
多感受野特征自适应融合及动态损失调整的初烤烟叶等级检测
2024-02-29 12:02:44何自芬张印辉陈光晨陈东东
光学精密工程 2024年2期
何自芬, 罗 洋, 张印辉, 陈光晨, 陈东东, 徐 林
(昆明理工大学 机电工程学院,云南 昆明 650500)
1 引 言
2021 年中国烟草种植面积达1 013 千公顷,初烤烟叶产量达202.01 万吨[1],贡献1.2 万亿财政税收。初烤烟叶分级[2]是烟叶实际收购过程中的重要环节,分级结果直接决定了初烤烟叶的价格以及烟草种植农户的利益。目前,由于分级精度不高,烤烟分级自动化方法未得到广泛应用,因此,每年烤烟采收季节,都需投入大量人力和财力对初烤烟叶进行人工分级。此外,人工分级结果依赖于专家经验知识,使得分级过程主观化、经验化,从而导致分级结果缺乏客观依据。为解决以上初烤烟叶分级任务中所存在的问题,研究一种精度高、速度快的初烤烟叶等级检测算法对提高自动化分级设备性能具有重要意义。
根据中国烤烟国家标准GB2635-1998,初烤烟叶颜色、成熟度、油分、长度、身份、残伤、叶片结构是决定其等级的重要因素。为了更好的对初烤烟叶进行分级,研究人员提出了基于机器视觉的初烤烟叶分级方法,主要分为传统视觉方法和深度学习方法。传统特征提取方法主要采用图像色彩阈值划分和形态学计算等方法来提取初烤烟叶图像的颜色、脉络等显式相关表层特征,再根据人工经验判断其等级。Zhang 等[3]提出了一种表示初烤烟叶特征分布的二维特征空间,利用传统数字图像处理技术提取初烤烟叶的颜色、纹理和形状参数等外观特征,再与专家标准进行对比,实现初烤烟叶分级。Tattersfield 和Forbes[4]提出一种颜色分析方法,将RGB 色彩空间转换为孟塞尔颜色体系来模拟人类视觉,对初烤烟叶进行颜色分组。Han[5]利用支持向量机对烟叶生长部位进行识别。Marcelo 等[6]采用近红外高光谱成像技术结合支持向量机对初烤烟叶进行分级。尽管传统视觉分级方法相较于人工分级取得了很大进步,但其在初烤烟叶图像预处理时需要人工调整大量超参数,且无法提取叶片的深层语义特征信息,从而限制了其分级精度和效率。
随着深度学习技术的发展,可实现自动提取特征并进行分类的卷积神经网络被广泛应用于农业生产中。林相泽等[7]结合字典学习与SSD目标检测网络,对不完整稻飞虱图像进行识别,为稻飞虱的预防和监督提供了技术支持。Zhang等[8]设计了一种基于区域分割和AlexNet 的快速定位分类模型,并将其部署于分拣机器人上,用于茶叶分拣,最高分选准确率达92%。Shang等[9]利用轻量级深度学习算法对自然环境下的苹果花进行实时检测。在卷积神经网络的应用提高了农产品生产效率的同时,深度学习方法也被应用在初烤烟叶分级任务中,曾祥云[10]改进了经典AlexNet 网络,增强了模型的学习能力,提高了初烤烟叶分级的准确率;Dasari 和Prasad[11]使用卷积神经网络从三个等级的初烤烟叶图像中自动提取特征,分级准确率达到85.10%,但作者仅应用了120 张初烤烟叶图像,数据集图像数量较少,这难以使神经网络充分学习初烤烟叶特征;Chen 等[12]使用MobileNetV2 和Swin Transformer 组成的并行双编码器结构对8 个等级的初烤烟叶进行分级,分级精度达到79.30%,但其模型图像处理时间达到每帧95 ms,无法达到实时检测的需求。Lu 等[13]搭建了一种细粒度视觉分类框架并将其应用于初烤烟叶分级任务中,六个等级的初烤烟叶分级准确率达到80.65%,尽管单帧初烤烟叶图像处理时间缩短至42.1 ms,但仍然达不到实时检测的需求。
YOLOv5 目标检测算法在检测精度和检测速度方面均具有优秀的性能,广泛应用于缺陷检测[14]、行人检测[15]、异物检测[16]等方面。将YOLOv5 用于初烤烟叶等级检测任务时,随着网络深度的增加,一些对初烤烟叶等级检测有益的深层特征信息随之丢失;缺乏对叶片的局部特征信息的关注,导致其无法有效区分相似度较高的不同等级的初烤烟叶;在模型定位过程中,真实框与预测框宽高比相同且中心点重合但真实框与预测框并未重合时,模型的定位损失函数性能退化。针对上述问题,本文提出一种多感受野特征自适应融合及动态损失调整的初烤烟叶等级检测网络(Flue-cured Tobacco Leaf Grade Detection Network,FTGDNet)。首先利用CSPNet[17]作为特征提取主干网络,利用GhostNet[18]作为辅助特征提取网络,在CSPNet 和GhostNet 末端将所提取的特征进行像素相加以增强模型特征提取能力,保留更多对初烤烟叶等级检测有益的深层特征信息;使用显式视觉中心瓶颈模块EVCB将全局信息与局部信息进行融合;嵌入多感受野特征自适应融合模块MRFA 增强模型局部感受野的同时突出有效通道信息;使用本文提出的MCIoU_Loss 代替CIoU_Loss,MCIoU_Loss 结合了真实框与预测框面积损失以及矩形相似度衰减系数,加快模型拟合的同时有效改善真实框与预测框宽高比相同且中心点重合时模型定位损失函数退化问题。
2 多感受野特征自适应融合及动态损失调整的初烤烟叶等级检测网络
2.1 FTGDNet 网络结构
FTGDNet 深度学习模型运用回归思想,以一阶段网络完成目标定位及分类。如图1 所示,FTGDNet 沿用了YOLOv5 的整体布局,其网络结构由Input,Backbone,Neck 以及Output 四部分组成。
FTGDNet 在Input 部分将图像缩放为640×640。Backbone 的第一层是Focus 模块,Focus 模块将输入图像进行4 次切片操作,切片操作采用间隔像素点采样的方式,将原图像宽度W、高度H转换到通道空间,输入通道由原RGB 3 通道变为12 通道,再通过卷积操作,将输入图像由640×640×3 变为320×320×32。 受启发于DenseNet[19]的密集跨层连接思想,CSPNet 利用不同层的特征信息进行局部跨层融合以获得更为丰富的特征图。GhostNet 的核心思想是以更少的参数生成更多的特征信息,进而达到减少模型参数量同时加快模型推理速度的目的。为增强模型主干特征提取能力,FTGDNet 采用CSPNet 作为特征提取主干,采用GhostNet 进行辅助特征提取。空间金字塔池化模块SPP 使用5×5,9×9,13×13 池化核进行最大池化操作,再将不同尺度的特征图进行拼接,增加了网络提取全局信息的能力。在Backbone 末端嵌入具有全局特征和局部特征相结合功能的EVCB 模块作为瓶颈层,随后添加MRFA_d,模块EVCB 模块和MRFA_d 模块将在2.2 和2.3 详细描述。Neck 部分由特征金字塔网络(Feature Pyramid Networks,FPN)和路径聚合网络(Path Aggregation Network,PAN)组成,FPN 自顶向下将高层特征信息与不同C3 模块的输出进行聚合,PAN自底向上聚合浅层特征,进而充分融合不同层的图像特征。Output 部分使用MCIoU_Loss 作为定位损失函数,加快模型拟合的同时有效改善真实框与预测框宽高比相等且中心点重合时CIoU_Loss 性能退化问题。
2.2 显式视觉中心瓶颈模块
显式视觉中心瓶颈模块(Explicit Visual Center Bottleneck module,EVCB)主要由可学习视觉中心模块(Learnable Visual Center,LVC)和轻量级多层感知机模块(Lightweight MLP,LMLP)两部分构成,其结构如图2 所示。可学习视觉中心模块中存在一个拥有固有码本和缩放因子的编码器,其中固有码本B={b1,b2,…,bk},缩放因子S={s1,s2,…,sk}为可学习的视觉中心。对于输入特征(在FTGDNet 中,该输入来自SPP 模块的输出),先使用7×7 卷积平滑所输入的特征信息,再利用一组卷积(由1×1 卷积、3×3 卷积、1×1 卷积、3×3 卷积+BN+ReLU 构成)对该特征进行编码,将编码后的特征xi输入Codebook中,使用缩放因子sk关联xi与bk,进而映射出xi与bk的位置信息,上述过程表达为如式(1)所示:
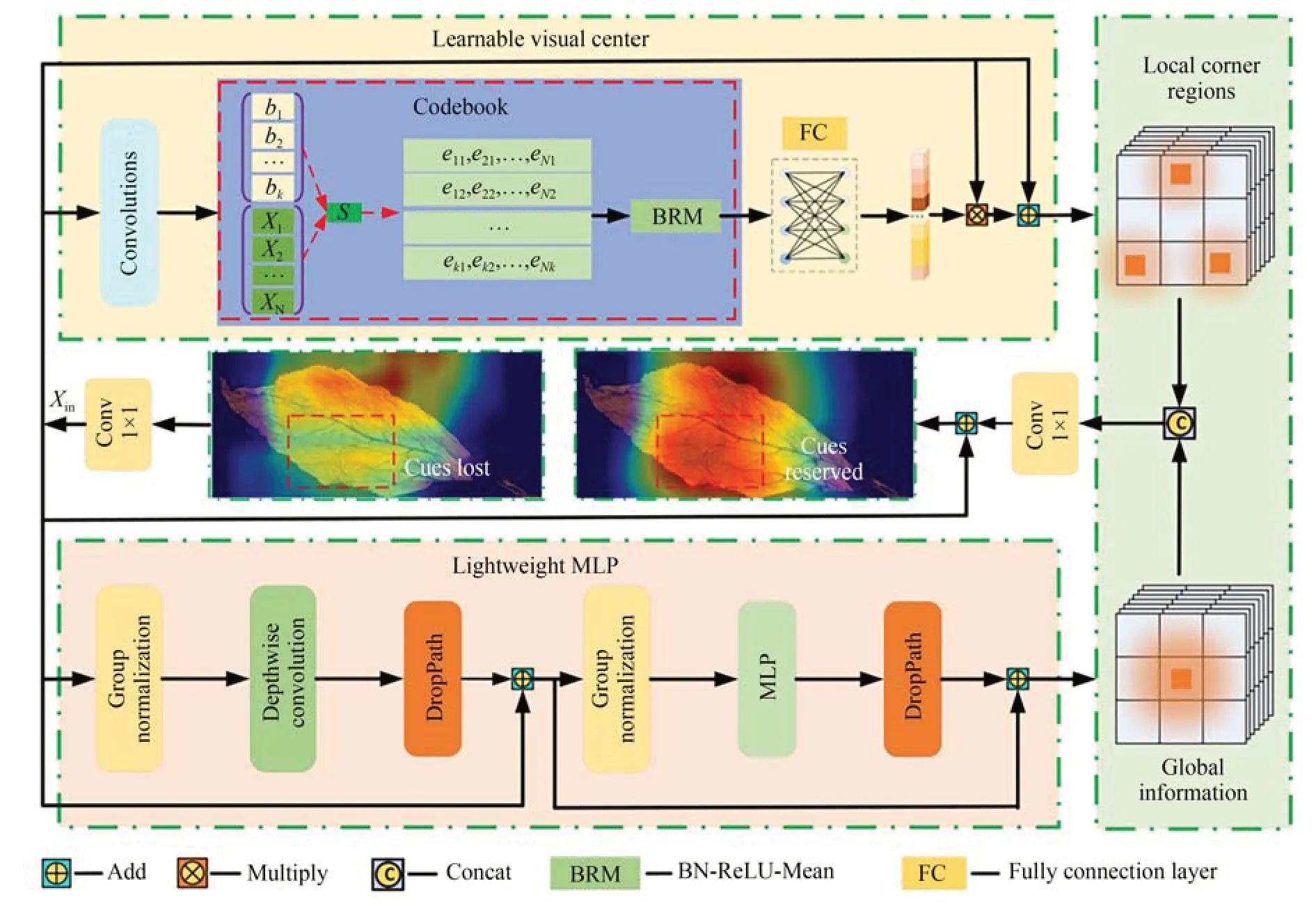
图2 EVCB 模块结构Fig.2 EVCB module sructure
其中:ek为输入特征图关于第k个码字的位置信息,N为输入特征的像素点总数,K为视觉中心的总数,xi为第i个像素点,bk为第k个码字,sk为第k个缩放因子。
使用BRM 融合所有的ek得到所有像素点关于全部码字的位置信息,将该信息输入全连接层中,突出具有类别区分性的局部信息,再使用view 函数将FC 输出的特征图大小变为1×1,同时将7×7 卷积的输出与view 函数的输出Xin进行通道相乘,该过程可以表示为:
其中:⊗表示通道相乘,R表示ReLU 激活函数。
最后将Y与Xin进行通道拼接,得到包含局部特征信息的LVC 的输出,上述过程表示为:
其中,⊕表示像素相加。
轻量级多层感知机模块由深度卷积残差模块和通道多层感知机残差模块构成,其中,通道多层感知机残差模块的输入是深度卷积残差模块的输出。在两个残差模块中均对输入特征沿着通道维度进行分组操作,同时使用DroupPath操作来提高模型的鲁棒性。具体来说,来自7×7卷积的特征信息Xin输入深度卷积残差模块,该过程表示为:
相较于空间多层感知机,通道多层感知机在保证模型检测性能的前提下,能够有效降低模型的计算复杂度。通道多层感知机残差模块信息处理过程可以表示为:
将LVC 模块和LMLP 模块的输出进行通道拼接,随后使用1×1 卷积将通道数减半,最后与Xin进行像素相加得到EVCB 模块的输出,上述过程表示为:
其中,Concat 表示通道拼接。
LVC 能够有效保留局部特征信息,而LMLP则有效获取具有长距离依赖的全局特征信息,EVCB 模块将二者进行结合,有效提高模型的表征能力进而提高模型检测精度。
2.3 多感受野特征自适应融合模块
多感受野特征自适应融合模块(Multi-Receptive Field Feature Adaptive Fusion module,MRFA)结构如图3 所示。MRFA 包含三层标准卷积结构,第一层和第三层均为1×1 卷积,主要用于减少通道数。第二层卷积结构由卷积核为3×3,5×5,7×7 的卷积并行而成,用于制造具有不同感受野的特征图。在卷积神经网络中,感受野是指卷积神经网络每层输出的特征图上的像素点在原始图像上映射区域的大小。感受野尺寸的求解相当于已知输出特征图大小反向求出输入特征图的过程。计算感受野大小时,常采用自顶向底的方式计算,即先计算最终特征图在前一层上的感受野,然后逐渐传递到第1 层。MRFA 中所使用卷积均为标准卷积且卷积步长s均为1,其感受野计算公式如式(7)所示:
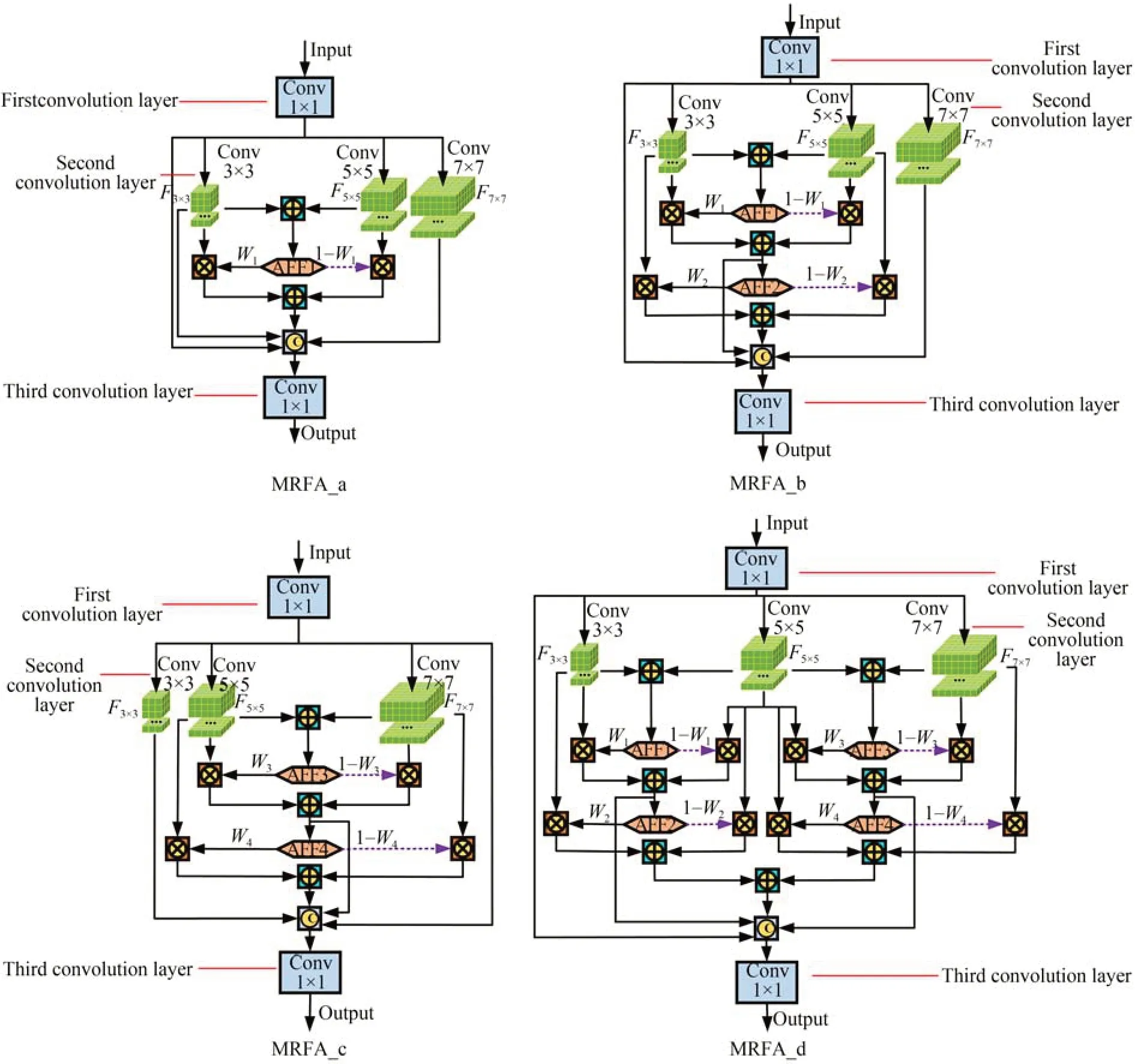
图3 四种MRFA 结构对比Fig.3 Comparison of four MRFA structures

图 4 AFF 机制Fig.4 AFF mechanism
其中:lm为第m层感受野,lm-1为第m-1 层感受野,s为第m层卷积步长,n为第m层卷积核尺寸。
MRFA 第三层卷积输出特征图感受野为1×1,即l3=1,根据式(8)计算,第二层3×3,5×5,7×7 卷积输出特征图感受野分别为3×3,5×5,7×7,即,卷积核尺寸为7×7 的卷积输出特征图感受野最大,再次利用式(7)计算,得到MRFA 模块输出的特征图的一个像素点在原始特征图的感受野为7×7。
MRFA 利用不同卷积核尺寸卷积制造了感受野为3×3,5×5,7×7 的特征图,定义相邻感受野特征图中较小感受野特征图为Fa×a,感受野较大特征图为Fb×b,将Fa×a与Fb×b进行像素相加,再将像素相加结果输入注意力特征融合AFF 机制中,获得通道注意力权重W。上述过程表示为:
AFF 是一种类似于压缩激励(Squeeze-and-Excitation,SE)[20]注意力机制的结构,能够在通道方向上筛选出重要的特征信息,其原理如图4所示。在获得通道注意力权重W后,权重W与Fa×a进行通道相乘,同时使用1-W与Fb×b进行通道相乘,再将通道相乘结果进行像素相加,即对相邻感受野特征图进行加权融合,上述过程表示为:
其中:Z表示相邻感受野特征图进行加权融合输出,W表示通道注意力权重。
本文设计了四种MRFA 结构,分别为图3 所示的MRFA_a,MRFA_b,MRFA_c,MRFA_d。定义3×3,5×5,7×7 感受野特征图为F3×3,F5×5,F7×7。MRFA_a 将F3×3,F5×5进行自适应加权融合,随后将其与感受野为3×3 和7×7 以及第一层卷积输出的特征图进行通道拼接,最后再输入1×1 卷积中将通道数减半。MRFA_a 特征处理过程可以表示为:
其中:Conv表示卷积核尺寸为1×1 的卷积,Concat表示通道拼接,C3×3,C5×5,C7×7分别表示F3×3,F5×5,F7×7对应通道,CAFF1表示F3×3与F5×5自适应加权融合特征对应通道,C0表示第一层卷积输出特征通道。
MRFA_b 在MRFA_a 的基础上进行二次加权特征融合,进一步增强特征图中的有用信息,MRFA_b 特征处理过程表示为:
其中:CAFF2表示F3×3与F5×5二次加权融合特征对应通道。
MRFA_c 与MRFA_b 相似,所不同的是MRFA_c 将F5×5与F7×7进行二次加权融合,其特征处理过程表示为:
其中:CAFF3表示F5×5与F7×7加权融合特征对应通道,CAFF4表示F5×5与F7×7二次加权融合特征对应通道。
MRFA_d 综合MRFA_b 与MRFA_c,同时将F3×3与F5×5以及F5×5与F7×7进行二次加权特征融合,并将二次加权融合结果进行像素相加,再与CAFF1,CAFF3,C0进行通道拼接,其特征处理过程表示为:
其中:C(AFF2⊕AFF4)表示将AFF2与AFF4像素相加后特征对应通道。
将多感受野特征自适应融合模块嵌入FTGDNet 中,增加模型局部感受野的同时突出有效特征信息,进一步提升模型表征能力。
2.4 目标定位损失
YOLOv5 网络中使用CIoU_Loss 定位损失函数,其定义如下:
其中:ρ2(cp,cg)表示真实框与预测框的中心点距离,d真实框与预测框最小外接矩形的对角线长度,wg和hg是真实框的宽度和高度,wp和hp是预测框的宽度和高度。
如图5 所示,网络在回归定位过程中真实框与预测框宽高比相等(即)且其中心点重合时,CIoU_Loss 中的以及αυ将失效,CIoU_Loss 退化为IoU_Loss,但此时真实框与预测框并未重合,这降低了模型拟合速度且不利于模型检测精度的提升。针对上述问题,本文提出MCIoU_Loss,MCIoU_Loss 定义如下:

图5 真实框与预测框拟合结果Fig.5 Fitting result of real box and prediction box
其中:β为真实框与预测框面积损失,wm和hm分别为真实框与预测框最小外接矩形面积的宽度和高度,将αυ和β定义为真实框与预测框的矩形相似度判别项,λ为矩形相似度衰减系数。
本文在MCIoU_Loss 中引入了真实框与预测框的面积损失,有效解决真实框与预测框宽高比相等且其中心点重合时CIoU_Loss 性能退化问题,同时引入矩形相似度衰减系数λ,随着预测框与真实的框重合度增加,λ增大,真实框与预测框的矩形相似度判别项数值不断衰减,在训练过程中对定位损失函数进行动态调整,加快模型拟合速度同时进一步提高模型定位精度。
3 实验结果与分析
3.1 实验数据集、实验配置及评价指标
本文使用智能分级设备5XYZ-9C 采集初烤烟叶图像,如图6 所示,该设备使用黑色传送带将叶片运送至装有工业面阵相机和固定光源的暗室中进行图像采集,工业面阵相机固定于暗室顶部,其镜头距离传送带845 mm。相机型号为CA050-11U,其分辨率为2 384×1 528,镜头型号为M0824-MPW2。光源设备型号XC-BK-650-1100,固定于暗室左右两侧顶部。利用5XYZ-9C获取代号为B1F,B2F,B3F,C2F,C3F,C4F,X2F,X3F,V,GY 十个等级初烤烟叶图像数据,其中,等级代号相邻的叶片间叶形及颜色特征差异较小,相似度较高。通过数据筛选,得到高质量图像共计3 192 幅,建立初烤烟叶分级数据集(Flue-cured Tobacco Leaf Grading Dataset,FTLGD),各等级初烤烟叶示例如图7 所示。使用LabelImg 对FTLGD 中叶片进行锚框标注,得到包含叶片中心坐标、宽、高信息的xml 文件,使用python 编程将xml 文件转换为txt 标注文件,建立可以在YOLO 模型中运行的数据集,并将其中2 700 幅按照4∶1 比例随机划分训练集和验证集、492 幅作为测试集用于网络训练和性能测试。

图6 智能分级设备5XYZ-9CFig.6 Intelligent grading equipment 5XYZ-9C

图7 FTLGD 中初烤烟叶叶片Fig.7 Flue-cured tobacco leaves in FTLGD
实验配置:11th Gen Intel(R) Core(TM) i5-11400 处理器,运行内存为16G,图形处理单元为NVIDIA GeForce RTX 3060(12G),深度学习框架为Pytorch1.8.0,使用CUDA11.1,cuDNN 8.0.4 加快网络训练。Batch_sizes 设置为16,Epoch 设置为300。在训练过程中,通过Mosaic 算法对输入数据进行在线增强,采用SGD 对训练过程进行优化。
评价指标:采用模型参数量(Parameters)、浮点运算数(FLOPs)以及前向推理时间(Inference time)对模型的计算效率进行评价。采用均值平均精度(mean Average Precision,mAP)对模型检测精度进行评价,其计算公式如式(16)所示:
其中:M为类别数,APi为第i类的识别精度。
3.2 实验结果与分析
3.2.1 FTGDNet 消融实验
FTGDNet 使用CSPNet 作为特征提取主干网络,为增强主干的特征提取能力,使用Ghost-Net 进行辅助特征提取。为验证上述改进的效果,本节对ShuffleNet[21],GhostNet,CSPNet 作为特征提取主干网络以及CSPNet 作为特征提取主干的同时Shufflenet 或GhostNet 作为辅助特征提取网络进行实验对比,对比结果如表1 所示。ShuffleNet 和GhostNet 具有模型轻量化的优点,但其特征提取能力有限。将ShuffleNet 和Ghost-Net 作为特征提取主干网络时,相较于CSPNet,浮点运算数分别下降6.9 G,5.2 G,参数量分别下降2.1 M,1.4 M,推理时间分别加快1.0 ms,0.7 ms,但初烤烟叶等级检测精度大幅下降,在测试集上仅为56.0%和59.5%,在验证集上仅为51.8%和55.5%。将CSPNet 作为特征提取主干网络,ShuffleNet 和GhostNet 分别作为辅助特征提取网络时,由于增加了一条辅助特征提取网络,模型的浮点运算数、参数量、推理时间均有不同程度的上升,但GhostNet 作为辅助特征提取网络时,在验证集和测试集上,检测精度分别达到83.5%和81.2%,相较于单一CSPNet 作为特征提取主干网络,上升4.7%和5.5%。
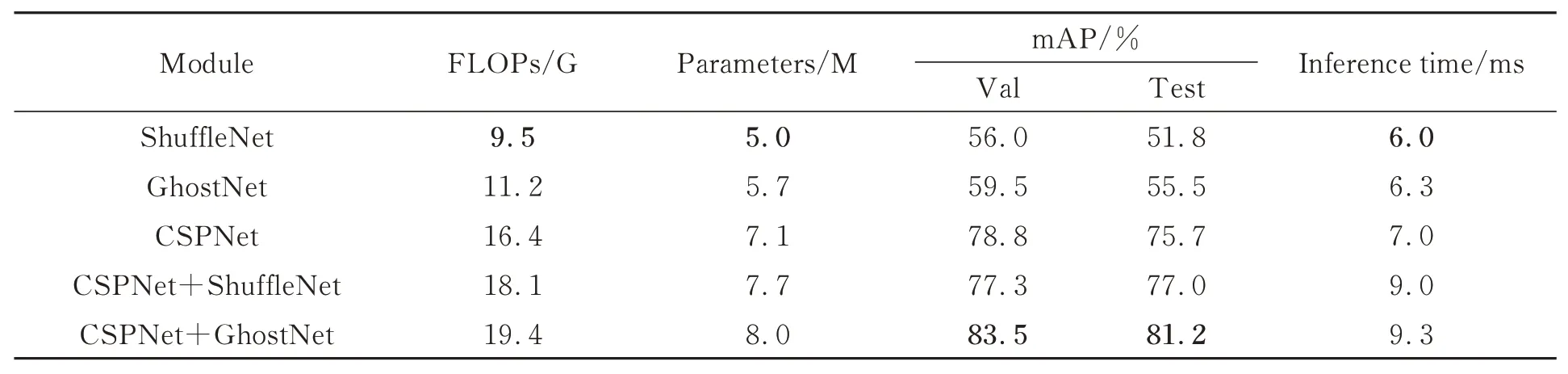
表1 主干网络对比实验Tab.1 Backbone network comparison study
本文以CSPNet+GhostNet 作为Baseline,以验证EVCB 模块、MRFA_d 模块、MCIoU_Loss定位损失函数的检测性能,各模块性能消融实验如表2 所示。由表2 可知,模型在采用EVCB 模块后,在验证集上检测精度上升3.1%,在测试集上检测精度上升1.0%,验证了EVCB 模块将全局与局部特征信息结合进而有效提高初烤烟叶等级检测精度的结论,但由于EVCB 中存在全连接层,模型的浮点运算数、参数量分别上升2.1 G,2.8 M,推理时间减慢1.6 ms。对MRFA_d 模块进行实验分析,在Baseline+EVCB 的基础上加入MRFA_d,在验证集和测试集上,模型检测精度分别达到89.2%和85.3%,模型浮点运算数上升到22.9 G,参数量上升到12.4 M,模型推理时间减慢至12.6 ms。对MCIoU_Loss 定位损失函数进行实验分析,在模型中使用MCIoU_Loss 定位损失函数后,模型的验证精度上升0.8%,达到90%,测试精度上升2.1%,达到87.4%,证明MCIoU_Loss 定位损失函数具有提高定位精度进而提高检测精度的能力。

表2 模块消融实验Tab.2 Module ablation study
3.2.2 显式视觉中心瓶颈层对比实验
本文将显式视觉中心瓶颈模块(EVCB)作为网络的瓶颈层(Stage 9)来提取初烤烟叶特征信息,为验证EVCB 作为网络瓶颈层的性能,本节选用YOLOv5 网络中作为瓶颈层结构的Bottleneck,BottleneckCSP,C3 与EVCB 进行对比,对比结果如表3 所示。由表3 可知,FTGDNet 采用Bottleneck 作为瓶颈层时,模型整体性能较差,对初烤烟叶等级的识别准确率最低,验证精度仅为81.5%,测试精度仅为81.4%。C3 模块作为瓶颈层时,其浮点运算数、参数量均为最低,分别为19.4 G,8.0 M,此外,其推理时间最快,仅为9.3 ms。当FTGDNet 选择EVCB 模块作为瓶颈层时,对初烤烟叶的识别精度最高,验证精度达到86.6%,相较于Bottleneck,BottleneckCSP,C3 模块分别提升5.1%,4.0%,3.1%,测试精度达到82.2%,相较于Bottleneck,BottleneckCSP,C3 模块分别提升0.8%,1.6%,1.0%,但由于EVCB中使用了全连接层结构,其浮点运算数和参数量均为最高,模型推理时间最慢,为10.9 ms。

表3 瓶颈模块效果对比Tab.3 Effect comparison of bottleneck module
3.2.3 多感受野特征自适应融合模块实验
本节在Baseline+EVCB 框架下,验证多感受野特征自适应融合模块在初烤烟叶等级检测任务中的优越性能。本文设计了四种多感受野自适应特征融合结构MRFA_a、MRFA_b、MRFA_c,MRFA_d,并将其嵌入网络的第10 层(Stege 10),四种多感受野自适应特征融合结构性能对比如表4 所示。根据表4 可知,将4 种多感受野特征自适应融合模块先后嵌入网络后,相较于Baseline+EVCB,模型的验证精度分别上升0.5%,2.0%,2.2%,2.6%,达 到 87.1%,88.6%,88.8%,89.2%,测试精度分别上升2.2%,1.5%,2.8%,3.1%,达 到 84.4%,83.7%,85.0%,85.3%。但多感受野特征自适应融合模块中使用了多个卷积层,模型的浮点运算数分别上升1.3 G,1.3 G,1.3 G,1.4 G,参数量均上升1.8 M,推理时间分别减慢1.2 ms,1.4 ms,1.4 ms,1.7 ms。综合考虑下,MRFA_d对初烤烟叶等级的检测精度最高,验证精度和测试精度分别达到89.2%和85.3%,更适合应用于初烤烟叶等级检测任务中。

表4 四种MRFA 结构性能对比Tab.4 Performance comparison of four MRFA structures
3.2.4 定位损失函数对比实验
为验证MCIoU_Loss 定位损失函数的性能,本节在FTGDNet 最终模型的基础上,选用GIoU_Loss,DIoU_Loss,SIoU_Loss,CIoU_Loss四种定位损失函数与MCIoU_Loss 进行实验对比,对比结果如表5 所示。根据表5,模型采用GIoU_Loss 的检测精度最低,验证精度仅为85.9%,测试精度仅为82.4%;DIoU_Loss 在GIoU_Loss 的基础上加入中心距损失,较GIoU_Loss 其检测精度上升1.8% 和2.4%;SIoU_Loss 同时使用了角度损失、中心距损失、形状损失,模型采用SIoU_Loss 定位损失函数后,测试精度和验证精度上升至88.2% 和85.3%;CIoU_Loss 相较DIoU_Loss,CIoU_Loss引入了宽高比损失,进一步提高了目标定位精度,其检测精度达到了89.2% 和85.3%;MCIoU_Loss 中引入真实框与预测框面积损失,同时引入矩形相似度衰减系数对真实框与预测框相似度判别项进行动态调整,模型使用MCIoU_Loss 后,在验证集上,检测精度达到90.0%,相 较 于 GIoU_Loss,DIoU_Loss,SIoU_Loss,CIoU_Loss 分别提升4.1%,2.3%,1.8%,0.8%,在测试集上,检测精度达到87.4%,相 较 于 GIoU_Loss,DIoU_Loss,SIoU_Loss,CIoU_Loss 分别提升5.0%,2.6%,2.1%,2.1%。图8 对比了训练过程中五种定位损失函数的数值变化,其中,本文提出的MCIoU_Loss 在40 个Epoch 后保持最低,图9 对比了训练过程中CIoU_Loss 与MCIoU_Loss 的mAP值,进一步验证了MCIoU_Loss 具有提高定位精度和加快模型拟合的能力。
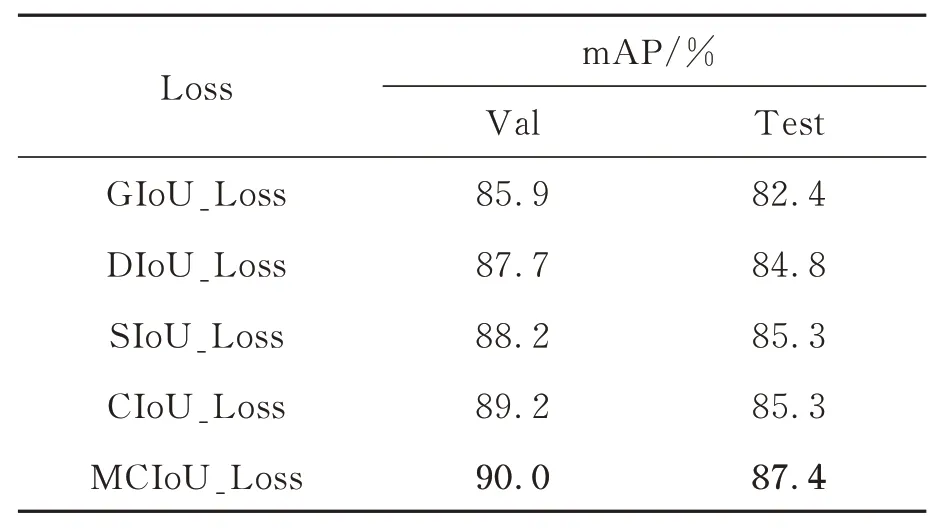
表5 不同损失函数性能对比Tab.5 Performance comparison of different Loss functions
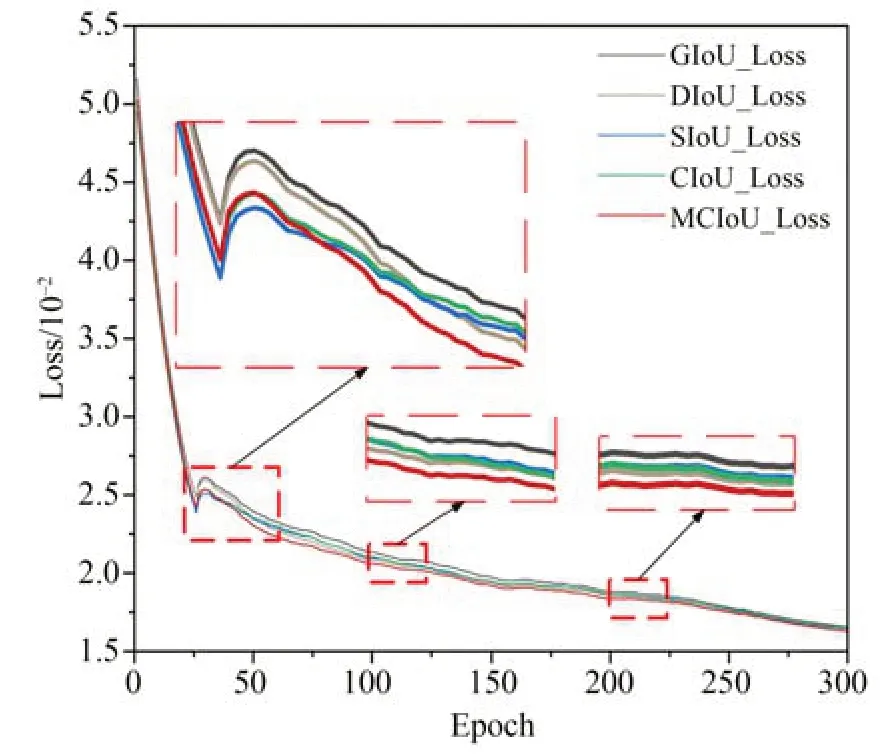
图8 训练过程损失值变化曲线Fig.8 Change curves of Loss value in training process
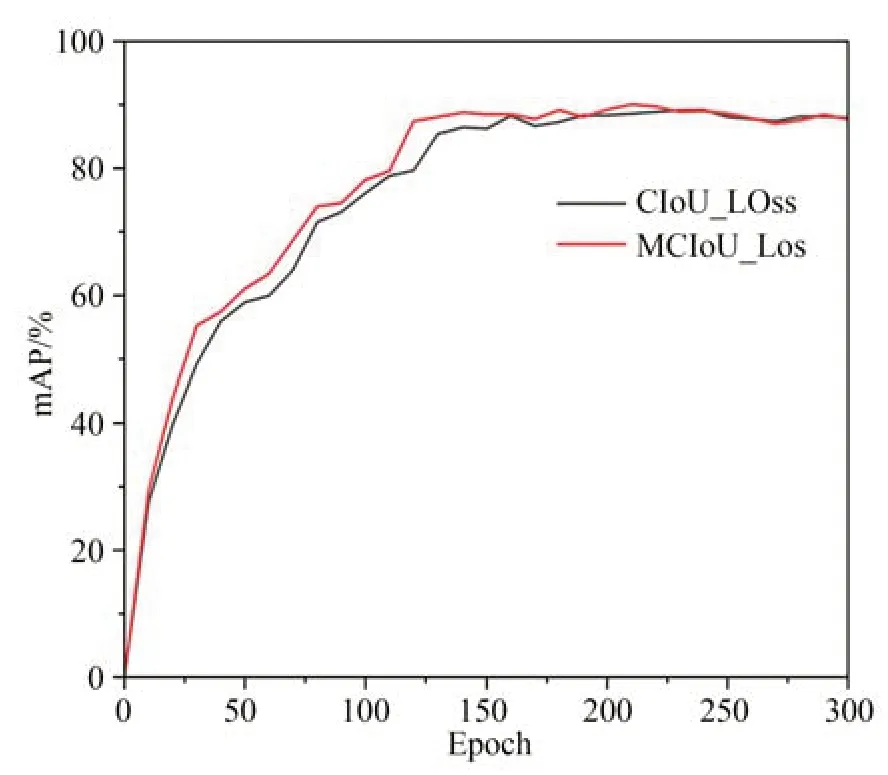
图9 训练过程mAP 值变化曲线Fig.9 Change curves of mAP value in training process
3.2.5 不同网络对比实验
为客观评价本文算法对初烤烟叶等级的检测性能,选用Faster R-CNN[22],Double_head RCNN[23],Dynamic R-CNN[24],SOBL[25],TOOD[26],Sparse R-CNN[27],YOLO 系列[28-33]共20 种检测算法,在实验设备、数据集结构不变条件下与本文方法进行对比实验,实验结果如表6所示。
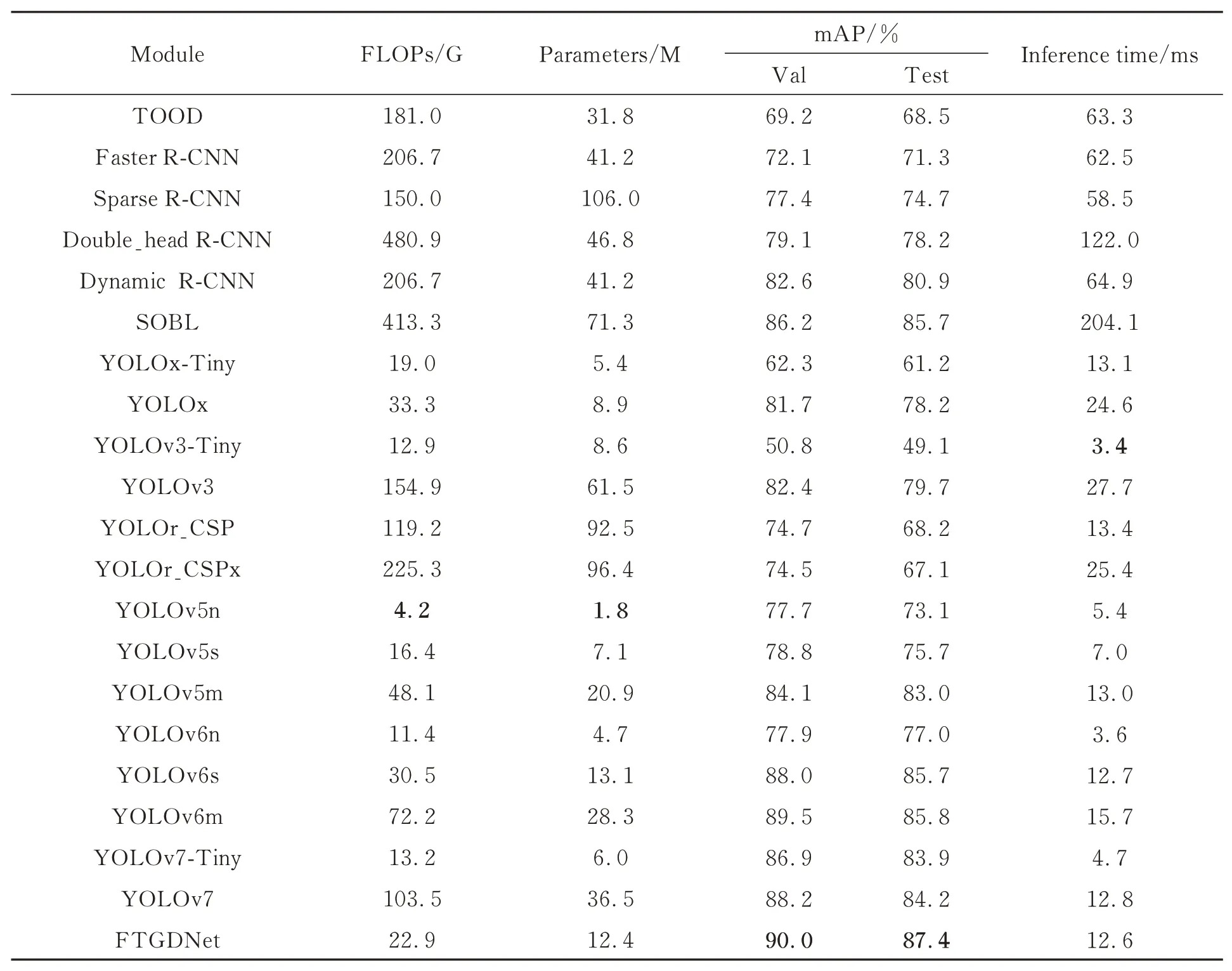
表6 模型效果对比Tab.6 Comparison of model effects
可得到如下结论:
(1)浮点运算数对比,本文模型的浮点运算数为22.9G,与TOOD,Faster R-CNN,Sparse RCNN,Double_head R-CNN ,Dynamic R-CNN,SOBL,YOLOv3,YOLOr_CSP,YOLOr_CSPx,YOLOv5m,YOLOv6m,YOLOv7 相比,FTGDNet 存在较大优势。
(2)参数量对比,FTGDNet 参数量为12.4M,分别为TOOD,Faster R-CNN,Sparse RCNN,Double_head R-CNN,Dynamic R-CNN,SOBL,YOLOv3,YOLOr_CSP,YOLOr_CSPx,YOLOv5m,YOLOv6m,YOLOv7 的 39.0%,30.1%, 11.7%, 26.5%, 30.1%, 17.4%,20.2%, 13.4%, 12.9%, 59.3%, 43.8%,34.0%。
(3)检测精度对比,FTGDNet 的验证精度达到90.0%,测试精度达到87.4%,均高于所对比的20 种先进检测网络。
(4)推理时间对比,本文模型的推理时间仅为12.6 ms,较YOLOv3-Tiny,YOLOv5n,YOLOv5s,YOLOv6n,YOLOv7-Tiny 轻量化模型慢,但仍具有较高的实时检测性。
综上分析,FTGDNet 在初烤烟叶等级检测任务有着更为优秀的性能。
3.3 检测结果与定性分析
由上述对比实验可知,在初烤烟叶分级据集FTLGD 上,本文所提方法有着更为优越的检测性能。图10 对比了不同网络对初烤烟叶分级的测试结果,可以看出,YOLOv3-Tiny,YOLOv3,YOLOv5s,YOLOv6s 均存在不同程度的检测缺失问题,预测框无法覆盖叶片区域,YOLOv7-Tiny,YOLOv7 存在错检或漏检问题。与原始YOLOv5s 网络相比,本文模型在精度和泛化能力均有较大提升,引入MCIoU_Loss 定位损失函数后,模型的定位精度有一定程度的提升。
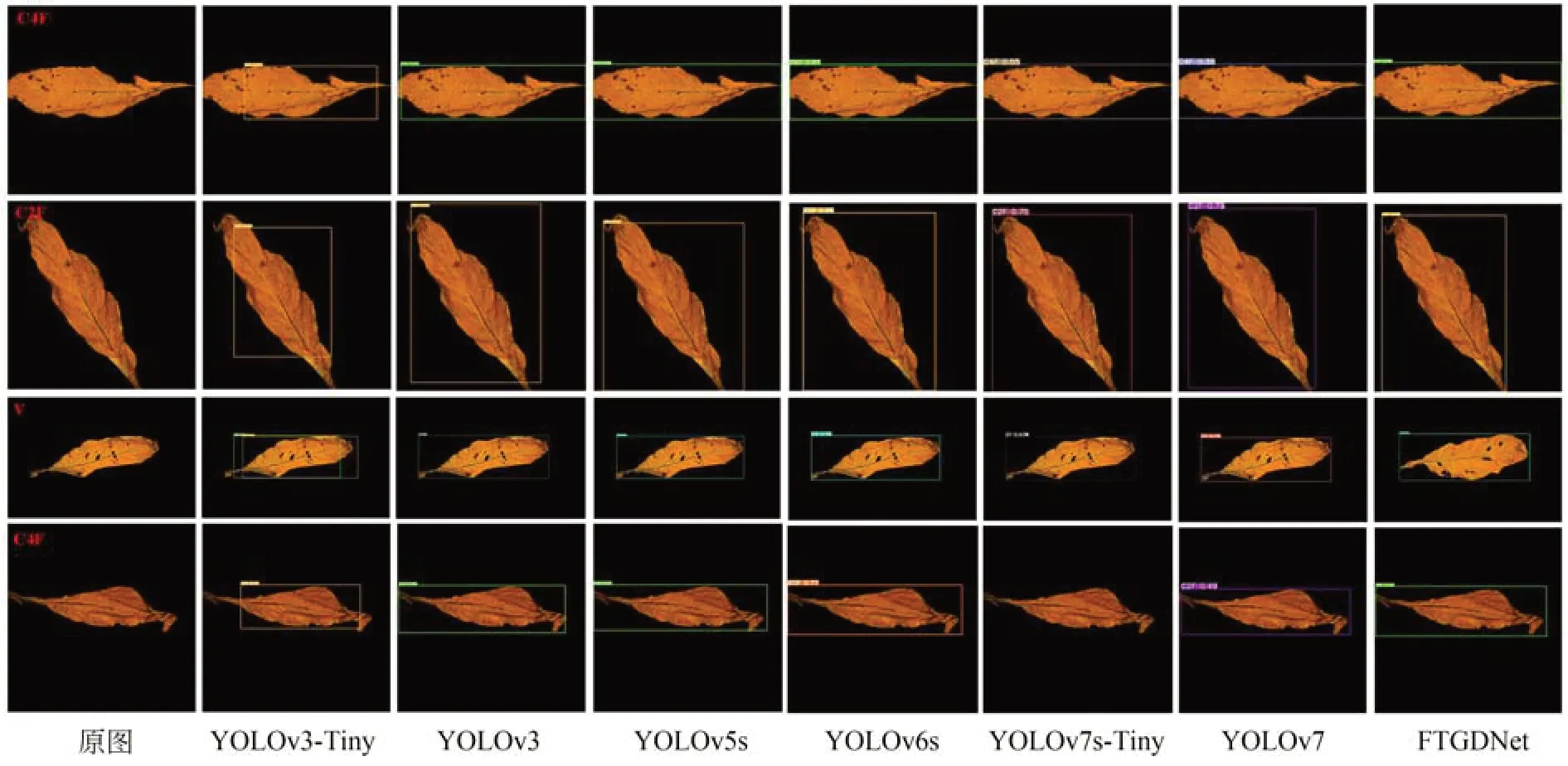
图10 网络检测结果可视化Fig.10 Test result visualization
为加深对FTGDNet 理解,本文对FTGDNet和YOLOv5 特征提取过程进行可视化,如图11所示,可以看出,Stage 0 到Stage 6 随着网络深度的加深,网络提取的特征从叶片的轮廓结构信息逐渐过渡到深层语义信息,CSPNet 和GhostNet共同提取叶片特征信息,在Stage 9 到Stage 20 由深层语义信息指导浅层轮廓信息,使网络获取更完整的目标轮廓和位置信息,在Stage9-Stage17阶段,随着网络深度的加深,FTGDNet 明显较YOLOv5 保留了更多的有效的深层特征信息。
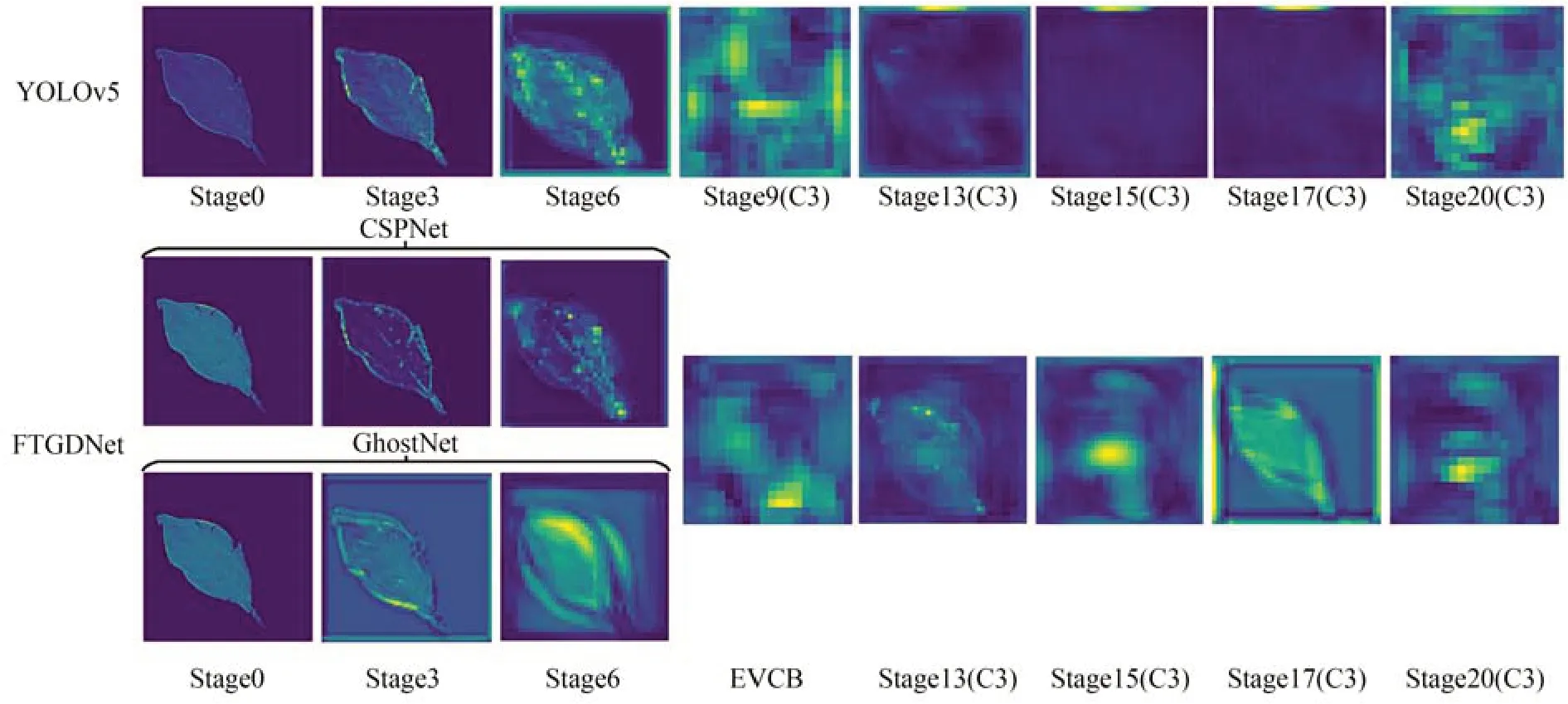
图11 FTGDNet 和YOLOv5 特征提取过程可视化Fig.11 Visualization of FTGDNet and YOLOv5 feature extraction process
4 结 论
针对相似度较高但等级不同的初烤烟叶难以区分问题,本文提出了多感受野特征自适应融合及动态损失调整的初烤烟叶等级检测算法FTGDNet,算法采用CSPNet 和GhostNet 共同提取叶片特征信息以达到增强模型特征提取能力的目的;嵌入显式视觉中心瓶颈模块将全局特征与局部特征相融合;通过多感受野特征自适应融合模块将不同感受野的特征图进行自适应加权融合,增强模型的局部感受野的同时突出有效通道信息;使用MCIoU_Loss 定位损失函数解决模型在回归定位过程中真实框与预测框宽高比相等且中心点重合时CIoU_Loss 定位性能退化问题。FTGDNet 对FTGD 中十个等级初烤烟叶的验证精度达到90%,测试精度达到87.4%,高于TOOD,Faster R-CNN,Sparse R-CNN,Double_head R-CNN,Dynamic R-CNN,SOBL,YOLOv3,YOLOx,YOLOr,YOLOv5,YOLOv6,YOLOv7 等主流目标检测网络,同时,FTGDNe的推理时间分别仅为12.6 ms,具有较高的实时检测性能。
猜你喜欢
活力(2019年15期)2019-09-25 07:21:56
电子制作(2018年19期)2018-11-14 02:37:08
现代园艺(2017年23期)2018-01-18 06:58:18
中国医疗保险(2017年6期)2017-07-18 11:28:19
自动化学报(2017年11期)2017-04-04 02:52:58
中国卫生(2016年5期)2016-11-12 13:25:50
中国卫生(2015年10期)2015-11-10 03:14:22
中国卫生(2015年6期)2015-11-08 12:02:44
天津造纸(2015年2期)2015-01-04 08:18:13
噪声与振动控制(2015年4期)2015-01-01 07:08:21
