
轻量级重参数化的遥感图像超分辨率重建网络设计
2024-02-29 12:02:20易见兵陈俊宽谢唯嘉
光学精密工程 2024年2期
易见兵, 陈俊宽, 曹 锋, 李 俊, 谢唯嘉
(江西理工大学 信息工程学院,江西 赣州 341000)
1 引 言
单图像超分辨率(Super-Resolution,SR)技术旨在从相应的低分辨率(Low Resolution,LR)图像或一系列LR 帧重建出高分辨率(High Resolution,HR)图像。SR 技术广泛应用于医学成像[1]、视频监控[2]、图像处理、视频分析[3]、智能手机照片处理[4]和遥感图像处理[5]等领域。在遥感领域,由于卫星成像设备的限制,所得到的遥感图像分辨率有限,导致后续的遥感解译任务(如目标探测[6]、场景分类[7]等)实现难度较大。虽然升级卫星成像设备可以提高遥感图像的分辨率,但这种方法成本非常高。因此,利用SR 技术提高遥感影像的空间分辨率是一种有效的方法。
单张图像的超分辨率是一个典型的非适定问题,通常采用图像先验的约束来恢复高分辨图像。早期,一些研究者提出了基于插值的单幅图像超分辨算法,比如双三次插值[8]和其改进的算法。这些算法简单的基于局部图像先验设计,无法取得更多的外部信息,导致所恢复图像的边缘和轮廓出现模糊的问题。之后,研究者又提出了基于学习的超分辨率算法,如基于邻域嵌入的算法[9],基于稀疏表示的算法[10],以及基于局部线性回归的算法[11]。这些算法非常依赖图像的先验信息,且在图像之间探索先验信息的过程是非常耗时的,并且先验信息的缺乏也会导致基于这些算法的性能急剧下降。
超分辨率卷积神经网络(SR Convolutional Neural Network,SRCNN)[12]是第一个提出利用卷积神经网络来解决超分辨率问题的算法,它通过三层网络学习低分辨图像到高分辨图像之间的映射,实现了较好的重建结果。从这时开始,许多基于深度学习的超分辨率算法被提出,这些算法通过引入多种复杂的网络结构,例如残差学习[13]和密集连接等[14]方式,在自然图像中取得了较好的重建效果。但相比于自然图像,遥感图像大多是城市地貌、山川田野和道路交通等地貌类型,所以遥感图像在更小的像素尺寸中包含更多的信息,对此许多基于深度学习的遥感图像超分辨率(Remote-Sensing Image Super-Resolution,RSISR)算法被一一提出。例如Haut 等人[15]采用视觉注意机制引导网络学习更高效的特征表示。Pan 等人[16]提出了一种残差密集反投影网络,用于提高RSISR 中尺度和大比例的因子。Dong 等人[17]设计了一种密集采样机制,引导网络考虑多尺度特征,进行大规模的RSISR 重建。Lei 等人[18]提出了一种混合尺度自相似度提取网络,同时利用单尺度和多尺度遥感图像中的相似特征,用来提高RSISR 的效果。虽然上述算法都取得了很好的性能,但它们通常都具有复杂的网络结构,需要高性能的计算平台来部署和运行,导致这些算法难于应用到资源有限的设备上,因此,研究轻量级的遥感图像超分辨率网络非常有必要。
为了构建高效和轻量的遥感图像超分辨率网络,本文提出了一种轻量级基于重参数化残差特征网络(Re-parameterization Residual Feature Network,ReRFN)。依据重参数化思想,本文设计了一个简单有效的重参数化分支模块(Re-parameterization Block,Reblock),具体就是在训练阶段采用几条重参数化分支来分别提取不同特征信息,之后在推理阶段合并为一个正常的3×3 卷积,达到既提升网络性能又不增加模型参数的目的。借助Reblock 在模型性能方面的优势,构建出一个更有效的重参数化残差局部特征模块(Re-parameterization Residual Local Feature Block, ReRLFB),作为网络模型局部特征提取的基本模块。考虑到遥感图像中存在许多相似特征,利用这些特征可以进一步提高RSISR 的性能,因此本文提出了一个轻量级的增强型全局上下文模块(Enhanced Global Context Block,EGCB),它可以有效地对全局上下文相似特征进行关联以提升网络的特征表达能力。为了充分提取图像的特征信息,本文将ReRLFB 与EGCB 结合组成本文特征提取的基本模块。最后,引入多层特征融合模块聚合所有的深度特征,以产生更全面的特征表示,从而提升模型性能。本文算法主要贡献如下:
(1) 基于重参数化思想,本文提出了一种简单高效的重参数化分支模块,该模块可以在不增加任何推理成本的情况下提升3×3 卷积的性能,随后以该模块为基础设计了一种残差特征模块,用于更好的提取图像的局部特征。
(2) 针对遥感图像中存在大量的重复和相似特征,本文提出了一种轻量级的增强型全局上下文模块,该模块通过关联图像的相似特征来提升网络的特征表达能力,并通过调整通道压缩倍数来减少模型的参数量和改善模型的性能。
(3) 为进一步提高模型的特征表达能力,本文设计了一个多层特征融合模块来聚合所有的深度特征,有效地提高了模型的图像超分辨重建能力。
2 相关工作
2.1 重参数化结构
最近,一些关于重参数化的研究证明了该项技术在各种视觉任务中可以取得非常好的效果,例如图像分类、目标检测和图像分割等。Arora等人[19]证明了随着网络层数的加深,全连接层的重参数化可以加速网络的训练。Ding 等人[20]提出了一种非对称的卷积模块(Asymmetric Convolution Block,ACB),通过合并三个不同的卷积来加强正常卷积,这种方式相当于一种形式的结构重参数化。RepVGG[21]首先将3×3 卷积解耦为标识映射的1×1 卷积和3×3 卷积组成的多分支模块,使传统VGG 的性能达到ResNet 系列的水准,其中多分支模块利用不同的尺度特征,极大地丰富了正常卷积的表达能力。Zhang 等人[22]提出了一种面向边缘的卷积模块(Edge-oriented Convolution Block,ECB),用来提高移动设备中实时超分辨率网络的性能。Zhang 等人[23]将边缘提取滤波器和宽激活(Wide activation)块集成到重参数化分支模块中,加强了重参数化模块的特征提取潜力,使模块能更好地学习特征中的高频信息。
2.2 注意力机制
注意力机制的作用是让机器在学习的过程中区分需要和不需要的数据信息,用于提高模型性能,该技术已被广泛用于各种视觉任务,例如:图像分类、图像超分辨率、图像配准和目标检测等。NLNet[24]中提出了一种Non-local 模块,通过非局部运算的方式查询全局上下文聚合信息的位置,为捕获长距离依赖关系提供了一种开创性的算法。Hu 等人[25]通过研究信息特征的构成方式,提出了压缩和扩张(Squeeze and Excitation,SE)模块,其目的是捕获通道之间的相互依赖关系,然后根据信息特征的重要程度选择强调或抑制信息特征,提高网络提取特征的质量。Cao 等人[26]对全局上下文进行建模,聚合所有位置的信息特征,提出了全局上下文(Global Context,GC)模块。Liu 等人[27]提出了极化自注意力模块(Polarized Self-Attention,PSA),通过融合通道和空间注意力分支中的Softmax 和Sigmoid 组成,并保持了输入特征的内部分辨率,解决了因池化和下采样导致的高分辨率信息丢失问题。Zhu 等人[28]为了高效地定位有价值的键值对,提出了双级路由注意力模块(Bi-level Routing Attention,BRA),其目的是在粗糙区域级别过滤掉大部分不相关的键值对,即冗余信息,保留有价值的键值对。鉴于注意力机制对网络性能的提升,本文通过使用注意力模型来增强网络提取特征的能力。然而,上述注意力往往不是轻量的,而且还有些注意力对SR 性能的提升相对有限,考虑到遥感图像存在许多相似特征,本文提出了一种轻量级的增强型全局上下文模块,可以有效地对全局上下文建模。
3 网络模型
3.1 网络的总体结构
重参数化残差特征网络(ReRFN)融合了重参数化思想、局部残差学习思想、全局上下文建模思想和后上采样策略,同时还引入了增强空间注意力(Enhanced Spatial Attention,ESA)提升模型性能。如图1 所示,该网络模型主要由四个部分组成:浅层特征提取网络、深层特征提取网络、多层特征融合网络和最后的上采样超分辨重建网络。
3.1.1 浅层特征提取
假定ILR和ISR分别表示模型输入和输出的图像,对于ILR,ISR∈RC0×H×W,其中C0表示输入图像的通道数,对于彩色图像C0为3,H×W表示图像的空间尺寸。首先在浅层特征提取之前对输入图像进行预处理,将输入图像复制n次,然后沿通道维度将其拼接在一起,增大浅层特征所提取的图像信息。其拼接过程可表示为:
其中:Concat(·)表示沿通道维度的拼接操作,n表示ILR的拼接个数,本文将n设置为4,InLR的特征维度为12×H×W。之后,将预处理后的图像输入到下一层的3×3 卷积中,提取图像的浅层特征信息,浅层特征提取的过程可以表示为:
其中:H3×3(·)表示3×3 卷积操作,F0表示提取到的浅层特征,其特征维度为C×H×W。
3.1.2 深层特征提取
在该部分中,本文使用了6 个ReFB 模块,其中每一个ReFB 的输入特征都是前一个模块的输出特征。浅层特征F0在经过几个堆叠的ReFB特征提取后,可以提取到不同的深度特征。该过程表示为:
其中:Hi表示第i个ReFB,Fi-1和Fi分别表示为第i个ReFB 的输入特征和输出特征,其特征维度均为C×H×W。
3.1.3 多层特征融合
为了充分利用来自所有深度的特征,首先通过Concat操作将各个深度的特征信息进行拼接,然后使用1×1 卷积和GELU 激活进行特征融合和映射,最后使用Reblock 将特征进行优化。多层特征融合的公式可以表示为:
其中:Concat(…)表示将模块输出各个深度的特征沿通道维度进行拼接,Hfusion(·)表示为特征融合模块,执行的是1×1 卷积操作和GELU 激活,然后采用Reblock 模块进行特征优化,Ffused表示最后的聚合特征,特征维度为C×H×W。
3.1.4 上采样超分辨率重建
将多层特征融合完成后,依据残差学习的思想使用了一个全局跳跃连接,将浅层特征F0与聚合特征Ffused特征值相加,然后进行图像的上采样操作。目前在超分辨率重建中将尺度放大的操作常见的有三种,分别为基于插值、亚像素卷积[29]和反卷积操作。在这几种图像上采样操作中,亚像素卷积不仅采样的效果较好,且速度更快更轻量,所以本文采用亚像素卷积操作组成本文的上采样重建模块,其重建的过程可以表示为:
其中:Hup表示图像重建模块,由3×3 卷积和像素洗牌操作组成。
3.1.5 损失函数
与其他的超分辨率算法类似,本文采用L1损失函数对模型进行优化,在超分辨率中L1 损失函数可以提供更为稳定的梯度,加快网络的收敛速度。其损失函数的表达式为:
其中:N表示应训练图像的数量,ISR和IHR分别表示重建后的图像与真实高分辨率的图像,i表示第i张图像,L1 损失函数通过这两张图像之间的差异来指导模型训练。
3.2 重参数化特征模块
如图2 所示,重参数化特征模块(ReFB)由重参数化残差局部特征模块(ReRLFB)、增强空间注意力(ESA)模块和增强型全局上下文模块(EGCB)组成。其中输入的特征首先需要经过ReRLFB 进行局部特征提取,然后再通过ESA 模块使残差特征更集中于关键的空间内容,最后再采用EGCB 对特征进行全局上下文建模,关注图像中的相似特征,这样可以使ReFB 更充分地提取图像中的有用信息,增强模型性能。
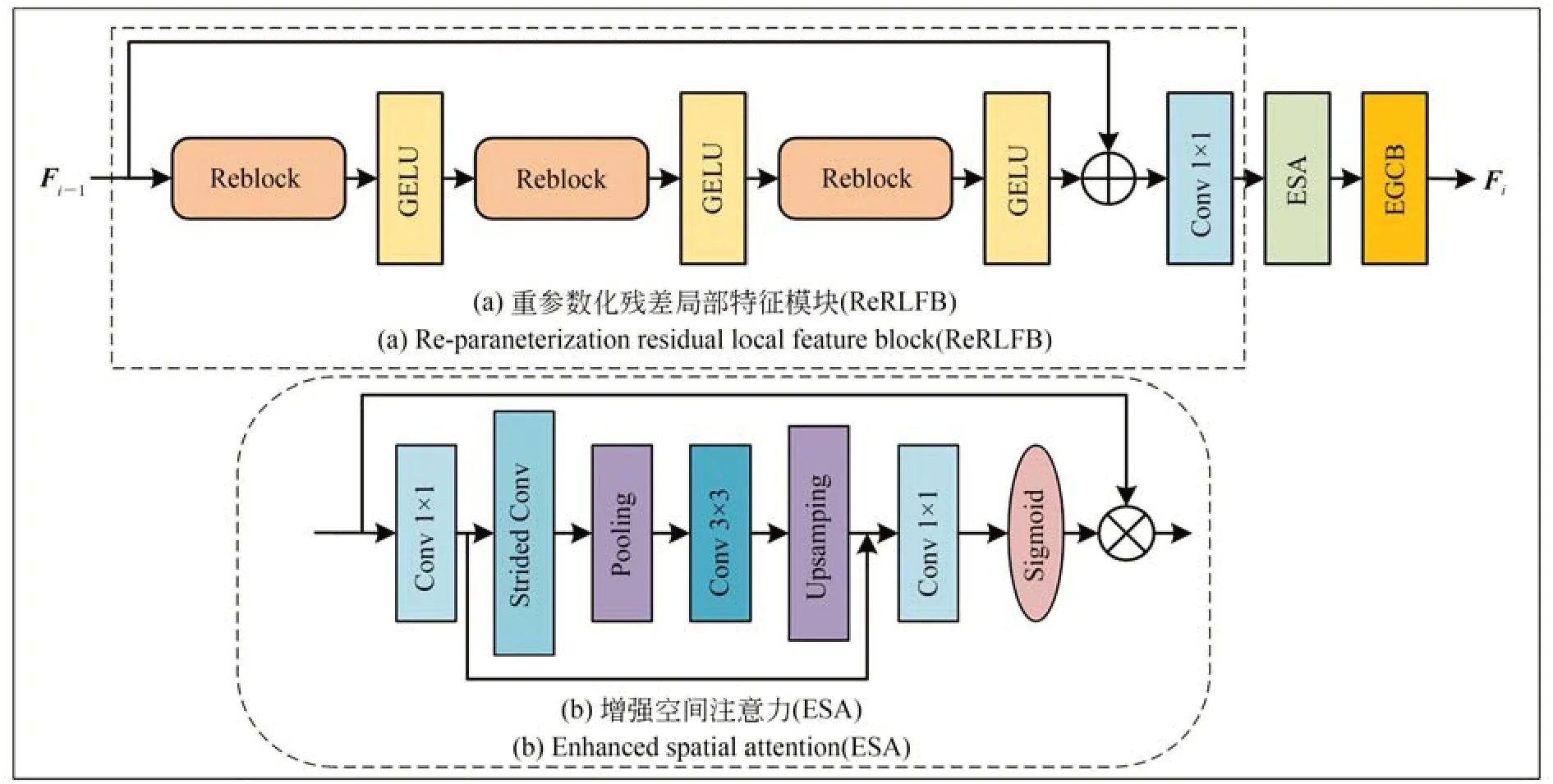
图2 重参数化特征模块(ReFB)Fig.2 Re-parameterization feature block(ReFB)
3.2.1 重参数化残差局部特征模块
在SR 任务中,大多数的轻量级模型主要是通过复杂的层连接来提高模型的特征利用率,但是这些方式通常具有较高的计算复杂度,且影响了模型的运行速度。为更好地实现模型性能与运行速度之间的平衡,本文在Kong 等人提出的残差局部特征模块(Residual Local Feature Block,RLFB)[30]上进行了优化,构建出了ReRLFB 模块,其总体框架如图2(a)所示。本文采用3 个堆叠的Reblock+GELU 层进行局部特征提取,具体来说,就是将每一个堆叠层都看作一个局部特征细化模块,将输入的特征进行逐步细化。假设输入的特征为Fin,这个过程可以表示为:
其中:RMj表示第j个细化模块,表示第j 个模块细化后的特征。在经过多个局部特征细化层的细化步骤后,本文使用残差连接方式将最开始输入的特征Fin与最后输出的细化特征相加,然后通过1×1 卷积将特征聚合,这个过程可以表示为:
其中:Frefined表示为最终细化的输出特征,H1×1(·)表示1×1 卷积操作。为了提高模型的特征利用率,本文引入了一个轻量级的增强空间注意力模块(ESA)[31]来增强模型的性能,其结构如图2(b)所示,该过程可以表示为:
其中:Fenhanced表示为增强后的特征,HESA(·)表示提高模型特征提取能力的ESA 模块。
3.2.2 增强型全局上下文模块
目前的一些超分辨率算法,为了给网络提供较大的感受野,通常是通过堆叠多个卷积层来实现,这导致了模型过深和效率过低,考虑到遥感图像中存在大量的重复和相似特征,如果能对图像全局特征的相似性进行关联,可以有效提高模型性能。因此,本文提出了一种增强型全局上下文模块(EGCB),该模块能够有效地关联图像的相似特征以提升其在图像恢复任务中的适用性,其结构如图3 所示。在EGCB 中,使用了多个1×1 卷积对全局上下文建模和特征转换,并且本文为了使模型变得更加轻量,还使用了通道压缩倍数r对输入特征图的通道数C进行压缩,达到减少模型的参数量与计算复杂度的目的。
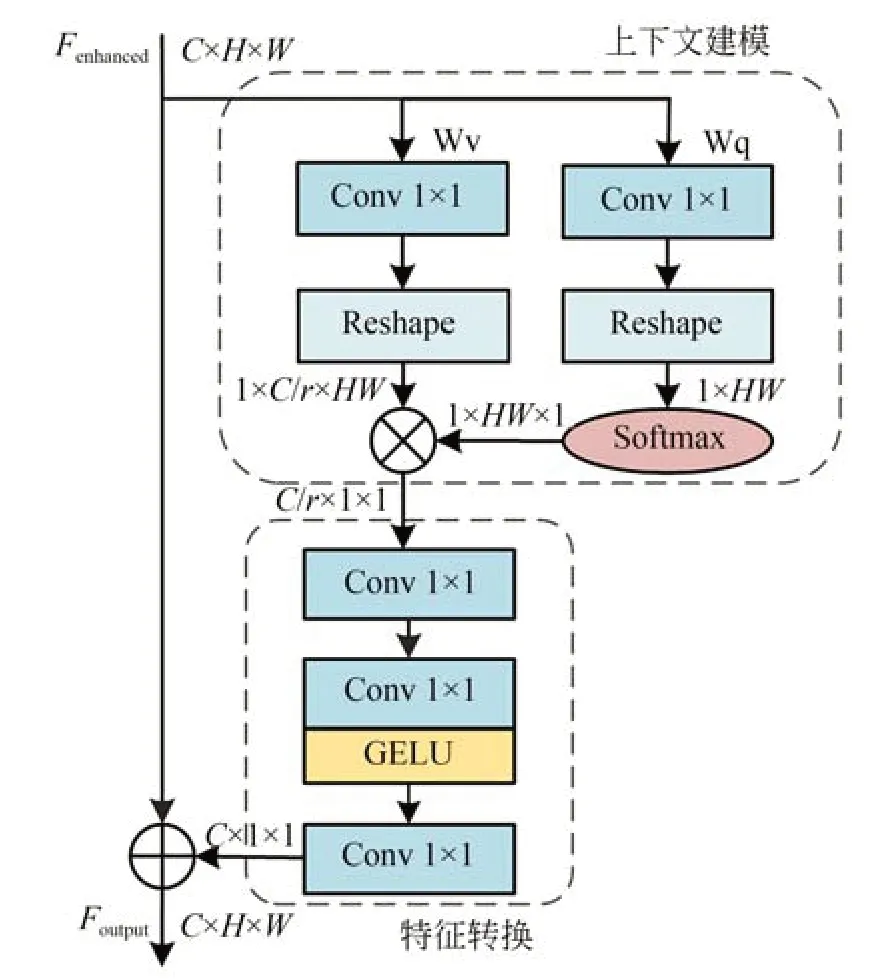
图3 增强型全局上下文模块(EGCB)Fig.3 Enhanced global context block(EGCB)
具 体 地 ,对 于 输 入 的 特 征 图Fenhanced∈RC×H×W,该模块主要分为三个过程:(1) 对输入的特征图Fenhanced进行上下文建模,用于获取全局上下文特征。其中一条分支采用1×1 卷积Wq和softmax 函数获得注意力权值,该注意力权值可以理解为每个像素点的相关性,另一条分支使用1×1 卷积Wv对输入特征进行细化,通过矩阵乘法的操作首先将注意力权值与1×C/r×HW维度的输入特征进行元素级的相乘,然后将每一个通道特征层内的所有值相加,最后得到C/r×1×1 的全局关系,获得全局上下文特征。其过程可以表示为:
其中:fq和fv都代表通道降维的1×1 卷积操作;Xq与Xv表示经过1×1 卷积操作后的特征图;与表示维度改变后的特征图;Softmax()得到的是0~1 之间的值,表示注意力权值;⊗表示矩阵乘法;Y表示获得全局上下文信息的特征图。(2)对获得的全局上下文信息进行特征转换并进一步提取信息,本文设计了几个1×1 的卷积对获得的全局上下文特征进行转换和优化。(3)将获得的特征聚合,本文使用残差连接的方式将变换后的全局上下文特征聚合到原始输入特征Fenhanced上,生成最终的输出特征图Foutput。该过程可以表示为:
其中:transform(·)表示特征转换操作,作用是将输入的特征进行优化和将C/r的通道数转换为C的通道数,以便与原始的输入特征图Fenhanced进行元素相加。
3.3 重参数化分支模块
本文所提算法核心就在于围绕重参数化的思想进行轻量化设计。通过研究其他重参数化结构,本文发现重参数化分支对正常卷积性能提升是非常有效的,但随着重参数化分支的增加,所带来的训练时间是成倍的增长,并且过多的分支在特征合并时会导致特征信息衰减。为了解决这些问题,本文减少了重参数化分支的数量,同时考虑到特征信息的衰减,本文采用残差连接作为一条重参数化分支来增强和保护特征信息,以此为基础,本文构建了一个简单而有效的重参数化分支模块,即Reblock,如图4 所示,Reblock由三条分支组成。
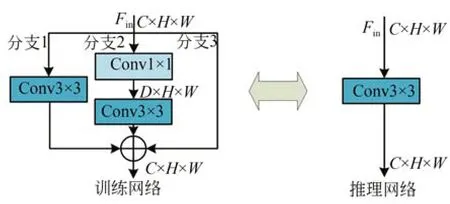
图4 重参数化分支模块(Reblock)Fig.4 Re-parameterization block(Reblock)
在训练阶段,本文使用Reblock 对模型进行训练,以获取更丰富的中间特征,其中第一条分支使用正常的3×3 卷积来保证模块的正常性能。这个正常卷积的过程可以表示为:
其中:Fn表示输出特征,Fin表示输入特征图,Kn表示正常卷积的权值,Bn表示偏置。
第二条分支采用扩张和压缩卷积。在SR 任务中,深度特征可以显著提高特征表达能力,提升模型性能,所以本文采用扩张和压缩卷积进一步从特征映射中提取深层信息。首先使用1×1卷积将输入特征图Fin的通道维度从C扩张到D,然后再通过3×3 卷积将通道维度压缩回C。扩张和压缩的卷积过程可以表示为:
其中:Fes表示经过扩张和压缩卷积后的输出特征,Fin表示输入特征图,Ks,Bs表示压缩卷积的权值和偏置,Ke,Be表示扩张卷积的权值与偏置。
第三条分支为恒等映射分支,即不经过任何卷积运算,用于增强和保护特征信息。在重参数化时恒等映射相当于一个特殊(以单位矩阵为卷积核)的1×1 卷积,Kin表示该特殊1×1 卷积的权值,偏置Bin为0。
然后,重参数化分支模块的输出特征结合了这三条分支的输出,该过程可以表示为:
其中:F为Reblock 的输出特征,最后将组合的特征F映射馈送到非线性激活层,本文采用GELU。
在推理阶段,本文将Reblock 转化为正常的3×3 卷积,达到既提升网络性能又不增加模型参数的目的。该过程是通过加法操作将三条分支的权值和偏置进行相加,然后将所有的参数合并到一个3×3 卷积上。该重参数化过程可以表示为:
其中:Krep表示重参数化后相加得到的权值;Brep表示重参数化后相加得到的偏置;Kes,Bes表示扩张和压缩卷积合并后的权值与偏置;Fin表示输入特征图;F表示单个卷积的输出特征,该输出特征与Reblock 的输出特征是等价的。
4 实验结果和分析
在本节中,本文将遥感图像的超分辨率重建效果作为实验主要任务,并将所提出的算法与最新的算法进行比较,然后还探讨了本文算法在自然图像超分辨率重建和自然图像去噪上的性能。对于提到的每一个任务,本文将分别说明数据集、实现细节和实验结果。实验环境配置:操作系统为Windows10,CPU 为3.6 GHz 的Inter(R)Xeon(R) W-2123,GPU 为11 GB 显存的NVIDIA RTX2080ti,采用深度学习框架pytorch1.9.0。
4.1 实验设置
本文所有实验均采用Adam 优化器来训练模型,一阶矩和二阶矩的指数衰减率分别设置为β1=0.9,β2=0.999。针对不同的任务的不同训练数据集,本文采取了不同的训练策略,首先在遥感图像的超分辨率任务中,将初始学习率设置为1×10-4并在第400 个epoch 减半处理;然后在自然图像的超分辨率任务中,将初始学习率设置为5×10-4,使用余弦退火调整学习率衰减;最后在自然图像的去噪任务中,将初始学习率设置为1×10-3,使用余弦退火调整学习率衰减,每个任务均采用L1 损失函数对模型优化。本文采用90°,180°,270°随机旋转和水平翻转的数据增强方法将数据集扩增10 倍。本文模型使用ReFB的个数为6,其中每个ReFB 的输入和输出通道数C均设置为50,在超分辨率任务中采用亚像素卷积的方法对图像进行2 倍、3 倍和4 倍放大,在图像去噪任务中不采取任何上采样操作。
本文采用峰值信噪比(PSNR)和结构相似性 (SSIM)对所有结果进行评价,其中PSNR 用于比较输出图像与HR 之间像素的差异,SSIM用于评价输出图像的结构相似度,两个评价指标的值越高说明网络模型效果越好。特别地,本文还分析了本文网络模型的参数量与计算量,用于衡量网络模型的大小与计算复杂度。
4.2 遥感图像超分辨重建实验
本文选择采用UC Merced 遥感数据集[32]来证明本文所提出算法的有效性。UC Merced 的数据集由21 个遥感场景类别组成,其中每一个类别都有100 张图像,总计2 100 张,并且每一种图像的大小均为256×256 pixel,空间分辨率为0.3 m/pixel。与其他遥感图像的超分率算法一样,本文将数据集分为两个部分:训练集和测试集,均为1 050 张图像。在本文实验中,通过双三次插值运算的方法对HR 进行下采样得到LR(下采样倍数为×2,×3,×4),并将相应的HR 图像作为ground truth,对于2 倍、3 倍和4 倍超分辨率任务,随机剪裁大小为96×96,144×144,196×196 的HR 块,最小训练批次设置为15,总共训练500 个周期。
为了验证本文算法对遥感图像超分辨率重建性能,将本文算法ReRFN 在UC Merced 测试集做了相关实验,并与多个优秀的遥感图像超分辨率算法进行对比,包括:Bicubic 插值[8],SC[33],SRCNN[12],FSRCNN[34],LGCNet[35],DCM[15],HSENet[18],CTN[36],ReFDN[23]等算法。表1 展示了各个算法性能对比的结果,此外本文还提供了在256×256 的HR 遥感图像下各种算法在不同尺度的参数量与计算量(M-Adds)。从表中数据可知,本文模型在各项指标中大部分优于其他模型,与比本文算法参数量少1/3 的CTN 算法相比较,本文算法在UC Merced 测试集中2 倍、3倍、4 倍超分辨率重建所得到的PSNR 值分别高0.75 dB,0.56 dB 和0.28 dB,SSIM 分别高0.007 2,0.013 和0.011 3。与HSENet 算法相比,本文算法的PSNR 值和SSIM 有高有低,但总体来说本文算法更加有效,且所需要的参数只有HSENet 算法的1/10。本文所提算法相较于其他更轻量的算法,在评价指标上均取得了更好的效果,并且在参数量和计算量上都做到了轻量级的水平。
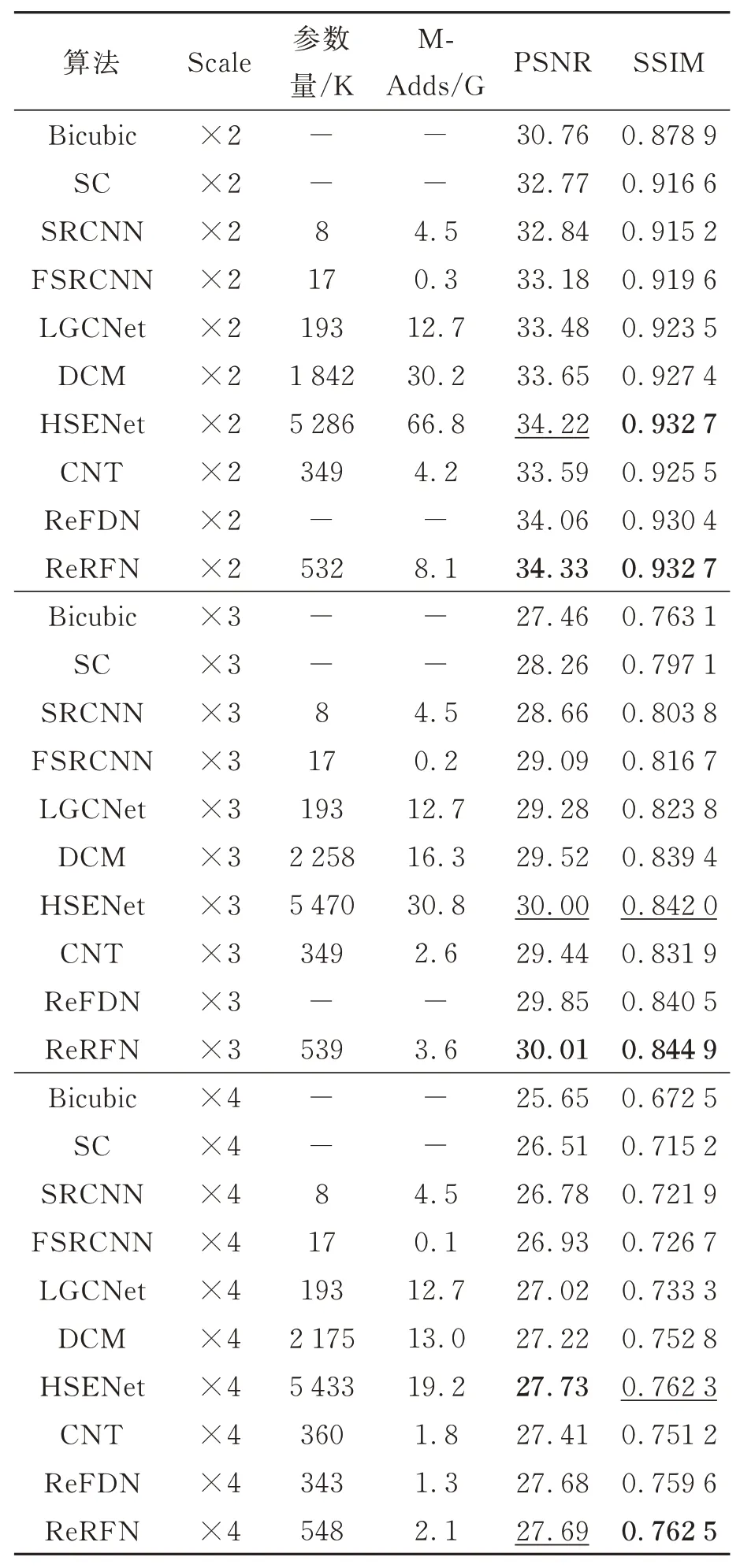
表1 各算法在UC Merced 测试集下的性能对比Tab.1 Performance comparison of various algorithms in UC Merced test dataset
主观视觉效果方面。在UC Merced 测试集的不同尺度重建结果如图5 和图6 所示。图5 表示的是各个算法对3 倍遥感图像重建的结果,以图像Airplane91 为例,Bicubic,SRCNN,LGCNet等算法恢复的飞机机翼存在明显的边缘模糊和伪像,虽然DCM,HSENet 和CNT 算法可以消除部分模糊和伪像,但仍然存在重建的图像质量不高的问题,相比之下本文算法恢复的图像边缘更加精准清晰,与HR 图像更为接近。图6表示的是各个算法在4 倍超分辨率重建的结果,以图像Runway50 为例,其中Bicubic,SRCNN,LGCNet 这三种算法重建的效果较差,跑道的路线模糊不清,存在明显的伪影,DCM,HSENet和CNT 算法重建的质量有所提升,但是仍然存在边缘扭曲的现象。本文算法ReRFN 相比其他算法能重建出更高质量的图像,对边缘和轮廓的恢复也是更加清晰可见,并在一定程度上抑制了虚假信息的产生。实验结果表明,本文提出的ReRFN 算法在主观视觉上也能取得更好的重建结果。

图5 Airplane91 在3 倍超分辨率重建的结果Fig.5 Reconstruction results of Airplane91 at ×3 SR

图6 Runway50 在4 倍超分辨率重建的结果Fig.6 Reconstruction results of Runway at ×4 SR
此外,为了对比各个算法在不同遥感场景下所取得的重建效果,表2 提供了在3 倍超分辨率下21 类遥感场景的PSNR 值。从表中的结果可以看出,本文算法在6 个遥感场景下取得了最好的PSNR 结果,在8 个遥感场景下取得了第二好的PSNR 结果,综合比较下来,本文算法所取得的重建结果最好。相较于其他算法,本文算法在一些包含有相同特征的场景中能够取得更好的重建结果,比如棒球场、森林、河流等地区。特别地,通过对比不同类别的遥感场景可以发现,图像中存在的高频信息越多,超分辨率重建后得到的PSNR 值越低,比如丛林、海港和停车场等地区;若存在的高频信息越少,超分辨率重建后的PSNR 值越高,比如海滩、高尔夫球场和棒球场等地区。
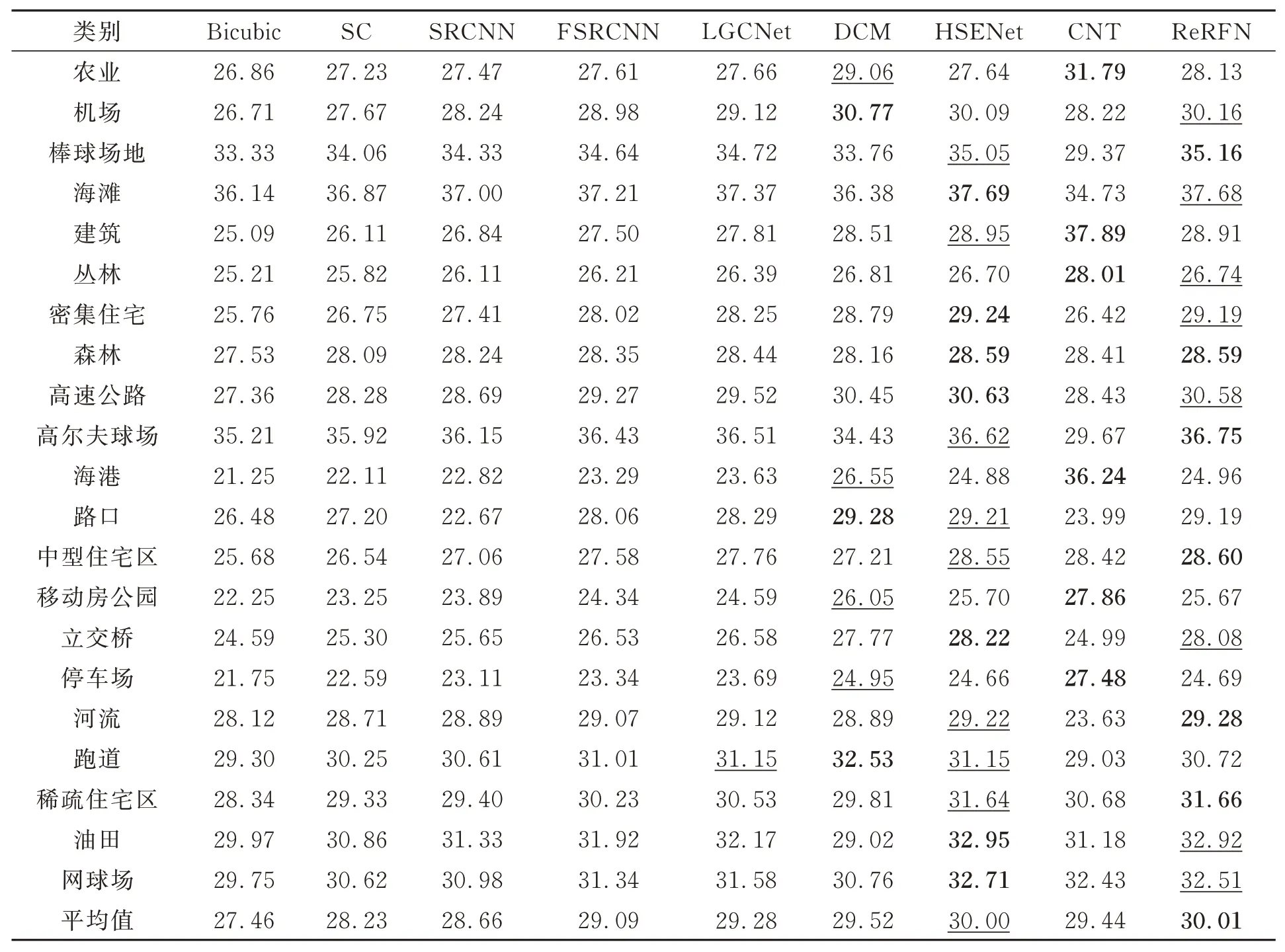
表2 各算法在3 倍超分辨率重建下21 类遥感场景的PSNR 值Tab.2 PSNR values of 21 types of remote sensing scenes for each algorithm under ×3 SR
为了验证算法的综合性能,本文算法分别在模型的参数量、计算量与推理时间等性能指标与其他优秀算法进行了对比,如表3 所示。从表3 可以看到,在遥感图像3 倍超分辨率数下,本文算法在运行时间、参数量、计算量与性能上取得了更好的平衡,并且本文算法以较低的参数量与计算量得到了最大的峰值信噪比,且运行速度相对较快,这对于将该模型应用到现实生活中来说十分重要。
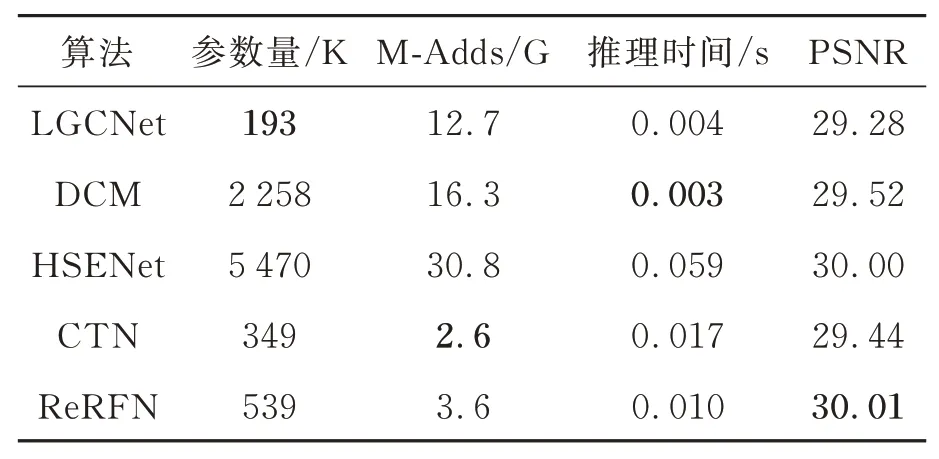
表3 各算法在3 倍超分辨率重建下的模型性能对比Tab.3 Comparison of model performance of various algorithms under ×3 SR
4.3 本文算法的消融实验
为了验证所提出模块的有效性,本文设计了多个消融实验,并分别统计了不同实验在UC Merced 验证集上4 倍超分辨率重建的结果,其中验证集是从测试集中随机抽取的105 张图像。通过消融实验分别进行以下验证:(1) ESA 与EGCB 模块对模型性能的影响;(2) EGCB 模块的通道压缩倍数r对模型性能的影响;(3)重参数化结构分支对模型性能的影响;(4) ReFB 模块的数量对模型性能的影响;(5)堆叠的Reblock+GELU 层数对模型性能的影响;(6)采用多层特征融合模块对模型性能的影响。
4.3.1 ESA 与EGCB 模块对模型性能影响
本文设计了5 种方法来评估ESA 与EGCB模块对模型性能的影响:(1) 方法1:在深层特征提取模块中不使用ESA 与EGCB 模块;(2)方法2:在深层特征提取模块中只使用ESA 模块;(3) 方法3:在深层特征提取模块中只使用EGCB 模块;(4) 方法4:在深层特征提取模块中同时使用ESA 与EGCB 模块,但模块使用的顺序为EGCB 模块在ESA 模块之前;(5) 方法5:在深层特征提取模块中同时使用ESA 与EGCB模块,使用顺序为ESA 模块在EGCB 模块之前。结果如表4 所示,从表中可以看出ESA 和EGCB 模块在不同程度上提高了超分辨率重建的效果,且同时使用ESA 与EGCB 模块所得到的重建结果更好,说明了这两个模块能够有效地获取图像的空间特征和全局上下文特征。并且在同时使用两个模块时,模块的前后顺序也会对结果造成一定影响,其中,ESA 模块的顺序在EGCB 之前时取得的效果最好,说明了ESA提取的空间特征中也存在全局上下文信息,将EGCB 放在模块最后可以进一步提升模型对超分辨率重建的性能。特别是,方法5 相比方法1,虽然参数量上增加了60 K,但是PSNR 和SSIM 分别提高了0.13 dB 和0.004 7,重建效果的改善十分明显。
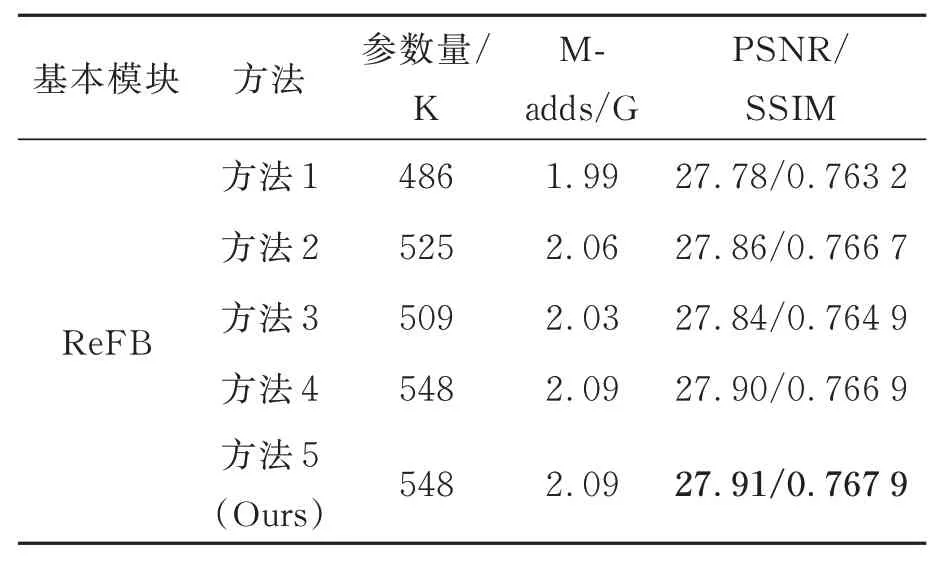
表4 ESA 与EGCB 模块对模型性能的影响Tab.4 Influence of ESA and EGCB on model performance
4.3.2 EGCB 模块的通道压缩倍数r对模型性能影响
本文设计了4 组对比实验,分别设r=1,2,3和4,其中r表示通道维度的压缩倍数。结果如表5 所示,从表中可以看出当r=1 时,即不对EGCB模块的通道数进行压缩,网络模型的整体性能表现最差,且参数量和计算量非常高。当压缩倍数r=2 时,模型的性能取得了最好的表现。随着压缩倍数r 的增加,模型的性能逐渐降低,但相比于r=1,网络的性能仍然要好很多。说明了合适的通道压缩倍数不仅可以减少模型参数量,还可以过滤掉一些无效的信息,提升EGCB 对全局上下文特征的提取能力。为了在性能和模型大小之间进行权衡,所以本文选择将通道压缩倍数设置为r=2。

表5 EGCB 模块的通道压缩倍数r 对模型性能的影响Tab.5 Impact of channel compression Rate (r) of EGCB module on model performance
4.3.3 重参数化结构分支模块对模型性能影响
本文设计了4 种方法来评估重参数化结构分支模块的有效性:(1) 采用正常3×3 卷积作为基本模块进行训练;(2)在基本模块中将扩张卷积和压缩卷积作为Reblock 的第二分支;(3) 在基本模块中将残差连接作为Reblock 的第二分支;(4) 在基本模块中将扩张卷积和压缩卷积作为Reblock 的第二分支,将残差连接作为第三分支,即本文方法。实验结果如表6 所示,从表中结果可以看出,使用这两个分支中的任何一个都可以提高3×3 卷积的性能,并且当两个分支同时使用时可以互补,进一步提高模型的性能。相比于正常的3×3 卷积,Reblock 的PSNR 和SSIM 提高了0.1 dB 和0.003 7,特别地,Reblock 在推理阶段可以合并为一个3×3 卷积,做到了不花费任何的推理成本便可以提高模型的性能。
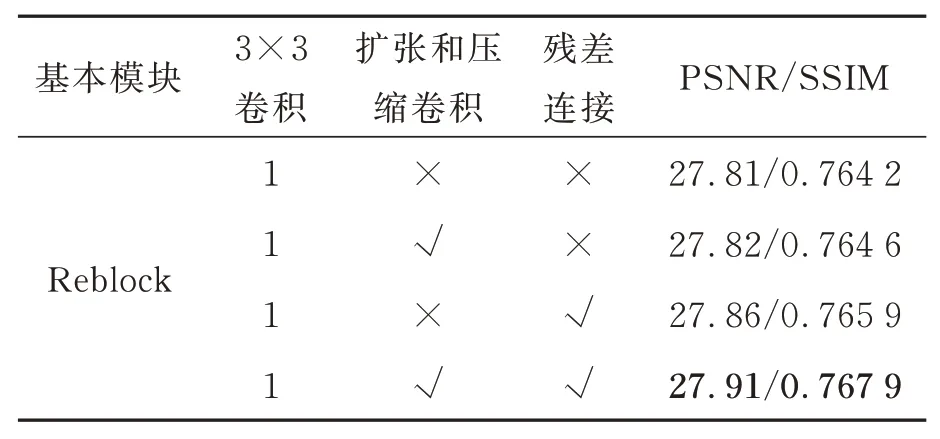
表6 重参数化结构分支模块的性能分析Tab.6 Performance analysis of the re-parameterized structural branch module
4.3.4 ReFB 模块的数量对模型性能影响
本文设计了5 组对比实验来评估ReFB 模块的数量对模型性能的影响,分别设N=4,5,6,7和8,其中N表示ReFB 模块的数量。结果如表7所示,从表中可以看出,当ReFB 的数量超过6时,超分辨率重建的效果达到饱和,且当数量设置为8 的效果比设置为6 和7 效果更差,可能是在增加模块或层数的过程中会引入特征冗余,意味着一些模块可能在信息内容上存在重叠,从而降低了模型的有效性。为了在性能和模型大小之间进行权衡,本文将ReFB 模块的数量设置为6。
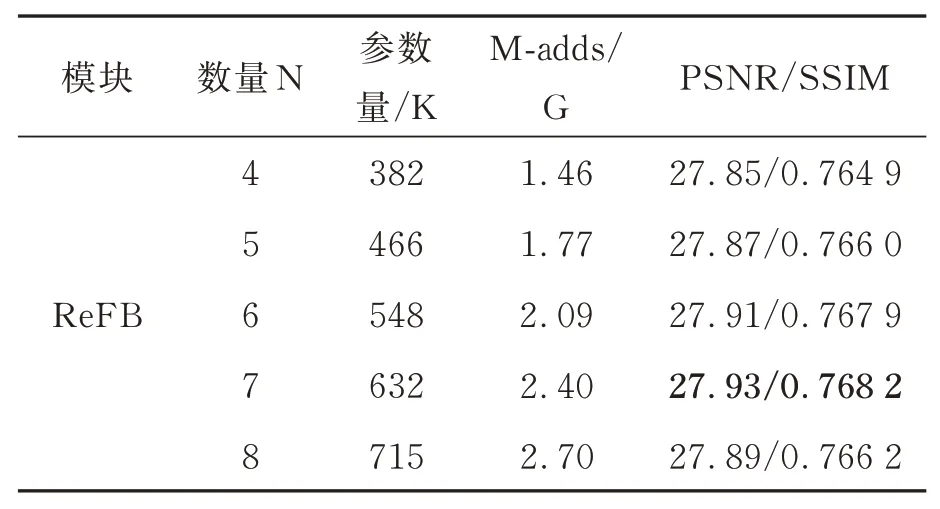
表7 ReFB 模块的数量对模型性能的影响Tab.7 Impact of the number of ReFB modules on model performance
4.3.5 堆叠的Reblock+GELU 层数对模型性能影响
本文设计了5 组对比实验来验证ReRLFB模块中堆叠的Reblock+GELU 层数对模型性能的影响,实验中分别将堆叠的Reblock+GELU层数设置为N=1,2,3,4,5,其中N表示堆叠层的数量。实验结果如表8 所示,从表中可以看出,随着堆叠层数的增加,ReRLFB 模块的性能逐渐提升,当堆叠层数N=4 时达到最好效果,但是随着层数的继续加深,模型性能并没有持续提升。考虑到模型的轻量化,本文选择采用3 个堆叠的Reblock+GELU 层进行局部特征提取,以较少的参数量和计算量获取较为不错的超分辨率重建效果。
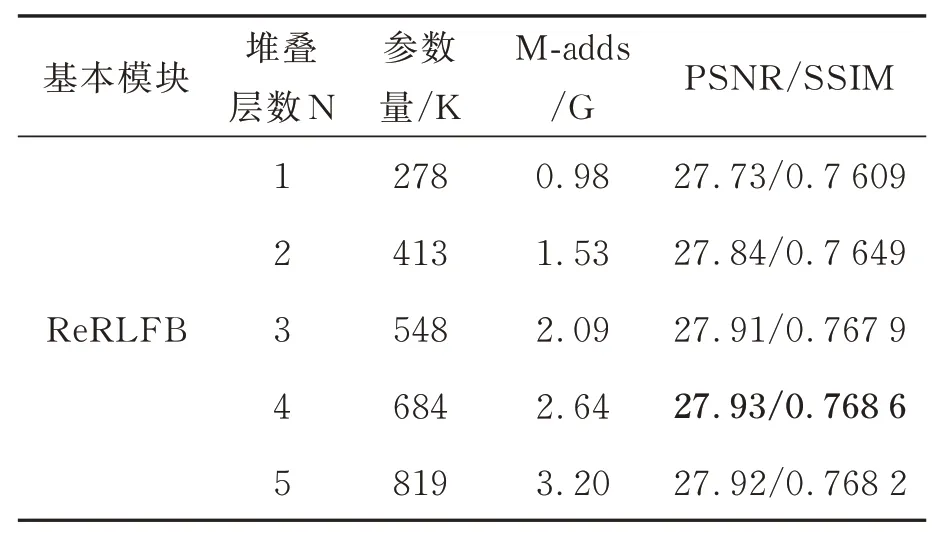
表8 堆叠的Reblock+GELU 层数的对模型性能的影响Tab.8 Impact of the number of stacked Reblock+GELU layers on model performance
4.3.6 多层特征融合模块对模型性能影响
本文设计了两种方法来评估提出的多层特征融合模块对模型性能的影响:(1)方法1:去除模型中的多层特征融合模块;(2)方法2:保留模型中多层特征融合模块。结果如表9 所示,从表中可以看出多层特征融合模块对模型性能的提升是非常有效的。在4 倍超分辨率中PSNR 和SSIM 分别提升了0.04 dB 和0.001 8。
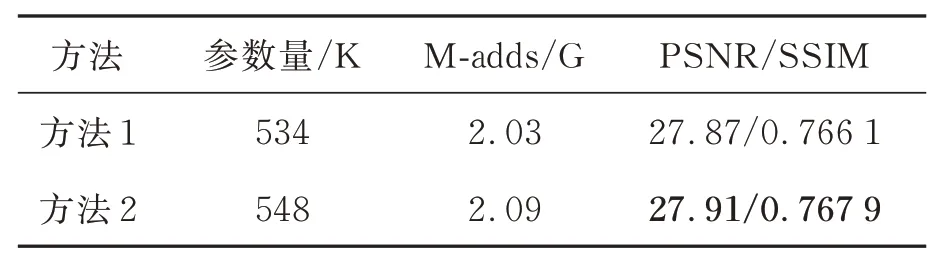
表9 多层特征融合模块对模型性能的影响Tab.9 Impact of the Multi-layer feature fusion module on model Performance
4.4 自然图像超分辨率重建实验
本文选择广泛使用的自然图像超分辨率数据集DIV2K 作为该任务的训练数据集,此数据集包含有1 000 张2 K 分辨率的RGB 图像,其中本文使用800 张HR 图像作为实验的训练集,对应不同尺度的LR 图像同样是使用双三次插值运算的方法进行下采样得到。为了测试模型性能,本文选择使用5 个常见的超分辨率基准测试集,分别为Set5,Set14,B100,Urban100 以及Manga109。对于2 倍、3 倍和4 倍超分辨率重建,随机剪裁大小为128×128,192×192,256×256 的HR 块,最小训练批次设置为64,总共迭代107次。将生成的超分辨率图像变换到YCbCr 空间,在Y 通道上计算PSNR 与SSIM 的值。
为了验证本文算法对自然图像超分辨率重建效果,将本文算法与其他先进的超分辨率算法进行比较,如:Bicubic 插值[8]、SRCNN[12],FSRCNN[34],CARN[37],IMDN[38],RFDN[39],RLFN[30]和DARN[40]等算法。在表10 中,本文提供了在1 280×720 的HR 图像下各种算法在不同尺度的参数量与计算量(M-Adds),通过表中数据可知,本文算法ReRFN 在5 个基准测试集中测试的结果大部分效果更好。其中与本文算法参数量和计算量相近的RLFN 算法相比,本文算法ReRFN 在2 倍超分辨率重建下取得的PSNR 与SSIM 平均提升了0.01 dB 和0.000 1,在3 倍超分辨率重建下取得的PSNR 和SSIM 平均提升了0.1 dB 和0.001,在4 倍超分辨率重建下取得的PSNR 和SSIM 平均提升了0.05 dB 和0.001。本文还通过对比各个算法的模型大小,发现本文算法ReRFN 所需参数量和计算量较少,充分证明了本文算法在模型大小和图像重建性能之间达到了较好的平衡。
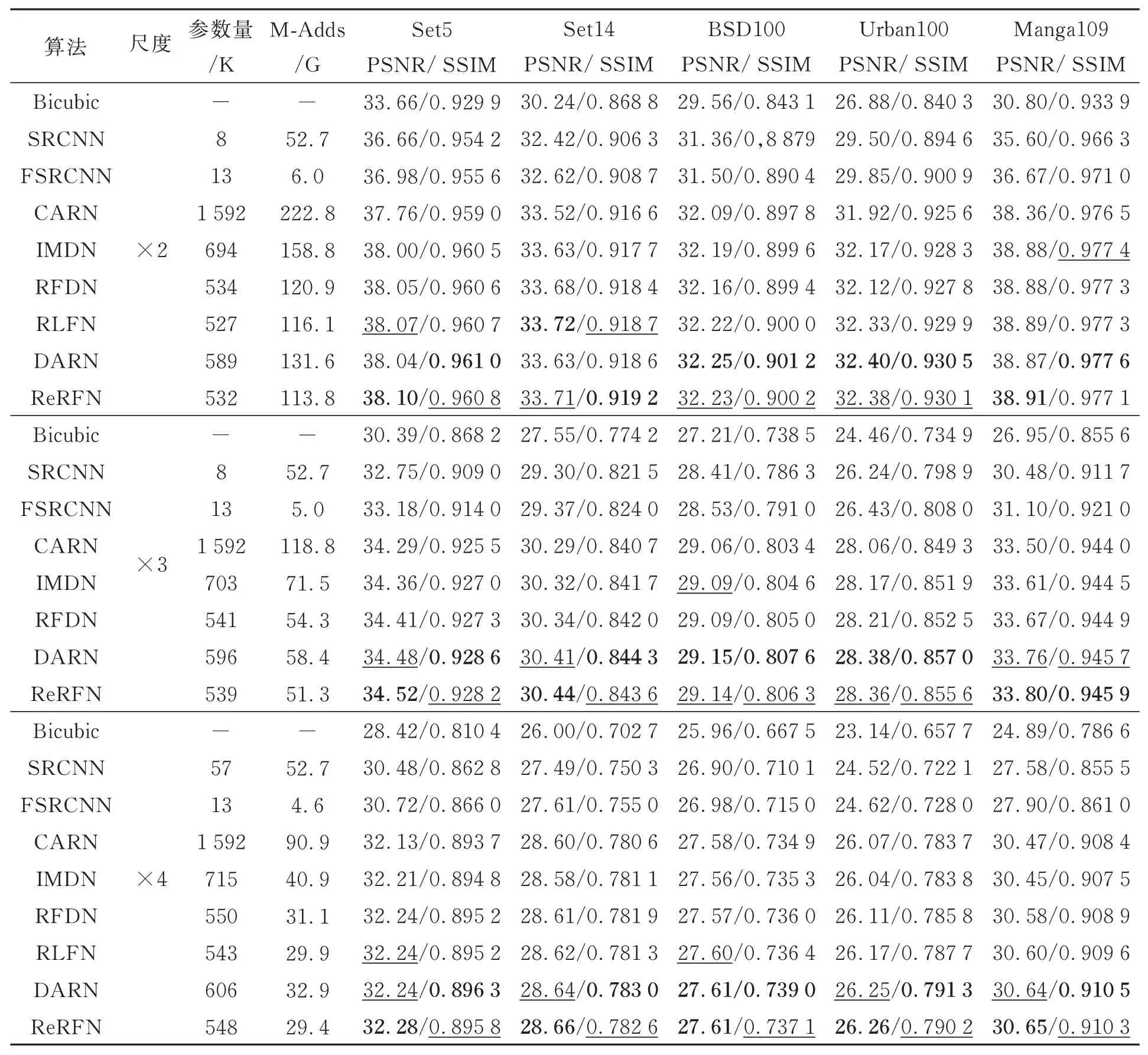
表10 各算法在基准数据集上2、3 和4 倍超分辨率重建下的性能对比Tab.10 Performance comparison of various algorithms on benchmark dataset for ×2,×3, and ×4 SR
主观视觉方面。为了更好的对比不同算法对于自然图像重建的结果,本文选择了具有挑战性的Ubran100 数据集,并在4 超分辨率重建下对Img062 和Img092 进行可视化,结果如图7~图8所示。从图中可以观察到所有算法都存在一定的边缘模糊和伪像,并产生了一定的虚假信息,但相比之下,本文提出的ReRFN 算法所恢复的边缘信息更偏向于真实高分辨率图像,特别是对于虚假信息的出现明显减少,例如图像建筑物中的玻璃边缘与缝隙边缘,其他算法恢复的边缘更加扭曲,图像的细节模糊不清。实验结果表明本文提出的ReRFN 算法在自然图像超分辨率上同样可以取得较为良好的效果。

图7 Urban100 中Img062 在4 倍超分辨重建的结果Fig.7 Results of ×4 super-resolution reconstruction for Img062 in Urban100
4.5 自然图像去噪实验
本文选择广泛使用的自然图像去噪数据集SIDD 作为该任务的训练数据集,该数据集是通过5 部智能手机的相机拍摄的,总共拥有360 个去噪图像对,其中每一张高清图像都有对应的噪声图像。与其他自然图像去噪任务设置一样,本文选择320 对去噪图像作为实验的训练集,40 对去噪图像作为测试集。在训练时,本文将图像裁剪为512×512 pixel 大小,最小训练批次设置为4,总共训练40 个周期,然后在测试集上评估图像去噪的性能。
为了验证本文算法对自然图像去噪的性能,将本文算法ReRFN 在SIDD 测试集上的实验结果与其他优秀的去噪算法进行比较,结果如表11所示。从实验结果可以看出本文算法的各项指标均优于其他算法,去噪后的图像PSNR 和SSIM 分别达到了39.13 dB 和0.954,高于其他算法,且本文算法的参数量只有0.53 M,满足轻量级网络的要求,证明了本文算法对自然图像去噪的有效性。
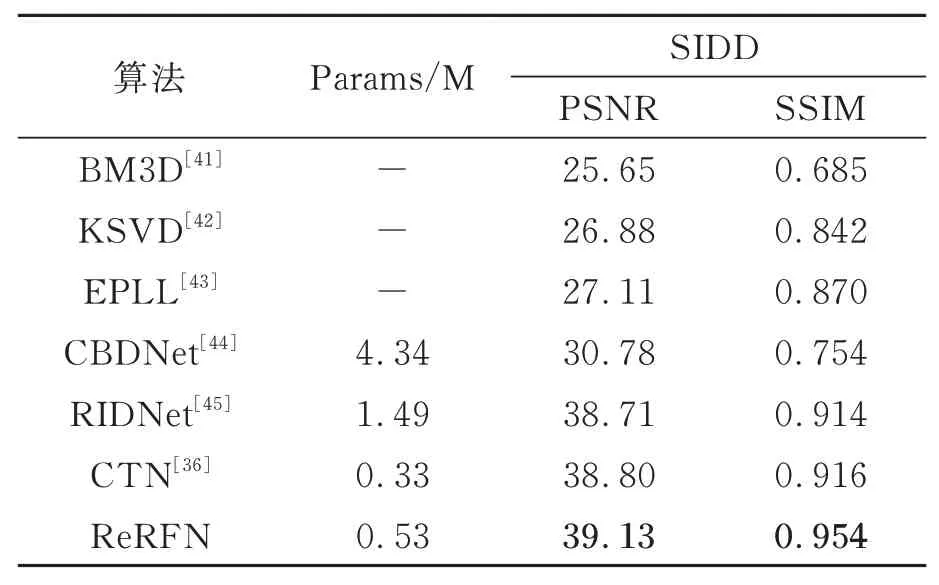
表11 各种算法在SIDD 测试集上的性能对比Tab.11 Performance comparison of various algorithms on the SIDD test set
为了进一步突出各个算法图像去噪的效果,将本文算法与CBDNet,RIDNet 和CTN 算法进行可视化比较,从测试集中抽取了两张图片,其可视化结果如图9 所示(彩图见期刊电子版),为了对比更加明显,本文对红色方框中的图像作了局部放大处理。从图中可以看出,CBDNet 算法恢复的图像仍然存在明显的噪声,图像细节非常模糊,虽然RIDNet 和CTN 算法的去噪能力有所提升,但是其恢复的图像依旧存在明显的噪声,例如图像(a)中的背景存在模糊斑点,线条较难辨清,图像(b)中的按键符号不够真实。本文提出的ReRFN 算法对图像有一定的效果,对边缘信息的恢复更偏向于真实图像,减少了模糊斑点的干扰,进一步验证了本文算法的有效性。

图9 各算法在抽取的SIDD 数据集部分样本的可视化结果Fig.9 Visualization results of selected samples from the SIDD dataset by various algorithms
5 结 论
本文提出了一种新的用于轻量级遥感图像超分辨率的重参数化残差特征网络。首先,采用重参数化残差局部特征模块提取图像中的局部特征;其次,引入增强型全局上下文模块来学习图像的相似特征;然后,将这两个模块结合组成重参数化特征模块,充分利用图像的特征信息;最后,引入多层特征融合模块聚合所有的深度特征,以产生更全面的特征表示,从而提升模型性能。在UC Merced 数据集上的实验结果表明,本文算法所重建遥感图像的PSNR 和SSIM 性能指标均优于其他算法,特别是在3 倍超分辨率重建结果中,相比于次优算法HSENet,PSNR 和SSIM 分别提升了0.01 dB 和0.002 9,且参数量上只有其10%。为了证明本文算法的泛化性,本文在自然图像超分辨率和自然图像去噪方面做了相关实验,实验结果表明本文算法在这两个任务中均有良好表现,进一步证明了本文算法的有效性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
广州文博(2020年0期)2020-06-09 05:15:44
数学物理学报(2019年3期)2019-07-23 01:15:40
电子制作(2019年11期)2019-07-04 00:34:38
家庭影院技术(2018年9期)2018-11-02 05:31:32
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
自动化学报(2017年5期)2017-05-14 06:20:52
成都信息工程大学学报(2017年6期)2017-03-16 03:04:32
兽医导刊(2016年6期)2016-05-17 03:50:15
中国民族医药杂志(2016年2期)2016-05-14 07:12:00
