期)2023-11-04 13:14:04
大自然探索(2023年11期)2023-03-01 09:04:36
新高考·高一数学(2022年3期)2022-04-28 07:02:46
学苑创造·A版(2022年3期)2022-03-29 23:32:16
趣味(作文与阅读)(2021年12期)2021-04-19 12:16:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
学生天地(2019年35期)2019-08-25 08:58:22
学苑创造·A版(2019年6期)2019-07-11 01:07:39
今日农业(2019年10期)2019-06-26 00:46:42
小猕猴学习画刊(2016年6期)2016-05-14 09:20:25
